Материалы по тегу: omni-path
|
24.11.2025 [08:45], Сергей Карасёв
Cornelis анонсировала 800G-адаптер CN6000 SuperNIC с поддержкой Omni-Path, RoCEv2 и Ultra Ethernet для ИИ и НРСКомпания Cornelis Networks анонсировала сетевой адаптер CN6000 SuperNIC со скоростью передачи данных до 800 Гбит/с, разработанный для систем ИИ и НРС. О намерении использовать решение объявили многие отраслевые игроки, включая Lenovo, Synopsys и Atipa Technologies. В устройстве реализована архитектура Omni-Path. Говорится о полной совместимости со стандартами Ultra Ethernet и RoCEv2. Таким образом, адаптер может применяться в высоконагруженных средах, где требуются максимальная пропускная способность при низких задержках. Адаптер CN6000 SuperNIC обеспечивает быстродействие до 1,6 млрд сообщений в секунду. Утверждается, что новинка поможет организациям ускорить обучение крупных ИИ-моделей при одновременном снижении расходов на электроэнергию и эксплуатацию дата-центров. 
Источник изображения: Cornelis Networks Cornelis заявляет, что традиционные архитектуры RoCEv2 испытывают трудности при масштабировании в рамках масштабных GPU-кластеров из-за требований к ресурсам памяти при управлении парами связанных очередей (Queue Pair, QP) для отправки и приёма данных. CN6000 SuperNIC позволяет решить проблему благодаря принципиально иной конструкции: задействованы «облегчённые» алгоритмы QP и аппаратно-ускоренные таблицы RoCEv2 In-Flight (RiF), что даёт возможность отслеживать миллионы одновременных операций с минимальными требованиями к ресурсам. Это гарантирует предсказуемую задержку при максимальной пропускной способности в системах любого масштаба. Пробные поставки CN6000 SuperNIC планируется начать к середине 2026 года, после чего будет организовано массовое производство.
04.06.2025 [22:00], Владимир Мироненко
Лучше, чем InfiniBand и Ethernet: Cornelis Networks представила 400G-интерконнект Omni-Path CN5000Поставщик сетевых решений Cornelis Networks объявил о выходе 400G-интерконнекта CN5000, «самого производительного в отрасли сквозного (end-to-end) сетевого решения, специально созданного для максимизации производительности ИИ и HPC». Это первая крупная платформа Cornelis Networks после выделения из Intel в 2021 году, призванная конкурировать с Ethernet и InfiniBand. Лиза Спелман (Lisa Spelman), генеральный директор Cornelis Networks, отметила, что сети должны не только быстро перемещать данные, но и раскрывать весь потенциал каждого вычислительного цикла. «Если вы посмотрите на текущие ИИ-кластеры или кластеры HPC, вы увидите, что использование вычислений в некоторых случаях составляет менее 30 %, а… в лучших архитектурах и лучших случаях оно достигает (лишь) 50 %», — сообщила Спелман в интервью Network World. 
Источник изображений: Cornelis Networks Согласно пресс-релизу, CN5000 позволяет ИИ- и HPC-приложениям достигать более быстрого и предсказуемого времени выполнения задач и большей вычислительной эффективности за счёт минимизации перегрузок и поддержания максимальной пропускной способности под нагрузкой. В HPC-нагрузках CN5000 обеспечивает по сравнению с InfiniBand NDR до двух раз более высокую скорость отправки сообщений, на 35 % меньшую задержку и на 30 % выше производительность в таких задачах как вычислительная гидродинамика (CFD), моделирование климата и сейсмическое моделирование. CN5000 также показывает более высокую устоявшуюся пропускную способность в реальных условиях. 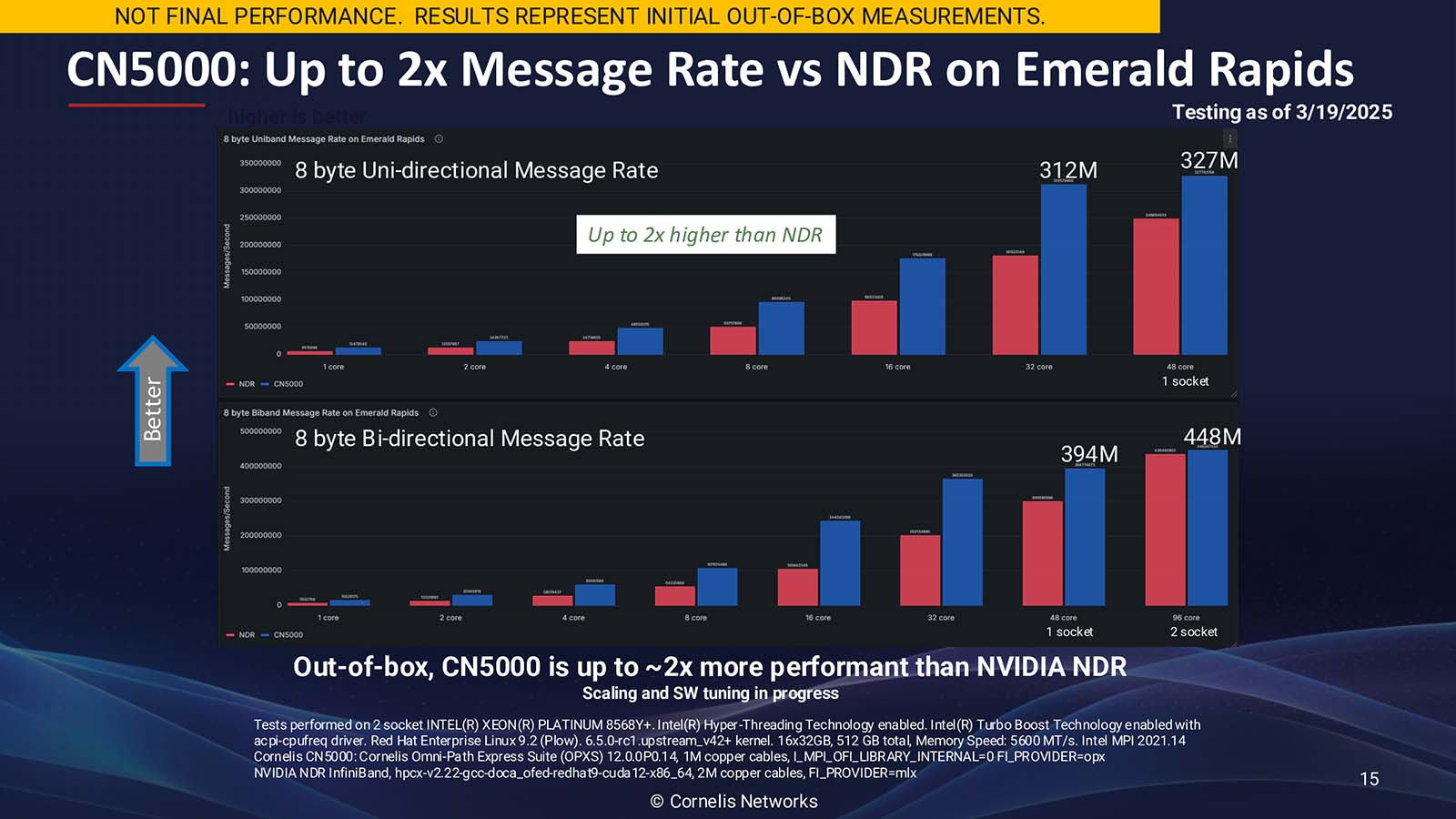 Для ИИ-приложений CN5000 предлагает в шесть раз более высокую производительность коллективных операций по сравнению RoCE. Коллективные операции, такие как all-reduce, представляют собой критические узкие места в распределённом обучении, где тысячи узлов должны эффективно синхронизировать обновления градиента. Сообщается, что CN5000 обеспечивает почти линейное масштабирование производительности обучения для больших языковых моделей (LLM) и более эффективный инференс с расширенной логикой. CN5000 является универсальным продуктом — интерконнект без проблем взаимодействует с CPU и GPU от AMD, Intel, NVIDIA и других производителей. Используется полностью открытый программный стек OpenFabrics, чтобы сделать переход от InfiniBand или Ethernet к Omni-Path «невероятно простым» для любого клиента, пояснила Спелман. Кроме того, OpenFabrics принят консорциумом Ultra Ethernet в качестве базового компонента.  Семейство CN5000 включает:
Как рассказала Спелман, CN5000 представляет собой третий архитектурный подход к высокопроизводительным сетям, отличный от реализаций Ethernet и InfiniBand. Вместо того, чтобы пытаться модернизировать существующие протоколы для рабочих ИИ- и HPC-нагрузок, Cornelis Networks расширила возможности Omni-Path от Intel с учётом конкретных вариантов использования: «Что мы сделали — это исправили архитектуру для рабочих нагрузок».  Архитектура нового решения получила несколько ключевых отличий, разработанных специально для масштабируемых параллельных вычислительных сред. В частности, управление потоком на основе кредитов обеспечивает передачу данных без потерь, в то время как тонкая адаптивная маршрутизация оптимизирует выбор пути в реальном времени. Улучшенные механизмы контроля перегрузки предназначены для поддержания стабильной производительности при высоких нагрузках, что является критически важным требованием для рабочих нагрузок ИИ-обучения, которые могут включать тысячи конечных точек. Всё это позволит улучшить использование GPU и других чипов в ИИ ЦОД, которые традиционно не используются в полной мере из-за неэффективности интерконнекта. Спелман отметила, что отличительной чертой архитектуры Cornelis Networks является то, что при той же пропускной способности можно достичь удвоения скорости передачи сообщений.  «При использовании точно таких же вычислительных ресурсов, просто заменив другую 400G-сеть на CN5000, вы увидите рост производительности приложений на 30 %, — пообещала Спелман. — Обычно для повышения производительности приложений на 30 % вам понадобится новое поколение ЦП». Более эффективное использование чипов позволяет либо работать с более крупными нагрузками на том же «железе», либо добиваться того же результата, используя меньше вычислительного оборудования.  «CN5000 — это сквозная сеть, в которой Super NIC и коммутатор или Director работают вместе», — пояснила Спелман. Платформа CN5000 поддерживает масштабирование до 500 тыс. конечных точек (250 тыс. узлов), что делает её подходящей для крупных установок, типичных для национальных лабораторий и корпоративных программ в области ИИ. Поставки CN5000 клиентам начнутся в июне, а массова она станет доступна с III квартала 2025 года у всех основных OEM-производителей. 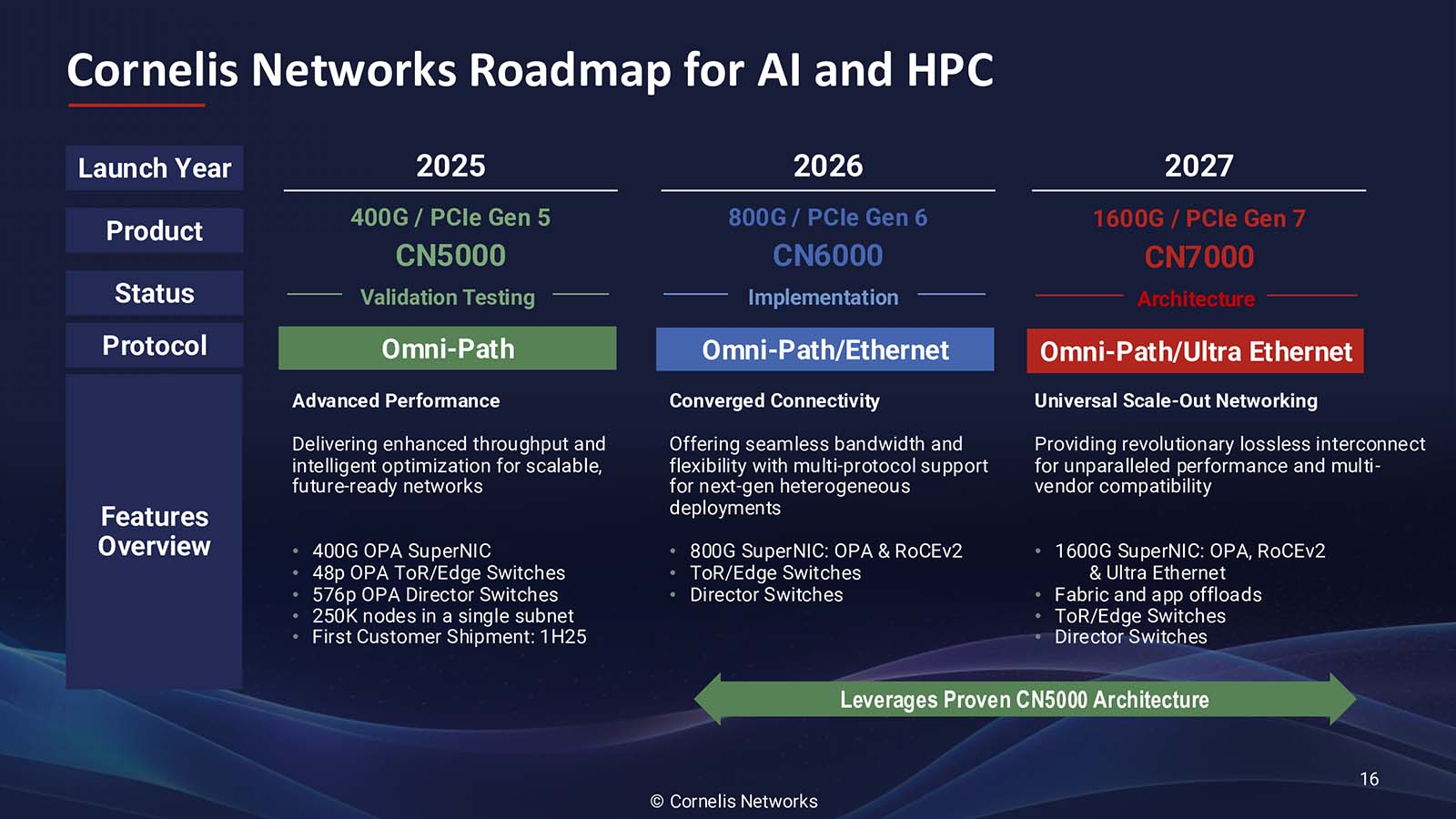 Cornelis Networks видит существенно большие рыночные возможности в следующих поколениях решения. Платформа CN6000 (800 Гбит/с) выйдет в 2026 году и будет включать возможности двухрежимного режима с поддержкой SuperNIC протоколов Ethernet для более широкой совместимости с экосистемой. В 2027 году должна выйти платформа CN7000 (1,6 Тбит/с), которая получит поддержку стандартов Ultra Ethernet на уровне коммутатора. Платформа также будет поддерживать 2 млн узлов и внутрисетевые вычисления. Анонс CN5000 состоялся ещё в конце 2023 года, т.е. у компании ушло довольно много времени на доработку продукта. Вместе с тем буквально вчера были представлены коммутаторы Broadcom Tomahawk 6, которые уже предлагают до 1,6 Тбит/с на порт, интегрированную фотонику (CPO) и поддержку Ultra Ethernet. А весной этого года NVIDIA представила 800G-платформу Ethernet/InfiniBand, причём изначально с CPO. Не осталась в стороне и Eviden (Atos), которая также анонсировала 800G-интерконнект BXI v3.
29.06.2021 [17:49], Алексей Степин
Cornelis Networks подняла упавшее знамя Intel Omni-PathОт собственной технологии интерконнекта Omni-Path (OPA) компания Intel довольно неожиданно отказалась летом 2019 года, хотя на тот момент OPA-решения составляли достойную конкуренцию InfiniBand EDR, Ethernet и проприетарным интерконнектам как по скорости, так и по уровню задержки и поддержки необходимых для высокопроизводительных вычислений (HPC) функций. В конце прошлого года все наработки по OPA перешли к компании Cornelis Networks, образованной выходцами из Intel. В арсенале Intel были процессоры Xeon и Xeon Phi со встроенным интерфейсом Omni-Path, PCIe-адаптеры, коммутаторы и сопутствующее ПО. Казалось бы, у технологии большое будущее, однако второе поколение шины OPA, поддерживающее скорость 200 Гбит/с, так и не было выпущено, а компания сосредоточилась на Ethernet. При этом NVIDIA уже анонсировала InfiniBand NDR (400 Гбит/c), да и 200GbE-решениями сейчас никого не удивить.  Однако идеи, заложенные в Omni-Path, не умерли, и упавшее знамя нашлось, кому подхватить. Cornelis Networks быстро принялась за дело — через месяц после представления компании уже были представлены новые машины с Omni-Path, причём как на базе Intel, так и на базе AMD. А на ISC 2021 Cornelis Networks анонсировала полный спектр собственных решений под брендом Omni-Path Express, реализующих все основные достоинства технологии.  Конечно, процессоров с разъёмом Omni-Path мы по понятным причинам уже не увидим, но компания предлагает низкопрофильные хост-адаптеры с пропускной способностью до 25 Гбайт/с (100 Гбит/с в каждом направлении). Они поддерживают открытый фреймворк Open Fabrics Interface (OFI) и предлагают коррекцию ошибок с нулевой латентностью. В качестве разъёма используется популярный в индустрии QSFP28.  Также представлен ряд коммутаторов. В серии CN-100SWE есть модели с поддержкой горячей замены, которые имеют 48 портов и общую пропускную способность до 1,2 Тбайт/с при латентности, не превышающей 110 нс. Поддерживается организация виртуальных линий Omni-Path Express и фреймы большого размера, от 2 до 10 Кбайт. При этом коммутаторы компактны и занимают всего 1 слот в стандартной стойке.  Директор CN-100SWE предназначен для крупных кластерных систем. Он является модульным и может занимать от 7U до 20U, реализуя при этом от 288 до 1152 портов Omni-Path Express со скоростью 100 Гбит/с на порт. Латентность при этом не превышает 340 нс. Для сравнения, сети на базе Ethernet, как правило, оперируют значениями в десятки миллисекунд в лучшем случае.  Технологиями Cornelis Networks уже заинтересовался крупный российский поставщик HPC-систем, группа компаний РСК, которая и ранее поставляла кластеры и суперкомпьютеры с Omni-Path, в том числе с коммутаторами, снабжёнными фирменной СЖО. РСК получила наивысший партнёрский статус Elite+ у Cornelis и уже готова интегрировать Omni-Path Express в системы «РСК Торнадо» на базе третьего поколения процессоров Xeon Scalable.
02.08.2019 [14:32], Геннадий Детинич
Intel хоронит шину Omni-PathДовольно неожиданно компания Intel отказалась от развития интерконнекта Omni-Path, которую она продвигала в серверных и HPC-платформах сначала для соединения узлов, в том числе для гиперконвергентных систем. Первое поколение шины Omni-Path с пропускной способностью до 100 Гбит/с на порт появилось несколько лет назад. Но ожидаемого второго поколения решений с пропускной способностью до 200 Гбит/с уже не будет. 
Ускорители Intel Xeon Phi с интегрированными контроллером и шиной Omni-Path Информацию о прекращении разработки и выпуска продукции Intel OmniPath Architecture 200 (OPA200) компания подтвердила, например, нашим коллегам с сайта HPCwire. Компания продолжит поддержку и поставку решений с шиной OPA100, но поставок продуктов с архитектурой OPA200 на рынок больше не будет. В принципе, сравнительно слабая поддержка шины Intel OmniPath со стороны клиентов рынка высокопроизводительных систем намекала на нечто подобное. Большей популярностью у строителей суперсистем и не только продолжает пользоваться InfiniBand и её новое HDR-воплощение с той же пропускной способностью до 200 Гбит/с. В свете ликвидации OPA200 становится понятно, почему Intel схватилась с NVIDIA за право поглощения компании Mellanox. Но не вышло: приз ушёл к NVIDIA. «Вообще, половина инсталляций в TOP500 использует Ethernet, но в основном 10/25/40 Гбит/с, и лишь совсем чуть-чуть может похвастаться 100 Гбит/с. InfiniBand установлен почти в 130 машинах, а Omni-Path есть чуть больше чем в 40. Остальное — проприетарные разработки». Что остаётся Intel? У лидера рынка микропроцессоров есть I/O-активы. Компания около 8 лет активно выстраивает направление для развития коммуникаций в ЦОД. За это время она поглотила разработчика коммутационных ASIC компанию Fulcrum Microsystems, подразделение по разработке адаптеров и коммутаторов InfiniBand компании QLogic и коммуникационное подразделение компании Cray. Относительно свежей покупкой Intel стала компания Barefoot Networks, разработчик решений для Ethernet-коммутаторов. Похоже, Intel решила вернуться к классике: InfiniBand (что менее вероятно) и Ethernet (что более вероятно), а о проприетарных шинах в виде той же Omni-Path решила забыть. В конце концов, Ethernet-подразделение компании славится своими продуктами. Новое поколения Intel Ethernet 800 Series способно заменить OPA100. |
|

