Материалы по тегу: in-memory
|
26.02.2025 [15:12], Сергей Карасёв
1376 ядер и 64 Тбайт RAM: Eviden представила суперсерверы Bullsequana SH с Intel Xeon 6500P/6700P и опциональной СЖОКомпания Eviden, входящая в Atos Group, анонсировала серверы семейства Bullsequana SH, построенные на процессорах Intel Xeon 6 семейства Granite Rapids-SP. По заявлениям разработчика, новые машины по сравнению с системами предыдущего поколения обеспечивают рост производительности в 1,5 раза и увеличение пропускной способности памяти в 1,7 раза. В серию вошли модели BullSequana SH21, SH41, SH81 и SH161 в форм-факторе 2U, 4U, 8U и 19U соответственно. Основой служат двухсокетные 2U-узлы, количество которых составляет один, два, четыре и восемь. Таким образом, общее число процессоров Xeon 6 в составе систем варьируется от 2 до 16. Поддерживаются чипы Xeon 6500P и 6700P, насчитывающие до 86 вычислительных ядер. Таким образом, количество ядер в одной системе может достигать 1376, а потоков — 2752. Узлы SH21, SH41 и SH81 напрямую объединяются между собой посредством Intel UPI 2.0 (24 ГТ/с), а вот для SH161 уже используется UPI-коммутатор UBox на базе ASIC, который позволяет объединить 16 сокетов в кеш-когерентную SMP-систему (CC-NUMA). Также есть 38U-модель BullSequana SH321 с 16 узлами и двумя коммутаторами UBox, но топология объединения узлов для неё не уточняется. 
Источник изображения: Eviden Каждый из 2U-узлов в составе новых серверов имеет 32 слота для модулей оперативной памяти DDR5 RDIMM или DDR5 RDIMM-3DS. Максимально поддерживаемый объём ОЗУ варьируется от 8 до 64 Тбайт. В расчёте на узел доступны до шести слотов PCIe 5.0 x8 и два разъёма PCIe 5.0 x16 или до пяти слотов PCIe 5.0 x16. Поддерживаются адаптеры 1/10/25/100/200/400GbE и FC32/64. На каждый узел доступны два коннектора M.2 для NVMe SSD с опциональным RAID 0/1. Опциональный модуль SSD Box допускает подключение от восьми до 64 NVMe-накопителей E1.S с возможностью горячей замены. Кроме того, может быть добавлен адаптер для формирования массивов RAID 0/1/5/6/00/10/50/60. 
Источник изображения: Eviden Серверы комплектуются блоками питания с сертификатом 80 PLUS Titanium мощностью 2200 или 3000 Вт. Каждый узел оснащается 12 вентиляторами охлаждения. Присутствуют контроллер Aspeed AST2600, сетевой порт управления 1GbE, два порта USB 3.1, последовательный порт и интерфейс D-Sub. Диапазон рабочих температур — от +10 до +35 °C. Заявлена совместимость с платформами SuSE Linux Enterprise Server, Red Hat Enterprise Linux, VMware vSphere (ESXiTM), Windows Server и Oracle Linux. Серверы Bullsequana SH ориентированы на корпоративных заказчиков, поставщиков облачных услуг и гиперскейлеров. Благодаря модульной конструкции обеспечивается гибкость масштабирования при решении задач НРС и ИИ. В качестве опции доступна технология прямого жидкостного охлаждения Eviden DLC: она, как утверждается, обеспечивает как минимум 10-% снижение потребления энергии по сравнению с воздушным охлаждением, а температуры воды на входе может достигать +40 °C. Устройства производятся на заводе Eviden в Анже (Франция) и обеспечиваются трёхлетней гарантией.
24.01.2025 [14:33], Сергей Карасёв
Бывший гендиректор Intel Пэт Гелсингер инвестировал средства в ИИ-стартап FractileЭкс-гендиректор Intel Пэт Гелсингер, по сообщению TrendForce, стал инвестором британского стартапа Fractile.ai, который специализируется на разработках в области ИИ. Сумма, которую предоставил бывший глава Intel на развитие этой компании, не раскрывается. Fractile.ai основана в 2022 году Уолтером Гудвином (Walter Goodwin) — специалистом, получившим докторскую степень в области искусственного интеллекта и робототехники в Оксфордском университете. Стартап разрабатывает специализированные ИИ-чипы, использующие метод вычислений в оперативной памяти. Такой подход может существенно повысить скорость инференса и выполнения других задач, связанных с интенсивными вычислениями. Утверждается, что по сравнению с традиционными ИИ-ускорителями на базе GPU решения Fractile.ai обеспечат ряд значительных преимуществ. В частности, говорится, что новые чипы позволят поднять производительность больших языковых моделей (LLM) в 100 раз при одновременном 10-кратном снижении затрат по сравнению с решениями NVIDIA. При этом чипы Fractile.ai обеспечат в 20 раз более высокую производительность в расчёте на 1 Вт затрачиваемой энергии по сравнению с любым другим оборудованием ИИ, представленным в настоящее время на рынке. 
Источник изображения: Intel Однако пока Fractile.ai не изготовила тестовые образцы изделий, а оценка их характеристик и возможностей проводится путём компьютерного моделирования. Тем не менее, Гелсингер говорит, что ни один подход в отношении ИИ-вычислений не воодушевляет его больше, чем тот, который предлагает Fractile.ai. По его словам, для дальнейшего масштабирования ИИ большое значение имеет снижение как энергопотребления, так и стоимости вычислений. Отмечается также, что стартап Fractile.ai ранее привлек в общей сложности $17,5 млн финансирования. В число инвесторов входят Kindred Capital, NATO Innovation Fund, Oxford Science Enterprises и несколько бизнес-ангелов.
20.01.2025 [07:53], Владимир Мироненко
SRAM, да и только: d-Matrix готовит ИИ-ускоритель CorsairСтартап d-Matrix создал ИИ-ускоритель Corsair, оптимизированный для быстрого пакетного инференса больших языковых моделей (LLM). Архитектура ускорителя основана на модифицированных ячейках SRAM для вычислений в памяти (DIMC), работающих на скорости порядка 150 Тбайт/с. Новинка, по словам компании, отличается производительностью и энергоэффективностью, пишет EE Times. Массовое производство Corsair начнётся во II квартале. Среди инвесторов d-Matrix — Microsoft, Nautilus Venture Partners, Entrada Ventures и SK hynix. d-Matrix фокусируется на пакетном инференсе с низкой задержкой. В случае Llama3-8B сервер d-Matrix (16 четырёхчиплетных ускорителей в составе восьми карт) может производить 60 тыс. токенов/с с задержкой 1 мс/токен. Для Llama3-70B стойка d-Matrix (128 чипов) может производить 30 тыс. токенов в секунду с задержкой 2 мс/токен. Клиенты d-Matrix могут рассчитывать на достижение этих показателей для размеров пакетов порядка 48–64 (в зависимости от длины контекста), сообщила EE Times руководитель отдела продуктов d-Matrix Шри Ганесан (Sree Ganesan). 
Источник изображений: d-Matrix Производительность оптимизирована для исполнения моделей в расчёте до 100 млрд параметров на одну стойку. По словам Ганесан, это реалистичный сценарий использования LLM. В таких сценариях решение d-Matrix обеспечивает 10-кратное преимущество в интерактивности (время до получения токена) по сравнению с решениями на базе традиционных ускорителей, таких как NVIDIA H100. Corsair ориентирован на модели размером менее 70 млрд параметров, подходящих для генерации кода, интерактивной генерации видео или агентского ИИ, которые требуют высокой интерактивности в сочетании с пропускной способностью, энергоэффективностью и низкой стоимостью.  Ранние версии архитектуры d-Matrix использовали MAC-блоки на базе SRAM-ячеек, дополненных большим количеством транзисторов для операций умножения. Сложение же выполнялось в аналоговом виде с использованием разрядных линий, измерения тока и аналого-цифрового преобразования. В 2020 году компания выпустила чиплетную платформу Nighthawk на основе этой архитектуры. «[Nighthawk] продемонстрировал, что мы можем значительно повысить точность по сравнению с традиционными аналоговыми решениями, но мы всё ещё отстаем на пару процентных пунктов от традиционных решений типа GPU», — сказал EE Times генеральный директор d-Matrix Сид Шет (Sid Sheth). 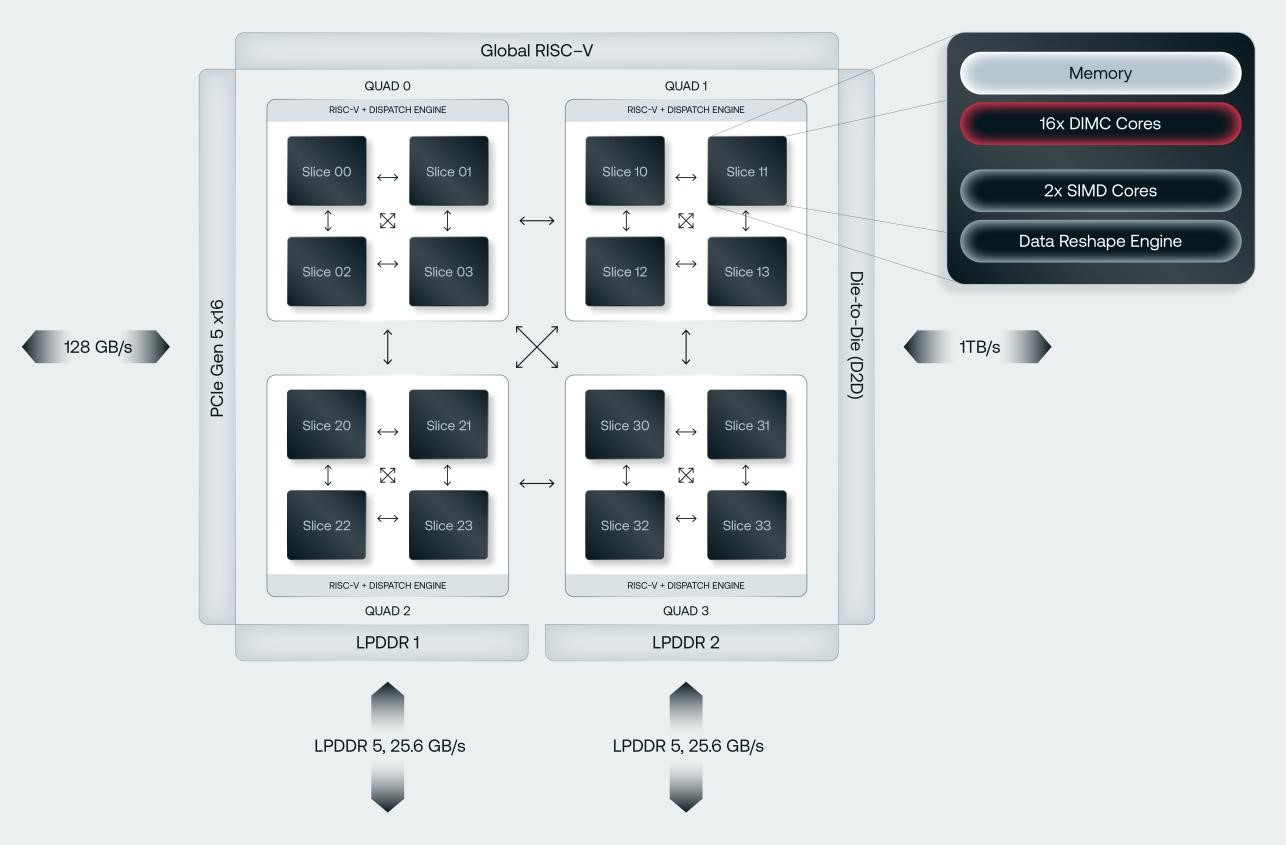 Однако потенциальным клиентам не понравилось, что при таком подходе возможно снижение точности, так что в Corsair компания вынужденно сделала выбор в пользу полностью цифрового сумматора. ASIC d-Matrix включает четыре чиплета, каждый из которых содержит по четыре вычислительных блока, объединённых посредством DMX Link по схеме каждый-с-каждым, и по одному планировщику и RISC-V ядру. Внутри каждого вычислительного блока есть 16 DIMC-ядер, состоящих из наборов SRAM-ячеек (64×64), а также два SIMD-ядра и движок преобразования данных. Суммарно доступен 1 Гбайт SRAM с пропускной способностью 150 Тбайт/с. 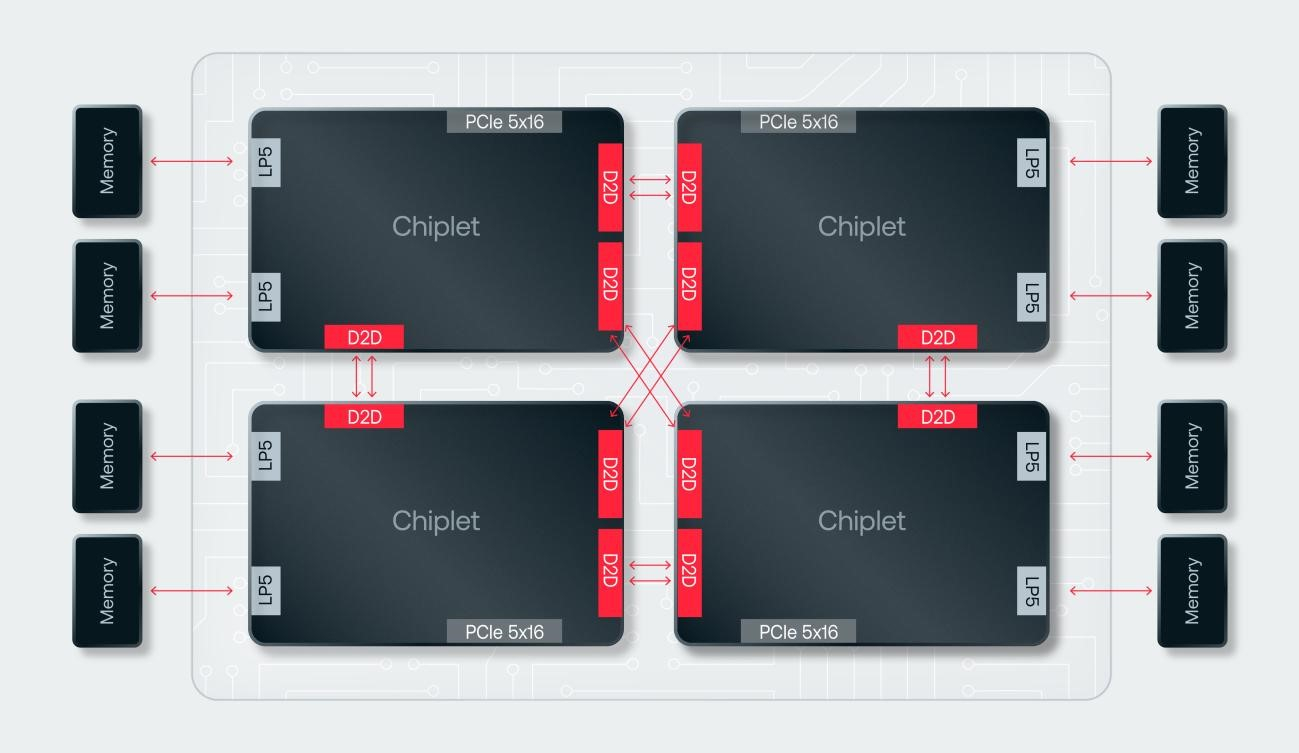 ASIC объединён со 128 Гбайт LPDDR5 (до 400 Гбайт/с) посредством органической подложки (без дорогостоящего кремниевого интерпозера). Хотя текущее поколение ASIC включает только четыре чиплета именно из-за ограничений подложки, в будущем их количество увеличится. Внешние интерфейсы ASIC представлены стандартным PCIe 5.0 x16 (128 Гбайт/с) и фирменным интерконнектом DMX Link (1 Тбайт/с) для объединения чиплетов. 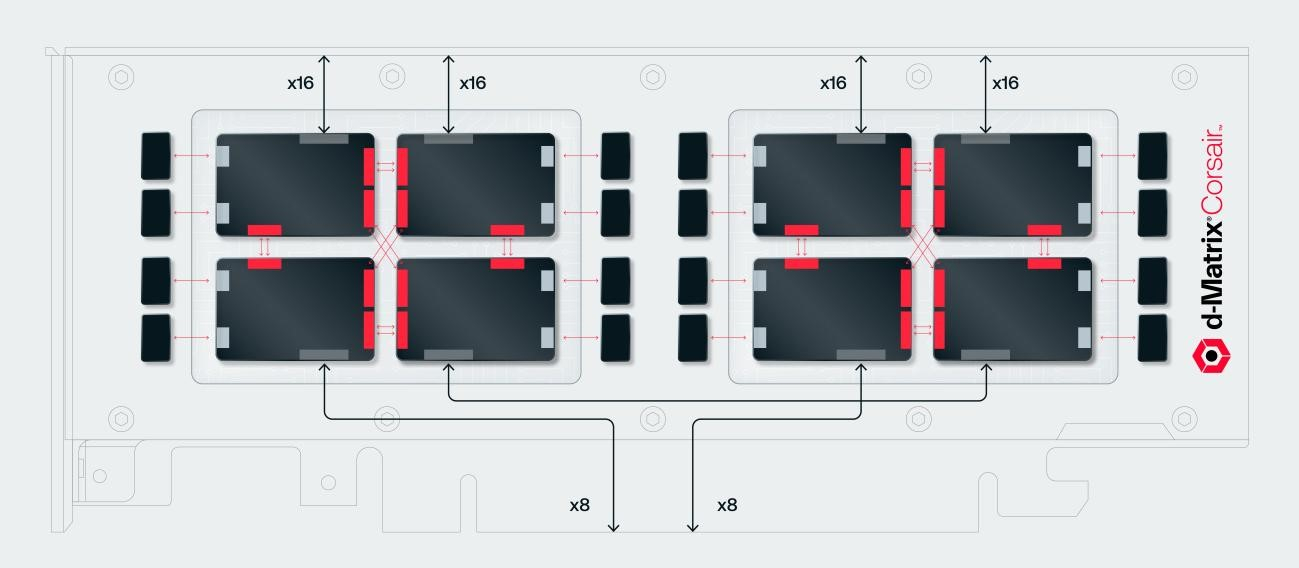 FHFL-карта Corsair включает два ASIC d-Matrix (т.е. всего восемь чиплетов) и имеет TDP на уровне 600 Вт. Ускоритель работает с форматами данных OCP MX (Microscaling Formats) и обеспечивает до 2400 Тфлопс в MXINT8-вычислениях или 9600 Тфолпс в случае MXINT4. Две карты Corsair можно объединить посредством 512-Гбайт/с мостика DMX Bridge. Их, по словам компании, достаточно для задействования тензорного параллелизма. Дальнейшее масштабирование возможно посредством PCIe-коммутации. Именно поэтому d-Matrix работает с GigaIO и Liqid. В одно шасси можно поместить восемь карт Corsair, а в стойку, которая будет потреблять порядка 6–7 кВт — 64 карты. 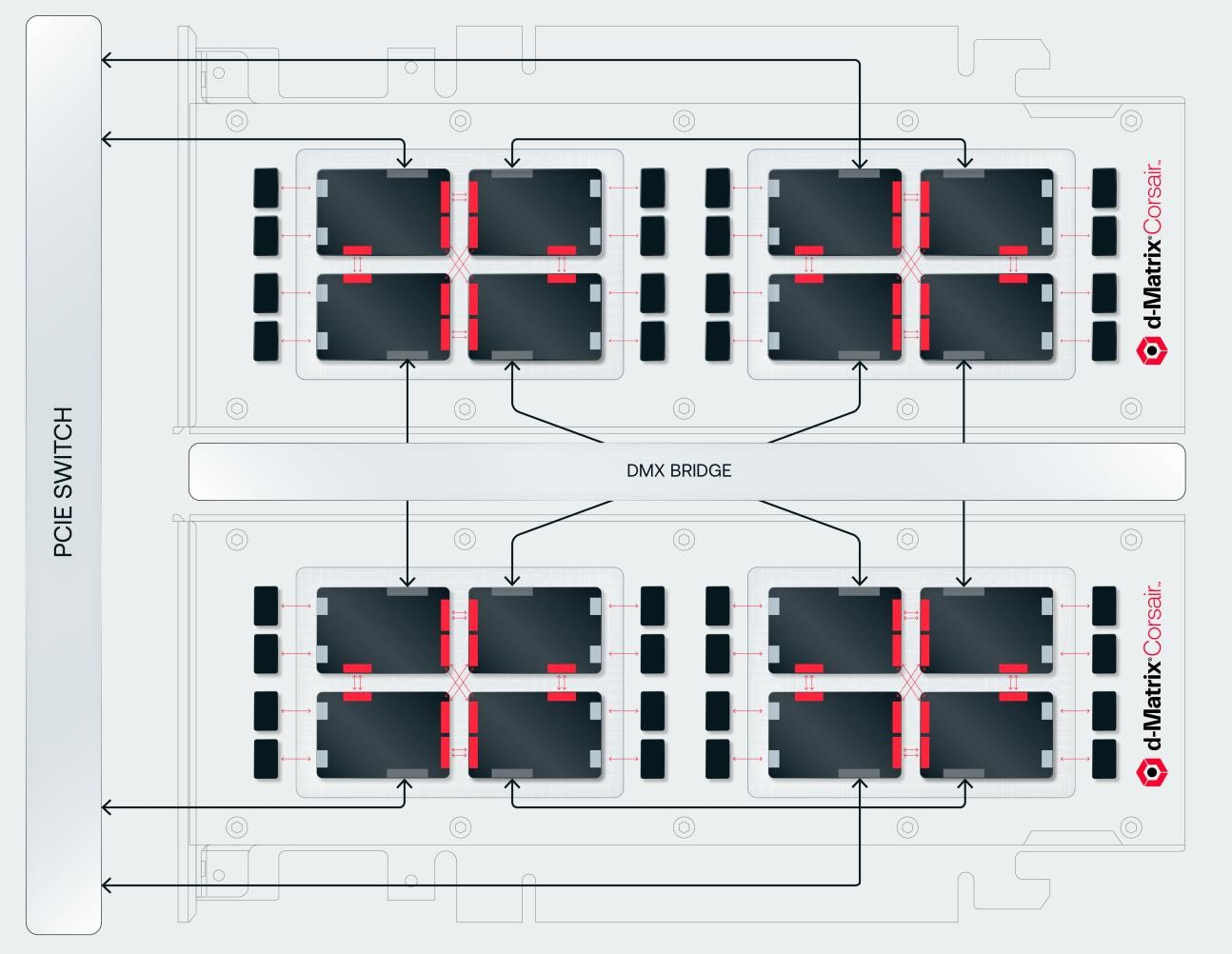 d-Matrix уже разрабатывает ASIC следующего поколения Raptor, который должен выйти в 2026 году. Raptor будет ориентирован на «думающие» модели и получит ещё больше памяти за счёт размещения DRAM непосредственно поверх вычислительных чиплетов. SRAM-чиплеты Raptor также перейдут с 6-нм техпроцесса TSMC, который используется при изготовлении Corsair, к 4 нм без существенных изменений микроархитектуры. По словам компании, она потратила два года на работу с TSMC, чтобы создать 3D-упаковку для нового поколения ASIC. 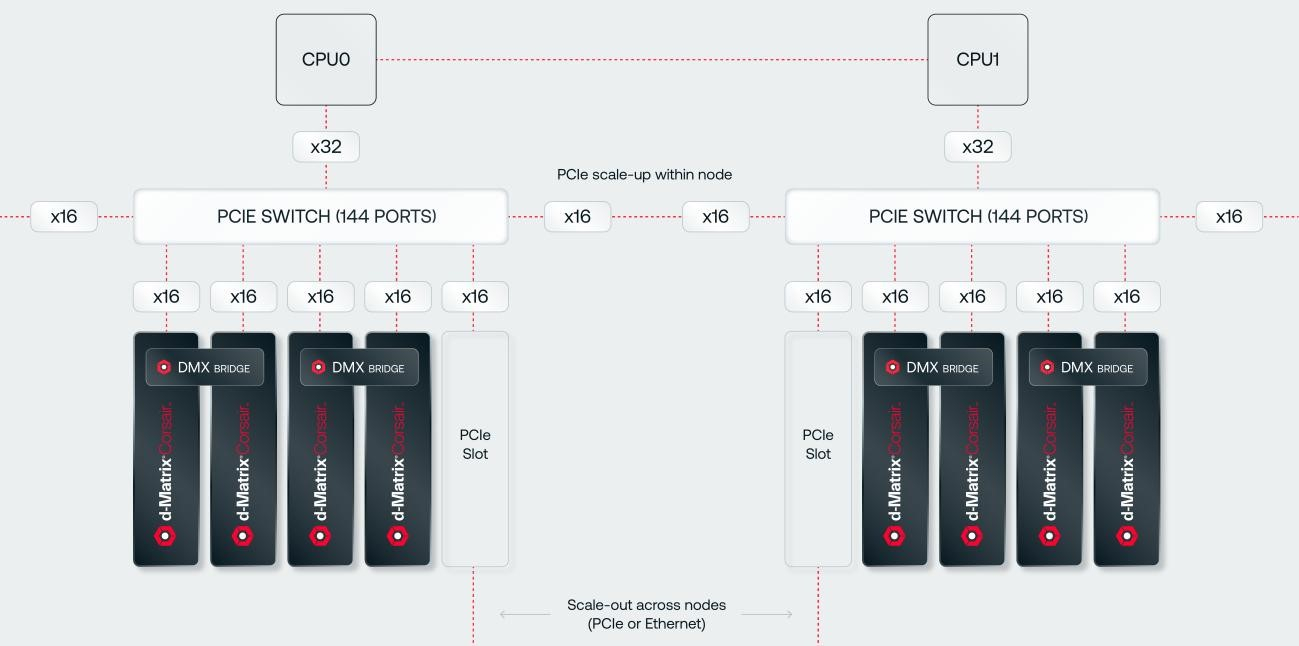 Как отмечает EETimes, команда разработчиков ПО d-Matrix в два раза больше команды разработчиков оборудования (120 против 60). Стратегия компании в области ПО заключается в максимальном использовании open source экосистемы, включая PyTorch, OpenAI Triton, MLIR, OpenBMC и т.д. Вместе они образуют программный стек Aviator, который отвечает за конвертацию моделей в числовые форматы d-Matrix, применяет к ним фирменные методы разрежения, компилирует их, распределяет нагрузку по картам и серверам, а также управляет исполнением моделей, включая обслуживание большого количества запросов.
17.12.2024 [12:30], Сергей Карасёв
1920 vCPU и 32 ТиБ RAM: AWS запустила инстансы EC2 U7inh на базе суперсерверов HPEОблачная платформа AWS объявила о доступности инстансов EC2 U7inh с сертификацией SAP. Эти экземпляры, построенные на серверах HPE, предлагают клиентам мощное и эффективное решение для запуска резидентных баз данных и приложений SAP в облаке. Задействована аппаратная платформа HPE Compute Scale-up Server 3200. Применяются серверы с 16 процессорами Intel Xeon Sapphire Rapids, насчитывающими до 60 вычислительных ядер каждый. Такие машины могут нести на борту до 32 Тбайт оперативной памяти DDR5. Допускается применение накопителей SATA/SAS HDD и SATA/SAS/NVMe SSD. Новые инстансы поддерживают Amazon Linux, Red Hat Enterprise Linux и SUSE Enterprise Linux Server. Сертификация SAP гарантирует, что экземпляры соответствуют строгим требованиям к производительности, объёму памяти и другим критическим характеристикам. Говорится о возможности использования SAP Business Suite on HANA (SoH), Business Suite S/4HANA, Business Warehouse on HANA (BW), SAP BW/4HANA. Несмотря на работу в виртуализированной среде, инстансы EC2 U7inh обеспечивают производительность, сопоставимую с bare metal. 
Источник изображения: HPE Конфигурация EC2 U7inh включает 1920 vCPU и 32 768 ГиБ памяти DDR5. Пропускная способность сетевого подключения составляет 200 Гбит/с, пропускная способность EBS — 160 Гбит/с. Подчёркивается, что инстансы EC2 U7inh предоставляют заказчикам высоконадёжное решение для поддержки масштабных рабочих нагрузок SAP, гарантируя бесшовную интеграцию и работу в облачной инфраструктуре AWS. Более того, возможно даже объедиение четырёх инстансов в кластер, что в сумме даёт уже 7680 vCPU и 128 ТиБ RAM.
03.12.2024 [17:58], Сергей Карасёв
Delta Computers представила первый в России модульный восьмипроцессорный сервер Delta SpiderРоссийская компания Delta Computers анонсировала систему Delta Spider. Это, как утверждается, первый в РФ модульный восьмипроцессорный сервер на аппаратной платформе Intel Xeon Sapphire Rapids. В составе Delta Spider применяются чипы с 60 ядрами, значение TDP которых может достигать 385 Вт. Возможны конфигурации с двумя, четырьмя и восемью процессорами, что в сумме даёт до 480 ядер. Процессоры объединены шиной UPI. Поддерживается память DDR5-4400/4800, объём которой в максимальной конфигурации составляет 32 Тбайт (128 × 256 Гбайт). Доступны базовые варианты Spider L и Spider XL в формате 7OU и 13OU соответственно. Допускается установка соответственно 16 и 32 SSD типоразмера SFF (U.2; NVMe) толщиной 7 мм или 8 и 16 SSD толщиной 15 мм. В модуле управления предусмотрены ещё два посадочных места для SSD (U.2; NVMe) толщиной 7 мм. Версия Spider L располагает 12 слотами для карт PCIe 5.0 х16 HHHL, модификация Spider XL — 24 слотами. 
Источник изображений: Delta Computers Серверы оборудованы гибридной системой охлаждения (вода+воздух) Delta Hybrid Cooling с возможность горячей замены вентиляторов, которая позволяет процессорам постоянно работать в Boost-режиме. Питание осуществляется от централизованного шинопровода OCP (12 В). Модуль управления наделён двумя портами USB 3.0, разъёмом 1GbE RJ-45, интерфейсами D-Sub и Mini-DP, а также сервисным портом USB Type-C. Применяется разработанное в России микропрограммное обеспечение Delta BIOS и Delta BMC.  По заявлениям Delta Computers, платформа Delta Spider подходит для высоконагруженных приложений, таких как системы управления предприятием (ERP и CRM), автоматизированные банковские системы (ABS), аналитические сервисы принятия решений реального времени, биллинговые и платежные системы, а также иных in-memory приложений.
12.01.2023 [15:47], Алексей Степин
Atos представила серверы BullSequana SH и edge-платформы EXR и EXD на базе Sapphire RapidsНовые процессоры Intel Xeon с архитектурой Sapphire Rapids навёрстывают упущенное и находят своё место в новых моделях серверов. На этот раз о новинках объявила компания Atos, представившая вычилительную систему BullSequana SH класса HPC и новые серверы в серии EX. Система BullSequana SH является модульной и расширяемой, базовым строительным блоком служит модуль SH20 с двумя процессорам Sapphire Rapids и 32 слотами DDR5 с поддержкой Optane PMem 300. Опциально такой модуль может нести на борту и пару DPU или GPU. До четырёх таких блоков можно объединить в единую систему с 8 процессорами, 32 Тбайт оперативной памяти и 8 ускорителями. Для этого нужны лишь UPI-коннекторы. Однако это не предел: с помощью специального модуля UBox высотой 3U, систему можно расширять и далее, не прибегая к помощи InfiniBand или иных сетей. Модуль UBox содержит внутри два контроллера Intel Ultra Path Interconnect (UPI), что позволяет с помощью одного модуля объединить в единую NUMA-систему до 16 процессоров. С помощью ещё одного UBox это число можно довести до 32 — именно такую конфигурацию имеет старшая модель BullSequana SH320. 
Источник изображений здесь и далее: Atos Все решения в серии SH поддерживают новые модели Xeon с числом ядер от 8 до 60 и частотами до 4,2 ГГц. Каждый модуль располагает двумя (1+1) блоками питания мощностью от 2200 до 3000 Вт, а также 12 вентиляторами с возможностью горячей замены. Для загрузки ОС в каждом модуле имеется 2 слота M.2, но опционально доступны дополнительные модули для установки NVMe-накопителей, а также корзины для GPU и PCIe-устройств с поддержкой горячей замены.  Компания также уделила внимание периферийным вычислениям: для этой сферы предназначены новые серверы BullSequana Edge EXR и EXD в корпусах 1U и 2U соответственно. Системы рассчитаны на использование процессоров Sapphire Rapids с числом ядер не более 24 и теплопакетом, не превышающим 185 Вт. Серверы могут функционировать при температурах от 0 до +45 °C в диапазоне влажности от 5% до 95%. Предусмотрена возможность крепления на стену. 
Модельный ряд BullSequana SH При этом предусмотрена возможность установки широкого ассортимента различных ускорителей — в спецификациях упоминаются NVIDIA T4, L40, H100, A2 и A16. Опционально в состав систем может входить поддержка беспроводных сетей LTE/5G, LoRA и Wi-Fi 6, поэтому серверы отлично подойдут и для развёртывания на периферии беспроводной инфраструктуры нового поколения. 
BullSequana Edge EXD (сверху) и EXR Модель EXR располагает 2 слотами M.2, но может комплектоваться дополнительной корзиной на 6 дисков SATA или 8 NVMe-накопителей, а EXD в некоторых конфигурациях может вмещать до 8 накопителей M.2 NVMe. Обе модели комплектуются двухпортовым 10GbE-контроллером (опционально 25GbE). Все новые системы Atos на базе новых процессоров Intel Xeon обеспечивают высокую степень безопасности благодаря поддержке Atos Root of Trust и Atos Chain-of-Trust.
24.08.2022 [22:42], Владимир Мироненко
Untether AI представила ИИ-ускоритель speedAI240 — 1,5 тыс. ядер RISC-V и 238 Мбайт SRAM со скоростью 1 Пбайт/сКомпания Untether AI анонсировала ИИ-архитектуру следующего поколения speedAI (кодовое название «Boqueria»), ориентированную на инференс-нагрузки. При энергоэффективности 30 Тфлопс/Вт и производительности до 2 Пфлопс на чип speedAI устанавливает новый стандарт энергоэффективности и плотности вычислений, говорит компания.  Поскольку at-memory вычисления в ряде задач значительно энергоэффективнее традиционных архитектур, они могут обеспечить более высокую производительность при одинаковых затратах энергии. Первое поколение устройств runAI в 2020 году Untether AI достигла энергоэффективности на уровне 8 Тфлопс/Вт для INT8-вычислений. Новая архитектура speedAI обеспечивает уже 30 Тфлопс/Вт. .jpg)
Изображения: Untether AI (via ServeTheHome) 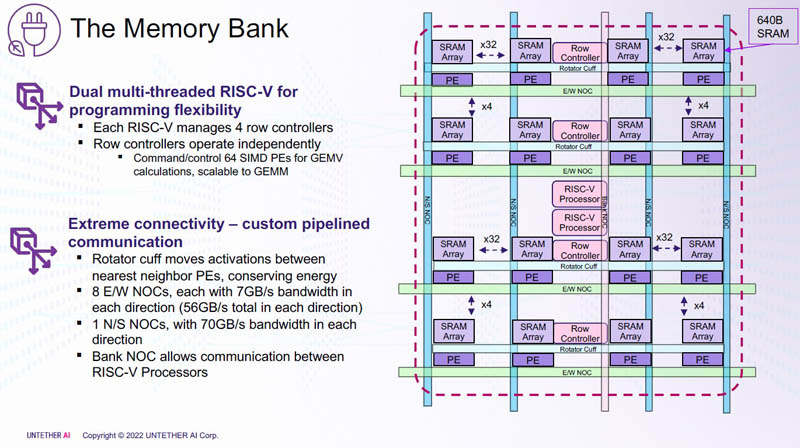 Этого удалось добиться благодаря архитектуре второго поколения, использованию более 1400 оптимизированных 7-нм ядер RISC-V (1,35 ГГц) с кастомными инструкциями, энергоэффективному управлению потоком данных и внедрению поддержки FP8. Вкупе это позволило вчетверо поднять эффективность speedAI по сравнению с runAI. Новинка может быть гибко адаптирована к различным архитектурам нейронных сетей. Концептуально speedAI напоминает ещё один тысячеядерный чип RISC-V — Esperanto ET-SoC-1. 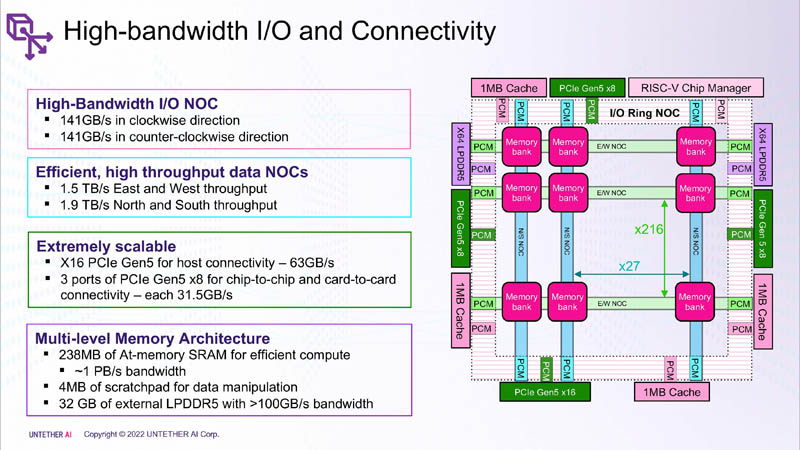 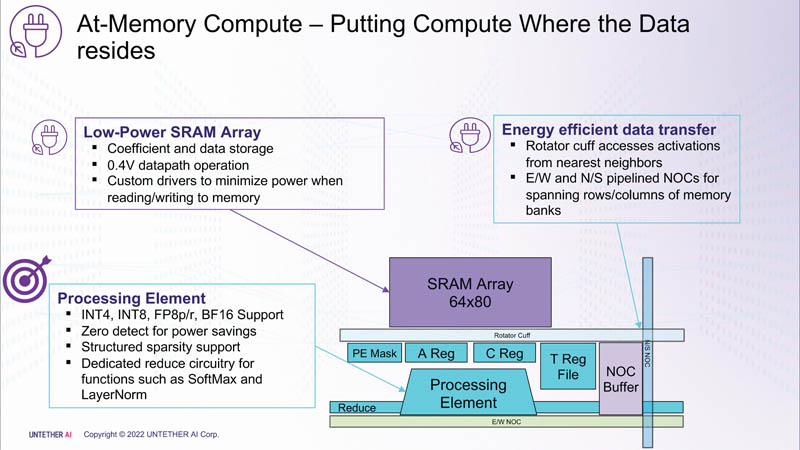 Первый член семейства speedAI — speedAI240 — обеспечивает 2 Пфлопс вычислениях в FP8-вычислениях или 1 Пфлопс для BF16-операций. Благодаря этому обеспечивается самая высокая в отрасли эффективность — например, для модели BERT заявленная производительность составляет 750 запросов в секунду на Вт (qps/w), что, по словам компании, в 15 раз выше, чем у современных GPU. Добиться повышения производительности удалось благодаря тесной интеграции вычислительных элементов и памяти.  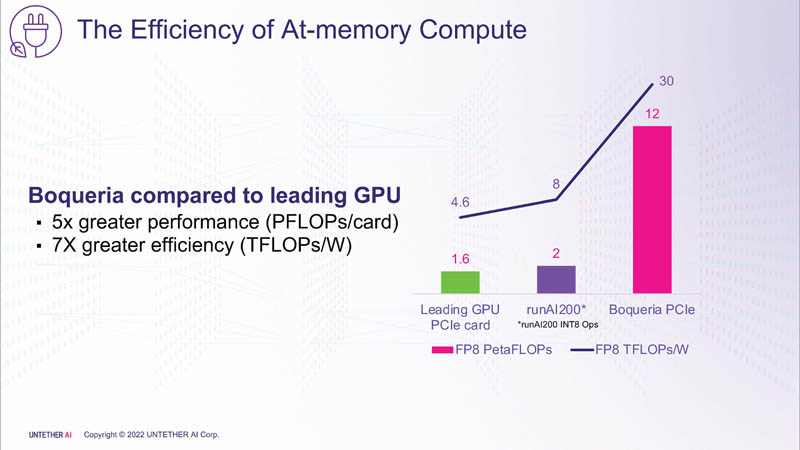 На каждый блок SRAM объёмом 328 Кбайт приходится 512 вычислительных блоков, поддерживающих работу с форматами INT4, INT8, FP8 и BF16. Каждый вычислительный блок имеет два 32-бит (RV32EMC) кастомных ядра RISC-V с поддержкой четырёх потоков и 64 SIMD. Всего есть 729 блоков, так что суммарно чип несёт 238 Мбайт SRAM и 1458 ядер. Блоки провязаны между собой mesh-сетью, к которой также подключены кольцевая IO-шина, несущая четыре 1-Мбайт блока общего кеша, два контроллера LPDRR5 (64 бит) и порты PCIe 5.0: один x16 для подключения к хосту и три x8 для объединения чипов. Суммарная пропускная способность SRAM составляет около 1 Пбайт/с, mesh-сети — от 1,5 до 1,9 Тбайт/с, IO-шины — 141 Гбайт/c в обоих направлениях, а 32 Гбайт DRAM — чуть больше 100 Гбайт/с. PCIe-интерфейсы позволяют объединить до трёх ускорителей, с шестью speedAI240 чипами у каждого. Решения speedAI будут предлагаться как в виде отдельных чипов, так и в составе готовых PCIe-карт и M.2-модулей. Ожидается, что первые поставки избранным клиентам начнутся в первой половине 2023 года. |
|

