Материалы по тегу: 400gbe
|
22.11.2024 [14:47], Руслан Авдеев
Nokia подписала пятилетнее соглашение по переводу ЦОД Microsoft Azure со 100GbE на 400GbEФинская Nokia расширила соглашение о поставке ЦОД Microsoft Azure маршрутизаторов и коммутаторов. По данным пресс-службы Nokia, соглашение будет действительно в течение пяти лет. Оборудование Nokia, по словам самой компании, повысит масштабируемость и надёжность ЦОД облака Azure по всему миру. Финансовые условия соглашения пока не разглашаются, но, по данным Nokia, благодаря сотрудничеству компаний финский вендор сможет расширить присутствие на рынках более чем на 30 стран и усилить свои позиции в качестве стратегического поставщика для облачной инфраструктуры Microsoft. На уже существующих объектах Azure будет поддерживаться миграция внутренних сетей со 100GbE на 400GbE. Вендор отмечает, что компании, как и ранее, сотрудничают в работе над open source ПО SONiC для маршрутизаторов и коммутаторов ЦОД. В Nokia заявили, что с февраля 2025 года начнёт внедрение платформы 7250 IXR-10e для поддержки многотерабитных сетей в дата-центров Microsoft. Маршрутизатор и коммутаторы, использующие платформу SONiC, будут внедряться на новых площадках ЦОД, что поможет Microsoft справиться с растущим требованиям к объёмам трафика в ближайшие годы. 
Источник изображения: Nokia В Nokia заявляют, что новая фаза сотрудничества повысит масштабируемость и надёжность дата-центров Microsoft Azure по всему миру. По словам представителя Microsoft, в последние шесть лет компания сотрудничала с инженерами Nokia для разработки маршрутизаторов на базе SONiC для содействия экспансии гиперскейлера. В последние месяцы Nokia заявила о наличии амбиций в индустрии ЦОД. В прошлом месяце глава компании Пекка Лундмарк (Pekka Lundmark) заявил, что вендор видит «важную возможность» расширить присутствие на рынке дата-центров. Также в минувшем сентябре Nokia анонсировала запуск платформы автоматизации ЦОД — Event-Driven Automation (EDA).
19.11.2024 [23:28], Алексей Степин
HPE обновила HPC-портфолио: узлы Cray EX, СХД E2000, ИИ-серверы ProLiant XD и 400G-интерконнект Slingshot
400gbe
amd
epyc
gb200
h200
habana
hardware
hpc
hpe
intel
mi300
nvidia
sc24
turin
ии
интерконнект
суперкомпьютер
схд
Компания HPE анонсировала обновление модельного ряда HPC-систем HPE Cray Supercomputing EX, а также представила новые модели серверов из серии Proliant. По словам компании, новые HPC-решения предназначены в первую очередь для научно-исследовательских институтов, работающих над решением ресурсоёмких задач. 
Источник изображений: HPE Обновление касается всех компонентов HPE Cray Supercomputing EX. Открывают список новые процессорные модули HPE Cray Supercomputing EX4252 Gen 2 Compute Blade. В их основе лежит пятое поколение серверных процессоров AMD EPYС Turin, которое на сегодняшний день является самым высокоплотным x86-решениями. Новые модули позволят разместить до 98304 ядер в одном шкафу. Отчасти это также заслуга фирменной системы прямого жидкостного охлаждения. Она охватывает все части суперкомпьютера, включая СХД и сетевые коммутаторы. Начало поставок узлов намечено на весну 2025 года. 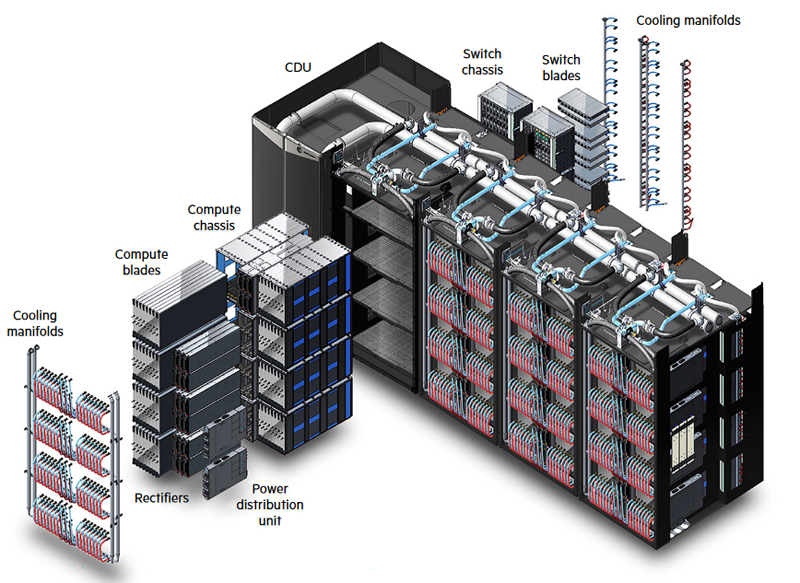 Процессорные «лезвия» дополнены новыми GPU-модулями HPE Cray Supercomputing EX154n Accelerator Blade, позволяющими разместить в одном шкафу до 224 ускорителей NVIDIA Blackwell. Речь идёт о новейших сборках NVIDIA GB200 NVL4 Superchip. Этот компонент появится на рынке позднее — HPE говорит о конце 2025 года. Обновление коснулось и управляющего ПО HPE Cray Supercomputing User Services Software, получившего новые возможности для пользовательской оптимизации вычислений, в том числе путём управления энергопотреблением. Апдейт получит и фирменный интерконнект HPE Slingshot, который «дорастёт» до 400 Гбит/с, т.е. станет вдвое быстрее нынешнего поколения Slingshot. Пропускная способность коммутаторов составит 51,2 Тбит/c. В новом поколении будут реализованы функции автоматического устранения сетевых заторов и адаптивноой маршрутизации с минимальной латентностью. Дебютирует HPE Slingshot interconnect 400 осенью 2024 года.  Ещё одна новинка — СХД HPE Cray Supercomputing Storage Systems E2000, специально разработанная для применения в суперкомпьютерах HPE Cray. В сравнении с предыдущим поколением, новая система должна обеспечить более чем двукратный прирост производительности: с 85 и 65 Гбайт/с до 190 и 140 Гбайт/с при чтении и записи соответственно. В основе новой СХД будет использована ФС Lustre. Появится Supercomputing Storage Systems E2000 уже в начале 2025 года.  Что касается новинок из серии Proliant, то они, в отличие от вышеупомянутых решений HPE Cray, нацелены на рынок обычных ИИ-систем. 5U-сервер HPE ProLiant Compute XD680 с воздушным охлаждением представляет собой решение с оптимальным соотношением производительности к цене, рассчитанное как на обучение ИИ-моделей и их тюнинг, так и на инференс. Он оснащён восемью ускорителями Intel Gaudi3 и двумя процессорами Intel Xeon Emerald Rapids. Новинка поступит на рынок в декабре текущего года.  Более производительный HPE ProLiant Compute XD685 всё так же выполнен в корпусе высотой 5U, но рассчитан на жидкостное охлаждение. Он будет оснащаться восемью ускорителями NVIDIA H200 в формате SXM, либо более новыми решениями Blackwell, но последняя конфигурация будет доступна не ранее 2025 года, когда ускорители поступят на рынок. Уже доступен ранее анонсированный вариант с восемью ускорителями AMD Instinict MI325X и процессорами AMD EPYC Turin.
21.10.2024 [13:21], Сергей Карасёв
Xsight Labs представила 400GbE DPU серии E1Компания Xsight Labs анонсировала, как утверждается, самую производительную на рынке программно-определяемую «систему на чипе» (SoC), предназначенную для создания DPU с поддержкой RoCEv2 и UET (Ultra Ethernet Transport). Изделие под названием E1 станет доступно заказчикам для тестирования во II квартале 2025 года. Чип будет предлагаться в модификациях E1-32 и E1-64. Первая содержит 32 ядра Arm Neoverse N2 v9.0-A, имеет 16 Мбайт кеша и использует конфигурацию памяти 2 × DDR5-5200. Показатель TDP равен 65 Вт. У второго варианта количество ядер составляет 64, размер конфигурируемого кеша/буфера — 32 Мбайт. Конфигурация памяти — 4 × DDR5-5200, величина TDP — 90 Вт. В обоих случаях используется полное шифрование памяти на лету (AES-XTS). Новинка использует до восьми блоков SerDes, обеспечивая сетевую пропускную способность до 800 Гбит/с. Возможны следующие конфигурации портов: 2 × 400GbE, 4 × 200GbE и 8 × 100/50/25/10GbE. Заявлена производительность на уровне 200 Mpps и 20 млн подключений в секунду. Также есть пара 1GbE-портов для внешнего управления. Доступны программируемые DMA-движки (до 3 Тбит/с) и разгрузка типовых операций, включая шифрование AES-GCM (для IPSec) и AES-XTS (для СХД) на лету. 
Источник изображения: Xsight Labs Есть восемь двухрежимных контроллеров и 40 (32+8) линий PCIe 5.0, а также поддержка P2P-коммутации PCIe. Упомянуты поддержка до четырёх хостов/устройств, SR-IOV (64K PF/VF), а также программная эмуляция и пространства MMIO. Реализована поддержка интерфейсов I2C/I3C/SMBus, SPI/QSPI, SMI, UART, GPIO, 1588 RTC, JTAG. Говорится о высоком уровне обеспечения безопасности: возможно создание изолированных и защищённых сред, которые аутентифицируют каждого клиента. Поддерживается функция безопасной загрузки UEFI Secure Boot with Arm Trusted Firmware (TF-A). Заявлена возможность работы «из коробки» в Debian, Ubuntu, SONiC и Lightbits Labs LightOS, а также совместимость с Netdev, VirtIO, XNA/XDP и DPDK/SPDK. В частности, возможна эмуляция NVMe-, RDMA- и сетевых устройств. Изделие E1 производится по 5-нм технологии TSMC. Оно, как утверждает Xsight Labs, обеспечивает беспрецедентную энергоэффективность и вычислительные возможности, устанавливая новый стандарт производительности для DPU SoC. Новинка ориентирована на облачные платформы и периферийные дата-центры, поддерживающие интенсивные ИИ-нагрузки. DPU позволяет создавать SDN/SDS-решения, брандмауэры, NVMe-oF СХД, вычислительные хранилища, CDN-платформы, балансировщики и т.п.
11.10.2024 [11:55], Сергей Карасёв
DPU + UEC: AMD представила 400G-адаптеры Pensando Salina и PollaraКомпания AMD анонсировала сетевой сопроцессор (DPU) третьего поколения Pensando Salina 400, а также сетевую карту Pensando Pollara 400, ориентированную на применение в составе ИИ-систем. Образцы изделий станут доступны заказчикам в текущем квартале, тогда как массовые продажи начнутся в I половине 2025 года. Решение Pensando Salina 400, рассчитанное на сетевые кластеры гиперскейлеров, обеспечивает пропускную способность до 400 Гбит/с. Утверждается, что по сравнению с DPU предыдущего поколения производительность увеличилась в два раза. Устройство Pensando Salina 400 выполнено в виде карты PCIe 5.0 с двумя портами 400GbE. Задействованы 16 ядер Arm Neoverse-N1 и 232 ядра P4 MPU. Объём памяти DDR5 достигает 128 Гбайт, её пропускная способность — 102 Гбайт/с. Новинка будет применяться в том числе в интеллектуальных коммутаторах, предназначенных для решения различных задач во внешней зоне: это может быть распределение данных, балансировка нагрузки, обеспечение безопасности, шифрование и пр. 
Источник изображений: AMD В свою очередь, Pensando Pollara 400 представляет собой интеллектуальный сетевой адаптер с одним портом 400 Гбит/с. Изделие выполнено на том же чипе, что и Pensando Salina 400. Компания AMD называет Pensando Pollara 400 первой в мире сетевой картой для приложений ИИ, соответствующей стандартам, которые определяет консорциум Ultra Ethernet (UEC). Примечательно, что первые спецификации консорциум намерен представить не раньше конца текущего года.  Цель UEC — разработка основанной на Ethernet открытой высокопроизводительной архитектуры с полным коммуникационным стеком, отвечающей задачам современных рабочих нагрузок ИИ и НРС. Благодаря программируемой архитектуре P4 адаптер можно настраивать с учётом конкретных требований. В целом, как утверждается, новинка является мощным решением для повышения производительности рабочих нагрузок ИИ и улучшения надёжности сети.
02.07.2024 [23:55], Алексей Степин
15 тыс. ускорителей на один ЦОД: Alibaba Cloud рассказала о сетевой фабрике, используемой для обучения ИИAlibaba Cloud раскрыла ряд сведений технического характера, касающихся сетевой инфраструктуры и устройства своих дата-центров, занятых обработкой ИИ-нагрузок, в частности, обслуживанием LLM. Один из ведущих инженеров компании, Эньнань Чжай (Ennan Zhai), опубликовал доклад «Alibaba HPN: A Data Center Network for Large Language Model Training», который будет представлен на конференции SIGCOMM в августе этого года. В качестве основы для сетевой фабрики Alibaba Cloud выбрала Ethernet, а не, например, InfiniBand. Новая платформа используется при обучении масштабных LLM уже в течение восьми месяцев. Выбор обусловлен открытостью и универсальностью стека технологий Ethernet, что позволяет не привязываться к конкретному вендору. Кроме того, меньше шансы пострадать от очередных санкций США. Отмечается, что традиционный облачный трафик состоит из множества относительно небыстрых потоков (к примеру, менее 10 Гбит/с), тогда как трафик при обучении LLM включает относительно немного потоков, имеющих периодический характер со всплесками скорости до очень высоких значений (400 Гбит/с). При такой картине требуются новые подходы к управлению трафиком, поскольку традиционные алгоритмы балансировки склонны к перегрузке отдельных участков сети. 
Источник здесь и далее: Alibaba Cloud Разработанная Alibaba Cloud альтернатива носит название High Performance Network (HPN). Она учитывает многие аспекты работы именно с LLM. Например, при обучении важна синхронизация работы многих ускорителей, что делает сетевую инфраструктуру уязвимой даже к единичным точкам отказа, особенно на уровне внутристоечных коммутаторов. Alibaba Cloud использует для решения этой проблемы парные коммутаторы, но не в стековой конфигурации, рекомендуемой производителями. 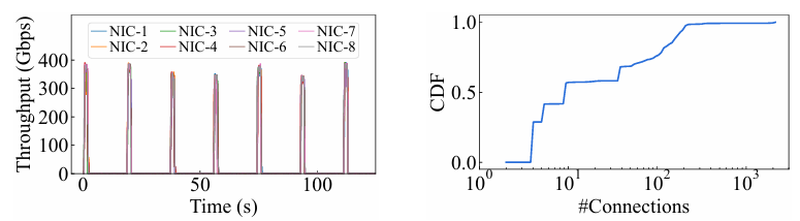
Характер трафика при обучении LLM Каждый хост содержит восемь ИИ-ускорителей и девять сетевых адаптеров. Каждый из NIC имеет по паре портов 200GbE. Девятый адаптер нужен для служебной сети. Между собой внутри хоста ускорители общаются посредством NVLink на скорости 400–900 Гбайт/с, а для общения с внешним миром каждому из них полагается свой 400GbE-канал с поддержкой RDMA. При этом порты сетевых адаптеров подключены к разным коммутаторам из «стоечной пары», что серьёзно уменьшает вероятность отказа. 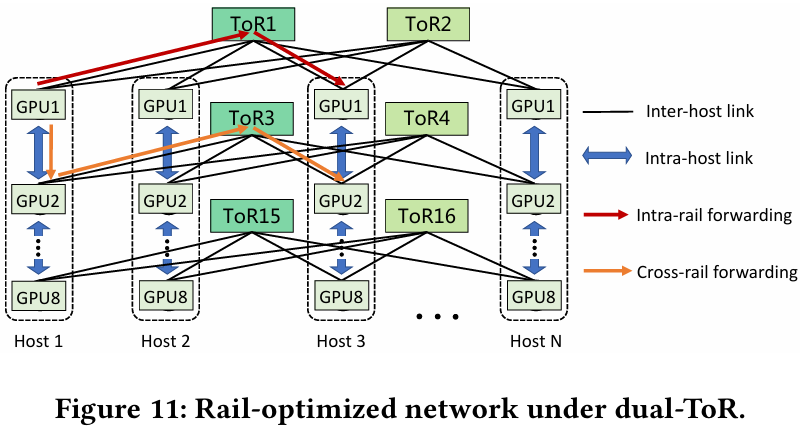 В докладе говорится, что Alibaba Cloud использует современные одночиповые коммутаторы с пропускной способностью 51,2 Тбит/с. Этим условиям отвечают либо устройства на базе Broadcom Tomahawk 5 (март 2023 года), либо Cisco Silicon One G200 (июнь того же года). Судя по использованию выражения «начало 2023 года», речь идёт именно об ASIC Broadcom.  Своё предпочтение именно одночиповых коммутаторов компания объясняет просто: хотя многочиповые решения с большей пропускной способностью существуют, в долгосрочной перспективе они менее надёжны и стабильны в работе. Статистика показывает, что аппаратные проблемы у подобных коммутаторов возникают в 3,77 раза чаще, нежели у одночиповых. 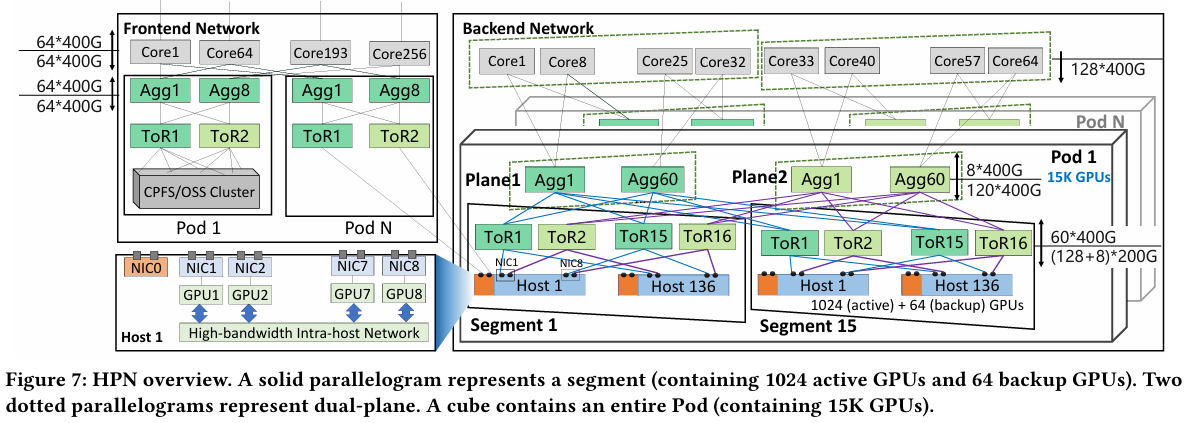 Одночиповые решения класса 51,2 Тбит/с выделяют много тепла, но ни один поставщик оборудования не смог предложить Alibaba Cloud готовые решения, способные удерживать температуру ASIC в пределах 105 °C. Выше этого порога срабатывает автоматическая защита. Поэтому для охлаждения коммутаторов Alibaba Cloud создала собственное решение на базе испарительных камер. 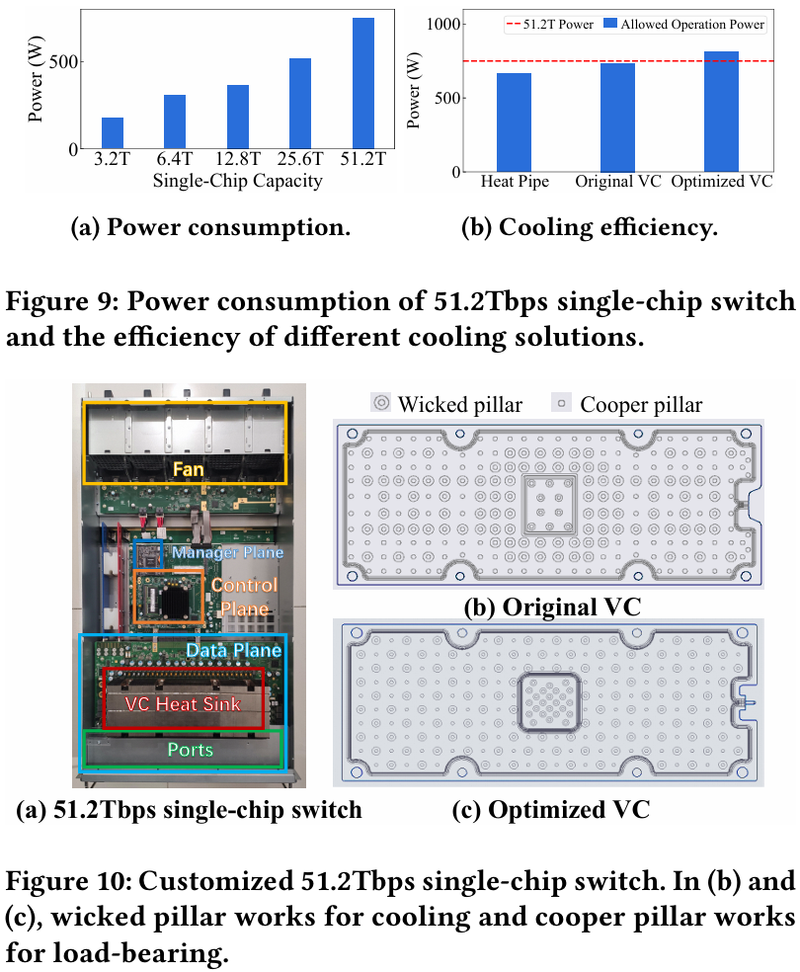 Сетевая фабрика позволяет создавать кластеры, каждый из которых содержит 15360 ускорителей и располагается в отдельном здании ЦОД. Такое высокоплотное размещение позволяет использовать оптические кабели длиной менее 100 м и более дешёвые многомодовые трансиверы, которые дешевле одномодовых примерно на 70 %. Ёмкость такого дата-центра составляет около 18 МВт. 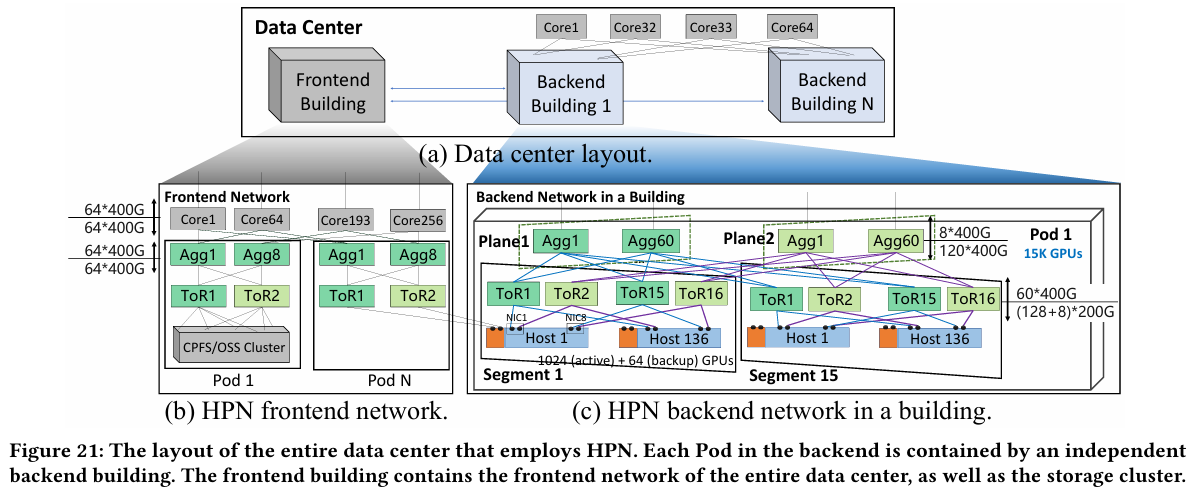 Но есть у HPN и недостаток: использование топологии с двумя внутристоечными коммутаторами и другие особенности архитектуры усложняют кабельную подсистему, поэтому инженеры поначалу столкнулись с ростом ошибок при подключении сетевых интерфейсов. В настоящее время активно используются тесты, позволяющие проверить каждое подключение на соответствие идентификаторов портов и коммутаторов рабочим схемам. Отмечается, что параметры Ethernet-коммутаторов удваиваются каждые два года, поэтому компания уже разрабатывает сетевую архитектуру следующего поколения, рассчитанную на применение будущих ASIC 102,4 Тбит/с. По словам Alibaba Cloud, обучение LLM с сотнями миллиардов параметров потребует огромного распределённого кластера, количество ускорителей в котором исчисляется миллионами. И ему требуется соответствующая сетевая инфраструктура.
22.11.2023 [11:18], Сергей Карасёв
NVIDIA представила сетевой ускоритель SuperNIC для ИИ-нагрузокКомпания NVIDIA анонсировала аппаратное решение SuperNIC — это сетевой ускоритель нового типа, предназначенный для масштабных рабочих нагрузок ИИ в системах на базе Ethernet. Устройство обеспечивает скорость передачи данных до 400 Гбит/с с использованием RDMA (RoCE). Новинка выполнена на основе DPU BlueField-3: это часть сетевой 400G/800G-платформы Spectrum-X, которая предусматривает использование коммутаторов на базе ASIC NVIDIA Spectrum-4 (51,2 Тбит/с). Отмечается, что сообща BlueField-3 SuperNIC и Spectrum-4 составляют основу вычислительной системы, специально разработанной для ускорения ИИ-нагрузок. При этом платформа Spectrum-X обеспечивает высокую эффективность сети, превосходя по производительности традиционные среды Ethernet. По заявления NVIDIA, DPU предоставляет множество расширенных функций, таких как высокая пропускная способность, подключение с небольшой задержкой и пр. 
Источник изображения: NVIDIA Среди ключевых особенностей SuperNIC называются: высокоскоростное переупорядочение пакетов; расширенный контроль перегрузок с использованием данных в реальном времени и специализированных сетевых алгоритмов; возможность программирования ввода-вывода (I/O); энергоэффективный низкопрофильный дизайн; полная оптимизация для ИИ (включая вычисления, сети, хранилище, системное ПО, коммуникационные библиотеки). В одной системе могут быть задействованы до восьми SuperNIC, что позволяет добиться соотношения 1:1 с GPU. А это даёт возможность максимизировать производительность при выполнении сложных задач ИИ.
25.06.2023 [16:53], Алексей Степин
Cisco представила ASIC Silicon One G200: 51,2 Тбит/с для ИИКомпания Cisco успешно выпустила новые ASIC для сетевых коммутаторов с производительностью 51,2 Тбит/с. Как заявляют разработчики, коммутаторы на базе чипа серии G200 способны объединить в единый комплекс 32 тыс. ускорителей. Новое решение входит в портфолио Cisco Silicon One и изначально нацелено на рынок гиперскейлеров и создателей ИИ-кластеров. В новом чипе в два раза увеличено количество блоков SerDes с производительностью 112 Гбит/с (с 256 до 512), что и позволило довести общую коммутационную производительность до 51,2 Тбит/с. Доступны конфигурации 64×800GbE, 128×400GbE или 256×200GbE, всё зависит от желаемой плотности размещения и скорости портов. Это, в частности, позволяет избавиться от избыточных уровней в топологии сети. 
Источник изображений: Cisco Cisco отмечает, что новинка вдвое энергоэффективнее и имеет вдвое меньшую задержку в сравнении с G100. Кроме того, чипы предлагают расширенную телеметрию, поддержку языка P4 для обработки трафика на лету, а также возможность использования современных интерфейсов, в том числе интегрированную оптику или медные кабели длиной до 4 м, чего более чем достаточно для организации связи на уровне стойки. 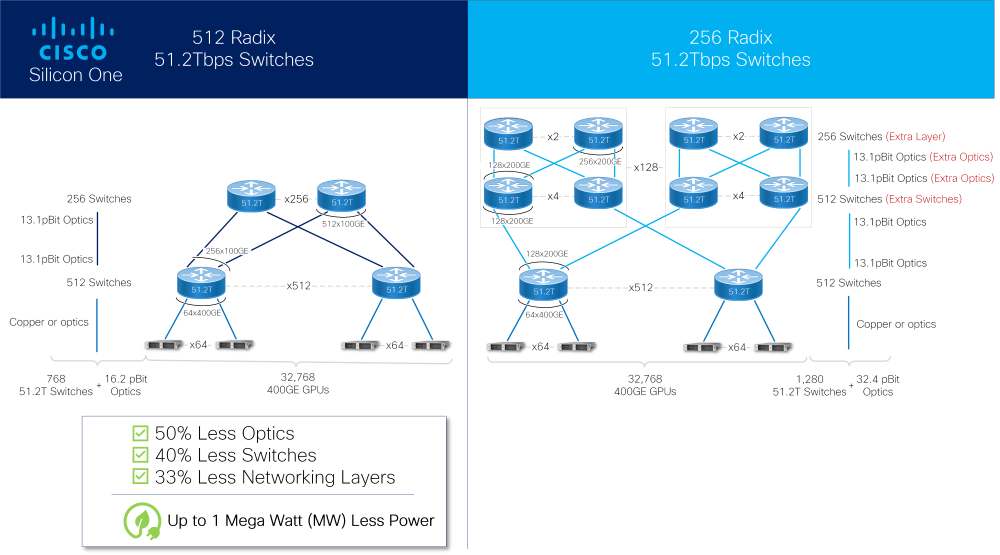 Как и Broadcom Tomahawk-5 или Jericho3-AI, Marvell Teralynx 10 и NVIDIA Spectrum-X, новый чип Cisco содержит возможности, востребованные в среде ИИ-систем, такие как продвинутые средства преодоления заторов в сети (congestion), технологии packet spraying и резервирование линков с возможностью мгновенного восстановления разорванного соединения. Новые чипы серии G200 уже поставляются, но компания пока не назвала даты появления на рынке коммутаторов Cisco на базе нового «кремния».
19.04.2023 [22:00], Алексей Степин
Broadcom представила чип-коммутатор Jericho3-AI для ИИ-платформ, попутно раскритиковав NVIDIAКомпания Broadcom, один из ведущих поставщиков «кремния» для сетевых решений, анонсировала новый сетевой процессор Jerico3-AI, который ориентирован на ИИ-системы. Более того, Broadcom считает подход NVIDIA к «интеллектуальным сетевым решениям» с использованием InfiniBand неверным и даже вредным для кластерных ИИ-систем. Ethernet-коммутаторы компании можно разделить три ветви: наиболее высокопроизводительные чипы Tomahawk, ориентированная на дополнительные возможности ветвь Trident и, наконец, серия Jericho, отличающаяся наибольшей гибкостью в программировании и располагающая более ёмкими буферами. Чип Jericho3-AI BCM88890 — новинка в последней категории, относящаяся к классу 28,8 Тбит/с. Новый коммутатор имеет 144 линка SerDes (106Gbps, PAM4) и может работать в конфигурации 18×800GbE, 36×400GbE или 72×200GbE. 
Источник здесь и далее: Broadcom (via ServeTheHome) В своей презентации Broadcom раскритиковала традиционный подход NVIDIA и других крупных игроков на сетевом рынке, заявив о том, что прямое наращивание пропускной способности и снижение латентности кластерной сети якобы является тупиковой ветвью развития. Вместо этого фабрика на базе Jericho3-AI, по словам компании, позволяет сделать так, чтобы процесс обучения нейросети как можно меньше времени тратил не сетевые операции.  Новый коммутатор обеспечивает идеальную балансировку загрузки, гарантирующую отсутствие заторов, и автоматическое переключение отказавшего соединения на резервное менее, чем за 10-нс, а также позволяет создавать большие «плоские» сети (до 32 тыс. портов 800GbE), характерные для ИИ-кластеров. Каждый ускоритель может получить 800G-подключение, а суммарная производительность фабрики на базе новых коммутаторов может достигать 26 Пбит/с. 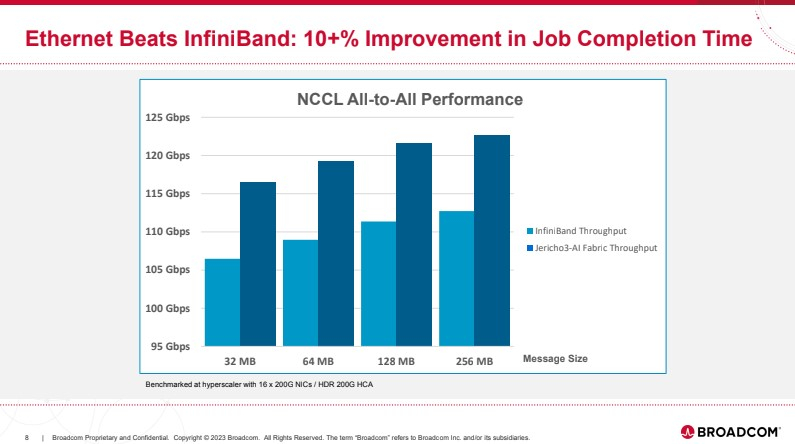 Broadcom утверждает, что сеть Ethernet на базе Jericho3-AI превосходит аналогичную по классу сеть NVIDIA InfiniBand в тестах с использованием NCCL. При этом новый коммутатор не содержит никаких вычислительных мощностей общего назначения — он проще, а за счёт использования стандарта Ethernet сети на его основе универсальны, что также снижает стоимость владения инфраструктурой.  Высокая степень интегрированности обеспечит и большую экономичность, а значит, решения на базе нового коммутатора Broadcom окажутся и более дружелюбны к экологии. Новые чипы уже доступны избранным клиентам Broadcom.
26.08.2022 [12:45], Алексей Степин
Интерконнект NVIDIA NVLink 4 открывает новые горизонты для ИИ и HPCПотребность в действительно быстром интерконнекте для ускорителей возникла давно, поскольку имеющиеся шины зачастую становились узким местом, не позволяя «прокормить» данными вычислительные блоки. Ответом NVIDIA на эту проблему стало создание шины NVLink — и компания продолжает активно развивать данную технологию. На конференции Hot Chips 34 было продемонстрировано уже четвёртое поколение, наряду с новым поколением коммутаторов NVSwitch. 
Изображения: NVIDIA Возможность использования коммутаторов для NVLink появилась не сразу, изначально использовалось соединение блоков ускорителей по схеме «точка-точка». Но дальнейшее наращивание числа ускорителей по этой схеме стало невозможным, и тогда NVIDIA разработала коммутаторы NVSwitch. Они появились вместе с V100 и предлагали до 50 Гбайт/с на порт. Нынешнее же, третье поколение NVSwitch и четвёртое поколение NVLink сделали важный шаг вперёд — теперь они позволяют вынести NVLink-подключения за пределы узла. 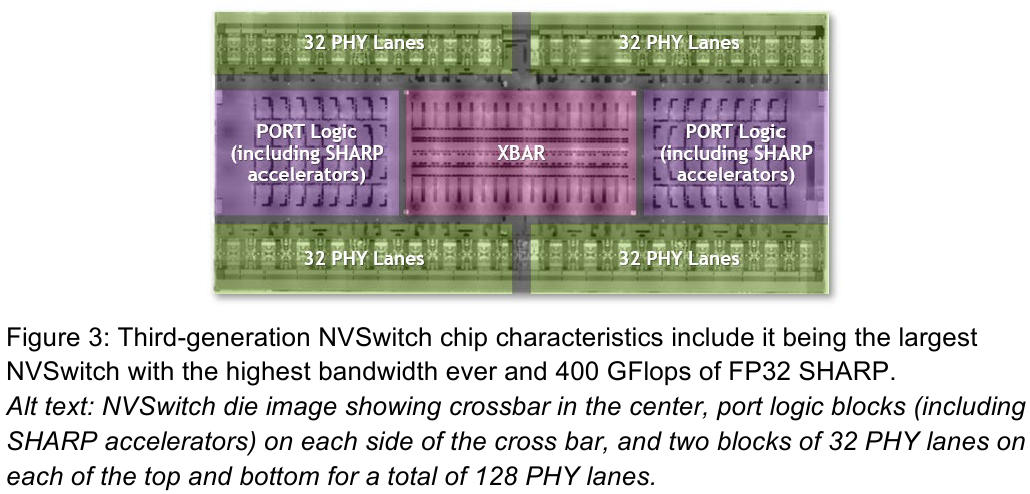 Так, совокупная пропускная способность одного чипа NVSwitch теперь составляет 3,2 Тбайт/с в обе стороны в 64 портах NVLink 4 (x2). Это, конечно, отразилось и на сложности самого «кремния»: 25,1 млрд транзисторов (больше чем у V100), техпроцесс TSMC 4N и площадь 294мм2. Скорость одной линии NVLink 4 осталась равной 50 Гбайт/с, но новые ускорители H100 имеют по 18 линий NVLink, что даёт впечатляющие 900 Гбайт/с. В DGX H100 есть сразу четыре NVSwitch-коммутатора, которые объединяют восемь ускорителей по схеме каждый-с-каждым и дополнительно отдают ещё 72 NVLink-линии (3,6 Тбайт/с). 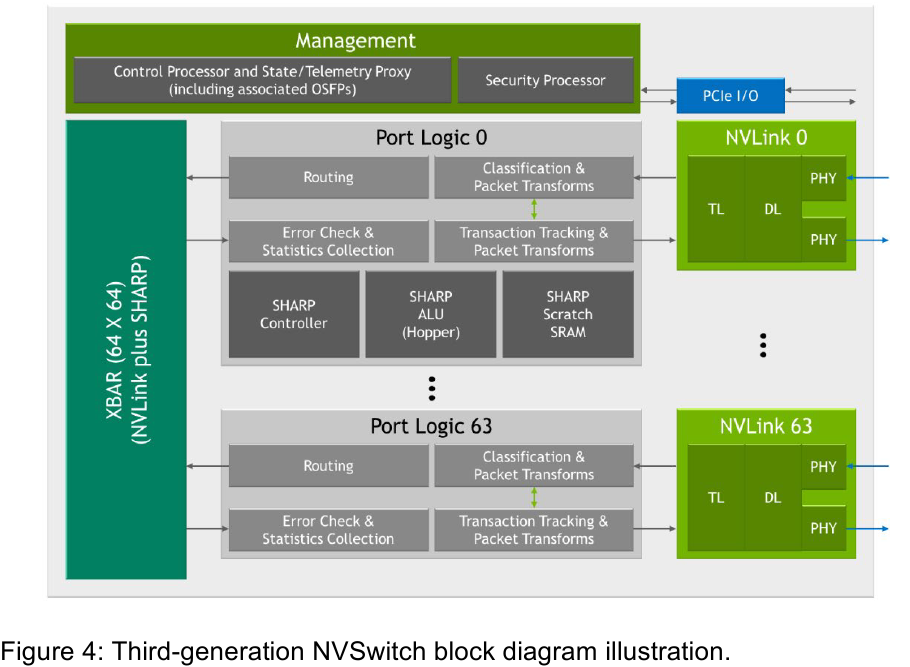 При этом у DGX H100 сохраняются прежние 400G-адаптеры Ethernet/InfiniBand (ConnectX-7), по одному на каждый ускоритель, и пара DPU BlueField-3, тоже класса 400G. Несколько упрощает физическую инфраструктуру то, что для внешних NVLink-подключений используются OSFP-модули, каждый из которых обслуживает 4 линии NVLink. Любопытно, что электрически интерфейсы совместимы с имеющейся 400G-экосистемой (оптической и медной), но вот прошивки для модулей нужны будут кастомные. 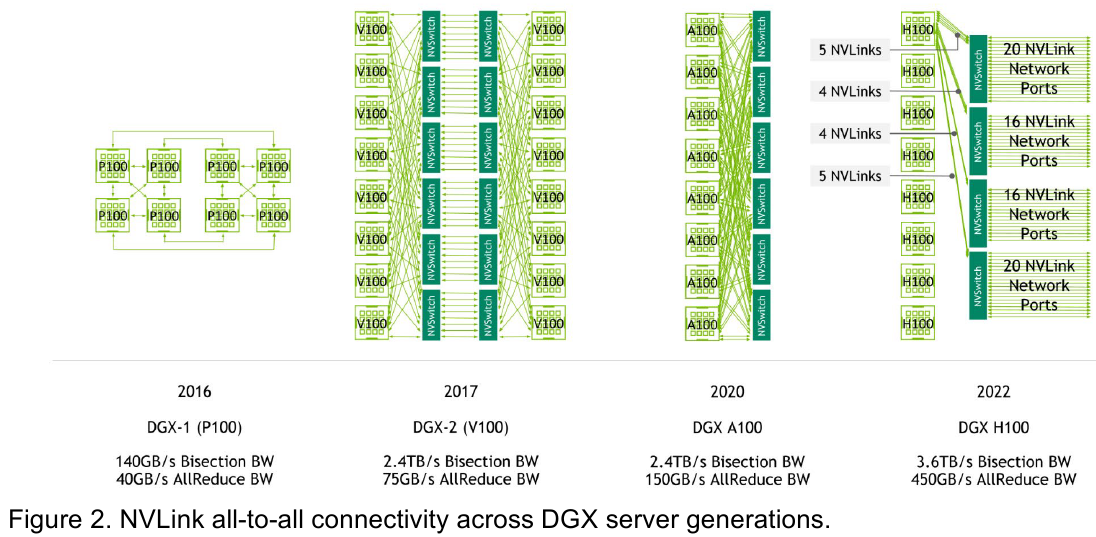 Подключаются узлы DGX H100 к 1U-коммутатору NVLink Switch, включающему два чипа NVSwitch третьего поколения: 32 OSFP-корзины, 128 портов NVLink 4 и агрегированная пропускная способность 6,4 Тбайт/с. В составе DGX SuperPOD есть 18 коммутаторов NVLink Switch и 256 ускорителей H100 (32 узла DGX). Таким образом, можно связать ускорители и узлы 900-Гбайт/с каналом. Как конкретно, остаётся на усмотрение пользователя, но сама NVLink-сеть поддерживает динамическую реконфигурацию на лету. 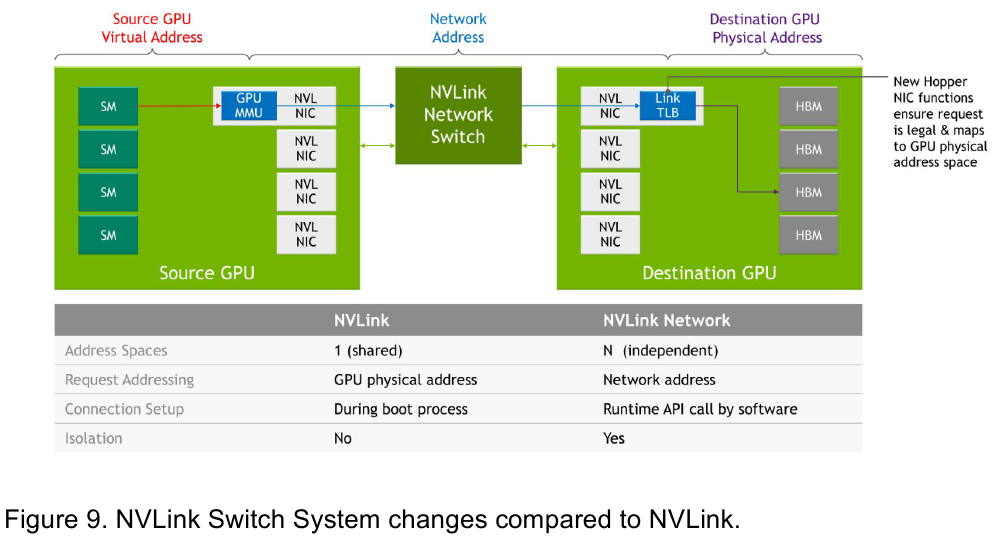 Ещё одна особенность нового поколения NVLink — продвинутые аппаратные SHARP-движки, которые избавляют CPU/GPU от части работ по подготовке и предобработки данных и избавляющие саму сеть от ненужных передач. Кроме того, в NVLink-сети реализованы разделение и изоляция, брандмауэр, шифрование, глубокая телеметрия и т.д. В целом, новое поколение NVLink получило полуторакратный прирост в скорости обмена данными, а в отношении дополнительных сетевых функций он стал трёхкратным. Всё это позволит освоить новые класса HPC- и ИИ-нагрузок, однако надо полагать, что удовольствие это будет недешёвым.
17.08.2022 [00:28], Алексей Степин
Broadcom представила 5-нм ASIC Tomahawk 5 с производительностью 51,2 Тбит/сРастущие объемы сетевого трафика, широкое распространение медиа-сервисов и видеоконференций, новые облачные услуги — всё это требует и нового сетевого «железа», способного справляться с повышающейся нагрузкой. И если не так давно для ASIC высшего класса нормой стал считаться показатель 25,6 Тбит/с, то сейчас вендоры осваивают следующий уровень производительности. Первенство в этой гонке принадлежит NVIDIA с её чипами Spectrum-4, но сейчас в игру вступила Broadcom. Компания представила пятое поколение «сетевого кремния» в серии StrataXGS Tomahawk, тоже способное осуществлять коммутацию на скоростях до 51,2 Тбит/с — 5-нм чип Tomahawk 5 (BCM78900). Появление ASIC такого класса существенно облегчает жизнь разработчикам HPС-систем для задач машинного обучения, поскольку позволит объединить в единый комплекс больше узлов без «наценки» на латентность в конфигурациях 64х800GbE, 128х400GbE или 256х100GbE. Поддерживается RoCEv2 и другие протоколы RDMA, виртуализация и сегментация сетей, VxLAN и прочие современные технологии. 
Источник: Broadcom Несколько ограничивают возможности новинки SerDes-блоки Peregrine (PAM4/106 Гбит/с). Каждые 8 таких блоков собраны в трансиверное ядро, всего ядер в новом чипе 64, что ограничивает эффективную производительность на порт именно цифрой 800 Гбит/с. Достоинством Tomahawk 5 станет его экономичность: использование 5-нм техпроцесса позволило довести удельное энергопотребление до цифры менее 1 Вт на 100 Гбит/с, то есть речь идёт о потреблении в районе 500 Вт для полной конфигурации. Цифра немалая, но всё же позволяющая сохранить воздушное охлаждение. Кроме того, новый ASIC снабжён шестью Arm-блоками для настраиваемой потоковой телеметрии. Следует отметить, что реальной потребности в таких скоростях пока очень немного: лишь 15 % (в деньгах) рынка Ethernet-устройств приходится на 400G-оборудование, но Broadcom считает, что постоянный рост аппетитов гиперскейлеров должен довести этот показатель до более чем 50 % уже к 2026 году. В случае же Tomahawk 5 пока речь идёт о первых поставках самих чипов, которые OEM-производителям ещё предстоит интегрировать в свои продукты. Они должны появиться на рынке в следующем году. |
|


