Материалы по тегу: rubin
|
23.03.2026 [12:55], Владимир Мироненко
Сначала Kyber, потом Feynman: NVIDIA раскрыла планы по выпуску ИИ-решений до 2028 годаВслед за анонсом ИИ-ускорителя LPU Groq 3 в составе платформы Vera Rubin компания NVIDIA представила обновлённую дорожную карту решений для ЦОД на период до 2028 года, включив в нее три поколения оборудования, пишет Data Center Dynamics. В рамках перехода на ежегодный цикл выпуска новых архитектур — Hopper, Blackwell (Ultra), Vera Rubin, компания после приобретения Groq за рекордные $20 млрд теперь планирует также ежегодно представлять новую архитектуру LPU. Выпуск LPU NVIDIA Groq 3 запланирован на II половину 2026 года. Также во II половине этого года выйдет платформа NVIDIA Vera Rubin, включающая, помимо NVIDIA Groq 3, Arm-процессоры Vera, ускорители Rubin, интерконнект NVLink 6, адаптеры ConnectX-9 SuperNIC и DPU BlueField-4, а также коммутаторы Spectrum/Quantum-6. На II половину 2027 года намечен выход ускорителя Rubin Ultra с четырьмя вычислительными чиплетами и 1 Тбайт HBM4E. Также во II половине следующего года выйдет второй LPU от NVIDIA — Groq LP35. Кроме того, в 2027 году компания планирует выпустить своё стоечное решение Kyber NVL144/NVL72. Система включает 144 ускорителя Rubin Ultra с NVLink 7, обеспечивая четырёхкратное повышение производительности по сравнению с системой Blackwell NVL72 (Oberon). 
Источник изображения: NVIDIA После анонса Rubin Ultra генеральный директор NVIDIA Дженсен Хуанг (Jensen Huang) заявил в 2025 году, что переход на эту платформу потребует «годы планирования». «Это не то же самое, что покупка ноутбука, — сказал он. — Нам нужно планировать с учётом территории и электроснабжения ЦОД вместе с инженерными командами на два-три года вперёд, поэтому я [показываю] дорожную карту». Планы NVIDIA на 2028 год включают масштабный запуск новых процессоров, ускорителей и LPU, получивших названия Rosa, Feynman и LP40 соответственно. По словам разработчика, в Feynman будет использоваться многослойная архитектура кристалла и высокоскоростная память для масштабирования производительности и увеличения пропускной способности. Также Feynman станет первым решением NVIDIA, в котором используются коммутаторы NVLink с интегрированной оптикой. Хуанг заявил, что спрос на продукцию NVIDIA к 2027 году достигнет отметки в $1 трлн, фактически удвоив свой прошлый прогноз. Финансовый директор Колетт Кресс (Colette Kress) уточнила позже, что эта цифра относится только к продуктам Blackwell и Rubin, а также к сопутствующему сетевому оборудованию, и не включает новые продукты, такие как LPU Groq и используемые отдельно процессоры. «Триллион долларов — это огромная сумма для инфраструктуры, — отметил Хуанг. — Вы должны быть полностью уверены, что триллион долларов, которые вы вкладываете, будут использованы, обеспечат высокую производительность, невероятную экономическую эффективность и будут иметь полезный срок службы на протяжении всего периода инвестиций в инфраструктуру. [NVIDIA] — единственная в мире инфраструктура, которую вы можете построить в любой точке мира с полной уверенностью».
17.03.2026 [10:32], Руслан Авдеев
NVIDIA анонсировала Space-1 Vera Rubin Module — ИИ-ускоритель для орбитальных ЦОД, который в 25 раз быстрее H100Глава NVIDIA Дженсен Хуанг (Jensen Huang) представил космический вычислительный модуль на архитектуре Vera Rubin. По его словам, модуль до 25 раз производительнее, чем NVIDIA H100, и шесть коммерческих космических компаний уже внедрили платформу, сообщает Tom’s Hardware. Space-1 Vera Rubin Module предназначен для орбитальных дата-центров, работающих с ИИ-моделями непосредственно в космосе. Он имеет тесно интегрированную архитектуру CPU–GPU и высокоскоростной интерконнект для работы с большими потоками данных от космических инструментов в режиме реального времени. Также предлагается вариант NVIDIA IGX Thor для критически важных периферийных сред с поддержкой выполнения ИИ-задач в режиме реального времени, безопасной загрузки, автономных операций и др. Наиболее компактный вариант NVIDIA Jetson Orin рассчитан на использование в спутниках с ограниченными размерами, весом и энергопотреблением — для систем бортового «зрения», навигации и обработки данных с датчиков. По данным NVIDIA, сейчас её новые платформы на Земле и в космосе используют компании Aetherflux, Axiom Space, Kepler Communications, Planet Labs PBC, Sophia Space и Starcloud. Kepler внедряет Jetson Orin в своей спутниковой группировке для управления данными и их маршрутизацией с помощью ИИ-инструментов. Jetson Orin применяется непосредственно в спутниках. 
Источник изображения: NVIDIA В октябре 2025 года основатель Amazon и Blue Origin Джефф Безос (Jeff Bezos) прогнозировал, что через 10–20 лет на орбите появятся ЦОД гигаваттного масштаба. Основными преимуществами таких решений назывались возможность непрерывного электроснабжения группировки с помощью солнечной энергии, а также упрощённая система охлаждения в космосе. Starcloud уже строит специальные орбитальные ИИ-ЦОД, предназначенные для обучения моделей и инференса непосредственно на орбите. Космические ЦОД — весьма перспективное направление в сфере ИИ. Одним из наиболее громких событий стала заявка SpaceX, попросившей у американских властей разрешение на вывод на орбиту миллиона микро-ЦОД. Инициатива подверглась критике Amazon как «спекулятивная», но компания столкнулась с критикой Федеральной комиссии по связи с США, потребовавшей навести порядок в собственном космическом бизнесе.
17.03.2026 [02:00], Владимир Мироненко
ИИ-ускорители Groq прописались в платформе NVIDIA Vera RubinNVIDIA объявила о том, что платформа Vera Rubin, объединяющая теперь уже семь различных чипов (ещё в январе их было шесть), которые вместе откроют новые горизонты агентного ИИ, запущена в производство. Платформа включает Arm-процессоры Vera, ускорители Rubin, интерконнект NVLink 6, адаптеры ConnectX-9 SuperNIC и DPU BlueField-4, а также Ethernet-коммутаторы Spectrum/Quantum-6. Седьмым чипом стал LPU Groq 3 — NVIDIA купила Groq за рекордные $20 млрд всего три месяца назад и активно наращивает производство LPU. Благодаря такому сочетанию компонентов платформа обеспечивает обработку ИИ-нагрузок на всех этапах — от масштабного предварительного обучения, постобучения и масштабирования во время тестирования до инференса агентных задач в реальном времени, говорит NVIDIA. «Vera Rubin — это скачок в развитии — семь прорывных чипов, пять стоек, один гигантский суперкомпьютер — созданный для обеспечения всех этапов работы ИИ», — сообщил Дженсен Хуанг (Jensen Huang), основатель и генеральный директор NVIDIA. Он отметил, что с появлением Vera Rubin в развитии агентного ИИ наступил переломный момент, положившей начало «крупнейшему в истории развёртыванию инфраструктуры». 
Источник изображений: NVIDIA «Платформа NVIDIA Vera Rubin предоставляет нам вычислительные ресурсы, сетевые возможности и системную архитектуру, позволяющие продолжать работу, одновременно повышая безопасность и надёжность, на которые полагаются наши клиенты», — подтвердил Дарио Амодеи (Dario Amodei), генеральный директор и соучредитель Anthropic. «Инфраструктура NVIDIA — это основа, которая позволяет нам расширять границы ИИ, — заявил Сэм Альтман (Sam Altman), генеральный директор OpenAI. — С NVIDIA Vera Rubin мы будем запускать более мощные модели и агентов в огромных масштабах и предоставлять более быстрые и надёжные системы сотням миллионов людей». Как отметила компания, Vera Rubin предлагает самую обширную комплексную ИИ-платформу — суперкомпьютер с множеством стоек, специально разработанных для ИИ, работающих как одна массивная, целостная система. NVIDIA Vera Rubin NVL72 обеспечивает высокую эффективность в обучение больших MoE-моделей с использованием вчетверо меньшего количества ускорителей по сравнению с платформой Blackwell и достижение до 10 раз большей пропускной способности инференса на ватт при в десять раз меньшей стоимости токена.  CPU-стойка Vera — это высокоплотная MGX-платформа с СЖО, объединяющая 256 процессоров Vera для обеспечения масштабируемой, энергоэффективной производительности с первоклассной однопоточной обработкой, что обеспечивает возможности для масштабируемого агентного ИИ. Стойки Vera имеют тесную синхронизацию сред во всей ИИ-фабрике. Вместе со стойками Rubin они обеспечивают основу крупномасштабных систем агентного ИИ и обучения с подкреплением — при этом Vera обеспечивает результаты в два раза эффективнее и наполовину быстрее, чем традиционные CPU (впрочем, в NVL8 по-прежнему будут Intel Xeon). Стойки Groq 3 LPX (тоже с СЖО и тоже на базе MGX) и Vera Rubin, разработанные для обеспечения низкой задержки и обработки больших контекстов, необходимых для агентных систем, обеспечивают до 35 раз более высокую пропускную способность инференса на мегаватт и до 10 раз больший потенциал дохода для моделей с триллионами параметров. В масштабе предприятия парк LPU функционирует как единый гигантский процессор для быстрого и детерминированного ускорения инференса.  Стойка LPX с 256 LPU-чипами имеет 128 Гбайт SRAM с агрегированной пропускной способностью 640 Тбайт/с. В сочетании с Vera Rubin NVL72 чипы LPU повышают эффективность декодирования, совместно вычисляя каждый слой модели ИИ для каждого выходного токена. Всё это позволяет работать с моделями с триллионами параметров и контектсным окном в миллионы токенов, сохраняя максимальную эффективность по энергопотреблению, памяти и вычислительным ресурсам. Любопытно, что Rubin CPX в этот раз NVIDIA решила особо не упоминать. Анонсированная вместе с Vera Rubin СХД BlueField-4 STX разработана специально для ИИ-нагрузок, обеспечивая бесперебойное расширение памяти GPU по всему POD-кластеру. Впрочем, теперь компания говорит, что BlueField-4 включает CPU Vera, а не Grace, и ConnectX-9 SuperNIC. STX обеспечивает высокоскоростной общий слой данных, оптимизированный для хранения и извлечения больших объёмов KV-кеша, генерируемых LLM и рабочими процессами агентного ИИ. А программная платформа DOCA Memos позволяет использовать выделенное KV-хранилище для увеличения пропускной способности инференса до пяти раз, также повышая энергоэффективность по сравнению с архитектурами хранения общего назначения.  Также NVIDIA совместно с более чем 200 партнёрами анонсировала платформу NVIDIA DSX для Vera Rubin, которая включает технологию DSX Max-Q, позволяющую динамически управлять питанием всей ИИ-фабрики целиком, позволяя увеличить на 30 % ИИ-инфраструктуру в ЦОД при том же энергопотреблении. ПО DSX Flex обеспечивает ИИ-фабрикам гибкость в работе с энергосетями, позволяя освоить до 100 ГВт неиспользуемой мощности сетей. Кроме того, NVIDIA выпустила эталонный проект Vera Rubin DSX AI Factory — схему для совместно разработанной ИИ-инфраструктуры, которая максимизирует количество токенов на ватт и общую пропускную способность, повышая отказоустойчивость системы и ускоряя развётывание. 
В Microsoft Azure появились первые Vera Rubin (Источник изображения: X/@satyanadella) Продукты на базе Vera Rubin будут доступны у партнёров NVIDIA, начиная со II половины этого года. В их число входят гиперскейлеры AWS, Google Cloud, Microsoft Azure и Oracle Cloud, а также партнёры NVIDIA Cloud — CoreWeave, Crusoe, Lambda, Nebius, Nscale и Together AI. Ожидается, что широкий спектр серверов на базе продуктов Vera Rubin будут поставлять глобальные производители систем Cisco, Dell Technologies, HPE, Lenovo и Supermicro, а также Aivres, ASUS, Foxconn, GIGABYTE, Inventec, Pegatron, Quanta Cloud Technology (QCT), Wistron и Wiwynn.
20.01.2026 [10:02], Владимир Мироненко
FP64 у вас ненастоящий: AMD сомневается в эффективности эмуляции научных расчётов на тензорных ядрах NVIDIAВместо создания специализированных чипов для аппаратных FP64-вычислений NVIDIA использует эмуляцию для повышения производительности HPC на ИИ-ускорителях, пишет The Register. Компания отказалась от развития FP64-блоков в поколении Blackwell Ultra, а в новейших ускорителях Rubin пиковая заявленная производительность векторных FP64-вычислений составляет 33 Тфлопс, тогда как у H100, вышедшего четыре года назад, она была равна 34 Тфлопс, а у Blackwell — около 40 Тфлопс. Если включить программную эмуляцию в библиотеках CUDA от NVIDIA, ускоритель, как утверждается, может достичь производительности до 200 Тфлопс в матричных FP64-вычислениях. Впрочем, и Blackwell с эмуляций способен выдать в этом случае до 150 Тфлопс, тогда как у Hopper были «честные» 67 Тфлопс. «В ходе многочисленных исследований с партнёрами и собственных внутренних изысканий мы обнаружили, что точность, достигаемая с помощью эмуляции, как минимум не уступает точности, получаемой от аппаратных тензорных ядер», — сообщил ресурсу The Register Дэн Эрнст (Dan Ernst), старший директор по суперкомпьютерным продуктам NVIDIA. В свою очередь, в AMD считают, что это утверждение справедливо не для всех сценариев. «В некоторых бенчмарках она показывает довольно хорошие результаты, но в реальных физических научных симуляциях это не очевидно», — говорит Николас Малайя (Nicholas Malaya), научный сотрудник AMD. Он выразил мнение, что, хотя эмуляция FP64, безусловно, заслуживает дальнейших исследований и экспериментов, такое решение ещё не готово к широкому применению. AMD и сама изучает возможность программной эмуляции FP64 на Instinct MI355X, чтобы определить области её возможного применения. 
Источник изображения: Hilda Trinidad / Unsplash Хотя чипы всё чаще используют типы данных с более низкой точностью, FP64 остаётся золотым стандартом для научных вычислений, и на то есть веские причины — FP64 не имеет себе равных по динамическому диапазону. Современные же LLM обучаются с использованием FP8-вычислений, а компактные типы данных MXFP8/MXFP4 или NVFP4 позволяют получить достаточный для ИИ диапазон значений. Это хорошее решение для нечёткой математики больших языковых моделей, но это не замена FP64 для HPC. ИИ-нагрузки обладают высокой устойчивостью к ошибкам, а HPC-задачи требуют высокой точности. AMD указала на то, что эмуляция FP64 у NVIDIA не совсем соответствует стандарту IEEE. Алгоритмы NVIDIA не учитывают такие понятия, как положительные и отрицательные нули, ошибки NaN (Not a Number) и ошибки infinite number (бесконечное число). Из-за этого небольшие ошибки в промежуточных вычислениях, используемых для эмуляции более высокой точности, могут привести к искажениям, способным повлиять на точность конечного результата, пояснил Малайя. По его словам, целесообразность использования эмуляции FP64 зависит от конкретного приложения. Эмуляция FP64 лучше всего работает для хорошо обусловленных проблем, где малые изменения «на входе» приводят к малым же изменениям в конечном результате. Ярким примером такой задачи является бенчмарк Linpack (HPL). «Но если вы посмотрите на материаловедение, коды для расчёта процессов горения, системы ленточых матриц и т.п., то увидите, что это гораздо менее обусловленные системы, и внезапно всё начинает давать сбои», — сказал он. 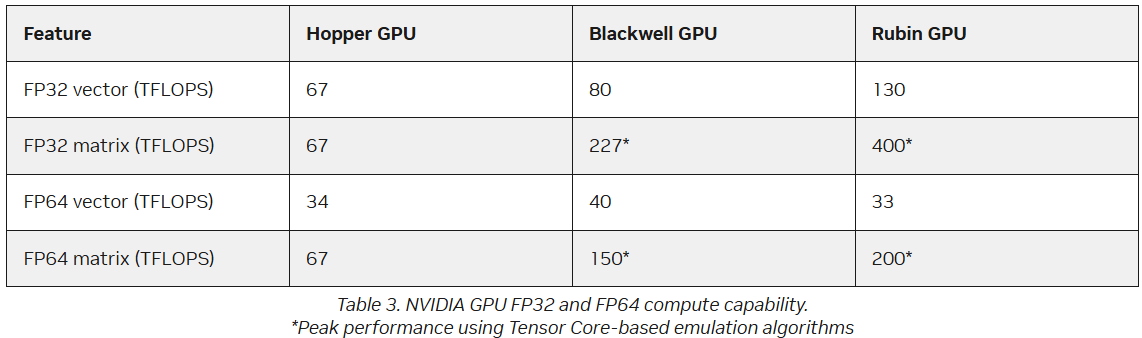
Источник изображения: NVIDIA Точность можно повысить, увеличив количество используемых операций, однако после определённого предела никаких преимуществ от эмуляции уже не будет. Вдобавок все эти операции требуют память. «У нас есть данные, которые показывают, что алгоритму Озаки требуется примерно вдвое больше памяти для эмуляции матриц FP64», — сказал Малайя. Поэтому компания готовит специализированные ускорители MI430X c повышенной FP64/FP32-производительностью, но, как опасаются учёные, она может оказаться не слишком в них заинтересована, поскольку ИИ-ускорители приносят больше денег. Эрнст утверждает, что для большинства специалистов в области HPC неполное соответствие стандарту IEEE не представляет большой проблемы. Всё во многом зависит от конкретного приложения. Тем не менее, NVIDIA разработала дополнительные алгоритмы для обнаружения и смягчения указанных выше ошибок и неэффективных операций эмуляции. Эрнст также признал, что использование памяти при эмуляции может быть несколько выше, но подчеркнул, что эти накладные расходы относятся к расчётам, а не к самому приложению — в большинстве случаев речь идёт о матрицах размером не более нескольких Гбайт. Впрочем, всё это не меняет того, что эмуляция полезна только для подмножества HPC-задач, которые полагаются на операции умножения плотных матриц (DGEMM). По словам Малайи, для 60–70 % рабочих нагрузок HPC эмуляция дает незначительные преимущества или ничего не меняет. «По нашим оценкам, подавляющее большинство реальных рабочих нагрузок HPC полагаются на векторное умножение (FMA), а не на DGEMM», — сказал он, отметив, что это действительно нишевый сегмент, хотя и не крошечная доля рынка. Для рабочих нагрузок, интенсивно использующих векторы, таких как вычислительная гидродинамика (CFD), ускорители Rubin по-прежнему будут полагаться на медленные векторные FP64-блоки.
06.01.2026 [14:28], Владимир Мироненко
NVIDIA объявила о запуске платформы Vera Rubin NVL72NVIDIA объявила о запуске платформы следующего поколения Rubin, которая приходит на смену Blackwell Ultra. Компания отметила, что платформа Rubin объединяет сразу пять инноваций, включая новейшие поколения интерконнекта NVIDIA NVLink, Transformer Engine, Confidential Computing и RAS Engine, а также процессор NVIDIA Vera. Примечательно, что NVIDIA снова решила вернуться к именованию на основе количества суперчипов (NVL72), а не ускорителей (NVL144), как обещала в прошлом году. Созданная с использованием экстремального совместного проектирования на аппаратном и программном уровнях, NVIDIA Vera Rubin обеспечивает десятикратное снижение стоимости токенов для инференса и четырёхкратное сокращение количества ускорителей для обучения моделей MoE по сравнению с платформой NVIDIA Blackwell. Коммутационные системы NVIDIA Spectrum-X Ethernet Photonics обеспечивают пятикратное повышение энергоэффективности и времени безотказной работы. 
Источник изображений: NVIDIA Платформа Rubin построена на шести чипах — Arm-процессоре Vera, ускорителе Rubin, коммутаторе NVLink 6, адаптере ConnectX-9 SuperNIC, DPU BlueField-4 и Ethernet-коммутаторе NVIDIA Spectrum-6. Ускорители Rubin поначалу будут доступны в двух форматах. В первом случае — в составе стоечной платформы DGX Vera Rubin NVL72, которая объединяет 72 ускорителя Rubin и 36 процессоров Vera, NVLink 6, ConnectX-9 SuperNIC и BlueField-4. Также ускорители Rubin будут доступны в составе платформы DGX/HGX Rubin NVL8 на базе x86-процессоров. Обе платформы будут поддерживаться кластерами NVIDIA DGX SuperPod, сообщил ресурс CRN.  Как отметила NVIDIA, разработанный для агентного мышления, процессор NVIDIA Vera является самым энергоэффективным процессором для крупномасштабных ИИ-фабрик. Он оснащён 88 кастомными Armv9.2-ядрами Olympus с 176 потоками с новой технологией пространственной многопоточности NVIDIA, 1,5 Тбайт системной памяти SOCAMM LPDDR5x (1,2 Тбайт/с), возможностями конфиденциальных вычислений и быстрым интерконнектом NVLink-C2C (1,8 Тбайт/с в дуплексе). 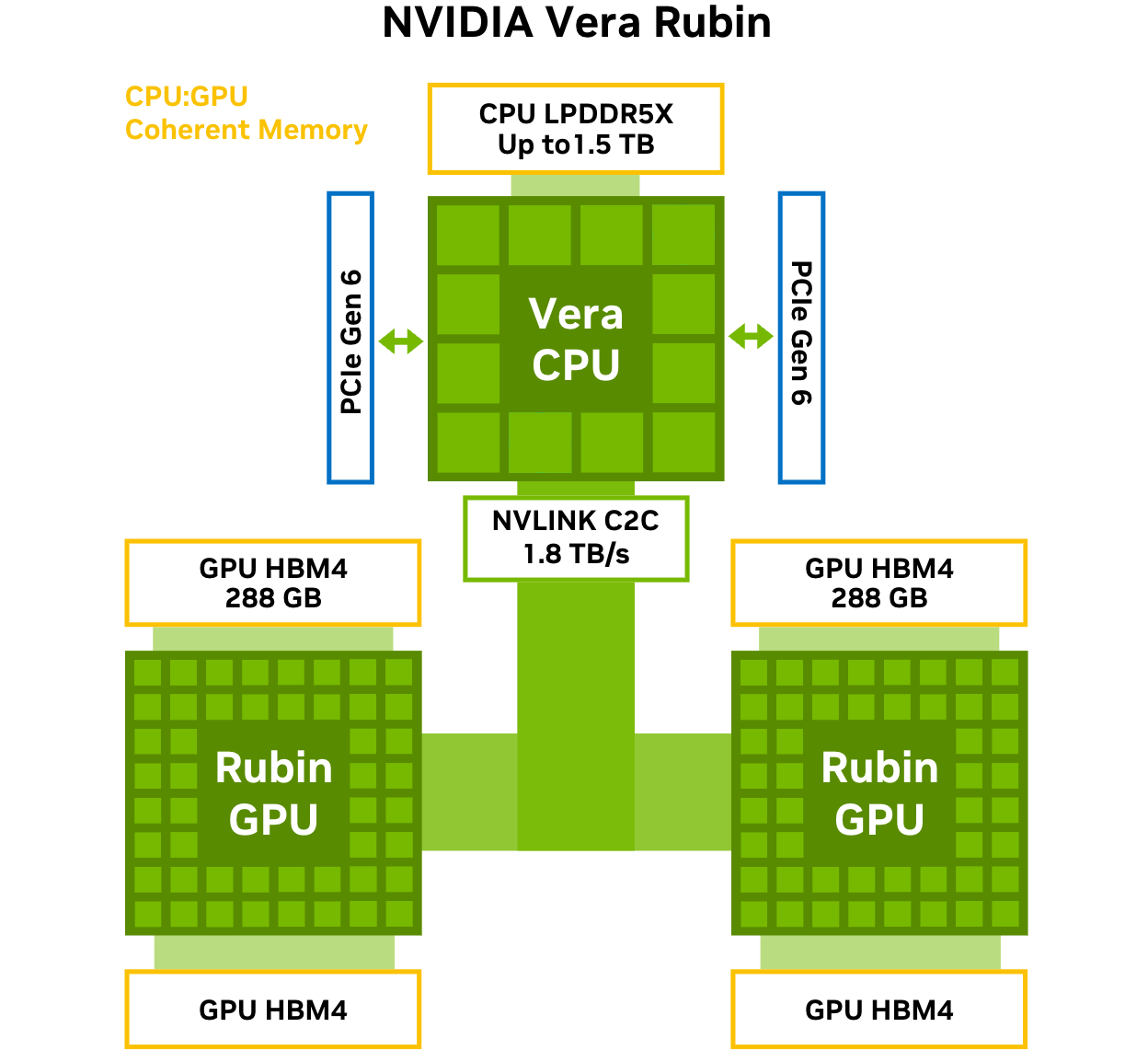 NVIDIA Rubin с аппаратным адаптивным сжатием данных обеспечивает до 50 Пфлопс (NVFP4) для инференса, что в пять раз быстрее, чем Blackwell. Он также обеспечивает до 35 Пфлопс (NVFP4) в режиме, что в 3,5 раза быстрее, чем его предшественник. Пропускная способность 288 Гбайт HBM4 составляет 22 Тбайт/с, что в 2,8 раза быстрее предшественника, а пропускная способность NVLink на один ускоритель вдвое выше — 3,6 Тбайт/с (в дуплексе).  NVIDIA также сообщила, что Vera Rubin NVL72 обладает 54 Тбайт памяти LPDDR5x, что в 2,5 раза больше, чем у Blackwell, и 20,7 Тбайт памяти HBM4, что на 50 % больше, чем у предшественника. Агрегированная пропускная способность HBM4 достигает 1,6 Пбайт/с, что в 2,8 раза больше, а скорость интерконнекта составляет 260 Тбайт/с, что вдвое больше, чем у платформы Blackwell NVL72, и «больше, чем пропускная способность всего интернета». Ожидаемый уровень энергопотребления составит от 190 до 230 кВт на стойку.  Компания отметила, что Vera Rubin NVL72 — первая стоечная платформа, обеспечивающая конфиденциальные вычисления, которая поддерживает безопасность данных на уровне доменов CPU, GPU и NVLink. Коммутатор NVLink 6 с жидкостным охлаждением оснащён 400G-блоками SerDes, обеспечивает пропускную способность 3,6 Тбайт/с на каждый GPU для связи между всеми GPU, общую пропускную способность 28,8 Тбайт/с и 14,4 Тфлопс внутрисетевых вычислений в формате FP8.  Хотя NVIDIA заявила, что Rubin находится в «полномасштабном производстве», аналогичные продукты от партнёров появятся только во II половине этого года. Среди ведущих мировых ИИ-лабораторий, поставщиков облачных услуг, производителей компьютеров и стартапов, которые, как ожидается, внедрят Rubin, компания назвала Amazon Web Services (AWS), Anthropic, Black Forest Labs, Cisco, Cohere, CoreWeave, Cursor, Dell Technologies, Google, Harvey, HPE, Lambda, Lenovo, Meta✴, Microsoft, Mistral AI, Nebius, Nscale, OpenAI, OpenEvidence, Oracle Cloud Infrastructure (OCI), Perplexity, Runway, Supermicro, Thinking Machines Lab и xAI.  ИИ-лаборатории, включая Anthropic, Black Forest, Cohere, Cursor, Harvey, Meta✴, Mistral AI, OpenAI, OpenEvidence, Perplexity, Runway, Thinking Machines Lab и xAI, рассматривают платформу NVIDIA Rubin для обучения более крупных и мощных моделей, а также для обслуживания мультимодальных систем с длинным контекстом с меньшей задержкой и стоимостью по сравнению предыдущими поколениями ускорителей. Партнёры по инфраструктурному ПО и хранению данных AIC, Canonical, Cloudian, DDN, Dell, HPE, Hitachi Vantara, IBM, NetApp, Nutanix, Pure Storage, Supermicro, SUSE, VAST Data и WEKA работают с NVIDIA над разработкой платформ следующего поколения для инфраструктуры Rubin.  В связи с тем, что рабочие нагрузки агентного ИИ генерируют огромные объёмы контекстных данных, NVIDIA также представляла новую платформу хранения контекста инференса NVIDIA Inference Context Memory Storage Platform — новый класс инфраструктуры хранения, разработанной для масштабирования контекста инференса.  Сообщается, что платформа, работающая на базе BlueField-4, обеспечивает эффективное совместное использование и повторное применение данных KV-кеша в рамках всей ИИ-инфраструктуры, повышая скорость отклика и пропускную способность, а также обеспечивая предсказуемое и энергоэффективное масштабирование агентного ИИ. Дион Харрис (Dion Harris), старший директор NVIDIA по высокопроизводительным вычислениям и решениям для ИИ-инфраструктуры, сообщил, что по сравнению с традиционными сетевыми хранилищами для данных контекста инференса, новая платформа обеспечивает до пяти раз больше токенов в секунду, в пять раз лучшую производительность на доллар и в пять раз лучшую энергоэффективность.
10.09.2025 [13:35], Сергей Карасёв
NVIDIA представила соускоритель Rubin CPX со 128 Гбайт GDDR7 для масштабных задач ИИ-инференсаNVIDIA неожиданно анонсировала чип Rubin CPX — GPU нового класса, спроектированный для масштабных задач ИИ-инференса и работы с моделями, использующими длинный контекст. Поставки решения планируется организовать в конце 2026 года. Чип Rubin CPX выполнен в виде монолитного кристалла и оснащён 128 Гбайт памяти GDDR7. Заявленная ИИ-производительность достигает 30 Пфлопс в режиме NVFP4. Предусмотрены по четыре блока NVENC и NVDEC для кодирования и декодирования видеоматериалов. Новинка дополнит другие ускорители компании. Оркестрацией нагрузок будет заниматься платформа NVIDIA Dynamo, распределяющая нагрузки между подходящими для каждой задачи ускорителями. 
Источник изображений: NVIDIA Изделие Rubin CPX предназначено для использования вместе с Arm-процессорами Vera и ускорителями Rubin в составе новой стоечной платформы NVIDIA Vera Rubin NVL144 CPX. Эта система будет объединять 144 чипа Rubin CPX, 144 чипа Rubin и 36 процессоров Vera (88 кастомных 3-нм Arm-ядер). Говорится об использовании суммарно 100 Тбайт памяти с агрегированной пропускной способностью 1,7 Пбайт/с. Общая производительность на операциях NVFP4 — до 8 Эфлопс, что примерно в 7,5 раза больше по сравнению с системами NVIDIA GB300 NVL72. Задействована система жидкостного охлаждения. Кроме того, NVIDIA планирует выпуск двухстоечного решения, включающего стойку Vera Rubin NVL144 CPX и «обычную» стойку Vera Rubin NVL144.  «Платформа Vera Rubin ознаменует собой новый скачок производительности в области вычислений ИИ, предлагая как GPU следующего поколения Rubin, так и чип нового класса CPX. Это первый CUDA GPU, специально разработанный для ИИ с длинным контекстом, когда модели одновременно обрабатывают миллионы токенов», — отмечает Дженсен Хуанг (Jensen Huang), основатель и генеральный директор NVIDIA. 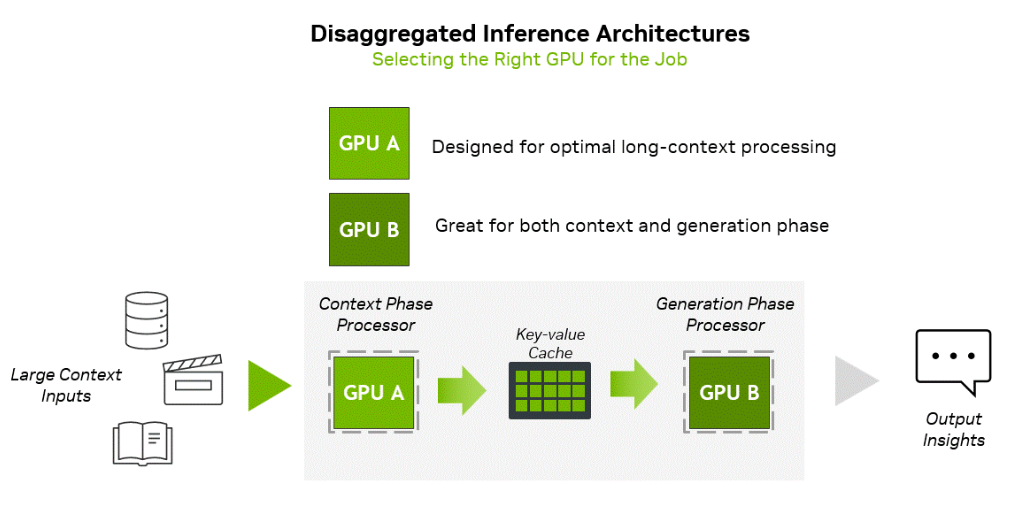 Основная задача Rubin CPX — работа с контекстом в больших моделях и создание KV-кеша. Эта операция ограничена вычислительными способностями чипа, тогда как генерация токенов зависит уже от пропускной способности памяти и интерконнекта для быстрого обмена данными. NVIDIA предложила разделить эти этапы и на аппаратном уровне. CPX лишён HBM, зато операции возведения в степень он делает втрое быстрее, чем Blackwell Ultra. 
20.03.2025 [01:10], Владимир Мироненко
Анонсированы суперускорители на Rubin и Rubin Ultra, в которых NVIDIA не будет ошибаться в подсчётахNVIDIA анонсировала ИИ-ускорители следующего поколения Rubin, которые придут на смену Blackwell Ultra во II половине 2026 года. Выход Rubin Ultra запланирован на II половину 2027 года. Компанию им составят Arm-процессоры Vera. Серия названа в честь астронома Веры Купер Рубин (Vera Florence Cooper Rubin), известной своими исследованиями тёмной материи. NVIDIA отметила, что в названии предыдущих ускорителей была «допущена ошибка». В Blackwell каждый чип состоит из двух GPU, но, например, в названии GB200/GB300 NVL72 упоминается только 72 GPU, хотя речь фактически идёт о 144 GPU. Поэтому, начиная с Rubin компания будет использовать новую схему наименований, которая больше не учитывает количество чипов, а относится исключительно к количеству GPU. Таким образом, следующее поколение суперускорителей, упакованных в ту же стойку Oberon, что используется для Grace Blackwell, получило название Vera Rubin NVL144. Rubin во многом повторяет дизайн Blackwell, поскольку R200 всё так же включает два кристалла GPU (в составе SXM7), способных выдавать до 50 Пфлопс в вычислениях FP4 (без разреженности), и 288 Гбайт памяти в восьми стеках 12-Hi, но на этот раз уже HBM4 с общей пропускную способностью 13 Тбайт/с (2048-бит шина). Кристаллы GPU будут изготовлены по техпроцессу TSMC N3P, а компанию им составят два IO-чиплета, отвечающие за все внешние коммуникации, пишет SemiAnalysis. Всё вместе будет упаковано посредством CoWoS-L. TDP новинок не указывается. 
Источник изображений: NVIDIA Чипы перейдут на интерконнект NVLink 6 со скоростью 1,8 Тбайт/с в каждую сторону (3,6 Тбайт/с в дуплексе), что вдвое выше, чем у текущего поколения NVLink 5. Аналогичным образом вырастет и коммутационная способность NVSwitch, а также NVLink C2C. Впрочем, при сохранении прежней схемы, когда один CPU обслуживает два модуля GPU, каждому из последних, по-видимому, достанется половина пропускной способности шины. Собственно процессор Vera получит 88 кастомных (а не Neoverse CSS в случае Grace) 3-нм Arm-ядра, причём с SMT, что даст 176 потоков. Каждый CPU получит порядка 1 Тбайт LPDDR-памяти и будет вдвое быстрее Grace при теплопакете в районе 50 Вт.  По словам NVIDIA, VR200 NVL144 будет в 3,3 раза быстрее: 3,6 Эфлопс в FP4-вычислениях для инференса и 1,2 Эфлопс в FP8 для обучения. Суммарный объём HBM-памяти составит более 20,7 Тбайт, системной памяти — 75 Тбайт. Внешняя сеть будет представлена адаптерами ConnectX-9 SuperNIC со скоростью 1,6 Тбит/с на порт, что вдвое больше, чем у ConnectX-8, обслуживающих GB300.  Во II половине 2027 года появится ускоритель Rubin Ultra (R300) с FP4-производительностью более 100 Пфлопс (без разреженности), объединяющий сразу четыре GPU, два IO-чиплета и 16 стеков HBM4e-памяти 16-Hi общим объёмом 1 Тбайт (32 Тбайт/с) в упаковке SXM8. Более того, ускорители, по-видимому, получат ещё и LPDDR-память. Процессор Vera перекочует в новую платформу без изменений, один CPU будет приходиться на четыре GPU. Внутренней шиной станет NVLink 7, которая сохранит скорость NVLink 6, зато получит вчетверо более производительные коммутатор NVSwitch. А вот внешнее подключение по-прежнему будут обслуживать адаптеры ConnectX-9.  Новая стойка Kyber полностью поменяет компоновку. Узлы теперь напоминают вертикальные блейд-серверы, используемые в суперкомпьютерах. Каждый узел (VR300) будет включать один процессор Vera и один ускоритель Rubin Ultra. Всего таких узлов будет 144, что в сумме даёт 144 CPU, 576 GPU и 144 Тбайт HBM4e. Суперускоритель Rubin Ultra NVL576 будет потреблять 600 кВт и обеспечит быстродействие в 15 Эфлопс для инференса (FP4) и 5 Эфлопс для обучения (FP8). При этом упоминается, что объём быстрой (fast) памяти составит 365 Тбайт, но сколько из них достанется CPU, не уточняется.  Дальнейшие планы NVIDIA включают выход во II половине 2028 года первого ускорителя на новой архитектуре Feynman, названной в честь физика-теоретика Ричарда Филлипса Фейнмана (Richard Phillips Feynman). Сообщается, что Feynman будет полагаться на память HBM «следующего поколения» и, вероятно, на CPU Vera. Это поколение также получит коммутаторы NVSwitch 8 (NVL-Next), сетевые коммутаторы Spectrum7 и адаптеры ConnectX-10.  UPD: осенью компания представила соускорители Rubin CPX для масштабных задач ИИ-инференса, которые дополняют платформу Vera Rubin. Эти чипы будут доступны как в составе гибридной платформы NVIDIA Vera Rubin NVL144 CPX (144 × Rubin CPX + 144 × Rubin + 36 × Vera), так и в виде двухстоечного решения: Vera Rubin NVL144 CPX + Vera Rubin NVL144.
05.07.2024 [09:18], Владимир Мироненко
Потрать доллар — получи семь: ИИ-арифметика от NVIDIANVIDIA заявила, что инвестиции в покупку её ускорителей весьма выгодны, передаёт ресурс HPCwire. По словам NVIDIA, компании, строящие огромные ЦОД, получат большую прибыль в течение четырёх-пяти лет их эксплуатации. Заказчики готовы платить миллиарды долларов, чтобы не отстать в ИИ-гонке. «Каждый доллар, вложенный провайдером облачных услуг в ускорители, вернётся пятью долларами через четыре года», — заявил Иэн Бак (Ian Buck), вице-президент HPC-подразделения NVIDIA на конференции BofA Securities 2024 Global Technology Conference. Он отметил, что использование ускорителей для инференса несёт ещё больше выгоды, позволяя получить уже семь долларов за тот же период. Как сообщается, инференс ИИ-моделей Llama, Mistral и Gemma становится всё масштабнее. Для удобства NVIDIA упаковывает открытые ИИ-модели в оптимизированные и готовые к запуску контейнеры NIM. Компания отметила, что её новейшие ускорители Blackwell оптимизированы для инференса. Они, в частности, поддерживают типы данных FP4/FP6, что повышает энергоэффективность оборудования при выполнении рабочих нагрузок ИИ с низкой интенсивностью. 
Источник изображений: NVIDIA Провайдеры облачных услуг планируют строительство ЦОД на пару лет вперёд и хотят иметь представление о том, какими будут ускорители в обозримом будущем. Бак отметил, что провайдерам важно знать, как будут выглядеть ЦОД с серверами на базе чипов Blackwell и чем они будут отличаться от дата-центров на Hopper. Скоро на смену Blackwell придут ускорители Rubin. Их выпуск начнётся в 2026 году, так что гиперскейлерам уже можно готовиться к обновлению дата-центров. Как ожидается, чипы Blackwell, первые партии которых будут поставлены к концу года, будут в дефиците. «С каждым новым технологическим переходом возникает… сочетание проблем спроса и предложения», — отметил Бак. По его словам, операторы ЦОД постепенно отказываются от инфраструктуры на базе CPU, освобождая место под большее количество ускорителей. Ускорители Hopper пока остаются в ЦОД и всё ещё будут основными «рабочими лошадками» для ИИ, но вот решения на базе архитектур Ampere и Volta уже перепродаются.  Microsoft и Google сделали ставку на ИИ и сейчас работают над более функциональными большими языковыми моделями, причём Microsoft (и OpenAI) в значительной степени полагается на ускорители NVIDIA, тогда как Google опирается на TPU собственной разработки для использования в своей ИИ-инфраструктуре. Пока что самая крупная модель насчитывает порядка 1,8 трлн параметров, но по словам Бака, это только начало. В дальнейшем появятся модели с триллионами параметров, вокруг которой будут построены более мелкие и более специализированные модели. Так, свежая GPT-модель (вероятно, речь о GPT-4o) включает 16 отдельных нейросетей. NVIDIA уже адаптирует свои ускорители к архитектуре Mixture of Experts (MoE, набор экспертов), где процесс обработки запроса пользователя делится между несколькими специализированными «экспертными» нейросетями. GB200 NVL72, по словам Бака, идеально подходит для MoE благодаря множеству ускорителей связанных быстрым интерконнектом, каждый из которых может обрабатывать часть запроса и быстро делится ответом с другими. |
|

