Материалы по тегу: ipu
|
10.04.2026 [23:09], Владимир Мироненко
Intel поставит Google несколько поколений Xeon и IPUIntel и Google объявили об углублении многолетнего партнёрства в области инфраструктуры ИИ и облачных вычислений, охватывающего как развёртывание процессоров, так и совместную разработку специализированных чипов инфраструктуры (IPU). За два дня до этого компания стала партнёром по производству микрочипов для мегапроекта Tesla Terafab. В итоге акции Intel за неделю выросли на треть. Intel и Google отметили, что по мере ускорения внедрения ИИ-инфраструктура становится всё более сложной и гетерогенной, что приводит к увеличению зависимости от CPU для оркестрации, обработки данных и повышения производительности на системном уровне. В рамках сотрудничества с Intel компания Google планирует использовать несколько поколений процессоров Intel Xeon для улучшения производительности, энергоэффективности и TCO в своих инстансах. Intel уже делает кастомные Xeon для AWS. Стороны подчеркнули, что одних только ускорителей недостаточно для удовлетворения потребностей современной ИИ-инфраструктуры. «ИИ меняет подход к построению и масштабированию инфраструктуры. Масштабирование ИИ требует большего, чем просто ускорители — оно требует сбалансированных систем. CPU и IPU играют центральную роль в обеспечении производительности, эффективности и гибкости, необходимых для современных рабочих нагрузок ИИ», — сообщил генеральный директор Intel Лип-Бу Тан (Lip-Bu Tan). Как отметил ресурс The Next Web, Intel потратила последние два года на переориентацию с рынка универсальных вычислений, где она когда-то доминировала, на процессоры и специализированные инфраструктурные чипы, которые играют структурную роль в развёртывании ИИ и которые постоянно недооценивали в рамках концепций, ориентированных на GPU. Одновременно компания развивает бизнес по производству кастомных чипов для ИИ-рынка. 
Источник изображения: Intel Амин Вахдат (Amin Vahdat), старший вице-президент и главный технолог Google по инфраструктуре ИИ отметил: «Процессоры и инфраструктурное ускорение остаются краеугольным камнем систем ИИ — от организации обучения до инференса и развёртывания. Intel является надёжным партнёром уже почти два десятилетия, и её план развития Xeon даёт нам уверенность в том, что мы сможем и дальше удовлетворять растущие требования к производительности и эффективности наших рабочих нагрузок». Что важно, партнёрство охватывает несколько поколений Intel Xeon, а не текущий цикл обновления оборудования Google. Партнёрство также включает расширенную совместную разработку IPU (DPU) — специализированных программируемых ускорителей на базе ASIC, предназначенных для разгрузки сетевых функций, функций хранения, функций безопасности и т.п., которые на масштабах гиперскейлера позволяют существенно сэкономить и упростить управление инфраструктурой. Ранее компании совместно разработали свой первый IPU Mount Evans. Момент для анонса партнёрства выбран подходящий. Рабочие нагрузки ИИ смещаются от обучения на ускорителях, что позволить себе могут немногие, к масштабируемому инференсу, который является распределённым, чувствительным к задержкам, непрерывным и требовательным к ресурсам CPU для оркестрации, работы с данными и управления системой в целом. По-видимому, собственные процессоры Google Axion пока не слишком годятся на эту роль. Впрочем, для внешних заказчиков компания точно так же предлагает инстансы с чипами NVIDIA, хотя её собственные TPU пользуются огромным спросом. Впрочем, расширение сотрудничество можно объяснить и более прозаично — дефицит серверных процессоров на рынке усиливается, так что заранее договориться о поставках с крупным игроком, да ещё имеющим собственное производство на территории США, всегда выгодно.
05.03.2022 [01:28], Алексей Степин
Graphcore анонсировала ИИ-ускорители BOW IPU с 3D-упаковкой кристаллов WoWРазработка специализированных ускорителей для задач и алгоритмов машинного обучения в последние несколько лет чрезвычайно популярна. Ещё в 2020 году британская компания Graphcore объявила о создании нового класса ускорителей, которые она назвала IPU: Intelligence Processing Unit. Их архитектура оказалась очень любопытной. Основной единицей IPU является не ядро, а «тайл» — область кристалла, содержащая как вычислительную логику, так и некоторое количество быстрой памяти с пропускной способностью в районе 45 Тбайт/с (7,8 Тбайт/с между тайлами). В первой итерации чип Graphcore получил 1216 таких тайлов c 300 Мбайт памяти, а сейчас компания анонсировала следующее поколение своих IPU. 
Изображения: Graphcore Новый чип, получивший название BOW, можно условно отнести к «поколению 2,5». Он использует кристалл второго поколения Colossus Mk2: 892 Мбайт SRAM в 1472 тайлах, способных выполнять одновременно 8832 потока. Этот кристалл по-прежнему производится с использованием 7-нм техпроцесса TSMC, но теперь Graphcore перешла на использование более продвинутой упаковки типа 3D Wafer-on-Wafer (3D WoW). Новый IPU стал первым в индустрии чипом высокой сложности, использующем новый тип упаковки, причём технология 3D WoW была совместно разработана Graphcore и TSMC с целью оптимизации подсистем питания. Процессоры такой сложности отличаются крайней прожорливостью, а «накормить» их при этом не просто. В итоге обычная упаковка не позволяет добиться от чипа уровня Colossus Mk2 максимальной производительности — слишком велики потери и паразитный нагрев. 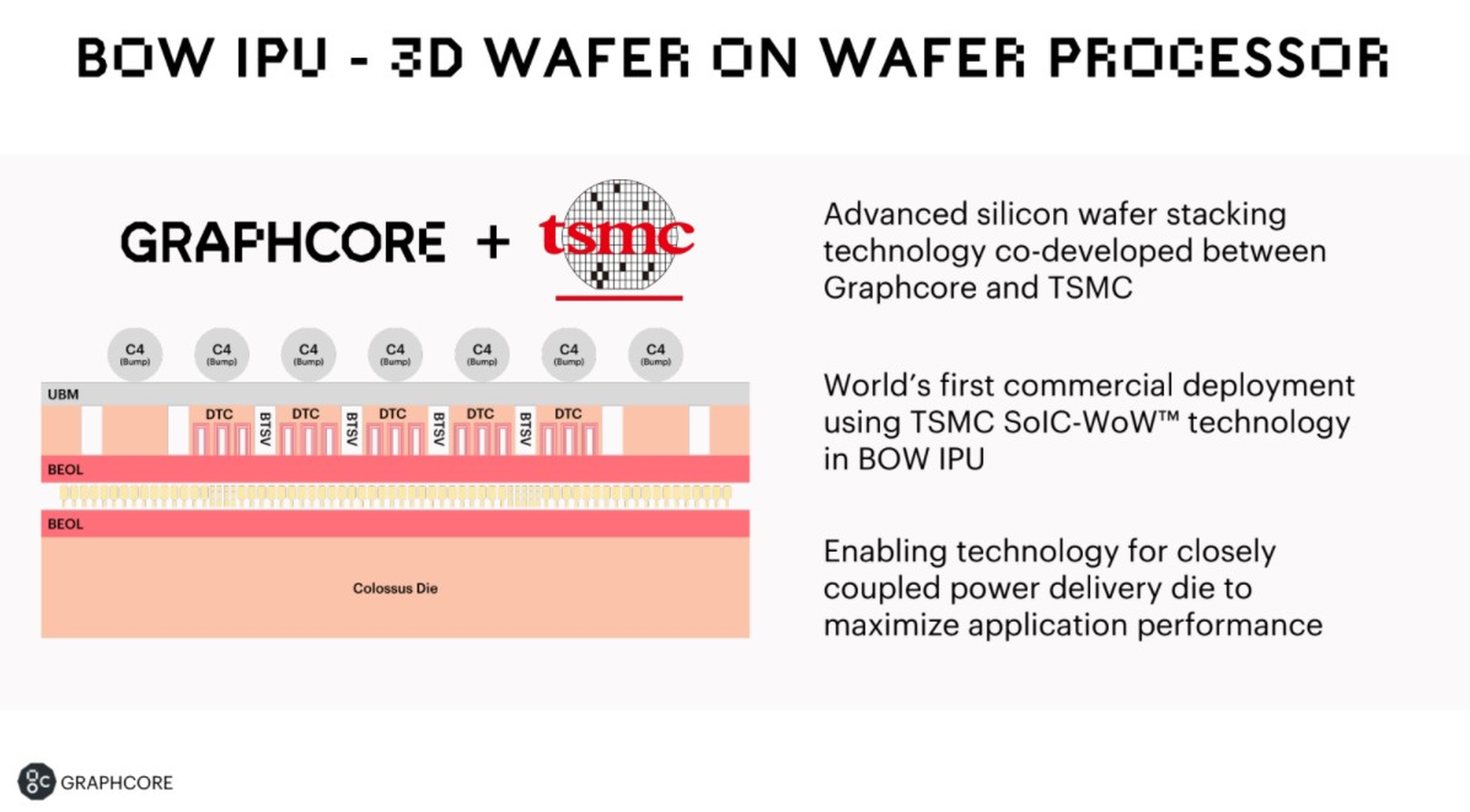 Реализована 3D WoW во многом аналогично технологии, применённой AMD в серверных чипах Milan-X. Упрощённо говоря, медные структуры-стержни пронизывают кристалл и позволяют соединить его напрямую с другим кристаллом, причём «склеиваются» они друг с другом благодаря. В случае с BOW роль нижнего кристалла отводится распределителю питания с системой стабилизирующих конденсаторов, который питает верхний кристалл Colossus Mk2. За счёт перехода с плоских структур на объёмные можно как увеличить подводимый ток, так и сделать путь его протекания более короткими. В итоге компании удалось дополнительно поднять частоту и производительность BOW, не прибегая к переделке основного процессора или переводу его на более тонкий и дорогой техпроцесс. Если у оригинального IPU второго поколения максимальная производительность составляла 250 Тфлопс, то сейчас речь идёт уже о 350 Тфлопс — для системы BOW-2000 с четырьмя чипами заявлено 1,4 Пфлопс совокупной производительности. И это хороший выигрыш, полученный без критических затрат.  С внешним миром IPU общается по-прежнему посредством 10 каналов IPU-Link (320 Гбайт/с). Внутренней памяти в такой системе уже почти 4 Гбайт, причём работает она на скорости 260 Тбайт/с — критически важный параметр для некоторых задач машинного обучения, которые требуют всё большие по объёму наборов данных. Ёмкость набортной памяти далека от предлагаемой NVIDIA и AMD, но выигрыш в скорости даёт детищу Graphcore серьёзное преимущество. Узлы BOW-2000 совместимы с узлами предыдущей версии. Четыре таких узла (BOW POD16) с управляющим сервером — всё в 5U-шасси — имеют производительность до 5,6 Пфлопс. А полная стойка с 16 узлами BOW-2000 (BOW POD64) даёт уже 22,4 Пфлопс. По словам компании, производительность новой версии возросла на 30–40 %, а прирост энергоэффективности составляет от 10 % до 16 %. 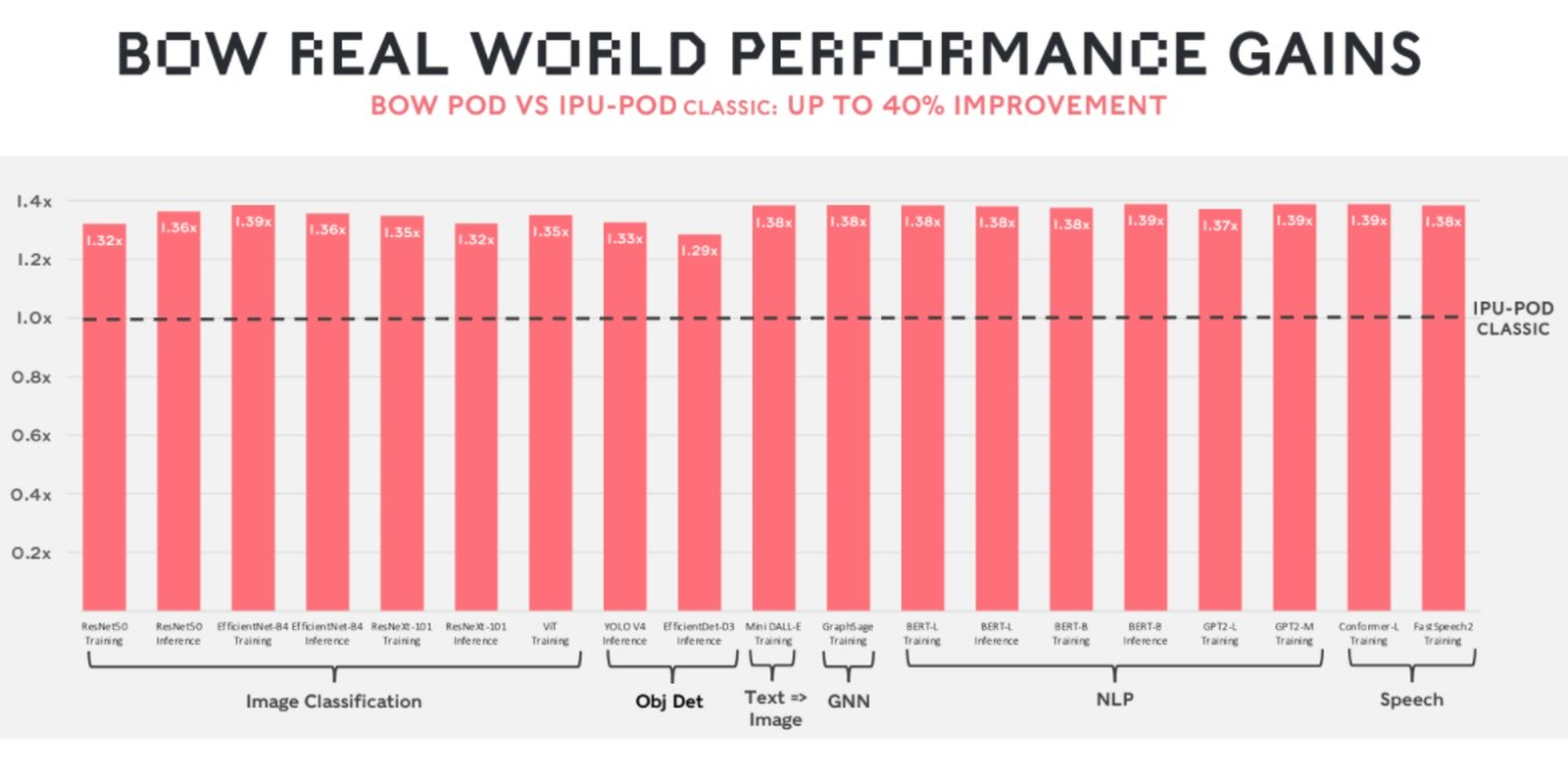 Graphcore говорит о десятикратном превосходстве BOW POD16 над NVIDIA DGX-A100 в полной стоимости владения (TCO). Cтоит BOW POD16 вдвое дешевле DGX-A100. К сожалению, говорить о завоевании рынка машинного обучения Graphcore рано: клиентов у компании уже довольно много, но среди них нет таких гигантов, как Google или Baidu. В долгосрочной перспективе ситуация для Graphcore далеко не безоблачна, но компания уже готовит третье поколение IPU на базе 3-нм техпроцесса.
27.08.2020 [19:13], Алексей Степин
TSMC и Graphcore создают ИИ-платформу на базе технологии 3 нмНесмотря на все проблемы в полупроводниковой индустрии, технологии продолжают развиваться. Технологические нормы 7 нм уже давно не являются чудом, вовсю осваиваются и более тонкие нормы, например, 5 нм. А ведущий контрактный производитель, TSMC, штурмует следующую вершину — 3-нм техпроцесс. Одним из первых продуктов на базе этой технологии станет ИИ-платформа Graphcore с четырьмя IPU нового поколения. Британская компания Graphcore разрабатывает специфические ускорители уже не первый год. В прошлом году она представила процессор IPU (Intelligence Processing Unit), интересный тем, что состоит не из ядер, а из так называемых тайлов, каждый из которых содержит вычислительное ядро и некоторое количество интегрированной памяти. В совокупности 1216 таких тайлов дают 300 Мбайт сверхбыстрой памяти с ПСП до 45 Тбайт/с, а между собой процессоры IPU общаются посредством IPU-Link на скорости 320 Гбайт/с. 
Colossально: ИИ-сервер Graphcore с четырьмя IPU на борту Компания позаботилась о программном сопровождении своего детища, снабдив его стеком Poplar, в котором предусмотрена интеграция с TensorFlow и Open Neural Network Exchange. Разработкой Graphcore заинтересовалась Microsoft, применившая IPU в сервисах Azure, причём совместное тестирование показало самые положительные результаты. Следующее поколение IPU, Colossus MK2, представленное летом этого года, оказалось сложнее NVIDIA A100 и получило уже 900 Мбайт сверхбыстрой памяти.  Машинное обучение, в основе которого лежит тренировка и использование нейронных сетей, само по себе требует процессоров с весьма высокой степенью параллелизма, а она, в свою очередь, автоматически означает огромное количество транзисторов — 59,4 млрд в случае Colossus MK2. Поэтому освоение новых, более тонких и экономичных техпроцессов является для этого класса микрочипов ключевой задачей, и Graphcore это понимает, заявляя о своём сотрудничестве с TSMC. 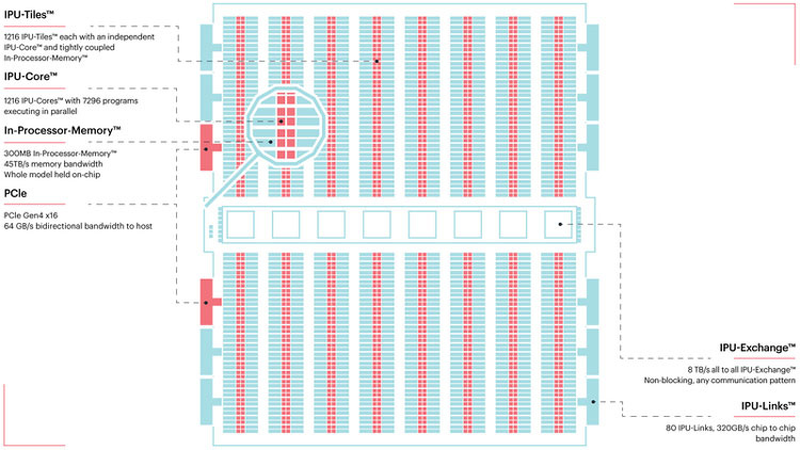
Тайловая архитектура Graphcore Colossus MK2 В настоящее время TSMC готовит к началу «рискового» производства новый техпроцесс с нормами 3 нм, причём скорость внедрения такова, что первые продукты на его основе должны увидеть свет уже в 2021 году, а массовое производство будет развёрнуто во второй половине 2022 года. И одним из первых продуктов на базе 3-нм технологических норм станет новый вариант IPU за авторством Graphcore, известный сейчас как N3. Судя по всему, использовать 5 нм британский разработчик не собирается. 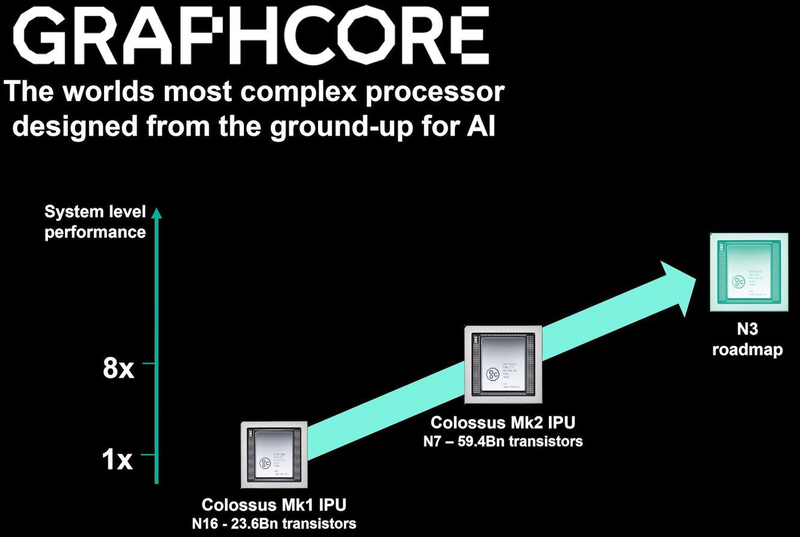
В планах компании явно указано использование 3-нм техпроцесса В настоящее время чипы Colossus MK2 производятся с использованием техпроцесса 7 нм (TSMC N7). Они включают в себя 1472 тайла и способны одновременно выполнять 8832 потока. В режиме тренировки нейросетей с использованием вычислений FP16 это даёт 250 Тфлопс, но существует удобное решение мощностью 1 Пфлопс — это специальный 1U-сервер Graphcore, в нём четыре IPU дополнены 450 Гбайт внешней памяти. Доступны также платы расширения PCI Express c чипами IPU на борту. Дела у Graphcore идут неплохо, её технология оказалась востребованной и среди инвесторов числятся Microsoft, BMW, DeepMind и ряд других компаний, разрабатывающих и внедряющих комплексы машинного обучения. Разработка 3-нм чипа ещё более упрочнит позиции этого разработчика. Более тонкие техпроцессы существенно увеличивают стоимость разработки, но финансовые резервы у Graphcore пока есть; при этом не и исключён вариант более тесного сотрудничества, при котором часть стоимости разработки возьмёт на себя TSMC. |
|

