Материалы по тегу: infiniband
|
04.06.2026 [10:29], Сергей Карасёв
NVIDIA разработала CPO-коммутатор Quantum-X InfiniBand Photonics Q3450-LD со 144 портами 800GСтартап Lambda, развивающий неооблачную ИИ-платформу, поделился подробностями о коммутаторе Quantum-X InfiniBand Photonics Q3450-LD, разработанном компанией NVIDIA для крупных дата-центров, ориентированных на ресурсоёмкие нагрузки ИИ. Устройство, анонсированное в прошлом году, выполнено в форм-факторе 4U по технологии CPO (Co-Packaged Optics). Реализованы 144 порта 800G InfiniBand (коннекторы MPO — Multi-fiber Push-On). Заявленная неблокируемая коммутационная способность составляет 115,2 Тбит/с. Коммутаторы CPO не требуют традиционных подключаемых трансиверов. Применяются 18 съёмных внешних модулей источников света, каждый из которых обслуживает восемь портов MPO. 
Источник изображений: Lambda Рич Андервуд (Rich Underwood), системный архитектор высокопроизводительных вычислений в компании Lambda, отмечает, что для традиционного 72-портового коммутатора необходимы 72 трансивера, каждый из которых потребляет примерно 25 Вт. Исключение этих компонентов из системы обеспечивает существенную экономию энергии. Коммутатор NVIDIA Photonics CPO потребляет 3,95 кВт против 7,0 кВт у стандартного устройства сопоставимого класса. Таким образом, достигается экономия 3,05 кВт на каждый коммутатор: эта мощность может быть перераспределена на другие задачи, в частности, на питание ИИ-ускорителей.  Кроме того, использование CPO позволяет повысить надёжность. Для дата-центра со 128 тыс. GPU требуется приблизительно 655 тыс. дискретных модулей трансиверов. Каждый из них является потенциальной точкой отказа. Технология CPO полностью исключает этот класс компонентов, а следовательно, повышает стабильность работы и минимизирует количество сбоев. Устройство Quantum-X InfiniBand Photonics Q3450-LD оснащено двухконтурным жидкостным охлаждением. Для питания служит шина постоянного тока 48 В.
23.03.2026 [09:31], Сергей Карасёв
HPE представила узлы на базе NVIDIA Vera для платформы Cray Supercomputing GX5000Компания HPE анонсировала новые решения семейства NVIDIA AI Computing by HPE, ориентированные на крупномасштабные ИИ-платформы и суперкомпьютерные системы. О намерении использовать такие инфраструктурные продукты в числе прочих сообщили Аргоннская национальная лаборатория (ANL) Министерства энергетики США (DOE), Hudson River Trading (HRT), Корейский институт научно-технической информации (KISTI) и Центр высокопроизводительных вычислений HLRS при Штутгартском университете в Германии. В частности, представлены новые узлы для суперкомпьютерной платформы HPE Cray Supercomputing GX5000 — blade-серверы HPE Cray Supercomputing GX240. Эти устройства могут нести на борту до 16 процессоров NVIDIA Vera (88C/176T). В одной стойке могут быть размещены до 40 узлов, что в сумме даёт 640 чипов Vera и 56 320 ядер Olympus. Реализовано жидкостное охлаждение. Система предназначена для решения наиболее ресурсоёмких вычислительных задач в области ИИ. Новые серверы появятся на рынке в следующем году. Для платформы HPE Cray Supercomputing GX5000 также будут доступны коммутаторы NVIDIA Quantum-X800 InfiniBand, предоставляющие 144 порта с пропускной способностью до 800 Гбит/с. В этих устройствах реализованы развитые функции снижения энергопотребления. Кроме того, HPE готовит OCP-серверы высокой плотности Compute XD700 для обучения LLM и инференса. В основу данной системы положена платформа NVIDIA HGX Rubin NVL8, а одна стойка может насчитывать до 128 ускорителей Rubin. Данное решение появится в начале 2027-го. 
Источник изображений: HPE Помимо этого, анонсирована стоечная система нового поколения NVIDIA Vera Rubin NVL72 by HPE — это флагманская ИИ-платформа, разработанная для моделей с более чем 1 трлн параметров. Конфигурация включает 36 процессоров Vera, 72 чипа Rubin, интерконнект NVIDIA NVLink шестого поколения, сетевые адаптеры NVIDIA ConnectX-9 SuperNIC и DPU NVIDIA BlueField-4. Система поступит в продажу в декабре 2026 года. 
28.10.2025 [20:35], Сергей Карасёв
NVIDIA анонсировала DPU BlueField-4: 800G-порты, ConnectX-9, CPU Grace и PCIe 6.0NVIDIA анонсировала DPU BlueField 4, рассчитанный на использование в составе масштабных инфраструктур ИИ. Устройство оснащено 800G-портами. Новинка в этом отношении вдвое быстрее BlueField-3, дебютировавших ещё в 2021 году. NVIDIA отмечает, что ИИ-фабрики продолжают развиваться с беспрецедентной скоростью. При этом требуется обработка колоссальных массивов структурированных и неструктурированных данных. Для удовлетворения этих потребностей необходимо формирование инфраструктуры нового класса, на которую как раз и ориентирован DPU BlueField-4. Новинка использует программно-определяемую архитектуру для ускорения сетевых операций, функций безопасности и задач хранения данных. По заявлениям NVIDIA, BlueField-4 позволяет трансформировать дата-центры в безопасную интеллектуальную ИИ-инфраструктуру с высокой производительностью. BlueField-4 объединяет 64-ядерный Arm-процессор NVIDIA Grace (114 Мбайт L3-кеш), 128 Гбайт LPDDR5, 512 Гбайт SSD, сетевой адаптер NVIDIA ConnectX-9 SuperNic (1,6 Тбит/с), а также коммутатор PCIe 6.0 с 48 линиями. Новинка будет доступна в виде карты расширения (PCIe 6.0 x16) и в виде модуля для узлов VR NVL144. Утверждается, что по сравнению с BlueField-3 вычислительная производительность выросла в шесть раз. При этом возможно формирование ИИ-фабрик вчетверо большего масштаба. Кроме того, BlueField-4 поддерживает многопользовательскую сеть, быстрый доступ к данным и микросервисы NVIDIA DOCA. Задействована архитектура NVIDIA BlueField Advanced Secure Trusted Resource Architecture. 
Источник изображения: NVIDIA Предполагается, что BlueField-4 возьмут на вооружение такие производители серверов и платформ хранения данных, как Cisco, DDN, Dell Technologies, HPE, IBM, Lenovo, Supermicro, VAST Data и WEKA. О поддержке новинки заявили Armis, Check Point, Cisco, F5, Forescout, Palo Alto Networks и Trend Micro, а также системные интеграторы Accenture, Deloitte и World Wide Technology. Интегрировать BlueField-4 в свои платформы намерены Canonical, Mirantis, Nutanix, Rafay, Red Hat, Spectro Cloud и SUSE. На рынок BlueField-4 поступит в 2026 году как часть экосистемы Vera Rubin.
18.03.2025 [23:12], Алексей Степин
Интегрированная фотоника и СЖО: NVIDIA анонсировала 800G-коммутаторы Spectrum-X и Quantum-XГонка в области ИИ накладывает отпечаток на облик ЦОД: сетевая инфраструктура становится всё сложнее и сложнее в погоне за высокой пропускной способностью и минимальными задержками. За это приходится платить повышенным расходом энергии на обеспечение работы оптических трансиверов. Поэтому NVIDIA представила новое поколение коммутаторов с интегрированной кремниевой фотоникой, которое должно решать эту проблему, а заодно обеспечить повышенную надёжность и скорость развёртывания сетевой инфраструктуры. По оценкам NVIDIA, традиционный облачный дата-центр на каждые 100 тысяч серверов расходует 2,3 МВт энергии на обеспечение работы оптических трансиверов, но в ИИ-кластерах, где каждому ускорителю нужно своё быстрое сетевое подключение, эта величина может достигать уже 40 МВт, т.е. до 10 % от общего уровня энергопотребления всего комплекса. Гораздо разумнее было тратить эту энергию на вычислительную, а не сетевую инфраструктуру. 
Источник здесь и далее: NVIDIA Новые коммутаторы Spectrum-X и Quantum-X должны решить эту проблему кардинально. В них применены новые ASIC, объединяющие на одной подложке чип-коммутатор и фотонные модули. Такой подход позволяет отказаться сразу от нескольких звеньев традиционной цепочки, входящих в классический оптический трансивер. Современный высокоскоростной трансивер включает восемь лазеров, которые потребляют порядка 10 Вт, и DSP-блок, который требует 20 Вт. 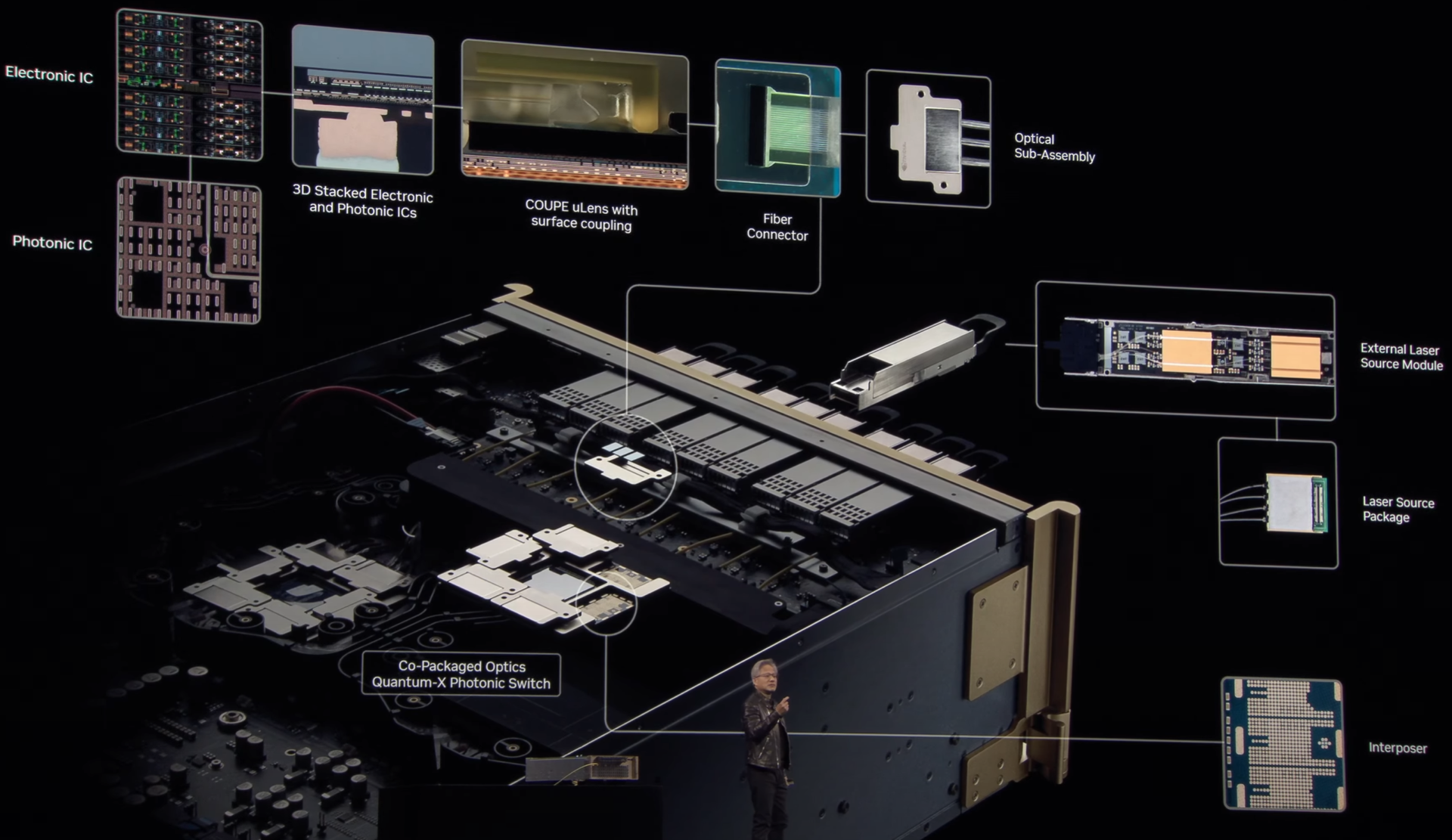 Интегрированная фотоника (CPO) позволяет обойтись всего двумя внешними лазерами для обеспечения работы одного порта 1,6 Тбит/с. Лазеры соединяется в этой схеме непосредственно с фотонным модулем на борту новых ASIC. Собственно оптический движок в составе ASIC потребляет всего 7 Вт, ещё 2 Вт требует лазер. Разница в энергопотреблении минимум трёхкратная.  Кроме того, упрощение схемы соединений способствует повышению надёжности: NVIDIA говорит о 63-кратном улучшении целостности сигнала, которому не приходится добираться через несколько электрических соединений от ASIC до трансивера и внутри последнего, и о десятикратном повышении общей надёжности сети. Если в традиционной схеме потери сигнала на его электрическом пути могут составлять 22 дБ, то для схемы с фотонным модулем этот показатель составляет всего 4 дБ.  Новая схема упаковки ASIC достаточно сложна: в ней реализованы разъёмные оптические соединители, позволяющие реализовывать сценарии с различной конфигурацией портов коммутаторов, со скоростями от 200 до 800 Гбит/с. Флагманский коммутатор Spectrum SN6800 включает 512 портов 800GbE с совокупной скоростью коммутации 409,6 Тбит/с. Модель SN6810 компактнее, она предлагает 128 портов 800GbE и коммутацию до 102,4 Тбит/с.  Серия Quantum-X пока представлена моделью Quantum 3450-LD: 144 порта 800G InfiniBand с совокупной производительностью 115 Тбит/с. Сочетание высокой плотности с такими скоростями потребовала разработки и интеграции кастомной системы жидкостного охлаждения. Новые коммутаторы Quantum-X станут доступны во II половине этого года, а Spectrum-X — во II половине 2026 года.  В оптических движках собственной разработки NVIDIA использованы микрокольцевые модуляторы (MRM), реализация которых стала доступной благодаря сотрудничеству NVIDIA с TSMC в области упаковки «многоэтажных» чипов COUPE. Помимо TSMC в создании новых коммутаторов приняли участие компании Browave, Coherent, Corning Incorporated, Fabrinet, Foxconn, Lumentum, SENKO, SPIL, Sumitomo Electric Industries и TFC Communication.  Особенно серьёзно преимущества новой схемы проявляют себя в больших масштабах, на уровне сотен тысяч ускорителей. Время развёртывания снижается в 1,3 раза, а общая надёжность сети становится на порядок выше. Правда, пока что речь идёт только о коммутаторах — оптические кабели будут напрямую подключаться к их портам. Однако другой конец кабеля всё равно будет уходить в трансивер, обслуживающий отдельный ускоритель или узел. Также пока нет никаких планов по переводу NVLink на «оптику», поскольку внутри узла и NVL-стойки работать с «медью» по-прежнему проще и выгоднее.
22.03.2024 [09:09], Алексей Степин
NVIDIA представила 800G-платформы Quantum-X800 и Spectrum-X800 для InfiniBand- и Ethernet-фабрик нового поколенияДополнением к только что представленным ИИ-ускорителям NVIDIA Blackwell станут новые сетевые 800G-платформы Quantum-X800 и Spectrum-X800, а также сетевые адаптеры ConnectX-8. Именно они позволят вывести масштабирование ИИ-кластеров на новый уровень и позволят «прокормить» гигантские массивы ускорителей в дата-центрах гиперскейлеров. Платформа NVIDIA Quantum-X800 ориентирована на наиболее производительные ИИ- и HPC-кластеры. Она использует новое поколение технологии InfiniBand, всё ещё обладающей рядом преимуществ в сравнении с Ethernet, и включает в себя обновлённые SHARP-движки. Технология SHARPv4 реализует «вычисления в сети» (In-Network Computing), что позволяет не только существенно разгрузить вычислительные узлы и серверы, но и обеспечить более высокую пропускную способность интерконнекта вкупе с более серьёзными возможностями его масштабирования. 
NVIDIA Q3400-RA 4U (справа) и SN5600. Источник изображений здесь и далее: NVIDIA Основой платформы Quantum-X800 стал 4U-коммутатор Q3400-RA, впервые в индустрии, как говорит компания, использующий 200G-блоки SerDes для каждой линии InfiniBand. Коммутатор располагает 144 портами 800G в 72 OSFP-модулях и выделенным портом для Unified Fabric Manager. Новинка имеет стандартное 19″ исполнение с воздушным охлаждением, но есть и вариант Q3400-LD с жидкостным охлаждением, предназначенный для 21″ OCP-стоек. В двухуровневом варианте fat tree коммутаторы позволят объединить 10 368 NIC.  Основным адаптером для новой платформы InfiniBand является ConnectX-8 SuperNIC с интерфейсом PCIe 6.0. Он является частью SHARPv4 и предлагается в однопортовом (OSFP224) и двухпортовом (QSFP112) вариантах и в нескольких форм-факторах, включая OCP 3.0. На платах также имеется разъём SocketDirect на 16 линий PCIe. Также компания представила компоненты NVIDIA LinkX: оптические трансиверы 2xDR4/2xFR4 и активные медные кабели (LACC).  Не забыла NVIDIA и про Ethernet: здесь вывести производительность сети на новый уровень должна платформа Spectrum-X800. Её основой служит новейший коммутатор SN5600 — это, по словам NVIDIA, первый в мире Ethernet-коммутатор класса 800GbE, специально разработанный для применения гиперскейлерами в крупных облачных ИИ-комплексах. Применяемая архитектура позволяет гарантировать каждому клиенту оптимальный и постоянный уровень производительности, а потоковая телеметрия позволит находить и ликвидировать возможные «бутылочные горлышки» в сети буквально на лету.  Общая пропускная способность SN5600 составляет 51,2 Тбит/с. Коммутатор располагает 64 портами 800GbE в формате OSFP. В нём используется ASIC пятого поколения на базе архитектуры Spectrum-4. В качестве основного адаптера предлагается SuperNIC на базе DPU BlueField-3 с двумя 400GbE-портами. 
Фото: Twitter/NVIDIANetworkng Spectrum-X800 сопровождает полноценный спектр инфраструктурных компонентов, включая кабели DAC и LACC. С оптическими трансиверами длина соединения 800GbE может достигать двух километров. Начиная со следующего года, решения на базе новых сетевых платформ NVIDIA будут доступны от широкого круга поставщиков оборудования, включая Aivres, DDN, Dell Technologies, Eviden, Hitachi Vantara, HPE, Lenovo, Supermicro и VAST Data.
09.11.2021 [12:17], Алексей Степин
NVIDIA представила Quantum-2, первый 400G-коммутатор InfiniBand NDRNVIDIA, нынешний владелец Mellanox, представила обновления своих решений InfiniBand NDR: коммутаторы Quantum-2, сетевые адаптеры ConnectX-7 и ускорители DPU BlueField-3. Это весьма своевременный апдейт, поскольку 400GbE-решения набирают популярность, а с приходом PCIe 5.0 в серверный сегмент станут ещё более актуальными. 
NVIDIA Quantum-2 (Здесь и ниже изображения NVIDIA) Первый и самый важный анонс — это платформа Quantum-2. Новый коммутатор не только обеспечивает вдвое более высокую пропускную способность на порт (400 Гбит/с против 200 Гбит/c), но также предоставляет в три раза больше портов, нежели предыдущее поколение. Это сочетание позволяет снизить потребность в коммутаторах в 6 раз при той же суммарной ёмкости сети. При этом новая более мощная инфраструктура также окажется более экономичной и компактной.  Более того, Quantum-2 относится к серии «умных» устройств и содержит в 32 раза больше акселераторов, нежели Quantum HDR первого поколения. В нём также реализована предиктивная аналитика, позволяющая избежать проблем с сетевой инфраструктурой ещё до их возникновения; за это отвечает технология UFM Cyber-AI. Также коммутатор предлагает синхронизацию времени с наносекундной точностью, что важно для распределённых нагрузок.  7-нм чип Quantum-2 содержит 57 млрд транзисторов, то есть он даже сложнее A100 с 54 млрд транзисторов. В стандартной конфигурации чип предоставляет 64 порта InfiniBand 400 Гбит/с, однако может работать и в режиме 128 × 200 Гбит/с. Коммутаторы на базе нового сетевого процессора уже доступны у всех крупных поставщиков серверного оборудования, включая Inspur, Lenovo, HPE и Dell Technologies. Возможно масштабирование вплоть 2048 × 400 Гбит/с или 4096 × 200 Гбит/с. 
NVIDIA ConnectX-7 Конечные устройства для новой инфраструктуры InfiniBand доступны в двух вариантах: это относительно простой сетевой адаптер ConnectX-7 и куда более сложный BlueField-3. В первом случае изменения, в основном, количественные: новый чип, состоящий из 8 млрд транзисторов, позволил вдвое увеличить пропускную способность, равно как и вдвое же ускорить RDMA и GPUDirect. 
NVIDIA BlueField-3 DPU BlueField-3, анонсированный ещё весной этого года, куда сложнее с его 22 млрд транзисторов. Он предоставляет гораздо больше возможностей, чем обычный сетевой адаптер или SmartNIC, и крайне важен для будущего развития инфраструктурных решений NVIDIA. Начало поставок ConnectX-7 намечено на январь, а вот BlueField-3 появится только в мае 2022 года. Оба адаптера совместимы с PCIe 5.0.
28.06.2021 [13:22], Алексей Степин
Обновление NVIDIA HGX: PCIe-вариант A100 с 80 Гбайт HBM2e, InfiniBand NDR и Magnum IO с GPUDirect StorageНа суперкомпьютерной выставке-конференции ISC 2021 компания NVIDIA представила обновление платформы HGX A100 для OEM-поставщиков, которая теперь включает PCIe-ускорители NVIDIA c 80 Гбайт памяти, InfiniBand NDR и поддержку Magnum IO с GPUDirect Storage. В основе новинки лежат наиболее продвинутые на сегодняшний день технологии, имеющиеся в распоряжении NVIDIA. В первую очередь, это, конечно, ускорители на базе архитектуры Ampere, оснащённые процессорами A100 с производительностью почти 10 Тфлопс в режиме FP64 и 624 Топс в режиме тензорных вычислений INT8.  HGX A100 предлагает 300-Вт версию ускорителей с PCIe 4.0 x16 и удвоенным объёмом памяти HBM2e (80 Гбайт). Увеличена и пропускная способность (ПСП), в новой версии ускорителя она достигла 2 Тбайт/с. И если по объёму и ПСП новинки догнали SXM-версию A100, то в отношении интерконнекта они всё равно отстают, так как позволяют напрямую объединить посредством NVLink только два ускорителя.  В качестве сетевой среды в новой платформе NVIDIA применена технология InfiniBand NDR со скоростью 400 Гбит/с. Можно сказать, что InfiniBand догнала Ethernet, хотя не столь давно её потолком были 200 Гбит/с, а в плане латентности IB по-прежнему нет равных. Сетевые коммутаторы NVIDIA Quantum 2 поддерживают до 64 портов InfiniBand NDR и вдвое больше для скорости 200 Гбит/с, а также имеют модульную архитектуру, позволяющую при необходимости нарастить количество портов NDR до 2048. Пропускная способность при этом может достигать 1,64 Пбит/с.  Технология NVIDIA SHARP In-Network Computing позволяет компании заявлять о 32-крантом превосходстве над системами предыдущего поколения именно в области сложных задач машинного интеллекта для индустрии и науки. Естественно, все преимущества машинной аналитики используются и внутри самого продукта — технология UFM Cyber-AI позволяет новой платформе исправлять большинство проблем с сетью на лету, что минимизирует время простоя.  Отличным дополнением к новым сетевым возможностями является технология GPUDirect Storage, которая позволяет NVMe-накопителям общаться напрямую с GPU, минуя остальные компоненты системы. В качестве программной прослойки для обслуживания СХД новая платформа получила систему Magnum IO с поддержкой вышеупомянутой технологии, обладающую низкой задержкой ввода-вывода и по максимуму способной использовать InfiniBand NDR. 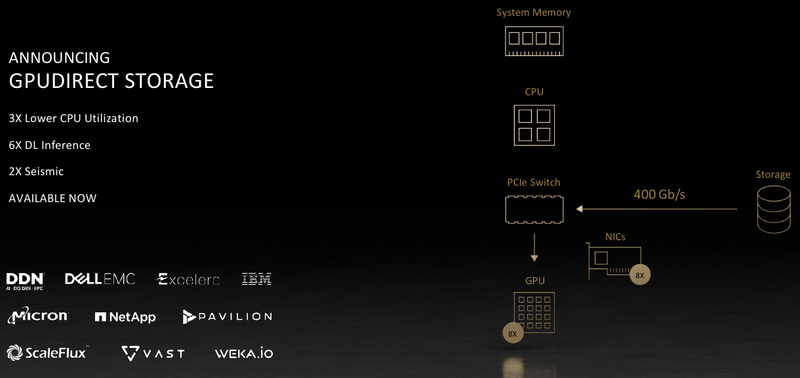 Три новых ключевых технологии NVIDIA помогут супервычислениям стать ещё более «супер», а суперкомпьютерам следующего поколения — ещё более «умными» и производительными. Достигнуты договорённости с такими крупными компаниями, как Atos, Dell Technologies, HPE, Lenovo, Microsoft Azure и NetApp. Решения NVIDIA используются как в индустрии — в качестве примера можно привести промышленный суперкомпьютер Tesla Automotive, так и в ряде других областей.  В частности, фармакологическая компания Recursion использует наработки NVIDIA в области машинного обучения для поиска новых лекарств, а национальный научно-исследовательский центр энергетики (NERSC) применяет ускорители A100 в суперкомпьютере Perlmutter при разработке новых источников энергии. И в дальнейшем NVIDIA продолжит своё наступление на рынок HPC, благо, она может предложить заказчикам как законченные аппаратные решения, так и облачные сервисы, также использующие новейшие технологии компании. |
|

