NVIDIA представила NVIDIA Vera Rubin POD — кластер из пяти специализированных стоечных систем, построенных на архитектуре NVIDIA MGX третьего поколения для эры агентного ИИ.
Компания отметила, что созданная в рамках совместного проектирования семи чипов, охватывающих вычислительные ресурсы, сети и хранилище данных, NVIDIA Vera Rubin представляет собой самую сложную ИИ-платформу. Готовый кластер Vera Rubin POD включает 40 стоек, 1,2 квадрлн транзисторов, почти 20 тыс. кристаллов NVIDIA, 1152 GPU NVIDIA Rubin. Он обеспечивает ИИ-производительность на уровне 60 Эфлопс и агрегированную скорость интерконнекта для вертикального масштабирования около 10 Пбайт/с. Входящие в состав NVIDIA Vera Rubin POD пять различных стоечных платформы образуют единую, высокоинтегрированную систему.

Источник изображений: NVIDIA
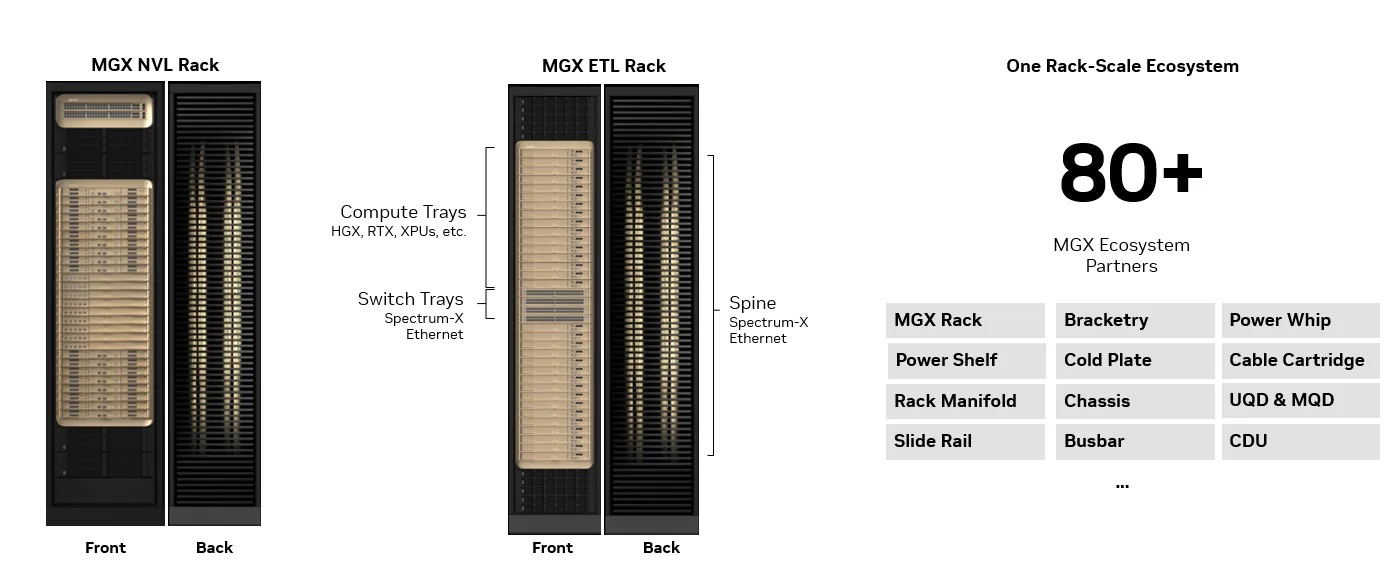
Кластер POD базируется на 19″ стойках стандарта NVIDIA MGX (OCP) третьего поколения, поддерживаемых экосистемой из более чем 80 партнёров с глобальной цепочкой поставок. При этом каждая стойка NVIDIA MGX с точки зрения ЦОД имеет одинаковые параметры питания, охлаждения и механические характеристики, что упрощает развёртывание.

Существует два типа стоек MGX с медными интерконнектами. MGX NVL использует NVIDIA NVLink, в частности, Vera Rubin NVL72 объединяет 72 ускорителя Rubin и 36 процессоров Vera, а восемь суперускорителей NVL72 объединяются в единый домен NVL576 посредством двухуровневой сети NVLink 6 (3,6 Тбайт/с на чип) с дальнейшим горизонтальным масштабированием с помощью Ethernet/InfiniBand (в том числе на уровне нескольких ЦОД). Новая стойка MGX ETL совместима со сторонними чипами, а в качестве интерконнекта использует Ethernet на базе Spectrum-X, либо, как в случае Groq 3 LPU, проприетарный интерконнект RealScale, но для горизонтального масштабирования опять-таки применяется Ethernet.
Стойка Vera Rubin NVL72
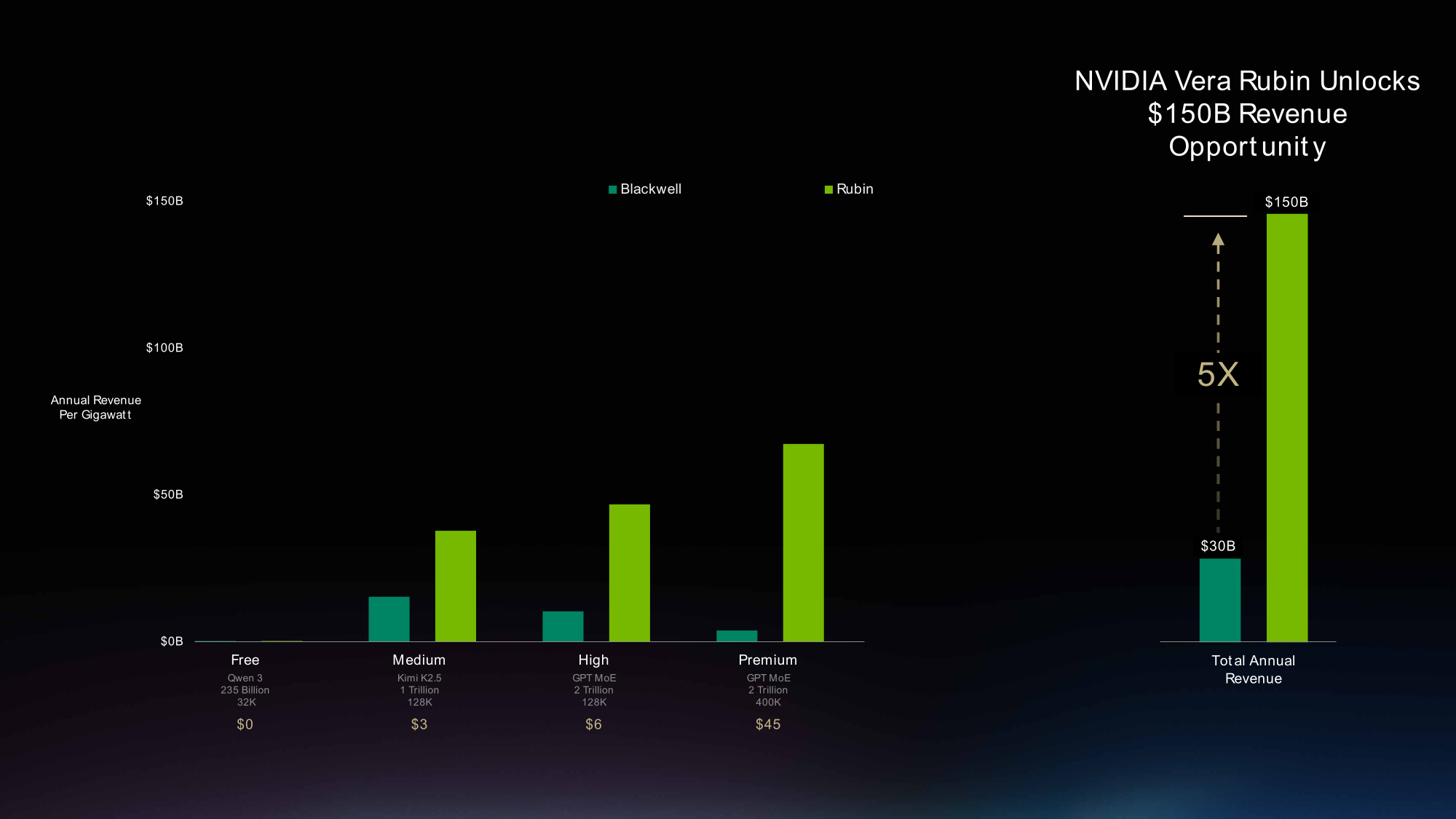
Vera Rubin NVL72, по словам NVIDIA, разработана для масштабирования четырёх ключевых ИИ-нагрузок: предварительного обучения, постобучения, ресурсоёмкого инференса (TTS) и работы агентов масштабирования. Суперускоритель может быть оптимизирован для сложных многомодальных задач с использованием MoE и ресурсоёмкой фазы работы с контекстом в процессе ИИ-инференса. Новая платформа обеспечивает до 4 раз лучшую производительность обучения и до 10 раз лучшую производительность инференса на Ватт, а также в десять раз меньшую стоимость токена по сравнению с NVIDIA Blackwell.

NVIDIA Vera Rubin NVL72 содержит почти в два раза больше транзисторов, чем GB200 NVL72. Стойка включает 18 вычислительных узлов, которые помимо 72 ускорителей NVIDIA и 36 процессоров Vera, включают восемь адаптеров ConnectX-9 SuperNIC и один DPU BlueField-4. Также стойка включает девять узлов-коммутаторов NVLink 6 — по 3,6 Тбайт/с (1,8 Тбайт/с в каждую сторону) на каждый ускоритель с агрегированной пропускной способностью почти 260 Тбайт/c. Как и прежде, в задней части находится основная магистраль NVLink в виде картриджей, имеющих по 5 тыс. медных соединений общей длиной более 3 км.
В общей сложности стойка вмещает 1,3 млн компонентов, почти 1300 микросхем и весит около 1800 кг (не каждый ЦОД выдержит такую нагрузку). Высокоинтегрированная стойка не требует возни с кабелями и шлангами, что до 20 раз ускоряет развёртывание и обслуживание кластера — на подготовку одного узла теперь уходит пять минут вместо двух часов. А сами узлы теперь гораздо ближе к блейд-серверам.
Vera Rubin NVL72 получил новые функции отказоустойчивости (RAS) в масштабе стойки. Например, коммутаторы NVLink можно переводить в режим обслуживания и заменять их, пока стойка продолжает работать. Архитектура обеспечивает непрерывную работу даже при недоступности нескольких коммутационных блоков. Rubin постоянно выполняют не прерывающие работу проверки состояния, а процессоры Vera оснащены встроенным тестированием. Переход к SOCAMM-модулям тоже не случаен — это позволяет быстро менять вышедшую из строя память.
Стойка Groq LPX
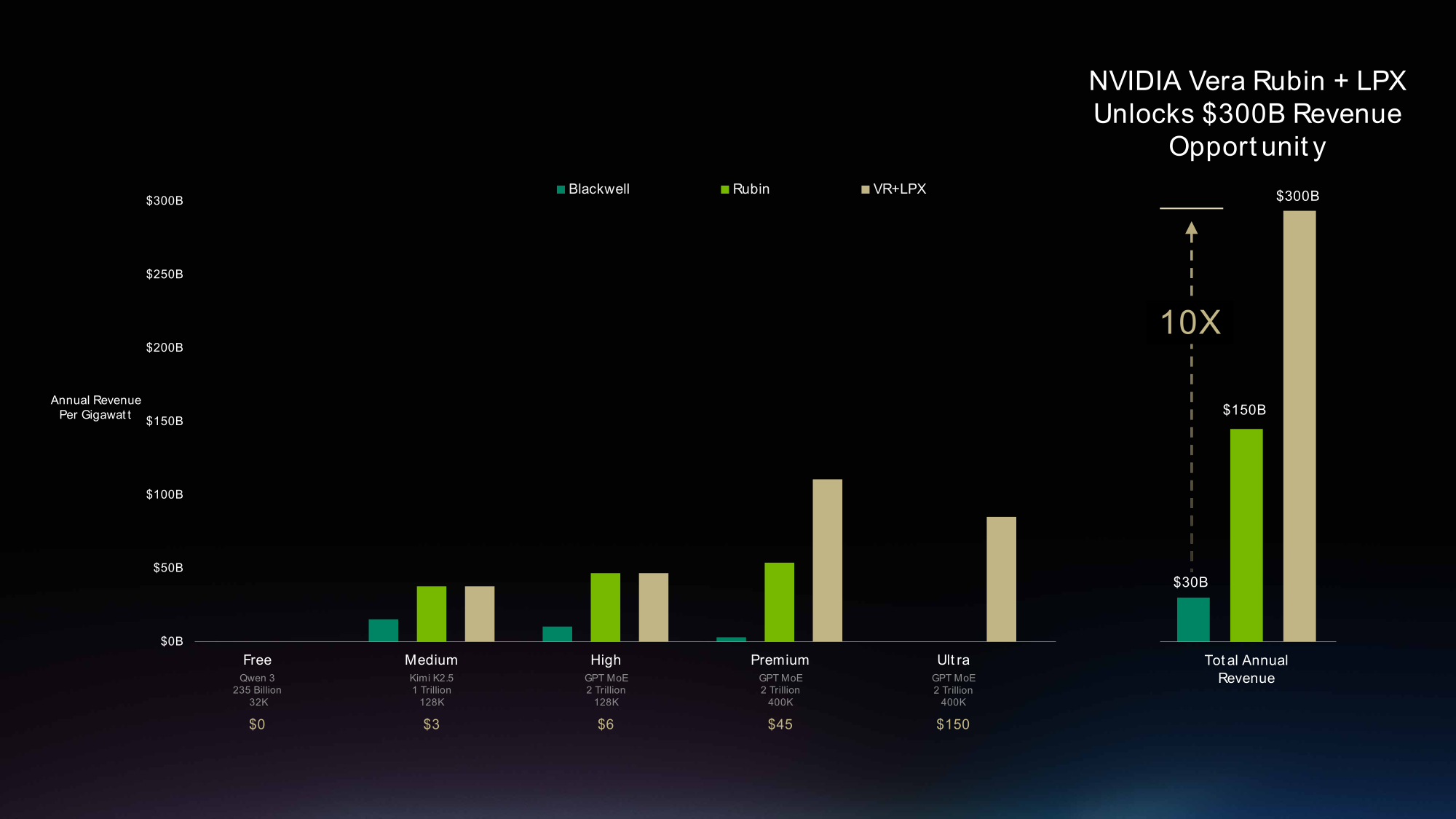
Стойка NVIDIA Groq 3 LPX с 256 ускорителями LPU работает в паре с Vera Rubin NVL72. Благодаря объединению высокоскоростных LPU, работающих только со SRAM, с ускорителями Rubin с ёмкой HBM система обеспечивает низкую задержку и высокую пропускную способность при большой длине контекста. Vera Rubin NVL72 плюс LPX обеспечивают до 35 раз больше токенов и до 10 раз больший потенциал дохода для моделей с триллионом параметров по сравнению с Blackwell. Стойка LPX в целом устроена так же, как NVL72. Для интерконнекта RealScale внутри стойки тоже используется медная магистраль в задней части (механически картриджи такие же, как у NVLink). При масштабировании до нескольких стоек LPX в ЦОД прямые межчиповые соединения сохраняются между стойками, что позволяет нескольким LPX формировать один домен.

Стойка Vera
Стойка Vera объединяет до 256 процессоров и способна одновременно обслуживать более 22,5 тыс. RL-сред или песочниц для агентов, максимизируя возможности тестирования, выполнения и проверки результатов со стоек Vera Rubin NVL72 и LPX. Стойки NVIDIA Vera CPU выступают в качестве основы для крупномасштабного агентного ИИ.

Стойка STX
Стойка BlueField-4 STX — это специализированное хранилище, разработанное для ИИ, на базе DPU BlueField-4 и Spectrum-X Ethernet. Стойка включает платформу хранения контекстной памяти NVIDIA CMX. Это новый класс инфраструктуры хранения для бесшовного расширения памяти ускорителей путём выгрузки KV-кеша в выделенный высокоскоростной уровень хранения. CMX оптимизирована для хранения и обслуживания больших объёмов контекстной памяти и рассматривает временный контекст инференса как нативный для ИИ тип данных, который может быть повторно использоваться разными сессиями и агентами. Это обеспечивает до пяти раз более высокую скорость генерации токенов и до пяти раз более высокую энергоэффективность по сравнению с традиционными методами хранения.

Стойки SPX
Сетевые стойки Spectrum-6 SPX, объединяющие компоненты POD в единый суперкомпьютер, разработаны для ускорения трафика east-west и north-south (внутри ЦОД и между ЦОД). Используются коммутаторы Spectrum-X Ethernet или Quantum-X800 InfiniBand. Коммутатор Spectrum-6 (102,4 Тбит/с) предлагает 512 200G-портов, а интегрированная кремниевой фотоника (CPO) позволяет отказаться от подключаемых трансиверов, обеспечивая высочайшую энергоэффективность и отказоустойчивость, низкую задержку и джиттер.

Стойки MGX третьего поколения
В основе всех этих стоек лежит открытая, стандартизированная архитектура MGX. Первая серийная система стоечного масштаба (Oberon) была выпущена совместно с NVIDIA Blackwell в 2024 году, впоследствии спецификации были переданы Open Compute Project (OCP). NVIDIA создала экосистему из более чем 80 глобальных партнёров, сформировав высокоэффективную, глобально диверсифицированную цепочку поставок, имеющую опыт вывода на рынок стоечных систем ИИ. В 2025 году началась поставка NVIDIA GB300 NVL72, а NVIDIA Vera Rubin NVL72 выйдет во II половине 2026 года.
Для бесшовного масштабирования домена за пределы NVL576 понадобится Kyber — стойка MGX NVL следующего поколения, рассчитанная на 144 ускорителя. Kyber позволит масштабироваться до массивного суперкомпьютера NVL1152 с All-to-All связями на базе оптического интерконнекта. Kyber заложит основу для следующей эры экстремального масштабирования ИИ-вычислений с использованием NVIDIA Feynman, но впервые Kyber будет представлена в составе Vera Rubin Ultra NVL144, а также NVL72 и NVL576.

NVIDIA Kyber NVL1152
Интерконнект
Стойка MGX 3 имеет высокомодульную объединительную плату — до четырёх предварительно интегрированных и проверенных картриджей с медными кабелями, которые соединяют узлы в единое целое. Стойка имеет одинаковый механический форм-фактор как для версии MGX NVL, так и для MGX ETL. Это же касается питания и охлаждения.

Все стойки MGX используют функцию динамического управления питанием, которое подаётся на компоненты, больше всего в нём нуждающиеся. Питание перераспределяется между CPU, GPU, коммутаторами NVLink таким образом, чтобы обеспечить работу компонентов в стойке с максимальной энергоэффективностью, повышая производительность на Ватт.
Электропитание
По оценкам самой NVIDIA, статическое распределение мощности (Max-P) приводит к недоиспользованию энергии. В реальности ИИ-кластеры работают не с однородными нагрузками на пике мощности, а со смешанными и с различными потребностями в электроэнергии. Динамическое распределение мощности и возможность работы не в полную силу (Max-Q) позволяет максимизировать пропускную способность ИИ-нагрузок на уровне ЦОД. В этом случае каждой стойке в зависимости от текущей нагрузки динамически выделятся необходимое количество энергии. На практике, по расчётам NVIDIA, можно развернуть до 30 % больше ускорителей при том же уровне энергопотребления ЦОД.
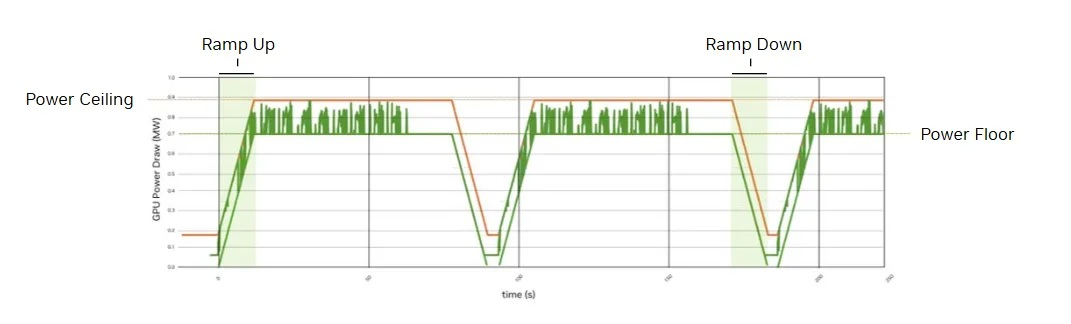
Ещё один важный аспект электропитания — сглаживание нагрузок на энергосистемы ЦОД и энергосеть в целом. Обучение и инференс приводят к значительным перепадам нагрузки. Поэтому NVIDIA на уровне стоек устанавливает накопители энергии на основе конденсаторов. Когда рабочие нагрузки требуют одновременно большого количества энергии, конденсатор обеспечивает дополнительную мощность, в то время как потребление электроэнергии в сети остается неизменным или увеличивается. Когда уровень рабочих нагрузок падает, конденсатор заряжается, а нагрузка на сети остаётся неизменной или снижается.
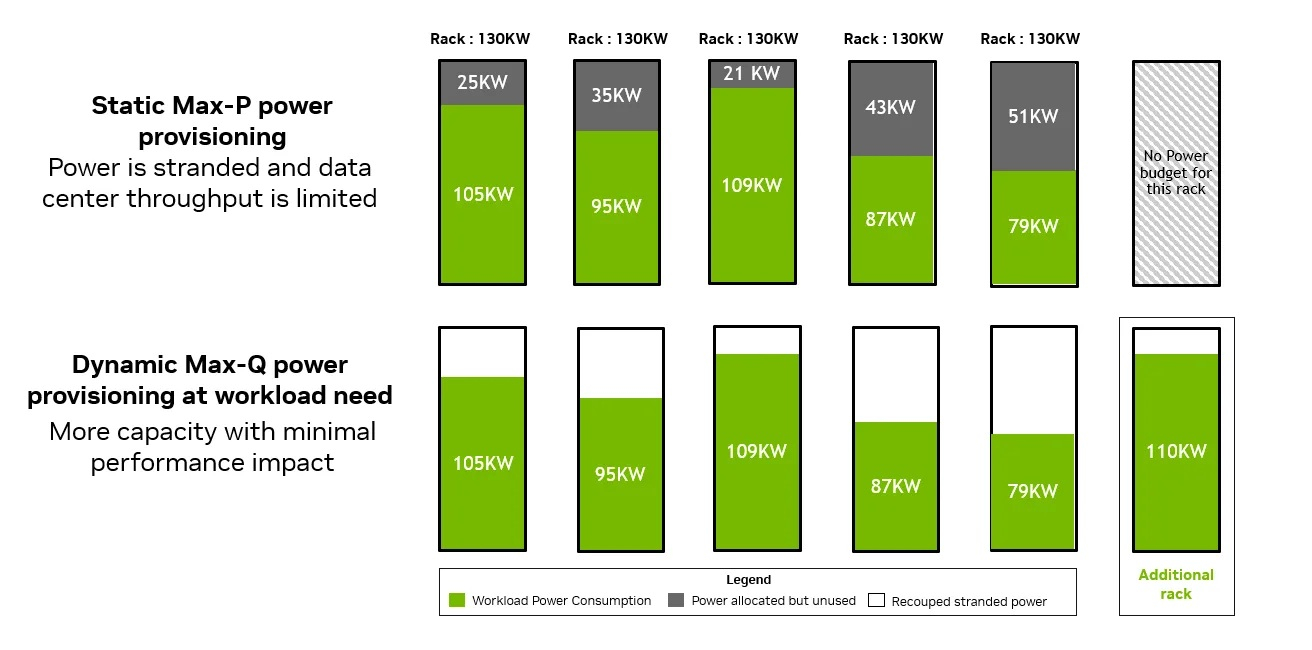
NVIDIA впервые начала применять такую систему в GB300 NVL72. В Vera Rubin NVL72 используется интеллектуальная система сглаживания энергопотребления (Intelligent Power Smoothing), которая имеет в шесть раз больший объём накопителей энергии на уровне стойки (400 Дж на GPU) по сравнению с предыдущими поколениями и представляет собой новую замкнутую систему, которая позволяет GPU непрерывно контролировать состояние заряда конденсаторов для более эффективного профилирования энергопотребления. Это позволяет обеспечить значительно меньших колебаний, снизить пиковые токовые нагрузки до 25 % и исключить необходимость в использовании массивных батарей для защиты от масштабных скачков напряжения.
Охлаждение
Все стойки MGX спроектированы для охлаждения горячей водой с температурой +45 °C на входе, поэтому дата-центрам, спроектированным с учётом использования СЖО, гарантируется плавный переход без перепроектирования инфраструктуры охлаждения. Это позволит ЦОД во многих климатических зонах использовать для охлаждения окружающий воздух и драйкулеры. Фрикулинг не только помогает уменьшить показатель PUE, но и высвободить средства для вычислительных ресурсов. Экономии электроэнергии в ЦОД достаточно для установки до 10 % дополнительных стоек Vera Rubin NVL72 в рамках того же энергетического бюджета, говорит компания.
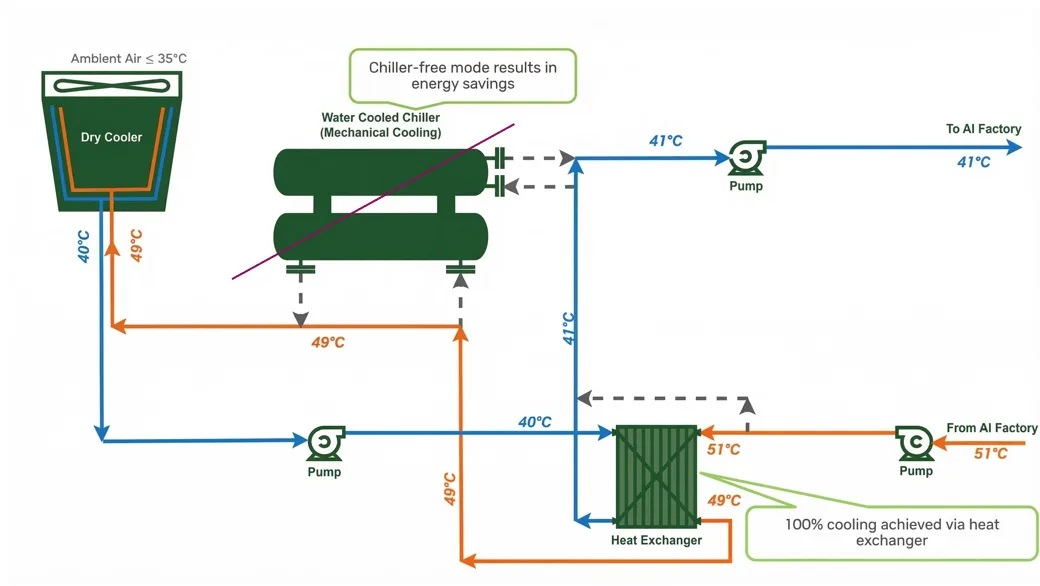
Для жидкостного охлаждения стоек MGX можно использовать ту же инфраструктуру охлаждения ЦОД, что и предыдущие поколения. Стойка MGX третьего поколения оснащена новыми внутренними коллекторами для лотков, коллекторами UQD08 и шинами с жидкостным охлаждением, поддерживающими ток до 5000 А. Используемая охлаждающая жидкость будет зависеть от заказчика и ЦОД, но многие продолжат использовать деионизированную воду или жидкость на основе пропиленгликоля (PG25), которая может служить до 10 лет в замкнутой системе с минимальным обслуживанием жидкостного контура.
Стойки MGX ETL
Хотя стойки MGX NVL обеспечивают масштабируемые вычислительные домены, рабочие процессы агентного ИИ требуют высокоспециализированных узлов для инференса с экстремально низкой задержкой, изоляции CPU и ускоренной контекстной памяти для KV-кеша. Для этого и нужны стойки MGX ETL с Ethernet Spectrum-X (по умолчанию) или другим C2C-интерконннектом (как у LPX). Причём физически внутристоечная магистраль тоже будет реализована в виде предварительно интегрированных и проверенных медных кабельных картриджей, как и в MGX NVL.

Стойки MGX ETL имеют тот же форм-фактор и физические особенности, что и стойки MGX NVL, и разработаны для работы в тех же механических условиях, параметрах питания и охлаждения. Обе стойки будут использовать одни и те же ключевые компоненты: стойки, шасси, лотки, кабельные картриджи, коллекторы жидкостного охлаждения, быстроразъёмные соединения, шины питания (стандартные и с жидкостным охлаждением), опорные кронштейны, боковые направляющие, силовые полки, лотки для защиты от протечек, ручки и многое другое.

MGX ETL со Spectrum-X станет основой для стоек Vera и BlueField-4 STX в составе Vera Rubin POD. Эти же стойки будут использоваться для систем HGX Rubin NVL8 или других XPU — до 256 чипов на стойку или даже больше. В этой конструкции коммутационные узлы (на основе Spectrum-6) располагаются посередине стойки. Порты на задней панели подключаются к медной магистрали, а 32 OSFP-корзины на передней панели обеспечивают оптическое подключение к остальной части POD. В MGX ETL используется топология, которая распределяет 200GbE-соединения между несколькими коммутаторами, обеспечивая полное соединение All-to-All («все со всеми») между узлами внутри стойки при сохранении одного сетевого уровня.
NVIDIA DSX
Для эксплуатации ИИ-фабрик на базе Vera Rubin компания предлагает платформу DSX. DSX предлагает эталонную архитектуру ИИ-фабрик, охватывающую всю платформу снизу доверху, от отдельных чипов до сети. Платформа позволяет максимизировать энергоэффективность, отказоустойчивость, масштабируемость и производительность кластеров, ускорить их развёртывание и удешевить их обслуживание.

DSX объединяет чипы, системы, программные библиотеки, API и глобальную партнёрскую экосистему в единую архитектуру, которая тесно интегрирует вычислительные ресурсы, сети, хранилище, электропитание, охлаждение и управление объектами всей ИИ-фабрики. Это позволяет партнёрам по экосистеме быстро проектировать, развёртывать и масштабировать гигаваттные ИИ ЦОД. Эталонный проект NVIDIA Vera Rubin DSX и модель NVIDIA Omniverse DSX для цифровых двойников ИИ-фабрик предоставляют единую основу для создания и эксплуатации ИИ ЦОД, обеспечивая значительное повышение производительности, экономической эффективности и экономию энергии, говорит NVIDIA.
Заключение
В Vera Rubin POD компания перешла к новому уровню интеграции компонентов. С одной стороны, это упрощает развёртывание и эксплуатацию платформы. С другой стороны, это негативно сказывается на кастомизации, что вряд ли понравится гиперскейлерам, т.е. основным заказчикам NVIDIA, и надёжности — даже несмотря на принятые NVIDIA меры выход одного компонента не всегда позволит заменить только его, а не весь модуль или узел целиком, что критично в рамках кластера.

Однако и NVIDIA можно понять. Для дальнейшего повышения эффективности требуется всё более вертикально интегрированные и масштабируемые платформы, разработанные с учётом одновременного взаимодействия всё большего числа компонентов. При этом повышение плотности и энергоёмкости стоек предъявляет всё более жёсткие требования к их конструкции, надёжности и безопасности, т.ч. свобода кастомизации может выйти боком.

И отказаться от такой архитектуры, по-видимому, не получится. Дженсен Хуанг отметил, что наступил переломный момент в сфере инференса — спрос на генерацию токенов резко растёт, и индустрия спешит строить ИИ-фабрики. Как показывают тесты SemiAnalysis InferenceMax, стоечные системы NVIDIA обеспечивают в 50 раз лучшую производительность на Ватт и в 35 раз меньше расходы на токен (GB300 NVL72 против H200), что напрямую приводит к увеличению доходов и прибыли компаний.
Источник:

