Материалы по тегу: a100
|
07.02.2026 [17:23], Руслан Авдеев
AWS: ни один сервер с NVIDIA A100 не выведен из эксплуатации, а некоторые клиенты всё ещё используют Intel Haswell — не всем нужен ИИПо словам главы AWS Мэтта Гармана (Matt Garman), клиенты до сих пор использует серверы на основе ИИ-ускорителей NVIDIA A100, представленных в 2020 году. Отчасти это происходит потому, что спрос на вычислительные ресурсы превышает предложение, так что устаревшие чипы по-прежнему востребованы, передаёт Datacenter Dynamics. По словам Гармана, все ресурсы фактически распроданы, а серверы с A100 из эксплуатации никогда не выводились. Комментарии Гармана перекликаются с прошлогодним заявлением Амина Вахдата (Amin Vahdat), отвечающего в Google за ИИ и инфраструктуру. По его словам, в Google одновременно работают семь поколений тензорных ускорителей (TPU). Ускорители возрастом семь-восемь лет загружены на 100 %, а спрос на TPU так высок, что Google вынуждена отказывать некоторым клиентам. Впрочем, оба топ-менеджера, возможно, несколько кривят душой и пытаются развеять опасения инвесторов относительно того, что ИИ-ускорители, на которые тратятся огромные деньги, через два-три года придётся выкинуть, чтобы купить более современные, энергоэффективные и, конечно же, дорогие. И что за это время они не успеют окупиться. Хотя Гарман назвал главной причиной сохранения работы серверов на A100 высокий спрос, он признал, что есть и другие причины. В частности, современные ИИ-чипы снижают точность вычислений с плавающей запятой. В результате некоторые клиенты попросту не могут перейти на Blackwell или вовсе вынуждены использовать Intel Xeon Haswell десятилетней давности для HPC-подобных вычислений, поскольку точности у современных ИИ-ускорителей недостаточно. В июне 2025 года AWS заявила о снижении цены доступа к устаревшим NVIDIA H100, H200 и A100 на своей платформе, причём для A100 стоимость снизилась на треть. 
Источник изображения: NVIDIA Стоит отметить, что «устаревшие» ускорители долго остаются востребованными, поскольку всё равно обладают большой производительностью. Наиболее яркий пример — разрешение на поставку в Китай чипов NVIDIA H200. Хотя США и их союзники готовятся к внедрению ускорителей поколения Vera Rubin, китайский бизнес готов покупать H200, поскольку те значительно производительнее, экономически выгоднее и удобнее отечественных ускорителей.
28.08.2025 [13:03], Руслан Авдеев
Китайский бизнес переходит на подержанные ускорители NVIDIA A100 и H100 из-за проблем с поставками H20Китайская ИИ-индустрия постепенно переходит на восстановленные или подержанные ИИ-ускорители NVIDIA A100 и H100 после того, как очередные экспортные ограничения на NVIDIA H20 заставили компании искать альтернативы этому продукту. Искусственно ослабленный ускоритель H20 должен был сохранить присутствие NVIDIA на китайском рынке, но чип фактически «оказался на обочине» даже после того, как на его продажи вновь дали зелёный свет после временного запрета — китайские регуляторы поставили под сомнение его безопасность, сообщает Tom’s Hardware со ссылкой на Digitimes. Всё это привело к стремительному росту спроса на старые модели A100 и H100, китайские компании проводят некую «реконфигурацию» таких ускорителей для использования в недорогих, но высокопроизводительных системах инференса. Последний требует значительно меньше ресурсов, чем обучение ИИ-моделей, рабочие нагрузки могут эффективно выполняться на относительно слабом оборудовании. Именно поэтому даже A100 с 80 Гбайт HBM2e (2 Тбайт/с), представленный ещё в 2020 году, в некоторых случаях остаётся вполне востребованным. Хотя архитектура Ampere уступает Hopper по пиковой производительности, она всё ещё эффективна для инференса благодаря относительно большому объёму памяти и развитой экосистеме ПО CUDA. Для чат-ботов и рекомендательных систем экономически эффективно использовать системы без самых современных чипов. Представленные в 2022 году H100 значительно производительнее A100 в задачах, связанных с обучением. В то же время H20 изначально был оптимизирован для менее ресурсоёмкого инференса, но его возможности урезали так сильно, что производительность в сравнении с H100 у этой модели ниже в 3–7 раз, а в задачах, связанных с вычислениями FP64, он медленнее более чем в 30 раз. Другими словами, даже A100 всё ещё могут быть привлекательнее для китайских покупателей, чем новые H20. 
Источник изображения: NVIDIA Поскольку пока никому не удалось создать что-то сопоставимое с программной экосистемой NVIDIA CUDA, старые GPU вполне востребованы. Тем более что оборудование для инференса менее требовательно во всех отношениях, а китайские ЦОД, по-видимому, не испытывают проблем с энергий и готовы платит за восстановленную устаревшую электронику, даже с пониженной надёжностью. В результате NVIDIA оказалась в странном положении. Компания в своё время списала $5,5 млрд из-за нераспроданных запасов H20 — когда в США решили полностью запретить их поставки в Китай. После снятия запрета компания резко нарастила выпуск H20, но теперь столкнулась уже с нежеланием властей КНР видеть эти чипы в стране. Тем не менее, её ускорители по-прежнему являются одним из главных катализаторов бума ИИ в Китае. Другими словами, чипы компании по-прежнему доминируют на рынке Поднебесной, но активность на теневых рынках может снизить выгоду от бизнеса с Китаем. Впрочем, уже появилась информация о разработке нового ускорителя на основе современной архитектуры Blackwell — хотя и тоже ослабленного.
22.06.2025 [23:30], Руслан Авдеев
Meta✴ ведёт переговоры о покупке венчурного фонда NFDG, у которого есть собственный ИИ-кластер AndromedaMeta✴ Platforms решила обновить свои компетенции в сфере ИИ, наняв ведущих отраслевых игроков — Ната Фридмана (Nat Friedman) и Дэниэла Гросса (Daniel Gross). Также компания намерена выкупить их венчурный фонд NFDG, сообщает The Information. Марк Цукерберг (Mark Zuckerberg) сначала пытался купить ИИ-стартап Safe Superintelligence (SSI) бывшего «главным учёным» OpenAI Ильи Суцкевера (Ilya Sutskever). После отказа Цукерберг попросту собрался нанять генерального директора SSI — Гросса. Ранее тот руководил ИИ-разработками в Apple и был партнёром Y Combinator. Фридман был главой GitHub и советником Midjourney. Гросс и Фридман были соучредителями инвестиционного фонда NFDG. NFDG имеет доли в в известных ИИ-компаниях, включая SSI, Perplexity и Character.ai. Ранее компания инвестировала в Weights & Biases, которую приобрела CoreWeave. NFDG занимается не только финансированием компаний, но и предлагает программу грантов, в рамках которой стартапам предоставляется финансирование на $250 тыс., а также $250 тыс. в виде облачных кредитов Microsoft Azure. В период дефицита ИИ-ускорителей NFDG построил собственный суперкомпьютер. Кластер Andromeda изначально включал 2512 ускорителей NVIDIA H100. С тех пор он вырос до 3 200 H100 в 400 узлах и ещё 432 H100 в 54 узлах, связанных 400G-интерконнектом InfiniBand, а также 768 A100 с 200G InfiniBand. Теперь Andromeda могут арендовать и компании, которые не относятся к NFDG, за $2,4–$3 за ускоритель в час. Сейчас можно арендовать до 2 тыс. H100 и получить доступ к ним в течение нескольких часов. 
Источник изображения: Amina Atar/unspalsh.com Помимо возможного найма Гросса и Фридмана, Meta✴ ведёт переговоры, конечной целью которых является выкуп значительной части активов NFDG и вывод из него партнёров за сумму более $1 млрд. При этом сделка не даст Meta✴ контроля над фондом или информации о бизнесе. Кому достанется Andromeda, не уточняется. Если сделка будет завершена, она войдёт в число более масштабных реформ в Meta✴, связанных с ИИ. Цукерберг планирует сформировать новую лабораторию по разработке «суперинтеллекта» и пересмотреть стратегию выкупа продуктов. В этом месяце Meta✴ уже подтвердила, что намерена потратить порядка $14 млрд на долю в Scale AI, специализирующейся на разметке данных для обучения ИИ.
11.06.2025 [09:11], Владимир Мироненко
AWS резко снизила стоимость EC2-инстансов с ускорителями NVIDIA, но только для старых моделейAWS объявила об очередном снижении тарифов на GPU-инстансы, которое, по словам компании, стало регулярной практикой благодаря активной работе над снижением расходов. Впрочем, в период острого дефицита вычислительных мощностей в последние год-два, когда использование ускорителей даже для внутренних нужд было резко ограничено, компания наверняка заработала достаточно, чтобы неоднократно окупить закупку и обслуживание соответствующего «железа». На прошлой неделе была снижена до 45 % стоимость использования инстансов EC2 на базе ускорителей NVIDIA, включая семейства P4 (P4d и P4de на базе A100) и P5 (P5 и P5en на базе H100 и H200 соответственно). Снижение стоимости тарифов On-Demand и Savings Plan распространяется на все регионы, где доступны эти инстансы. На On-Demand — с 1 июня, на Savings Plan — после 4 июня. Savings Plans предлагает гибкую модель ценообразования с низкими ценами на использование вычислений в обмен на обязательство по постоянному объёму использования (измеряется в $/час) в течение 1 года или 3 лет. AWS предлагает два типа Savings Plans:
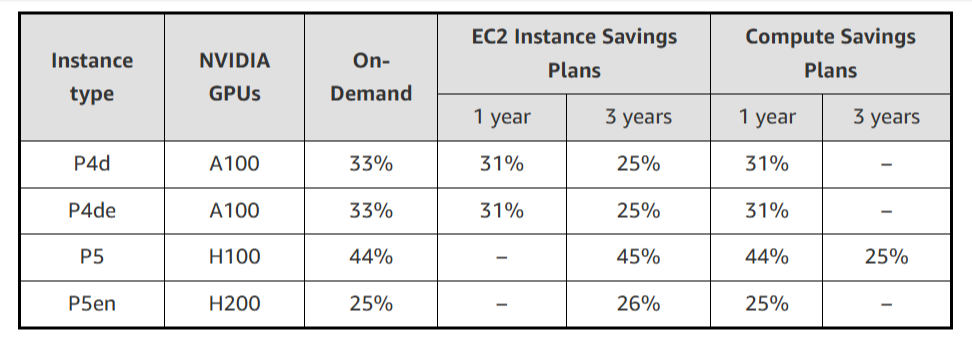
Источник изображения: AWS Чтобы обеспечить повышенную доступность по сниженным ценам, AWS предоставляет масштабируемую ёмкость в рамках тарифа On-Demand для:
Также теперь AWS предлагает инстансы Amazon EC2 P6-B200 в рамках тарифа Savings Plan для поддержки крупномасштабных развёртываний, которые стали доступны 15 мая 2025 года при запуске только через EC2 Capacity Blocks для машинного обучения. Инстансы EC2 P6-B200 на базе ускорителей NVIDIA Blackwell обеспечивают обработку широкого спектра рабочих нагрузок, но особенно хорошо подходят для крупномасштабного распределённого обучения и ИИ-инференса, отметила AWS.
29.11.2024 [10:22], Владимир Мироненко
«РТК-ЦОД» запустил в работу обновленный сервис BareMetal 2.0 с ускорителями NVIDIAСервис-провайдер «РТК-ЦОД» (дочерняя компания «Ростелекома», предоставляющая услуги дата-центров и облачные услуги) объявил о запуске обновлённого сервиса BareMetal 2.0 с GPU-ускорителями. Как сообщает «РТК-ЦОД», сервис BareMetal 2.0 обеспечивает максимально эффективное использование вычислительных ресурсов, в том числе, с помощью интеграции физических серверов в единую сеть с виртуальной облачной инфраструктурой. Это дает возможность выстраивать гибридные IaaS-решения для повышения производительности и масштабируемости. По словам компании, обновлённый сервис идеально подходит для задач, требующих максимальной производительности: от анализа данных и машинного обучения до научных исследований и обработки графики. Согласно пресс-релизу, работу BareMetal 2.0 обеспечивают выделенные серверы без виртуализации, предоставляемые в составе «Публичного облака». Доступные конфигурации включают процессоры с частотой 2,6 и 3,0 ГГц, поддержку до 48 ядер и объём оперативной памяти до 1024 Гбайт с возможностью использования высокоскоростных сетевых SSD для хранения данных. В обновлённом сервисе для работы с графикой, 3D-моделированием, рендерингом, интенсивными вычислительными задачами можно выбрать сервер с ускорителями NVIDIA L4 (24 Гбайт), RTX A6000 (48 Гбайт) или A100 (80 Гбайт). 
Источник изображения: «РТК-ЦОД» Клиентам доступен выделенный менеджер и команда архитекторов, которые помогут адаптировать решение под индивидуальные задачи. BareMetal 2.0 и другие облачные сервисы РТК-ЦОД можно самостоятельно настроить через единый портал, а также использовать инструменты для удалённого управления.
28.09.2024 [23:24], Сергей Карасёв
Индия запустила сразу пять суперкомпьютеров за два дня
a100
amd
atos
cascade lake-sp
epyc
eviden
hardware
hpc
intel
milan
nvidia
xeon
индия
метео
суперкомпьютер
Премьер-министр Индии Нарендра Моди, по сообщению The Register, объявил о вводе в эксплуатацию трёх новых высокопроизводительных вычислительных комплексов PARAM Rudra. Запуск этих суперкомпьютеров, как отмечается, является «символом экономической, социальной и промышленной политики» страны. Вдаваться в подробности о технических характеристиках машин Моди во время презентации не стал. Однако некоторую информацию раскрыли организации, которые займутся непосредственной эксплуатацией этих НРС-систем. Один из суперкомпьютеров располагается в Национальном центре радиоастрофизики Индии (NCRA). Данная машина оснащена «несколькими тысячами процессоров Intel» и 90 ускорителями NVIDIA A100, 35 Тбайт памяти и хранилищем вместимостью 2 Пбайт. Ещё один НРС-комплекс смонтирован в Центре фундаментальных наук имени С. Н. Бозе (SNBNCBS): известно, что он обладает быстродействием 838 Тфлопс. Оператором третьей системы является Межуниверситетский центр ускоренных вычислений (IUAC): этот суперкомпьютер с производительностью на уровне 3 Пфлопс использует 24-ядерные чипы Intel Xeon Cascade Lake-SP. Ёмкость хранилища составляет 4 Пбайт. Упомянут интерконнект с пропускной способностью 240 Гбит/с. The Register отмечает, что указанные характеристики в целом соответствуют описанию суперкомпьютеров Rudra первого поколения. Согласно имеющейся документации, такие машины используют:
Ожидается, что машины Rudra второго поколения получат поддержку процессоров Xeon Sapphire Rapids и четырёх GPU-ускорителей. Суперкомпьютеры третьего поколения будут использовать 96-ядерные Arm-процессоры AUM, разработанные индийским Центром развития передовых вычислений: эти изделия будут изготавливаться по 5-нм технологии TSMC. 
Источник изображения: pixabay.com Между тем компания Eviden (дочерняя структура Atos) сообщила о поставках в Индию двух новых суперкомпьютеров. Один из них установлен в Индийском институте тропической метеорологии (IITM) в Пуне, второй — в Национальном центре среднесрочного прогнозирования погоды (NCMRWF) в Нойде. Эти системы, построенные на платформе BullSequana XH2000, предназначены для исследования погоды и климата. В создании комплексов приняли участие AMD, NVIDIA и DDN. Система IITM, получившая название ARKA, обладает быстродействием 11,77 Пфлопс: 3021 узел с AMD EPYC 7643 (Milan), 26 узлов с NVIDIA A100, NVIDIA Quantum InfiniBand и хранилище на 33 Пбайт (ранее говорилось о 3 Пбайт SSD + 29 Пбайт HDD). В свою очередь, суперкомпьютер NCMRWF под названием Arunika обладает производительностью 8,24 Пфлопс: 2115 узлов с AMD EPYC 7643 (Milan), NVIDIA Quantum InfiniBand и хранилище DDN EXAScaler ES400NVX2 (2 Пбайт SSD + 22 Пбайт HDD). Кроме того, эта система включает выделенный блок для приложений ИИ и машинного обучения с быстродействием 1,9 Пфлопс (точность не указана), состоящий из 18 узлов с NVIDIA A100.
17.09.2024 [23:07], Игорь Осколков
Швейцария ввела в эксплуатацию гибридный суперкомпьютер Alps: 11 тыс. NVIDIA GH200, 2 тыс. AMD EPYC Rome и щепотка A100, MI250X и MI300AШвейцарская высшая техническая школа Цюриха (ETH Zurich) провела церемонию официального запуска суперкомпьютера Alps в Швейцарском национальном суперкомпьютерном центре (CSCS) в Лугано. Система, построенная HPE, уже заняла шестую строчку в последнем рейтинге TOP500 и имеет устоявшеюся FP64-производительность 270 Пфлопс (теоретический пик — 354 Пфлопс). К ноябрю будут введены в строй остальные модули машины, и её максимальная производительность составит порядка 500 Пфлопс. 
Источник изображений: CSCS В июньском рейтинге TOP500 участвовал раздел из 2688 узлов HPE Cray EX254n с «фантастической четвёркой» NVIDIA Quad GH200. Если точнее, это всё же «старый» вариант ускорителя с H100 (96 Гбайт HBM3), 72-ядерным Arm-процессором Grace и 128 Гбайт LPDDR5x — суммарно 10 752 Grace Hopper. Данный раздел потребляет 5,2 МВт и в Green500 находится на 14 месте. Узлы, конечно же, используют СЖО. Это основной, но не единственный раздел суперкомпьютера. Ещё в 2020 году HPE развернула 1024 двухпроцессорных узла с 64-ядерными AMD EPYC 7742 (Rome) и 256/512 Гбайт RAM. Его производительность составляет 4,7 Пфлопс. Кроме того, в состав Alps входят 144 узла с одним 64-ядерным AMD EPYC, 128 Гбайт RAM и четырьмя NVIDIA A100 (80 или 96 Гбайт HBM2e).  Наконец, машина получит 24 узла с одним 64-ядерным AMD EPYC, 128 Гбайт RAM и четырьмя AMD Instinct MI250X (128 Гбайт HBM2e) и 128 узлов с четырьмя гибридными ускорителями AMD Instinct MI300A. Большая часть узлов будет объединена интерконнектом HPE Slingshot-11: 200G-подключение на узел или ускоритель. Более точную конфигурацию системы раскроют в ноябре. Lustre-хранилище для будущей машины обновили ещё в прошлом году. Основной СХД является Cray ClusterStor E1000 с подключением Slingshot-11. Так, было добавлено 100 Пбайт полезной HDD-ёмкости (8480 × 16 Тбайт) с пропускной способностью 1 Тбайт/с (300 тыс. IOPS на запись, 1,5 млн IOPS на чтение) и 5 Пбайт SSD, а также резервные ёмкости. За архивное хранение отвечают две ленточные библиотеки объёмом 130 Пбайт каждая.  Особенностью системы является её геораспределённость (фактически узлы размещены в четырёх местах) и облачная модель использования. Так, метеослужба страны MeteoSwiss получила в своё распоряжение выделенный виртуальный кластер, что уже позволило перейти на использование метеомодели более высокого разрешения, которая лучше отражает сложный рельеф Швейцарии. Кроме того, для подстраховки часть узлов Alps размещена на территории Федеральной политехнической школы Лозанны (EPFL). Alps приходит на смену суперкомпьютеру Piz Daint (Cray XC50/40, 21,2 Пфлопс), о завершении жизненного цикла которого было объявлено в конце июля 2024 года. В CSCS пока останутся машины Arolla + Tsa (для нужд MeteoSwiss) и Blue Brain 5 (решает задачи реконструкции и симуляции мозга). Alps же помимо традиционных HPC-нагрузок, будет использоваться для разработки ИИ-решений.
13.09.2024 [00:17], Владимир Мироненко
Производительность суперкомпьютера «Сергей Годунов» выросла вдвое — до 114,67 Тфлопс
a100
hardware
hpc
ice lake-sp
intel
nvidia
rtx
xeon
новосибирск
россия
рск
сделано в россии
суперкомпьютер
Группа компаний РСК сообщила о завершении плановой модернизации суперкомпьютера «Сергей Годунов» в Институте математики имени С.Л. Соболева Сибирского отделения Российской академии наук (ИМ СО РАН), благодаря чему его суммарная пиковая FP64-производительность теперь составляет 114,67 Тфлопс: 75,87 Тфлопс на CPU и 38,8 Тфлопс на GPU. 
Источник изображений: РСК Работы по запуску машины были завершены РСК в ноябре 2023 года, а её официальное открытие состоялось в феврале этого года. На тот момент производительность суперкомпьютера составляла 54,4 Тфлопс. Директор ИМ СО РАН Андрей Евгеньевич Миронов отметил, что использование нового суперкомпьютера позволило существенно повысить эффективность научных исследований, и выразил уверенность, что он также будет способствовать развитию новых технологий. Миронов сообщил, что после запуска суперкомпьютера появилась возможность решать мультидисциплинарные задачи, моделировать объёмные процессы и предсказывать поведение сложных математических систем. По его словам, на суперкомпьютере проводятся вычисления по критически важным проблемам и задачам, среди которых:

Источник изображений: РСК Суперкомпьютер «Сергей Годунов» является основным инструментом для проведения исследований и прикладных разработок в Академгородке Новосибирска и создания технологической платформы под эгидой Научного совета Отделения математических наук РАН по математическому моделированию распространения эпидемий с учётом социальных, экономических и экологических процессов. Он был назван в память об известном советском и российском математике с мировым именем Сергее Константиновиче Годунове. Отечественный суперкомпьютер создан на базе высокоплотной и энергоэффективной платформы «РСК Торнадо» с жидкостным охлаждением. Система включает вычислительные узлы с двумя Intel Xeon Ice Lake-SP, узел на базе четырёх ускорителей NVIDIA A100 и сервер визуализации с большим объёмом памяти: Intel Xeon Platinum 8368, 4 Тбайт RAM, пара NVIDIA RTX 5000 Ada с 32 Гбайт GDDR6.
09.11.2022 [14:50], Владимир Мироненко
Производители специально ухудшают характеристики чипов для китайских серверов, чтобы избежать санкций СШАВ связи с вводом Соединёнными Штатами новых экспортных ограничений на поставки в Китай, производители стали намеренно снижать производительность чипов, чтобы соответствовать требованиям экспортного контроля США и избежать проблем с получением специальных лицензий. Как отметил ресурс The Register, у систем, построенных на чипах NVIDIA, изготовленных на производственных мощностях TSMC для поставок в Китай, характеристики хуже по сравнению с теми, что были ранее. В частности, китайский производитель серверов Inspur указал на использование вместо ускорителя NVIDIA A100 чипа A800, разработанного NVIDIA специально для Китая в соответствии с экспортными ограничениями. Китайские производители H3C и Omnisky тоже представили решения на базе A800. Данный ускоритель, по словам NVIDIA, начала производиться в III квартале этого года. У A800 скорость передачи данных составляет 400 Гбайт/с, тогда как у A100 этот показатель равен 600 Гбайт/с, причём обойти эти ограничения, по словам NVIDIA, невозможно. Речь, судя по всему, идёт о характеристиках интерконнекта NVLink, которые прямо влияют на производительность кластеров из двух и более ускорителей в машинном обучении и других задачах. Изменения касаются 40- и 80-Гбайт вариантов с интерфейсами PCIe и SXM. 
Источник изображения: Inspur Между тем ускорители, находящиеся в разработке и выпускаемые TSMC по контракту с Alibaba и стартапом Biren Technology, тоже, как сообщается, имеют пониженную скорость передачи данных. Это позволит выпускать данные чипы на заводе TSMC, не опасаясь санкций США. До этого TSMC приостановила выпуск 7-нм чипов ускорителей Biren BR100 как раз из-за возможных санкций со стороны Вашингтона.
10.08.2022 [22:05], Владимир Мироненко
На пути к Aurora: запущен «тренировочный» суперкомпьютер PolarisАргоннская национальная лаборатория (ANL) Министерства энергетики США объявила о доступности суперкомпьютера Polaris, ранний вариант которого занял 14-е место в последней версии списка TOP500. Он будет использоваться для проведения научных исследований и в качестве испытательного стенда для 2-Эфлопс суперкомпьютера Aurora, запуск которой намечен на ближайшие месяцы. Правда, аппаратно Aurora и Polaris отличаются. Созданная HPE система Polaris состоит из 560 узлов Apollo 6500, каждый из которых оснащён процессором AMD EPYC Milan, четырьмя ускорителями NVIDIA A100 (40 Гбайт) и 512 Гбайт DDR4-памяти. Эти узлы объединены в сеть интерконнектом HPE Slingshot 10 (осенью он будет обновлен до Slingshot 11) и подключены к сдвоенному 100-Пбайт Lustre-хранилищу (Grand и Eagle). Заявленная пиковая производительность должна составить 44 Пфлопс. «Polaris примерно в четыре раза быстрее нашего суперкомпьютера Theta, что делает его самым мощным компьютером в Аргонне на сегодняшний день», — отметил Майкл Папка (Michael Papka), директор Argonne Leadership Computing Facility (ALCF). Он добавил, что возможности Polaris позволят пользователям выполнять моделирование, анализ данных и ИИ-задачи с такими масштабом и скоростью, которые были невозможны с предыдущими вычислительными системами. 
Фото: ANL Помимо работы над подготовкой к запуску Aurora, суперкомпьютер Polaris будет обслуживать внутренние потребности лаборатории, например, работу с комплексом Advanced Photon Source (APS) X-ray. «Благодаря тесной интеграции суперкомпьютеров ALCF с APS, CNM и другими экспериментальными установками мы можем помочь ускорить проведение анализа данных и предоставить информацию, которая позволит исследователям управлять своими экспериментами в режиме реального времени», — заявил Майкл Папка. |
|

