Материалы по тегу: rtx
|
15.06.2026 [09:32], Сергей Карасёв
96 NVMe SSD с СЖО и четыре RTX Pro 6000: Wiwynn показала сверхбыстрое хранилище на базе NVIDIA SCADAКомпания Wiwynn (дочерняя структура Wistron), по сообщению ресурса Tom's Hardware, продемонстрировала один из первых в отрасли серверов хранения NVIDIA SCADA (SCaled Accelerated Data Access). Устройство ориентировано на высокопроизводительную обработку больших объёмов данных в рамках задач обучения ИИ-моделей и инференса. 
Источник изображений: Wiwynn Новинка выполнена в MGX-шасси высотой 6U и рассчитана на монтаж в 19″ серверную стойку. Задействован процессор NVIDIA Vera, который содержит 88 ядер Olympus, или Intel Xeon (в составе HPM-). Доступны восемь слотов для модулей DDR5. Система несёт на борту четыре ускорителя NVIDIA RTX Pro 6000 Blackwell Server Edition, четыре коммутатора PCIe 6.x и четыре 800G-карты ConnectX-9 SuperNIC/DPU BlueField-4 (опционально GPU можно поменять на DPU). Реализовано полностью жидкостное охлаждение.  Сервер рассчитан на 96 накопителей EDSFF E3.S SSD с вертикальной загрузкой. При использовании изделий Micron 9650 Pro вместимостью 30,72 Тбайт с интерфейсом PCIe 6.0 суммарная ёмкость достигает 2,949 Пбайт. При этом обеспечивается показатель IOPS на операциях случайного чтения до 528 млн. Максимальное энергопотребление новинки — 9 кВт (питание DC 50 В). Кабели питания и гибкие шланги СЖО расположенные в нишах по бокам, что позволяет выдвигать лоток с накопителями и производить «горячую» замену SSD. 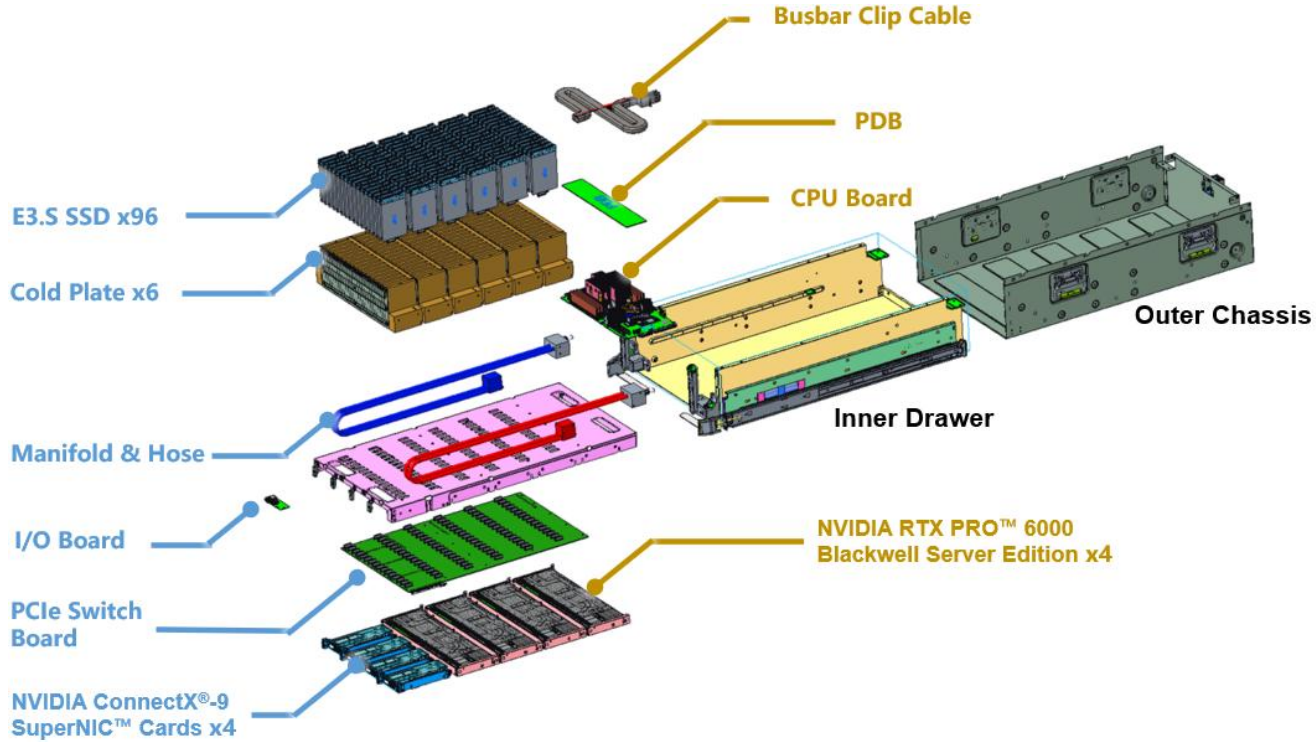 Отмечается, что традиционные серверы на основе CPU плохо справляются с такими задачами, как векторный поиск, генерация с дополненной выборкой (RAG), анализ графов и извлечение данных из KV-кеша. При таких нагрузках процессору необходимо выдавать команды, обрабатывать запросы и контролировать передачу данных, из-за чего создаются узкие места. 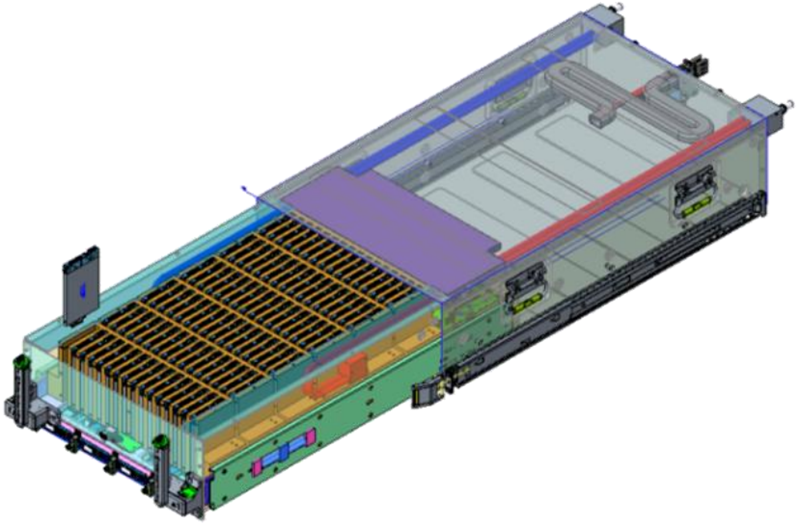 Платформа SCADA позволяет решить проблему благодаря тому, что операции ввода-вывода и обработка данных возлагаются на GPU — без участия CPU. По сути, ускорители RTX Pro 6000 Blackwell Server Edition в составе машины выполняют функции процессоров хранения, которые инициируют и обрабатывают транзакции и миллионы запросов со стороны ИИ-приложений, а также передают данные на вычислительные узлы посредством карт ConnectX-9.
25.03.2026 [12:08], Сергей Карасёв
ZutaCore представила водоблок для NVIDIA RTX Pro 6000 Blackwell Server EditionРазработчик систем прямого безводного двухфазного жидкостного охлаждения ZutaCore анонсировал водоблок OmniTherm для ускорителя NVIDIA RTX Pro 6000 Blackwell Server Edition. Новинка позволяет повысить плотность монтажа ИИ-карт в составе серверов, ориентированных на корпоративные и облачные среды. Решение OmniTherm обеспечивает возможность применения двухфазного охлаждения. При этом используется герметичная конструкция с диэлектрической жидкостью. Теплоноситель при контакте с чипом закипает и превращается в пар, который конденсируется в отдельном контуре. Блок OmniTherm позволяет реализовать однослотовую систему охлаждения, благодаря чему достигается экономия пространства внутри сервера. 
Источник изображения: ZutaCore Переход на СЖО также помогает повысить энергетическую эффективность оборудования, снизить уровень шума и вибрации (благодаря отсутствию вентиляторов). ZutaCore отмечает, что OmniTherm отводит тепло не только от кристалла GPU, но и от других расположенных рядом дорогостоящих компонентов, включая чипы памяти НВМ. Снижение тепловой нагрузки на эти элементы может повысить долговременную стабильность и минимизировать вероятность сбоев. Кроме того, ZutaCore представила облачную платформу HyperCool Cloud, предназначенную для управления системами жидкостного охлаждения в комплексных средах. Эта платформа практически в режиме реального времени предоставляет информацию о работе различного оборудования, включая блоки распределения охлаждающей жидкости (CDU).
18.03.2026 [08:44], Сергей Карасёв
NVIDIA выпустила однослотовый ускоритель RTX Pro 4500 Blackwell Server Edition с 32 Гбайт памяти GDDR7Компания NVIDIA анонсировала ускоритель RTX Pro 4500 Blackwell Server Edition, подходящий для решения таких задач, как ИИ-инференс, анализ данных, обработка видеоматериалов и пр. Новинка ориентирована на дата-центры, облачные платформы и периферийные инфраструктуры. Решение выполнено на архитектуре Blackwell. Конфигурация включает 10 496 ядер CUDA, 82 ядра RT четвёртого поколения, а также 32 Гбайт GDDR7 с 256-бит шиной и пропускной способностью 800 Гбайт/с. Задействованы тензорные ядра пятого поколения, которые обеспечивают до трёх раз более высокую производительность по сравнению с более ранними изделиями и предлагают поддержку режима FP4. Карта получила однослотовое исполнение FHFL и пассивное охлаждение. Заявленное энергопотребление составляет 165 Вт. Для подключения служит интерфейс PCIe 5.0 x16. ИИ-быстродействие на операциях FP4 (Tensor Core) достигает 1,6 Пфлопс, FP8 (Tensor Core) — 811 Тфлопс, FP16/BF16 (Tensor Core) — 406 Тфлопс, TF32 (Tensor Core) — 203 Тфлопс. Как отмечает NVIDIA, по сравнению с системами, работающими только на основе CPU, ускоритель RTX Pro 4500 Blackwell Server Edition обеспечивает до 100 раз более высокую производительность при анализе видеоматериалов с помощью алгоритмов ИИ. Благодаря этому компании могут извлекать данные из видеопотока в режиме реального времени, ускоряя работу приложений компьютерного зрения — как в ЦОД, так и на периферии. 
Источник изображения: NVIDIA Предусмотрены три аппаратных движка NVIDIA NVENC девятого поколения. Они имеют поддержку кодирования 4:2:2 H.264 и HEVC, а также улучшают качество при работе с HEVC и AV1. Вместе с тем три движка NVIDIA NVDEC шестого поколения демонстрируют вдвое более высокую пропускную способность при декодировании материалов H.264, а также поддерживают 4:2:2 H.264 и HEVC.
06.03.2026 [08:58], Руслан Авдеев
Akamai развернёт тысячи ускорителей NVIDIA RTX Blackwell для распределённого инференсаОблачный провайдер Akamai анонсировал покупку «тысяч» ИИ-ускорителей для развития своей распределённой облачной инфраструктуры по всему миру. Развёртывание новых чипов позволит создать единую оптимизированную ИИ-платформу для быстрого и распределённого инференса в глобальной сети Akamai. По словам компании, она готовит базовую инфраструктуру для «физического» и «агентного» ИИ, где решения необходимо принимать в режиме реального времени. Ранее компания анонсировала проект Akamai Inference Cloud. Как заявляет Akamai, пока крупные облачные бизнесы расширяют проекты обучения ИИ, компания сосредоточилась на удовлетворении потребностей эпохи инференса. Централизованные ИИ-фабрики имеют важное значение для создания моделей, но для их масштабной эксплуатации необходима децентрализованная «нервная система». Внедрение NVIDIA Blackwell в распределённая инфраструктуру, как ожидается, позволит ИИ взаимодействовать с «физическим» миром на местах — с системами автономной доставки, умными энергосетями, роботами-хирургами, антифрод-системами т.п. — без географических и финансовых ограничений, характерных для классических облаков. Интеграция ускорителей Blackwell обеспечит:
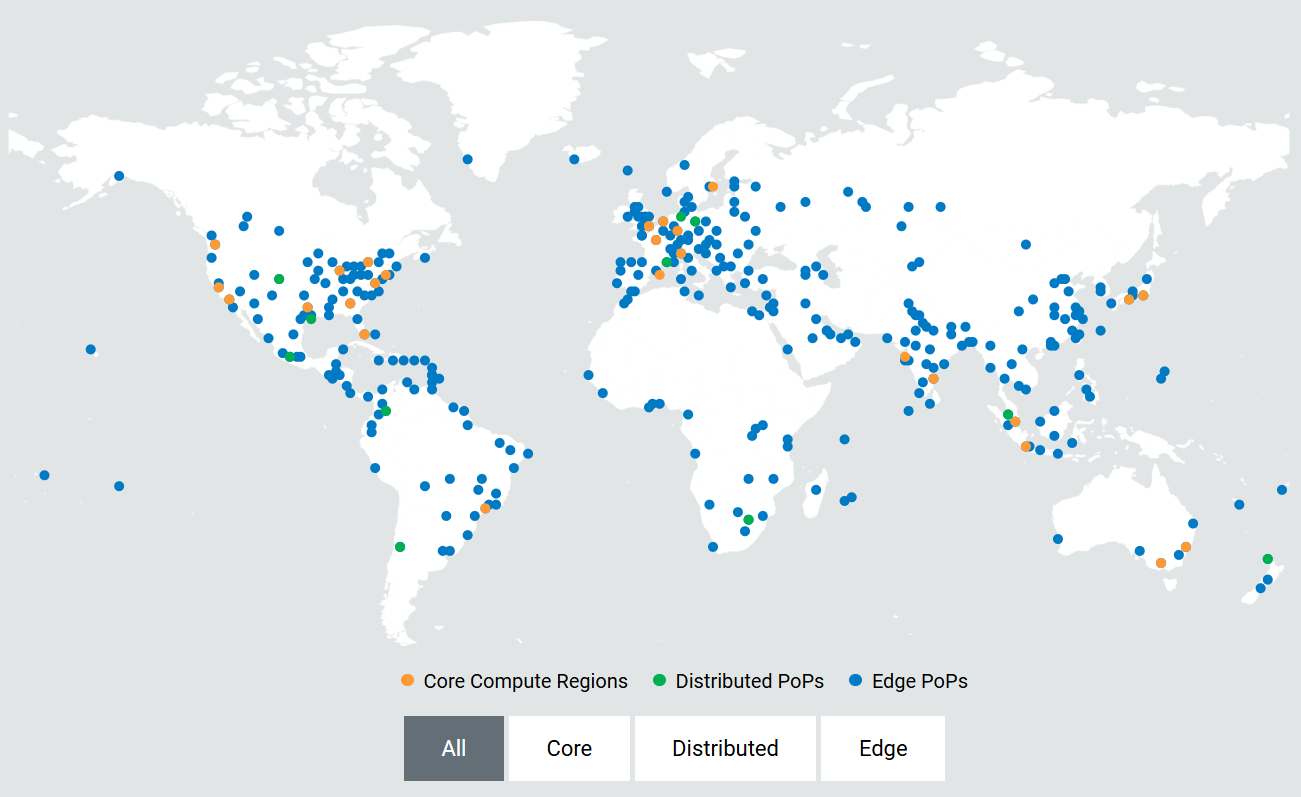
Источник изображения: Akamai Предоставляя инструментарий для выполнения задач ближе к конечным пользователям, Akamai обеспечивает высокую пропускную способность и, как утверждается, одновременно снижает задержку до 2,5 раз. Это позволит бизнесам экономить до 86 % на инференсе в сравнении с обычными облачными компаниями-гиперскейлерами. Платформа объединяет серверы на основе ускорителей NVIDIA RTX Pro 6000 Blackwell Server Edition с DPU NVIDIA BlueField-3 и распределённую облачную инфраструктуру Akamai с 4,4 тыс. точек присутствия. Cloudflare применяет платформу с «бессерверным» инференсом в более чем 200 городах. Её Workers AI обеспечивают глобальный инференс с задержкой менее 100 мс без специального выделения кластеров ускорителей. Fastly применяет платформу периферийных вычислений, но предлагает меньшее количество локальных точек присутствия (PoP) для выполнения задач на GPU/CPU.
13.01.2026 [09:03], Руслан Авдеев
Lenovo представила серверы для ИИ-инференса: ThinkSystem SR675i V3/SR650i V4 и ThinkEdge ThinkEdge SE455i V4Lenovo представила новые серверные системы серии Lenovo Hybrid AI Advantage, оптимизированные для ИИ-инференса: ThinkSystem SR675i V3, ThinkSystem SR650i V4 и ThinkEdge SE455i V4. Если ранее акцент делался на решениях для обучения всё более производительных ИИ-моделей, то теперь бизнес обращает всё больше внимания на продукты для инференса. Новинки предлагаются параллельно с ПО для оптимизации инференса — для унификации и получения данных из разных источников для использования ИИ-моделями. 
Источник изображений: Lenovo Флагманской версией серии является ThinkSystem SR675i V3 в исполнении 3U на платформе AMD EPYC Turin 9535 (64C/128T, 2,4 ГГц, TDP 300 Вт). Сервер получил 1,5 Тбайт DDR5-6400 (24 × 64 Гбайт). За хранение данных отвечают до двух E3.S NVMe SSD по 3,84 Тбайт (PCIe 5.0 x4) и до двух M.2 NVMe SSD по 960 Гбайт (PCIe 4.0 x4). Возможна установка восьми ускорителей NVIDIA RTX PRO 6000 Blackwell Server Edition, а также пяти DPU NVIDIA BlueField-3 (4 × 400G, 1 × 200G). IPMI в данной модели не доступен. Для карт расширения доступно до шести слотов PCIe 5.0 х16 и один слот OCP 3.0 x8/x16. За питание отвечают четыре блока Titanium второго поколения (по 2300 Вт), а за охлаждение — пять вентиляторов.  ThinkSystem SR650i V4 позиционируется в качестве системы для инференса и корпоративных рабочих нагрузок. Этот 2U-сервер получил два Intel Xeon Granite Rapids-SP 6530P (32C/64T, 2,3 ГГц, TDP 225 Вт), 512 Гбайт DDR5-6400 (8 × 64 Гбайт), два ускорителя RTX PRO 6000 Blackwell Server Edition. За хранение отвечают два 3,84-Тбайт U.2 NVMe SSD (PCIe 5.0 x4), хотя всего таких слотов восемь, а также RAID1-массив из пары 960-Гбайт M.2 SATA SSD. Всего доступно шесть слотов расширения PCIe 5.0 x16 и два слота OCP 3.0 x8/x16. Имеется двухпортовый 25GbE-адаптер Broadcom 57414 (SFP28). За питание отвечают два Titanium-блока мощностью 2700 Вт каждый, а за охлаждение шесть вентиляторов, но есть и опция установки фирменной СЖО Neptune.  Наконец, Lenovo ThinkEdge SE455i V3 (2U) глубиной всего 440 мм представляет собой компактную модель, предназначенную для периферийного инференса — в ретейле, телекоммуникациях и промышленности. Сервер имеет защищённую конструкцию и может работать при температурах от -5 до +40 °C. Сервер построен на базе одного процессора AMD EPYC Embedded 8534P (64C/128T, 2,3 ГГц, TDP 200 Вт), дополненного 576 Гбайт DDR5-4800 (6 × 96 Гбайт) и двумя ускорителями NVIDIA L4 24 Гбайт (PCIe 4.0 x16). В комплекте идёт один 3,84-Тбайт NVMe SSD и один 960-Гбайт SATA SSD. Имеется два блока питания Platinum второго поколения с возможностью горячей замены. Для карт расширения есть до двух слотов PCIe 5.0 x16 и до четырёх слотов PCIe 4.0 x8, а также один слот OCP 3.0 (PCIe 5.0 x16). Установлен двухпортовый OCP-адаптер Broadcom 57416 (10GbE). IPMI отключён.  Фактически компания предлагает готовые конфигурации, которые можно переконфигурировать лишь слегка, чаще всего добавив накопители и/или сетевые адаптеры. Платформы будут доступны в рамках подписки TruScale. Также компания анонсировала новые сервисы Hybrid AI Factory Services, в том числе консультации по инференсу, которые помогают развёртывать оборудование и управлять им для оптимизации ИИ-производительности.
02.12.2025 [18:20], Сергей Карасёв
Российская ИИ-система Delta Sprut XL поддерживает до 25 GPU
delta computers
gpu
granite rapids
h200
hardware
intel
nvidia
ocp
rtx
sierra forest
xeon
ии
сделано в россии
сервер
Российская компания Delta Computers представила OCP-систему Delta Sprut XL, предназначенную для ресурсоёмких нагрузок, таких как обучение ИИ-моделей, инференс, научное моделирование и задачи HPC. В основу новинки положена аппаратная платформа Intel Xeon 6. 
Источник изображений: Delta Computers CPU-секция допускает установку двух процессоров Sierra Forest-SP или Granite Rapids-SP с показателем TDP до 330 и 350 Вт соответственно: в первом случае могут быть задействованы в общей сложности до 288 E-ядер, во втором — до 172 P-ядер. Доступны 32 слота для модулей оперативной памяти DDR5-6400 RDIMM или DDR5-8000 MRDIMM суммарным объёмом до 8 Тбайт. Могут быть установлены четыре SFF-накопителя U.2 толщиной 15 мм с интерфейсом PCIe 5.0 (NVMe) или восемь таких SSD толщиной 7 мм. Кроме того, есть два коннектора M2.2280 (PCIe). Реализованы четыре слота PCIe 5.0 x16 для карт типоразмера HHHL и слот OCP 3.0 (PCIe 5.0). Присутствуют разъёмы USB 3.0 Type-A и miniDP, а также выделенный сетевой порт управления 1GbE.  В системе Delta Sprut XL ускорители на базе GPU устанавливаются в отдельные модули. В общей сложности могут использоваться до 20 карт NVIDIA H200 или до 25 экземпляров NVIDIA RTX Pro 6000 Blackwell Server Edition. Каждый квартет NVIDIA H200 объединён при помощи NVLink. «Delta Computers представляет GPGPU-платформу, способную консолидировать до 20 ускорителей NVIDIA H200 в одном кластере. При этом необходимость использования InfiniBand или 400GbE появляется лишь в случае потребности у заказчика в ещё большем количестве ускорителей — при таком сценарии предусмотрены отдельные слоты расширения для объединения нескольких платформ Delta Sprut XL в единый кластер», — отмечает компания.  Питание обеспечивается посредством централизованного шинопровода OCP на 12 или 48 В. Применено встроенное ПО Delta BMC, предназначенное для мониторинга (сбор телеметрии, отслеживание состояния платформы, её модулей и компонентов) и удалённого администрирования серверного оборудования. Эта прошивка включена в реестр Минцифры РФ и сертифицирована ФСТЭК.
19.09.2025 [11:42], Сергей Карасёв
AAEON представила компактную ИИ-систему Intelli i14 Edge с ускорителем NVIDIA RTXКомпания AAEON анонсировала компьютер небольшого форм-фактора Intelli i14 Edge, рассчитанный на использование в коммерческой и индустриальной сферах. Устройство подходит для решения задач промышленной автоматизации, машинного зрения, предиктивного обслуживания, проектирования робототехники и пр. В основу новинки положена аппаратная платформа Intel Raptor Lake. Применён процессор Core i9-14900T, который объединяет 24 вычислительных ядра (8Р + 16Е; 32 потока). Максимальная тактовая частота — 5,5 ГГц. В состав чипа входит графический блок Intel UHD Graphics 770. Объём оперативной памяти DDR5-4800 может достигать 32 Гбайт в виде двух модулей SO-DIMM с поддержкой ЕСС. Компьютер несёт на борту ускоритель NVIDIA RTX A2000 или RTX A4500 (MXM), благодаря чему обеспечивается возможность локальной обработки ИИ-моделей. Есть два коннектора M.2 2280 M-Key для NVMe SSD и разъём M.2 2230 E-Key для адаптера Wi-Fi / Bluetooth. Реализованы два интерфейса DisplayPort для вывода изображения. 
Источник изображений: AAEON Благодаря наличию сетевых портов 2.5GbE (Intel I226-IT) и 1GbE (Intel I219-LM), а также пяти разъёмов USB 3.2 Gen1 Type-A, как отмечает AAEON, обеспечивается бесшовная интеграция с камерами, лидарами, инерциальными измерительными блоками (IMU) и промышленными концентраторами ввода-вывода. Предусмотрен также один порт USB 3.2 Gen2 Type-C.  Устройство имеет размеры 205 × 190 × 70 мм и весит около 3 кг. Диапазон рабочих температур — от 0 до +50 °C. Решение протестировано на устойчивость к вибрации в соответствии со стандартом IEC EN60068-2-64, что делает его пригодным для использования в автомобильных системах помощи водителю при движении (ADAS), оборонных комплексах, робототехнических платформах и других системах, которые эксплуатируются в неблагоприятных условиях. Говорится о совместимости с Windows 10 IoT.
02.09.2025 [12:15], Сергей Карасёв
MSI выпустила серверы на платформе NVIDIA MGX с ускорителями RTX Pro 6000 Blackwell Server EditionКомпания MSI анонсировала серверы CG480-S5063 и CG290-S3063 на модульной архитектуре NVIDIA MGX. Новинки, ориентированные на задачи ИИ, оснащаются ускорителями NVIDIA RTX Pro 6000 Blackwell Server Edition с 96 Гбайт GDDR7. Модель CG480-S5063 выполнена в форм-факторе 4U. Допускается установка двух процессоров Intel Xeon 6700E (Sierra Forest-SP) или Xeon 6500P/6700P (Granite Rapids-SP) с показателем TDP до 350 Вт. Доступны 32 слота для модулей оперативной памяти DDR5 (RDIMM 6400/5200 или MRDIMM 8000). Во фронтальной части могут быть размещены 20 накопителей E1.S с интерфейсом PCIe 5.0 x4 (NVMe). Кроме того, есть два внутренних коннектора М.2 2280/22110 (PCIe 5.0 x2; NVMe). Система предлагает восемь слотов PCIe 5.0 x16 для карт FHFL двойной ширины и пять слотов PCIe 5.0 x16 для карт FHFL одинарной ширины. Таким образом, могут быть задействованы до восьми ИИ-ускорителей NVIDIA RTX Pro 6000 Blackwell Server Edition. В оснащение входят контроллер ASPEED AST2600, два сетевых порта 10GbE на основе Intel X710-AT2, выделенный сетевой порт управления 1GbE, интерфейсы USB 3.0/2.0 Type-A и Mini-DisplayPort. Питание обеспечивают четыре блока мощностью 3200 Вт с сертификатом 80 PLUS Titanium. Задействовано воздушное охлаждение с вентиляторами, допускающими горячую замену. Диапазон рабочих температур — от 0 до +35 °C. 
Источник изображений: MSI В свою очередь, сервер CG290-S3063 типоразмера 2U рассчитан на один процессор Xeon 6500P/6700P с TDP до 350 Вт. Предусмотрены 16 слотов для модулей DDR5 (RDIMM 6400/5200 или MRDIMM 8000). В тыльной части расположены отсеки для четырёх SFF-накопителей U.2 с интерфейсом PCIe 5.0 x4 (NVMe). Внутри есть два коннектора М.2 2280/22110 для SSD (PCIe 5.0 x2; NVMe).  Данная система предоставляет четыре слота PCIe 5.0 x16 для карт FHFL двойной ширины и три слота PCIe 5.0 x16 для карт FHFL одинарной ширины. Могут быть использованы до четырёх ускорителей NVIDIA RTX Pro 6000 Blackwell Server Edition. Прочие характеристики включают контроллер ASPEED AST2600, сетевой порт управления 1GbE, интерфейсы USB 3.0/2.0 Type-A и Mini-DisplayPort. Применены четыре блока питания мощностью 2400 Вт с сертификатом 80 PLUS Titanium и воздушное охлаждение.
16.08.2025 [14:45], Сергей Карасёв
Dell представила ИИ-серверы PowerEdge R7725 и R770 на базе NVIDIA RTX Pro 6000 Blackwell Server EditionКомпания Dell анонсировала серверы PowerEdge R7725 и PowerEdge R770 в форм-факторе 2U, построенные на аппаратной платформе AMD и Intel соответственно. Новинки оснащаются ускорителями NVIDIA RTX Pro 6000 Blackwell Server Edition. 
Источник изображений: Dell Модель PowerEdge R7725 может нести на борту два процессора AMD EPYC 9005 (Turin), а также до 6 Тбайт оперативной памяти DDR5-6400 в виде 24 модулей. Доступны до восьми слотов PCIe 5.0 x8 или x16. При этом возможна установка двух GPU-ускорителей. Сервер предлагает различные варианты исполнения подсистемы хранения данных с фронтальным доступом: 12 × LFF SAS/SATA, 8/16/24 × SFF SAS/SATA, 16 × SFF SAS/SATA + 8 × U.2/NVMe или 8/16/32/40 × EDSFF E3.S. Имеется выделенный сетевой порт управления 1GbE, а дополнительно предлагается установка адаптеров с поддержкой 1GbE, 10GbE, 25GbE, 100GbE и 400GbE.  В свою очередь, вариант PowerEdge R770 комплектуется двумя чипами Intel Xeon 6 Granite Rapids с производительными Р-ядрами или Xeon 6 Sierra Forest с энергоэффективными Е-ядрами. Реализованы 32 слота для модулей оперативной памяти DDR5-6400 суммарным объёмом до 8 Тбайт. Предлагается широкий набор опций в плане установки накопителей в лицевой и тыльной частях корпуса, включая 24 × SFF SAS/SATA и 40 × EDSFF E3.S. Система может быть укомплектована четырьмя картами OCP NIC 3.0 (вплоть до 400GbE). Есть слоты PCIe 5.0 x8 и x16.  Серверы поддерживают воздушное и прямое жидкостное охлаждение (DLC). Мощность блоков питания с сертификатом 80 Plus Titanium достигает 3200 Вт. Заявлена совместимость с Canonical Ubuntu Server LTS, Windows Server (Hyper-V), Red Hat Enterprise Linux, SUSE Linux Enterprise Server и VMware ESXi.
14.08.2025 [09:21], Сергей Карасёв
Gigabyte представила MGX-сервер с восемью ускорителями NVIDIA RTX Pro 6000Компания Gigabyte расширила ассортимент серверов для ИИ-задач, анонсировав модель XL44-SX2-AAS1 в форм-факторе 4U с модульной архитектурой NVIDIA MGX. Новинка предназначена для формирования ИИ-фабрик, работы с большими языковыми моделями (LLM) корпоративного уровня, научной визуализации, создания цифрового контента и других ресурсоёмких нагрузок. Сервер допускает установку двух процессоров Intel Xeon 6700/6500 и 32 модулей оперативной памяти DDR5 RDIMM/MRDIMM. В оснащение входят до восьми ускорителей NVIDIA RTX Pro 6000 Blackwell Server Edition, которые ориентированы на требовательные приложения ИИ. Эти карты несут на борту 96 Гбайт памяти GDDR7 (ECC) с пропускной способностью до 1,6 Тбайт/с. Во фронтальной части располагаются отсеки для восьми накопителей SFF с интерфейсом PCIe 5.0 (NVMe). Есть восемь разъёмов PCIe 5.0 x16 для двухслотовых карт FHFL, а также коннектор PCIe 5.0 x16 для однослотового DPU NVIDIA BlueField-3. В конструкции задействованы коммутационная плата NVIDIA MGX PCIe 6.0 на базе ASIC ConnectX-8 и контроллер Intel X710-AT2, на базе которого реализованы два сетевых порта 10GbE. 
Источник изображения: Gigabyte За питание отвечают четыре блока с сертификатом 80 PLUS Titanium мощностью 3200 Вт каждый с резервированием по схеме 3+1, благодаря чему обеспечиваются стабильность и надёжность во время непрерывной круглосуточной эксплуатации. На лицевую панель выведены гнёзда RJ45 для сетевых кабелей и порты USB Type-A. Прочие технические характеристики сервера Gigabyte XL44-SX2-AAS1 пока не раскрываются. |
|

