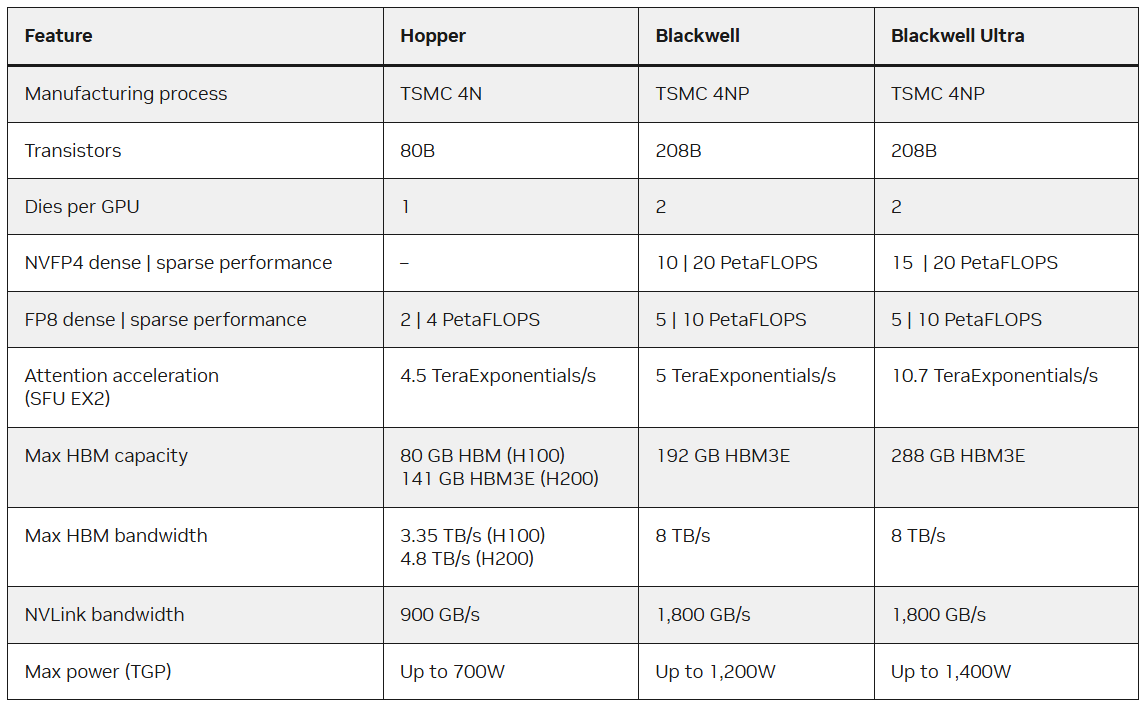
NVIDIA поделилась подробностями об ускорителе Blackwell Ultra, обновлённом и улучшенном варианте NVIDIA Blackwell, представленном более года назад. Blackwell Ultra по-прежнему состоит из двух кристаллов с максимальными размерами в пределах фотолитографической маски, соединённых с помощью интерфейса NVIDIA High-Bandwidth Interface (NV-HBI) с пропускной способностью 10 Тбайт/с. Чип имеет 208 млрд транзисторов, изготовленных по кастомному техпроцессу TSMC 4NP — в 2,6 раза больше, чем NVIDIA Hopper — и с точки зрения ПО выглядит как один ускоритель.
Чип имеет 160 потоковых мультипроцессоров (SM), включающих 640 тензорных ядер (Tensor Core) пятого поколения общей с производительностью 15 Пфлопс в вычислениях в фирменном 4-бит формате NVFP4 (без разреженности) и общий L2-кеш с полностью когерентным доступом к памяти. SM объединены в восемь кластеров GPC (Graphics Processing Clusters).

Источник изображений: NVIDIA
Каждый SM представляет собой автономный вычислительный блок, содержащий:
- 128 ядер CUDA для операций FP32/INT32/FP16/BF16 и других точных вычислений.
- 4 тензорных ядра пятого поколения с движком NVIDIA Transformer Engine второго поколения, оптимизированным для вычислений FP8, FP6 и NVFP4.
- 256 Кбайт памяти Tensor Memory (TMEM) для WARP-синхронного хранения промежуточных результатов, что обеспечивает более эффективное повторное использование данных и сокращение трафика внекристальной памяти.
- Специальные функциональные блоки (SFU) для трансцендентной математики и специальных операций, используемых в вычислительных ядрах (kernel).

Когда NVIDIA впервые представила тензорные ядра в архитектуре Volta, они фундаментально изменили возможности ускорителей для глубокого обучения, расширяя с каждым новым поколением свои возможности, точность и параллелизм, говорит NVIDIA. Blackwell (Ultra) выводят эту технологию на новый уровень благодаря тензорным ядрам пятого поколения и Transformer Engine второго поколения, обеспечивая более высокую пропускную способность и меньшую задержку как для обычных, так и для разреженных ИИ-вычислений.

Новые тензорные ядра тесно интегрированы с 256 Кбайт тензорной памяти (TMEM), оптимизированной для хранения данных близко к вычислительным блокам. Они также поддерживают двухпотоковые блочные MMA-операции, где парные SM взаимодействуют в одной операции MMA, деля операнды и сокращая избыточный трафик памяти. Результатом является более высокая стабильная пропускная способность, более высокая эффективность использования памяти, более быстрое обучение и более эффективный инференс с малыми пакетами данных и высокой интерактивностью.
Не менее важным для производительности стало внедрение NVIDIA NVFP4, нового 4-бит формата с плавающей запятой, который сочетает микроблочное масштабирование FP8 (E4M3), применяемое к блокам по 16 значений, и масштабирование FP32 на тензорном уровне, что обеспечивает аппаратное ускорение квантования с заметно более низким уровнем ошибок, чем стандартный FP4. При этом точность практически такая же как FP8 (часто с разницей менее ~1 %), но потребление памяти снижается в 1,8 раза (и до ~3,5 раза по сравнению с FP16). При этом от развития FP64 компания практически отказалась.
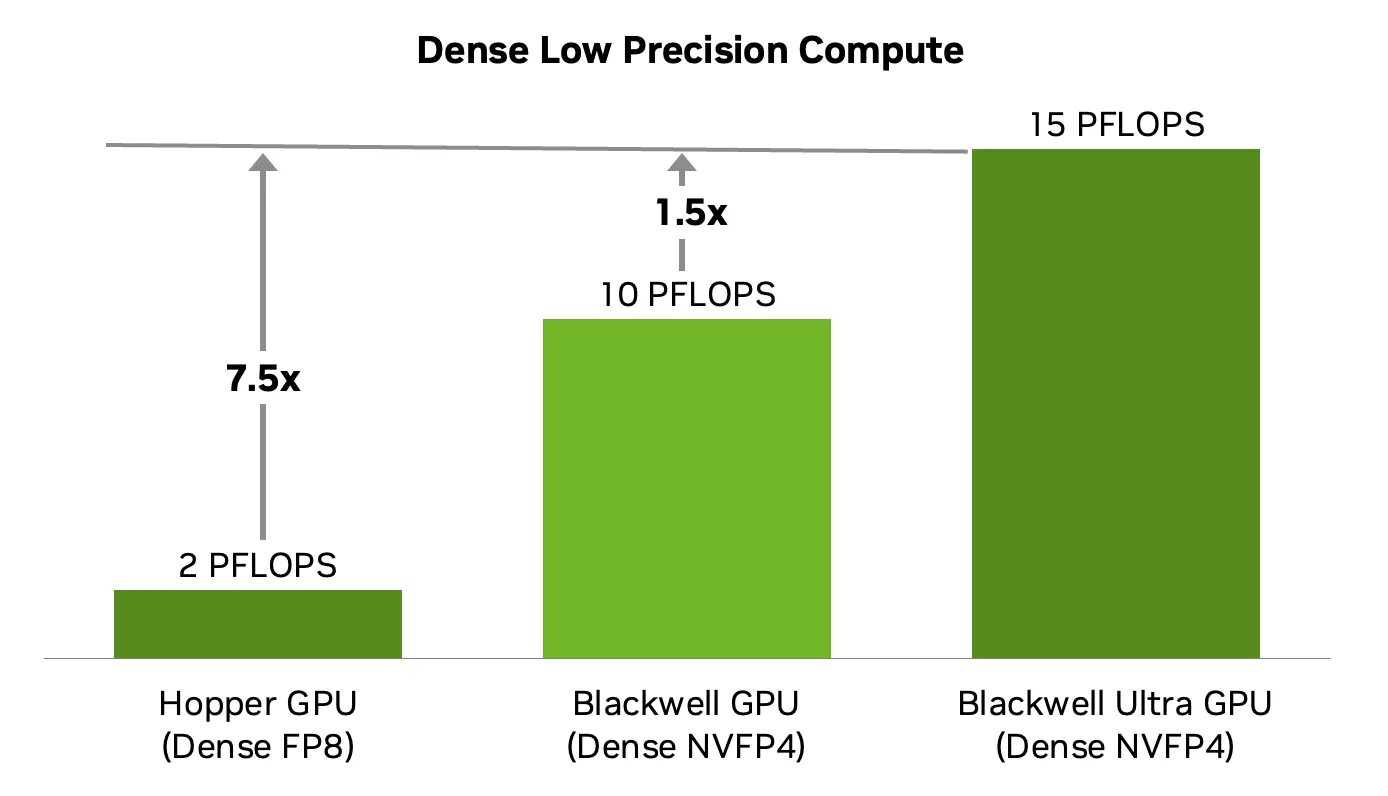
NVFP4 обеспечивает оптимальный баланс точности, эффективности и производительности для ИИ-инференса, заявляет NVIDIA. «Плотные» NVFP4-вычисления в Blackwell Ultra обеспечивают существенный прирост производительности по сравнению с оригинальным ускорителем Blackwell — с 10 Пфлопс до 15 Пфлопс в NVFP4, то есть в 1,5 раза, или в 7,5 раза по сравнению с NVIDIA Hopper. Это ускорение напрямую влияет на масштаб инференса, обеспечивая большее количество параллельных экземпляров моделей, более быстрое время отклика и снижение затрат на каждый сгенерированный токен.
В Blackwell Ultra пропускная способность SFU для ключевых инструкций, используемых в слое внимания (attention layer), удвоена, что обеспечивает до двух раз более быстрые вычисления по сравнению с оригинальными Blackwell. Это улучшение ускоряет внимание как на коротких, так и на длинных последовательностях, но особенно эффективно для рассуждающих моделей с большими контекстными окнами, где softmax-этап, когда определяется наиболее вероятный токен для дальнейшего решения задачи, может стать узким местом по задержке.
Таким образом, ускорение работы механизма внимания в Blackwell Ultra уменьшает время до выдачи первого токена в интерактивных приложениях, cнижает вычислительные затраты за счёт сокращения общего количества циклов обработки на запрос и повышает энергоэффективность — больше последовательностей на Вт. В сочетании с NVFP4 новые ускорители позволяют добиться повышения качества многоступенчатых рассуждений и многомодального инференса.

Blackwell Ultra получили и улучшенную подсистему памяти — 288 Гбайт HBM3e, наполовину больше, чем в Blackwell (192 Гбайт). Всего используются восемь HBM-стеков и 16 × 512-бит контроллеров (общая разрядность 8192 бит). Пропускная способность осталась прежней — 8 Тбайт/с. Столь большой объём быстрой памяти позволяет целиком разместить в ней крупные модели (300+ млрд параметров), реже обращаться к системной памяти или накопителям, увеличить длину контекста и размер KV-кеша.
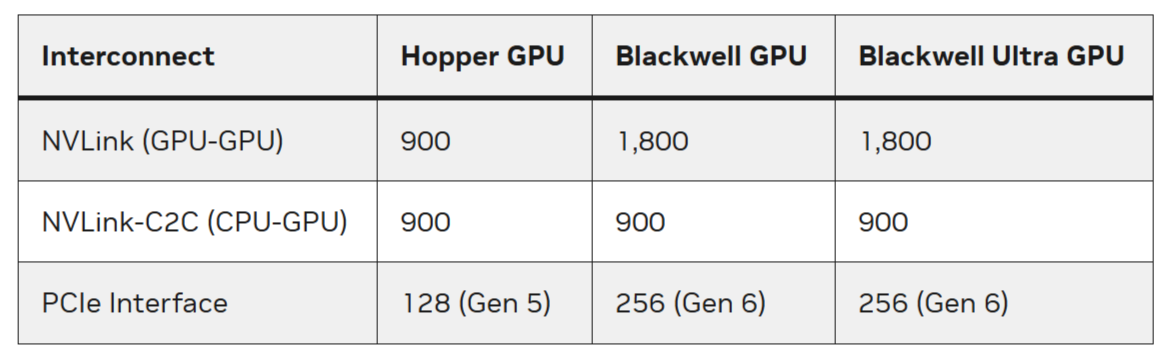
С точки зрения внешних коммуникаций изменений мало. Blackwell Ultra всё так же полагается в первую очередь на интерконнект NVLink 5 с пропускной способностью 1,8 Тбайт/с (по 900 Гбайт/в каждую сторонц) и возможностью объединения в рамках одного домена до 576 GPU в неблокируемой вычислительной фабрике. Хост-интерфейсы представлены PCIe 6.0 x16 (по 128 Гбайт/с в каждом направлении) и NVLink-C2C с когерентностью памяти (900 Гбайт/с).
Blackwell Ultra позволяет создавать более крупные модели, чем Blackwell, и повышать пропускную способность без ущерба для эффективности. Ускоренное выполнение softmax дополнительно повышает скорость реального инференса, увеличивая количество токенов в секунду на пользователя (TPS/пользователь) и одновременно улучшая количество токенов в секунду на МВт (TPS/МВт) в ЦОД.
Архитектурные инновации улучшают экономичность ИИ-инференса и переосмысливают возможности проектирования ИИ-фабрик, обеспечивая больше экземпляров моделей, более быстрые отклики и более высокую производительность на 1 МВт по сравнению с любой предыдущей платформой NVIDIA, говорит компания.

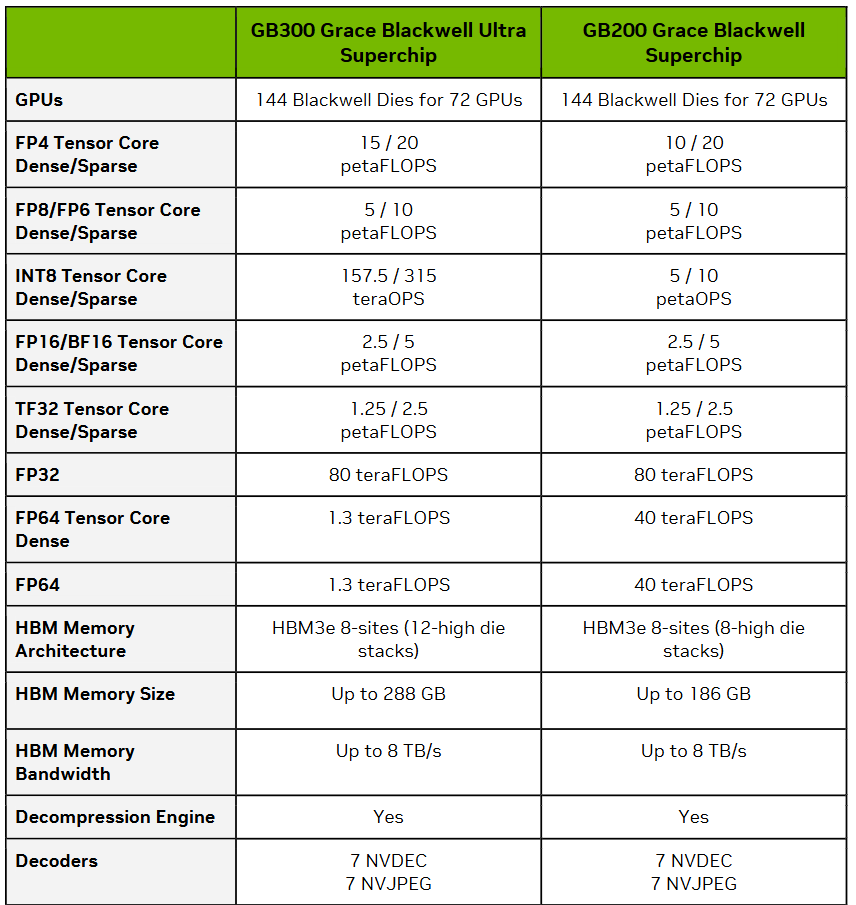
Суперчип NVIDIA Grace Blackwell Ultra объединяет один Arm-процессор Grace с двумя ускорителями Blackwell Ultra через NVLink‑C2C, обеспечивая NVFP4-производительность c разреженностью до 40 Пфлопс (до 30 Пфлопс без разреженности), а также унифицированную память объёмом 1 Тбайт, сочетающую HBM3E и LPDDR5X. Сетевые адаптеры ConnectX-8 SuperNIC обеспечивают высокоскоростное 800G-подключение.
Суперчип NVIDIA Grace Blackwell Ultra является базовым вычислительным компонентом стоечной системы GB300 NVL72, которая объединяет посредством NVLink 5 сразу 36 суперчипов Grace Blackwell (1,1 Эфлопс в FP4 без разреженности). Системы GB300 также выводят управление питанием на новый уровень. Они используют конфигурации с несколькими полками питания для обслуживания и сглаживания синхронных изменений нагрузки ускорителей.
Как отметила компания, NVIDIA Blackwell Ultra закладывает основу для создания ИИ-фабрик, позволяя обучать и развёртывать интеллектуальные системы с беспрецедентной масштабируемостью и эффективностью. Благодаря революционным инновациям в области интеграции двух кристаллов, ускорению NVFP4, огромному объёму памяти и передовой технологии интерконнекта, Blackwell Ultra позволяет создавать ИИ-приложения, которые ранее было невозможно создать с вычислительной точки зрения.
Источник:

