Материалы по тегу: a100
|
28.06.2021 [13:22], Алексей Степин
Обновление NVIDIA HGX: PCIe-вариант A100 с 80 Гбайт HBM2e, InfiniBand NDR и Magnum IO с GPUDirect StorageНа суперкомпьютерной выставке-конференции ISC 2021 компания NVIDIA представила обновление платформы HGX A100 для OEM-поставщиков, которая теперь включает PCIe-ускорители NVIDIA c 80 Гбайт памяти, InfiniBand NDR и поддержку Magnum IO с GPUDirect Storage. В основе новинки лежат наиболее продвинутые на сегодняшний день технологии, имеющиеся в распоряжении NVIDIA. В первую очередь, это, конечно, ускорители на базе архитектуры Ampere, оснащённые процессорами A100 с производительностью почти 10 Тфлопс в режиме FP64 и 624 Топс в режиме тензорных вычислений INT8.  HGX A100 предлагает 300-Вт версию ускорителей с PCIe 4.0 x16 и удвоенным объёмом памяти HBM2e (80 Гбайт). Увеличена и пропускная способность (ПСП), в новой версии ускорителя она достигла 2 Тбайт/с. И если по объёму и ПСП новинки догнали SXM-версию A100, то в отношении интерконнекта они всё равно отстают, так как позволяют напрямую объединить посредством NVLink только два ускорителя.  В качестве сетевой среды в новой платформе NVIDIA применена технология InfiniBand NDR со скоростью 400 Гбит/с. Можно сказать, что InfiniBand догнала Ethernet, хотя не столь давно её потолком были 200 Гбит/с, а в плане латентности IB по-прежнему нет равных. Сетевые коммутаторы NVIDIA Quantum 2 поддерживают до 64 портов InfiniBand NDR и вдвое больше для скорости 200 Гбит/с, а также имеют модульную архитектуру, позволяющую при необходимости нарастить количество портов NDR до 2048. Пропускная способность при этом может достигать 1,64 Пбит/с.  Технология NVIDIA SHARP In-Network Computing позволяет компании заявлять о 32-крантом превосходстве над системами предыдущего поколения именно в области сложных задач машинного интеллекта для индустрии и науки. Естественно, все преимущества машинной аналитики используются и внутри самого продукта — технология UFM Cyber-AI позволяет новой платформе исправлять большинство проблем с сетью на лету, что минимизирует время простоя.  Отличным дополнением к новым сетевым возможностями является технология GPUDirect Storage, которая позволяет NVMe-накопителям общаться напрямую с GPU, минуя остальные компоненты системы. В качестве программной прослойки для обслуживания СХД новая платформа получила систему Magnum IO с поддержкой вышеупомянутой технологии, обладающую низкой задержкой ввода-вывода и по максимуму способной использовать InfiniBand NDR. 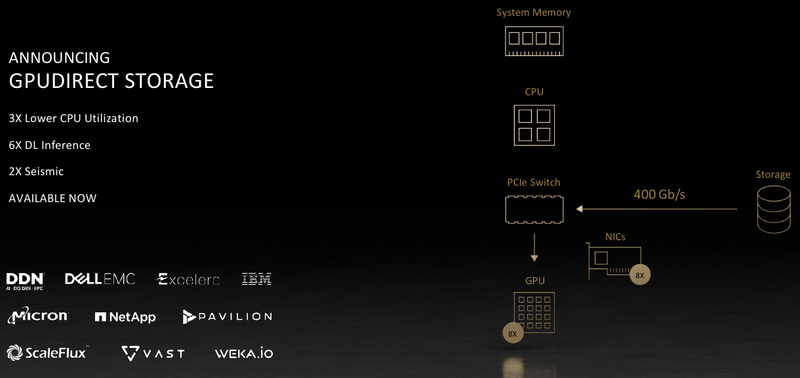 Три новых ключевых технологии NVIDIA помогут супервычислениям стать ещё более «супер», а суперкомпьютерам следующего поколения — ещё более «умными» и производительными. Достигнуты договорённости с такими крупными компаниями, как Atos, Dell Technologies, HPE, Lenovo, Microsoft Azure и NetApp. Решения NVIDIA используются как в индустрии — в качестве примера можно привести промышленный суперкомпьютер Tesla Automotive, так и в ряде других областей.  В частности, фармакологическая компания Recursion использует наработки NVIDIA в области машинного обучения для поиска новых лекарств, а национальный научно-исследовательский центр энергетики (NERSC) применяет ускорители A100 в суперкомпьютере Perlmutter при разработке новых источников энергии. И в дальнейшем NVIDIA продолжит своё наступление на рынок HPC, благо, она может предложить заказчикам как законченные аппаратные решения, так и облачные сервисы, также использующие новейшие технологии компании.
28.05.2021 [00:33], Владимир Мироненко
Perlmutter стал самым мощным ИИ-суперкомпьютером в мире: 6 тыс. NVIDIA A100 и 3,8 ЭфлопсВ Национальном вычислительном центре энергетических исследований США (NERSC) Национальной лаборатории им. Лоуренса в Беркли состоялась торжественная церемония, посвящённая официальному запуску суперкомпьютера Perlmutter, также известного как NERSC-9, созданного HPE в партнёрстве с NVIDIA и AMD. Это самый мощный в мире ИИ-суперкомпьютер, базирующийся на 6159 ускорителях NVIDIA A100 и примерно 1500 процессорах AMD EPYC Milan. Его пиковая производительность в вычислениях смешанной точности составляет 3,8 Эфлопс или почти 60 Пфлопс в FP64-вычислениях. Perlmutter основан на платформе HPE Cray EX с прямым жидкостным охлаждением и интерконнектом Slingshot. В состав системы входят как GPU-узлы, так и узлы с процессорами. Для хранения данных используется файловая система Lustre объёмом 35 Пбайт скорость обмена данными более 5 Тбайт/с, которая развёрнута на All-Flash СХД HPE ClusterStor E1000 (тоже, к слову, на базе AMD EPYC). 
Perlmutter (Phase 1). Фото: NERSC Установка Perlmutter разбита на два этапа. На сегодняшней презентации было объявлено о завершении первого (Phase 1) этапа, который начался в ноябре прошлого года. В его рамках было установлено 1,5 тыс. вычислительных узлов, каждый из которых имеет четыре ускорителя NVIDIA A100, один процессор AMD EPYC Milan и 256 Гбайт памяти. На втором этапе (Phase 2) в конце 2021 года будут добавлены 3 тыс. CPU-узлов c двумя AMD EPYC Milan и 512 Гбайт памяти., а также ещё ещё 20 узлов доступа и четыре узла с большим объёмом памяти. 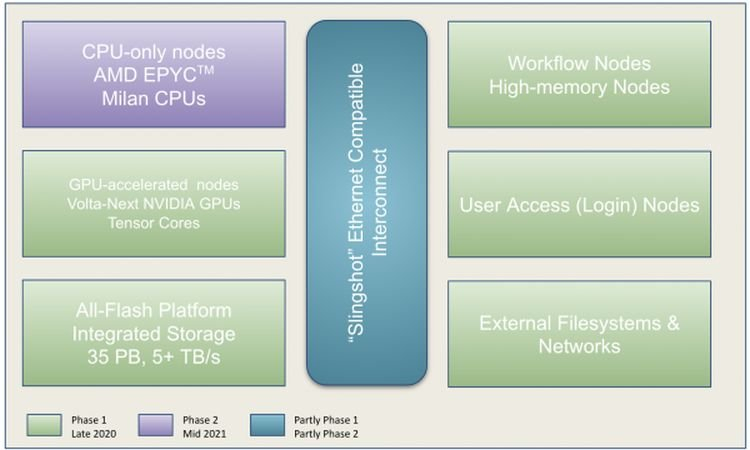
NERSC Также на первом этапе были развёрнуты служебные узлы, включая 20 узлов доступа пользователей, на которых можно подготавливать контейнеры с приложениями для последующего запуска на суперкомпьютере и использовать Kubernetes для оркестровки. Среда разработки будет включать NVDIA HPC SDK в дополнение к наборам компиляторов CCE (Cray Compiling Environment), GCC и LLVM для поддержки различных средств параллельного программирования, таких как MPI, OpenMP, CUDA и OpenACC для C, C ++ и Fortran. 
Фото: DESI Сообщается, что для Perlmutter готовится более двух десятков заявок на вычисления в области астрофизики, прогнозирования изменений климата и в других сферах. Одной из задач для новой системы станет создание трёхмерной карты видимой Вселенной на основе данных от DESI (Dark Energy Spectroscopic Instrument). Ещё одно направление, для которого задействуют суперкомпьютер, посвящено материаловедению, изучению атомных взаимодействий, которые могут указать путь к созданию более эффективных батарей и биотоплива.
16.11.2020 [17:00], Игорь Осколков
SC20: NVIDIA представила ускоритель A100 с 80 Гбайт HBM2e и настольный «суперкомпьютер» DGX STATIONNVIDIA представила новую версию ускорителя A100 с увеличенным вдвое объёмом HBM2e-памяти: 80 Гбайт вместо 40 Гбайт у исходной A100, представленной полгода назад. Вместе с ростом объёма выросла и пропускная способность — с 1,555 Тбайт/с до 2 Тбайт/с. В остальном характеристики обоих ускорителей совпадают, даже уровень энергопотребления сохранился на уровне 400 Вт. Тем не менее, объём и скорость работы быстрой набортной памяти влияет на производительность ряда приложений, так что им такой апгрейд только на пользу. К тому же MIG-инстансы теперь могут иметь объём до 10 Гбайт. PCIe-варианта ускорителя с удвоенной памятью нет — речь идёт только об SXM3-версии, которая используется в собственных комплексах NVIDIA DGX и HGX-платформах для партнёров. 
NVIDIA A100 80 Гбайт  Последним ориентировочно в первом квартале следующего года будут предоставлены наборы для добавления новых A100 в существующие решения, включая варианты плат на 4 и 8 ускорителей. У самой NVIDIA обновлению подверглись, соответственно, DGX A100 POD и SuperPOD for Enterprise. Недавно анонсированные суперкомпьютеры Cambridge-1 и HiPerGator на базе SuperPOD одними из первых получат новые ускорители с 80 Гбайт памяти. Ожидается, что HGX-решения на базе новой A100 будут доступны от партнёров компании — Atos, Dell Technologies, Fujitsu, GIGABYTE, Hewlett Packard Enterprise, Inspur, Lenovo, Quanta и Supermicro — в первой половине 2021 года.   Но, пожалуй, самый интересный анонс касается новой рабочей станции NVIDIA DGX STATION A100, которую как раз и можно назвать настольным «суперкомпьютером». В ней используются четыре SXM3-ускорителя A100 с не требующей обслуживания жидкостной системой охлаждения и полноценным NVLink-подключением. Будут доступны две версии, со 160 или 320 Гбайт памяти с 40- и 80-Гбайт A100 соответственно. Базируется система на 64-ядерном процессоре AMD EPYC, который можно дополнить 512 Гбайт RAM.   Для ОС доступен 1,92-Тбайт NVMe M.2 SSD, а для хранения данных — до 7,68 Тбайт NVMe U.2 SSD. Сетевое подключение представлено двумя 10GbE-портами и выделенным портом управления. Видеовыходов четыре, все mini Display Port. DGX STATION A100 отлично подходит для малых рабочих групп и предприятий. В том числе благодаря тому, что функция MIG позволяет эффективно разделить ресурсы станции между почти тремя десятками пользователей. В продаже она появится у партнёров компании в феврале следующего года.  Вероятно, все выпускаемые сейчас A100 c увеличенным объёмом памяти идут на более важные проекты. Новинкам предстоит конкурировать с первым ускорителем на базе новой архитектуры CDNA — AMD Instinct MI100.
22.06.2020 [12:39], Илья Коваль
NVIDIA представила PCIe-версию ускорителя A100Как и предполагалось, NVIDIA вслед за SXM4-версией ускорителя A100 представила и модификацию с интерфейсом PCIe 4.0 x16. Обе модели используют идентичный набор чипов с одинаковыми характеристикам, однако, помимо отличия в способе подключения, у них есть ещё два существенных отличия. 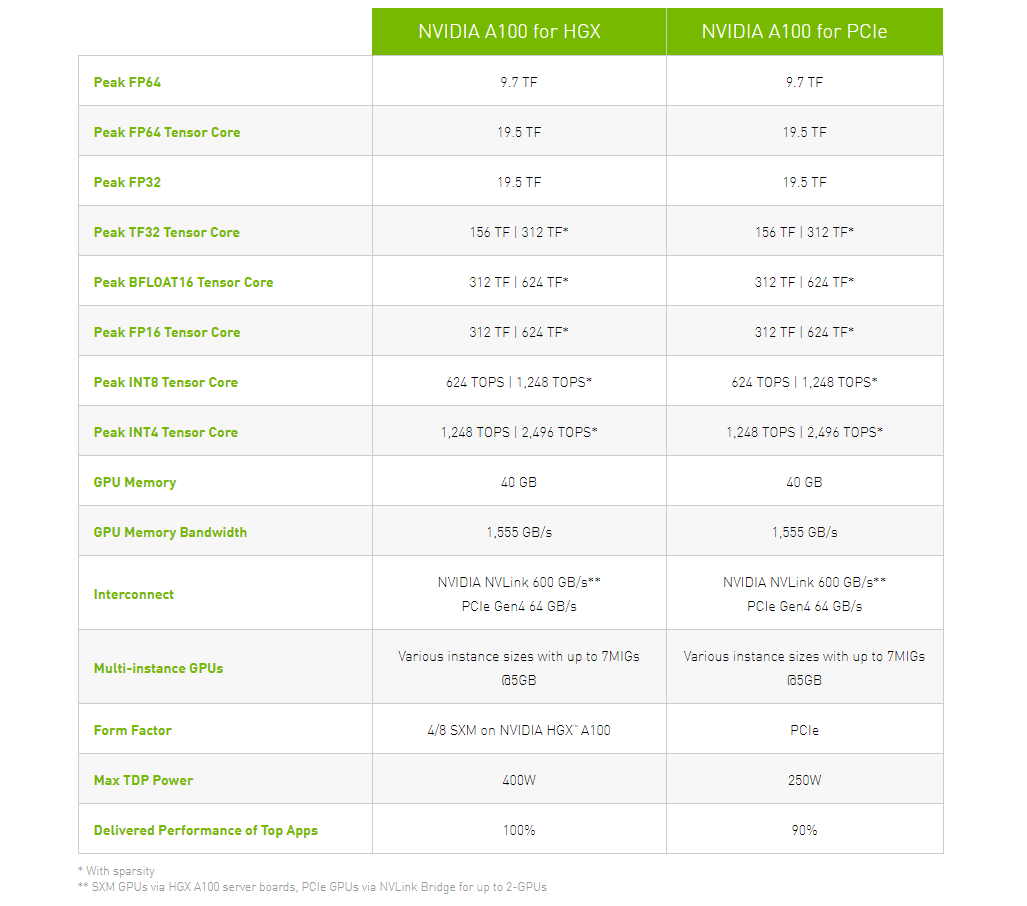 Первое — сниженный с 400 Вт до 250 Вт показатель TDP. Это прямо влияет на величину устоявшейся скорости работы. Сама NVIDIA указывает, что производительность PCIe-версии составит 90% от SXM4-модификации. На практике разброс может быть и больше. Естественным ограничением в данном случае является сам форм-фактор ускорителя — только классическая двухслотовая FLFH-карта с пассивным охлаждением совместима с современными серверами.  Второе отличие касается поддержки быстрого интерфейса NVLink. В случае PCIe-карты посредством внешнего мостика можно объединить не более двух ускорителей, тогда как для SXM-версии есть возможность масштабирования до 8 ускорителей в рамках одной системы. С одной стороны, NVLink в данном случае практически на порядок быстрее PCIe 4.0. С другой — PCIe-версия наверняка будет заметно дешевле и в этом отношении универсальнее. 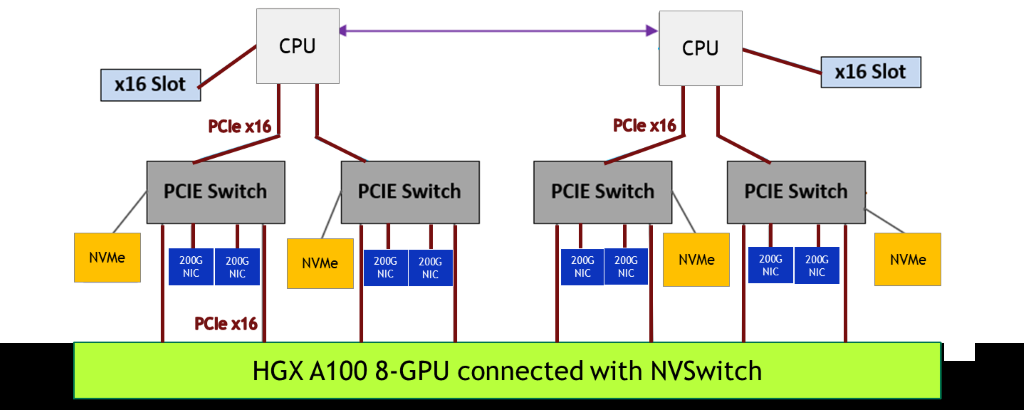 Производители серверов уже объявили о поддержке новых ускорителей в своих системах. Как правило, это уже имеющиеся платформы с возможностью установки 4 или 8 (реже 10) карт. Любопытно, что фактически единственным разумным вариантом для плат PCIe 4.0, как и в случае HGX/DGX A100, является использование платформ на базе AMD EPYC 7002.
14.05.2020 [18:52], Рамис Мубаракшин
NVIDIA представила ускорители A100 с архитектурой Ampere и систему DGX A100 на их основеNVIDIA официально представила новую архитектуру графических процессоров под названием Ampere, которая является наследницей представленной осенью 2018 года архитектуры Turing. Основные изменения коснулись числа ядер — их теперь стало заметно больше. Кроме того, новинки получили больший объём памяти, поддержку bfloat16, возможность разделения ресурсов (MIG) и новые интерфейсы: PCIe 4.0 и NVLink третьего поколения. NVIDIA A100 выполнен по 7-нанометровому техпроцессу и содержит в себе 54 млрд транзисторов на площади 826 мм2. По словам NVIDIA, A100 с архитектурой Ampere позволяют обучать нейросети в 40 раз быстрее, чем Tesla V100 с архитектурой Turing. 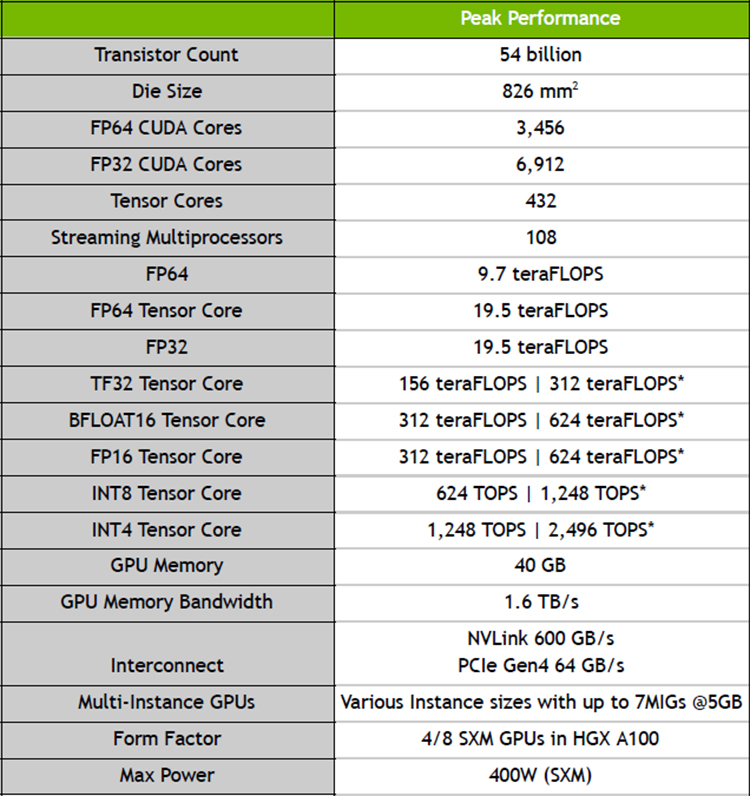
Характеристики A100 Первой основанной на ней вычислительной системой стала фирменная DGX A100, состоящая из восьми ускорителей NVIDIA A100 с NVSwitch, имеющих суммарную производительность 5 Пфлопс. Стоимость одной системы DGX A100 равна $199 тыс., они уже начали поставляться некоторым клиентам. Известно, что они будут использоваться в Аргоннской национальной лаборатории для поддержания работы искусственного интеллекта, изучающего COVID-19 и ищущего от него лекарство. Так как некоторые группы исследователей не могут себе позволить покупку системы DGX A100 из-за ее высокой стоимости, их планируют купить поставщики услуг по облачным вычислений и предоставлять удалённый доступ к высоким мощностям. На данный момент известно о 18 провайдерах, готовых к использованию систем и ускорителей на основе архитектуры Ampere, и среди них есть Google, Microsoft и Amazon. 
Система NVIDIA DGX A100 Помимо системы DGX A100, компания NVIDIA анонсировала ускорители NVIDIA EGX A100, предназначенная для периферийных вычислений. Для сегмента интернета вещей компания предложила плату EGX Jetson Xavier NX размером с банковскую карту. |
|

