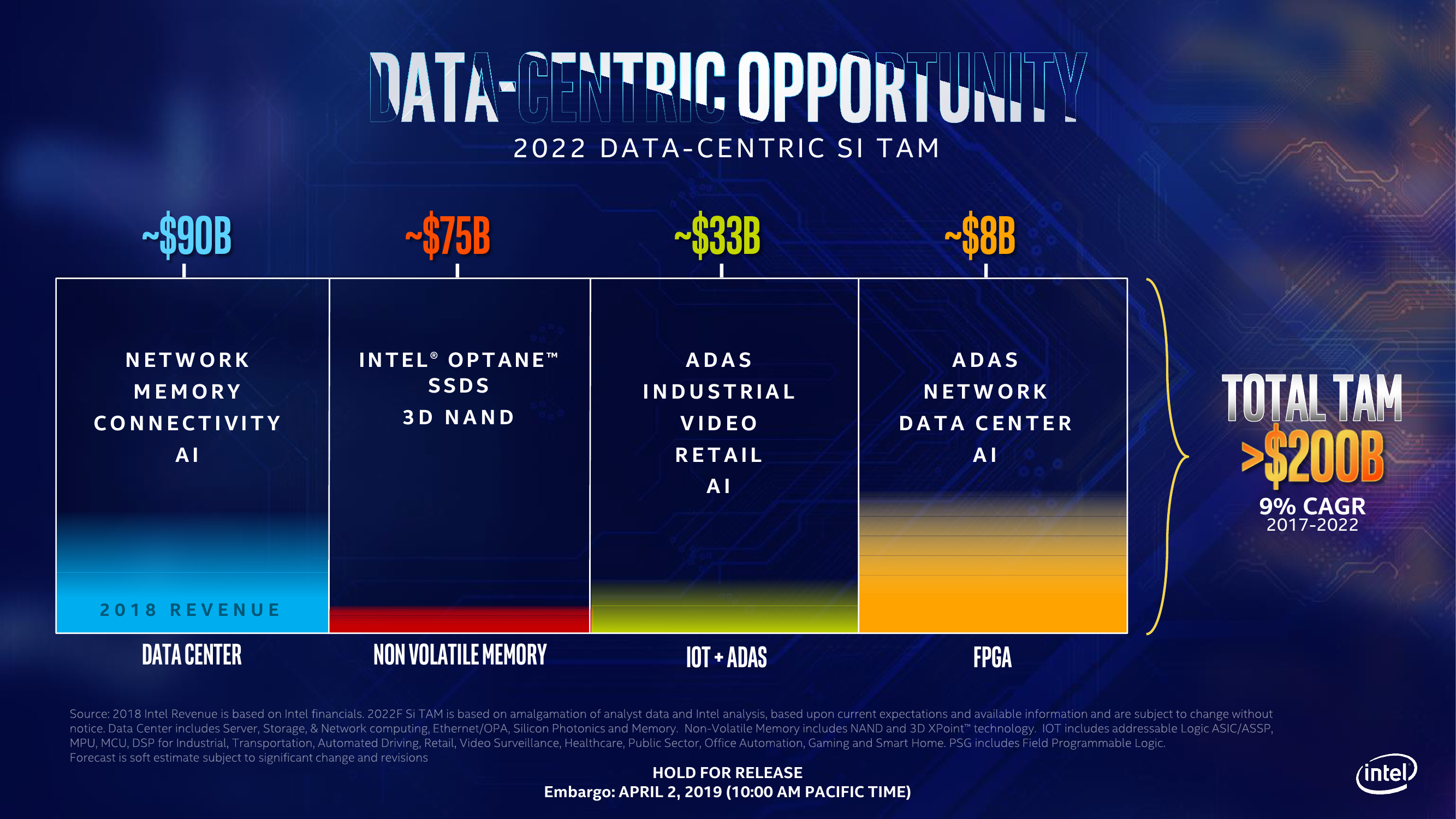
Строго говоря, речь идёт не только и не столько об обновлении серверных процессоров, сколько о большом и важном для самой компании запуске целой плеяды разнородных продуктов, так или иначе связанных с дата-центрами. Кусочки этого пазла проявляются то тут, то там. Глобально всё это обновление укладывается в общую стратегию Intel по выстраиванию единой платформы, охватывающей и пронизывающей по возможности всю современную электронику и её применения в реальной жизни: от сенсоров интернете вещей и беспилотников до собственно дата-центров. Отдельно останавливаться на этом не будем, но общий посыл и так понятен: данных в мире много и будет ещё больше, данные эти надо обрабатывать и извлекать из них пользу. И чем быстрее, тем лучше. Применительно к дата-центрам, корпоративным и промышленным системам всё это сводится к трём основным столпам: быстрой передаче данных, большому объёму хранения и высокой скорости обработки.
 |
 |
 |
|
 |
 |
 |
 |
| Кликните по изображению продукта для перехода в соответствующий раздел/материал | |||
Вы находитесь здесь
Для общего понимания надо уточнить несколько моментов. Процессоры Cascade Lake SP, как и их предшественники Skylake, всё так же относятся к платформе Purley, теперь уже второго поколения — Purley Refresh. Они полностью совместимы со Skylake на уровне разъёма, чипсетов и имеющихся материнских плат. О нюансах подобного апгрейда в некоторых конфигурациях, не связанных, правда, с самой Intel, мы поговорим чуть ниже. Cascade Lake AP, хоть и являются «удвоенными» версиями SP, относятся к платформе Walker Pass. Оба варианты — SP и AP — представлены вот только что, как и Xeon D 1600 с платформой Grangeville. Про Intel Atom C поколения Snow Ridge, которые можно считать своего рода Xeon D «для самых маленьких», говорили ещё в январе.

Intel Xeon Cascade Lake SP
Дальше чуть сложнее. Параллельно идёт работа над двумя новыми сериями процессоров и двумя платформами, которые появятся не раньше 2020 года. Cooper Lake SP можно условно считать развитием Skylake и Cascade Lake, а вот Ice Lake SP будут уже другими. На уровне платформ нас ждут Whitley, которая будет совместима с обеими сериями новых CPU, и Cedar Island — только для Cooper Lake. Xeon D впоследствии тоже перейдёт на ядра Ice Lake. Впрочем, все названия и планы пока носят предварительный характер. Для Xeon E относительно скоро стоит ждать небольшое обновление в связи с переходом на Coffee Lake-E Refresh, а прямо сейчас доступна карта PCI-E SGX card — ускоритель на базе трёх Xeon E, наследник VCA. В 2019 году также должны наконец выйти ИИ-ускорители Nervana Spring Crest и Spring Hill.
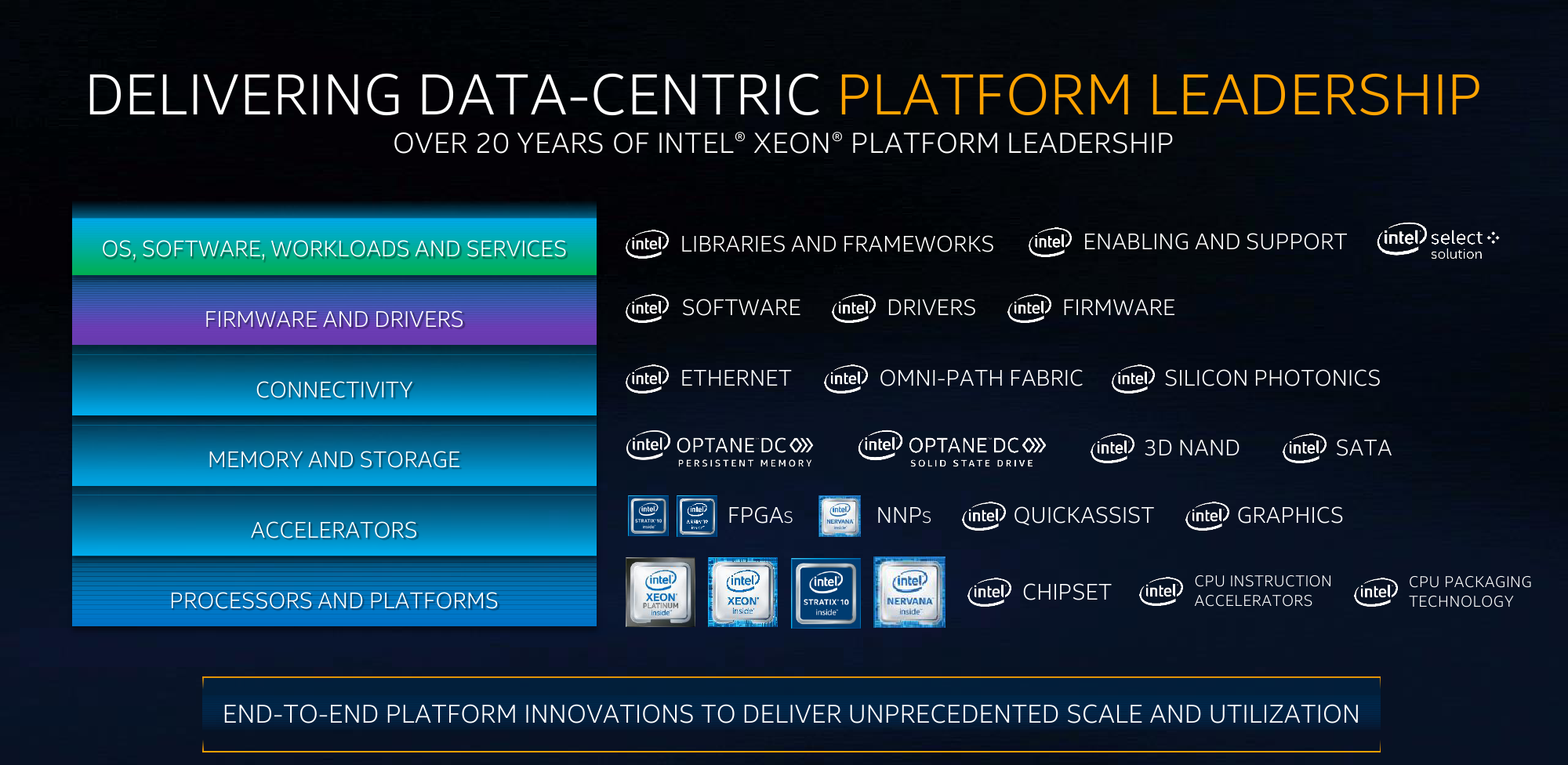
FPGA Intel Agilex представлены сейчас, равно как и 100GbE-продукты Columbiaville. Позже появятся и другие сетевые продукты, а также новое поколение Intel Omni Path. Наконец, через пару лет стоит ждать и GPU (хотя скорее уже просто ускорители) Arctic Sound для ЦОД.
Вот теперь с этим багажом знаний мы и попытается взлететь. В данном материале коснёмся лишь некоторых обновлений: процессоров Cascade Lake SP и AP, их технологий и памяти Intel Optane DC Persistent Memory.

Памяти много не бывает
Intel Xeon Cascade Lake SP
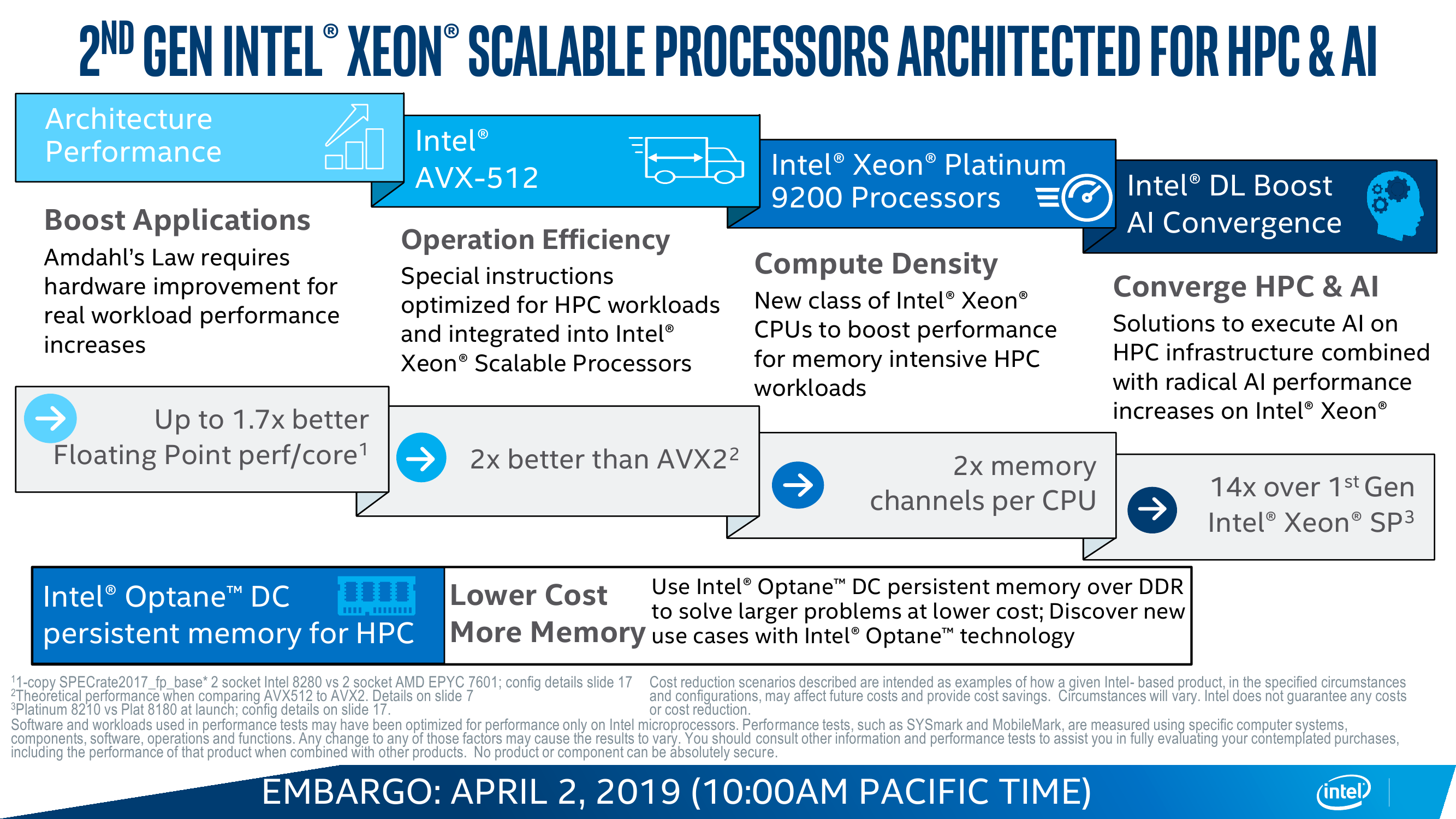
Общая схема наименований и серии Platinum, Gold, Silver, Bronze остались прежними, а вот "суффиксов" стало больше. Уже имеющиеся L и M всё так же указывают на поддержку увеличенного объёма памяти — до 4,5 и 2 Тбайт вместо базовых 1,5 Тбайт соответственно. Варианты T для процессоров с расширенным сроком поддержки, готовых к работе в более жёстких условиях, тоже сохранились. Новыми для Xeon стали версии Y, N, V и S — все они являются вариациями процессоров с поддержкой Speed Select. Наиболее общий и универсальный вариант — это Y. Версии N и S заранее оптимизированы для работы с сетевыми приложениями и с базами данных соответственно. Версия V нацелена на плотную виртуализацию. Версий F с интегрированным модулем Intel Omni-Path теперь нет (хотя и те, что были, всё равно нельзя было просто так купить).


К традиционным уже ограничениям на число сокетов, каналов UPI, одновременно выполняемых AVX/FMA-инструкций и частот памяти для процессоров Bronze и Silver добавилось ещё одно — они не умеют работать с Intel Optane DC Persistent Memory. Впрочем, она им, наверное, не очень-то и нужна, несмотря на то, что это как раз одно из главных новшеств Cascade Lake. Вообще говоря, на уровне общей архитектуры и техпроцесса новинки мало чем отличаются от прошлых Skylake SP. Их следует рассматривать как очередной этап оптимизации Skylake в целом или, если хотите, работу над ошибками и над реализацией тех задумок, которые изначально должны были быть в процессорах первого поколения, но по тем или иным причинам до стадии производства не дошли.


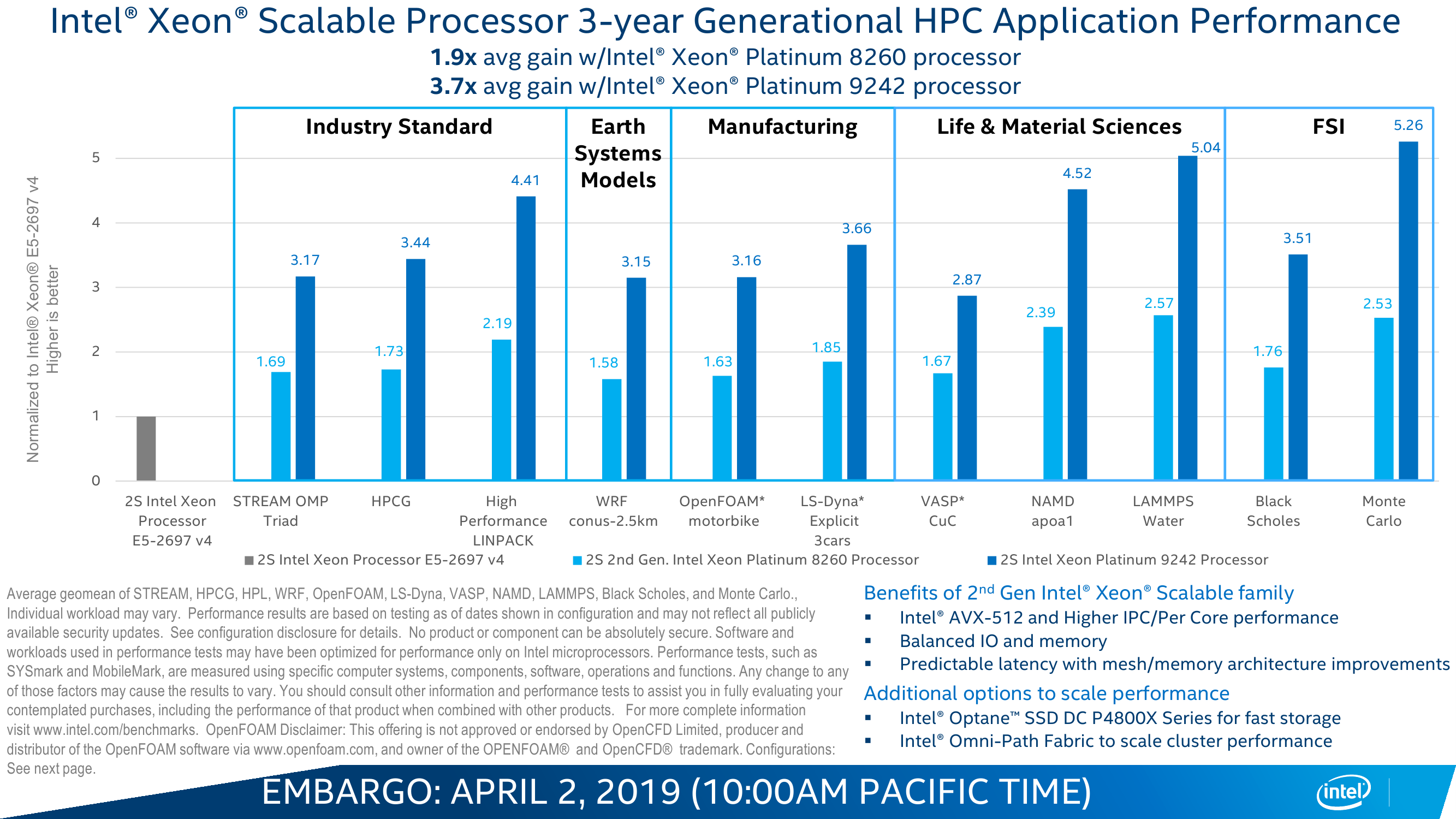
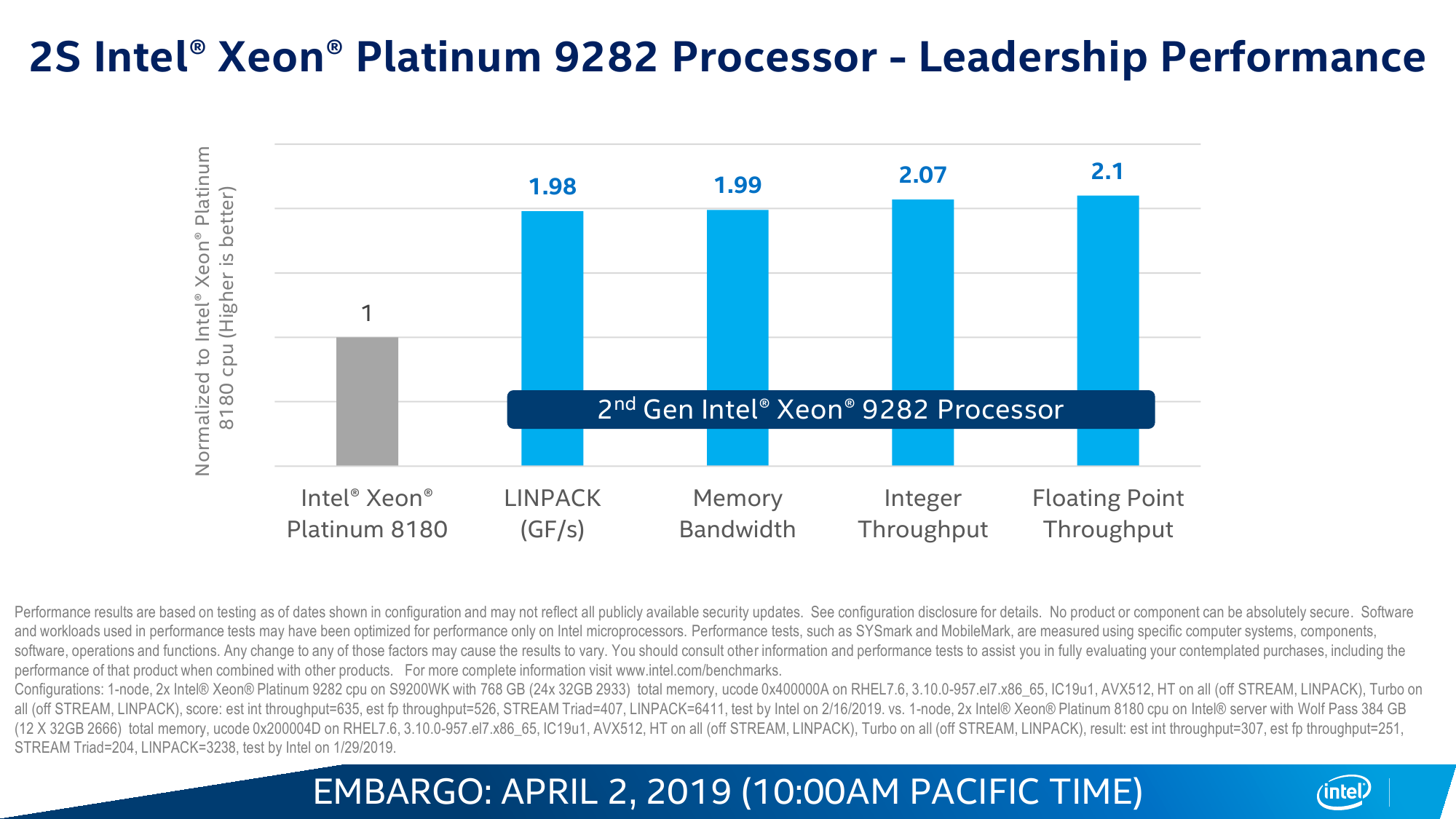
В целом различных микроапдейтов не один десяток, но из более-менее общих и заметных внешнему наблюдателю выделяются два. Во-первых, в среднем чуть подросли частоты при сохранении прежнего TDP, то есть вычисления стали «дешевле». В среднем заявленный прирост для популярной серии Gold составляет около трети, но он не совсем уж равномерен по классам и задачам, хотя та или иная прибавка есть везде. Во-вторых, появилась поддержка DDR4-2933 c 16-Гбит чипами, то есть с типовым объёмом модуля 64-256 Гбайт. Но для конфигураций с двумя DIMM на канал частота всё равно снижается до привычных 2666 MT/s.
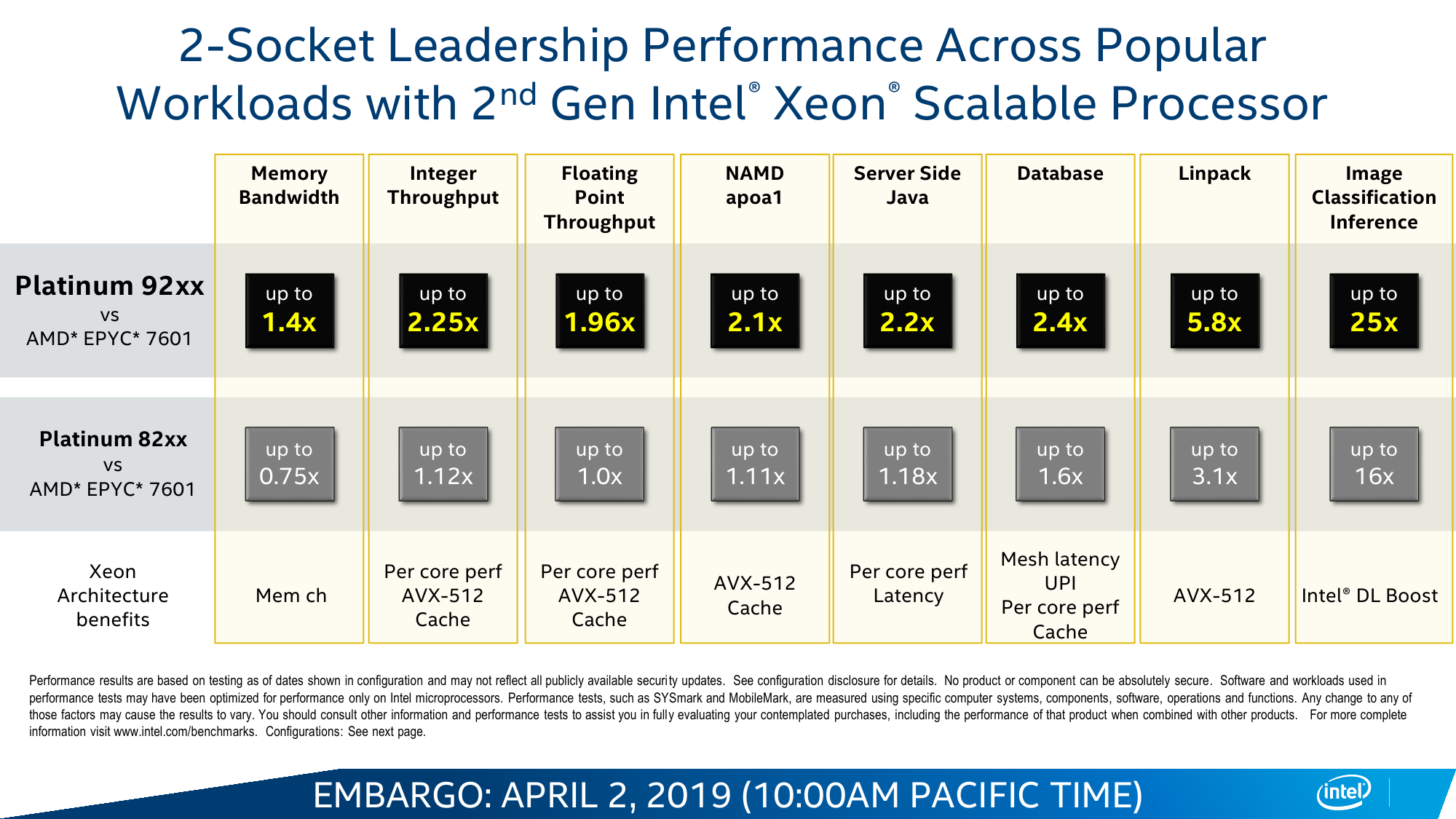
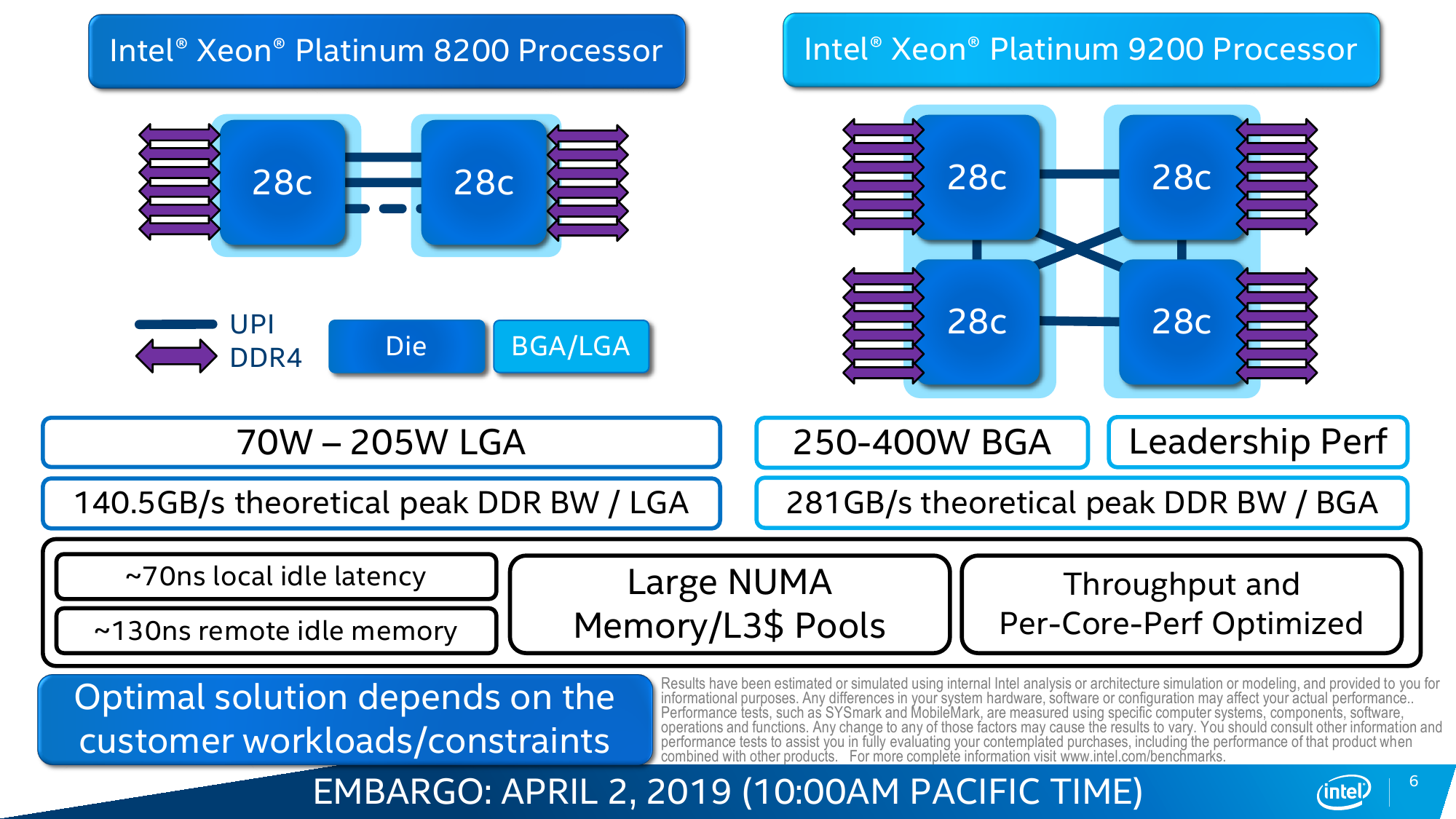
В остальном базовые характеристики и набор возможностей остались прежними. Число ядер и объёмы кешей не поменялись: до 28 и по 1 Мбайт L2 на ядро + до 38,5 Мбайт общего L3. Число и тип линий PCI-E тоже такие же, какие и были, — 48 линий версии 3.0. Масштабируемость не изменилась: до 3 линий UPI на 10,4 GT/s и до 8 (бесшовно) сокетов в системе. Остальные сведения об архитектуре и особенностях можно найти в материале «Знакомство с Intel Xeon Skylake-SP: сmeshaть, но не взбалтывать».

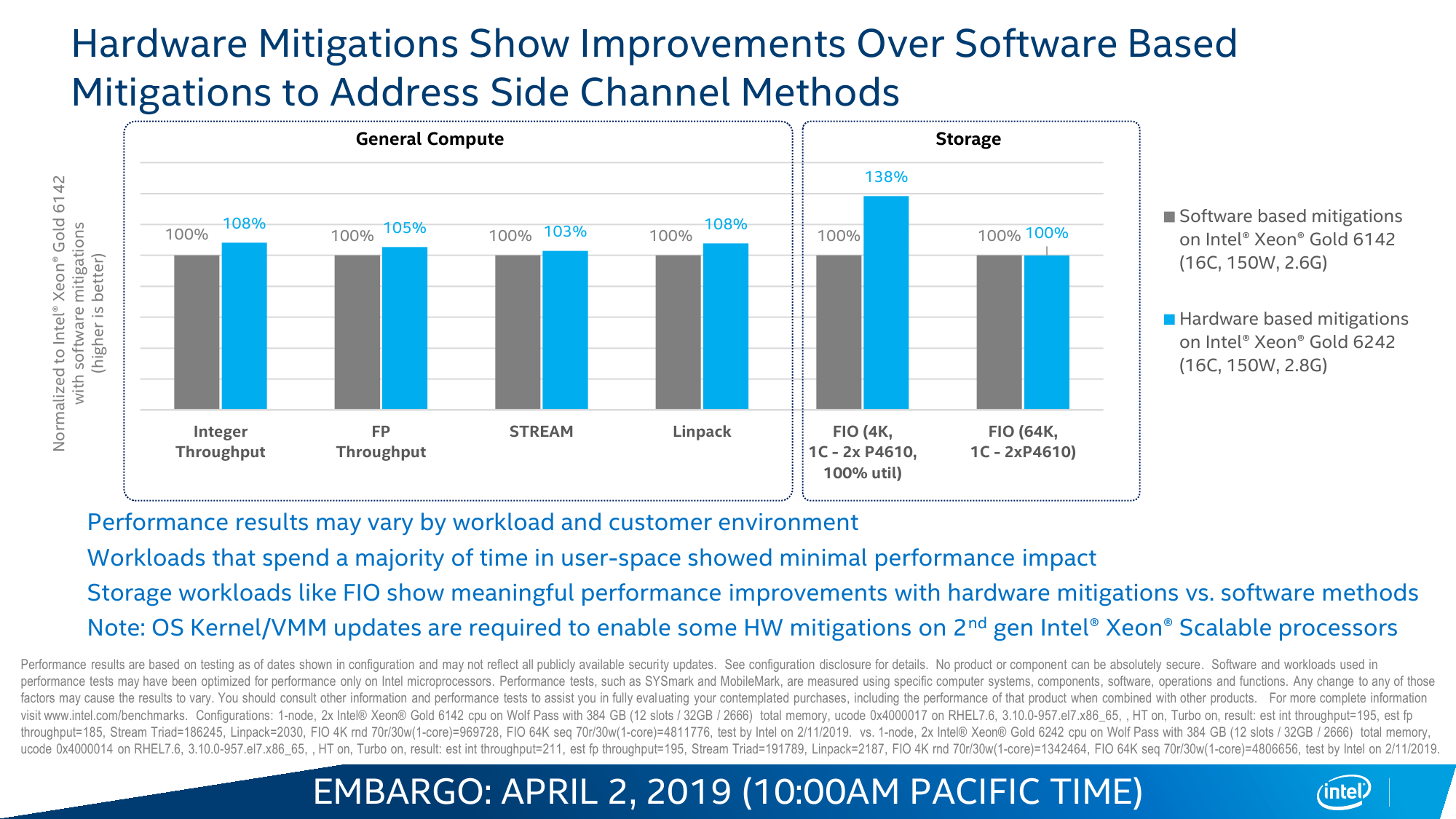
Ну и конечно, в Cascade Lake появились первые заплатки против нашумевших в прошлом году уязвимостей. В различных сочетаниях программно-аппаратные решения работают против вариантов 2 (Spectre), 3, 3a и 4 (Spectre NG), а также против L1TF (Foreshadow). Для Spectre Variant 1 всё так же предлагается только программный патч, а вот про SPOILER ничего пока не говорится. С одной стороны, презентация новинок для прессы проходила ещё до того, как поднялся шум по поводу последней. С другой же, на момент написания материала сведений от Intel всё ещё нет. Впрочем, представители компании говорят, что не боролись с конкретными вариантами, а работали над повышением защищённости CPU от подобных уязвимостей в целом.








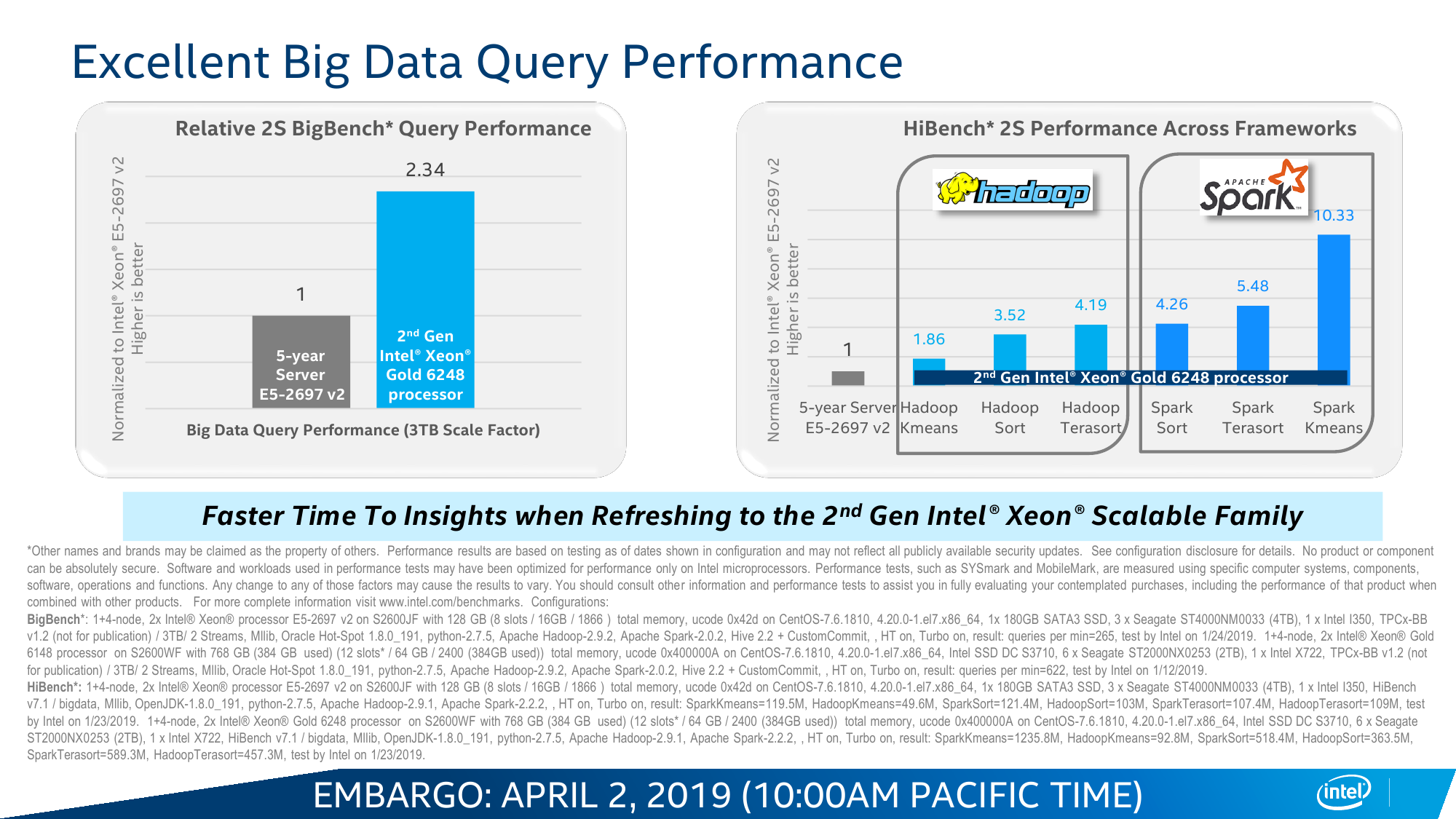

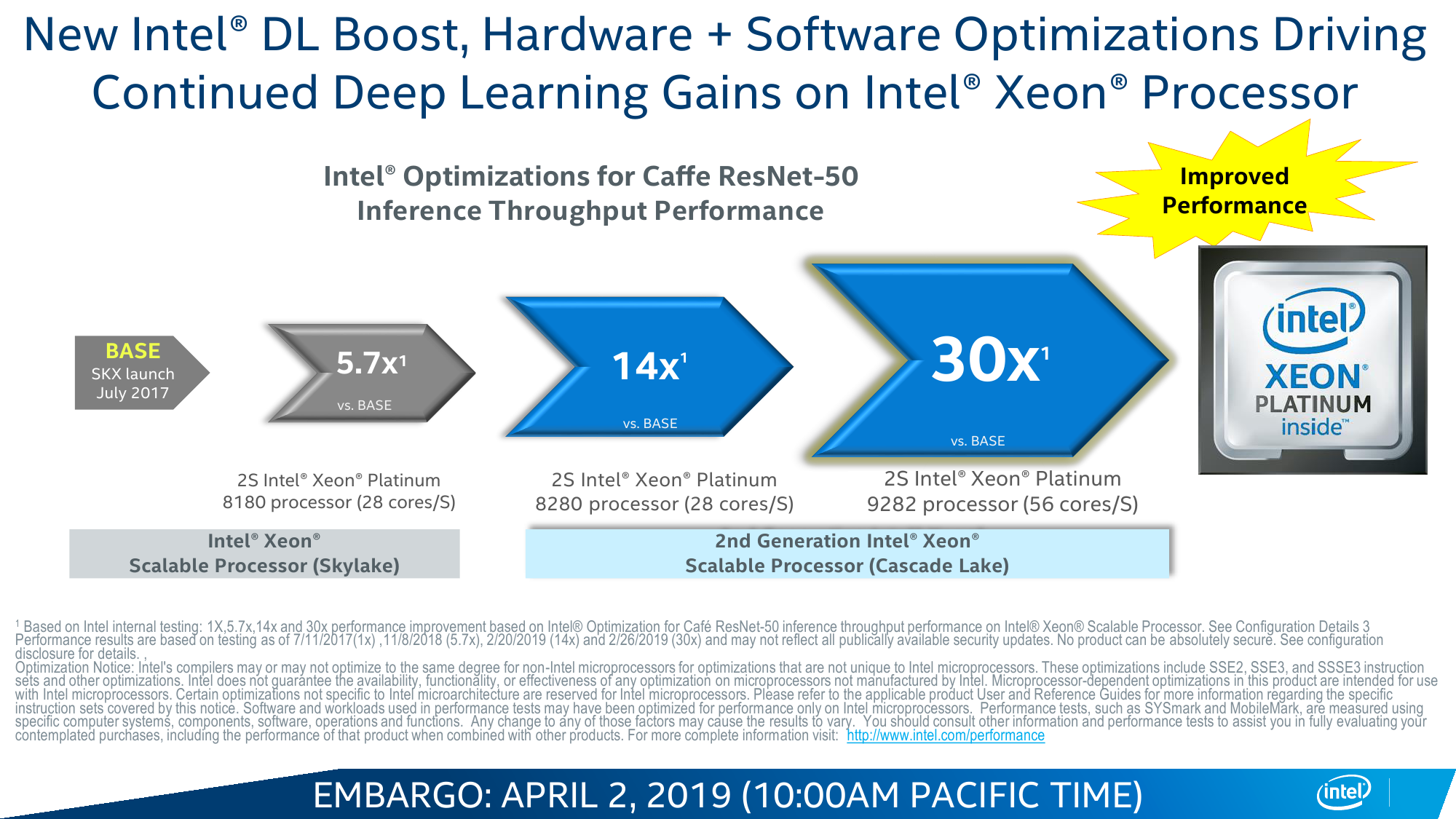

Intel Optane DC Persistent Memory
На уровне подхода идея расширения объёма DRAM за счёт использования более медленного, зато более дешёвого типа памяти не нова. Ранее для Xeon Skylake уже использовалась технология Intel Memory Drive Technology: гипервизор + NVMe-модули Optane. Как уже отмечалось, это на самом деле разработка компании ScaleMP, которой теперь пользуются и другие производители: на SC18 Western Digital предлагала аналогичное решение для своих NAND SSD. Это достаточно простой, но не всегда производительный вариант работы из-за использования PCI-E вместо DDR4-T. Собственно говоря, внедрением Optane как устройства класса Storage Class Memory на уровень DRAM и на уровень SSD Intel пытается закрыть провал в скорости, объёме и цене между оперативной памятью и накопителями — это всё то же перекраивание иерархии памяти, о котором неоднократно говорилось.

Intel Optane DC Persistent Memory
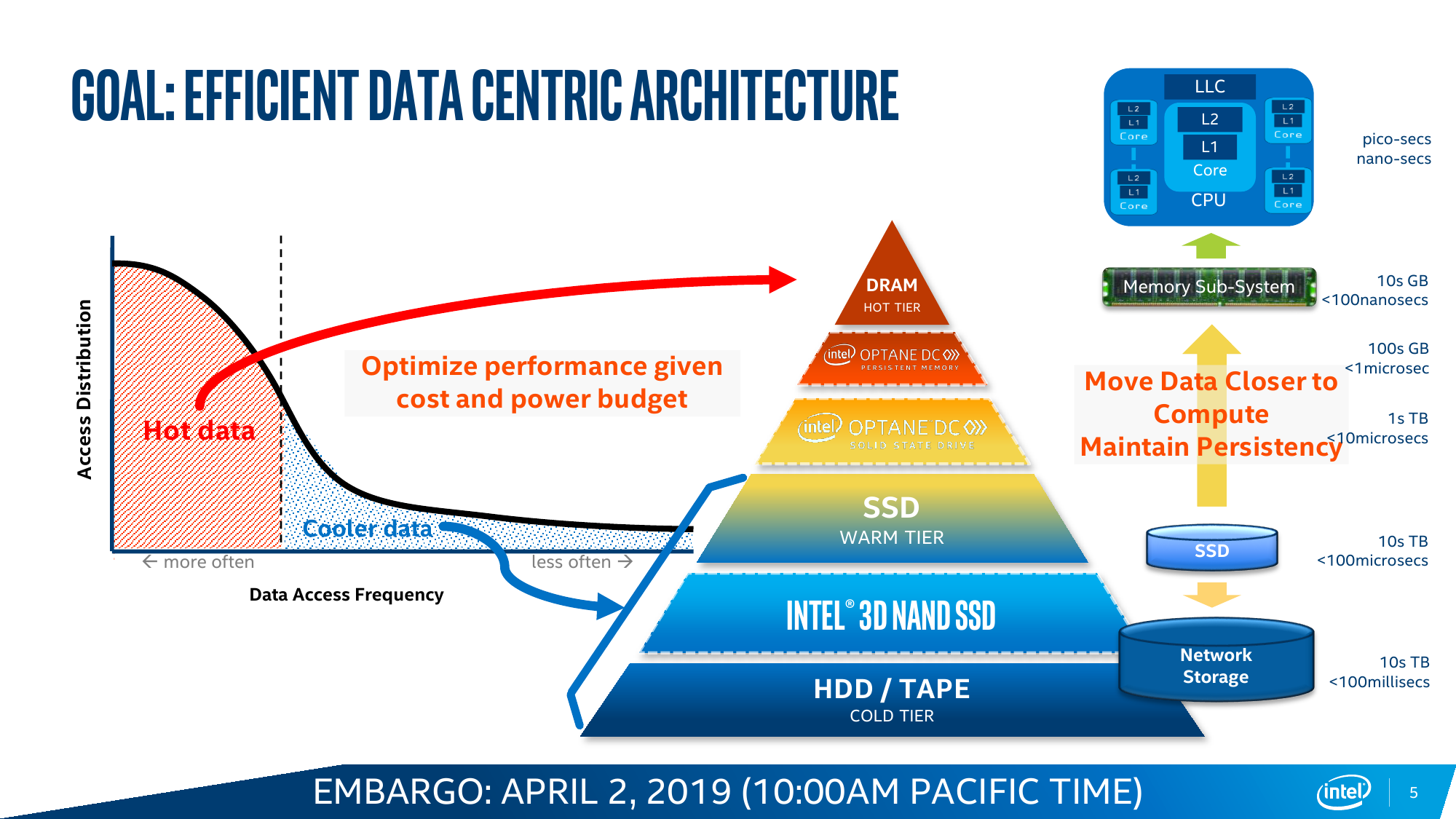
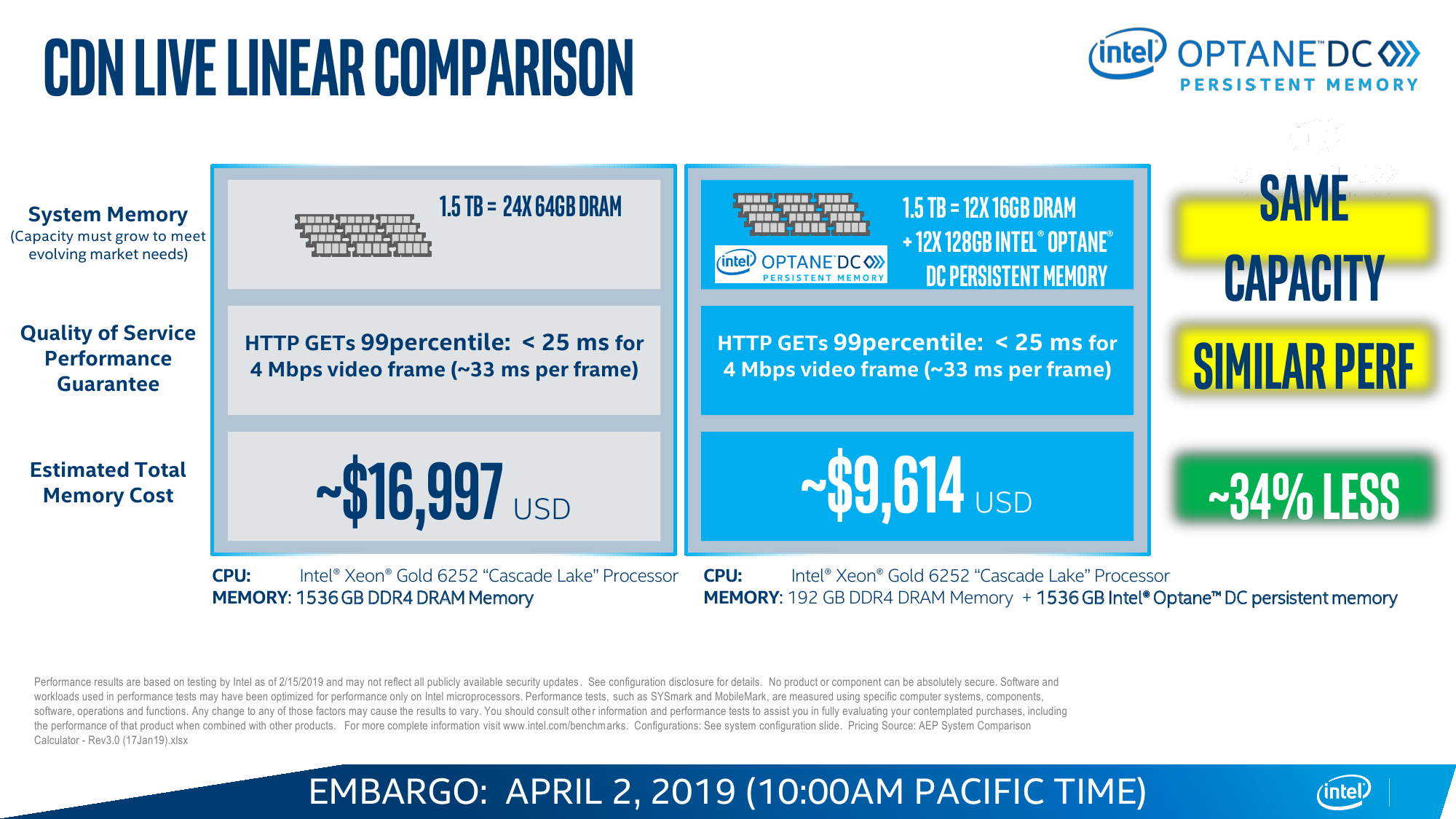
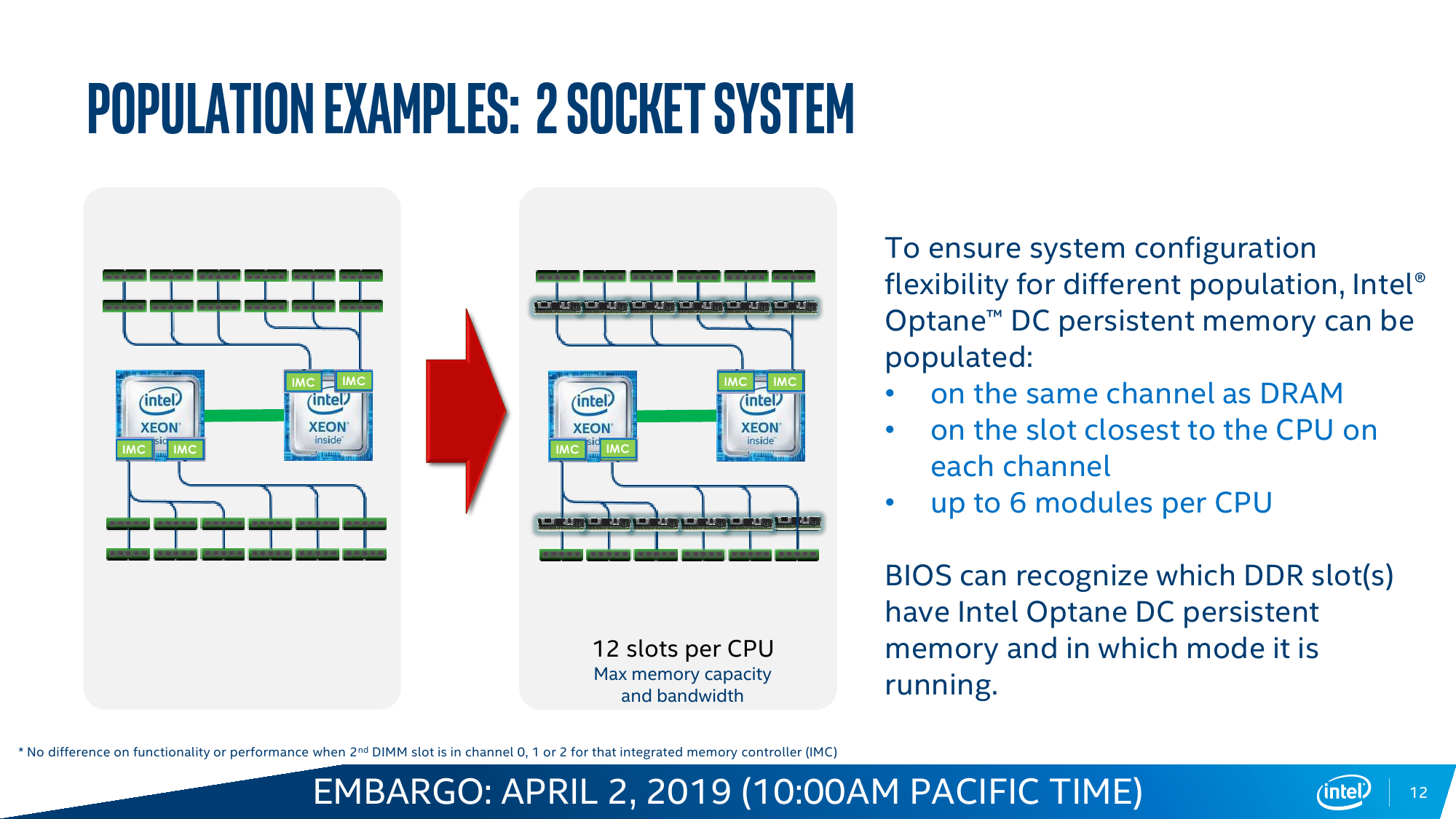
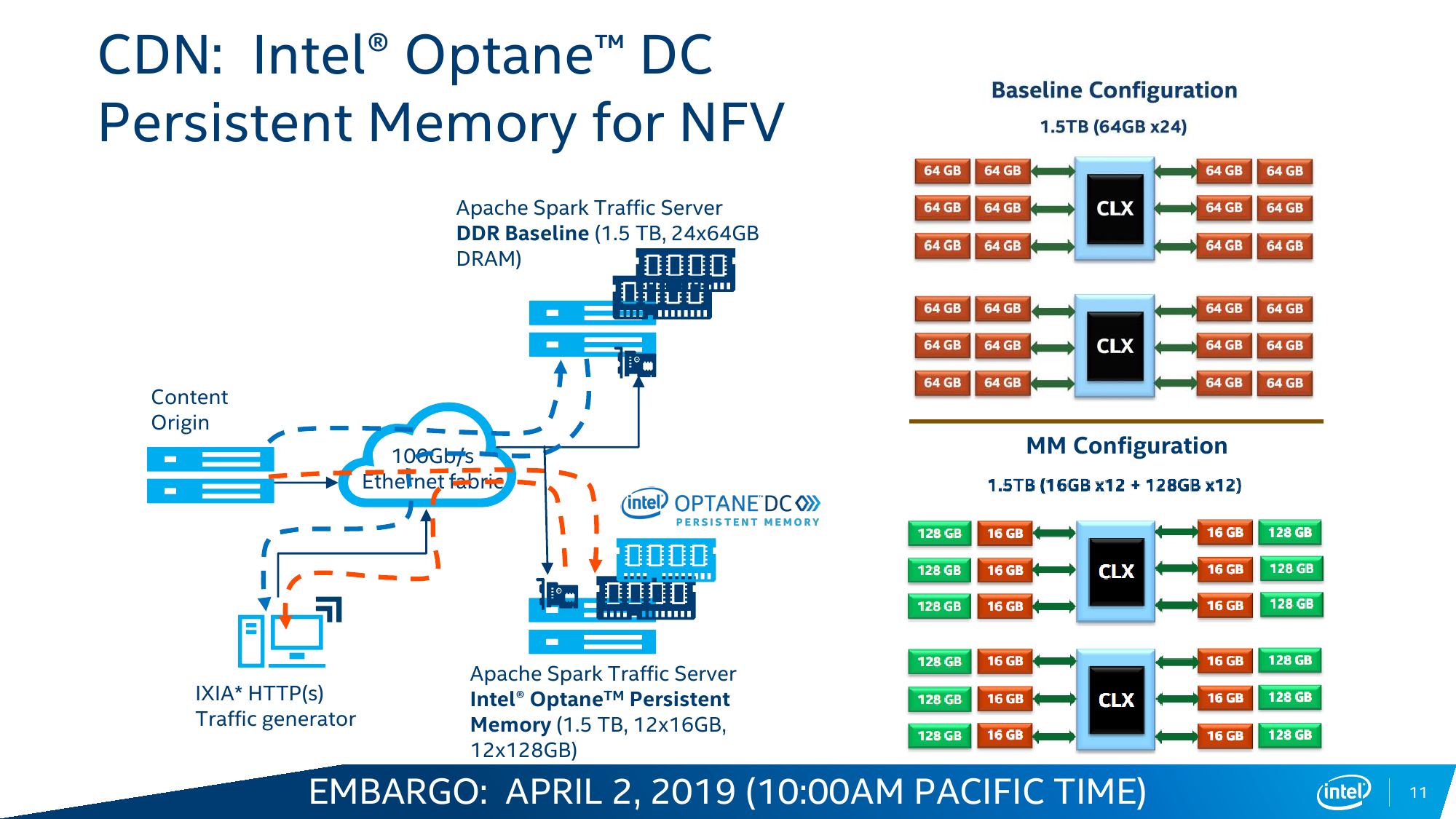
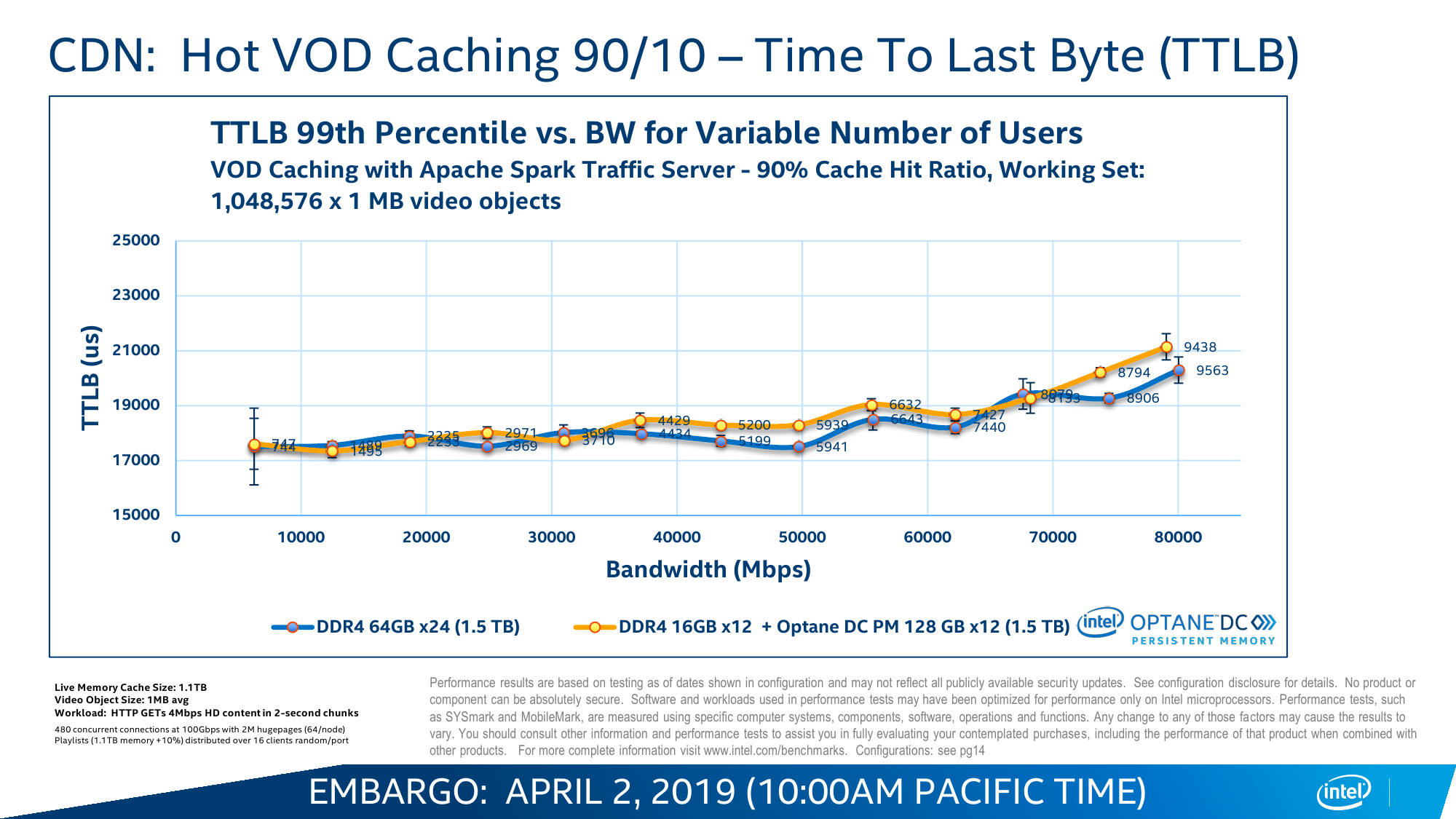
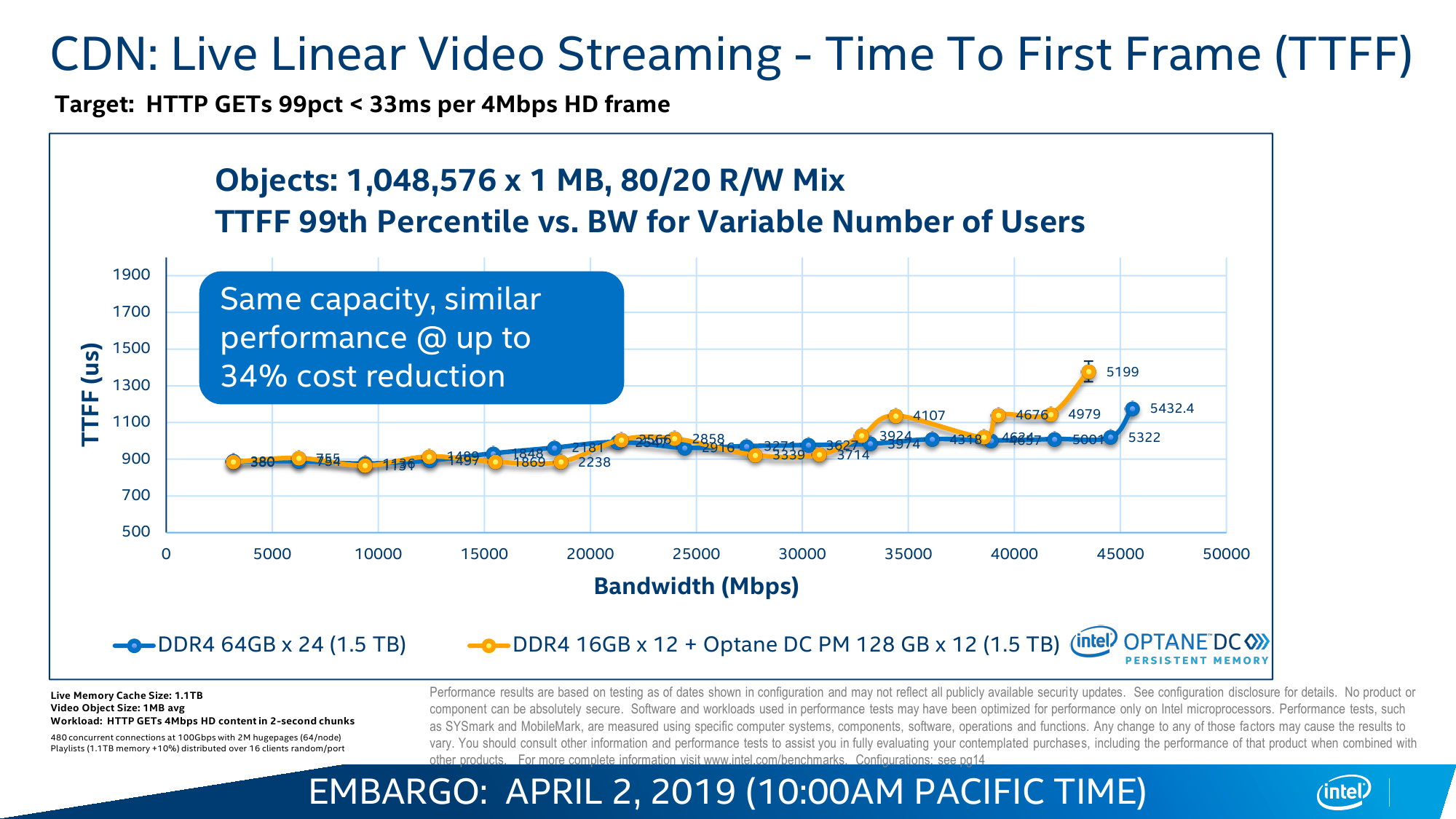
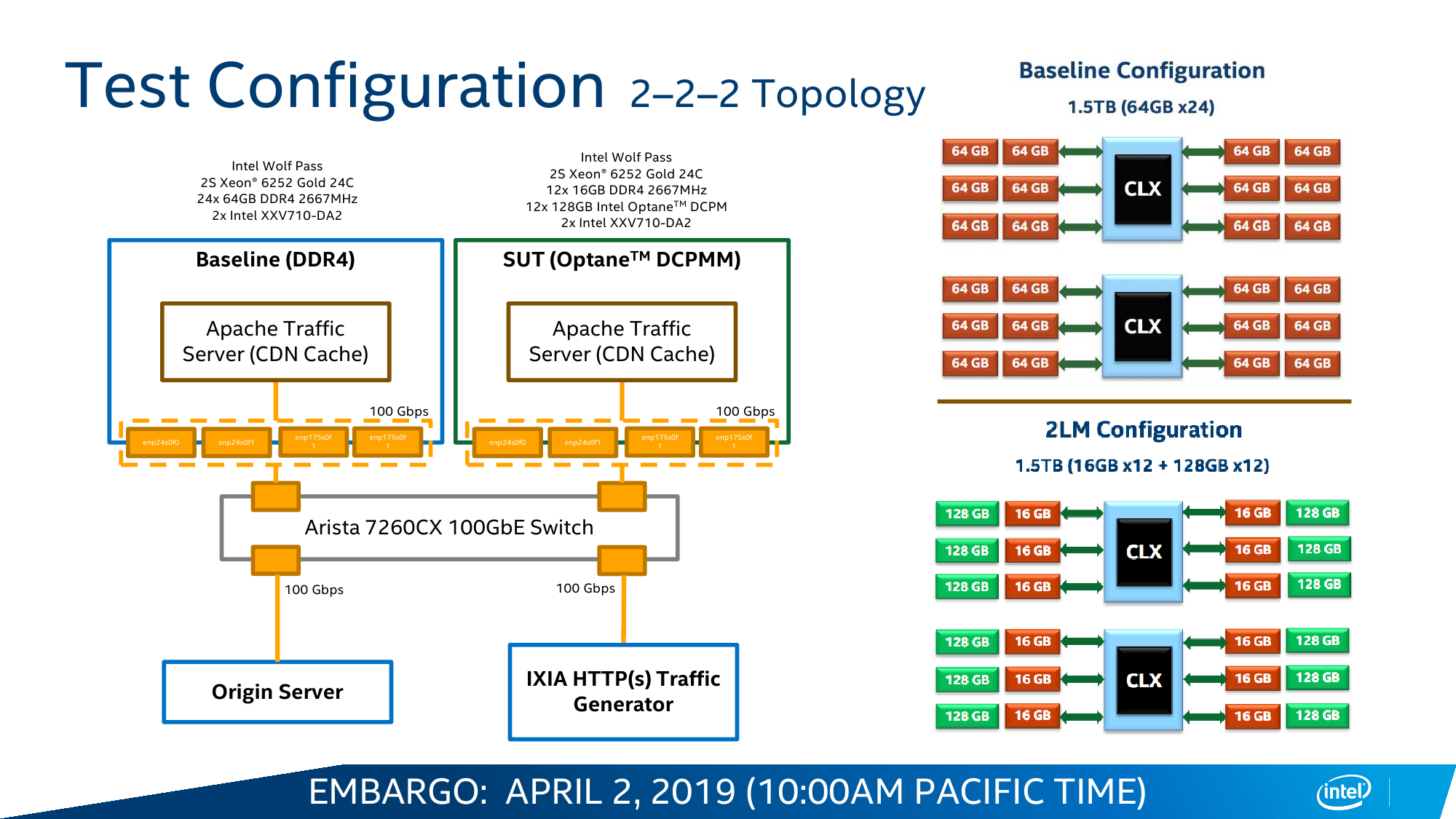
В случае с Cascade Lake и Intel Optane DC Persistent Memory (DCPM) всё меняется. Оба продукта с первого дня разрабатывались параллельно и изначально предназначены друг для друга. Модули DCPMM визуально похожи на модули DIMM, электрически и механически совместимы с ними, работают на скорости 2666 MT/s и имеют объём 128/256/512 Гбайт. Но на логическом уровне они используют протокол DDR4-T (Transaction), который, по словам Intel, одобрен JEDEC, но на практике его поддержка есть только в контроллерах памяти Cascade Lake. Однако и тут кроются некоторые нюансы. Для работы DCPM всё равно требуется наличие хотя бы одного обычного DIMM на каждом контроллере памяти (в CPU их два, у каждого три канала). Также рекомендуется ставить DCPM в слот, ближайший к CPU. При схеме в два модуля на канал получаем 12 слотов, из которых половина отдаётся Optane. При текущем максимальном объёме модуля DCPM 512 Гбайт выходит до 3 Тбайт памяти на сокет + DRAM. И такая конфигурация намного дешевле варианта с аналогичным объёмом, набранным только DDR-модулями.

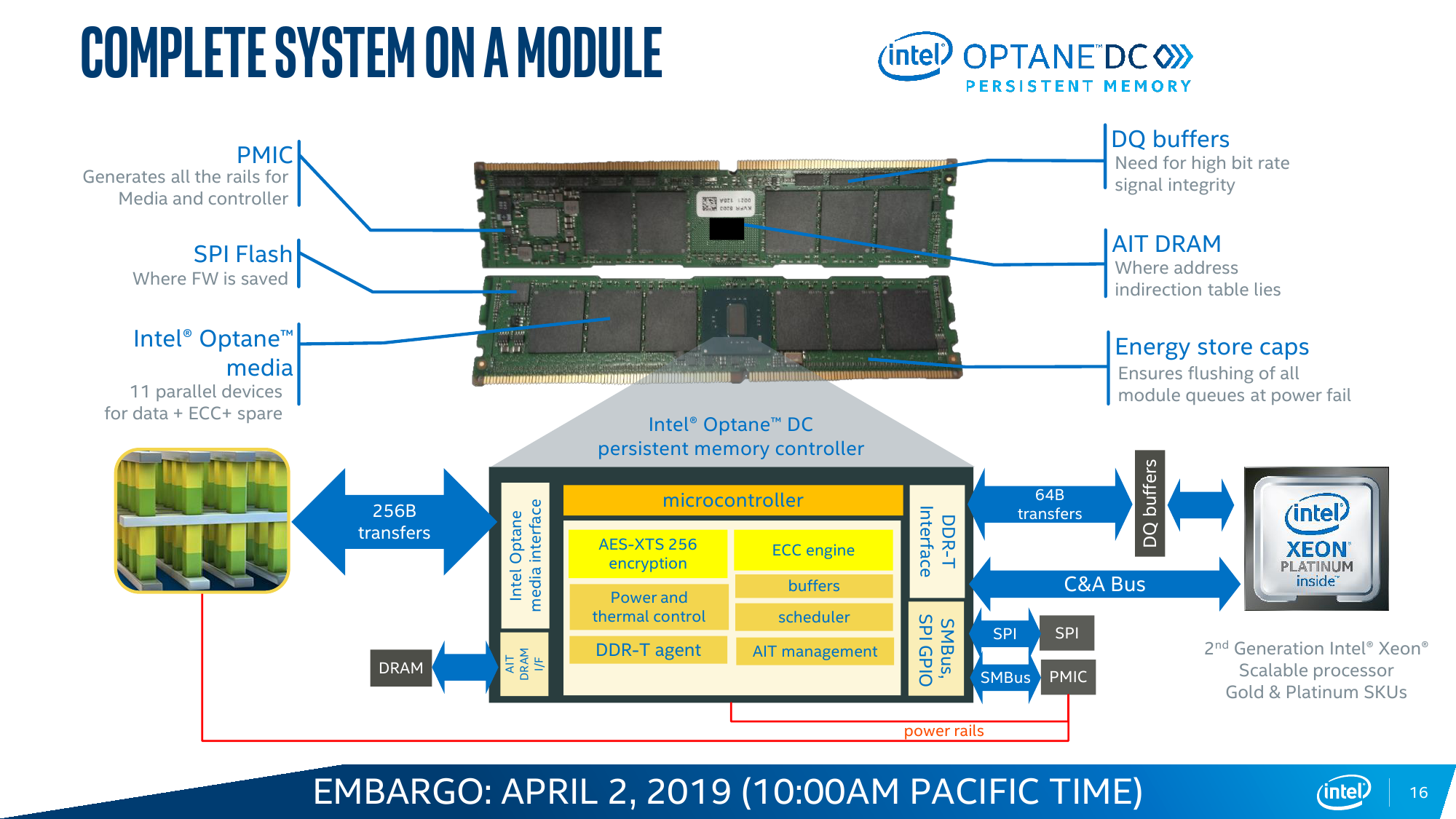
Так выглядит идеальная картинка, а на практике могут возникнуть ограничения. Текущее поколение DCPM потребляет до 18 Вт в случае наиболее ёмкого модуля на 512 Гбайт, что накладывает дополнительные требования и на подсистему питания, и на охлаждение. Впрочем, Intel предусмотрела возможность настройки профиля энергопотребления в диапазоне от 12 до 18 Вт с шагом 0,25 Вт, однако это напрямую влияет на производительность. Неслучайно модули DCPM изначально снабжены радиаторами. Внутри каждого модуля есть сразу 11 блоков памяти Optane: восемь для хранения данных, два для организации коррекции ошибок ECC и ещё один подменный. Есть выравнивание износа, а общий срок службы заявлен как сопоставимый со сроком службы сервера в целом.
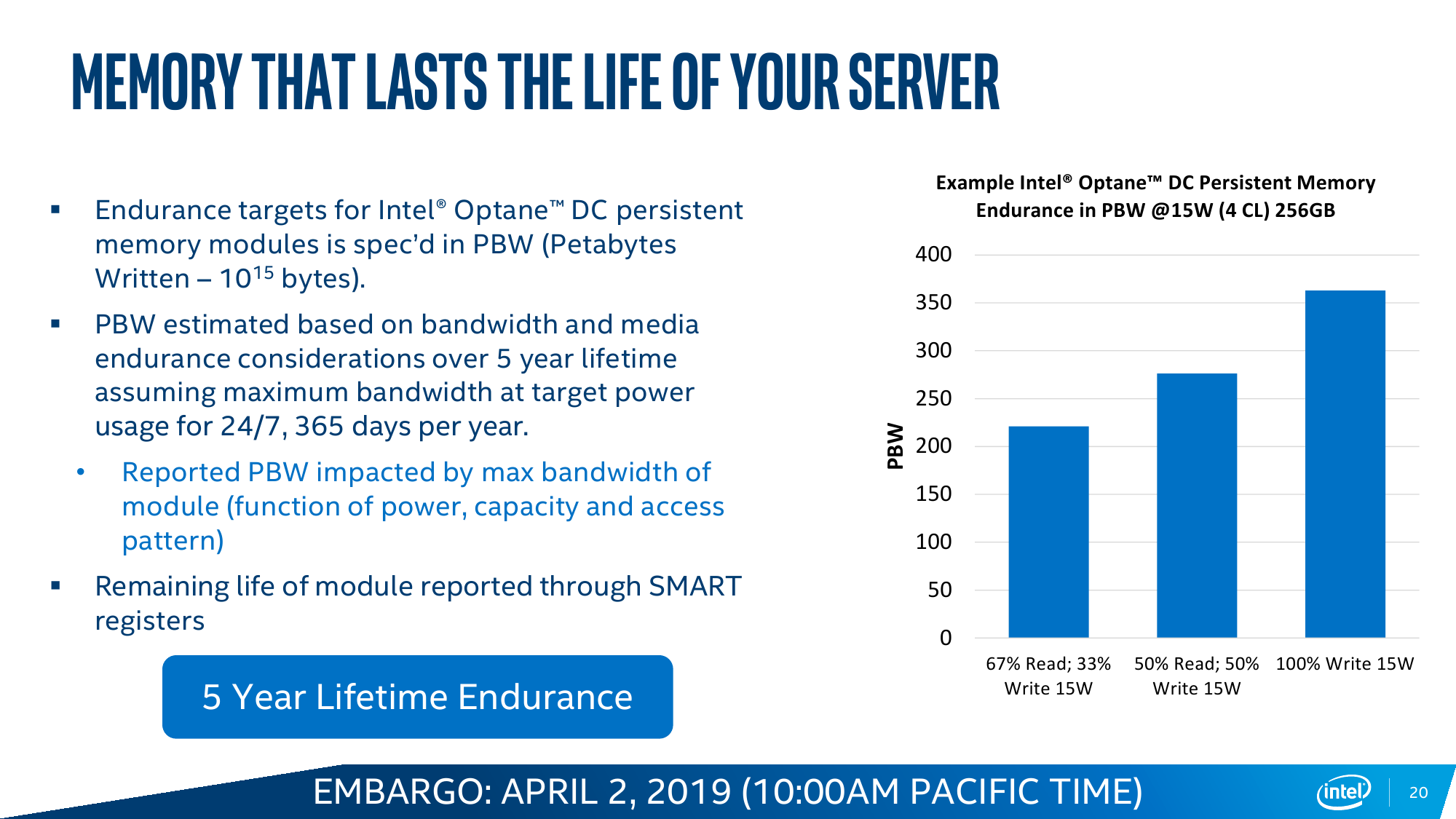

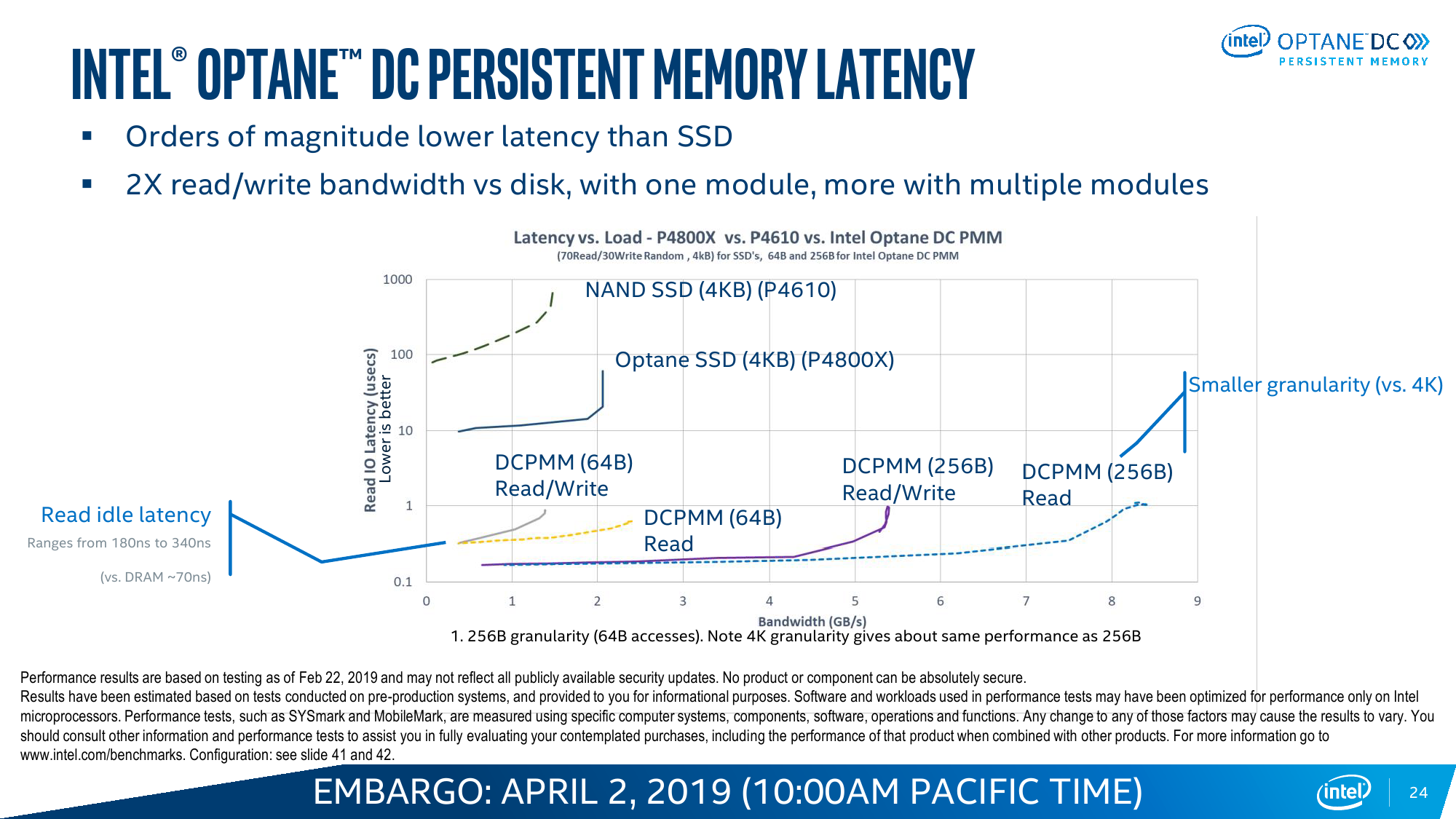
Другой нюанс заключается в том, что внутренний обмен данными для чипов Optane организован в блоки по 256 байт/запрос, тогда как внешний интерфейс для контроллера памяти CPU «синхронизирован» с внутренней шиной на 64 байт/цикл. В результате случайные короткие обращения в среднем менее эффективны, чем последовательная работа с данными. Впрочем, по скорости и/или по уровню задержки DCPM всё равно в среднем лучше прежнего варианта IMDT.
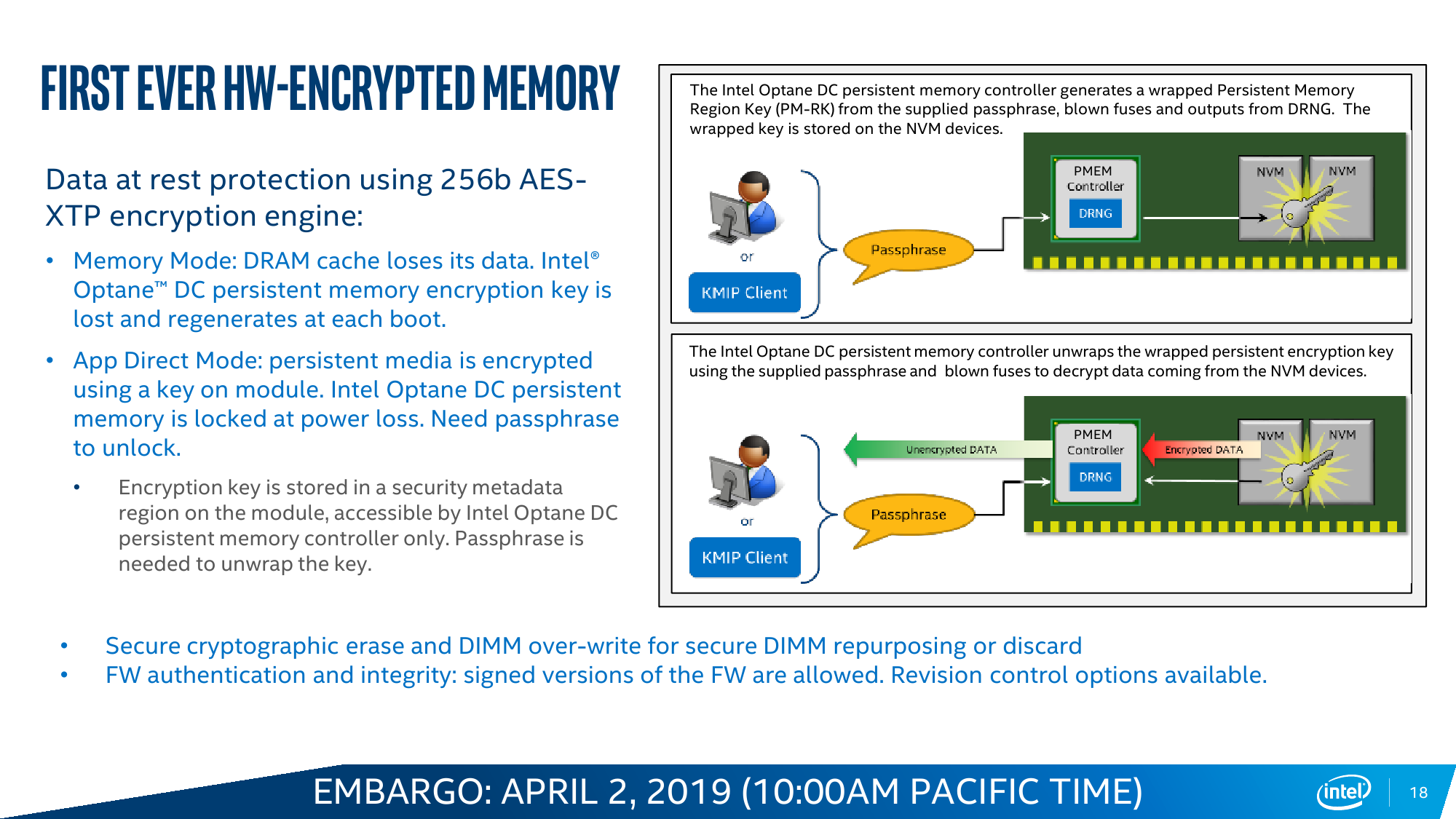
Особенностью DCPM также является принудительное аппаратное шифрование всех данных по алгоритму AES-XTP с индивидуальным для каждого модуля ключом длиной 256 бит, который хранится где-то в недрах памяти и к которому имеет доступ только контроллер самого модуля. Это в каком-то смысле вынужденная предосторожность, связанная с тем, что Optane — не динамическая память. Есть даже выделенные конденсаторы, запаса энергии в которых в случае сбоя хватит для экстренной очистки данных в режиме Memory Mode, и так штатно эмулирующего поведение DRAM. Да, самое главное — Intel Optane DC Persistent Memory предусматривает два варианта работы, которые задаются при загрузке системы: Memory Mode и AppDirect Mode.
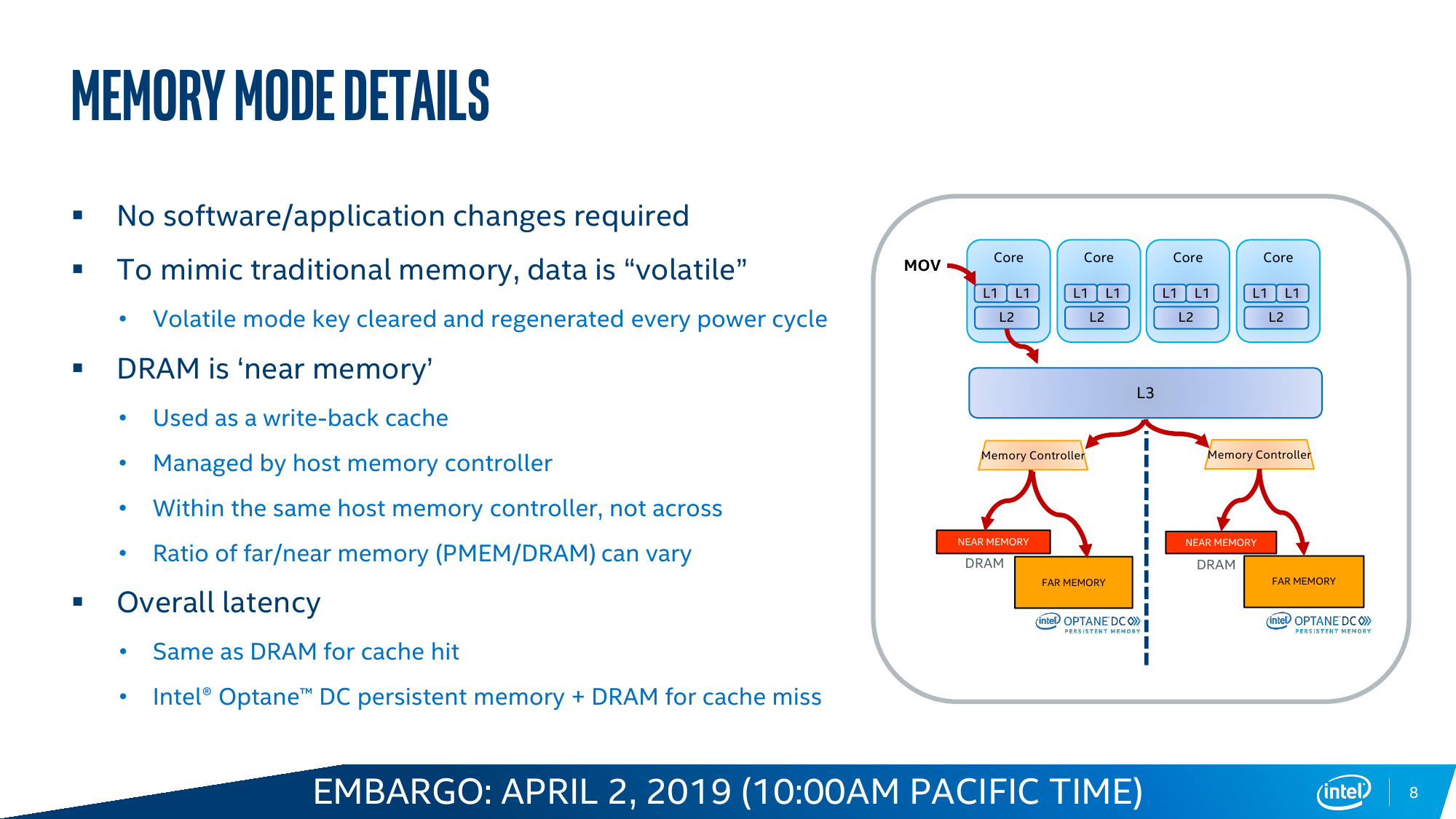
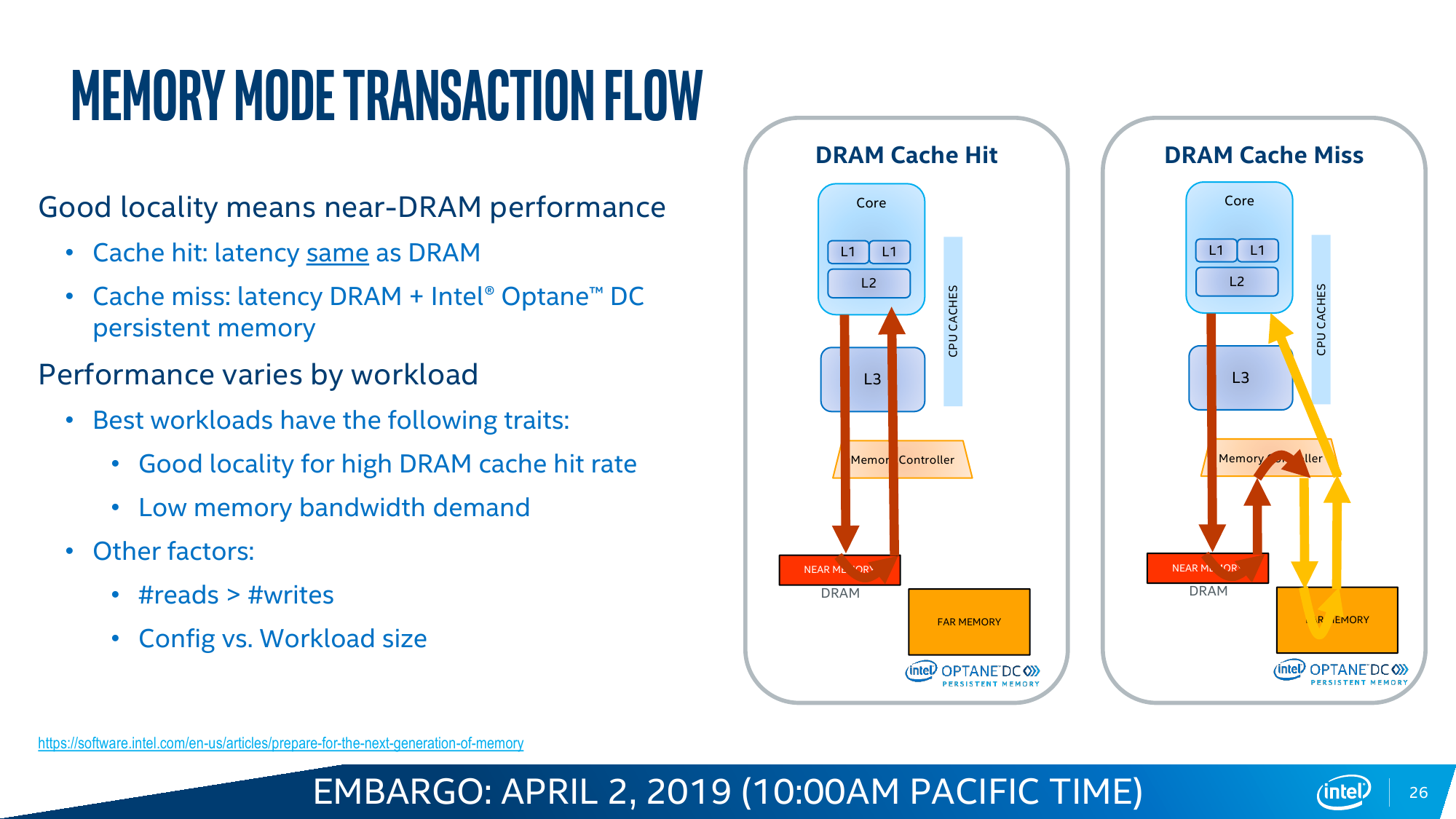
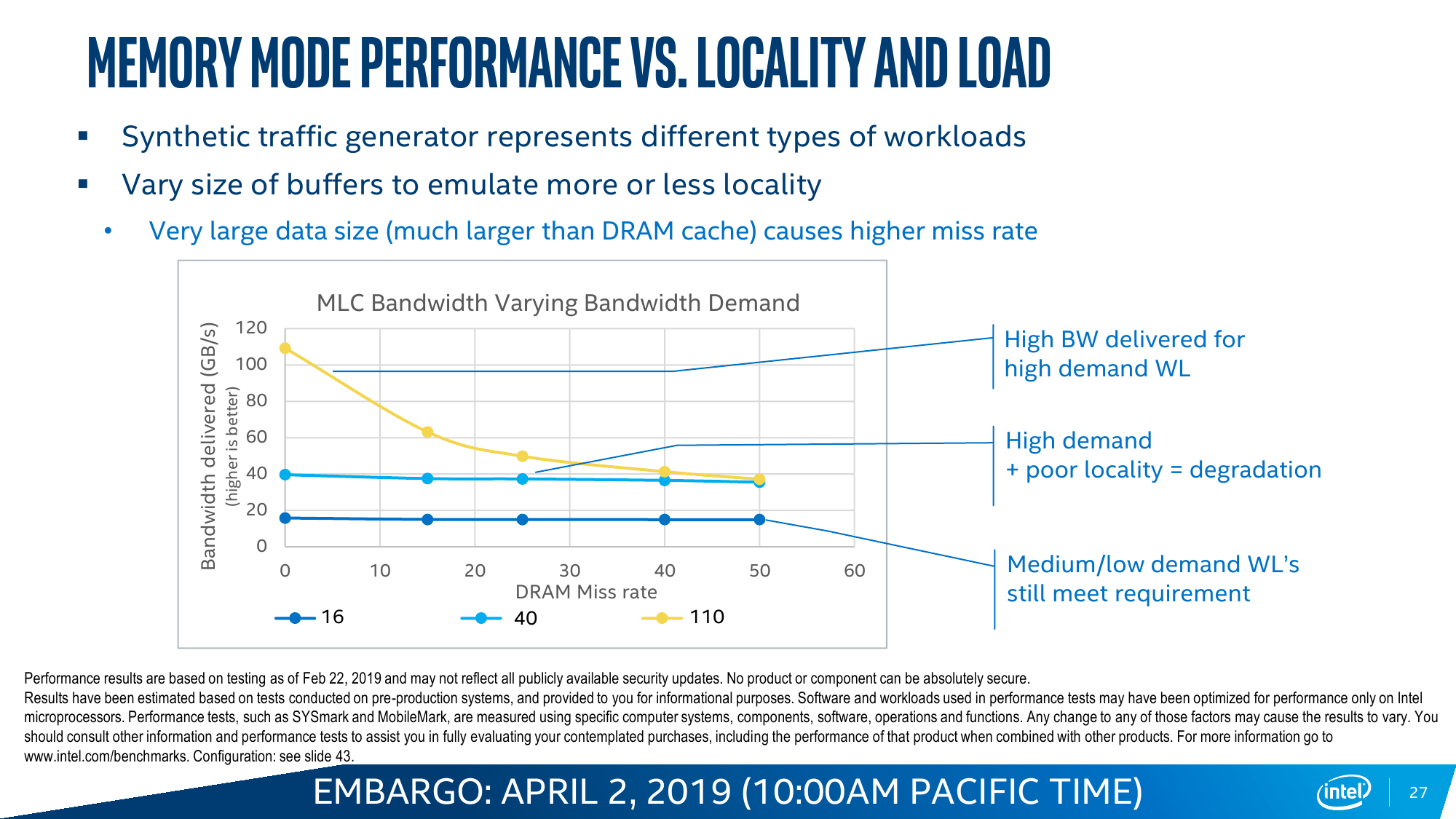
Memory Mode прозрачно расширяет видимый системой объём RAM за счёт DCPM. Собственно DRAM в этом случае просто является write-back кешем, стоящим перед массивом Optane. Очевидное преимущество в том, что нет необходимости переписывать старые приложения, они просто увидят увеличенный объём памяти. Очевидный недостаток — при росте числа промахов кеша будет расти и задержка, так как она теперь состоит из двух частей: латентности самой DRAM и латентности DCPM. Ну и при превышении рабочим набором объёма собственно DRAM будет падать скорость. Тем не менее при сочетании низкой интенсивности обращений с необходимостью в большом объёме памяти Memory Mode всё равно оказывается эффективней, чем работа с DRAM и NVMe по отдельности, так как выкидывается куча промежуточных этапов при обращении к обычному диску.
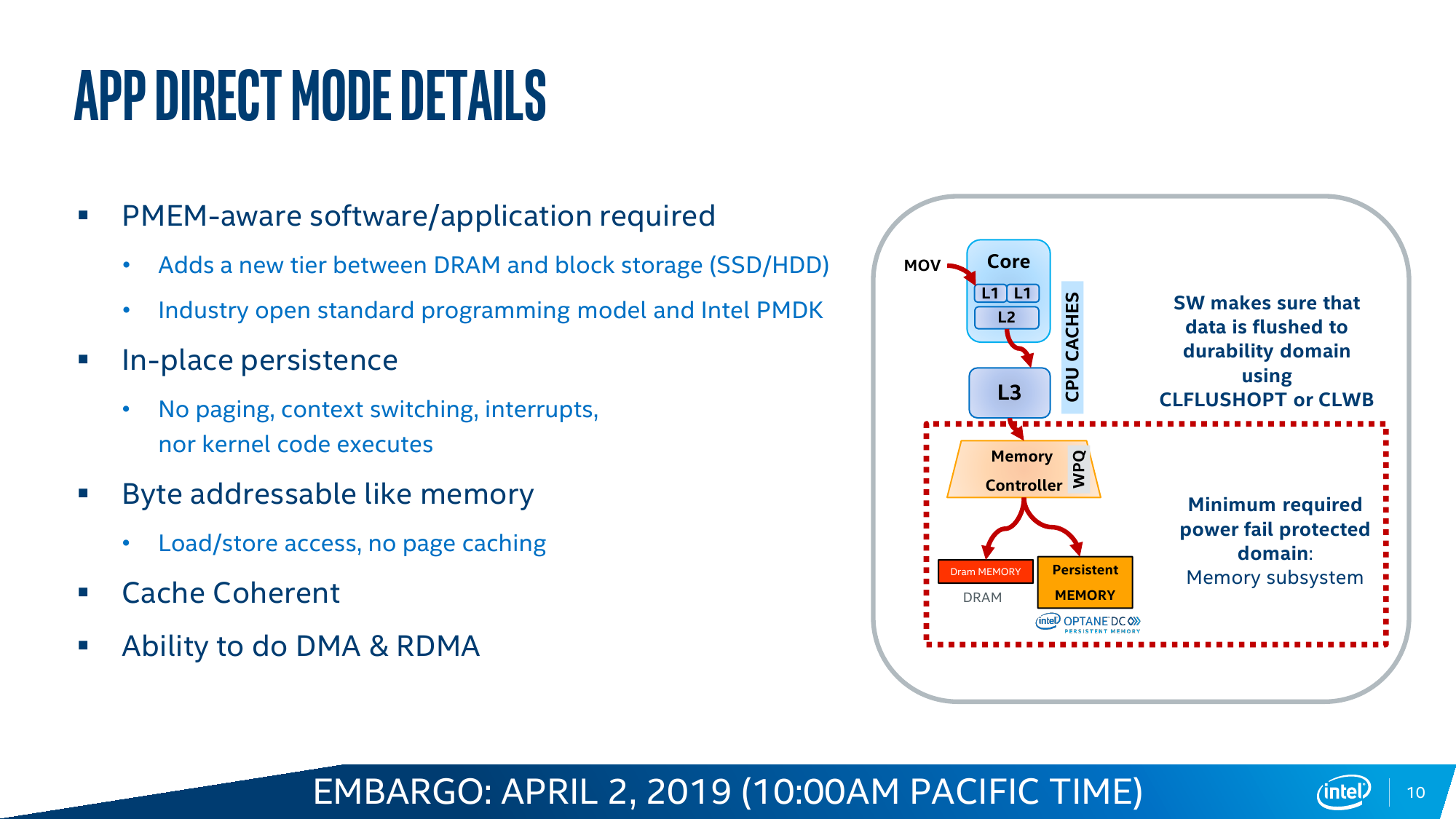
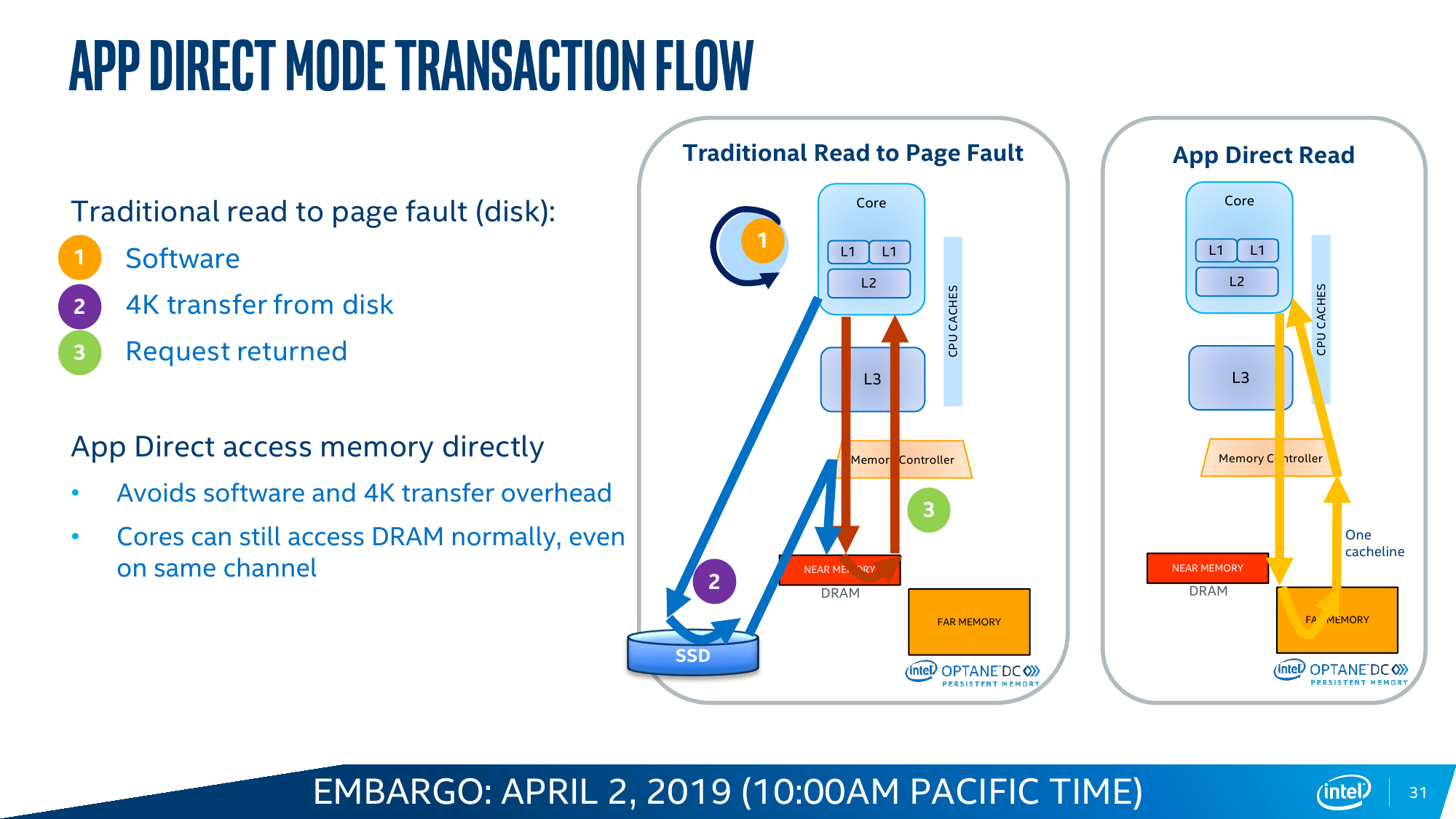
Ровно то же происходит и в AppDirect Mode, который следует считать, пожалуй, основным режимом работы Intel Optane DC Persistent Memory. В нем у приложения на выбор есть три вида памяти — DRAM, NAND SSD и промежуточный по скорости/объёму вариант в виде Optane. И его надо адаптировать к этому. DCPM может представляться и как классическое блочное устройство, то есть его можно разбить на разделы, отформатировать и использовать как сверхбыстрый SSD. А может представляться и как просто память с побитовым доступом. В любом случае при сбое по питанию или просто при перезагрузке данные останутся в памяти, что может быть крайне важно для различных критических систем, работающих с большими объёмами информации. В теории есть и ещё один нестандартный вариант — загрузка непосредственно с DCPM, что позволяет избавиться от обычных накопителей в системах, где требуется высокая плотность размещения компонентов или просто компактность.
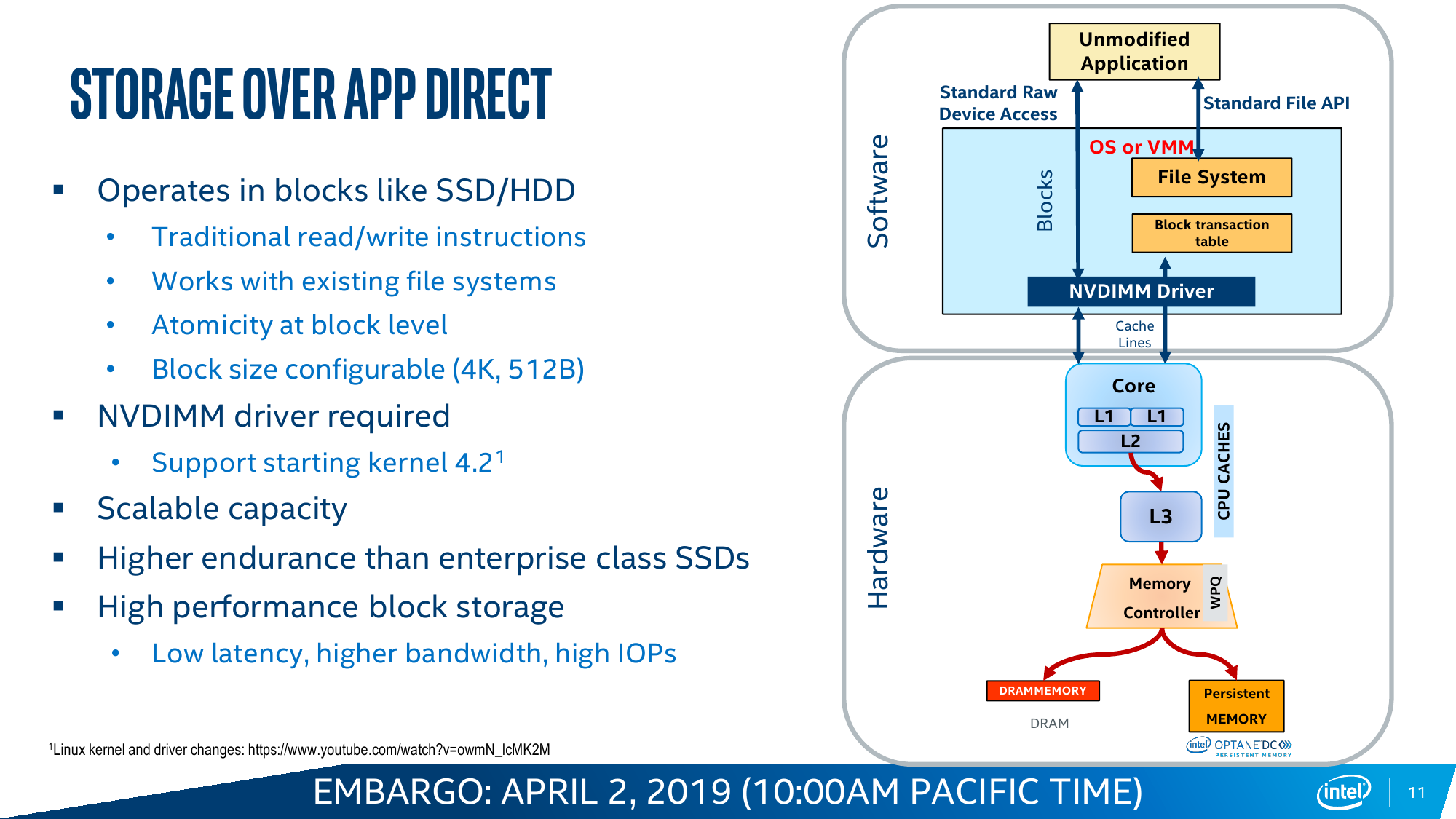
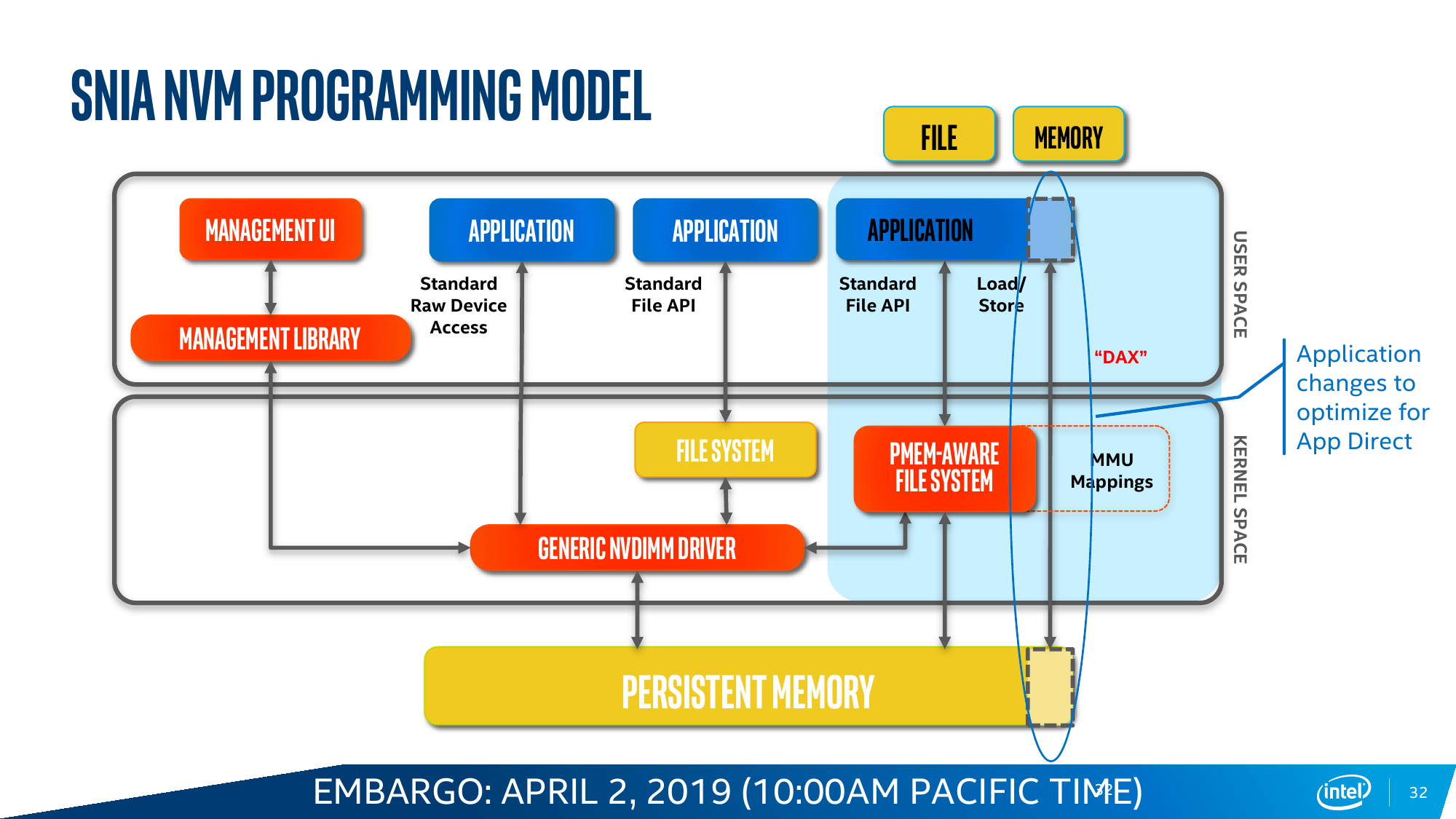
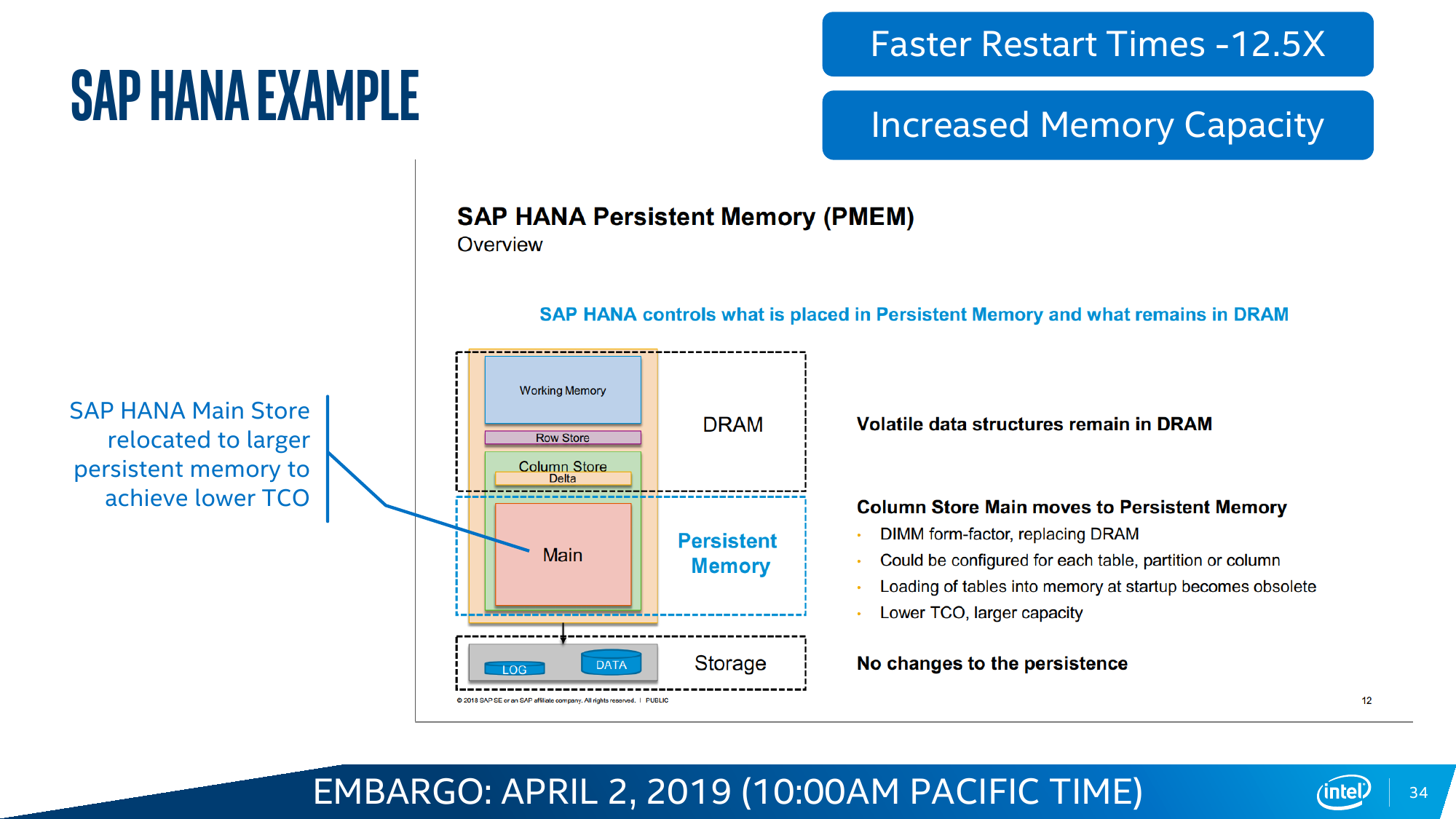
Почему именно AppDirect Mode должен стать основным? Потому что программистов в целом неплохо бы приучить к тому, что существует третий тип памяти. Ну или наоборот, что есть теперь уже достаточно гладкая кривая для соотношения скорости и объёма. В качестве примеров эффективной оптимизации под такую иерархию Intel приводит работу приложений, которые выигрывают от грамотного разнесения данных по классам: SAP HANA, большие базы данных, системы аналитики Big Data. А для Memory Mode типичный пример — повышение плотности размещения виртуальных машин. В любом случае, бездумно переходить на DCPM особого смысла нет — разработчики неоднократно повторяют, что работу приложений надо тщательнее изучать и оптимизировать.










Intel RDT и Speed Select
Одним из инструментов, который доступен в Cascade Lake, является Intel Resource Director Technology (RDT). Технология RDT, если кратко, предоставляет собой механизмы довольно тонкого мониторинга и контроля над исполнением приложений и использованием ресурсов. Она сама по себе нова и присутствовала в процессорах и раньше. В данном случае она предлагает классификацию и приоритизацию, влияющие на распределение запущенных потоков, пропускной способности кеша и памяти, — всё для того, чтобы более высокоприоритетное приложение вовремя получало всё, что ему нужно. Естественно, за счёт некоторого «ущемления в правах» других приложений.
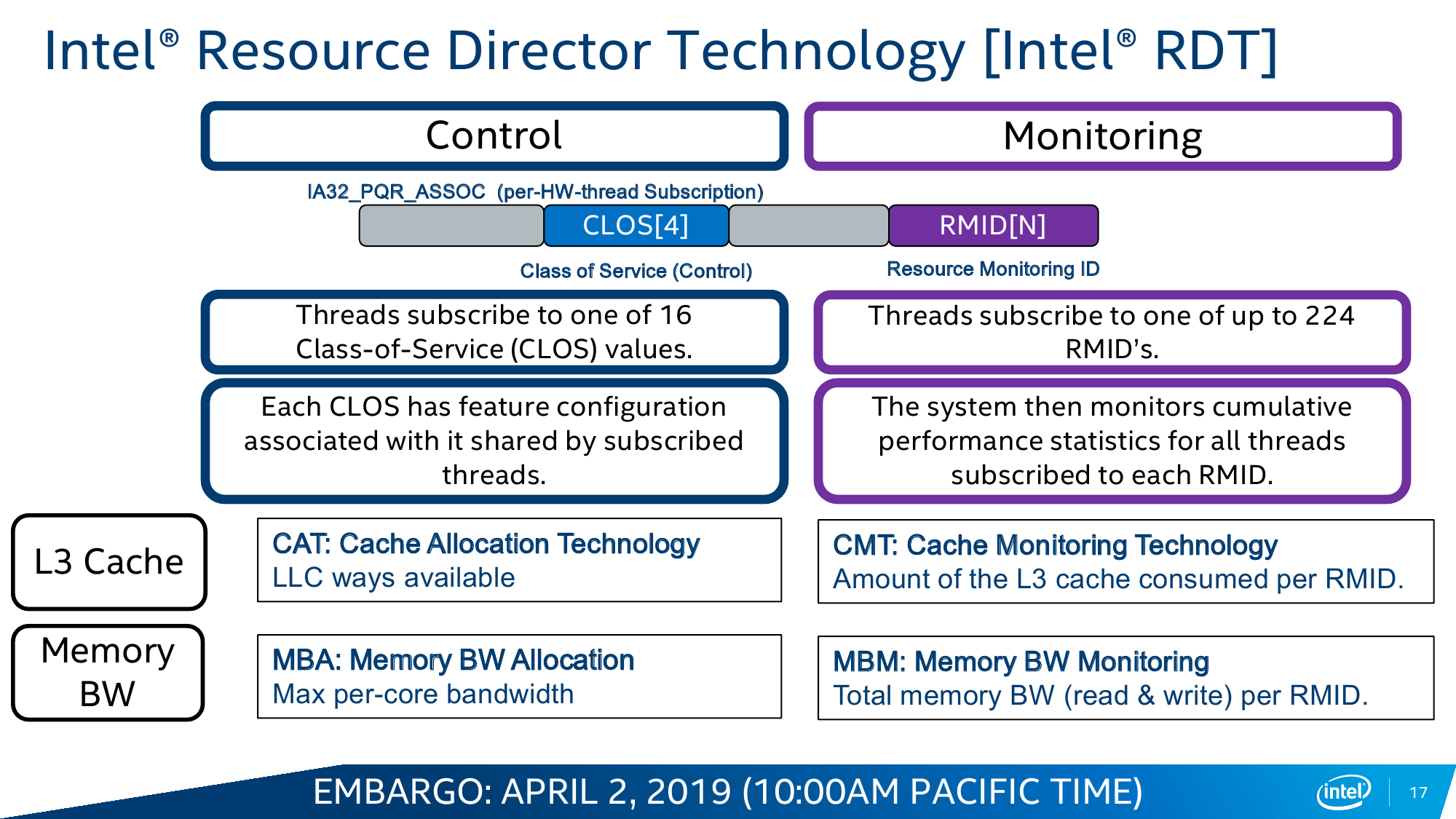
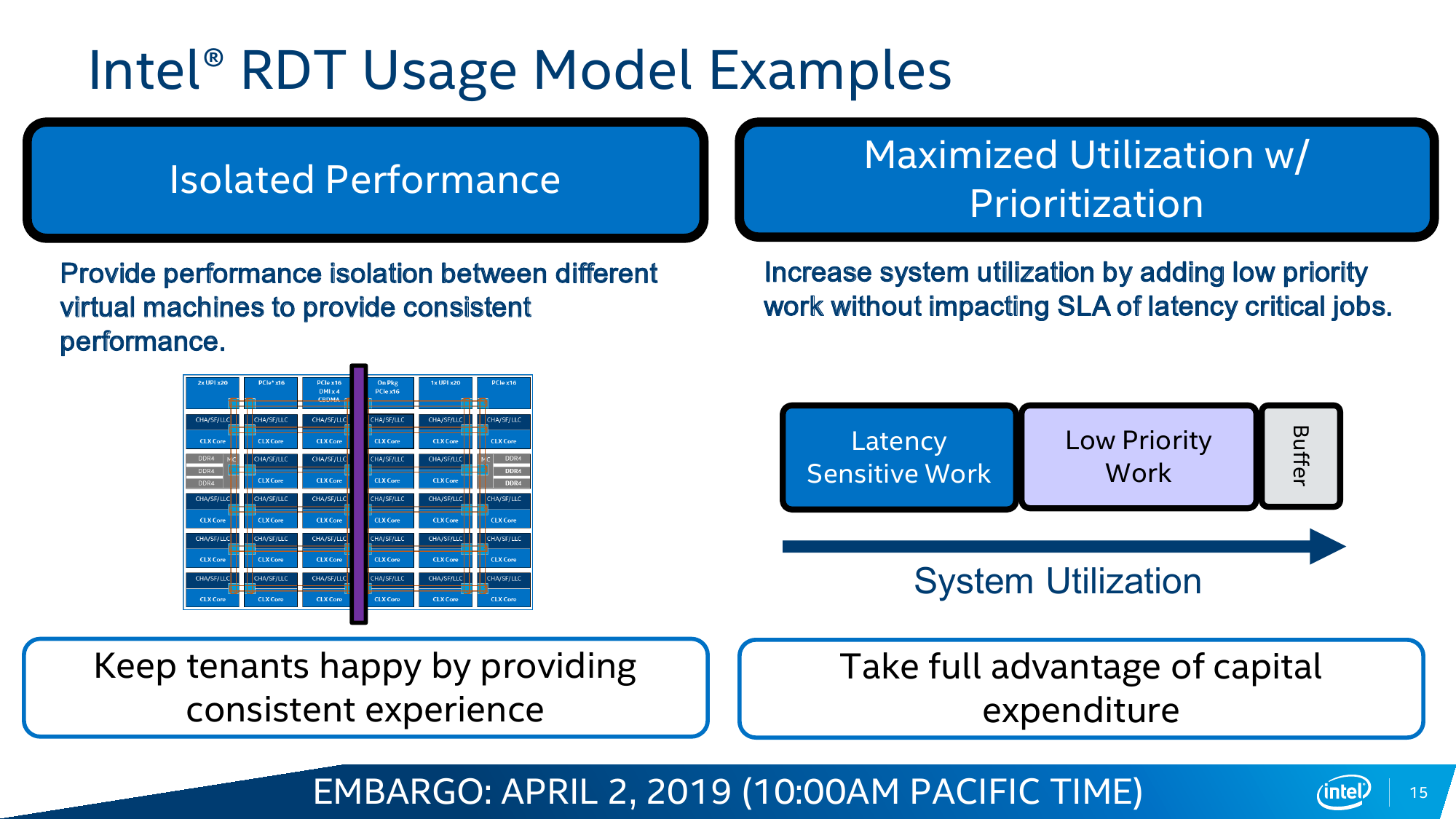

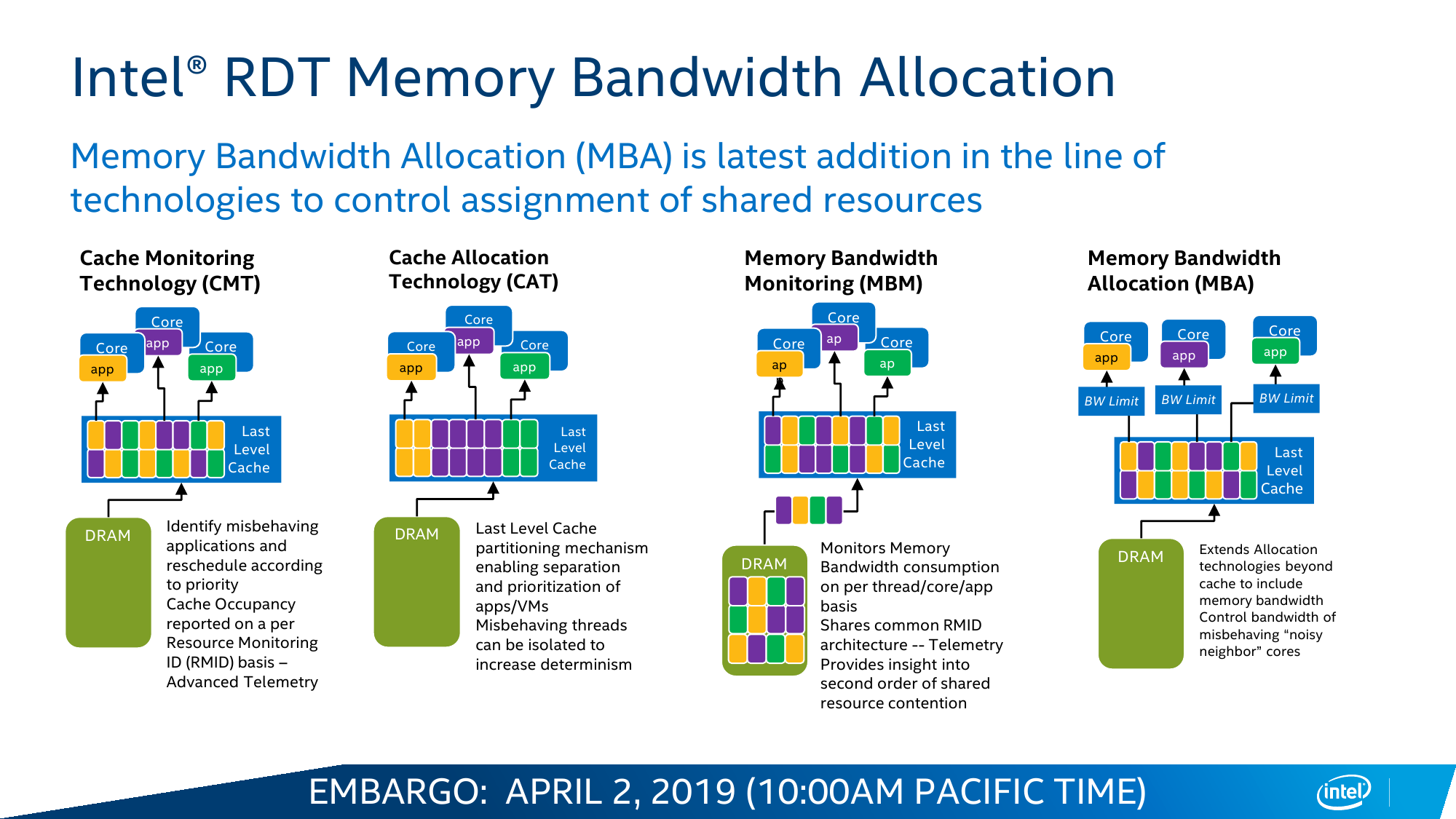
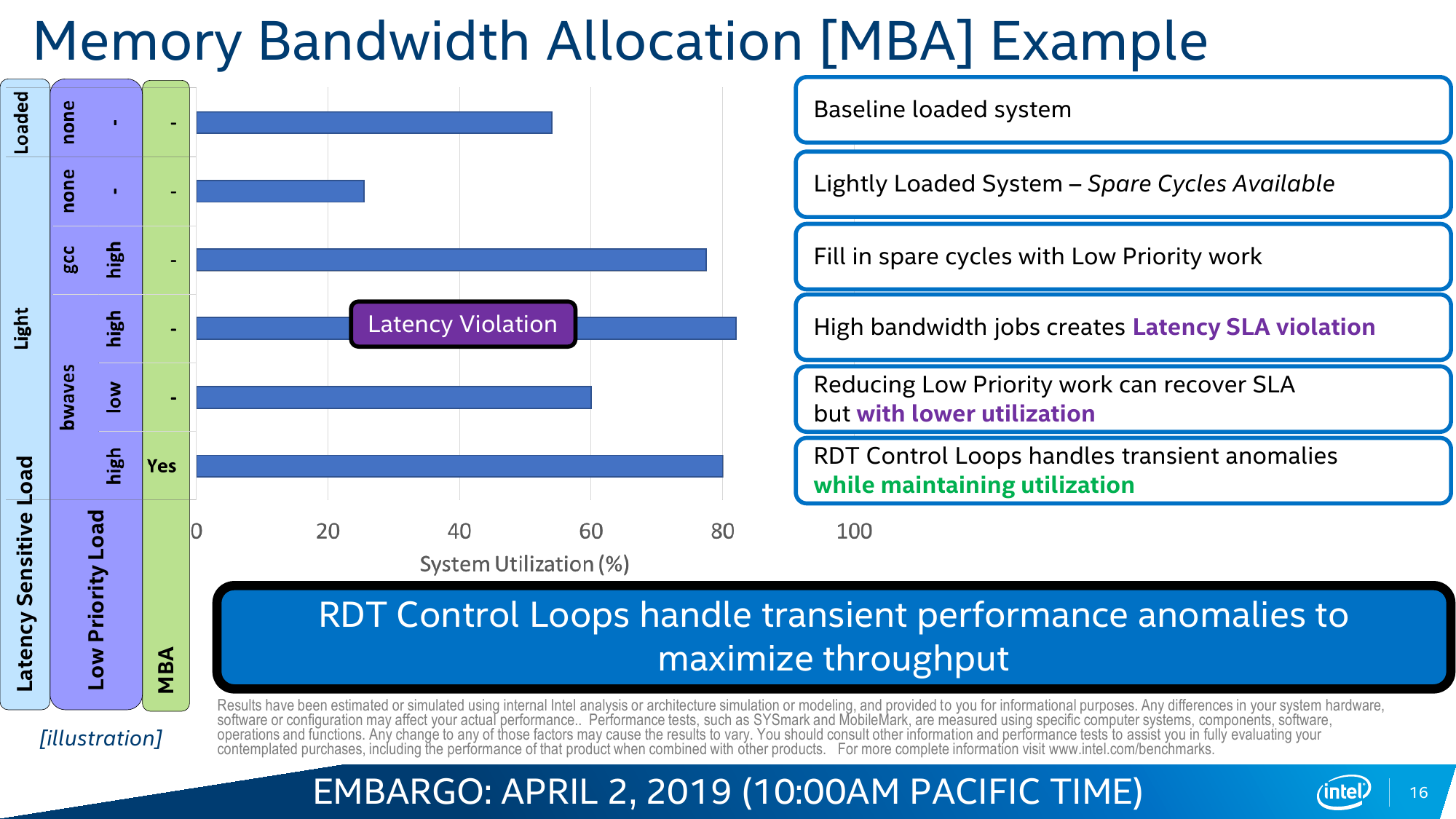

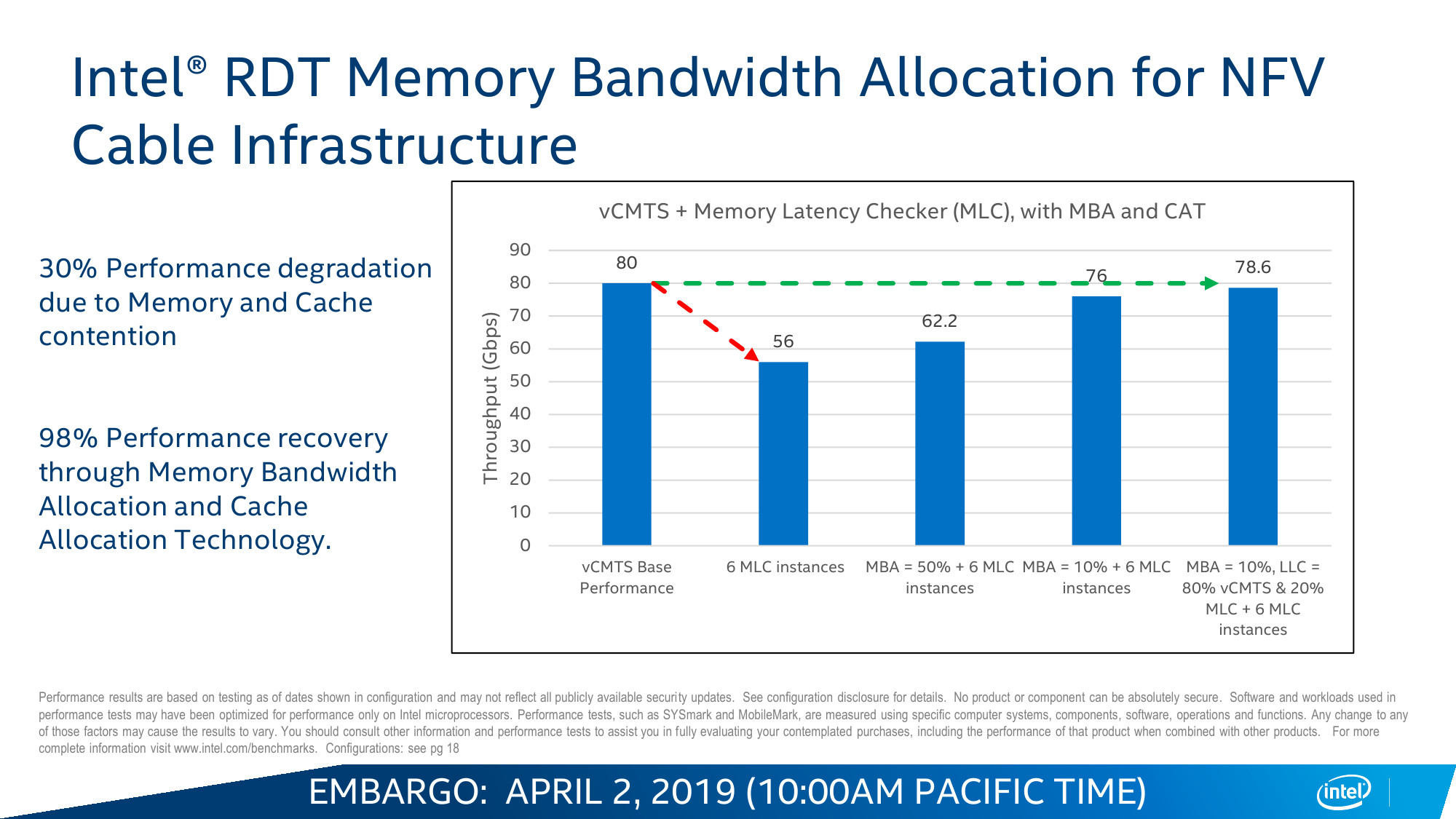

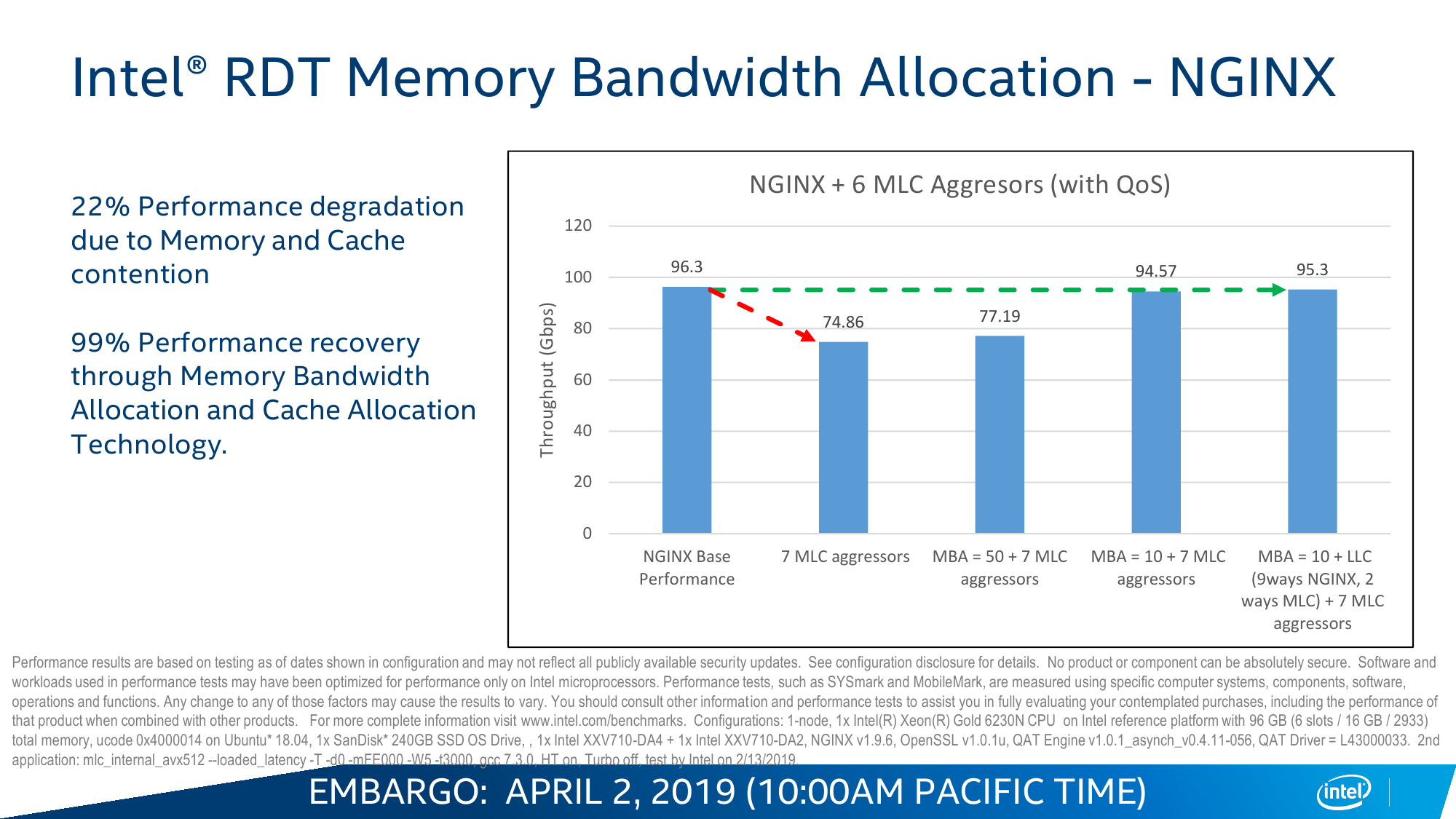
Ровно ту же саму идею приоритизации реализует и технология Speed Select (SST), но уже на уровне ядер. Опять-таки сама по себе она не нова: например, разработчики СХД уже давно программно «навешивают» тяжёлые операции вроде компрессии или дедупликации на отдельные ядра. В Cascade Lake Intel с помощью SST предлагает ещё во время загрузки жёстко выделить группу ядер, которая будет иметь повышенный приоритет над другими. Это заметно повышает предсказуемость поведения ПО и время реакции, а в сочетании с RDT позволяет провести ещё более точный тюнинг.
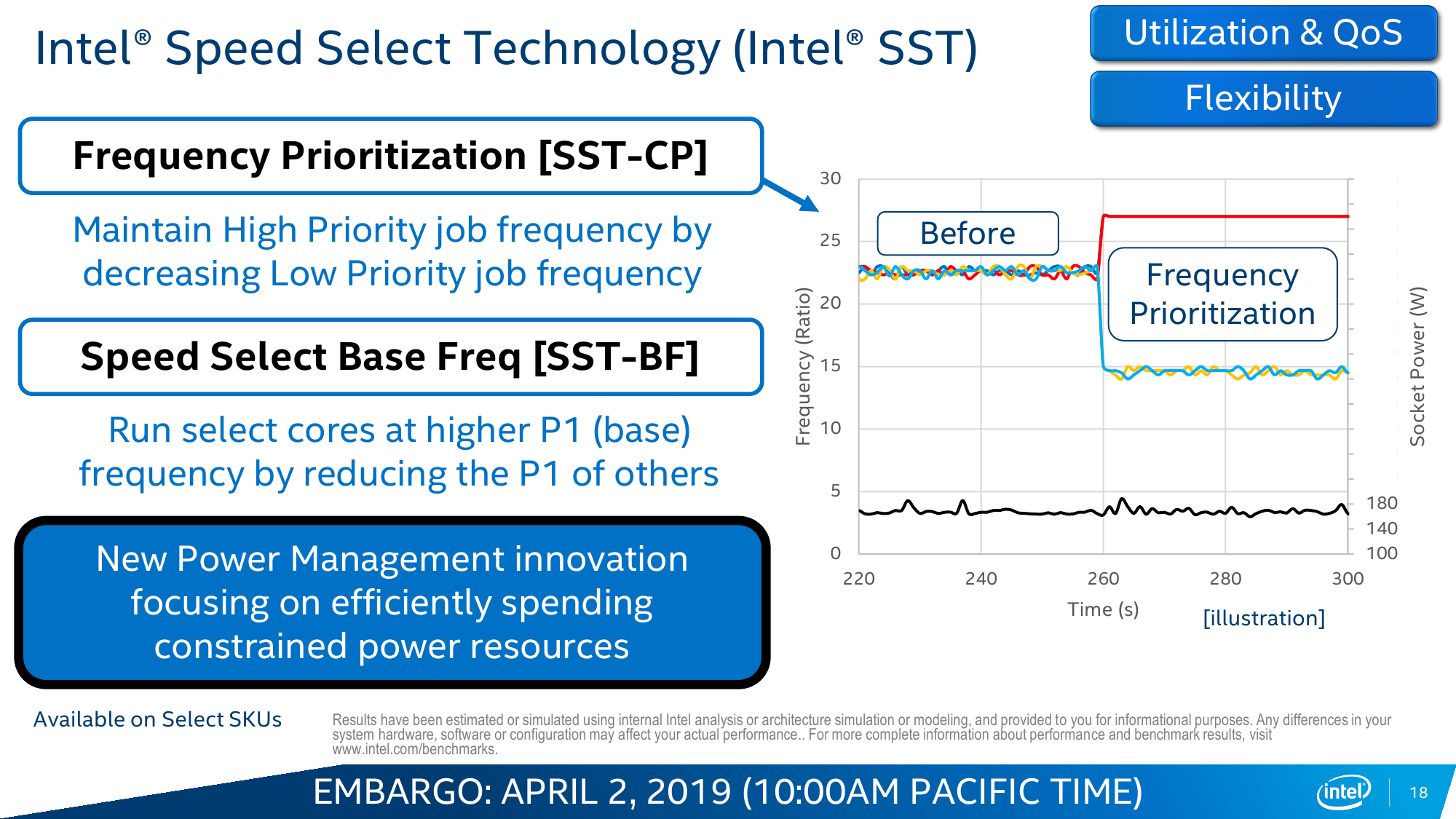

SST предлагает два варианта работы. Первый, то есть SST-CP, динамически снижает частоты более низких по приоритету ядер, когда ядрам с более высоким приоритетом необходимо больше и на более долгий срок задействовать вычислительные ресурсы, что позволяет не упираться в потолок по питанию и охлаждению. Проще говоря, на турбочастотах такие ядра будут работать дольше. Второй вариант — SST-BF — устроен проще. В этом случае группа привилегированных ядер постоянно работает на более высокой базовой частоте, чем стандартная, а для всех остальных базовая частота, что очевидно, снижается. Всего можно задать три различных профиля поведения групп ядер. В наиболее общем виде SST представлена в маленькой серии процессоров Y. Заранее адаптированными вариациями являются серии N и S.
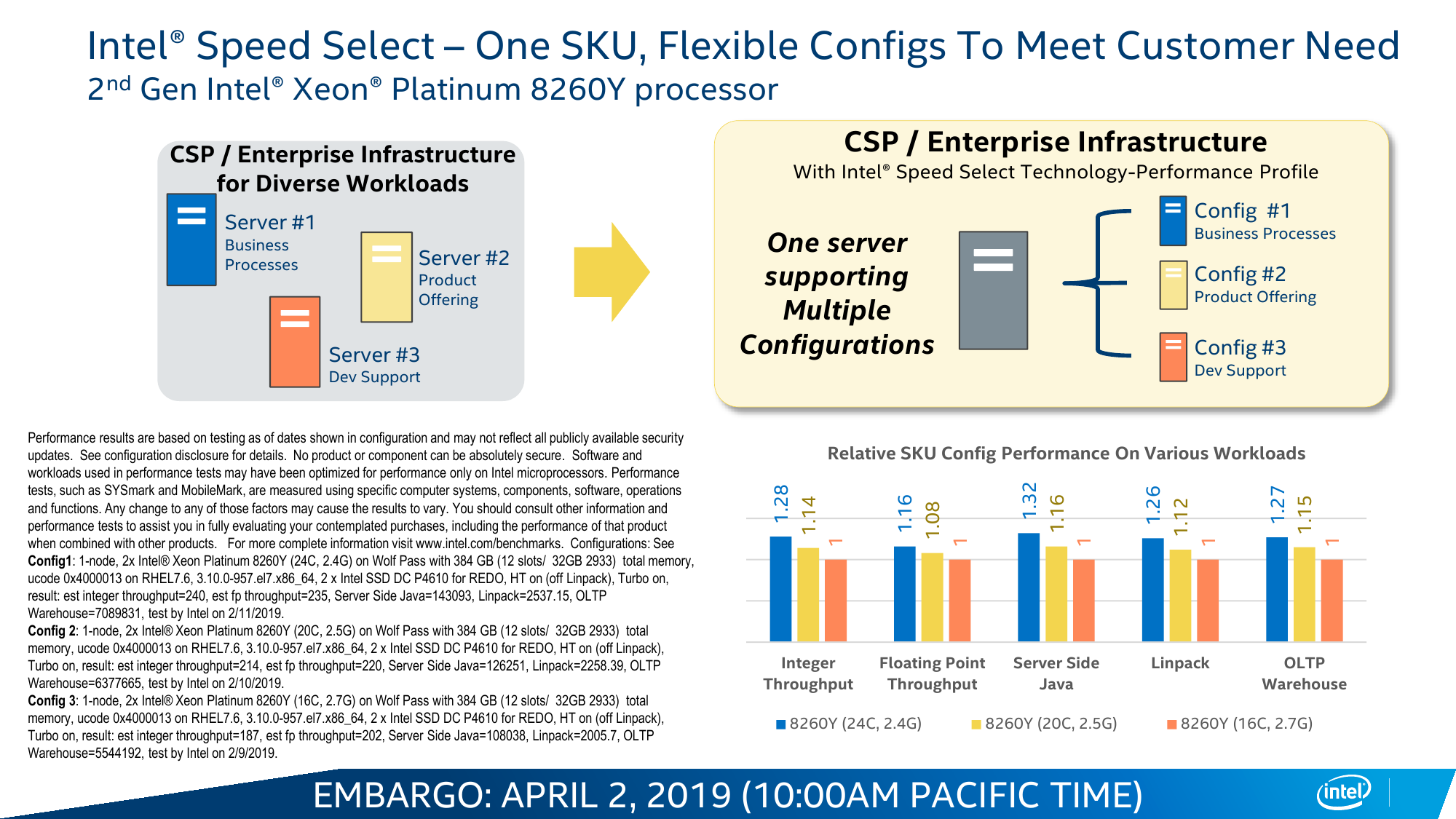
Единственный представитель последней ориентирован на работу с поиском — в первую очередь в базах данных. Но это больше касается тех систем, где требуется предсказуемая и по возможности малая задержка. Аналогичная задача возложена и на серию N, которая специально создана для виртуализации сетевых функций, или, проще говоря, для SDN во всём их многообразии, популярность которых стремительно растёт. Они же могут быть полезны не только в ЦОД или облаках, но и на пограничных (edge) узлах, предварительно обрабатывая, к примеру, IoT-трафик. Несмотря на то, что публичный набор SKU этих серий очень невелик, надо полагать, что именно они в виде semi-custom решений — а на таковые в принципе приходится половина всех выпускаемых чипов — будут пользоваться спросом.
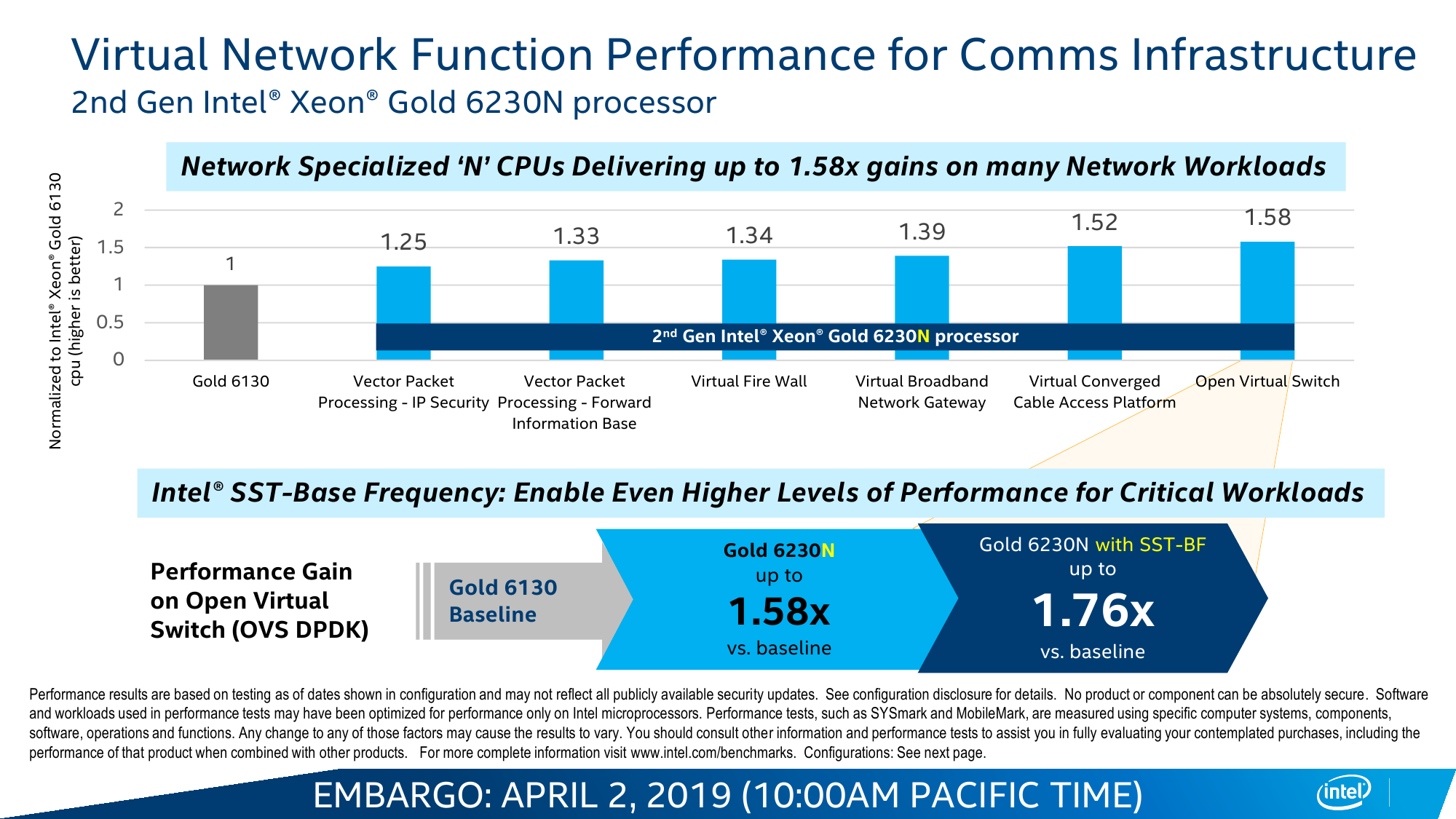
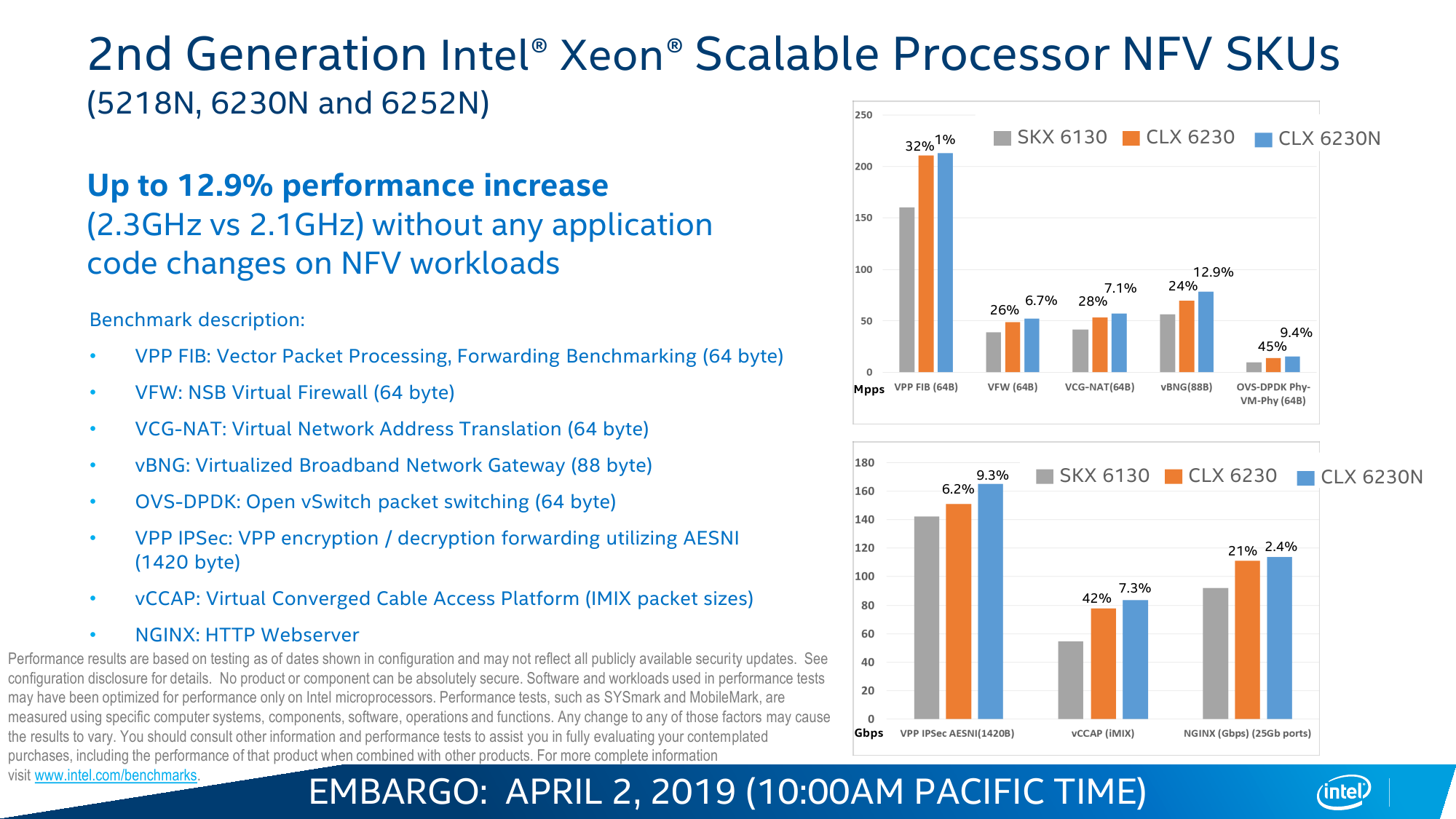

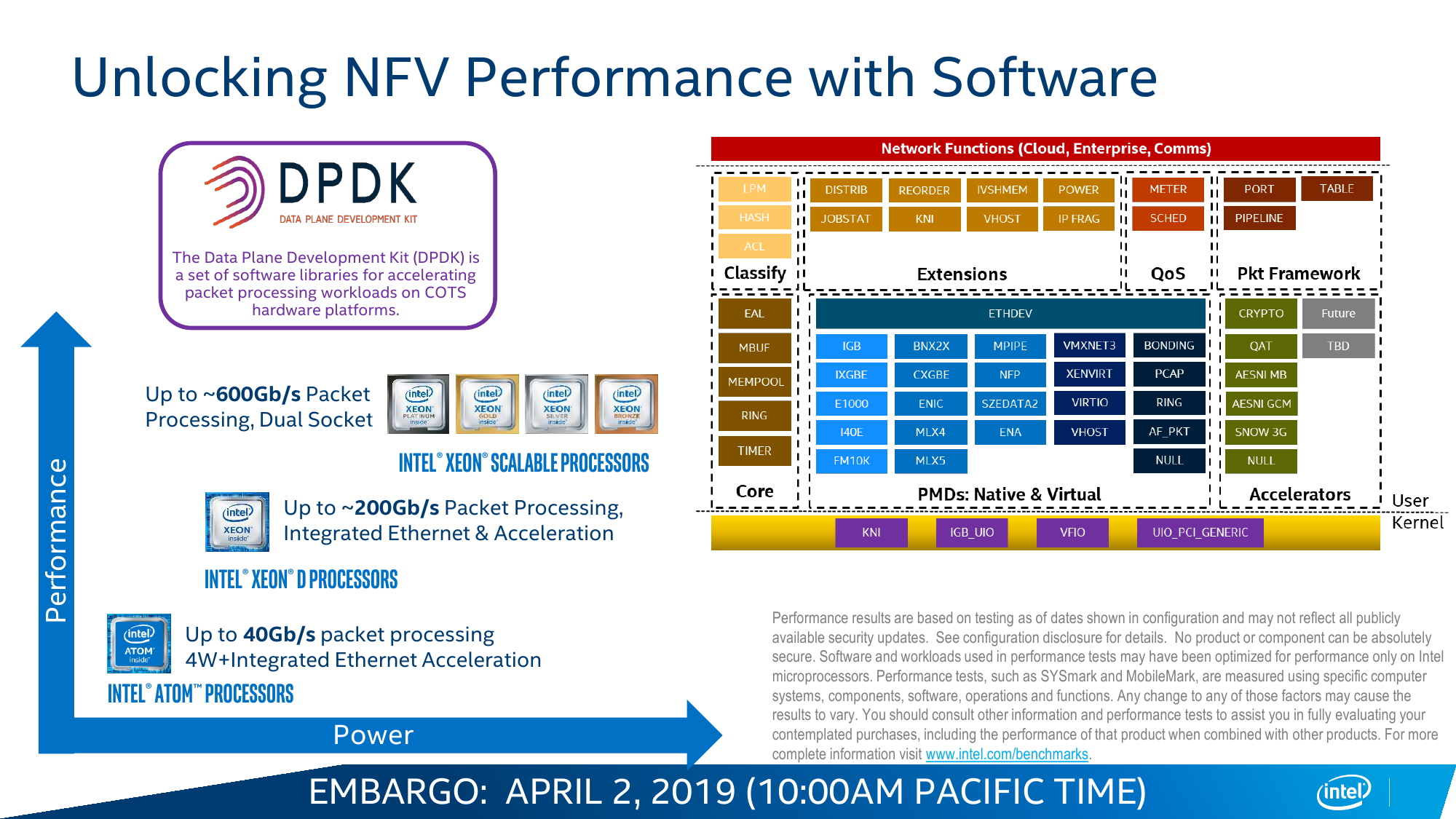





Для N-серии отличным компаньоном должны стать новые Ethernet-контроллеры Intel 800 и софт DPDK вкупе с RDT. Контроллеры в дополнение к давно уже представленной технологии Quick Assist Technology обзавелись эволюционировавшей компонентой eXpress Data Path (AF_XDP), выносящей обработку трафика в пространство пользователя и позволяющей приложениям напрямую общаться с контроллером. Другое важное обновление касается Application Device Queues (ADQ) и Dynamic Device Personalization (DDP). ADQ позволяет приоритизировать трафик для приложений, а DDP дает возможность классифицировать его путём разбора пакетов на лету по заданным правилам. Всё вместе позволяет весьма тонко оптимизировать работу сетевых приложений на всём цикле исполнения: от обращений к диску и памяти до отправки пакетов по назначению.
✴-media" data-instgrm-captioned=" " data-instgrm-permalink="https://www.instagram.com/p/BvG_xOrFnqv/?utm_source=ig_embed&utm_medium=loading" data-instgrm-version="12" rel="nofollow" target="_blank">
Intel DL Boost
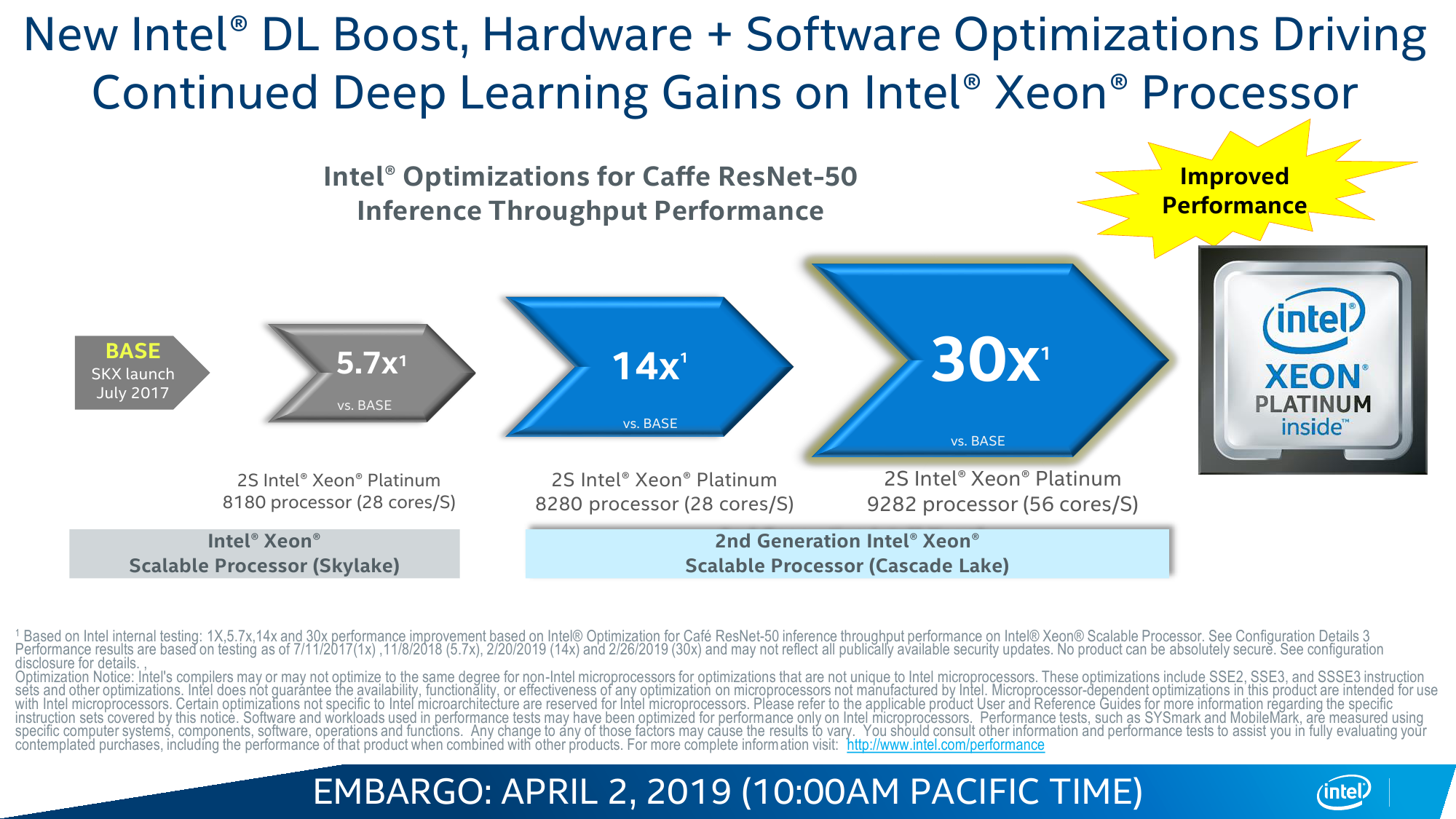
Следующее нововведение касается нового набора инструкций, носивших ранее кодовое имя VNNI — Vector Neural Network Instructions. История тут довольно проста. Рост потребностей в системах с ИИ (давайте уж для простоты обобщённо называть их так, пусть это и не совсем корректно) очевиден. И если с процессом обучения, который проходит на GPU или скорее уже специализированных ускорителях, Intel ничего поделать пока не может, то вот с запуском натренированных моделей ситуация ровно обратная — по словам компании, на практике до 80 % таких нагрузок исполняется на CPU. В том числе потому, что процесс этот на порядки менее требовательный, чем обучение, а также благодаря более лёгкой масштабируемости, ну и за счёт того, что далеко не всегда есть необходимость покупать для этого специальные карты, которые хоть и высокопроизводительны, но не дёшевы.
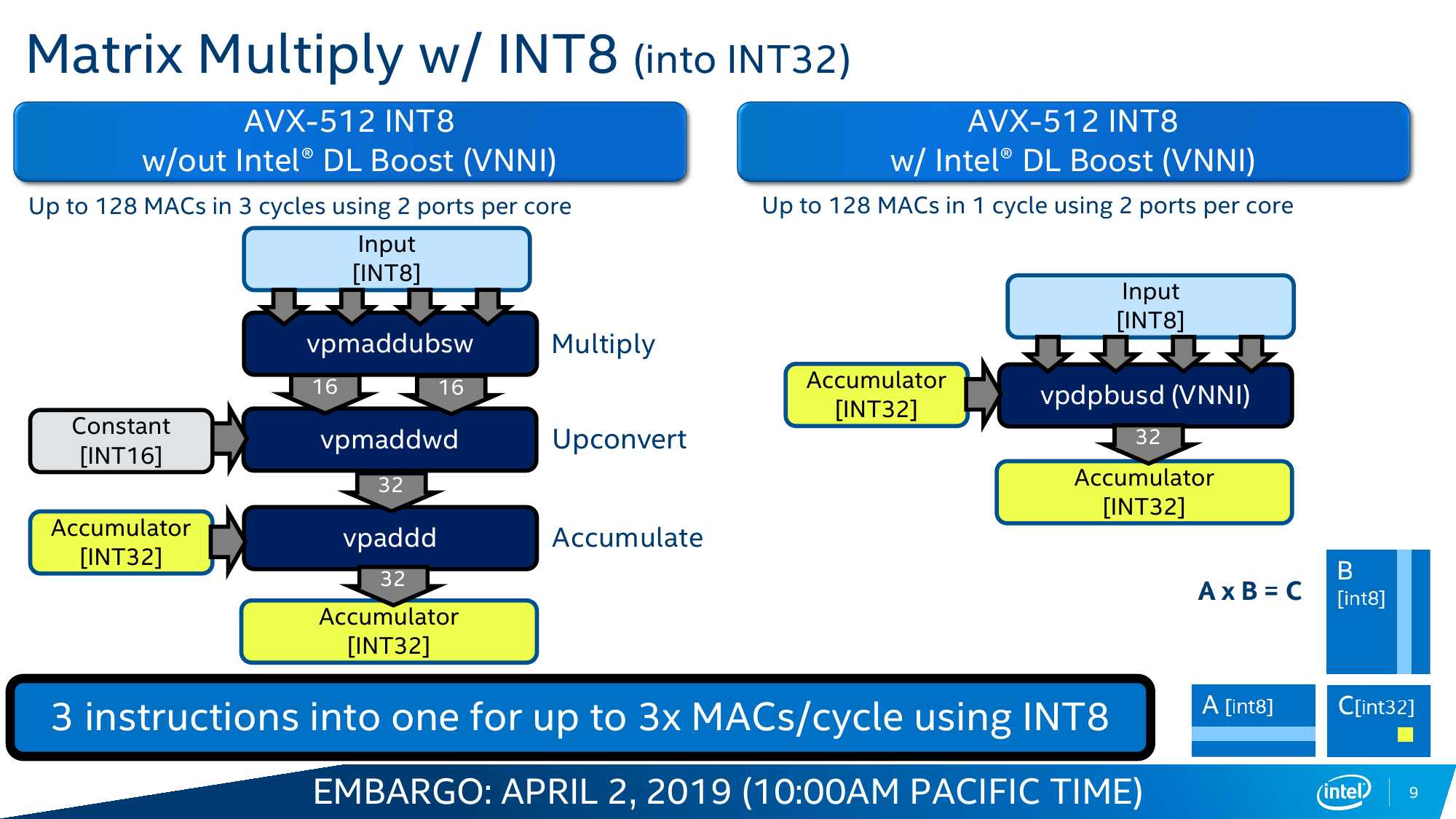

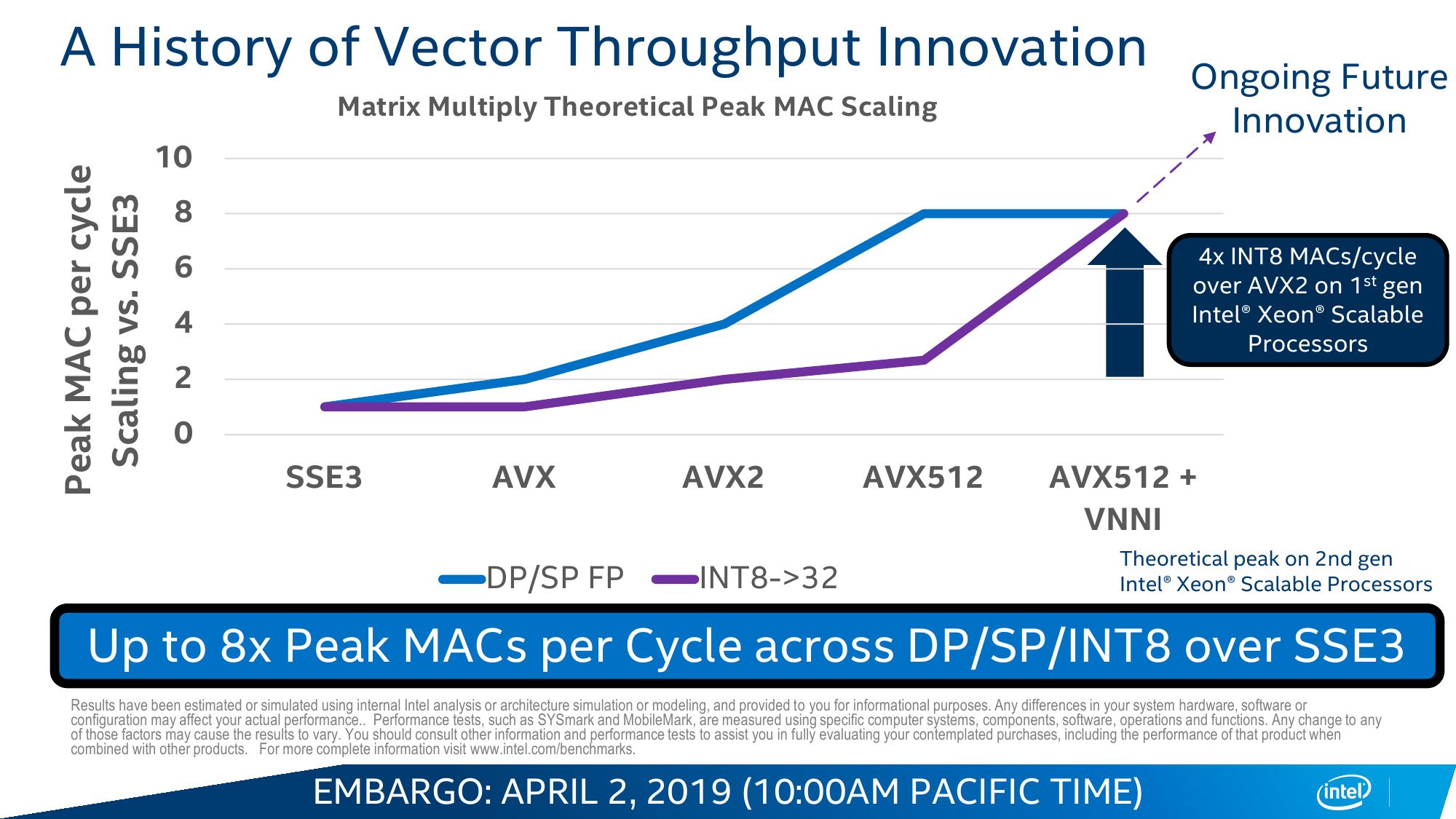
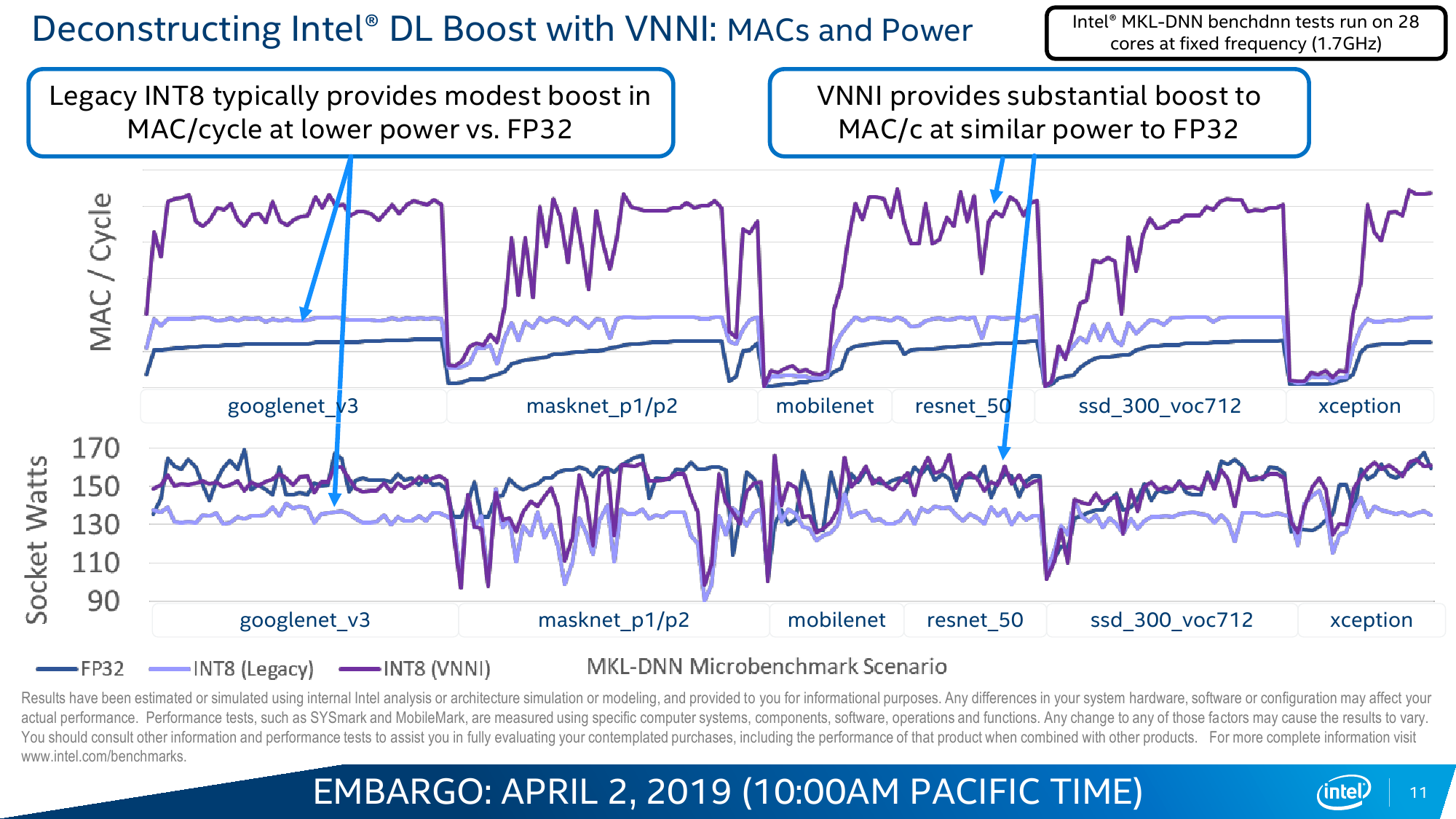
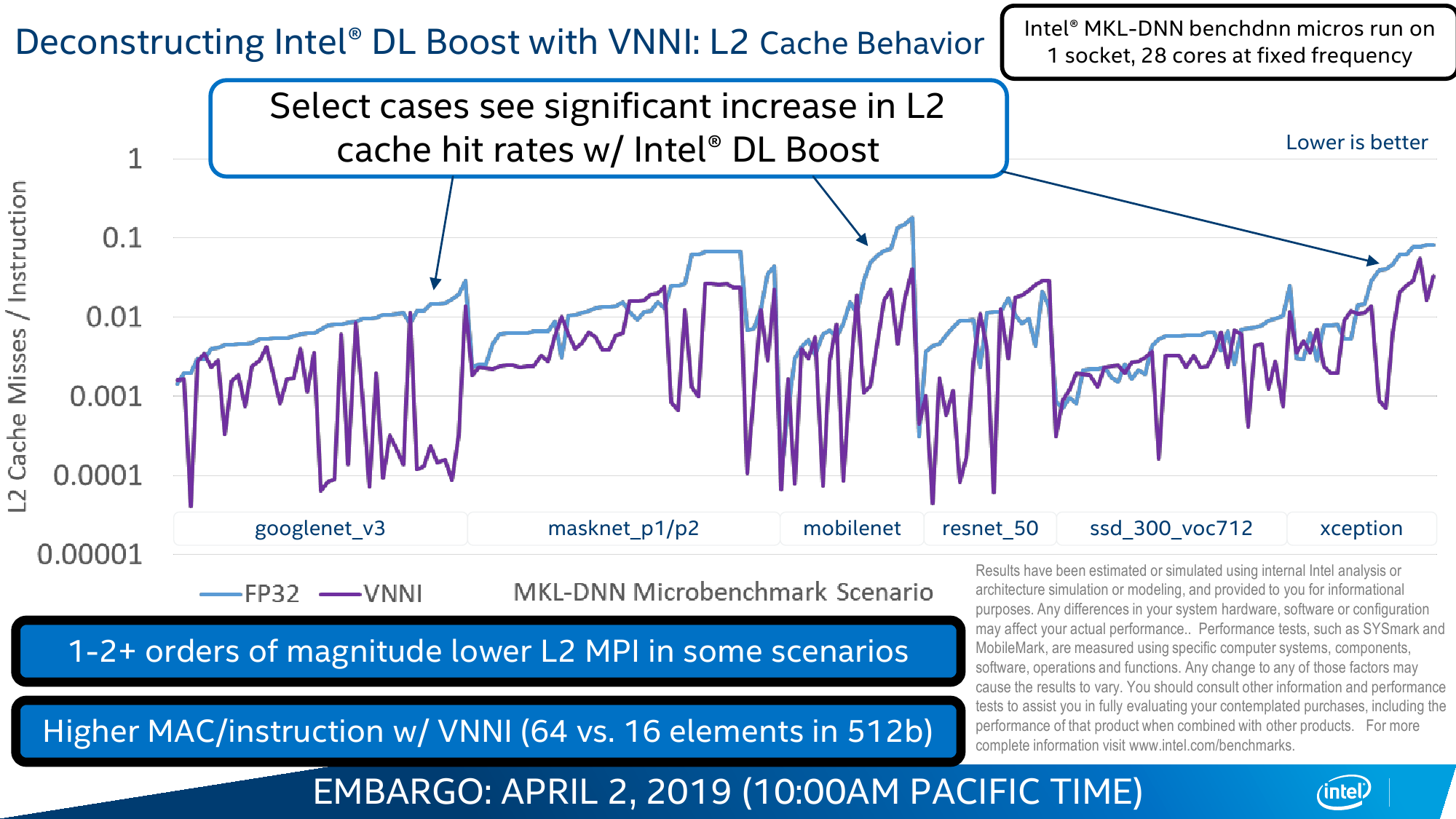
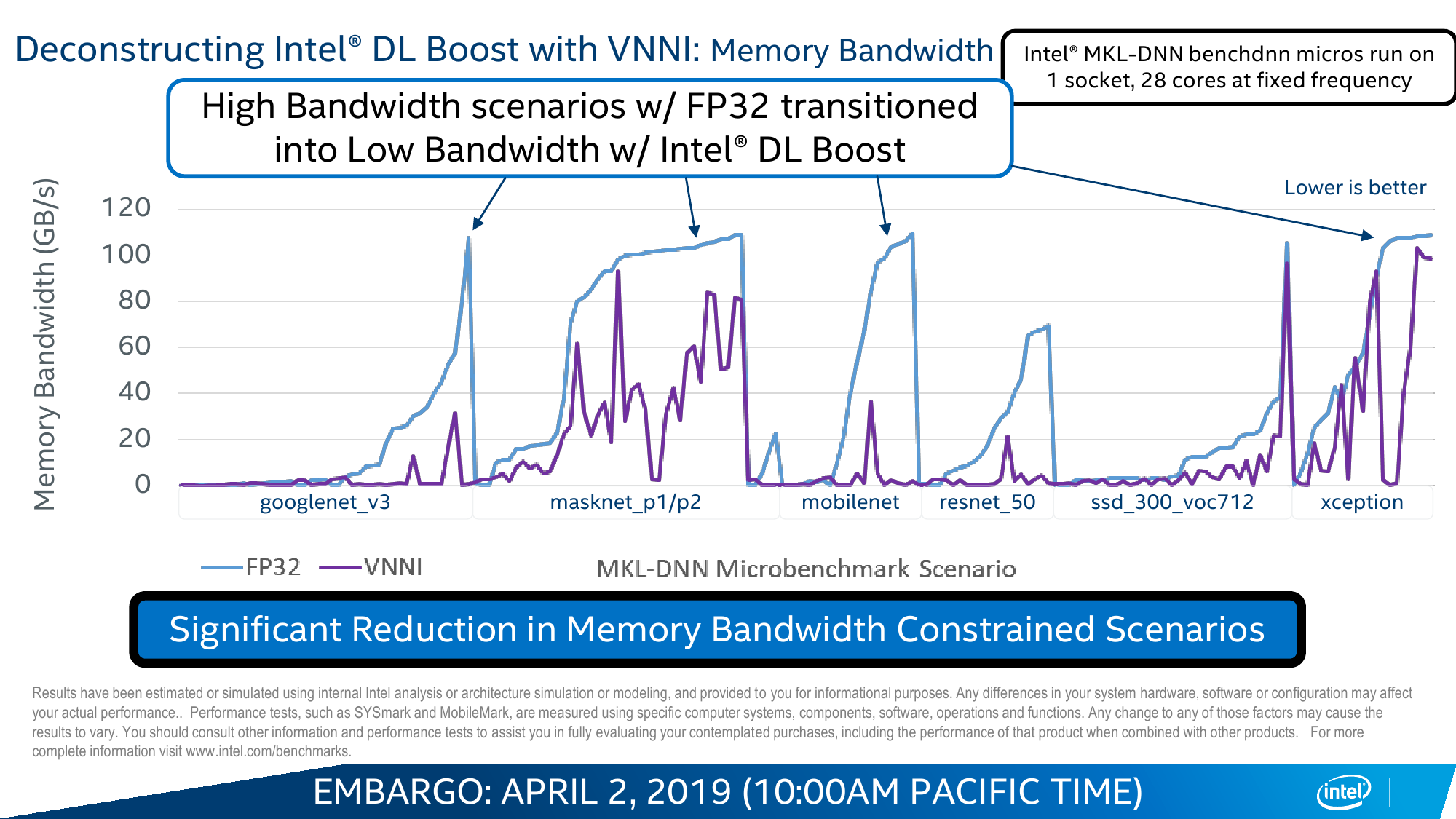
Вот на последний пункт — универсальность CPU вкупе с изрядно возросшей в таких задачах производительностью — Intel и напирает. Никакой магии тут, конечно, нет. VNNI, по сути, — всего лишь ещё одна надстройка над AVX-512, которые и так использовали для запуска моделей. Для формата INT8, который выбран в качестве основного, вместо трёх инструкций для операции MAC теперь нужна всего одна. То есть за цикл один AVX-блок может выполнить до 64 таких операций, а блоков в старших сериях два. Собственно MAC (умножение и сложение) — это базовая операция при работе с матрицами, которые и представляют собой основу нынешних нейронных сетей в общем виде.


Аналогичные операции делают и Tensor-ядра NVIDIA, и блоки Google TPU, и прочие ускорители. Даже в FPGA они появились. Разница — в оптимизации под разные задачи и форматы. У Intel есть и ещё один козырь — OpenVINO Toolkit, который позволяет настроить и оптимизировать исполнение натренированных моделей под конкретную архитектуру. Проект открытый, но изначально разрабатывался внутри Intel, так что её собственное «железо» может получить некоторое преимущество. Сами же Cascade Lake — лишь малая часть всего ИИ-портфолио компании.



Intel Xeon Cascade Lake AP
Описание Cascade Lake AP умышленно сдвинуто в конец материала, потому что эти процессоры не для простых смертных, так сказать. На них даже цена не указывается. Но это как раз понятно, потому что упаковка серии Xeon Platinum 9200 — это BGA5903. Поставляться они будут только в виде уже готовых блоков, предварительно оттестированных и валидированных самой Intel. Собственно AP-процессоры представляют собой сразу два чипа SP в виде MCP под одной теплораспределяющей крышкой. Очевидно, что при TDP от 250 до 400 Вт для каждого процессорного разъёма (а их может на одной плате быть два) требования к системе охлаждения резко возрастают, как и требования к питанию.


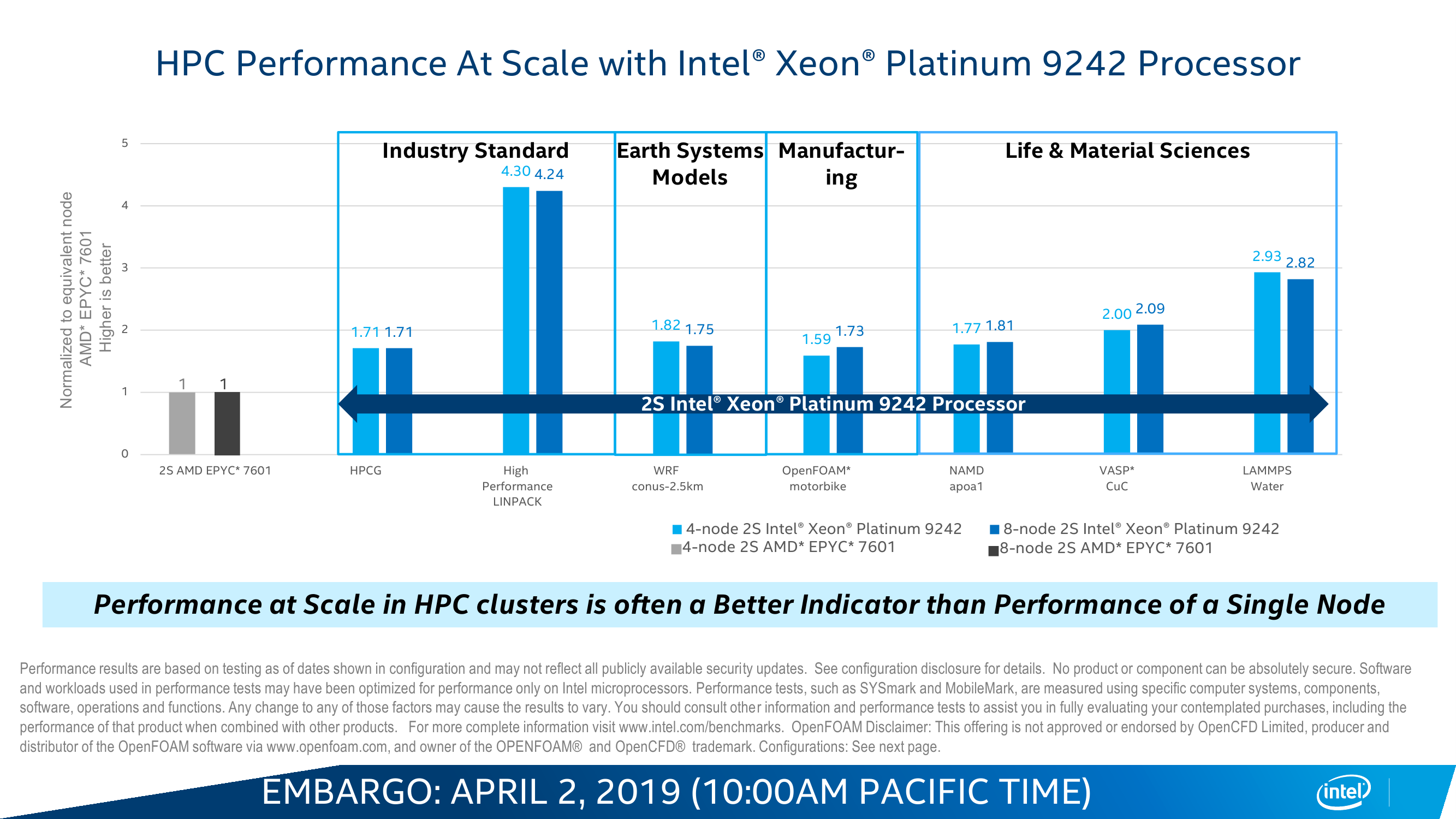
Разводка и самой упаковки, и платы заметно усложняется. А тут ещё и 12 каналов памяти + 40 линий PCI-E + 4 линии UPI для каждого сокета, которые тоже надо вывести. В целом серия AP нужна для повышения плотности размещения ресурсов. Двухсокетная сборка AP — других, похоже, и не предполагается — почти эквивалентна четырёхсокетной из обычных SP, но в гораздо более компактном исполнении. Это пригодится либо для HPC или суперкомпьютеров и ИИ, либо для приложений, которым нужен очень большой локальный объём памяти, для систем аналитики. Формально 9200 AP — это самые лучшие процессоры компании на текущий момент, хотя лидерство здесь достигнуто не совсем привычным путём. Что же, видимо, снова пришла пора мультичиповых сборок.






Для Cascade Lake AP у Intel есть готовые платформы серии S9200WK в чуть непривычном исполнении. В шасси высотой 2U с тремя общими для всех узлов БП можно установить в различных вариантах блоки половиной ширины и высотой 1U или 2U. Каждый блок имеет по два процессора и по 24 слота для памяти. Самый компактный вариант предполагает установку только пары накопителей M.2 и двух низкопрофильных плат PCI-E через райзеры. Варианты покрупнее дают возможность установки ещё двух дополнительных дисков U.2 и ещё двух карт. Для двух из трёх исполнений используются общая СЖО, и лишь один предполагает воздушное охлаждение.

Платформа Intel S9200WK для Xeon Cascade Lake AP







Объединяй и властвуй
Сегодняшний выход новых процессоров можно считать первым этапом глобальным обновления платформы ЦОД, так как во второй половине года будет ещё парочка интересных анонсов. Но и рассматривать Cascade Lake сами по себе тоже немного неправильно — одновременно вышли Xeon-D 1600, Agilex, Ethernet 800. Сама компания называет это крупнейшим запуском в своей истории, стратегически очень важным для неё. Это ответ на текущие запросы индустрии. Мало памяти? Возьмите Optane DC Persistent Memory. Хотите работать с ИИ? Получите новый набор инструкций. Нужна лучшая оптимизация под NFV, но нет готовности заказать semi-custom? Есть и такие CPU. Быстрая сеть с разнообразной разгрузкой? Получите. А ещё есть интерконнект (внутренний и внешний), решения для HPC, пачка FPGA, целая плеяда разнообразнейших Xeon, собственные SSD, ИИ-ускорители, готовые платформы, а скоро будут GPU и, вероятно, квантовые вычислители.

А ещё есть 5G, беспилотные авто и IoT, пути которых тоже заканчиваются в дата-центрах, где есть CPU, FPGA, сеть, накопители… в общем, смотри выше. Всё это постепенно провязывается между собой программными компонентами, в которые Intel вкладывает много сил и денег. Как уже говорилось в самом начале, все это — попытка выстроить единую экосистему продуктов и инфраструктуру будущего, что должно дать преимущество перед другими производителями. И уже вызывает их серьёзные опасения, потому что такие попытки уже были. Сначала на уровне набора чипов, потом на уровне ПК и платформ, а сейчас и вовсе на уровне индустрии. Что это — безоговорочный лидер или колосс на шести глиняных столпах?