Материалы по тегу: vera
|
03.06.2026 [10:59], Сергей Карасёв
Dell представила серверы PowerEdge на базе NVIDIA Vera для агентного ИИКомпания Dell Technologies сообщила об обновлении семейства решений AI Factory with NVIDIA, ориентированных на внедрение ИИ. Дебютировали серверы PowerEdge R9822 и PowerEdge M9822 на аппаратной платформе NVIDIA Vera, предназначенные в том числе для развёртывания ИИ-агентов. Процессоры Vera содержат 88 ядер Olympus (176 потоков инструкций), совместимых с набором инструкций Arm v9.2. Возможно использование до 1,5 Тбайт LPDDR5X с пропускной способностью до 1,2 Тбайт/с. Сервер PowerEdge R9822 выполнен в форм-факторе 3U и оснащён воздушным охлаждением. Система подходит для различных сценариев использования — от агентных приложений и аналитики данных до задач общего назначения, обрабатываемых посредством CPU. Машина может интегрироваться в инфраструктуры существующих дата-центров. В свою очередь, модель PowerEdge M9822 наделена системой прямого жидкостного охлаждения. Этот сервер обеспечивает высокую плотность мощности в средах, оптимизированных для ИИ-агентов и НРС. 
Источник изображения: Dell Прочие характеристики новинок пока не раскрываются. Но отмечается, что платформа Dell AI Factory with NVIDIA поддерживает такие сетевые технологии, как Spectrum-X Ethernet и Quantum-X800 InfiniBand. Могут использоваться программные решения NVIDIA AI Enterprise, мультимодальные языковые модели NVIDIA Nemotron, среда OpenShell и пр. В продажу по всему миру серверы PowerEdge R9822 и PowerEdge M9822 поступят в сентябре текущего года. Нужно отметить, что решения на платформе NVIDIA Vera готовят и другие ведущие поставщики серверного оборудования. В частности, такие системы недавно анонсировала компания HPE.
02.06.2026 [11:12], Сергей Карасёв
HPE представила сервер ProLiant Compute DL394 Gen12 на платформе NVIDIA VeraКомпания HPE анонсировала сервер ProLiant Compute DL394 Gen12 для ресурсоёмких нагрузок в области ИИ и обработки данных. Система выполнена на аппаратной платформе NVIDIA Vera. Изделия Vera насчитывают 88 ядер Olympus, совместимых с набором инструкций Arm v9.2. Возможна одновременная обработка до 176 потоков инструкций. Поддерживается до 1,5 Тбайт LPDDR5X с пропускной способностью до 1,2 Тбайт/с. Характеристики ProLiant Compute DL394 Gen12 пока полностью не раскрываются. Известно, что новинка выполнена в форм-факторе 2U. HPE отмечает, что изделия Vera благодаря монолитной конструкции позволяют решить проблему неоднородного доступа к памяти, которая может наблюдаться при использовании традиционных чиплетных архитектур с большим количеством ядер. Эта особенность приводит к переменным задержкам и непредсказуемой производительности. В случае Vera каждому вычислительному ядру предоставляется полоса пропускания до 14 Гбайт/с, что даёт возможность обрабатывать данные на стабильно высокой скорости. 
Источник изображения: HPE В сервере реализованы средства управления HPE Integrated Lights-Out (HPE iLO 7). Говорится о защите от будущих кибератак, основанных на квантовых вычислениях, в соответствии с требованиями Национального института стандартов и технологий США (NIST). Средства HPE Compute Ops Management (COM) обеспечивают унифицированное управление серверной инфраструктурой из единой консоли. ProLiant Compute DL394 Gen12 может применяться для агентного ИИ, обработки больших объёмов транзакций и других задач. В продажу сервер поступит осенью текущего года.
27.05.2026 [00:56], Владимир Мироненко
Серверные Arm-процессоры NVIDIA Vera обогнали современные Intel Xeon и AMD EPYC в некоторых тестахПортал Phoronix провёл тестирование серверного Arm-процессора NVIDIA Vera, разработанного специально для обеспечения функционирования агентного ИИ, взяв для сравнения одно- и двухсокетные конфигурации на базе Intel Xeon 6980P (Granite Rapids-AP), а также AMD EPYC Turin: 9755, 9575F и 9475F. Также в сравнительное тестирование включили процессоры NVIDIA первого поколения Grace на базе ядер Arm Neoverse V2 (Demeter). Сообщается, что NVIDIA дала добро на проведение на этом предрелизном чипе тестов только для определённых рабочих нагрузок, соответствующих предполагаемым задачам/областям применения Vera в ЦОД, включая стандартные рабочие нагрузки, такие как компиляция, STREAM, кодирование видео, Python/Java и производительность СУБД. Исходя из среднего геометрического значения результатов тестов NVIDIA Vera занял первое место, превысив почти на 11 % лучшие результаты самых передовых разработок AMD, и примерно на 55,3 % показатели лучшей односокетной конфигурации Intel Xeon. Он также превзошёл в тестах двухсокетные конфигурации, что говорит о проблемах масштабирования некоторых рабочих нагрузок на нескольких сокетах. Эти ограниченные тесты отражают превосходство NVIDIA Vera по сравнению с любой архитектурой на базе Arm, с TDP 450 Вт для процессора и 50 Вт для пула памяти объемом 768 Гбайт. 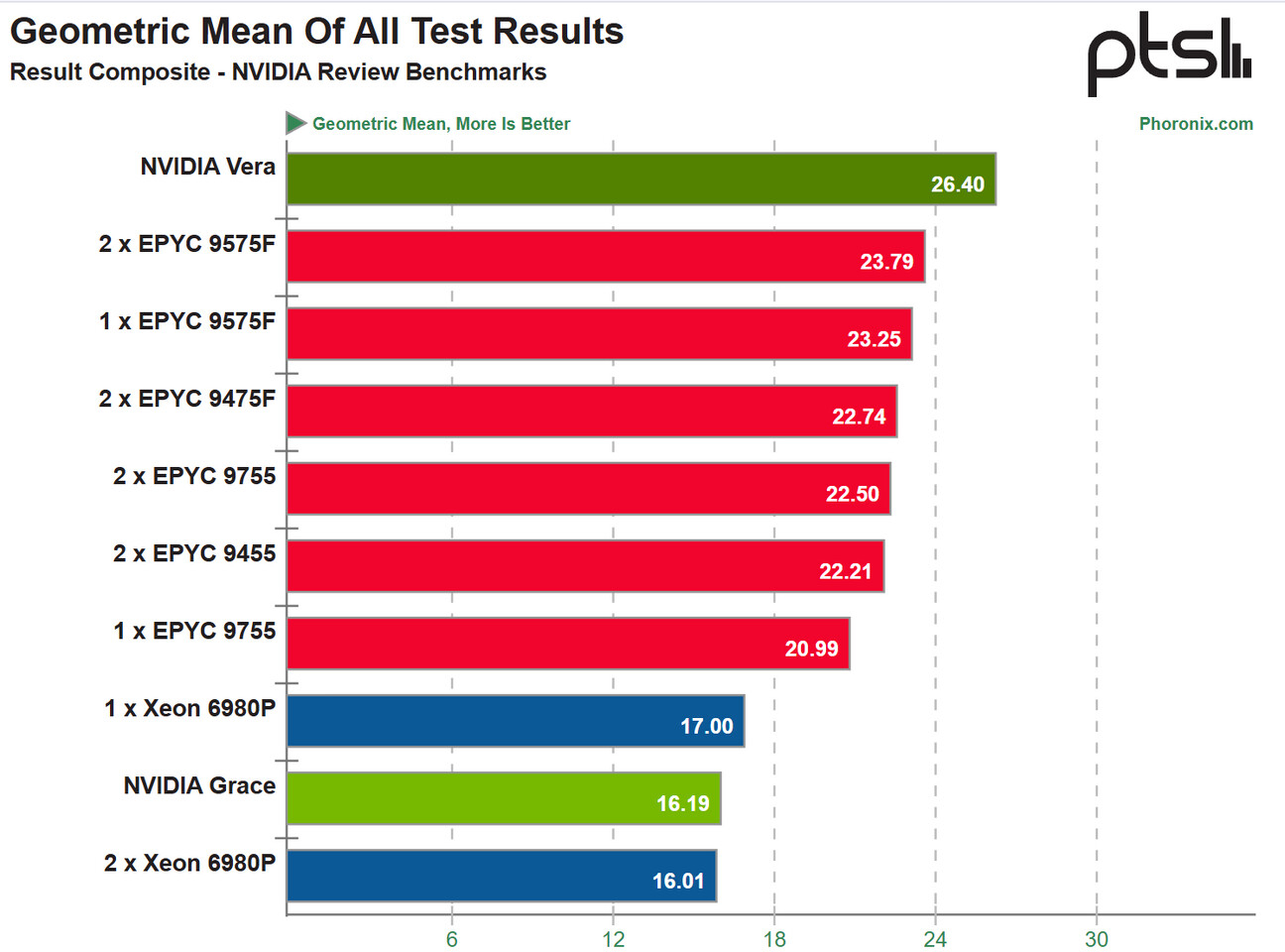
Источник изображения: Phoronix Предполагается, что NVIDIA продаст процессоров Vera и Grace на сумму около $20 млрд, охватив общий потенциальный рынок (TAM) в $200 млрд. NVIDIA сотрудничает со всеми крупными гиперскейлерами для поставки стоек с процессорами Vera (чаще всего в составе Vera Rubin), также наблюдается множество развёртываний у поставщиков инфраструктуры для их собственных задач и предложений для сторонних клиентов. Такой подход позволит NVIDIA выйти на огромный рынок процессоров, став одним из лидеров уже в этом году.
19.05.2026 [17:00], Руслан Авдеев
Arm-процессоры NVIDIA Vera поставили в ведущие ИИ-лаборатории мира — Oracle развернёт сотни тысяч таких CPUПервые CPU Vera, разработанные компанией NVIDIA, поставили в Anthropic, OpenAI, Oracle Cloud Infrastructure (OCI) и SpaceX/xAI. Процессоры специально разработаны с учётом особенностей «агентных» ИИ-систем и отличаются от обычных CPU. Это первый кастомный процессор NVIDIA, специально разработанный для агентных систем. Он обеспечивает оркестрацию, вызов инструментов, RL-нагрузки, анализ данных, «песочницы» для агентов и др. Процессор предназначен для ИИ-лабораторий, облачных провайдеров и компаний, масштабно работающих с агентными ИИ-системами. Модель получила 88 кастомных ядер Olympus, а пропускная способность памяти составляет 1,2 Тбайт/с. Глава NVIDIA Дженсен Хуанг (Jensen Huang) позиционирует Vera как новый многомиллиардный вектор развития компании. Как сообщает NVIDIA, агентный ИИ создаёт намного более высокую нагрузку на вычислительную инфраструктуру, от компиляции и тестирования программного кода до анализа данных, поиска файлов и др. При этом ИИ-агенты не просто используют ускорители, но и требуют оркестрации, управления агентными «песочницами», и т. п., это работа для CPU. Поток параллельных задач перегружает не рассчитанные на это CPU, но характеристики Vera позволяют повысить эффективность ИИ-фабрик целиком. 
Источник изображения: NVIDIA OCI намерена развернуть сотни тысяч CPU Vera для обеспечения работы нового поколения корпоративного ИИ. Это первый облачный провайдер, намеренный внедрить Vera в таких масштабах. Для корпоративных клиентов это означает, что будет создана агентная ИИ-инфраструктура уровня, недоступного другим облачным провайдерам. Ранее сообщалось, что Oracle строит «вчерашние» ЦОД, не имея на это достаточно средств и теперь, компания, похоже, готова опровергнуть этот тезис. 
Источник изображения: NVIDIA Процессор не только является самостоятельным CPU, но и лежит в основе платформы Vera Rubin NVL72, где он посредством NVLink-C2C второго поколения связан с парой GPU Rubin. Стоит отметить, что работы с Vera фактически ведутся уже давно. Например, ещё в марте HPE представила узлы на базе NVIDIA Vera для платформы Cray Supercomputing GX5000.
23.03.2026 [12:55], Владимир Мироненко
Сначала Kyber, потом Feynman: NVIDIA раскрыла планы по выпуску ИИ-решений до 2028 годаВслед за анонсом ИИ-ускорителя LPU Groq 3 в составе платформы Vera Rubin компания NVIDIA представила обновлённую дорожную карту решений для ЦОД на период до 2028 года, включив в нее три поколения оборудования, пишет Data Center Dynamics. В рамках перехода на ежегодный цикл выпуска новых архитектур — Hopper, Blackwell (Ultra), Vera Rubin, компания после приобретения Groq за рекордные $20 млрд теперь планирует также ежегодно представлять новую архитектуру LPU. Выпуск LPU NVIDIA Groq 3 запланирован на II половину 2026 года. Также во II половине этого года выйдет платформа NVIDIA Vera Rubin, включающая, помимо NVIDIA Groq 3, Arm-процессоры Vera, ускорители Rubin, интерконнект NVLink 6, адаптеры ConnectX-9 SuperNIC и DPU BlueField-4, а также коммутаторы Spectrum/Quantum-6. На II половину 2027 года намечен выход ускорителя Rubin Ultra с четырьмя вычислительными чиплетами и 1 Тбайт HBM4E. Также во II половине следующего года выйдет второй LPU от NVIDIA — Groq LP35. Кроме того, в 2027 году компания планирует выпустить своё стоечное решение Kyber NVL144/NVL72. Система включает 144 ускорителя Rubin Ultra с NVLink 7, обеспечивая четырёхкратное повышение производительности по сравнению с системой Blackwell NVL72 (Oberon). 
Источник изображения: NVIDIA После анонса Rubin Ultra генеральный директор NVIDIA Дженсен Хуанг (Jensen Huang) заявил в 2025 году, что переход на эту платформу потребует «годы планирования». «Это не то же самое, что покупка ноутбука, — сказал он. — Нам нужно планировать с учётом территории и электроснабжения ЦОД вместе с инженерными командами на два-три года вперёд, поэтому я [показываю] дорожную карту». Планы NVIDIA на 2028 год включают масштабный запуск новых процессоров, ускорителей и LPU, получивших названия Rosa, Feynman и LP40 соответственно. По словам разработчика, в Feynman будет использоваться многослойная архитектура кристалла и высокоскоростная память для масштабирования производительности и увеличения пропускной способности. Также Feynman станет первым решением NVIDIA, в котором используются коммутаторы NVLink с интегрированной оптикой. Хуанг заявил, что спрос на продукцию NVIDIA к 2027 году достигнет отметки в $1 трлн, фактически удвоив свой прошлый прогноз. Финансовый директор Колетт Кресс (Colette Kress) уточнила позже, что эта цифра относится только к продуктам Blackwell и Rubin, а также к сопутствующему сетевому оборудованию, и не включает новые продукты, такие как LPU Groq и используемые отдельно процессоры. «Триллион долларов — это огромная сумма для инфраструктуры, — отметил Хуанг. — Вы должны быть полностью уверены, что триллион долларов, которые вы вкладываете, будут использованы, обеспечат высокую производительность, невероятную экономическую эффективность и будут иметь полезный срок службы на протяжении всего периода инвестиций в инфраструктуру. [NVIDIA] — единственная в мире инфраструктура, которую вы можете построить в любой точке мира с полной уверенностью».
23.03.2026 [09:31], Сергей Карасёв
HPE представила узлы на базе NVIDIA Vera для платформы Cray Supercomputing GX5000Компания HPE анонсировала новые решения семейства NVIDIA AI Computing by HPE, ориентированные на крупномасштабные ИИ-платформы и суперкомпьютерные системы. О намерении использовать такие инфраструктурные продукты в числе прочих сообщили Аргоннская национальная лаборатория (ANL) Министерства энергетики США (DOE), Hudson River Trading (HRT), Корейский институт научно-технической информации (KISTI) и Центр высокопроизводительных вычислений HLRS при Штутгартском университете в Германии. В частности, представлены новые узлы для суперкомпьютерной платформы HPE Cray Supercomputing GX5000 — blade-серверы HPE Cray Supercomputing GX240. Эти устройства могут нести на борту до 16 процессоров NVIDIA Vera (88C/176T). В одной стойке могут быть размещены до 40 узлов, что в сумме даёт 640 чипов Vera и 56 320 ядер Olympus. Реализовано жидкостное охлаждение. Система предназначена для решения наиболее ресурсоёмких вычислительных задач в области ИИ. Новые серверы появятся на рынке в следующем году. Для платформы HPE Cray Supercomputing GX5000 также будут доступны коммутаторы NVIDIA Quantum-X800 InfiniBand, предоставляющие 144 порта с пропускной способностью до 800 Гбит/с. В этих устройствах реализованы развитые функции снижения энергопотребления. Кроме того, HPE готовит OCP-серверы высокой плотности Compute XD700 для обучения LLM и инференса. В основу данной системы положена платформа NVIDIA HGX Rubin NVL8, а одна стойка может насчитывать до 128 ускорителей Rubin. Данное решение появится в начале 2027-го. 
Источник изображений: HPE Помимо этого, анонсирована стоечная система нового поколения NVIDIA Vera Rubin NVL72 by HPE — это флагманская ИИ-платформа, разработанная для моделей с более чем 1 трлн параметров. Конфигурация включает 36 процессоров Vera, 72 чипа Rubin, интерконнект NVIDIA NVLink шестого поколения, сетевые адаптеры NVIDIA ConnectX-9 SuperNIC и DPU NVIDIA BlueField-4. Система поступит в продажу в декабре 2026 года. 
17.03.2026 [10:32], Руслан Авдеев
NVIDIA анонсировала Space-1 Vera Rubin Module — ИИ-ускоритель для орбитальных ЦОД, который в 25 раз быстрее H100Глава NVIDIA Дженсен Хуанг (Jensen Huang) представил космический вычислительный модуль на архитектуре Vera Rubin. По его словам, модуль до 25 раз производительнее, чем NVIDIA H100, и шесть коммерческих космических компаний уже внедрили платформу, сообщает Tom’s Hardware. Space-1 Vera Rubin Module предназначен для орбитальных дата-центров, работающих с ИИ-моделями непосредственно в космосе. Он имеет тесно интегрированную архитектуру CPU–GPU и высокоскоростной интерконнект для работы с большими потоками данных от космических инструментов в режиме реального времени. Также предлагается вариант NVIDIA IGX Thor для критически важных периферийных сред с поддержкой выполнения ИИ-задач в режиме реального времени, безопасной загрузки, автономных операций и др. Наиболее компактный вариант NVIDIA Jetson Orin рассчитан на использование в спутниках с ограниченными размерами, весом и энергопотреблением — для систем бортового «зрения», навигации и обработки данных с датчиков. По данным NVIDIA, сейчас её новые платформы на Земле и в космосе используют компании Aetherflux, Axiom Space, Kepler Communications, Planet Labs PBC, Sophia Space и Starcloud. Kepler внедряет Jetson Orin в своей спутниковой группировке для управления данными и их маршрутизацией с помощью ИИ-инструментов. Jetson Orin применяется непосредственно в спутниках. 
Источник изображения: NVIDIA В октябре 2025 года основатель Amazon и Blue Origin Джефф Безос (Jeff Bezos) прогнозировал, что через 10–20 лет на орбите появятся ЦОД гигаваттного масштаба. Основными преимуществами таких решений назывались возможность непрерывного электроснабжения группировки с помощью солнечной энергии, а также упрощённая система охлаждения в космосе. Starcloud уже строит специальные орбитальные ИИ-ЦОД, предназначенные для обучения моделей и инференса непосредственно на орбите. Космические ЦОД — весьма перспективное направление в сфере ИИ. Одним из наиболее громких событий стала заявка SpaceX, попросившей у американских властей разрешение на вывод на орбиту миллиона микро-ЦОД. Инициатива подверглась критике Amazon как «спекулятивная», но компания столкнулась с критикой Федеральной комиссии по связи с США, потребовавшей навести порядок в собственном космическом бизнесе.
17.03.2026 [10:21], Сергей Карасёв
NVIDIA представила серверные Arm-процессоры Vera с 88 ядрами Olympus для ИИ и не толькоNVIDIA анонсировала процессоры Vera, спроектированные с прицелом на современные ресурсоёмкие задачи в области ИИ. Изделия, как утверждается, обеспечивают исключительную производительность каждого ядра, а также высокую пропускную способность памяти и коммутационной сети. В основу Vera положены ядра Olympus — это первые CPU-решения NVIDIA, специально разработанные для дата-центров. Olympus используют интерфейс выборки и декодирования шириной в 10 инструкций, а также нейронный алгоритм предсказания ветвлений, позволяющий оценивать два варианта ветвления за каждый цикл. Изделие полностью совместимо с набором инструкций Arm v9.2 и существующим ПО. 
Источник изображений: NVIDIA Конфигурация Vera предусматривает наличие 88 ядер Olympus с возможностью одновременной обработки до 176 потоков инструкций. Объём кеша L3 составляет 162 Мбайт. Задействована шина NVIDIA Scalable Coherency Fabric (SCF) второго поколения, первоначально разработанная для CPU Grace. В составе процессора SCF отвечает за связь вычислительных ядер Olympus с общим кешем L3 и подсистемой памяти, обеспечивая стабильную задержку и пропускную способность на уровне 3,4 Тбайт/с: это позволяет использовать более 90 % пиковой пропускной способности памяти под нагрузкой. Каждому ядру Olympus доступна полоса до 14 Гбайт/с, что примерно в три раза превышает пропускную способность на ядро в традиционных CPU для дата-центров, говорит NVIDIA. 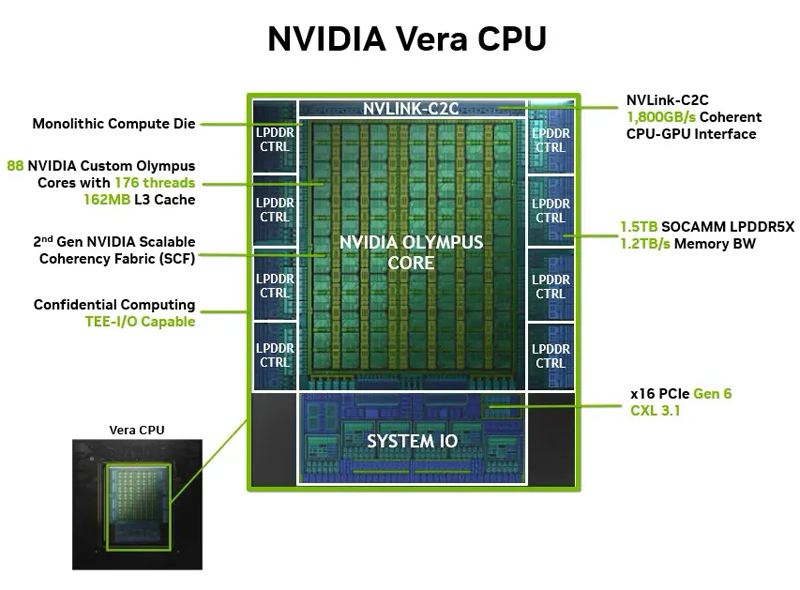 В составе Vera применяется подсистема памяти LPDDR5X на основе модулей SOCAMM. Суммарная ёмкость может составлять до 1,5 Тбайт, что втрое больше по сравнению с решениями предыдущего поколения. Пропускная способность памяти достигает 1,2 Тбайт/с, тогда как энергопотребление составляет менее 50% по сравнению с традиционными конфигурациями DDR. При этом модули SOCAMM являются заменяемыми, что упрощает модернизацию и обслуживание систем.  Процессор Vera выполнен на основе единого монолитного вычислительного кристалла. Каждое ядро обеспечивается единообразной пропускной способностью. Большинство операций, чувствительных к задержкам, выполняются локально, что позволяет минимизировать межкристальный трафик, который обычно присутствует в традиционных CPU. В целом, как утверждается, реализованные архитектурные особенности позволяют чипам Vera демонстрировать до 1,5 раз более высокую производительность одного ядра по сравнению с конкурирующими решениями x86 при выполнении задач в песочнице с максимальной нагрузкой на сокет. 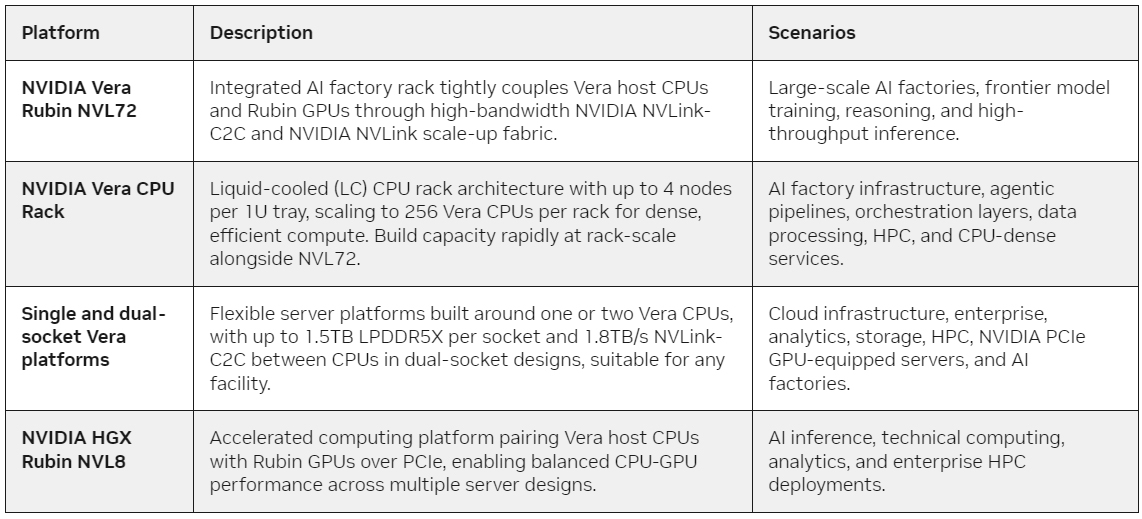 NVIDIA разработала семейство платформ на базе Vera для решения разнообразных задач в сфере ИИ. Это, в частности, CPU-стойки с жидкостным охлаждением, а также системы с ускорителями Rubin. Устройства на базе Vera будут поставляться крупными OEM-производителями, включая Cisco, Dell, HPE, Lenovo и Supermicro. Такие машины станут доступны во II половине текущего года.
17.03.2026 [02:00], Владимир Мироненко
ИИ-ускорители Groq прописались в платформе NVIDIA Vera RubinNVIDIA объявила о том, что платформа Vera Rubin, объединяющая теперь уже семь различных чипов (ещё в январе их было шесть), которые вместе откроют новые горизонты агентного ИИ, запущена в производство. Платформа включает Arm-процессоры Vera, ускорители Rubin, интерконнект NVLink 6, адаптеры ConnectX-9 SuperNIC и DPU BlueField-4, а также Ethernet-коммутаторы Spectrum/Quantum-6. Седьмым чипом стал LPU Groq 3 — NVIDIA купила Groq за рекордные $20 млрд всего три месяца назад и активно наращивает производство LPU. Благодаря такому сочетанию компонентов платформа обеспечивает обработку ИИ-нагрузок на всех этапах — от масштабного предварительного обучения, постобучения и масштабирования во время тестирования до инференса агентных задач в реальном времени, говорит NVIDIA. «Vera Rubin — это скачок в развитии — семь прорывных чипов, пять стоек, один гигантский суперкомпьютер — созданный для обеспечения всех этапов работы ИИ», — сообщил Дженсен Хуанг (Jensen Huang), основатель и генеральный директор NVIDIA. Он отметил, что с появлением Vera Rubin в развитии агентного ИИ наступил переломный момент, положившей начало «крупнейшему в истории развёртыванию инфраструктуры». 
Источник изображений: NVIDIA «Платформа NVIDIA Vera Rubin предоставляет нам вычислительные ресурсы, сетевые возможности и системную архитектуру, позволяющие продолжать работу, одновременно повышая безопасность и надёжность, на которые полагаются наши клиенты», — подтвердил Дарио Амодеи (Dario Amodei), генеральный директор и соучредитель Anthropic. «Инфраструктура NVIDIA — это основа, которая позволяет нам расширять границы ИИ, — заявил Сэм Альтман (Sam Altman), генеральный директор OpenAI. — С NVIDIA Vera Rubin мы будем запускать более мощные модели и агентов в огромных масштабах и предоставлять более быстрые и надёжные системы сотням миллионов людей». Как отметила компания, Vera Rubin предлагает самую обширную комплексную ИИ-платформу — суперкомпьютер с множеством стоек, специально разработанных для ИИ, работающих как одна массивная, целостная система. NVIDIA Vera Rubin NVL72 обеспечивает высокую эффективность в обучение больших MoE-моделей с использованием вчетверо меньшего количества ускорителей по сравнению с платформой Blackwell и достижение до 10 раз большей пропускной способности инференса на ватт при в десять раз меньшей стоимости токена.  CPU-стойка Vera — это высокоплотная MGX-платформа с СЖО, объединяющая 256 процессоров Vera для обеспечения масштабируемой, энергоэффективной производительности с первоклассной однопоточной обработкой, что обеспечивает возможности для масштабируемого агентного ИИ. Стойки Vera имеют тесную синхронизацию сред во всей ИИ-фабрике. Вместе со стойками Rubin они обеспечивают основу крупномасштабных систем агентного ИИ и обучения с подкреплением — при этом Vera обеспечивает результаты в два раза эффективнее и наполовину быстрее, чем традиционные CPU (впрочем, в NVL8 по-прежнему будут Intel Xeon). Стойки Groq 3 LPX (тоже с СЖО и тоже на базе MGX) и Vera Rubin, разработанные для обеспечения низкой задержки и обработки больших контекстов, необходимых для агентных систем, обеспечивают до 35 раз более высокую пропускную способность инференса на мегаватт и до 10 раз больший потенциал дохода для моделей с триллионами параметров. В масштабе предприятия парк LPU функционирует как единый гигантский процессор для быстрого и детерминированного ускорения инференса.  Стойка LPX с 256 LPU-чипами имеет 128 Гбайт SRAM с агрегированной пропускной способностью 640 Тбайт/с. В сочетании с Vera Rubin NVL72 чипы LPU повышают эффективность декодирования, совместно вычисляя каждый слой модели ИИ для каждого выходного токена. Всё это позволяет работать с моделями с триллионами параметров и контектсным окном в миллионы токенов, сохраняя максимальную эффективность по энергопотреблению, памяти и вычислительным ресурсам. Любопытно, что Rubin CPX в этот раз NVIDIA решила особо не упоминать. Анонсированная вместе с Vera Rubin СХД BlueField-4 STX разработана специально для ИИ-нагрузок, обеспечивая бесперебойное расширение памяти GPU по всему POD-кластеру. Впрочем, теперь компания говорит, что BlueField-4 включает CPU Vera, а не Grace, и ConnectX-9 SuperNIC. STX обеспечивает высокоскоростной общий слой данных, оптимизированный для хранения и извлечения больших объёмов KV-кеша, генерируемых LLM и рабочими процессами агентного ИИ. А программная платформа DOCA Memos позволяет использовать выделенное KV-хранилище для увеличения пропускной способности инференса до пяти раз, также повышая энергоэффективность по сравнению с архитектурами хранения общего назначения.  Также NVIDIA совместно с более чем 200 партнёрами анонсировала платформу NVIDIA DSX для Vera Rubin, которая включает технологию DSX Max-Q, позволяющую динамически управлять питанием всей ИИ-фабрики целиком, позволяя увеличить на 30 % ИИ-инфраструктуру в ЦОД при том же энергопотреблении. ПО DSX Flex обеспечивает ИИ-фабрикам гибкость в работе с энергосетями, позволяя освоить до 100 ГВт неиспользуемой мощности сетей. Кроме того, NVIDIA выпустила эталонный проект Vera Rubin DSX AI Factory — схему для совместно разработанной ИИ-инфраструктуры, которая максимизирует количество токенов на ватт и общую пропускную способность, повышая отказоустойчивость системы и ускоряя развётывание. 
В Microsoft Azure появились первые Vera Rubin (Источник изображения: X/@satyanadella) Продукты на базе Vera Rubin будут доступны у партнёров NVIDIA, начиная со II половины этого года. В их число входят гиперскейлеры AWS, Google Cloud, Microsoft Azure и Oracle Cloud, а также партнёры NVIDIA Cloud — CoreWeave, Crusoe, Lambda, Nebius, Nscale и Together AI. Ожидается, что широкий спектр серверов на базе продуктов Vera Rubin будут поставлять глобальные производители систем Cisco, Dell Technologies, HPE, Lenovo и Supermicro, а также Aivres, ASUS, Foxconn, GIGABYTE, Inventec, Pegatron, Quanta Cloud Technology (QCT), Wistron и Wiwynn.
06.01.2026 [14:28], Владимир Мироненко
NVIDIA объявила о запуске платформы Vera Rubin NVL72NVIDIA объявила о запуске платформы следующего поколения Rubin, которая приходит на смену Blackwell Ultra. Компания отметила, что платформа Rubin объединяет сразу пять инноваций, включая новейшие поколения интерконнекта NVIDIA NVLink, Transformer Engine, Confidential Computing и RAS Engine, а также процессор NVIDIA Vera. Примечательно, что NVIDIA снова решила вернуться к именованию на основе количества суперчипов (NVL72), а не ускорителей (NVL144), как обещала в прошлом году. Созданная с использованием экстремального совместного проектирования на аппаратном и программном уровнях, NVIDIA Vera Rubin обеспечивает десятикратное снижение стоимости токенов для инференса и четырёхкратное сокращение количества ускорителей для обучения моделей MoE по сравнению с платформой NVIDIA Blackwell. Коммутационные системы NVIDIA Spectrum-X Ethernet Photonics обеспечивают пятикратное повышение энергоэффективности и времени безотказной работы. 
Источник изображений: NVIDIA Платформа Rubin построена на шести чипах — Arm-процессоре Vera, ускорителе Rubin, коммутаторе NVLink 6, адаптере ConnectX-9 SuperNIC, DPU BlueField-4 и Ethernet-коммутаторе NVIDIA Spectrum-6. Ускорители Rubin поначалу будут доступны в двух форматах. В первом случае — в составе стоечной платформы DGX Vera Rubin NVL72, которая объединяет 72 ускорителя Rubin и 36 процессоров Vera, NVLink 6, ConnectX-9 SuperNIC и BlueField-4. Также ускорители Rubin будут доступны в составе платформы DGX/HGX Rubin NVL8 на базе x86-процессоров. Обе платформы будут поддерживаться кластерами NVIDIA DGX SuperPod, сообщил ресурс CRN.  Как отметила NVIDIA, разработанный для агентного мышления, процессор NVIDIA Vera является самым энергоэффективным процессором для крупномасштабных ИИ-фабрик. Он оснащён 88 кастомными Armv9.2-ядрами Olympus с 176 потоками с новой технологией пространственной многопоточности NVIDIA, 1,5 Тбайт системной памяти SOCAMM LPDDR5x (1,2 Тбайт/с), возможностями конфиденциальных вычислений и быстрым интерконнектом NVLink-C2C (1,8 Тбайт/с в дуплексе). 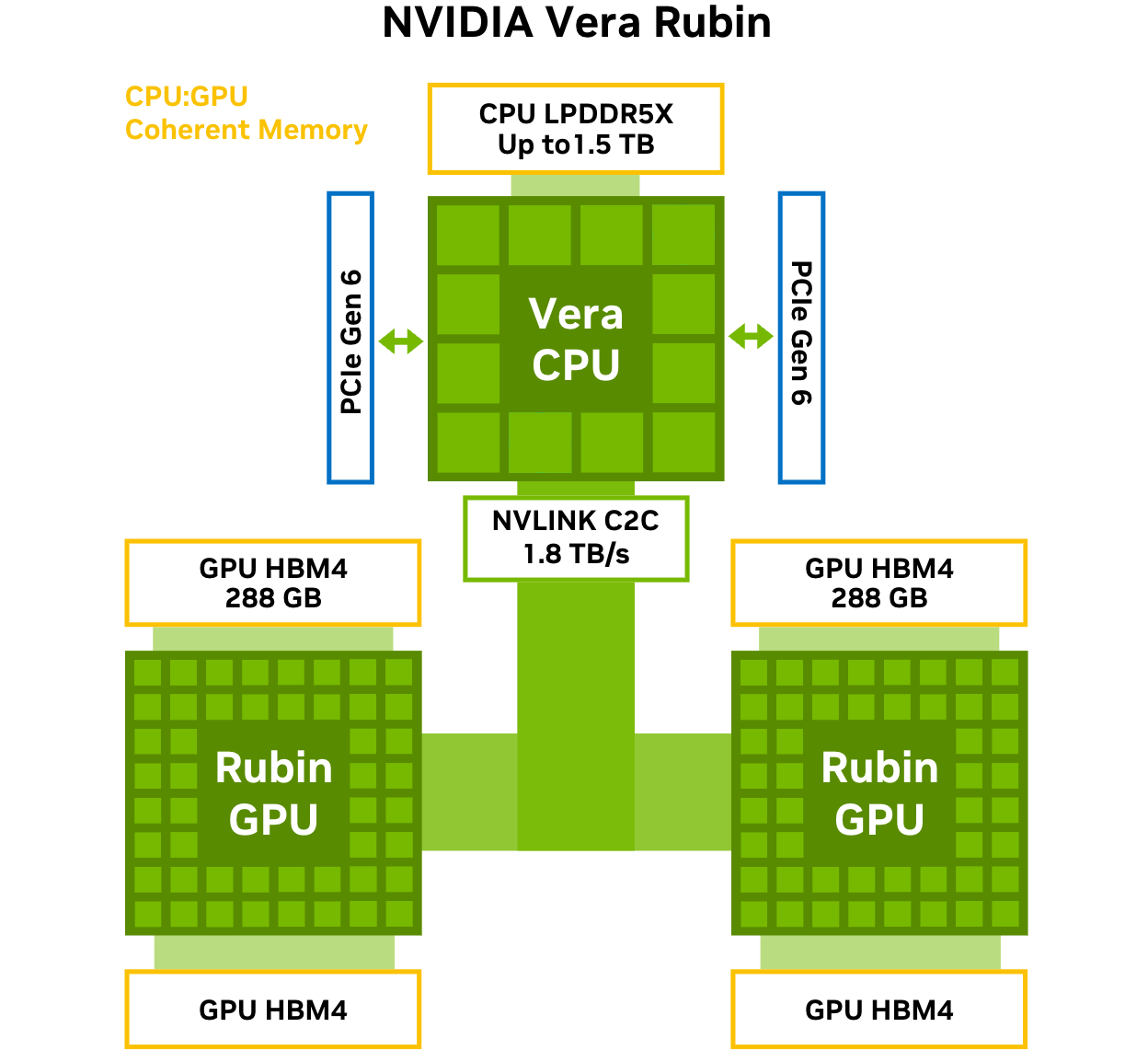 NVIDIA Rubin с аппаратным адаптивным сжатием данных обеспечивает до 50 Пфлопс (NVFP4) для инференса, что в пять раз быстрее, чем Blackwell. Он также обеспечивает до 35 Пфлопс (NVFP4) в режиме, что в 3,5 раза быстрее, чем его предшественник. Пропускная способность 288 Гбайт HBM4 составляет 22 Тбайт/с, что в 2,8 раза быстрее предшественника, а пропускная способность NVLink на один ускоритель вдвое выше — 3,6 Тбайт/с (в дуплексе).  NVIDIA также сообщила, что Vera Rubin NVL72 обладает 54 Тбайт памяти LPDDR5x, что в 2,5 раза больше, чем у Blackwell, и 20,7 Тбайт памяти HBM4, что на 50 % больше, чем у предшественника. Агрегированная пропускная способность HBM4 достигает 1,6 Пбайт/с, что в 2,8 раза больше, а скорость интерконнекта составляет 260 Тбайт/с, что вдвое больше, чем у платформы Blackwell NVL72, и «больше, чем пропускная способность всего интернета». Ожидаемый уровень энергопотребления составит от 190 до 230 кВт на стойку.  Компания отметила, что Vera Rubin NVL72 — первая стоечная платформа, обеспечивающая конфиденциальные вычисления, которая поддерживает безопасность данных на уровне доменов CPU, GPU и NVLink. Коммутатор NVLink 6 с жидкостным охлаждением оснащён 400G-блоками SerDes, обеспечивает пропускную способность 3,6 Тбайт/с на каждый GPU для связи между всеми GPU, общую пропускную способность 28,8 Тбайт/с и 14,4 Тфлопс внутрисетевых вычислений в формате FP8.  Хотя NVIDIA заявила, что Rubin находится в «полномасштабном производстве», аналогичные продукты от партнёров появятся только во II половине этого года. Среди ведущих мировых ИИ-лабораторий, поставщиков облачных услуг, производителей компьютеров и стартапов, которые, как ожидается, внедрят Rubin, компания назвала Amazon Web Services (AWS), Anthropic, Black Forest Labs, Cisco, Cohere, CoreWeave, Cursor, Dell Technologies, Google, Harvey, HPE, Lambda, Lenovo, Meta✴, Microsoft, Mistral AI, Nebius, Nscale, OpenAI, OpenEvidence, Oracle Cloud Infrastructure (OCI), Perplexity, Runway, Supermicro, Thinking Machines Lab и xAI.  ИИ-лаборатории, включая Anthropic, Black Forest, Cohere, Cursor, Harvey, Meta✴, Mistral AI, OpenAI, OpenEvidence, Perplexity, Runway, Thinking Machines Lab и xAI, рассматривают платформу NVIDIA Rubin для обучения более крупных и мощных моделей, а также для обслуживания мультимодальных систем с длинным контекстом с меньшей задержкой и стоимостью по сравнению предыдущими поколениями ускорителей. Партнёры по инфраструктурному ПО и хранению данных AIC, Canonical, Cloudian, DDN, Dell, HPE, Hitachi Vantara, IBM, NetApp, Nutanix, Pure Storage, Supermicro, SUSE, VAST Data и WEKA работают с NVIDIA над разработкой платформ следующего поколения для инфраструктуры Rubin.  В связи с тем, что рабочие нагрузки агентного ИИ генерируют огромные объёмы контекстных данных, NVIDIA также представляла новую платформу хранения контекста инференса NVIDIA Inference Context Memory Storage Platform — новый класс инфраструктуры хранения, разработанной для масштабирования контекста инференса.  Сообщается, что платформа, работающая на базе BlueField-4, обеспечивает эффективное совместное использование и повторное применение данных KV-кеша в рамках всей ИИ-инфраструктуры, повышая скорость отклика и пропускную способность, а также обеспечивая предсказуемое и энергоэффективное масштабирование агентного ИИ. Дион Харрис (Dion Harris), старший директор NVIDIA по высокопроизводительным вычислениям и решениям для ИИ-инфраструктуры, сообщил, что по сравнению с традиционными сетевыми хранилищами для данных контекста инференса, новая платформа обеспечивает до пяти раз больше токенов в секунду, в пять раз лучшую производительность на доллар и в пять раз лучшую энергоэффективность. |
|

