Материалы по тегу: cerebras
|
10.07.2026 [18:55], Сергей Карасёв
Cerebras увеличит выпуск ИИ-систем CS-3 в СШАКомпания Cerebras Systems объявила о расширении сотрудничества с Flex в рамках производства в США своих мощных систем CS-3 для ресурсоёмких ИИ-задач. Ожидается, что объём выпуска оборудования в течение нынешнего года будет увеличен примерно в семь раз. Ранее AMD и Flex договорились о расширении выпуска в США серверов с ускорителями Instinct. В основу стоек Cerebras CS-3 положены фирменные ускорители WSE-3. Эти изделия содержат 4 трлн транзисторов, 900 тыс. ядер и 44 Гбайт памяти SRAM. Суммарная пропускная способность встроенной памяти достигает 21 Пбайт/с, внутреннего интерконнекта — 214 Пбит/с. Быстродействие составляет до 125 Пфлопс (в разреженных FP16-вычислениях). Отмечается, что спрос на ИИ-оборудование стремительно растёт. На этом фоне Cerebras договорилась об увеличении объёмов выпуска CS-3 на мощностях Flex в Милпитасе (Калифорния, США). На этом объекте будут развёрнуты новые производственные линии и сформирована передовая испытательная инфраструктура. Кроме того, потребуется расширение штата специалистов. 
Источник изображения: Cerebras Подчёркивается, что производство CS-3 сопряжено с трудностями, которые редко встречаются при изготовлении традиционных серверов. Каждая система требует специализированных процессов обработки, особой оснастки, точной калибровки и обширной проверки на системном уровне. Эти задачи усложняются тем, что в состав CS-3 входят компоненты жидкостного охлаждения и высокопроизводительная подсистема питания. Инженеры Flex тесно сотрудничали со специалистами Cerebras для внедрения инновационных методов сборки, а также автоматизированных тестовых станций, специально адаптированных под особенности WSE-3. Каждый этап производственного процесса — от механической интеграции до окончательной квалификации системы — требовал взаимодействия между инженерными группами двух компаний.
09.07.2026 [17:12], Сергей Карасёв
Cerebras развернёт в Европе 200 МВт ИИ-мощностей к концу 2027 годаАмериканская компания Cerebras Systems, занимающаяся разработкой ИИ-ускорителей, намерена активно развивать сеть дата-центров в европейском регионе. Первый объект планируется ввести в эксплуатацию к концу текущего года с последующим расширением инфраструктуры в 2027-м. О планах по созданию ЦОД в Европе рассказал генеральный директор Cerebras Эндрю Фельдман (Andrew Feldman). По его словам, такие объекты позволят удовлетворить спрос со стороны местных клиентов на вычислительные ресурсы для задач ИИ. При этом расположение дата-центров непосредственно на территории региона поможет снизить задержки, а также учесть требования европейских регуляторов. Cerebras сосредоточит усилия по развёртыванию дата-центров во Франции и странах Северной Европы. В частности, площадки будут созданы в Норвегии и Финляндии. В общей сложности до конца 2027 года компания рассчитывает ввести в эксплуатацию до 200 МВт мощностей. О том, с какими ЦОД-операторами Cerebras сотрудничает в европейском регионе, ничего не сообщается. 
Источник изображения: Cerebras В мае этого года Cerebras подписала договор об аренде 40 МВт мощностей в дата-центре Digi Power X в Колумбиане (Алабама, США). Кроме того, компания оперирует кластерами для инференса в Санта-Кларе и Стоктоне (Калифорния, США), а также в Далласе (Техас, США). Параллельно Cerebras разворачивает площадки в Миннеаполисе (Миннесота, США). В Канаде компания планирует арендовать мощности в Монреале на площадке Bit Digital, а также в Саскачеване и Манитобе на объектах Bell. Ведутся предварительные переговоры о вводе мощностей в Израиле, ОАЭ, Австралии, Сингапуре, Индии и Индонезии. Нужно отметить, что в мае нынешнего года Cerebras провела первичное публичное размещений акций (IPO) на бирже Nasdaq в США, получив $5,55 млрд. Тогда сообщалось, что привлечённые средства компания направит в том числе на развитие своего семейства ИИ-ускорителей. Кроме того, Cerebras намерена укрепить партнёрские отношения с ведущими облачными провайдерами и разработчиками ИИ-моделей.
24.06.2026 [22:07], Владимир Мироненко
Акции Cerebras Systems упали, несмотря на почти двукратный рост выручкиАкции Cerebras Systems упали примерно на 14 % на предварительных торгах после того, как компания объявила результаты за I квартал 2026 года, закончившийся 31 марта, и прогноз на текущий. Выручка Cerebras выросла на 94 % по сравнению с аналогичным периодом прошлого года и на 13 % по сравнению с предыдущим кварталом, составив $193,4 млн при прогнозе Уолл-стрит в $180,8 млн (по данным Investing.com). Компания заявила, что рост был обусловлен растущим спросом на ИИ-чипы и облачные сервисы инференса, которые всё чаще используются для обработки больших объёмов задач. Операционные убытки составили $15,0 млн, тогда как годом ранее этот показатель был равен $28,5 млн. Чистые убытки тоже стали немного меньше — $14,0 млн против $23,9 млн год назад. Компания не оправдала ожиданий Уолл-стрит по чистым убыткам, которые составили $0,22 на разводнённую акцию при консенсус-прогнозе аналитиков в размере $0,16 на разводнённую акцию. 
Источник изображения: Cerebras Systems Структура доходов Cerebras заметно изменилась. Выручка компании от продажи оборудования выросла на 59 % в годовом исчислении до $110,6 млн, а выручка от облачных сервисов и других услуг увеличилась на 178 % до $82,8 млн, что свидетельствует о всё большем вкладе в бизнес компании сервисов для обработки данных. «Для инвесторов и операторов инфраструктуры этот переход может оказаться столь же важным, как и сама технология Cerebras», — отметил ресурс Converge! Network Digest. Cerebras ожидает получить во II квартале выручку примерно $194 млн (рост примерно на 88 % в годовом исчислении). За весь 2026 финансовый год компания прогнозирует выручку в диапазоне от $855 до $865 млн, что примерно на 69 % больше год к году в среднем показателе. Однако прогноз валовой прибыли за II квартал в размере от 36 % до 38 %, что гораздо ниже по сравнению с 47 % в I квартале, был негативно воспринят инвесторами, что привело к падению цены акций компании. Несмотря на негативную реакцию инвесторов, аналитики Morgan Stanley заявили, что Cerebras показала «сильный дебютный квартал» после IPO, указав на «потенциал роста выручки и существенный потенциал роста валовой прибыли». Прогноз валовой прибыли Cerebras оказался выше прогноза банка в 24 % и консенсус-прогноза Уолл-стрит в 24,6 %.
15.05.2026 [12:23], Сергей Карасёв
Cerebras провела крупнейшее IPO в США в 2026 году, получив $5,55 млрдАмериканская компания Cerebras Systems, специализирующаяся на разработке ИИ-ускорителей, провела первичное публичное размещений акций (IPO) на бирже Nasdaq. В ходе процедуры привлечено $5,55 млрд, что стало крупнейшим размещением в США в нынешнем году. Cerebras намеревалась предложить 28 млн обыкновенных акций класса А. Предполагалось, что стоимость бумаг во время IPO составит от $115 до $125. Позднее стало известно, что будут выпущены 30 млн акций по цене $185. Кроме того, Cerebras предоставила андеррайтерам 30-дневный опцион на приобретение до 4,5 млн дополнительных акций класса А по цене IPO за вычетом комиссий. В число организаторов размещения вошли Morgan Stanley, Citigroup, Barclays, UBS Investment Bank, Mizuho, TD Cowen, Needham & Company, Craig-Hallum, Wedbush Securities, Rosenblatt, Academy Securities, Credit Agricole CIB, MUFG и First Citizens Capital Securities. Торги бумагами начались 14 мая 2026 года под тикером CBRS: сразу же после этого их стоимость подскочила на 108% — до $385. Рыночная капитализация Cerebras в первый день торгов превысила $66 млрд. 
Источник изображения: Cerebras Отраслевые эксперты полагают, что после проведения IPO компания Cerebras сосредоточится на обновлении своего продуктового семейства. Ускорители Cerebras Wafer Scale Engine третьего поколения (WSE-3), дебютировавшие в марте 2024 года, уже изрядно устарели, а конкуренция со стороны других игроков рынка усиливается. Ожидается, что изделия Cerebras WSE-4 обеспечат значительный прирост производительности по сравнению с предшественниками, которые демонстрируют показатель на уровне 125 Пфлопс в разреженных FP16-вычислениях. Предполагается также, что Cerebras увеличит объём памяти SRAM, который у WSE-3 составляет 44 Гбайт. Отмечается, что именно размер памяти является ограничивающим фактором при работе с LLM, оперирующими огромным количеством параметров. Так, для моделей с триллионами параметров, например, Kimi K2, требуется от 12 до 48 ускорителей WSE-3 — в зависимости от способа хранения весов и других характеристик. Таким образом, любое увеличение объёма SRAM позволит значительно повысить эффективность работы ускорителей. На фоне IPO компания Cerebras также может упрочить партнёрские отношения с ведущими облачными провайдерами и разработчиками ИИ-моделей. Напомним, ранее компания заключила соглашение о сотрудничестве с Amazon Web Services (AWS). Вместе с тем OpenAI намерена закупить ускорители Cerebras на $20 млрд.
06.05.2026 [17:08], Сергей Карасёв
Президент OpenAI оказался владельцем долей в Cerebras и CoreWeave, у которых миллиардные сделки с самой OpenAIСоучредитель и президент OpenAI Грег Брокман (Greg Brockman), по сообщению ресурса Datacenter Dynamics, владеет долями в ряде технологических компаний: Cerebras, CoreWeave, Stripe и Helion. С двумя из них OpenAI имеет контракты на десятки миллиардов долларов. Об этом стало известно в ходе судебного разбирательства, инициированного миллиардером Илоном Маском (Elon Musk). В декабре 2015 года Брокман вместе с Маском, Сэмом Альтманом (Sam Altman) и др. основали некоммерческую организацию OpenAI с целью разработки безопасного и самодостаточного ИИ. После того, как Маск в 2019 году покинул компанию, Альтман стал генеральным директором, и OpenAI сформировала дочернюю коммерческую структуру для привлечения средств. В тот момент Брокман получил крупную долю в OpenAI, оцениваемую сейчас примерно в $30 млрд. В своём иске Маск пытается получить от OpenAI крупную материальную компенсацию, добиться отстранения Альтмана и Брокмана от управления компанией и трансформировать её обратно исключительно в некоммерческую организацию. Примечательно, что Брокман в момент основания OpenAI пообещал пожертвовать организации $100 тыс., но так этого и не сделал. 
Источник изображения: персональный сайт Брокмана В том же 2019 году, как стало известно, Брокман начал покупать акции CoreWeave: его доля по состоянию на апрель 2026 года оценивается в $817,37 тыс. Между тем сама OpenAI заключила ряд соглашений по аренде ИИ-инфраструктуры у CoreWeave, обязавшись потратить на услуги этой компании в общей сложности $22,4 млрд. В ходе более раннего судебного разбирательства, инициированного Маском в 2024 году, выяснилось, что OpenAI рассматривала возможность приобретения компании Cerebras — разработчика ИИ-ускорителей. С этим стартапом OpenAI недавно заключила соглашение на приобретение оборудования стоимостью более $20 млрд. Выяснилось, что по состоянию на конец 2025 года стоимость доли Брокмана в Cerebras составляет $2,82 млн. В 2023 году Брокман также начал скупать акции Helion Energy, которая занимается разработкой термоядерных реакторов: на конец прошлого года его доля в деньгах составляла $433,58 тыс. Любопытно, что Альтман инвестирует в эту компанию с 2015-го и до нынешнего года входил в совет её директоров. При этом OpenAI намерена закупать термоядерную энергию у Helion в «огромных объёмах». Что касается компании Stripe (создаёт решения для приёма и обработки электронных платежей), то в ней Брокман получил долю ещё до начала работы в OpenAI. В Stripe он трудился на позиции технического директора, а его доля в этой фирме составляет в акциях $471,26 млн. Stripe обрабатывает часть платежей OpenAI. В 2023 году было объявлено о трёхлетнем контракте стоимостью $60 млн.
05.05.2026 [00:15], Владимир Мироненко
Cerebras объявила о запуске IPO с оценкой капитализации в $26 млрдКомпания Cerebras Systems объявила о планах начать так называемое роуд-шоу — серию встреч с потенциальными инвесторами — в рамках подготовки в первичному публичному размещению (IPO) своих акций. Заявку в Комиссию по ценным бумагам и биржам США (SEC) на размещение 28 млн своих обыкновенных акций класса А на бирже Nasdaq Global Select Market под тикером CBRS компания подала 17 апреля. Cerebras также сообщила о планах предоставить андеррайтерам 30-дневный опцион на приобретение до 4,2 дополнительных акций своих обыкновенных акций класса А. Ожидается, что цена акции во время IPO составит от $115,00 до $125,00. При верхней границе диапазона Cerebras будет оцениваться до $26,62 млрд, что сделает ее крупнейшей компанией, специализирующейся исключительно на чипах для ИИ, на бирже за последнее время. Это размещение также рассматривается как важный барометр для оценки рыночного энтузиазма в отношении инвестиций в ИИ-инфраструктуру. В качестве ведущих андеррайтеров, несущих основную ответственность за заполнение книги заявок при размещении, выступят банки Morgan Stanley, Citigroup, Barclays и UBS Investment Bank. Им окажут помощь Mizuho и TD Cowen. А Needham & Company, Craig-Hallum, Wedbush Securities, Rosenblatt, Academy Securities, Credit Agricole CIB, MUFG и First Citizens Capital Securities выступят в качестве соорганизаторов. Размещение будет осуществляться только посредством проспекта. Заявление о регистрации ценных бумаг было подано в SEC, но ещё не вступило в силу. 
Источник изображения: Cerebras Cerebras пользуется поддержкой серьёзных инвесторов. Ранее в этом году компания завершила раунд финансирования в размере $1 млрд, возглавляемый технологическим инвестиционным гигантом Tiger Global при участии Benchmark, Fidelity Management, Altimeter, AMD и Coatue, а также других известных институциональных инвесторов. После его проведения оценка рыночной капитализации Cerebras составляет $23 млрд. Следует отметить, что это вторая попытка Cerebras провести первичное публичное размещение акций. Компания отозвала свою предыдущую заявку на IPO в октябре прошлого года. Её возвращение сейчас — на фоне усиливающегося интереса к инвестициям в ИИ и более широкого восстановления рынка IPO — привлекло значительно большее внимание рынка. В отличие от прошлогоднего незаметного отзыва, Cerebras возвращается с высокими финансовыми показателями и крупными клиентскими контрактами. В частности, она заключила соглашение с OpenAI на сумму $20 млрд на поставку в течение следующих трёх лет ИИ-ускорителей в дополнение к предыдущей сделке на $10 млрд. UPD 12.05.2026: Cerebras подняла оценку стоимости акций до $150–$160/шт., что позволит получить ей во время IPO не $3,5 млрд, как ожидалось ранее, а около $4,8 млрд.
17.04.2026 [22:53], Владимир Мироненко
ИИ-стартап Cerebras поставит OpenAI ускорители ещё на $20 млрдКомпания OpenAI заключила соглашение с ИИ-стартапом Cerebras, согласно которому она выплатит более $20 млрд в течение следующих трёх лет за поставку ИИ-ускорителей, сообщило издание The Information. В рамках сделки OpenAI получит варранты на миноритарную долю в Cerebras, при этом её доля может увеличиться по мере роста расходов, утверждают источники The Information. По их данным, OpenAI также согласилась предоставить Cerebras около $1 млрд для финансирования развёртывания ЦОД на базе её ИИ-ускорителей. До этого, в январе Cerebras договорилась с OpenAI о поставке в течение трёх лет своих ускорителей общей мощностью 750 МВт. Стоимость этой сделки оценивается в $10 млрд. Новое соглашение подчеркивает растущий интерес отрасли к вычислительным мощностям для инференса, отметило агентство Reuters. По его данным, Cerebras может раскрыть некоторые подробности своего соглашения с OpenAI, когда предоставит регулятору документы для проведения первичного публичного размещения (IPO). 
Источник изображения: Cerebras Исходя из общей суммы контрактов The Information допускает, что OpenAI может получить варранты, представляющие до 10 % доли в Cerebras. Сотрудничество с OpenAI является ключевым элементом в планах Cerebras по выходу на биржу, планирующего провести листинг во II квартале этого года. Cerebras, чья рыночная стоимость, по последним оценкам, составляет $23,1 млрд, планирует привлечь $3 млрд в ходе первичного публичного размещения акций в следующем месяце при оценке примерно в $35 млрд, сообщил The Information. Выход на биржу неоднократно откладывался. Сначала компанию подозревали в опосредованных связях с Китаем и зависимости от ближневосточных нефтедолларов, а потом компания дважды получила крупные инвестиции и нарастила капитализацию. Сделки с AWS и OpenAI укрепили её позиции и успокоили инвесторов. В пятницу Cerebras объявила о подаче заявки на первичное публичное размещение акций (IPO) в США. Компания планирует разместить свои акции на Nasdaq под тикером CBRS. Ведущими андеррайтерами размещения являются Morgan Stanley, Citigroup, Barclays и UBS. Ранее на этой неделе Morgan Stanley открыл Cerebras возобновляемую кредитную линию с доступом до $250 млн, с возможностью увеличения лимита до $850 млн после IPO, сообщил CNBC. Согласно документам, поданным в пятницу, среди инвесторов Cerebras — Alpha Wave, Benchmark, Eclipse, Fidelity и Foundation Capital. На сайте Cerebras также указан генеральный директор OpenAI Сэм Альтман (Sam Altman) в качестве инвестора. Cerebras указала в заявке, что не владеет ЦОД, которые использует для предоставления облачных услуг, но может построить собственные в будущем. В документе также сообщается, что чистая прибыль Cerebras за 2025 год составила $87,9 млн при выручке в $510 млн (рост год к году на 76 %). Компания получила прибыль в размере $1,38 на акцию, по сравнению с убытком в $9,90 на акцию годом ранее. По состоянию на 31 декабря 2025 года у Cerebras оставалось $24,6 млрд невыполненных обязательств, и ожидается, что 15 % этой суммы будет учтено в 2026 и 2027 годах.
14.03.2026 [18:42], Владимир Мироненко
Царь-ускорители Cerebras в облаке AWS пятикратно ускорят инференс ИИAmazon Web Services (AWS) и Cerebras Systems объявили о сотрудничестве, «которое позволит создать в ближайшие месяцы самые быстрые решения для инференса в системах генеративного ИИ и рабочих нагрузок машинного обучения». Решение, которое будет развёрнуто на платформе Amazon Bedrock в ЦОД AWS, объединяет серверы на базе ускорителей Trainium, системы Cerebras CS-3 на базе царь-чипов WSE-3 и DPU EFA. Ожидается, что эта технология увеличит скорость генерации результатов ИИ-моделями в пять раз. Позже в этом году AWS предложит ведущие open source решения машинного обучения и собственные ИИ-модели Amazon Nova, использующие оборудование Cerebras. Как отметил Дэвид Браун (David Brown), вице-президент по вычислительным и машинным сервисам AWS, при инференсе критическим узким местом для ресурсоёмких рабочих нагрузок, таких как помощь в кодировании в реальном времени и интерактивные приложения, остаётся скорость: «Решение, которое мы разрабатываем совместно с Cerebras, решает эту проблему: разделяя нагрузку по инференсу между Trainium и CS-3 и соединяя их с помощью EFA, каждая система делает то, что у неё лучше всего получается. В результате инференс будет на порядок быстрее и производительнее, чем сегодня». 
Источник изображения: Amazon Совместное решение использует «дезагрегацию вывода» — метод, который разделяет ИИ-инференс на два этапа: этап интенсивной обработки подсказок, или «предварительного заполнения» (процесс обработки запроса LLM), и этап генерации выходных данных, известный как «декодирование», на котором модель формирует ответ на вопрос пользователя. 
Источник изображений: Cerebras Предварительное заполнение является параллельным, вычислительно интенсивным процессом и не требует большой пропускной способности памяти. Декодирование, с другой стороны, является последовательным процессом с минимальными требованиями к вычислительным ресурсам, но интенсивно использует пропускную способность памяти. Декодирование обычно занимает большую часть времени при инференсе, поскольку каждый выходной токен должен генерироваться последовательно, отметила AWS. 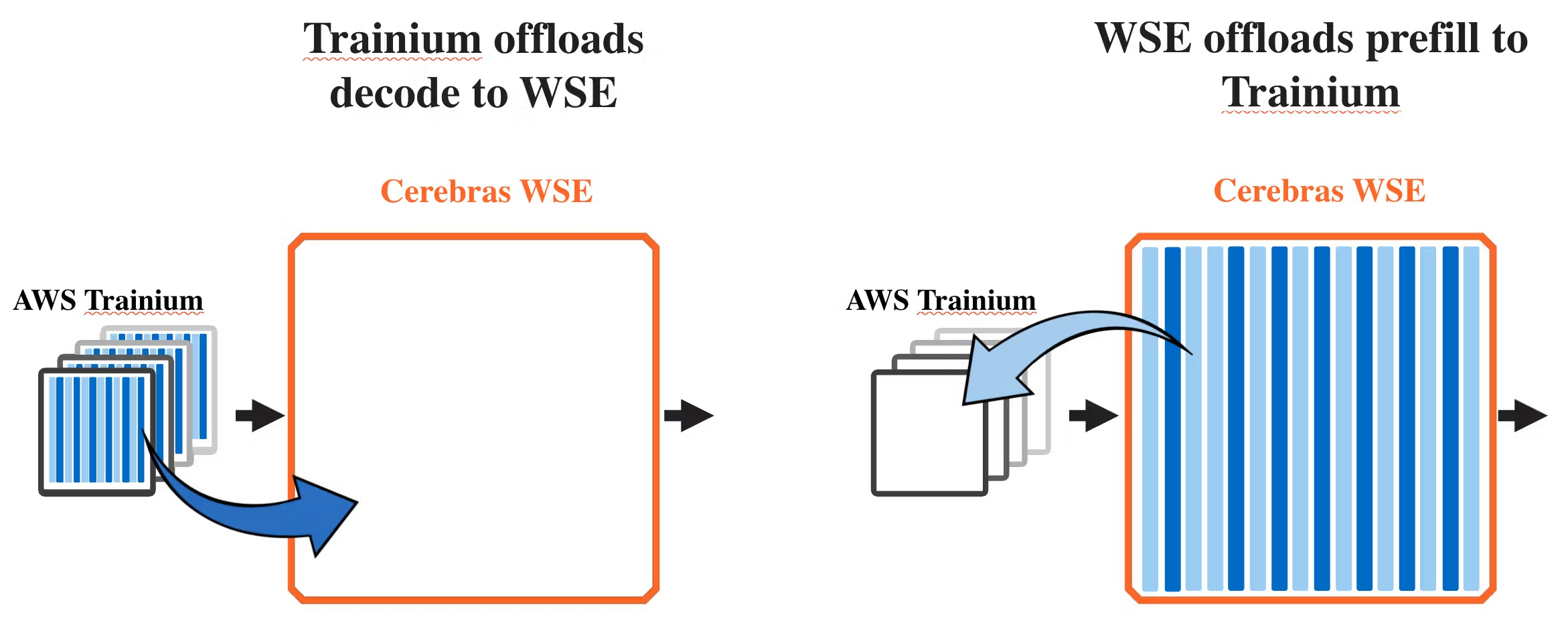 Задачи предварительного заполнения и декодирования обычно выполняются одним и тем же чипом. В дезагрегированной архитектуре AWS чипы Trainium обеспечивают этап предварительного заполнения, а чипы WSE-3 выполняют декодирование. «Дезагрегированный подход идеален, когда у вас большие, стабильные рабочие нагрузки, — сообщил в блоге директор по маркетингу продукции Cerebras Джеймс Ванг (James Wang). — Большинство клиентов используют смешанные рабочие нагрузки с различными коэффициентами предварительного заполнения/декодирования, где традиционный агрегированный подход по-прежнему идеален. Мы ожидаем, что большинство клиентов захотят иметь доступ к обоим вариантам».  Одним из главных преимуществ WSE-3 является то, что он может передавать данные между своими логическими схемами и цепями памяти быстрее, чем многие другие чипы. По данным Cerebras, WSE-3 обеспечивает внутреннюю пропускную способность памяти в 21 Пбайт/с, что значительно превышает пропускную способность NVLink для ускорителей от NVIDIA. Впрочем, у NVIDIA теперь есть ускорители Groq, которые тоже помогают ускорить инференс. Несколько недель назад Cerebras заключила с OpenAI сделку на $10 млрд по поставке чипов общей мощностью 750 МВт до 2028 года. Сделка была объявлена в период между двумя раундами финансирования, которые в совокупности принесли Cerebras более $2 млрд. Ожидается, что компания подаст заявку на IPO уже во II квартале 2026 года. Сделки с AWS и OpenAI могут способствовать повышению интереса инвесторов к листингу, отметил SiliconANGLE.
21.02.2026 [15:03], Сергей Карасёв
G42 из ОАЭ и Cerebras построят в Индии национальный ИИ-суперкомпьютер с царь-ускорителями WSE-3Холдинг G42 из Абу-Даби (ОАЭ) и компания Cerebras в партнёрстве с Университетом искусственного интеллекта им. Мохаммеда бин Зайеда (MBZUAI) и Индийским центром развития передовых вычислительных технологий (C-DAC) развернут в Индии национальный ИИ-суперкомпьютер. Технические подробности проекта не раскрываются. Отмечается лишь, что система обеспечит ИИ-производительность на уровне 8 Эфлопс (точность вычислений не указана). Комплекс, размещённый на территории Индии, будет эксплуатироваться в соответствии с местными требованиями к безопасности, а все обрабатываемые данные останутся в национальной юрисдикции. Иными словами, речь идёт о формировании суверенной вычислительной платформы. Как отмечает The Register, в основу суперкомпьютера лягут ускорители Cerebras WSE-3. Эти изделия содержат 4 трлн транзисторов, 900 тыс. ядер и 44 Гбайт SRAM. Суммарная пропускная способность встроенной памяти достигает 21 Пбайт/с. Производительность составляет до 125 Пфлопс на операциях FP16. Таким образом, в составе НРС-системы могут быть задействованы 64 экземпляра Cerebras WSE-3. 
Источник изображения: G42 После ввода в эксплуатацию новый суперкомпьютер станет доступен широкому кругу пользователей в Индии — от ведущих научных организаций, институтов и государственных структур до стартапов, малых и средних предприятий. Ожидается, что появление системы позволит ускорить инновации в области ИИ. «Суверенная инфраструктура ИИ становится важнейшим компонентом национальной конкурентоспособности. Новый проект предоставит Индии такую платформу, позволив местным исследователям и предприятиям внедрять ИИ, обеспечивая при этом полную безопасность данных», — заявил Ману Джайн (Manu Jain), генеральный директор G42 India. Нужно отметить, что в Индии активно развивается инфраструктуры для ИИ-вычислений. В частности, индийские Tata Group, Tata Consultancy Services (TCS) и OpenAI намерены развернуть в стране ИИ ЦОД мощностью до 1 ГВт. Вместе с тем индийский конгломерат Adani вложит $100 млрд в создание ЦОД общей мощностью 5 ГВт, снабжаемых возобновляемой энергией.
06.02.2026 [11:04], Руслан Авдеев
Cerebras привлекла ещё $1 млрд инвестиций после сделки с OpenAIЧерез четыре месяца после завершения раунда финансирования в объёме $1,1 млрд Cerebras Systems заявила о привлечении ещё $1 млрд, во многом от прежних инвесторов, сообщает Datacenter Dynamics. Сделку серии H возглавила Tiger Global, к ней присоединились AMD, Fidelity Management, Atreides Management, Alpha Wave Global, Altimeter, Coatue, 1789 Capital и другие компании. Сегодня оценка рыночной капитализации Cerebras составляет $23 млрд. Новый раунд привлечения средств объявлен через несколько недель после того, как компания заключила с OpenAI сделку на $10 млрд. Cerebras сегодня предлагает суперчип WSE-3 с 4 трлн транзисторов, это в 19 раз больше, чем может обеспечить NVIDIA Blackwell B200. Чип включает 44 Гбайт SRAM, что, как считается, позволяет добиться большей скорости инференса и меньше зависеть от поставок всё более дефицитных HBM и DDR. 
Источник изображения: Cerebras В сентябре 2024 года Cerebras подала заявку на IPO. Тогда компания сообщала, что в I полугодии 2024 года её выручка составила $136,4 млн, это более чем в 10 раз выше год к году. Убытки за тот же период сократились с $77,8 млн до $66,6 млн. В 2025 году компания отозвала заявку на IPO, посчитав, что документ более не отражает состояние бизнеса. В частности, в 2025 году значительно выросла выручка и теперь компания рассчитывает повторно подать документы для выхода на биржу уже во II квартале 2026 года. |
|

