Материалы по тегу: groq
|
30.07.2025 [14:46], Руслан Авдеев
Groq намерен привлечь $600 млн финансирования — в случае успеха это удвоит капитализацию бизнесаПо данным источников, знакомых с ходом переговоров в ИИ-отрасли, стартап Groq, занимающийся разработкой ИИ-чипов и программного обеспечения, намерен привлечь около $600 млн в рамках очередного раунда финансирования. В результате капитализация компании может достичь порядка $6 млрд, сообщает издание SCMP. Лидером текущего раунда выступает венчурный инвестор VC Disruptive, который, по данным осведомлённых источников, выделил более $300 млн. В самих Groq и VC Disruptive от комментариев отказались. Основанная в 2012 году компания VC Disruptive из Далласа уже инвестировала в такие технологические гиганты, как Palantir Technologies и Airbnb. Итоги раунда финансирования ещё могут измениться, поскольку он пока не завершён. Во вторник издание The Information сообщило, что Groq сократила прогноз выручки на 2025 год более чем на $1 млрд. По словам одного из источников, Groq скорректировала прогнозируемую выручку. Вместе с тем, по его словам, компания рассчитывает компенсировать недополученные доходы в 2026 году. Сама Groq отказалась комментировать данные о продажах. 
Источник изображения: Groq Тем временем, как отмечают источники, новый раунд финансирования оказался масштабнее, чем первоначально планировалось. Благодаря этому общий объём привлечённых средств превысил $2 млрд, а рыночная стоимость компании удвоилась. В 2024 году компания привлекла $640 млн в рамках раунда, организованного фондом BlackRock. Groq занимается разработкой ИИ-ускорителей и стремится в перспективе составить конкуренцию NVIDIA, рыночная капитализация которой превысила $4 трлн на фоне стремительного роста интереса к ИИ. Кроме того, компания инвестирует в создание глобальной распределённой сети, которая позволит пользователям мгновенно получать ответы на свои запросы. Недавно Groq объявила о первой сделке, предусматривающей строительство европейского ЦОД — в Хельсинки (Финляндии).
08.07.2025 [14:55], Руслан Авдеев
Groq запустила свой первый европейский ЦОД в ХельсинкиКомпания Groq, предлагающая сервисы ИИ-инференса, объявила о расширении своей сети дата-центров, открыв свой первый в Европе ЦОД в Хельсинки (Финляндия). Это поможет удовлетворить растущие потребности европейских клиентов, сообщает пресс-служба компании. Как заявил глава Groq Джонатан Росс (Jonathan Ross), спрос на ИИ-инференс растёт всё быстрее, а европейский дата-центр позволит местным клиентам получить минимальную задержку и готовую инфраструктуру для инференса уже сегодня. Кроме того, данные хранятся на территории Европы. Новый объект создан в Хельсинки на площадке Equinix. Партнёрство Equinix и Groq позволяет клиентам Equinix Fabric организовать инференс на платформе GroqCloud. Новые и действующие пользователи в США и EMEA получат доступ к мощностям для инференса через инфраструктуру Equinix Fabric — публичную, частную или суверенную. В Equinix подчеркнули, что Скандинавия — отличное место для ИИ-инфраструктуры. Благодаря политике поддержки экоустойчивой энергетики, возможности использования фрикулинга для охлаждения и надёжности электросети Финляндия стала приоритетным выбором для размещения новых мощностей. 
Источник изображения: Groq Европейские государственные и негосударственные структуры рассчитывают получить полный контроль над развёртываемой инфраструктурой, в местах, которые выбирают они сами — они пытаются сохранить баланс между потребностью в обеспечении суверенитета данных и защиты их конфиденциальности и обеспечением мобильности этих данных. Благодаря новому проекту клиенты могут получать доступ к GroqCloud через частные подключения. Экспансия в Европе расширяет мощности Groq на площадках Equinix и DataBank в США, Bell Canada в Канаде и HUMAIN в Саудовской Аравии. Они уже генерируют более 20 млн токенов в секунду по всей сети Groq. В некоторой степени это отражает спрос на ИИ-ускорители Groq LPU (Language Processing Unit). Чуть более года назад Groq объявила, что больше не продаёт свои ИИ-ускорители, предлагая вместо этого совместно создавать ЦОД и облачные сервисы. Как заявляют в Groq, компания обеспечивает самую низкую стоимость за токен без ущерба качеству, что делает масштабное использование ИИ экономически выгодным как для ИИ-стартапов, так и для крупных корпораций по всему миру.
30.05.2025 [16:25], Руслан Авдеев
Скромно, зато всё своё: Bell Canada и Telus развернут в Канаде сеть ИИ ЦОДКрупнейшая по объёму выручки телеком-компания Канады создаст по всей стране сеть ИИ ЦОД, ориентируясь на пример США и других стран. Речь идёт о Bell Canada Enterprises (BCE), намеренной инвестировать в шести городах сотни миллионов долларов, сообщает Bloomberg со ссылкой на данные оператора. Первый объект в Камлупсе (Kamloops, Британская Колумбия) должны ввести в эксплуатацию уже в июне текущего года, а якорным арендатором для него станет стартап Groq, занимающийся разработкой ИИ-чипов и облачными сервисами. В той же провинции, а также в Манитобе и Квебеке в ближайшие годы планируется строительство и других объектов. Ожидается, что после завершения проекта, получившего имя Bell AI Fabric, мощность дата-центров составит 500 МВт, что немало для поддержки ИИ-проектов, но намного скромнее, чем проекты в США, на Ближнем Востоке и в Азии. Groq станет эксклюзивным партнёром сети ЦОД в деле инференса. Как заявляют в BCE, стране необходим суверенный ИИ, которым управляют канадцы — в компании хотят быть уверенными, что Канада «не будет отключена» в случае геополитической напряжённости и сохранит доступ к технологиям, необходимым для канадской экономики. В компании сетуют, что местные учёные во многом стали пионерами в области разработки современного ИИ, но страна отстаёт в коммерциализации соответствующих технологий. 
Источник изображения: BCE BCE — не единственная компания, стремящаяся развивать ИИ в стране. Местный телеком-оператор Telus объявил о намерении потратить CA$70 млрд ($50. млрд) на расширение и апгрейд своей инфраструктуры. В частности, речь идёт о поддержке ЦОД, которые Telus также называет «суверенными ИИ-фабриками». Заодно планируется утилизировать тысячи тонн устаревших медных кабелей и расширить оптоволоконную сеть. В следующие пять лет Telus намерена ввести в эксплуатацию суверенные ИИ-объекты в Камлупсе, Британской Колумбии и Квебеке. Ранее в этом году, как сообщает Datacenter Dynamics, компания сотрудничала с NVIDIA над внедрением ускорителей Hopper и Blackwell в дата-центре в Квебеке к лету 2025 года. Сообщалось, что ИИ-фабрика будет использовать сеть PureFibre в сочетании с дата-центрами, на 99 % питаемыми возобновляемой энергией, для предоставления AIaaS. 
Источник изображения: BCE Также в апреле сообщалось, что в Канаде построят крупнейший в мире 7,5-ГВт ЦОД с питанием от природного газа. Проект Wonder Valley предусматривает строительство крупного ИИ ЦОД без подключения к магистральным энергосетям в муниципальном округе Гринвью (Greenview) провинции Альберта. Стремление Канады увеличить количество локальных ИИ ЦОД также соответствует растущему спросу на инференс. В то время, как ИИ ЦОД, ориентированные на обучения ИИ-моделей, можно размещать почти где угодно при наличии свободной земли и энергии, для быстрого инференса необходима близость к потребителям и развитая сетевая инфраструктура. Как сообщают в Groq, суверенные ИИ-платформы составляют немалую часть бизнеса компании. Её сервисами пользуются более 1,6 млн разработчиков, которые могут выбрать как ИИ-модель, так и местоположение ЦОД для работы с данными. Над расширением суверенной инфраструктуры работают всё больше стран. В этом месяце Саудовская Аравия (также сотрудничающая с Groq) и Объединённые Арабские Эмираты (ОАЭ) объявили о планах по работе с американскими технологическими компаниями, включая NVIDIA и OpenAI над созданием локальной ИИ-инфраструктуры. Новые проекты подпитываются растущим спросом на вычислительные ресурсы для запуска ИИ-моделей, а также желанием оптимизировать ИИ под региональные потребности и языки.
06.05.2025 [21:12], Руслан Авдеев
Meta✴ Llama API задействует ИИ-ускорители Cerebras и GroqMeta✴ объединила усилия с Cerebras и Groq для инференс-сервиса с применением API Llama. Открыв API-доступ к собственным моделям, Meta✴ становится чуть более похожа на облачных провайдеров. Как утверждают в Cerebras, разработчики, применяющие API для работы с моделями Llama 4 Cerebras, могут получить скорость инференса до 18 раз выше, чем у традиционных решений на базе GPU. В компании объявили, что такое ускорение позволит использовать новейшее поколение приложений, которые невозможно построить на других ИИ-технологиях. Речь, например, идёт о «голосовых» решениях с низкой задержкой, интерактивной генерации кода, мгновенном многоэтапном рассуждении и т. п. — многие задачи можно решать за секунды, а не минуты. После запуска инференс-платформы в 2024 году Cerebras обеспечила для Llama самый быстрый инференс, обрабатывая миллиарды токенов через собственную ИИ-инфраструктуру. Теперь прямой доступ к альтернативам решений OpenAI получит широкое сообщество разработчиков. По словам компании, партнёрство Cerebras и Meta✴ позволит создавать ИИ-системы, «принципиально недосягаемые для ведущих облаков». Согласно замерам Artificial Analysis, Cerebras действительно предлагает самые быстрые решения для ИИ-инференса, более 2600 токенов/с для Llama 4 Scout. 
Источник изображения: Meta✴ При этом Cerebras не единственный партнёр Meta✴. Она также договорилась с Groq об использовании ускорителей Language Processing Units (LPU), которые обеспечивают высокую скорость (до 625 токенов/с), низкую задержку и хорошую масштабируемость при довольно низких издержках. Groq использует собственную вертикально интегрированную архитектуру, полностью контролируя и железо, и софт. Это позволяет добиться эффективности, недоступной в облаках на базе универсальных ИИ-чипов. Партнёрство с Meta✴ усиливает позиции Groq и Cerebras в борьбе с NVIDIA. Для Meta✴ новое сотрудничество — очередной шаг в деле выпуска готовых open source ИИ-моделей, которые позволят сосредоточиться на исследованиях и разработке, фактически передав инференс надёжному партнёру. Разработчики могут легко перейти на новый стек без необходимости дообучения моделей или перенастройки ускорителей — API Llama совместимы с API OpenAI. Пока что доступ к новым API ограничен. Цены Meta✴ также не сообщает. Meta✴ активно работает над продвижением своих ИИ-моделей. Так, она даже выступила с довольно необычной инициативой, предложив «коллегам-конкурентам» в лице Microsoft и Amazon, а также другим компаниям, поделиться ресурсами для развития и обучения моделей Llama.
10.02.2025 [19:33], Сергей Карасёв
Groq развернула в Саудовской Аравии почти 20 тыс. ИИ-ускорителей LPUКомпании Groq и Aramco Digital объявили об открытии крупнейшего в Европе, на Ближнем Востоке и в Африке (EMEA) вычислительного ИИ-центра, ориентированного на задачи инференса. Площадка располагается в Даммаме в Саудовской Аравии. Groq занимается разработкой ускорителей LPU (Language Processing Unit) для работы с большими языковыми моделями (LLM). Утверждается, что они могут успешно конкурировать с ИИ-ускорителями NVIDIA, AMD и Intel. Aramco Digital, подразделение нефтегазового и химического гиганта Aramco, и Groq сообщили о намерении создать в Саудовской Аравии крупнейший в мире центр по развитию ИИ в марте 2024 года. Тогда говорилось, что Aramco Digital будет сдавать мощности Groq LPU в аренду клиентам на Ближнем Востоке. Предполагается также, что партнёрство с Groq поможет Aramco Digital вывести на рынок управляемую голосом ИИ-модель Norous. 
Источник изображения: Twitter/@sundeep Как теперь сообщается, на базе нового ИИ-центра заработал облачный регион GrogCloud, включающий 19 725 LPU. Инвестиции в проект составили $1,5 млрд — совместно от Groq и Aramco Digital. Джонатан Росс (Jonathan Ross), генеральный директор Groq, сообщил, что к концу I квартала 2025 года компания развернёт сможет генерировать не менее 25 млн токенов в секунду. В перспективе планируется повышение данного показателя вплоть до 1 млрд токенов в секунду. 
Источник изображения: Twitter/@sundeep С момента запуска GroqCloud в марте 2024 года более 800 тыс. разработчиков по всему миру начали использовать эту платформу на базе LPU Inference Engine через программный интерфейс Groq API. Облако, как утверждается, обеспечивает инференс в реальном времени с меньшей задержкой и большей пропускной способностью, чем у конкурентов. GroqCloud подходит для генеративных и разговорных приложений ИИ. 
Источник изображения: Twitter/@sundeep В целом, Groq создаёт высокопроизводительную инфраструктуру ИИ, предназначенную для обслуживания более 4 млрд человек в Саудовской Аравии, на Ближнем Востоке, в Африке и за пределами этого региона. Сделка с Groq является частью крупномасштабного плана Vision-2030, предполагающего переход Саудовской Аравии к инновационной экономике на базе ИИ, которая призвана снизить зависимость страны от добычи нефти и газа.
16.09.2024 [10:51], Руслан Авдеев
Aramco Digital объявила о партнёрстве с Cerebras, Groq и Qualcomm для развития ИИ и 5G IoT в Саудовской АравииПодразделение нефтегазовой саудовской Aramco — Aramco Digital анонсировало серию соглашений с компаниями, действующими в сфере ИИ и беспроводных технологий. По информации Datacenter Dynamics, компания подписала меморандумы о взаимопонимании с Cerebras Systems, развитии передовой ИИ-модели Norous совместно с Groq и сотрудничестве в сфере 5G-технологий совместно с Qualcomm. Aramco принадлежит государству и является крупнейшим в мире добытчиком нефти и газа, располагая вторыми по величине разведанными запасами сырой нефти в мире. Её подразделение Aramco Digital — попытка диверсифицировать бизнес, уделив внимание освоению информационных технологий. Сотрудничество с Cerebras Systems позволит обеспечить высокопроизводительными ИИ-решениями промышленность, университеты и коммерческие предприятия Саудовской Аравии. В рамках соглашения компания будет применять вычислительные системы Cerebras CS-3 на сусперускорителях WSE-3 в облачном бизнесе, чтобы ускорить создание, обучение и внедрение больших языковых моделей и ИИ-приложений. Тем временем партнёрство с Groq поможет Aramco Digital вывести на рынок управляемую голосом ИИ-модель Norous. 
Источник изображения: M Zaedm/unsplash.com В будущем планируется создать систему управления цепочками поставок, способную генерировать миллиарды токенов в секунду. Как сообщают арабские СМИ, пока Aramco Digital планирует обеспечивать до 25 млн токенов к концу I квартала 2025 года, а в этом году будет обеспечено 20 % от заявленных показателей. В Groq заявляют, что компания намерена стать экспортёром вычислительных мощностей для приблизительно 4 млрд человек, этого будет достаточно для «близлежащих континентов» и позволит обеспечивать части Европы, Африки и, возможно, даже часть Индии. Также совместно с Qualcomm компания Aramco Digital задействует 5G-чипы для частотного диапазона 450 МГц. IoT-решения Qualcomm QCS8550/QCS6490 будут поддерживать умные устройства с возможностью периферийных вычислений. Решение включает ряд компонентов, от модема до собственно передатчика, усилителя и систем фильтрации сигнала, а также другие элементы. Эксперты утверждают, что этот диапазон можно эффективно использовать как в помещениях, так и вне их, поэтому новое решение станет одним из важнейших элементов цифровой трансформации Саудовской Аравии. Партнёры также работают над «инкубатором стартапов» совместно с саудовским Управлением по вопросам исследований, развития и инноваций (RDIA). Программа Design in Saudi Arabia (DISA) будет поддерживать стартапы, занимающиеся разработкой и внедрением ИИ, беспроводных технологий и Интернета вещей, обеспечив им техническую помощь, бизнес-коучинг и прочую помощь. Резиденты инкубатора также получат доступ к технологическим платформам Qualcomm и Aramco Saudi Accelerated Innovation Lab. Предполагается, что это простимулирует новую волну технологических инноваций в Саудовской Аравии и коммерциализацию разработок стартапов.
06.08.2024 [00:31], Владимир Мироненко
Cisco и Samsung инвестировали в разработчика ИИ-ускорителей GroqСтартап Groq, разрабатывающий ускорители и решения для генеративного ИИ, объявил о завершении раунда финансирования, позволившего привлечь $640 млн инвестиций. В результате его рыночная стоимость выросла до $2,8 млрд. В раунде финансирования, который возглавила BlackRock Private Equity Partners, приняли участие как существующие, так и новые инвесторы, включая Neuberger Berman, Type One Ventures, а также стратегические инвесторы, включая Cisco Investments, KDDI Open Innovation Fund III и Samsung Catalyst Fund. По словам Джонатана Росса (Jonathan Ross), гендиректора и основателя Groq, полученные инвестиции позволят дополнительно развернуть более 100 тыс. ИИ-ускорителей LPU в GroqCloud, а также пополнить штат квалифицированными кадрами. Предыдущий раунд финансирования Groq прошёл в 2021 году. Его возглавили Tiger Global и D1 Capital. При этом стартап получил $300 млн инвестиций при оценке рыночной стоимости в $1 млрд. 
Источник изображения: Groq Также было объявлено о двух новых назначениях. На должность главного операционного директора компании был принят Стюарт Панн (Stuart Pann), бывший старший исполнительный директор HP и Intel, а Янн Лекун (Yann LeCun), вице-президент и главный научный сотрудник по ИИ в Meta✴, присоединился к Groq в качестве технического консультанта компании, сохранив свою должность в Meta✴. В марте этого года Groq приобрёл компанию Definitive Intelligence, предлагающую ряд бизнес-ориентированных ИИ-решений, чтобы сформировать новое бизнес-подразделение Groq Systems, которое нацелено на обслуживание организаций, правительственных агентств США и суверенных государств. Заодно Groq заключил партнёрское соглашение с Carahsoft, государственным ИТ-подрядчиком. Groq также сотрудничает с саудовской Aramco Digital с целью установки LPU в строящихся ЦОД на Ближнем Востоке и создания крупнейшего в мире центра ИИ. А в рамках соглашения с Earth Wind & Power до конца 2024 года будет развёрнуто 21 600 LPU с возможностью увеличения до 129 600 LPU в 2025 году.
08.04.2024 [01:50], Владимир Мироненко
Groq больше не продаёт свои ИИ-ускорители, предлагая вместо этого совместно создавать ЦОД и облачные сервисыСтартап Groq, создавший ускоритель LPU на базе собственного массивно-параллельного тензорного процессора TSP, больше не продаёт оборудование, предлагая вместо этого воспользоваться его облачными ИИ-сервисами или стать партнёром в создании ЦОД. Об этом генеральный директор Groq Джонатан Росс (Jonathan Ross) сообщил ресурсу EE Times. Он пояснил, что для стартапа заниматься продажами чипов слишком сложно, потому что «минимальная сумма покупки, чтобы это имело смысл, высока, затраты высоки, и никто не хочет рисковать, покупая большое количество оборудования — неважно, насколько оно потрясающее». По его словам, в облаке GroqCloud для инференса больших языковых моделей (LLM) в реальном времени уже зарегистрировано 70 тыс. разработчиков и запущено более 19 тыс. новых приложений. 
Источник изображений: Groq В случае поступления заказов на поставку больших объёмов чипов для очень крупных систем Groq вместо продажи предлагает партнёрство по развёртыванию ЦОД. Groq подписала соглашение с саудовской государственной нефтяной компанией Aramco, которое предполагает масштабное развёртывание LPU. Похожее соглашение в ОАЭ подписала Cerebras, ещё один молодой разработчик ИИ-ускорителей. «Правительство США и его союзники — единственные, кому мы готовы продавать оборудование, — говорит Росс. — Для всех остальных мы лишь (совместно) создаём коммерческие облака». По его словам, в этом году Groq планирует разместить 42 тыс. LPU в GroqCloud, при этом Aramco и другие партнёры «завершают» свои сделки по получению такого же количества чипов. Компания способна выпустить 220 тыс. LPU только в этом году, а общий объём производства на ближайшее время составляет 1,5 млн ускорителей. Около 1 млн из них всё ещё не зарезверированы, но это количество быстро сокращается. Росс пообещал, что к концу 2025 году компания развернёт столько LPU, что их вычислительная мощность будет эквивалентна ИИ-мощностям всех гиперскейлерам вместе взятых.  Росс с оптимизмом смотрит на перспективы Groq, поскольку чипы TSP не используют память HBM, на которую полагаются решения конкурентов, включая NVIDIA, и поставки которой расписаны до конца 2024 года. Что касается LPU следующего поколения, то компания планирует сразу перейти с 14-нм техпроцесса (Global Foundries) на 4-нм. По словам Росса, новый чип будет оптимизирован для генеративного ИИ, но у него в силу универсальности архитектуры не будет каких-то специальных функций для обработки LLM. Будет ли новый ускоритель всё так же изготавливаться на территории США, не уточняется. Groq, похоже, достаточно уверена в своих чипах, которые в бенчмарках действительно обгоняют конкурентов. После анонса архитектуры NVIDIA Blackwell, обеспечивающей кратное увеличение производительности в задачах генеративного ИИ, компания выпустил в ответ пресс-релиз из одного предложения: «Groq всё ещё быстрее». А чуть позже даже раскритиковала NVIDIA.
21.10.2023 [16:09], Сергей Карасёв
В Аргоннской национальной лаборатории запущена ИИ-система GroqАргоннская национальная лаборатория Министерства энергетики США сообщила о запуске вычислительного кластера, использующего специализированные ИИ-решения Groq. Ресурсы системы предоставляются исследователям на базе тестовой площадки ALCF (Argonne Leadership Computing Facility). Groq является разработчиком чипов GroqChip, спроектированных с прицелом на решение задач ИИ и машинного обучения. Эти изделия, наделённые 230 Мбайт памяти SRAM, обеспечивают производительность до 750 TOPS INT8 и до 188 Тфлопс FP16. 
Источник изображения: Аргоннская национальная лаборатория Процессоры GroqChip являются основой ускорителей GroqCard с интерфейсом PCIe 4.0 x16. Восемь таких карт входят в состав сервера GroqNode формата 4U. Наконец, до восьми серверов GroqNode используются в кластерах GroqRack. И именно такие узлы являются основой новой ИИ-платформы ALCF. Заявленная производительность каждого узла достигает 48 POPS (INT8) или 12 Пфлопс (FP16). Экосистема программного и аппаратного обеспечения Groq предназначена для ускорения решения сложных ИИ-задач, в частности, инференса. Исследователи будут применять НРС-платформу при реализации ресурсоёмких научных проектов в таких областях, как визуализация, термоядерная энергия, материаловедение, создание лекарственных препаратов нового поколения и пр. Отмечается, что уникальная архитектура Groq и универсальный компилятор обеспечат повышенную производительность для широкого спектра ИИ-моделей. В рамках сотрудничества Аргоннская национальная лаборатория и Groq работают над лекарствами от коронавируса, спровоцировавшего пандемию COVID-19: говорится, что время получения результатов сократилось с дней до минут. Создавая модели вируса и помогая исследователям быстро сравнивать их с базой данных, содержащей миллиарды молекул препаратов, модели ИИ позволяют идентифицировать перспективные соединения, которые будут использоваться в клинических терапевтических испытаниях.
15.09.2023 [20:52], Алексей Степин
Groq назвала свои ИИ-чипы TSP четырёхлетней давности идеальными для LLM-инференсаТензорный процессор TSP, разработанный стартапом Groq, был анонсирован ещё осенью 2019 года и его уже нельзя назвать новым. Тем не менее, как сообщает Groq, TSP всё ещё является достаточно мощным решением для инференса больших языковых моделей (LLM). Теперь Groq позиционирует своё детище как LPU (Language Processing Unit) и продвигает его в качестве идеальной платформы для запуска больших языковых моделей (LLM). Согласно имеющимся данным, в этом качестве четырёхлетний процессор проявляет себя весьма неплохо. Groq открыто хвастается своим преимуществом над GPU, но в последних раундах MLPerf участвовать не желает. 
Источник изображений здесь и далее: Groq В своё время Groq разработала не только сам тензорный процессор, но и дизайн ускорителя на его основе, а также продумала вопрос взаимодействия нескольких TSP в составе вычислительного узла с дальнейшим масштабированием до уровня мини-кластера. Именно для такого кластера и опубликованы свежие данные о производительности Groq в сфере LLM. 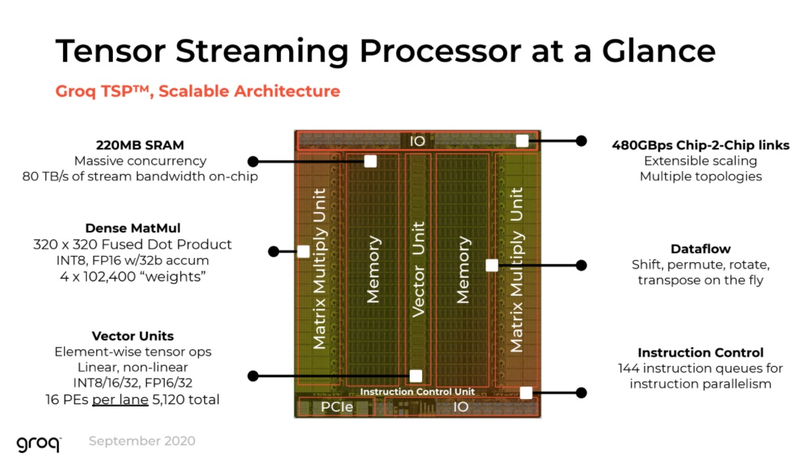 Система разработки, содержащая в своём составе 640 процессоров Groq TSP, была успешно использована для запуска модели Meta✴ Llama-2 с 70 млрд параметров. Как показали результаты тестов, модель на данной платформе работает с производительностью 240 токенов в секунду на пользователя. Для адаптации и развёртывания Llama-2, по словам создателей Groq, потребовалось всего несколько дней. В настоящее время усилия Groq будут сконцентрированы на адаптации имеющейся платформы в сфере LLM-инференса, поскольку данный сектор рынка растёт быстрее, нежели сектор обучения ИИ-моделей. Для LLM-инференса важнее умение эффективно масштабировать потоки небольших блоков (8–16 Кбайт) на большое количество чипов. 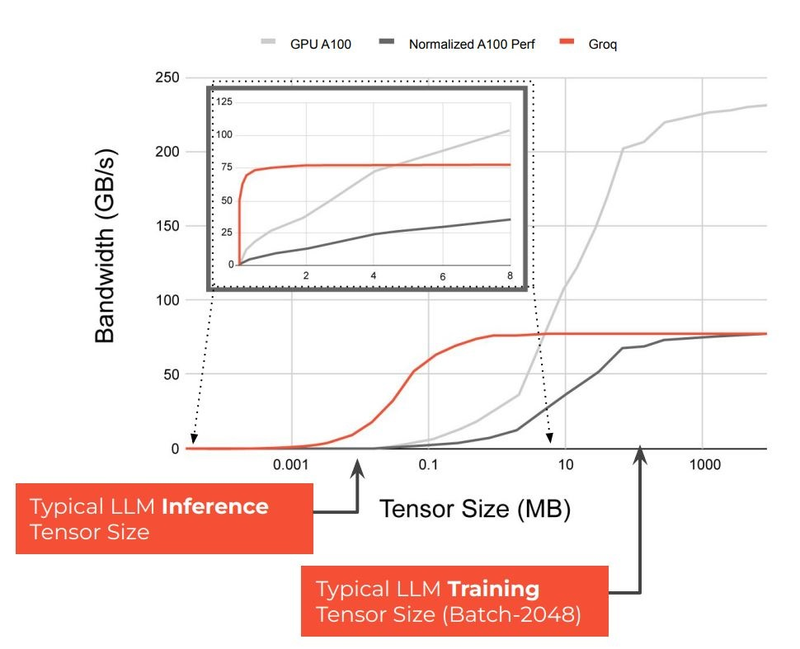 В этом Groq TSP превосходит NVIDIA A100: если в сравнении двух серверов выиграет решение NVIDIA, то уже при 40 серверах показатели латентности у Groq TSP будут намного лучше. В распоряжении Groq имеется пара 10-стоечных кластеров с 640 процессорами, один из которых используется для разработки, а второй — в качестве облачной платформы для клиентов Groq в области финансовых услуг. Работает система Groq и в Аргоннской национальной лаборатории (ALCF), где она используется для исследований в области термоядерной энергетики.  В настоящее время Groq TSP производятся на мощностях GlobalFoundries, а упаковка чипов происходит в Канаде, но компания работает над вторым поколением своих процессоров, которое будет производиться уже на заводе Samsung в Техасе. Параллельно Groq работает над созданием 8-чипового ускорителя на базе TSP первого поколения. Это делается для уплотнения вычислений, а также для более полного использования проприетарного интерконнекта и обхода ограничений, накладываемых шиной PCIe 4.0. Также ведётся дальнейшая оптимизация ПО для кремния первого поколения. 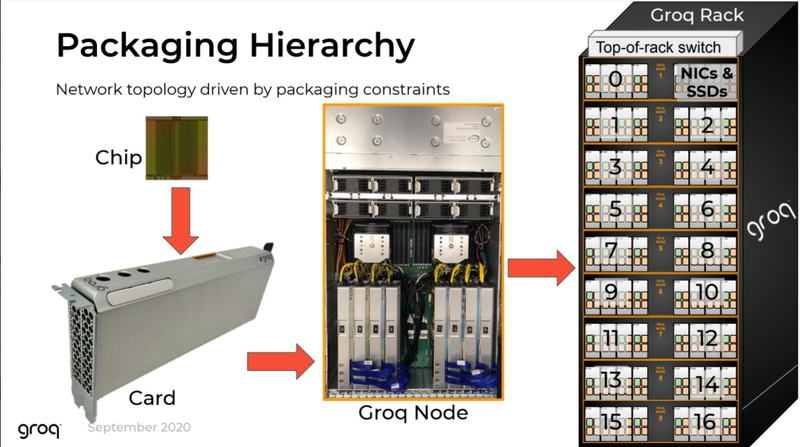 Простота и скорость разработки ПО для платформы Groq TSP объясняется историей создания этого процессора — начала Groq с создания компилятора и лишь затем принялась за проектирование кремния с учётом особенностей этого компилятора. Перекладывание на плечи компилятора всех задач оркестрации вычислений позволило существенно упростить дизайн TSP, а также сделать предсказуемыми показатели производительности и латентности ещё на этапе сборки ПО. При этом архитектура Groq TSP вообще не предусматривает использования «ядер» (kernels), то есть не требует блоков низкоуровневого кода, предназначенного для общения непосредственно с аппаратной частью. В случае с TSP любая задача разбивается на набор небольших инструкций, реализованных в кремнии и выполняемых непосредственно чипом. 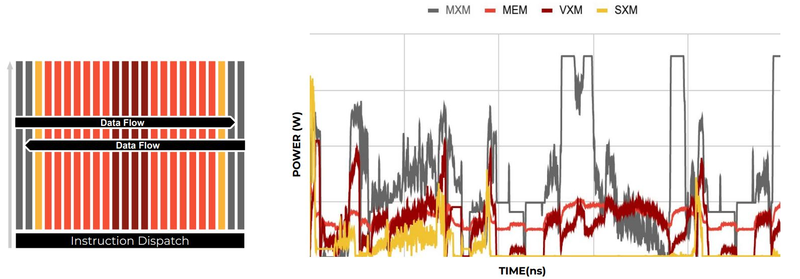
Компилятор Groq позволяет визуализировать и предсказывать энергопотребление с точностью до наносекунд. Источник: Groq Предсказуемость Groq TSP распространяется и на энергопотребление: оно полностью профилируется ещё на этапе компиляции, так что пики и провалы можно спрогнозировать с точностью вплоть до наносекунд. Это позволяет добиться от платформы более надёжного функционирования, избежав так называемой «тихой» порчи данных — сбоев, происходящих в результате резких всплесков энергетических и тепловых параметров кремния. 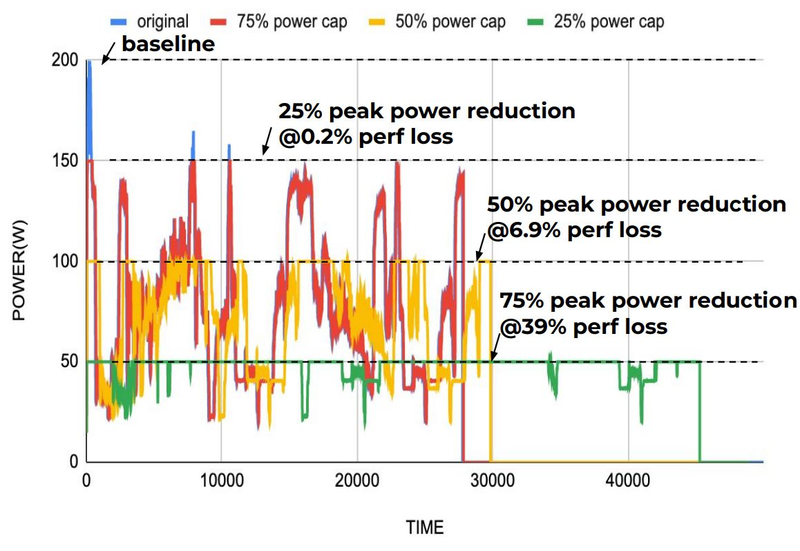
Энергопотребление Groq TSP поддаётся тонкой настройке на уровне программного обеспечения. Источник: Groq Что касается будущего LLM-инференса, то Groq считает, что этой отрасли есть, куда расти. В настоящее время LLM дают ответ на запрос сразу, и затем пользователи могут уточнить его в последующих итерациях, но в будущем они начнут «рефлексировать» — то есть, «продумывать» несколько вариантов одновременно, используя совокупный результат для более точного «вывода» и ответа. Разумеется, такой механизм потребует больших вычислительных мощностей, и здесь масштабируемая и предсказуемая архитектура Groq TSP может прийтись как нельзя более к месту. |
|

