Материалы по тегу: graphcore
|
12.10.2025 [14:51], Сергей Карасёв
Graphcore, спасённая SoftBank, воспрянула духом — штат в Великобритании удвоится, а в разработку в Индии инвестируют $1 млрдБританский стартап Graphcore, занимающийся созданием специализированных ИИ-ускорителей, по сообщению Datacenter Dynamics, намерен инвестировать в Индии до $1 млрд в течение следующих 10 лет. При этом в Бангалоре на юге страны будет сформирован кампус для разработки ИИ-решений. Компания Graphcore, основанная в Бристоле в 2016 году, проектирует ускорители нового класса под названием Intelligence Processing Unit (IPU). Архитектура таких изделий основана на применении особых «тайлов» — это область кристалла, содержащая вычислительную логику и некоторое количество быстрой памяти. В июле прошлого года фирму Graphcore за неназванную сумму приобрела японская холдинговая корпорация SoftBank Group, которая активно развивает направление ИИ. Как отмечает Graphcore, на базе нового ИИ-кампуса в Индии будут сформированы около 500 новых рабочих мест. Планируется привлекать специалистов в области проектирования логических схем, дизайна, тестирования и пр. Инженеры Graphcore в Бангалоре займутся разработкой передовых ИИ-решений, которые в перспективе помогут в решении глобальных проблем в области общественного здравоохранения, экологической устойчивости и пр. 
Источник изображения: Graphcore Говорится, что с 2015 года SoftBank Group инвестировала в различные инициативы в Индии более $12 млрд. Создаваемая в Бангалоре площадка будет способствовать реализации комплексной стратегии SoftBank Group по трансформации в ведущего мирового поставщика ИИ-платформ. Напомним, японская корпорация участвует в масштабном проекте Stargate по развитию ИИ-инфраструктуры в США: предполагается, что суммарные затраты в рамках данной инициативы достигнут $500 млрд. Между тем Graphcore заявила о намерении увеличить численность персонала. Ожидается, что в ближайшие два года количество сотрудников в британском представительстве вырастет примерно вдвое, достигнув 750 человек. Речь идёт о привлечении разработчиков чипов и ПО, а также специалистов в сфере ИИ. При этом два года назад состояние компании было не лучшим. Из-за проблем с финансами она закрыла офис в Китае, свернула операции в Норвегии, Японии и Южной Корее, а также сократила пятую часть штата.
11.11.2024 [19:03], Руслан Авдеев
Softbank животворящий: Graphcore активно нанимает персонал для разработки новых ИИ-решенийЧерез четыре месяца после покупки японским конгломератом SoftBank британский стартап Graphcore, разрабатывающий ИИ-ускорители, занялся наймом новых сотрудников. По данным EE Times, сейчас у компании открыто 75 позиций в сферах разработки и тестирования полупроводников, управления инфраструктурой ЦОД и ИИ-исследований. Всего год назад компания спешно искала финансирование и сокращала персонал. Сейчас штат Graphcore насчитывает 375 человек, но компания намерена увеличить количество сотрудников на 20 % в Великобритании, Польше и на Тайване. Прочие офисы, включая подразделение в Китае, закрылись. По словам главы Graphcore Найджела Туна (Nigel Toon), компания представляет собой место, где эксперты по полупроводникам, ПО, ИИ и т.п. могут и полностью реализовать себя. Тем не менее, производственные планы бизнеса пока не раскрываются. 
Источник изображения: Graphcore На момент покупки Graphcore имела в своём портфолио три поколения чипов. Однако последнее поколение Bow IPU, выпущенное в 2022 году, по большому счёту являлось апгрейдом продукта второго поколения от 2020 года. Модель имела 892 Мбайт набортной SRAM, дополненной внешней DDR-памятью, а не HBM. Другими словами, теоретически продукт не слишком подходит для обучения больших языковых моделей (LLM). Впрочем, Cerebras тоже использует SRAM в составе своих суперчипов, но последняя дополнена массивами гибридной памяти MemoryX. А SambaNova в SN40L в итоге пришла к сочетанию SRAM, HBM и DDR. Если Graphcore намерена создать новое поколение ИИ-ускорителей, то она, вероятно, пойдёт по пути SambaNova, считают в EE Times. На это косвенно указывает вакансия инженера ЦОД, для которой желателен опыт работы с жидкостным охлаждением. Также компании требуются специалисты для работы над облачными платформами и инфраструктурой ЦОД. Не исключено, что компания сменит бизнес-модель на манер Groq, продавая не ускорители, а доступ к ИИ-сервисам. Cerebras и SambaNova, например, уже успели по очереди похвастаться производительностью своих инференс-платформ. В случае Graphcore смещение фокуса на инференс открывает возможности для освоения корпоративных и суверенных ИИ-решений, которых ещё не было, когда последние чипы компании вышли на рынок. Тем не менее, пока нет данных, готов ли SoftBank обеспечить Graphcore достаточными средствами для развития больших ЦОД.
12.07.2024 [11:32], Руслан Авдеев
SoftBank приобрела британского разработчика ИИ-ускорителей GraphcoreЯпонская SoftBank, уже владеющая британским разработчиком процессоров Arm, приобрела британскую же компанию Craphcore, занятую разработкой ИИ-ускорителей. По данным The Register, сумма потенциальной сделки не называется, но по некоторым оценкам она составит $600 млн — для сравнения, Graphcore привлекла $700 млн в ходе всех раундов финансирования. Graphcore официально объявила о сделке в четверг, а её глава Найджел Тун (Nigel Toon) публично одобрил её, подчеркнув, что спрос на ИИ-вычисления сейчас высок и продолжает расти, а SoftBank является тем партнёром для Graphcore, который поможет «изменить ландшафт» ИИ-технологий. Штаб-квартира компании по-прежнему останется в Бристоле. Ключевые активы компании — ИИ-ускорители Intelligence Processing Units (IPU), а также стек ПО. Хотя вычислительные системы BOW POD16 оказались производительнее NVIDIA DGX A100, процветания в компании не дождались и рассматривали продажу ещё в феврале 2024 года. 
Источник изображения: Graphcore Несмотря на первоначальный успех, бизнес не смог стать прибыльным. В 2022 году выручка составила всего $2,7 млн — на 46 % меньше год к году, операционные расходы составили $206,8 млн. После этого начались увольнения — по словам представителей компании, необходимые для того, чтобы удержать бизнес на плаву. Более того, компания даже стала получать иски. Сотрудничество с китайскими бизнесами могло бы вывести Graphcore из тупика, но США ограничили продажи высокопроизводительных ускорителей в КНР. Тем временем NVIDIA закрепила своё влияние на рынке решений для генеративных ИИ-систем. Тун прогнозирует, что SoftBank, наконец, даст возможность Graphcore составить конкуренцию лидерам отрасли. 
Источник изображения: Graphcore По словам SoftBank Investment Advisers, новое поколение полупроводников и вычислительных систем имеет чрезвычайное значение для работ над т.н. «общим искусственным интеллектом» (AGI), поэтому SoftBank рада сотрудничать с Graphcore. При этом в SoftBank не акцентируют внимание на том, что компания уже является владельцем контрольного пакета акций британской Arm, на решениях которой строятся многие современные полупроводники. Последняя имеет собственные амбиции и намерена представить альтернативу решениям NVIDIA. Graphcore предлагает ещё одну альтернативу и уже имеет готовое техническое решение. С учётом финансовых ресурсов SoftBank и связей с Arm, компания, возможно, получит второе дыхание для нового старта. Другими словами, сектор ИИ-инфраструктуры сможет стать более конкурентным, что в любом случае пойдёт на благо покупателей.
05.03.2022 [01:28], Алексей Степин
Graphcore анонсировала ИИ-ускорители BOW IPU с 3D-упаковкой кристаллов WoWРазработка специализированных ускорителей для задач и алгоритмов машинного обучения в последние несколько лет чрезвычайно популярна. Ещё в 2020 году британская компания Graphcore объявила о создании нового класса ускорителей, которые она назвала IPU: Intelligence Processing Unit. Их архитектура оказалась очень любопытной. Основной единицей IPU является не ядро, а «тайл» — область кристалла, содержащая как вычислительную логику, так и некоторое количество быстрой памяти с пропускной способностью в районе 45 Тбайт/с (7,8 Тбайт/с между тайлами). В первой итерации чип Graphcore получил 1216 таких тайлов c 300 Мбайт памяти, а сейчас компания анонсировала следующее поколение своих IPU. 
Изображения: Graphcore Новый чип, получивший название BOW, можно условно отнести к «поколению 2,5». Он использует кристалл второго поколения Colossus Mk2: 892 Мбайт SRAM в 1472 тайлах, способных выполнять одновременно 8832 потока. Этот кристалл по-прежнему производится с использованием 7-нм техпроцесса TSMC, но теперь Graphcore перешла на использование более продвинутой упаковки типа 3D Wafer-on-Wafer (3D WoW). Новый IPU стал первым в индустрии чипом высокой сложности, использующем новый тип упаковки, причём технология 3D WoW была совместно разработана Graphcore и TSMC с целью оптимизации подсистем питания. Процессоры такой сложности отличаются крайней прожорливостью, а «накормить» их при этом не просто. В итоге обычная упаковка не позволяет добиться от чипа уровня Colossus Mk2 максимальной производительности — слишком велики потери и паразитный нагрев. 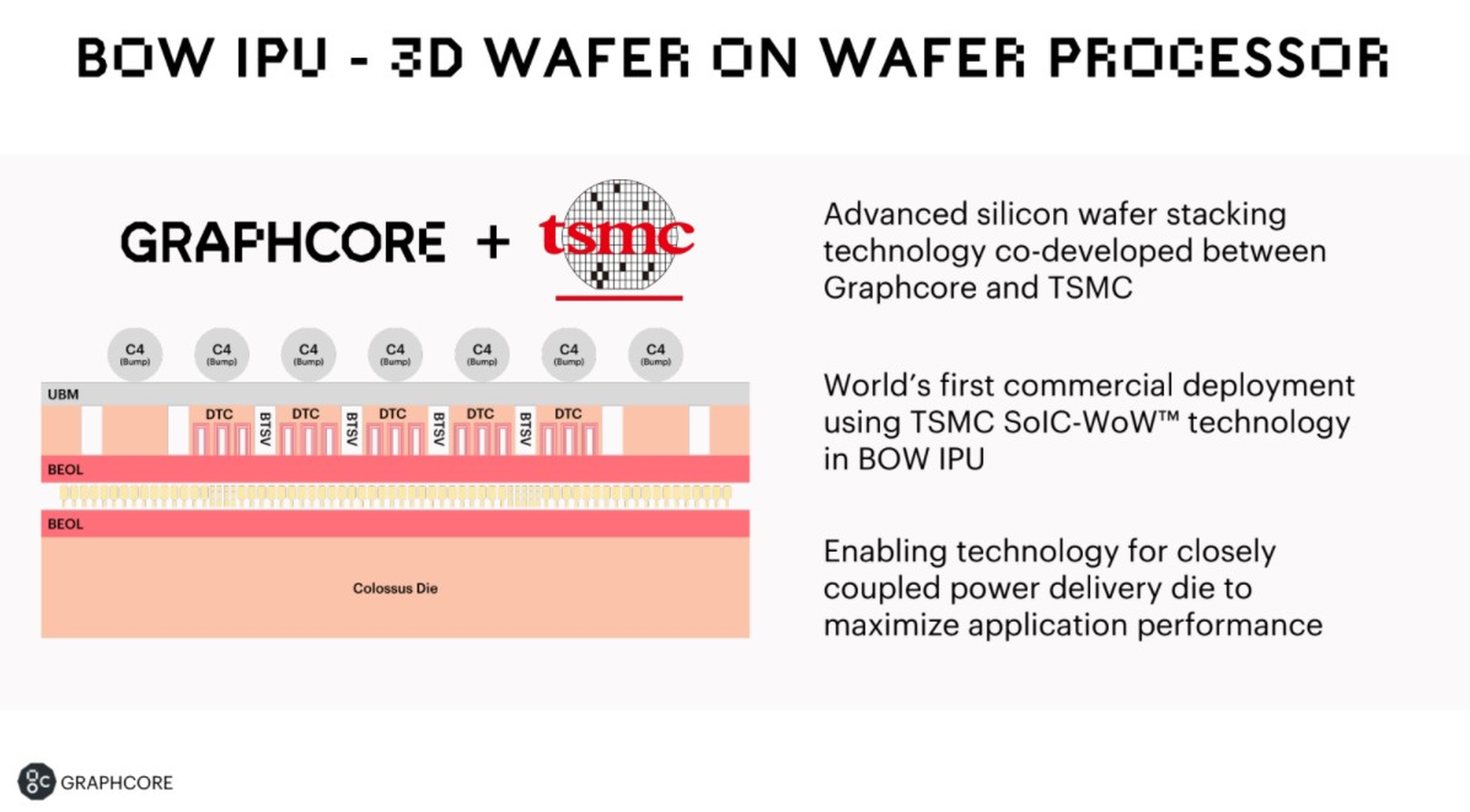 Реализована 3D WoW во многом аналогично технологии, применённой AMD в серверных чипах Milan-X. Упрощённо говоря, медные структуры-стержни пронизывают кристалл и позволяют соединить его напрямую с другим кристаллом, причём «склеиваются» они друг с другом благодаря. В случае с BOW роль нижнего кристалла отводится распределителю питания с системой стабилизирующих конденсаторов, который питает верхний кристалл Colossus Mk2. За счёт перехода с плоских структур на объёмные можно как увеличить подводимый ток, так и сделать путь его протекания более короткими. В итоге компании удалось дополнительно поднять частоту и производительность BOW, не прибегая к переделке основного процессора или переводу его на более тонкий и дорогой техпроцесс. Если у оригинального IPU второго поколения максимальная производительность составляла 250 Тфлопс, то сейчас речь идёт уже о 350 Тфлопс — для системы BOW-2000 с четырьмя чипами заявлено 1,4 Пфлопс совокупной производительности. И это хороший выигрыш, полученный без критических затрат. 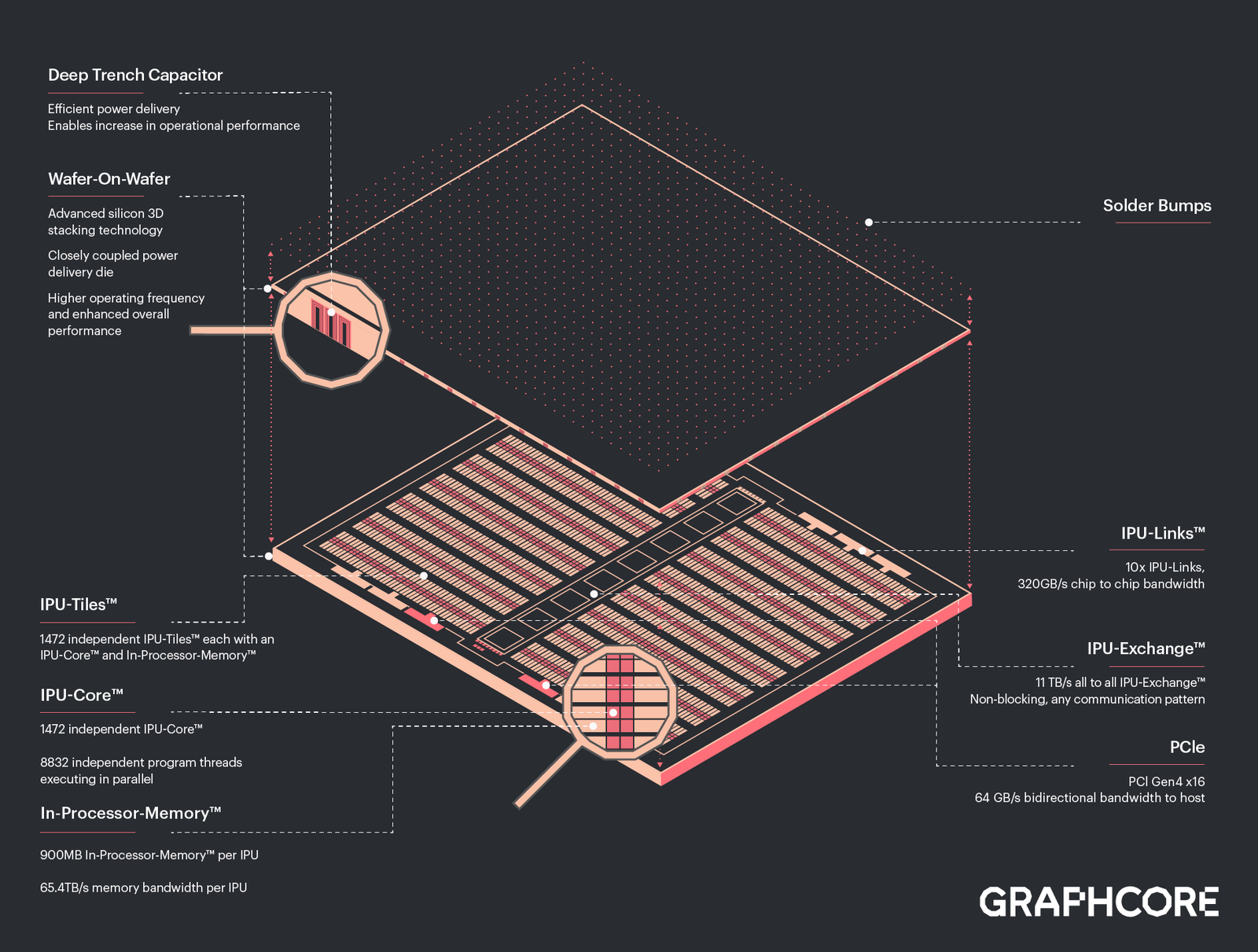 С внешним миром IPU общается по-прежнему посредством 10 каналов IPU-Link (320 Гбайт/с). Внутренней памяти в такой системе уже почти 4 Гбайт, причём работает она на скорости 260 Тбайт/с — критически важный параметр для некоторых задач машинного обучения, которые требуют всё большие по объёму наборов данных. Ёмкость набортной памяти далека от предлагаемой NVIDIA и AMD, но выигрыш в скорости даёт детищу Graphcore серьёзное преимущество. Узлы BOW-2000 совместимы с узлами предыдущей версии. Четыре таких узла (BOW POD16) с управляющим сервером — всё в 5U-шасси — имеют производительность до 5,6 Пфлопс. А полная стойка с 16 узлами BOW-2000 (BOW POD64) даёт уже 22,4 Пфлопс. По словам компании, производительность новой версии возросла на 30–40 %, а прирост энергоэффективности составляет от 10 % до 16 %. 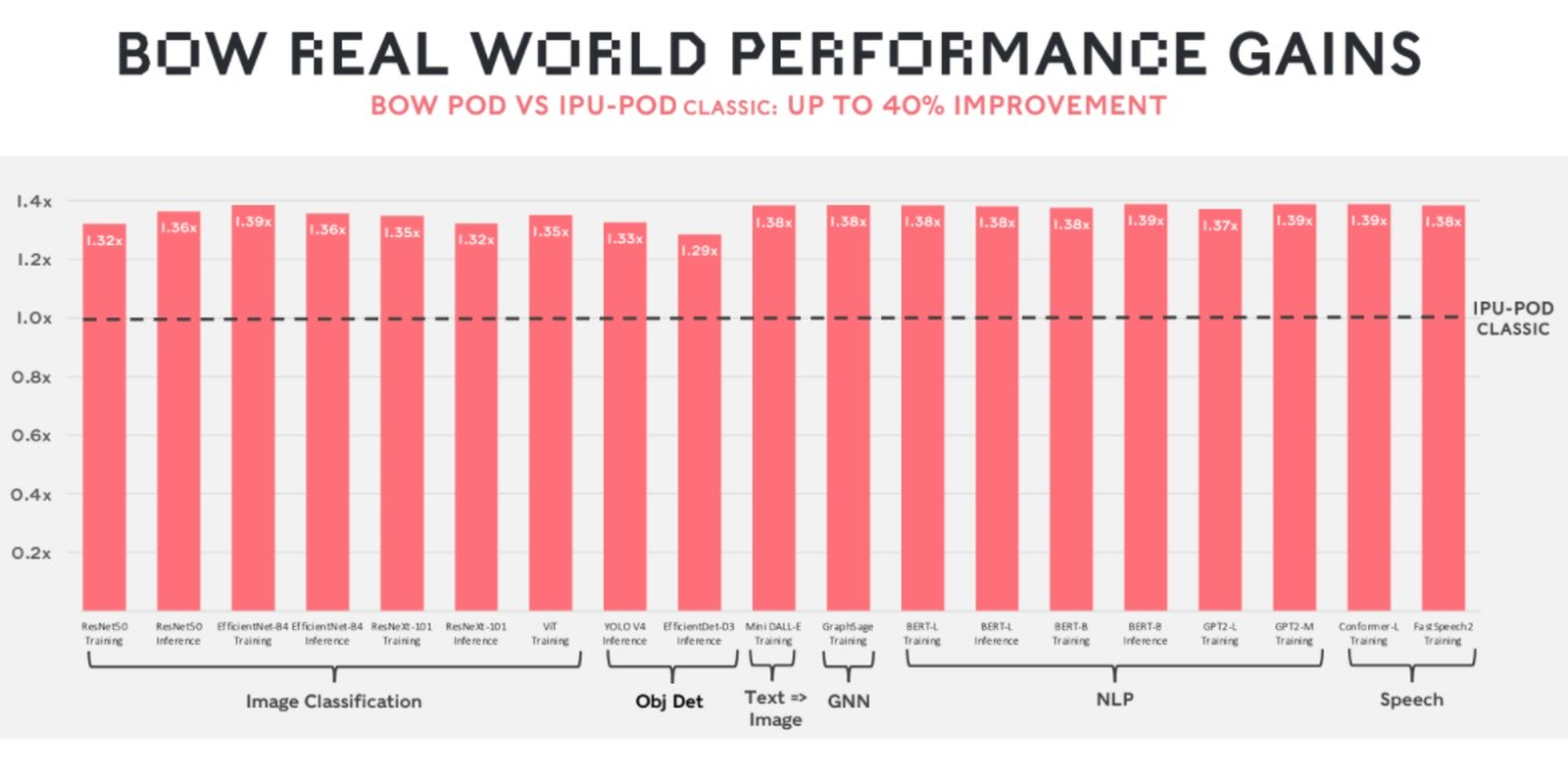 Graphcore говорит о десятикратном превосходстве BOW POD16 над NVIDIA DGX-A100 в полной стоимости владения (TCO). Cтоит BOW POD16 вдвое дешевле DGX-A100. К сожалению, говорить о завоевании рынка машинного обучения Graphcore рано: клиентов у компании уже довольно много, но среди них нет таких гигантов, как Google или Baidu. В долгосрочной перспективе ситуация для Graphcore далеко не безоблачна, но компания уже готовит третье поколение IPU на базе 3-нм техпроцесса.
27.08.2020 [19:13], Алексей Степин
TSMC и Graphcore создают ИИ-платформу на базе технологии 3 нмНесмотря на все проблемы в полупроводниковой индустрии, технологии продолжают развиваться. Технологические нормы 7 нм уже давно не являются чудом, вовсю осваиваются и более тонкие нормы, например, 5 нм. А ведущий контрактный производитель, TSMC, штурмует следующую вершину — 3-нм техпроцесс. Одним из первых продуктов на базе этой технологии станет ИИ-платформа Graphcore с четырьмя IPU нового поколения. Британская компания Graphcore разрабатывает специфические ускорители уже не первый год. В прошлом году она представила процессор IPU (Intelligence Processing Unit), интересный тем, что состоит не из ядер, а из так называемых тайлов, каждый из которых содержит вычислительное ядро и некоторое количество интегрированной памяти. В совокупности 1216 таких тайлов дают 300 Мбайт сверхбыстрой памяти с ПСП до 45 Тбайт/с, а между собой процессоры IPU общаются посредством IPU-Link на скорости 320 Гбайт/с. 
Colossально: ИИ-сервер Graphcore с четырьмя IPU на борту Компания позаботилась о программном сопровождении своего детища, снабдив его стеком Poplar, в котором предусмотрена интеграция с TensorFlow и Open Neural Network Exchange. Разработкой Graphcore заинтересовалась Microsoft, применившая IPU в сервисах Azure, причём совместное тестирование показало самые положительные результаты. Следующее поколение IPU, Colossus MK2, представленное летом этого года, оказалось сложнее NVIDIA A100 и получило уже 900 Мбайт сверхбыстрой памяти.  Машинное обучение, в основе которого лежит тренировка и использование нейронных сетей, само по себе требует процессоров с весьма высокой степенью параллелизма, а она, в свою очередь, автоматически означает огромное количество транзисторов — 59,4 млрд в случае Colossus MK2. Поэтому освоение новых, более тонких и экономичных техпроцессов является для этого класса микрочипов ключевой задачей, и Graphcore это понимает, заявляя о своём сотрудничестве с TSMC. 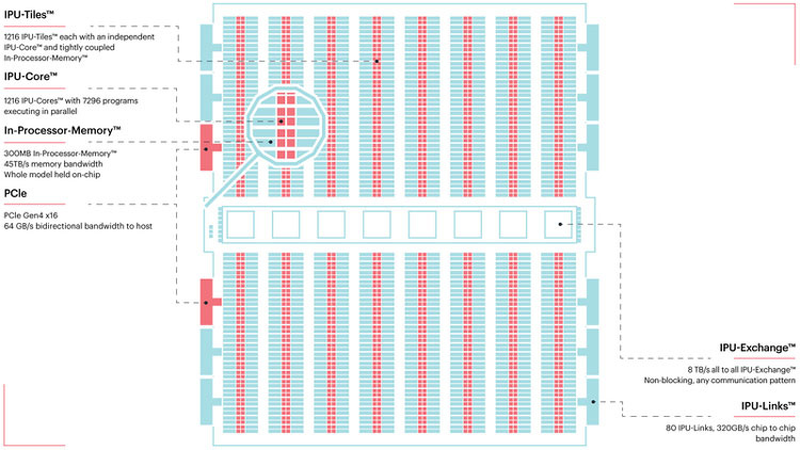
Тайловая архитектура Graphcore Colossus MK2 В настоящее время TSMC готовит к началу «рискового» производства новый техпроцесс с нормами 3 нм, причём скорость внедрения такова, что первые продукты на его основе должны увидеть свет уже в 2021 году, а массовое производство будет развёрнуто во второй половине 2022 года. И одним из первых продуктов на базе 3-нм технологических норм станет новый вариант IPU за авторством Graphcore, известный сейчас как N3. Судя по всему, использовать 5 нм британский разработчик не собирается. 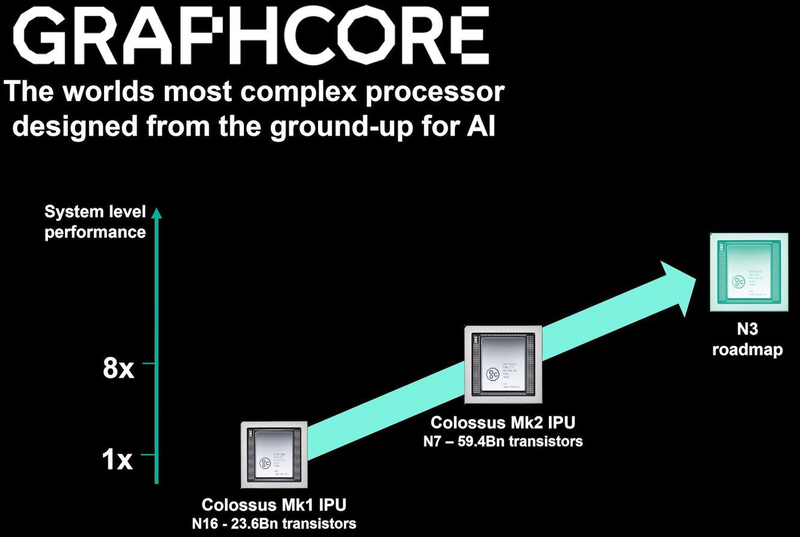
В планах компании явно указано использование 3-нм техпроцесса В настоящее время чипы Colossus MK2 производятся с использованием техпроцесса 7 нм (TSMC N7). Они включают в себя 1472 тайла и способны одновременно выполнять 8832 потока. В режиме тренировки нейросетей с использованием вычислений FP16 это даёт 250 Тфлопс, но существует удобное решение мощностью 1 Пфлопс — это специальный 1U-сервер Graphcore, в нём четыре IPU дополнены 450 Гбайт внешней памяти. Доступны также платы расширения PCI Express c чипами IPU на борту. Дела у Graphcore идут неплохо, её технология оказалась востребованной и среди инвесторов числятся Microsoft, BMW, DeepMind и ряд других компаний, разрабатывающих и внедряющих комплексы машинного обучения. Разработка 3-нм чипа ещё более упрочнит позиции этого разработчика. Более тонкие техпроцессы существенно увеличивают стоимость разработки, но финансовые резервы у Graphcore пока есть; при этом не и исключён вариант более тесного сотрудничества, при котором часть стоимости разработки возьмёт на себя TSMC. |
|

