Материалы по тегу: groq
|
23.06.2026 [12:00], Руслан Авдеев
Groq привлекла $650 млн на развитие своей облачной инференс-платформыСтартап Groq, занимающийся разработкой чипов для инференса и купленный NVIDIA за $20 млрд, объявил о привлечении $650 млн на развитие собственного облака, сообщает Silicon Angle. Возглавили раунд инвестиционная группа Disruptive и хеджевый фонд Infinitum. В декабре 2025 года NVIDIA согласилась заключить исключительное лицензионное соглашение на технологии и наняла нескольких сотрудников Groq, в том числе её основателя и генерального директора. При этом формально «зелёным» облако GroqCloud в рамках сделки не досталось. Компания раскрыла, что её облачная платформа обрабатывает триллионы токенов в неделю для 5 млн разработчиков. 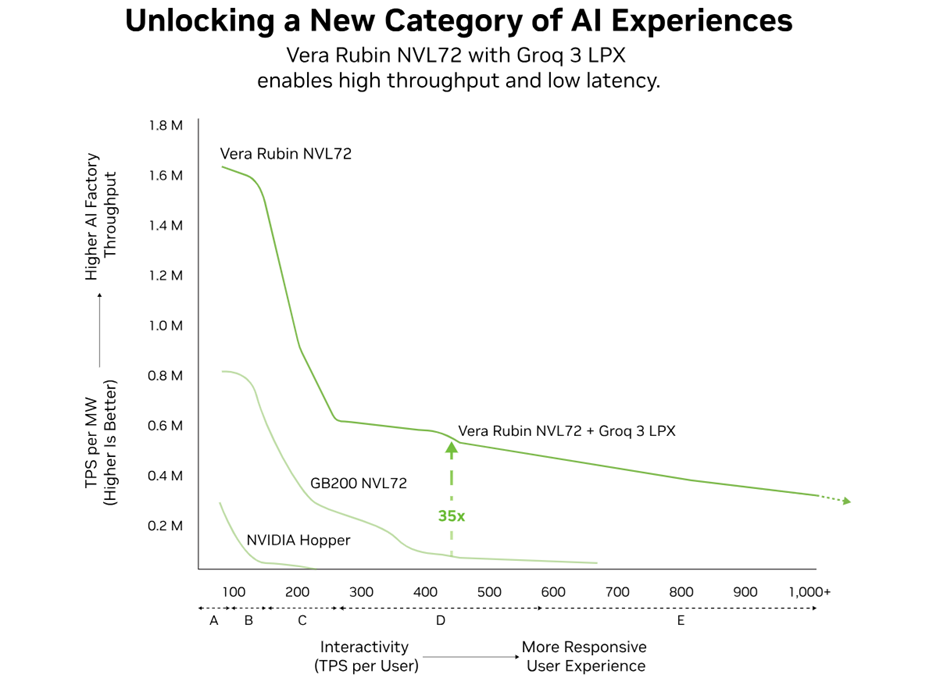
Источник изображения: NVIDIA Облачная инфраструктура Groq работает на базе 13 ЦОД на нескольких континентах. Компания рассчитывает потратить привлечённые средства для расширения мощностей до 200 МВт к 2027 году. В Groq утверждают, что часть новых вычислительных мощностей получит системы NVIDIA LPX на основе LPU 3. Прочие облачные операторы в теории тоже способны создать сервис для инференса на основе решений NVIDIA/Groq.
23.03.2026 [12:55], Владимир Мироненко
Сначала Kyber, потом Feynman: NVIDIA раскрыла планы по выпуску ИИ-решений до 2028 годаВслед за анонсом ИИ-ускорителя LPU Groq 3 в составе платформы Vera Rubin компания NVIDIA представила обновлённую дорожную карту решений для ЦОД на период до 2028 года, включив в нее три поколения оборудования, пишет Data Center Dynamics. В рамках перехода на ежегодный цикл выпуска новых архитектур — Hopper, Blackwell (Ultra), Vera Rubin, компания после приобретения Groq за рекордные $20 млрд теперь планирует также ежегодно представлять новую архитектуру LPU. Выпуск LPU NVIDIA Groq 3 запланирован на II половину 2026 года. Также во II половине этого года выйдет платформа NVIDIA Vera Rubin, включающая, помимо NVIDIA Groq 3, Arm-процессоры Vera, ускорители Rubin, интерконнект NVLink 6, адаптеры ConnectX-9 SuperNIC и DPU BlueField-4, а также коммутаторы Spectrum/Quantum-6. На II половину 2027 года намечен выход ускорителя Rubin Ultra с четырьмя вычислительными чиплетами и 1 Тбайт HBM4E. Также во II половине следующего года выйдет второй LPU от NVIDIA — Groq LP35. Кроме того, в 2027 году компания планирует выпустить своё стоечное решение Kyber NVL144/NVL72. Система включает 144 ускорителя Rubin Ultra с NVLink 7, обеспечивая четырёхкратное повышение производительности по сравнению с системой Blackwell NVL72 (Oberon). 
Источник изображения: NVIDIA После анонса Rubin Ultra генеральный директор NVIDIA Дженсен Хуанг (Jensen Huang) заявил в 2025 году, что переход на эту платформу потребует «годы планирования». «Это не то же самое, что покупка ноутбука, — сказал он. — Нам нужно планировать с учётом территории и электроснабжения ЦОД вместе с инженерными командами на два-три года вперёд, поэтому я [показываю] дорожную карту». Планы NVIDIA на 2028 год включают масштабный запуск новых процессоров, ускорителей и LPU, получивших названия Rosa, Feynman и LP40 соответственно. По словам разработчика, в Feynman будет использоваться многослойная архитектура кристалла и высокоскоростная память для масштабирования производительности и увеличения пропускной способности. Также Feynman станет первым решением NVIDIA, в котором используются коммутаторы NVLink с интегрированной оптикой. Хуанг заявил, что спрос на продукцию NVIDIA к 2027 году достигнет отметки в $1 трлн, фактически удвоив свой прошлый прогноз. Финансовый директор Колетт Кресс (Colette Kress) уточнила позже, что эта цифра относится только к продуктам Blackwell и Rubin, а также к сопутствующему сетевому оборудованию, и не включает новые продукты, такие как LPU Groq и используемые отдельно процессоры. «Триллион долларов — это огромная сумма для инфраструктуры, — отметил Хуанг. — Вы должны быть полностью уверены, что триллион долларов, которые вы вкладываете, будут использованы, обеспечат высокую производительность, невероятную экономическую эффективность и будут иметь полезный срок службы на протяжении всего периода инвестиций в инфраструктуру. [NVIDIA] — единственная в мире инфраструктура, которую вы можете построить в любой точке мира с полной уверенностью».
17.03.2026 [02:00], Владимир Мироненко
ИИ-ускорители Groq прописались в платформе NVIDIA Vera RubinNVIDIA объявила о том, что платформа Vera Rubin, объединяющая теперь уже семь различных чипов (ещё в январе их было шесть), которые вместе откроют новые горизонты агентного ИИ, запущена в производство. Платформа включает Arm-процессоры Vera, ускорители Rubin, интерконнект NVLink 6, адаптеры ConnectX-9 SuperNIC и DPU BlueField-4, а также Ethernet-коммутаторы Spectrum/Quantum-6. Седьмым чипом стал LPU Groq 3 — NVIDIA купила Groq за рекордные $20 млрд всего три месяца назад и активно наращивает производство LPU. Благодаря такому сочетанию компонентов платформа обеспечивает обработку ИИ-нагрузок на всех этапах — от масштабного предварительного обучения, постобучения и масштабирования во время тестирования до инференса агентных задач в реальном времени, говорит NVIDIA. «Vera Rubin — это скачок в развитии — семь прорывных чипов, пять стоек, один гигантский суперкомпьютер — созданный для обеспечения всех этапов работы ИИ», — сообщил Дженсен Хуанг (Jensen Huang), основатель и генеральный директор NVIDIA. Он отметил, что с появлением Vera Rubin в развитии агентного ИИ наступил переломный момент, положившей начало «крупнейшему в истории развёртыванию инфраструктуры». 
Источник изображений: NVIDIA «Платформа NVIDIA Vera Rubin предоставляет нам вычислительные ресурсы, сетевые возможности и системную архитектуру, позволяющие продолжать работу, одновременно повышая безопасность и надёжность, на которые полагаются наши клиенты», — подтвердил Дарио Амодеи (Dario Amodei), генеральный директор и соучредитель Anthropic. «Инфраструктура NVIDIA — это основа, которая позволяет нам расширять границы ИИ, — заявил Сэм Альтман (Sam Altman), генеральный директор OpenAI. — С NVIDIA Vera Rubin мы будем запускать более мощные модели и агентов в огромных масштабах и предоставлять более быстрые и надёжные системы сотням миллионов людей». Как отметила компания, Vera Rubin предлагает самую обширную комплексную ИИ-платформу — суперкомпьютер с множеством стоек, специально разработанных для ИИ, работающих как одна массивная, целостная система. NVIDIA Vera Rubin NVL72 обеспечивает высокую эффективность в обучение больших MoE-моделей с использованием вчетверо меньшего количества ускорителей по сравнению с платформой Blackwell и достижение до 10 раз большей пропускной способности инференса на ватт при в десять раз меньшей стоимости токена.  CPU-стойка Vera — это высокоплотная MGX-платформа с СЖО, объединяющая 256 процессоров Vera для обеспечения масштабируемой, энергоэффективной производительности с первоклассной однопоточной обработкой, что обеспечивает возможности для масштабируемого агентного ИИ. Стойки Vera имеют тесную синхронизацию сред во всей ИИ-фабрике. Вместе со стойками Rubin они обеспечивают основу крупномасштабных систем агентного ИИ и обучения с подкреплением — при этом Vera обеспечивает результаты в два раза эффективнее и наполовину быстрее, чем традиционные CPU (впрочем, в NVL8 по-прежнему будут Intel Xeon). Стойки Groq 3 LPX (тоже с СЖО и тоже на базе MGX) и Vera Rubin, разработанные для обеспечения низкой задержки и обработки больших контекстов, необходимых для агентных систем, обеспечивают до 35 раз более высокую пропускную способность инференса на мегаватт и до 10 раз больший потенциал дохода для моделей с триллионами параметров. В масштабе предприятия парк LPU функционирует как единый гигантский процессор для быстрого и детерминированного ускорения инференса.  Стойка LPX с 256 LPU-чипами имеет 128 Гбайт SRAM с агрегированной пропускной способностью 640 Тбайт/с. В сочетании с Vera Rubin NVL72 чипы LPU повышают эффективность декодирования, совместно вычисляя каждый слой модели ИИ для каждого выходного токена. Всё это позволяет работать с моделями с триллионами параметров и контектсным окном в миллионы токенов, сохраняя максимальную эффективность по энергопотреблению, памяти и вычислительным ресурсам. Любопытно, что Rubin CPX в этот раз NVIDIA решила особо не упоминать. Анонсированная вместе с Vera Rubin СХД BlueField-4 STX разработана специально для ИИ-нагрузок, обеспечивая бесперебойное расширение памяти GPU по всему POD-кластеру. Впрочем, теперь компания говорит, что BlueField-4 включает CPU Vera, а не Grace, и ConnectX-9 SuperNIC. STX обеспечивает высокоскоростной общий слой данных, оптимизированный для хранения и извлечения больших объёмов KV-кеша, генерируемых LLM и рабочими процессами агентного ИИ. А программная платформа DOCA Memos позволяет использовать выделенное KV-хранилище для увеличения пропускной способности инференса до пяти раз, также повышая энергоэффективность по сравнению с архитектурами хранения общего назначения.  Также NVIDIA совместно с более чем 200 партнёрами анонсировала платформу NVIDIA DSX для Vera Rubin, которая включает технологию DSX Max-Q, позволяющую динамически управлять питанием всей ИИ-фабрики целиком, позволяя увеличить на 30 % ИИ-инфраструктуру в ЦОД при том же энергопотреблении. ПО DSX Flex обеспечивает ИИ-фабрикам гибкость в работе с энергосетями, позволяя освоить до 100 ГВт неиспользуемой мощности сетей. Кроме того, NVIDIA выпустила эталонный проект Vera Rubin DSX AI Factory — схему для совместно разработанной ИИ-инфраструктуры, которая максимизирует количество токенов на ватт и общую пропускную способность, повышая отказоустойчивость системы и ускоряя развётывание. 
В Microsoft Azure появились первые Vera Rubin (Источник изображения: X/@satyanadella) Продукты на базе Vera Rubin будут доступны у партнёров NVIDIA, начиная со II половины этого года. В их число входят гиперскейлеры AWS, Google Cloud, Microsoft Azure и Oracle Cloud, а также партнёры NVIDIA Cloud — CoreWeave, Crusoe, Lambda, Nebius, Nscale и Together AI. Ожидается, что широкий спектр серверов на базе продуктов Vera Rubin будут поставлять глобальные производители систем Cisco, Dell Technologies, HPE, Lenovo и Supermicro, а также Aivres, ASUS, Foxconn, GIGABYTE, Inventec, Pegatron, Quanta Cloud Technology (QCT), Wistron и Wiwynn.
10.03.2026 [17:49], Владимир Мироненко
Groq увеличил заказ на производство ИИ-чипов у Samsung более чем в 1,5 разаИИ-стартап Groq, приобретённый NVIDIA за $20 млрд, направил Samsung Electronics запрос на увеличение производства своих чипов, сообщил Chosunbiz со ссылкой на информированные источники. Источники утверждают, что Groq недавно принял решение увеличить производство ИИ-чипов, которое в прошлом году было передано на аутсорсинг подразделению Samsung Electronics, с примерно 9 тыс. пластин до примерно 15 тыс. Если в прошлом году объём производства был ограничен изготовлением опытных образцов чипов для определения их эффективности при использовании для ИИ-инференса, то в этом году, судя по объёму, Groq находится на ранней стадии массового производства для выхода на коммерческие рельсы. 
Источник изображения: Groq Как отметил Chosunbiz, хотя объём поставок Groq для Samsung Electronics невелик, подразделение Samsung Electronics активно работает с потенциальными клиентами, чтобы заложить основу для получения крупных заказов на поставку ИИ-чипов. Помимо Groq, подразделение Samsung Electronics также производит весь ассортимент процессоров для HyperExcel — южнокорейского стартапа по разработке чипов для ИИ-инференса. Samsung Electronics производит ИИ-чипы для Groq и HyperExcel по 4-нм техпроцессу. По словам источника в полупроводниковой отрасли, «4-нм техпроцесс, используемый Samsung Electronics для массового производства чипов Groq для ИИ-нагрузок, включает ряд улучшенных процессов для повышения производительности чипа. Учитывая высокую стоимость процесса и самый высокий спрос в отрасли на 4–5-нм техпроцессы, это также имеет важное значение для обеспечения конкурентного преимущества перед TSMC». Собеседник ресурса Chosunbiz прогнозирует, что с учётом выхода NVIDIA на рынок ИИ-чипов и увеличения производства Groq ожидается бурный рост рынка чипов для ИИ-инференса. Ожидается, что на мероприятии GTC 2026 NVIDIA представит чип для ИИ-инференса на основе дизайна, разработанного Groq, в котором используется память SRAM вместо HBM. Как сообщают источники, одним из заказчиков нового чипа будет OpenAI.
03.02.2026 [17:15], Руслан Авдеев
OpenAI не устроили чипы NVIDIA для инференса, теперь она ищет альтернативыПо данным многочисленных отраслевых источников, компания OpenAI недовольна некоторыми ИИ-чипами NVIDIA и с прошлого года ищет им альтернативы. Потенциально это усложнит отношения между крупнейшими игроками рынка на фоне бума ИИ, сообщает Reuters. Изменения стратегии OpenAI связаны с усилением акцента на инференсе. NVIDIA доминирует в нише ускорителей для обучения ИИ-моделей, но теперь инференс стал отдельным рынком с сильной конкуренцией. Решение OpenAI — вызов доминированию NVIDIA в сфере ИИ и препятствие $100-млрд сделки между компаниями, обеспечивающей разработчику чипов долю в ИИ-стартапе в обмен на доступ к передовым ускорителям. Предполагалось, что сделка будет закрыта за недели, но вместо этого переговоры ведутся месяцами. В то же время OpenAI заключила соглашение с AMD и Cerebras (её в своё время даже хотели купить) для получения «альтернативных» чипов, а также разрабатывает собственный ИИ-ускоритель при участии Broadcom. Amazon тоже не прочь предоставить OpenAI собственные ускорители, равно как и Google. Изменение планов OpenAI изменило и потребности в вычислительных мощностях и замедлило переговоры с NVIDIA. 
Источник изображения: Robin Jonathan Deutsch / Unsplash В минувшую субботу глава NVIDIA Дженсен Хуанг (Jensen Huang) опроверг слухи о проблемах с OpenAI, назвав их «чепухой» и подчеркнув, что клиенты продолжают выбирать NVIDIA для инференса, поскольку компания обеспечивает наилучшее соотношение производительности и совокупной стоимости владения, причём в больших масштабах. Отдельно представитель OpenAI заявлял, что компания полагается на NVIDIA для поставок большинства чипов для инференса, причём именно NVIDIA обеспечивает наилучшую производительность на каждый вложенный доллар. Глава OpenAI Сэм Альтман (Sam Altman) отметил, что NVIDIA выпускает «лучшие чипы в мире» и есть надежда, что OpenAI останется её «гигантским» клиентом очень долгое время. При этом, как сообщает Reuters со ссылкой на семь источников, OpenAI не удовлетворена производительностью инференса, на которую способны чипы NVIDIA. В частности, речь идёт о специализированных задачах вроде разработки ПО с помощью ИИ и коммуникаций ИИ с другим ПО. По данным одного из источников, компании понадобится новое аппаратное обеспечение, которое в конечном счёте обеспечит в будущем порядка 10 % вычислительных мощностей для инференса. 
Источник изображения: OpenAI OpenAI обсуждала возможности работы с ИИ-стартапами, включая Cerebras и Groq для обеспечения чипов с более быстрым инференсом, но NVIDIA фактически поглотила Groq на $20 млрд, что привело к прекращению переговоров с компанией. Хотя формально речь идёт неэксклюзивном лицензировании технологий Groq, что в теории позволяет сторонним компаниям получить доступ к решениям Groq, фактически все разработчики перешли в NVIDIA, а оставшаяся небольшая команда отвечает за выполнение облачных контрактов с имеющимися заказчиками. Чипы NVIDIA хорошо подходят для обработки больших объёмов данных при обучении больших ИИ-моделей вроде тех, что стоят за ChatGPT. Тем не менее прогресс требует массового использования уже обученных моделей для дальнейшего инференса и ИИ-рассуждений. Как сообщается, OpenAI с 2025 года ищет альтернативы ускорителям NVIDIA с упором на компании, создающие чипы с большими объёмами интегрированной SRAM. Maia 200 от Microsoft, по-видимому, компании не очень подходит. 
Источник изображения: Hermann Wittekopf - kmkb / Unsplash Инференс моделей более требователен к памяти, чем обучение, а вычислительная нагрузка, наоборот, не так велика. В тоге нередко на доступ к данным уходит больше времени, чем на расчёты. NVIDIA и AMD полагаются на внешнюю память, что замедляет соответствующие процессы общения с чат-ботами. В OpenAI проблемы отметили при эксплуатации системы Codex, активно продвигаемой компанией для создания кода. В компании считают, что некоторые слабости системы связаны именно с оборудованием NVIDIA. Конкуренты OpenAI полагаются на альтернативное оборудование. Anthropic активно использует AWS Trainium и Google TPU, а Google уже много лет использует свои TPU, которые с недавних пор готова отдавать на сторону. TPU оптимизированы в том числе для инференса и в некоторых отношениях более производительны, чем GPU общего назначения AMD и NVIDIA. Когда OpenAI недвусмысленно выразила отношение к технологиям NVIDIA, та предложила компаниям, создающим ускорители с упором на SRAM, включая Cerebras и Groq, купить их бизнес. Cerebras отказалась и заключила прямую сделку с OpenAI. Groq вела переговоры с OpenAI о предоставлении вычислительных мощностей, что вызвало интерес у инвесторов, оценивших капитализацию компании на уровне $14 млрд.
14.01.2026 [09:45], Владимир Мироненко
Самая загадочная сделка 2025 года: зачем NVIDIA потратила $20 млрд на Groq?Сделка NVIDIA с ИИ-стартапом Groq, фактически означающая его поглощение, вызвала вопросы по поводу целей, которые преследует лидер ИИ-рынка. Для того, чтобы избежать волокиты с одобрением сделки регулирующими органами и антимонопольных расследований, NVIDIA провела её под видом приобретения неисключительной лицензии на технологии Groq. В результате сделки ключевые кадры Groq перешли в NVIDIA, а остатки команды во главе с финансовым директором продолжат управлять инфраструктурой GroqCloud и вряд ли смогут сохранить былую конкурентоспособность стартапа. Похожую сделку NVIDIA провела немногим ранее, фактически поглотив стартап Enfabrica, занимавшийся разработкой интерконнекта. В случае с Enfabrica, по слухам, сумма сделки составила $900 млн. Это большая сумма для стартапа, находящегося на ранней стадии, но вполне обоснованная в нынешних условиях, пишет EE Times. Groq — более крупный стартап, но и стоимость сделки гораздо выше — $20 млрд при последней оценке стартапа на уровне $6,9 млрд. Если в отношении Enfabrica предполагалось, что сделка была связана, хотя бы частично, с наймом персонала, то для Groq такая большая сумма вряд ли выглядит оправданной, если речь идёт только о привлечении квалифицированных кадров. Можно допустить, что NVIDIA планирует выпускать чипы Groq. Их упомянул в электронном письме сотрудникам гендиректор NVIDIA Дженсен Хуанг: «Мы планируем интегрировать процессоры Groq с низкой задержкой в архитектуру NVIDIA AI Factory, расширив платформу для обслуживания ещё более широкого спектра задач ИИ-инференса и рабочих нагрузок в реальном времени». 
Источник изображений: Groq Вместе с тем в ходе CES 2026 Хуанг заявил, что технология Groq не станет частью основного портфолио NVIDIA для ЦОД. «[Groq] — это совсем, совсем другое, и я не ожидаю, что что-либо заменит то, что мы делаем с Vera Rubin и нашим следующим поколением, — сказал Хуанг. — Однако мы могли бы добавить его технологию таким образом, чтобы что-то постепенно улучшить, чего мир ещё не смог сделать». Судя по фразе «могли бы», NVIDIA пока окончательно не определилась с тем, что будет делать с активами Groq. Технология Groq позволит решать задачи, которые недоступны для Vera Rubin, в частности, сверхбыстрый инференс в реальном времени, пишет EE Times. Можно предположить, что NVIDIA будет производить и развёртывать чипы Groq как отдельное решение в ЦОД. Хотя Хуанг и сказал об интеграции чипов Groq с архитектурой NVIDIA AI Factory, это всё ещё кажется несколько надуманным, так как означает признание NVIDIA в том, что её GPU не вполне подходят для некоторых рабочих нагрузок. Однако Дженсен Хуанг в очередной раз подчеркнул на CES 2026, что гибкости GPU вполне хватит для любых нагрузок. Впрочем, анонс соускорителей Rubin CPX говорит скорее об обратном.  У Groq есть собственный программный стек, но насколько он хорош, сказать трудно. Для перезапуска технологий Groq в качестве продукта NVIDIA потребуется немало работы над ПО, а полноценная интеграция в программную экосистему может оказаться очень сложной. Более реалистичным вариантом может быть использование чиплета Groq вместе с большим чиплетом GPU для обработки определённых нагрузок, но и в этом случае ПО станет камнем преткновения, поскольку аппаратная часть принципиально слабо совместима с CUDA. Возникает вопрос: «Что же есть у Groq, чего нет у NVIDIA?». Одним из ответов может быть детерминизм — концепция, лежащая в основе архитектуры LPU Groq, которую компания пыталась продвинуть в автомобильной промышленности в 2020 году. Детерминизм имеет существенные преимущества для приложений, требующих функциональной безопасности, включая робототехнику — Хуанг в письме, упомянутом выше, говорит о «приложениях реального времени». Но для этого NVIDIA придется изменить свою риторику, признав, что для периферийных вычислений её ускорители подходят не всегда. В любом случае, у NVIDIA имеются огромные ресурсы и команда квалифицированных специалистов. Если бы она захотела создать ИИ-ускоритель, ориентированный на работу со SRAM, а не HBM, это обошлось бы гораздо дешевле уплаченных за Groq $20 млрд. Кроме того, утверждает EE Times, она могла бы за существенно меньшую сумму пробрести d-Matrix или даже SambaNova, которая готова продаться Intel всего за $1,6 млрд.  Как полагают аналитики EE Times, помимо лицензирования технологии и найма специалистов Groq, в принятии решения купить стартап также сыграли роль коммерческие факторы. Groq имеет обширные партнёрские отношения с крупными компаниями стран Персидского залива. У стартапа также есть соглашения о суверенном ИИ и в других странах, что могло показаться привлекательным для NVIDIA. Тем не менее, одним из главных аргументов в пользу покупки Groq до сих пор было то, что это вполне жизнеспособная и недорогая альтернатива NVIDIA для построения суверенной ИИ-инфраструктуры. То есть покупку Groq можно также объяснить желанием помешать одному из клиентов-гиперскейлеров купить Groq, будь то из-за аппаратной интеллектуальной собственности или уже развёрнутой инфраструктуры. Это может быть Meta✴, Microsoft или даже OpenAI, чьи планы по созданию собственного ИИ-оборудования всё ещё находятся на стадии подготовки или пока имеют умеренный успех, тогда как Google уже готов отдать «на сторону» свои ускорители TPU, а AWS со своими Trainium всё-таки готова сотрудничать с NVIDIA по аппаратной части.  В свою очередь, аналитики ресурса The Register объясняют покупку Groq за столь крупную сумму интересом NVIDIA к «конвейерной архитектуре» (dataflow) стартапа, которая, по сути, создана специально для ускорения вычислений линейной алгебры, выполняемых в ходе инференса. Стоит отметить, что архитектуры с управляемым потоком данных не ограничиваются проектами, ориентированными на SRAM. Например, NextSilicon использует HBM. Groq выбрал SRAM только потому, что это упростило задачу, но нет никаких причин, по которым NVIDIA не могла бы создать dataflow-ускоритель на основе IP-блоков Groq, используя SRAM, HBM или GDDR, пишет The Register. Правильно реализовать такую архитектуру очень сложно, но Groq удалось заставить её работать надлежащим образом, по крайней мере, для инференса, утверждает The Register. Таким образом, Groq даст NVIDIA оптимизированную для инференса вычислительную архитектуру, чего ей так сильно не хватало, полагают аналитики ресурса. Именно этого и не хватает NVIDIA, поскольку у неё фактически нет выделенных чипов для этой задачи. Ситуация изменится с запуском NVIDIA Rubin в 2026 году и их «напарников» Rubin CPX. При этом ускорители Groq LPU в силу малого объёма SRAM для обработки современных LLM необходимо объединять в кластеры из десятков и сотен чипов. Это верно и для других ускорителей примерно того же типа, включая Cerebras. Вместе с тем LPU, по мнению The Register, теоретически могут пригодиться для т.н. спекулятивного декодирования, когда малая модель, не больше нескольких миллиардов параметров, используется для предсказания ответов большой модели. Если малая модель правильно «угадывает» их, общая производительность инференса может вырасти в два-три раза. Стоит ли такая опция $20 млрд, вопрос отдельный, но Хуанг, по-видимому, играет вдолгую.
29.12.2025 [23:06], Владимир Мироненко
Ни один сотрудник Groq не останется внакладе в результате сделки с NVIDIAЗаключение NVIDIA соглашения с Groq, своим конкурентом в области производства ИИ-ускорителей, вызвало вопросы, что означает эта сделка для самих компаний, а также их сотрудников. Структура сделки, оцениваемой, по данным источников Axios, в $20 млрд, призвана свести к минимуму возможность столкновения с обвинениями в нарушении антимонопольного законодательства со стороны регуляторов, поскольку формально нигде на бумаге не зафиксирован факт покупки. Подобного рода сделки заключались на ИИ-рынке и ранее. Согласно условиям соглашения, Groq продолжит действовать как самостоятельная компания под руководством нового гендиректора Саймона Эдвардса (Simon Edwards), ранее исполнявшего обязанности финансового директора. А нынешний генеральный директор Groq Джонатан Росс (Jonathan Ross) и президент Санни Мадра (Sunny Madra) присоединятся к NVIDIA. Оставшиеся сотрудники, по-видимому, будут ответственны за обслуживание ускорителей на Ближнем Востоке и в Европе. Согласно данным источников Axios, большинство акционеров Groq получат выплаты на акцию, привязанные к оценке рыночной стоимости стартапа в $20 млрд. Около 85 % назначенной суммы будет выплачено авансом, еще 10 % — в середине 2026 года, а оставшаяся часть — в конце 2026 года. 
Источник изображения: Groq Также сообщается, что около 90 % персонала Groq перейдёт в NVIDIA. Всем им причитается выплата наличными за все полностью принадлежащие (vested) акции в стартапе. Акции, которые будут им принадлежать после выполнения определённых условий (unvested), будут оплачены согласно оценке стартапа в $20 млрд акциями NVIDIA, которые перейдут в их полную собственность согласно графику. Около 50 человек, перешедших в NVIDIA, получат выплату за все пакеты акций наличными в ускоренном порядке. Остальные сотрудники Groq также получат выплаты за имеющиеся акции стартапа, а также пакет, обеспечивающий экономические стимулы участия в деятельности стартапа. Всем сотрудникам Groq, проработавшим менее года, будет отменен «период ожидания» (vesting period) для закреплённых за ними акций. Благодаря этому ценные бумаги перейдут в их полное владение раньше срока, и они смогут их продать при желании. Также сообщается, что с момента своего основания в 2016 году Groq привлёк около $3,3 млрд венчурного капитала. В число его инвесторов вошли Social Capital, Disruptive, BlackRock, Neuberger Berman, Deutsche Telekom Capital Partners, Samsung, 1789 Capital, Cisco, D1, Cleo Capital, Altimeter, Firestreak Ventures, Conversion Capital и Modi Venture. Кроме того, известно, что Groq ни разу не проводил вторичный тендер, то есть у него не было случаев, когда не были достигнуты намеченные цели по финансированию.
25.12.2025 [02:15], Игорь Осколков
NVIDIA купит за $20 млрд активы разработчика ИИ-ускорителей Groq — это самая дорогая покупка в истории компанииNVIDIA приобретёт активы Groq, своего конкурента в области ИИ-ускорителей, за $20 млрд, передаёт CNBC. Сама Groq заявила, что «заключила неисключительное лицензионное соглашение с NVIDIA на технологии инференса» и что основатель и генеральный директор Groq Джонатан Росс (Jonathan Ross), а также президент компании Санни Мадра (Sunny Madra) и другие высокопоставленные сотрудники «присоединятся к NVIDIA, чтобы помочь продвижению и масштабированию лицензированной технологии». При этом Groq продолжит свою деятельность как независимая компания под руководством Саймона Эдвардса (Simon Edwards). Финансовый директор Nvidia Колетт Кресс (Colette Kress) отказалась комментировать сделку. По-видимому, речь фактически идёт о поглощении Groq, а столь необычная форма сделки выбрана, по примеру других, в попытке снизить внимание к ней регулирующих органов. Стоимость сделки официально не называется, однако Алекс Дэвис (Alex Davis), глава Disruptive, которая инвестировала в Groq более $500 млн, называет сумму в $20 млрд, причём «живыми» деньгами. Дэвис сообщил CNBC, что NVIDIA получит все активы Groq, за исключением её облачного бизнеса. Groq заявила, что «GroqCloud продолжит работать без перебоев». В электронном письме сотрудникам, полученном CNBC, глава NVIDIA Дженсен Хуанг (Jensen Huang) заявил, что сделка расширит возможности NVIDIA: «Мы планируем интегрировать ускорители Groq в архитектуру NVIDIA AI Factory, расширив платформу для обслуживания ещё более широкого спектра задач инференса и рабочих нагрузок в реальном времени». Хуанг добавил: «Хотя мы пополняем наши ряды талантливыми сотрудниками и лицензируем интеллектуальную собственность Groq, мы не приобретаем Groq как компанию». 
Источник изображения: Groq Эта сделка является крупнейшей покупкой NVIDIA за всю историю. До этого самой крупной сделкой была покупка Mellanox почти за $7 млрд в 2019 году. В конце октября у NVIDIA было $60,6 млрд наличных средств и краткосрочных инвестиций, что на $13,3 млрд больше, чем в начале 2023 года. По схожей с Groq схеме была организована и сделка c Enfabrica, в рамках которой NVIDIA заплатила $900 млн деньгами и акциями за лицензирование технологий и переход главы Enfabrica Рочана Санкара (Rochan Sankar) и других ключевых в NVIDIA. Всего три месяца назад Groq, основанная в 2016 году разработчиками ИИ-ускорителей Google TPU, привлекла $750 млн при оценке примерно в $6,9 млрд. Раунд возглавила Disruptive, к которой присоединились Blackrock, Neuberger Berman, Deutsche Telekom Capital Partners, Samsung, Cisco, D1, Altimeter, 1789 Capital и Infinitum. Повлияло ли на решение NVIDIA слухи о намерении Intel купить разработчика ИИ-ускорителей для инференса SambaNova, который наряду с Cerebras является одним из немногих стартапов, способных составить хоть какую-то серьёзную конкуренцию NVIDIA, не уточняется. Сама Groq планировала достичь выручки в $500 млн в этом году. По словам Дэвиса, компания не планировала продажу, когда к ней обратилась NVIDIA. В сентябре NVIDIA объявила о намерении вложить $5 млрд в Intel, а также инвестировать до $100 млрд в OpenAI. Впрочем, последняя сделка носит циклический характер и пока далеко не продвинулась.
21.10.2025 [00:35], Владимир Мироненко
Ещё одна альтернатива платформам NVIDIA — IBM объединила усилия с GroqIBM и Groq объявили о стратегическом партнёрстве с целью предоставления клиентам возможностей высокоскоростного ИИ-инференса по доступной цене путём объединения watsonx Orchestrate от IBM с аппаратными решениями Groq, что позволит ускорить развёртывание агентных систем ИИ. В рамках партнёрства Groq и IBM планируют интегрировать и усовершенствовать технологию Red Hat vLLM с архитектурой LPU Groq. Ожидается, что совместное решение позволит клиентам использовать возможности watsonx Orchestrate привычным образом и с привычными инструментам в инференс-платформе GroqCloud, предоставляющей разработчикам доступ к высокоскоростной и недорогой обработке LLM. Эта интеграция позволит удовлетворить ключевые потребности разработчиков ИИ-решений, включая оркестрацию инференса, балансировку нагрузки и аппаратное ускорение, что в конечном итоге оптимизирует сам процесс инференса. Также планируется поддержка моделей IBM Granite в GroqCloud для клиентов IBM. IBM отметила, что предприятия при переводе ИИ-агентов из пилотной версии в промышленную эксплуатацию продолжают сталкиваться с проблемами обеспечения скорости, стоимости и надёжности. Партнёрство IBM и Groq позволяет объединить скорость инференса Groq, экономическую эффективность и доступ к новейшим open source моделям с оркестрацией агентского ИИ IBM, предоставляя клиентам инфраструктуру, необходимую для их масштабирования, говорит компания. 
Источник изображения: Groq IBM сообщила, что LPU обеспечивают минимум в пять раз более быстрый и экономичный инференс, чем системы на ускорителях конкурентов, имея, по всей видимости, в виду NVIDIA. Это позволяет обеспечить стабильно низкую задержку и производительность при масштабировании нагрузок, что особенно важно для ИИ-агентов в регулируемых отраслях. В качестве примера IBM привела деятельность клиентов из сферы здравоохранения, которые одновременно получают тысячи сложных вопросов пациентов. Благодаря Groq ИИ-агенты IBM смогут анализировать информацию в режиме реального времени и мгновенно предоставлять точные ответы, позволяя организациям в этой сфере принимать более оперативные и обоснованные решения. В нерегулируемых отраслях клиенты IBM с помощью платформы GroqCloud смогут ускорить работу ИИ-агентов и повысить автоматизацию кадровых процессов и производительность сотрудников. IBM объявила, что сразу же предоставит клиентам доступ к возможностям GroqCloud, а совместные с Groq команды сосредоточатся на предоставлении заказчикам IBM следующих возможностей:
Groq привлекла инвестиции в размере $1,8 млрд, включая раунд финансирования на сумму $750 млн в прошлом месяце с оценкой в $6,9 млрд. В числе её инвесторов — Cisco и Samsung. Также Groq сотрудничает с саудовской Aramco Digital. По данным WSJ, компания развернула в этом году 12 ЦОД и намерена развернуть как минимум ещё 12 в 2026 году. В 2024 году Groq сменила модель работы — с тех пор она больше не продаёт свои ИИ-ускорители, предлагая вместо этого создание ЦОД или облака.
18.09.2025 [10:54], Сергей Карасёв
Стартап Groq привлёк на развитие $750 млн, получив оценку в $6,9 млрдКомпания Groq, предоставляющая сервисы ИИ-инференса, объявила о проведении раунда финансирования на $750 млн — это на 25 % больше суммы в $600 млн, которую планировалось получить изначально. При этом рыночная стоимость стартапа достигла $6,9 млрд, что более чем в два раза превышает оценку годичной давности. Groq была основана в 2016 году Джонатаном Россом (Jonathan Ross), который ранее отвечал за разработку ИИ-ускорителей Google Cloud TPU. Компания Groq занимается созданием специализированных чипов LPU (Language Processing Unit) для работы с большими языковыми моделями (LLM). Кроме того, стартап предлагает клиентам облачные ИИ-сервисы и оборудование для построения локальных вычислительных кластеров. 
Источник изображения: Groq Сообщается, что новый раунд финансирования проведён под предводительством Disruptive при участии Blackrock, Neuberger Berman, Deutsche Telekom Capital Partners и крупной американской управляющей компании паевых инвестиционных фондов Западного побережья США. Кроме того, инвестиционную программу поддержали Samsung, Cisco, D1, Altimeter, 1789 Capital и Infinitum. В целом, по оценкам PitchBook, на сегодняшний день Groq привлекла на развитие более $3 млрд. Компания заявляет, что она обеспечивает вычислительными ресурсами более 2 млн клиентов, включая корпорации из списка Fortune 500. Стартап активно расширяет своё присутствие в глобальном масштабе, используя дата-центры в Северной Америке, Европе и на Ближнем Востоке. В частности, ранее Groq и Aramco Digital, подразделение нефтегазового и химического гиганта Aramco, анонсировали проект по созданию в Саудовской Аравии крупнейшего в мире центра по развитию ИИ. |
|

