Материалы по тегу: hgx
|
14.07.2026 [13:09], Сергей Карасёв
Gigabyte представила ИИ-сервер G4L4-SD3-LAX7 на базе NVIDIA HGX B300 с СЖОКомпания Gigabyte анонсировала сервер G4L4-SD3-LAX7, построенный на аппаратной платформе NVIDIA HGX B300. Устройство, рассчитанное на ресурсоёмкие нагрузки ИИ, оборудовано системой прямого жидкостного охлаждения (DLC) с функцией обнаружения протечек. Машина выполнена в форм-факторе 4U: допускается установка двух процессоров Intel Xeon 6700P/6500P (Granite Rapids) с показателем TDP до 350 Вт. Предусмотрены 32 слота для модулей оперативной памяти DDR5 RDIMM-6400 или MRDIMM-8000. Во фронтальной части расположены восемь отсеков для SFF-накопителей с интерфейсом PCIe 5.0 (NVMe). Кроме того, есть два внутренних коннектора для SSD типоразмера M.2 2280/22110 с интерфейсом PCIe 5.0 x4 и PCIe 5.0 x2. Система оснащена восемью SXM-ускорителями Blackwell Ultra. Доступны четыре слота для карт PCIe 5.0 x16 стандарта FHHL. Реализованы восемь портов 800 Гбит/с OSFP XDR InfiniBand на базе NVIDIA ConnectX-8 SuperNIC. Говорится о совместимости с DPU NVIDIA BlueField-3. Питание обеспечивают десять блоков мощностью 3000 Вт с резервированием и сертификатом 80 PLUS Titanium. 
Источник изображения: Gigabyte На фронтальную панель выведены два сетевых порта 10GbE на основе Intel X710-AT2, а также выделенный сетевой порт управления 1GbE. Сзади находится дополнительный порт управления 1GbE. Упомянуты контроллер ASPEED AST2600 с разъёмом D-Sub и два порта USB 3.0 Type-A. Диапазон рабочих температур простирается от +10 до +35 °C. Габариты составляют 447 × 175,5 × 901 мм.
13.07.2026 [12:08], Сергей Карасёв
ASRock Rack представила ИИ-сервер 2U16X-GNR2/DLC Rubin с СЖОКомпания ASRock Rack анонсировала высокопроизводительный сервер 2U16X-GNR2/DLC Rubin, предназначенный для ресурсоёмких нагрузок ИИ. Устройство выполнено в форм-факторе 2U на аппаратной платформе NVIDIA HGX Rubin NVL8. Новинка получила двухсокетную конфигурацию. Допускается установка двух процессоров Intel Xeon 6700P, 6500P (Granite Rapids) или 6700E (Sierra Forest) в исполнении LGA 4710. Задействованы восемь ИИ-ускорителей NVIDIA Rubin, связанных через интерконнект NVLink. Предусмотрены 32 слота для модулей оперативной памяти DDR5 RDIMM-6400 или DDR5 MRDIMM-8000 суммарным объёмом до 4 Тбайт. Во фронтальной части расположены восемь отсеков для NVMe-накопителей E1.S (PCIe 6.0 x4). Кроме того, есть два внутренних коннектора для SSD типоразмера M.2 2280 с интерфейсом PCIe 5.0 x4. В оснащение входят BMC-контроллер ASPEED AST2600, сетевой адаптер Intel I210 1GbE с портом RJ45 и выделенный сетевой порт управления на базе Realtek RTL8211F. Реализованы восемь портов OSFP 800 Гбит/с через NVIDIA ConnectX-9 SuperNIC. Плюс к этому доступен слот FHHL PCIe 6.0 x16 для DPU NVIDIA BlueField-4. 
Источник изображения: ASRock Rack Сервер оборудован полностью жидкостной системой охлаждения, которая охватывает в том числе накопители E1.S и DPU. Габариты составляют 800 × 448 × 87 мм. Имеются порты USB 3.0 Type-A, Micro-USB и Mini-DisplayPort. Диапазон рабочих температур простирается от +10 до +35 °C. Упомянут аппаратный криптографический модуль TPM 2.0, расположенный на отдельной стандартизированной плате управления сервером DC-SCM.
28.05.2026 [23:48], Владимир Мироненко
Yandex B2B Tech, Selectel и MetaMentor представили ИИ ПАК по подпискеYandex B2B Tech совместно с Selectel и MetaMentor представила AIaaS (AI-as-a-Service) ПАК для on-premise развёртывания по подписке платформы Yandex AI Studio. Рещение позволит компаниям быстро развернуть ИИ-проект с размещением инфраструктуры в собственном контуре и соблюдением регуляторных требований и внутренних политик. ПАК включает три компонента: ИИ-платформу Yandex AI Studio, GPU-серверы Selectel и услуги MetaMentor по внедрению, настройке и интеграции решения в ИТ-контур компании. Как сообщается в пресс-релизе, в новом формате доступны все основные возможности Yandex AI Studio: генеративные модели, инструменты для работы с данными и файлами, файловый поиск и визуальные интерфейсы для создания ИИ-агентов даже без навыков программирования. Также в решение могут быть включены ИИ-инструменты для офисной работы. Selectel предоставляет в аренду GPU-инфраструктуру с размещением на площадке заказчика и обязательством по обслуживанию и обновлению оборудования. В частности, доступны платформы NVIDIA HGX A100/B200/B300, RTX PRO 6000 и др., а также ИИ-сервер собственной разработки Selectel. На подготовку и доставку оборудования клиенту уйдёт до пяти рабочих дней. 
Источник изображения: Selectel На MetaMentor лежит задача помочь подготовить решение к запуску, включая интеграцию платформы с корпоративными системами заказчика и помощь в создании ИИ-агентов под его задачи. В дальнейшем MetaMentor продолжит системно сопровождать проект, оказывая техническую и клиентскую поддержку по всем вопросам, а также обновляя ПО. Yandex Cloud, Selectel и MetaMentor выводят новый продукт на рынок on-premises платформенного ПО на базе ИИ, который, по данным совместного исследования Yandex Cloud и AHD, составил в России в 2025 году около 16 млрд руб. Значительная часть компаний уже развёртывает ИИ в локальном контуре, поэтому новое решение может вызвать интерес среди заказчиков.
30.04.2026 [17:07], Сергей Карасёв
Giga Computing представила 4OU-сервер TO46-SD3 на базе NVIDIA HGX B300 с СЖОGiga Computing, подразделение Gigabyte Group, анонсировала OCP-сервер TO46-SD3-LA07 для ресурсоёмких ИИ-нагрузок. Новинка выполнена на платформе NVIDIA HGX B300 в форм-факторе 4OU и наделена прямым жидкостным охлаждением. Говорится, что применённая СЖО охватывает и секцию GPU, и зону CPU. Предусмотрена функция обнаружения утечек. 
Источник изображений: Giga Computing Система несёт на борту два процессора Intel Xeon 6 6500/6700 поколения Granite Rapids-SP. Доступны 32 слота для модулей DDR5 RDIMM/MRDIMM. Во фронтальной части расположены восемь отсеков для SFF-накопителей (NVMe) с возможностью горячей замены. Кроме того, могут быть установлены два SSD типоразмера M.2 с интерфейсом PCIe 5.0 x4 и PCIe 5.0 x2.  Сервер оборудован четырьмя слотами PCIe 5.0 x16 для карт расширения формата FHHL. Говорится о совместимости с DPU NVIDIA BlueField-3. Могут быть реализованы восемь OSFP-портов InfiniBand XDR с пропускной способностью до 800 Гбит/с или сдвоенные 400GbE-порты на базе NVIDIA ConnectX-8 SuperNIC. Кроме того, есть два сетевых порта 10GbE на основе контроллера Intel X710-AT2. Интерфейсные разъёмы, включая гнёзда RJ45 для сетевых кабелей и порты USB Type-A, сосредоточены во фронтальной части. Giga Computing отмечает, что сервер TO46-SD3-LA07 подходит для решения таких задач, как обучение крупных ИИ-моделей и инференс. Система построена с применением открытых стандартов и модульных принципов, обеспечивая масштабируемость и эффективность в рамках корпоративных инфраструктур и дата-центров гиперскейлеров.
30.03.2026 [11:59], Сергей Карасёв
ИИ-сервер Gigabyte G894-AD3 использует платформу NVIDIA HGX B300 и чипы Intel Xeon 6900Компания Gigabyte пополнила ассортимент серверов мощной моделью G894-AD3-AAX7, предназначенной для решения ресурсоёмких задач в сфере ИИ. Система выполнена на платформе NVIDIA HGX B300 с восемью SXM-ускорителями Blackwell Ultra. Допускается установка двух процессоров Intel Xeon 6900P поколения Granite Rapids-SP в исполнении LGA 7529 (Socket BR) с показателем TDP до 500 Вт. Доступны 24 слота для модулей DDR5-6400/8800 RDIMM/MRDIMM, два внутренних коннектора M.2 2280/22110 для SSD с интерфейсом PCIe 5.0 x4 и PCIe 5.0 x2, а также восемь отсеков для SFF-накопителей (NVMe) с доступом через фронтальную панель (возможна горячая замена). Реализованы четыре слота PCIe 5.0 x16 для карт расширения FHHL. В оснащение входят контроллер ASPEED AST2600, два сетевых порта 10GbE на основе Intel X710-AT2, выделенный сетевой порт управления 1GbE, а также восемь портов 800G OSFP InfiniBand XDR (NVIDIA ConnectX-8 SuperNIC). Подсистема питания включает 12 блоков мощностью 3000 Вт с сертификатом 80 PLUS Titanium. Реализовано воздушное охлаждение с 27 вентиляторами в следующей конфигурации: 6 × 60 мм в области материнской платы, 4 × 40 мм в зоне портов OSFP, 2 × 80 мм в секции PCIe-слотов и 15 × 80 мм в лотке GPU. 
Источник изображения: Gigabyte Сервер выполнен в форм-факторе 8U с габаритами 447 × 351 × 923 мм, а масса составляет 91,6 кг. Диапазон рабочих температур — от +10 до +30 °C. Среди прочего упомянуты два порта USB 3.0 Type-A (5 Гбит/с), аналоговый интерфейс D-Sub, а также три гнезда RJ45 для сетевых кабелей. Опционально может быть добавлен модуль TPM 2.0 для обеспечения безопасности.
23.03.2026 [09:31], Сергей Карасёв
HPE представила узлы на базе NVIDIA Vera для платформы Cray Supercomputing GX5000Компания HPE анонсировала новые решения семейства NVIDIA AI Computing by HPE, ориентированные на крупномасштабные ИИ-платформы и суперкомпьютерные системы. О намерении использовать такие инфраструктурные продукты в числе прочих сообщили Аргоннская национальная лаборатория (ANL) Министерства энергетики США (DOE), Hudson River Trading (HRT), Корейский институт научно-технической информации (KISTI) и Центр высокопроизводительных вычислений HLRS при Штутгартском университете в Германии. В частности, представлены новые узлы для суперкомпьютерной платформы HPE Cray Supercomputing GX5000 — blade-серверы HPE Cray Supercomputing GX240. Эти устройства могут нести на борту до 16 процессоров NVIDIA Vera (88C/176T). В одной стойке могут быть размещены до 40 узлов, что в сумме даёт 640 чипов Vera и 56 320 ядер Olympus. Реализовано жидкостное охлаждение. Система предназначена для решения наиболее ресурсоёмких вычислительных задач в области ИИ. Новые серверы появятся на рынке в следующем году. Для платформы HPE Cray Supercomputing GX5000 также будут доступны коммутаторы NVIDIA Quantum-X800 InfiniBand, предоставляющие 144 порта с пропускной способностью до 800 Гбит/с. В этих устройствах реализованы развитые функции снижения энергопотребления. Кроме того, HPE готовит OCP-серверы высокой плотности Compute XD700 для обучения LLM и инференса. В основу данной системы положена платформа NVIDIA HGX Rubin NVL8, а одна стойка может насчитывать до 128 ускорителей Rubin. Данное решение появится в начале 2027-го. 
Источник изображений: HPE Помимо этого, анонсирована стоечная система нового поколения NVIDIA Vera Rubin NVL72 by HPE — это флагманская ИИ-платформа, разработанная для моделей с более чем 1 трлн параметров. Конфигурация включает 36 процессоров Vera, 72 чипа Rubin, интерконнект NVIDIA NVLink шестого поколения, сетевые адаптеры NVIDIA ConnectX-9 SuperNIC и DPU NVIDIA BlueField-4. Система поступит в продажу в декабре 2026 года. 
12.01.2026 [14:41], Сергей Карасёв
ASRock Rack показала ИИ-сервер на базе NVIDIA HGX B300 с СЖО ZutaCore HyperCoolКомпания ASRock Rack на выставке CES 2026 продемонстрировала ИИ-сервер 4U16X-GNR2/ZC, первая информация о котором была раскрыта в октябре прошлого года. Новинка создана в партнёрстве с разработчиком систем жидкостного охлаждения ZutaCore. Устройство выполнено в форм-факторе 4U. Возможна установка двух процессоров Intel Xeon 6700E (Sierra Forest-SP) или Xeon 6500P/6700P (Granite Rapids-SP). Доступны 32 слота для модулей оперативной памяти DDR5, три разъёма PCIe 5.0 x16 для карт FHHL и два сетевых порта 1GbE на базе контроллера Intel I350-AM2. Задействована аппаратная платформа NVIDIA HGX B300. Для отвода тепла используется система прямого жидкостного охлаждения ZutaCore HyperCool. Это двухфазное решение основано на применении специальной диэлектрической жидкости, которая не вызывает коррозии. Утверждается, что конструкция HyperCool безопасна для IT-оборудования и гарантирует сохранение работоспособности даже в случае утечки. СЖО поставляется в полностью собранном виде, что сокращает время монтажа в стойку.  Сервер 4U16X-GNR2/ZC оборудован 12 фронтальными отсеками для SFF-накопителей с интерфейсом PCIe 5.0 x4 (NVMe); допускается горячая замена. Кроме того, есть внутренний разъём для одного SSD типоразмера М.2 (PCIe 5.0 x2). За питание отвечают десять блоков мощностью 3000 Вт с сертификатом 80 Plus Titanium. Габариты машины составляют 900 × 448 × 175 мм. Отмечается, что в стандартной стойке 42U могут быть размещены до восьми подобных серверов, что обеспечивает высокую плотность вычислительной мощности для наиболее ресурсоёмких нагрузок ИИ.
06.01.2026 [14:28], Владимир Мироненко
NVIDIA объявила о запуске платформы Vera Rubin NVL72NVIDIA объявила о запуске платформы следующего поколения Rubin, которая приходит на смену Blackwell Ultra. Компания отметила, что платформа Rubin объединяет сразу пять инноваций, включая новейшие поколения интерконнекта NVIDIA NVLink, Transformer Engine, Confidential Computing и RAS Engine, а также процессор NVIDIA Vera. Примечательно, что NVIDIA снова решила вернуться к именованию на основе количества суперчипов (NVL72), а не ускорителей (NVL144), как обещала в прошлом году. Созданная с использованием экстремального совместного проектирования на аппаратном и программном уровнях, NVIDIA Vera Rubin обеспечивает десятикратное снижение стоимости токенов для инференса и четырёхкратное сокращение количества ускорителей для обучения моделей MoE по сравнению с платформой NVIDIA Blackwell. Коммутационные системы NVIDIA Spectrum-X Ethernet Photonics обеспечивают пятикратное повышение энергоэффективности и времени безотказной работы. 
Источник изображений: NVIDIA Платформа Rubin построена на шести чипах — Arm-процессоре Vera, ускорителе Rubin, коммутаторе NVLink 6, адаптере ConnectX-9 SuperNIC, DPU BlueField-4 и Ethernet-коммутаторе NVIDIA Spectrum-6. Ускорители Rubin поначалу будут доступны в двух форматах. В первом случае — в составе стоечной платформы DGX Vera Rubin NVL72, которая объединяет 72 ускорителя Rubin и 36 процессоров Vera, NVLink 6, ConnectX-9 SuperNIC и BlueField-4. Также ускорители Rubin будут доступны в составе платформы DGX/HGX Rubin NVL8 на базе x86-процессоров. Обе платформы будут поддерживаться кластерами NVIDIA DGX SuperPod, сообщил ресурс CRN.  Как отметила NVIDIA, разработанный для агентного мышления, процессор NVIDIA Vera является самым энергоэффективным процессором для крупномасштабных ИИ-фабрик. Он оснащён 88 кастомными Armv9.2-ядрами Olympus с 176 потоками с новой технологией пространственной многопоточности NVIDIA, 1,5 Тбайт системной памяти SOCAMM LPDDR5x (1,2 Тбайт/с), возможностями конфиденциальных вычислений и быстрым интерконнектом NVLink-C2C (1,8 Тбайт/с в дуплексе). 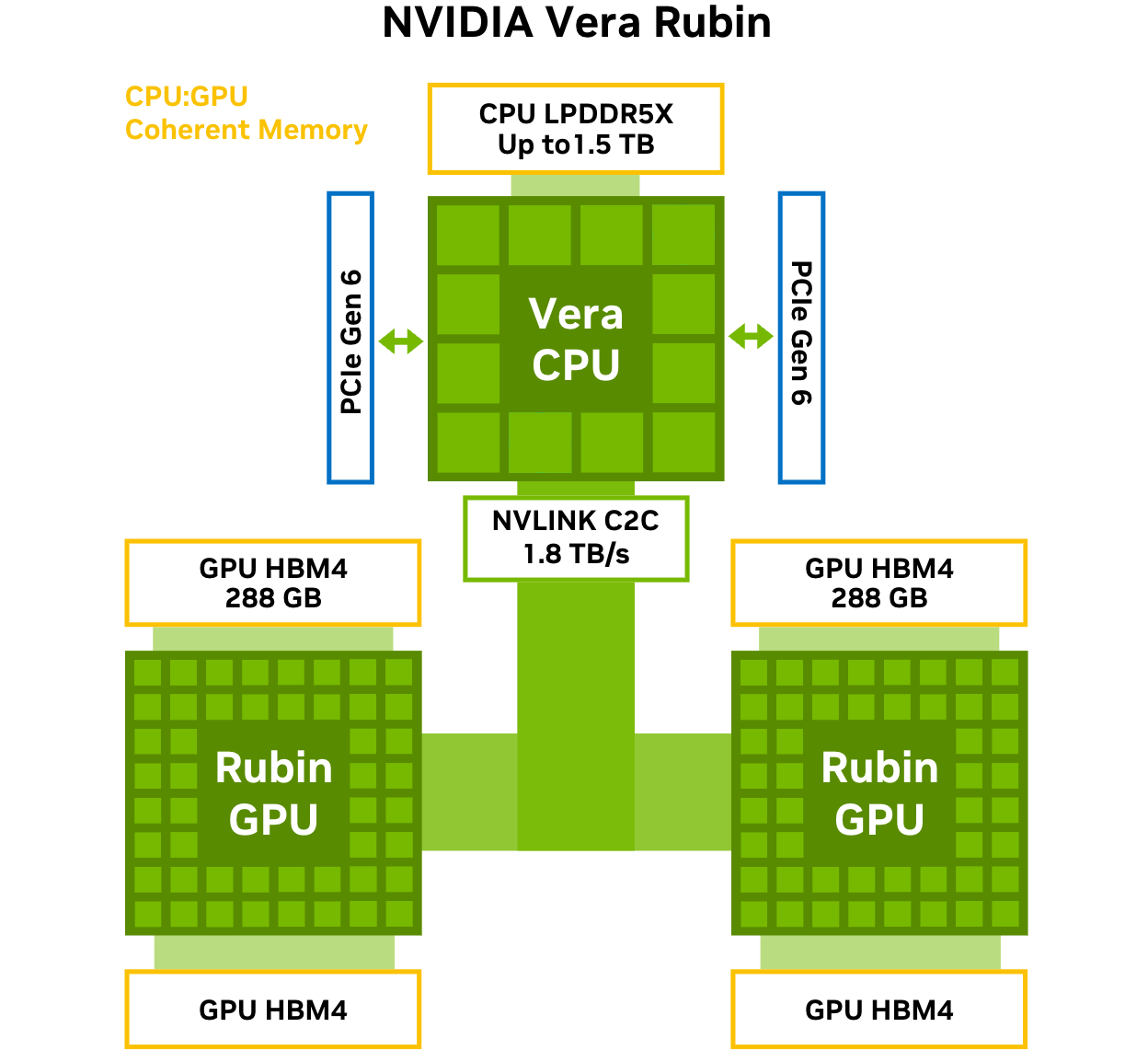 NVIDIA Rubin с аппаратным адаптивным сжатием данных обеспечивает до 50 Пфлопс (NVFP4) для инференса, что в пять раз быстрее, чем Blackwell. Он также обеспечивает до 35 Пфлопс (NVFP4) в режиме, что в 3,5 раза быстрее, чем его предшественник. Пропускная способность 288 Гбайт HBM4 составляет 22 Тбайт/с, что в 2,8 раза быстрее предшественника, а пропускная способность NVLink на один ускоритель вдвое выше — 3,6 Тбайт/с (в дуплексе).  NVIDIA также сообщила, что Vera Rubin NVL72 обладает 54 Тбайт памяти LPDDR5x, что в 2,5 раза больше, чем у Blackwell, и 20,7 Тбайт памяти HBM4, что на 50 % больше, чем у предшественника. Агрегированная пропускная способность HBM4 достигает 1,6 Пбайт/с, что в 2,8 раза больше, а скорость интерконнекта составляет 260 Тбайт/с, что вдвое больше, чем у платформы Blackwell NVL72, и «больше, чем пропускная способность всего интернета». Ожидаемый уровень энергопотребления составит от 190 до 230 кВт на стойку.  Компания отметила, что Vera Rubin NVL72 — первая стоечная платформа, обеспечивающая конфиденциальные вычисления, которая поддерживает безопасность данных на уровне доменов CPU, GPU и NVLink. Коммутатор NVLink 6 с жидкостным охлаждением оснащён 400G-блоками SerDes, обеспечивает пропускную способность 3,6 Тбайт/с на каждый GPU для связи между всеми GPU, общую пропускную способность 28,8 Тбайт/с и 14,4 Тфлопс внутрисетевых вычислений в формате FP8.  Хотя NVIDIA заявила, что Rubin находится в «полномасштабном производстве», аналогичные продукты от партнёров появятся только во II половине этого года. Среди ведущих мировых ИИ-лабораторий, поставщиков облачных услуг, производителей компьютеров и стартапов, которые, как ожидается, внедрят Rubin, компания назвала Amazon Web Services (AWS), Anthropic, Black Forest Labs, Cisco, Cohere, CoreWeave, Cursor, Dell Technologies, Google, Harvey, HPE, Lambda, Lenovo, Meta✴, Microsoft, Mistral AI, Nebius, Nscale, OpenAI, OpenEvidence, Oracle Cloud Infrastructure (OCI), Perplexity, Runway, Supermicro, Thinking Machines Lab и xAI.  ИИ-лаборатории, включая Anthropic, Black Forest, Cohere, Cursor, Harvey, Meta✴, Mistral AI, OpenAI, OpenEvidence, Perplexity, Runway, Thinking Machines Lab и xAI, рассматривают платформу NVIDIA Rubin для обучения более крупных и мощных моделей, а также для обслуживания мультимодальных систем с длинным контекстом с меньшей задержкой и стоимостью по сравнению предыдущими поколениями ускорителей. Партнёры по инфраструктурному ПО и хранению данных AIC, Canonical, Cloudian, DDN, Dell, HPE, Hitachi Vantara, IBM, NetApp, Nutanix, Pure Storage, Supermicro, SUSE, VAST Data и WEKA работают с NVIDIA над разработкой платформ следующего поколения для инфраструктуры Rubin.  В связи с тем, что рабочие нагрузки агентного ИИ генерируют огромные объёмы контекстных данных, NVIDIA также представляла новую платформу хранения контекста инференса NVIDIA Inference Context Memory Storage Platform — новый класс инфраструктуры хранения, разработанной для масштабирования контекста инференса.  Сообщается, что платформа, работающая на базе BlueField-4, обеспечивает эффективное совместное использование и повторное применение данных KV-кеша в рамках всей ИИ-инфраструктуры, повышая скорость отклика и пропускную способность, а также обеспечивая предсказуемое и энергоэффективное масштабирование агентного ИИ. Дион Харрис (Dion Harris), старший директор NVIDIA по высокопроизводительным вычислениям и решениям для ИИ-инфраструктуры, сообщил, что по сравнению с традиционными сетевыми хранилищами для данных контекста инференса, новая платформа обеспечивает до пяти раз больше токенов в секунду, в пять раз лучшую производительность на доллар и в пять раз лучшую энергоэффективность.
09.11.2025 [13:38], Сергей Карасёв
Nebius Аркадия Воложа развернула в Великобритании платформу AI Cloud на базе NVIDIA HGX B300Компания Nebius (бывшая материнская структура «Яндекса» Yandex N.V.) объявила о своём первом развёртывании ИИ-инфраструктуры в Великобритании. Кластер Nebius AI Cloud расположен в кампусе Longcross Park на площадке Ark Data Centres недалеко от Лондона. Как отмечает основатель и генеральный директор Nebius Аркадий Волож, Великобритания является одним из ведущих ИИ-центров в мире. Поэтому для компании создание кластера на территории этой страны имеет большое значение. Кластер состоит из 126 стоек с оборудованием, размещённых в трёх машинных залах. В рамках первой фазы проекта установлены 4 тыс. ускорителей NVIDIA HGX B300 (Blackwell Ultra) в составе серверов пятого поколения (Gen5) собственной разработки Nebius. Вторая фаза предполагает монтаж ещё 3 тыс. ускорителей B300. Общая мощность системы — 16 МВт. По заявлениям Nebius, британский кластер AI Cloud использует передовые энергоэффективные технологии охлаждения, сетевое подключение NVIDIA Quantum-X800 InfiniBand с низкой задержкой и надёжную локальную систему генерации электроэнергии. Говорится о полной интеграции с программной платформой NVIDIA AI Enterprise, предназначенной для разработки и развёртывания ИИ-приложений. 
Источник изображения: Nebius Объединяя нашу облачную инфраструктуру с новейшими технологиями NVIDIA, мы предоставляем организациям по всей Великобритании возможность обучать, развёртывать и масштабировать модели и приложения ИИ быстрее, безопаснее и эффективнее, чем когда-либо», — говорит Волож. Британский кластер использует облачную платформу Nebius AI Cloud 3.0 Aether, которая разработана специально для создания и использования ИИ в таких областях, как здравоохранение, финансы, науки о жизни, корпоративный сектор и государственная сфера. Говорится о поддержке сквозного шифрования и о полном соответствии стандартам защиты данных GDPR и CCPA. Ранее Nebius сообщила о запуске своего первого кластера AI Cloud в Израиле, который расположился на площадке в Модиине (Modiin). У Nebius также имеются дата-центры в Финляндии, Франции и США.
30.10.2025 [12:20], Сергей Карасёв
ASUS представила ИИ-сервер XA NB3I-E12 на базе NVIDIA HGX B300Компания ASUS анонсировала сервер XA NB3I-E12 на аппаратной платформе NVIDIA HGX B300, предназначенный для интенсивных нагрузок ИИ. В качестве потенциальных заказчиков системы названы предприятия, которые работают с большими языковыми моделями (LLM) и НРС-приложениями: это могут быть научно-исследовательские структуры и финансовые организации, компании автомобильного сектора и пр. Сервер выполнен в форм-факторе 9U. Возможна установка двух процессоров Intel Xeon 6700P поколения Granite Rapids с показателем TDP до 350 Вт. Доступны 32 слота для модулей оперативной памяти DDR5-6400 RDIMM / 3DS RDIMM. Во фронтальной части расположены 10 посадочных мест на SFF-накопителей (NVMe). Предусмотрены четыре слота расширения PCIe 5.0 х16 и один слот PCIe 5.0 х8. Система имеет архитектуру 8-GPU (NVIDIA HGX B300 288GB 8-GPU). Задействованы сетевые адаптеры NVIDIA ConnectX-8 и DPU NVIDIA BlueField-3. Реализованы два сетевых порта 10GbE с разъёмами RJ45 на основе контроллера Intel X710-AT2 и выделенный сетевой порт управления (RJ45). Питание обеспечивают 10 блоков мощностью 3200 Вт с сертификатом 80 PLUS Titanium. Применяется воздушное охлаждение; диапазон рабочих температур — от +10 до +35 °C. 
Источник изображения: ASUS ASUS отмечает, что сервер имеет модульную конструкцию, благодаря чему минимизируется использование кабелей, упрощается обслуживание и повышается ремонтопригодность. Габариты устройства составляют 945 × 447 × 394,5 мм, масса — примерно 120 кг без установленных накопителей. |
|

