Материалы по тегу: l4
|
13.01.2026 [09:03], Руслан Авдеев
Lenovo представила серверы для ИИ-инференса: ThinkSystem SR675i V3/SR650i V4 и ThinkEdge ThinkEdge SE455i V4Lenovo представила новые серверные системы серии Lenovo Hybrid AI Advantage, оптимизированные для ИИ-инференса: ThinkSystem SR675i V3, ThinkSystem SR650i V4 и ThinkEdge SE455i V4. Если ранее акцент делался на решениях для обучения всё более производительных ИИ-моделей, то теперь бизнес обращает всё больше внимания на продукты для инференса. Новинки предлагаются параллельно с ПО для оптимизации инференса — для унификации и получения данных из разных источников для использования ИИ-моделями. 
Источник изображений: Lenovo Флагманской версией серии является ThinkSystem SR675i V3 в исполнении 3U на платформе AMD EPYC Turin 9535 (64C/128T, 2,4 ГГц, TDP 300 Вт). Сервер получил 1,5 Тбайт DDR5-6400 (24 × 64 Гбайт). За хранение данных отвечают до двух E3.S NVMe SSD по 3,84 Тбайт (PCIe 5.0 x4) и до двух M.2 NVMe SSD по 960 Гбайт (PCIe 4.0 x4). Возможна установка восьми ускорителей NVIDIA RTX PRO 6000 Blackwell Server Edition, а также пяти DPU NVIDIA BlueField-3 (4 × 400G, 1 × 200G). IPMI в данной модели не доступен. Для карт расширения доступно до шести слотов PCIe 5.0 х16 и один слот OCP 3.0 x8/x16. За питание отвечают четыре блока Titanium второго поколения (по 2300 Вт), а за охлаждение — пять вентиляторов.  ThinkSystem SR650i V4 позиционируется в качестве системы для инференса и корпоративных рабочих нагрузок. Этот 2U-сервер получил два Intel Xeon Granite Rapids-SP 6530P (32C/64T, 2,3 ГГц, TDP 225 Вт), 512 Гбайт DDR5-6400 (8 × 64 Гбайт), два ускорителя RTX PRO 6000 Blackwell Server Edition. За хранение отвечают два 3,84-Тбайт U.2 NVMe SSD (PCIe 5.0 x4), хотя всего таких слотов восемь, а также RAID1-массив из пары 960-Гбайт M.2 SATA SSD. Всего доступно шесть слотов расширения PCIe 5.0 x16 и два слота OCP 3.0 x8/x16. Имеется двухпортовый 25GbE-адаптер Broadcom 57414 (SFP28). За питание отвечают два Titanium-блока мощностью 2700 Вт каждый, а за охлаждение шесть вентиляторов, но есть и опция установки фирменной СЖО Neptune.  Наконец, Lenovo ThinkEdge SE455i V3 (2U) глубиной всего 440 мм представляет собой компактную модель, предназначенную для периферийного инференса — в ретейле, телекоммуникациях и промышленности. Сервер имеет защищённую конструкцию и может работать при температурах от -5 до +40 °C. Сервер построен на базе одного процессора AMD EPYC Embedded 8534P (64C/128T, 2,3 ГГц, TDP 200 Вт), дополненного 576 Гбайт DDR5-4800 (6 × 96 Гбайт) и двумя ускорителями NVIDIA L4 24 Гбайт (PCIe 4.0 x16). В комплекте идёт один 3,84-Тбайт NVMe SSD и один 960-Гбайт SATA SSD. Имеется два блока питания Platinum второго поколения с возможностью горячей замены. Для карт расширения есть до двух слотов PCIe 5.0 x16 и до четырёх слотов PCIe 4.0 x8, а также один слот OCP 3.0 (PCIe 5.0 x16). Установлен двухпортовый OCP-адаптер Broadcom 57416 (10GbE). IPMI отключён.  Фактически компания предлагает готовые конфигурации, которые можно переконфигурировать лишь слегка, чаще всего добавив накопители и/или сетевые адаптеры. Платформы будут доступны в рамках подписки TruScale. Также компания анонсировала новые сервисы Hybrid AI Factory Services, в том числе консультации по инференсу, которые помогают развёртывать оборудование и управлять им для оптимизации ИИ-производительности.
20.12.2024 [12:50], Сергей Карасёв
Провайдер mClouds запустил облачную GPU-платформу с чипами AMD EPYC Genoa и ускорителями NVIDIAРоссийский облачный провайдер mClouds объявил о запуске новой платформы на базе GPU для решения ресурсоёмких задач, таких как проектирование в BIM и CAD, рендеринг и обработка видео, машинное обучение, работа с нейросетями и пр. В основу платформы положены процессоры AMD EPYC 9374F поколения Genoa. Эти чипы насчитывают 32 ядра (64 потока инструкций) с тактовой частотой 3,85 ГГц и возможностью повышения до 4,1 ГГц. Стандартный показатель TDP равен 320 Вт. Доступны три базовые конфигурации облачной GPU-платформы: с ускорителями NVIDIA A16 (64 Гбайт памяти) для задач BIM и CAD, NVIDIA L40S (48 Гбайт) для сложных вычислений и рендеринга, а также с NVIDIA L4 (24 Гбайт) для нейросетевого обучения и аналитики. При этом можно добавлять необходимые ресурсы — vCPU, RAM и SSD. Доступны также средства резервного копирования и антивирусная защита Kaspersky Endpoint Security. Провайдер mClouds предлагает гибкие варианты конфигурирования под собственные нужды. Платформа размещена в аттестованном московском дата-центре NORD4 уровня Tier III Gold. Доступность сервиса заявлена на отметке 99,9998 % (по итогам 2023 года), а время реагирования на инциденты составляет менее 15 минут. В тарифы при аренде мощностей на базе GPU входят защита от DDoS-атак, каналы связи с пропускной способностью до 120 Мбит/с на каждый сервер, ОС Windows Server или Linux. 
Источник изображения: mClouds «Наша платформа на базе AMD EPYC и NVIDIA выводит вычислительные возможности клиентов на совершенно новый уровень. Мы предоставляем клиентам не просто облачные ресурсы, а инструмент, который поможет им оставаться конкурентоспособными в условиях цифровой трансформации и ускорения внедрения ИИ в бизнесе», — говорит Александр Иванников, директор по развитию провайдера облачной инфраструктуры mClouds.
29.11.2024 [10:22], Владимир Мироненко
«РТК-ЦОД» запустил в работу обновленный сервис BareMetal 2.0 с ускорителями NVIDIAСервис-провайдер «РТК-ЦОД» (дочерняя компания «Ростелекома», предоставляющая услуги дата-центров и облачные услуги) объявил о запуске обновлённого сервиса BareMetal 2.0 с GPU-ускорителями. Как сообщает «РТК-ЦОД», сервис BareMetal 2.0 обеспечивает максимально эффективное использование вычислительных ресурсов, в том числе, с помощью интеграции физических серверов в единую сеть с виртуальной облачной инфраструктурой. Это дает возможность выстраивать гибридные IaaS-решения для повышения производительности и масштабируемости. По словам компании, обновлённый сервис идеально подходит для задач, требующих максимальной производительности: от анализа данных и машинного обучения до научных исследований и обработки графики. Согласно пресс-релизу, работу BareMetal 2.0 обеспечивают выделенные серверы без виртуализации, предоставляемые в составе «Публичного облака». Доступные конфигурации включают процессоры с частотой 2,6 и 3,0 ГГц, поддержку до 48 ядер и объём оперативной памяти до 1024 Гбайт с возможностью использования высокоскоростных сетевых SSD для хранения данных. В обновлённом сервисе для работы с графикой, 3D-моделированием, рендерингом, интенсивными вычислительными задачами можно выбрать сервер с ускорителями NVIDIA L4 (24 Гбайт), RTX A6000 (48 Гбайт) или A100 (80 Гбайт). 
Источник изображения: «РТК-ЦОД» Клиентам доступен выделенный менеджер и команда архитекторов, которые помогут адаптировать решение под индивидуальные задачи. BareMetal 2.0 и другие облачные сервисы РТК-ЦОД можно самостоятельно настроить через единый портал, а также использовать инструменты для удалённого управления.
21.03.2023 [19:45], Игорь Осколков
Толстый и тонкий: NVIDIA представила самый маленький и самый большой ИИ-ускорители L4 и H100 NVLНа весенней конференции GTC 2023 компания NVIDIA представила два новых ИИ-ускорителя, ориентированных на инференес: неприличной большой H100 NVL, фактически являющийся парой обновлённых ускорителей H100 в формате PCIe-карты, и крошечный L4, идущий на смену T4. 
Изображения: NVIDIA NVIDIA H100 NVL действительно выглядит как пара H100, соединённых мостиками NVLink. Более того, с точки зрения ОС они выглядят как пара независимых ускорителей, однако ПО воспринимает их как единое целое, а обмен данными между двумя картам идёт в первую очередь по мостикам NVLink (600 Гбайт/с). Новинка создана в первую очередь для исполнения больших языковых ИИ-моделей, в том числе семейства GPT, а не для их обучения. 
NVIDIA H100 NVL Однако аппаратно это всё же не просто пара обычных H100 PCIe. По уровню заявленной производительности NVL-вариант вдвое быстрее одиночного ускорителя H100 SXM, а не PCIe — 3958 и 7916 Тфлопс в разреженных (в обычных показатели вдвое меньше) FP16- и FP8-вычислениях на тензорных ядрах соответственно, что в 2,6 раз больше, чем у H100 PCIe. Кроме того, NVL-вариант получил сразу 188 Гбайт HBM3-памяти с суммарной пропускной способностью 7,8 Тбайт/с. 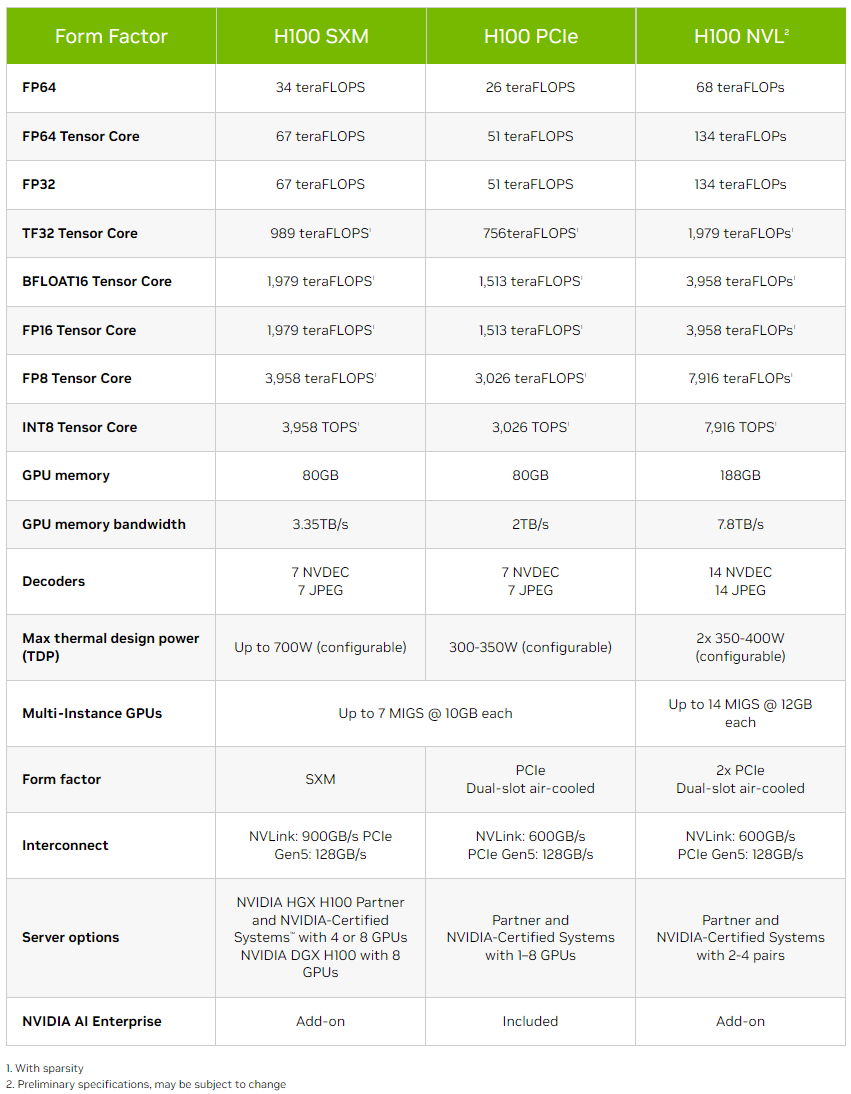 NVIDIA утверждает, что форм-фактор H100 NVL позволит задействовать новинку большему числу пользователей, хотя четыре слота и TDP до 800 Вт подойдут далеко не каждой платформе. NVIDIA H100 NVL станет доступна во второй половине текущего года. А вот ещё одну новинку, NVIDIA L4 на базе Ada, в ближайшее время можно будет опробовать в облаке Google Cloud Platform, которое первым получило этот ускоритель. Кроме того, он же будет доступен в рамках платформы NVIDIA Launchpad, да и ключевые OEM-производители тоже взяли его на вооружение. 
NVIDIA L4 Сама NVIDIA называет L4 поистине универсальным серверным ускорителем начального уровня. Он вчетверо производительнее NVIDIA T4 с точки зрения графики и в 2,7 раз — с точки зрения инференса. Маркетинговые упражнения компании при сравнении L4 с CPU оставим в стороне, но отметим, что новинка получила новые аппаратные ускорители (де-)кодирования видео и возможность обработки 130 AV1-потоков 720p30 для мобильных устройств. С L4 возможны различные сценарии обработки видео, включая замену фона, AR/VR, транскрипцию аудио и т.д. При этом ускорителю не требуется дополнительное питание, а сам он выполнен в виде HHHL-карты. 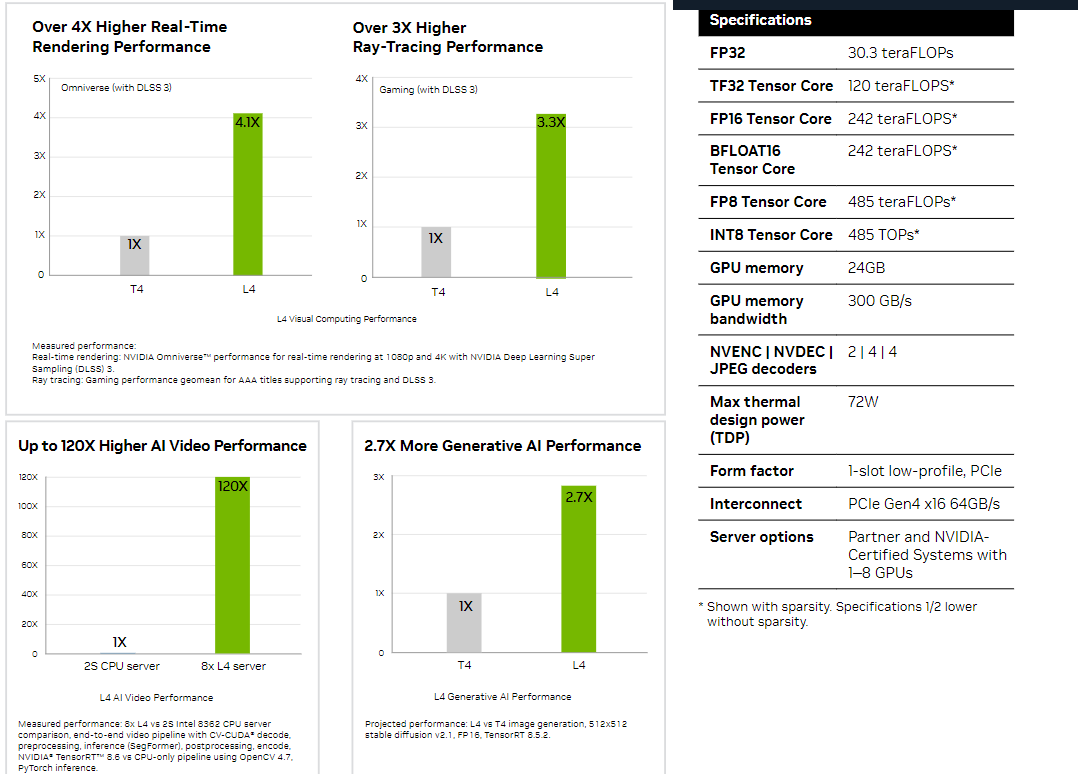 |
|

