Самая крупная за всю историю NVIDIA сделка — приобретение Groq за $20 млрд — начала приносить первые плоды. Компания интегрировала архитектурно чуждые ИИ-ускорители LPU в свою ИИ-платформу Vera Rubin, чтобы резко ускорить инференс, сделав его дезагрегированным, а платформу — гетерогенной. Именно LPU помжет удовлетворить требования к низкой задержке при интерактивной работе с ИИ и быстроте обработке большого контекста в агентных системах. При этом об анонсированных ранее соускорителях Rubin CPX компания теперь предпочитает не вспоминать.
Стоечный ускоритель NVIDIA Groq LPX
Система LPX обеспечивает ИИ-фабрику движком, оптимизированным для быстрой и предсказуемой генерации токенов, в то время как Vera Rubin NVL72 выступает в роли гибкого универсального инструмента для обучения и инференса, обеспечивая высокую пропускную способность на этапах предварительного заполнения и декодирования, включая обработку длинного контекста, работу механизма внимания и обслуживание систем с высокой степенью параллелизма в масштабе.

Источник изображений: NVIDIA
Такое сочетание необходимо, поскольку будущее агентов требует новой категории инференса. По мере того как скорость генерации приближается к 1000 токенов/с (TPS) на каждого пользователя, модели выходят за рамки взаимодействия со скоростью человеческого разговора, говорит NVIDIA. При таких темпах ИИ-системы могут постоянно рассуждать, моделировать и реагировать, что позволяет им взаимодействовать не столько в пошаговом чате, сколько в режиме совместной работы в реальном времени. Этот сдвиг также повышает планку для мультиагентных систем.

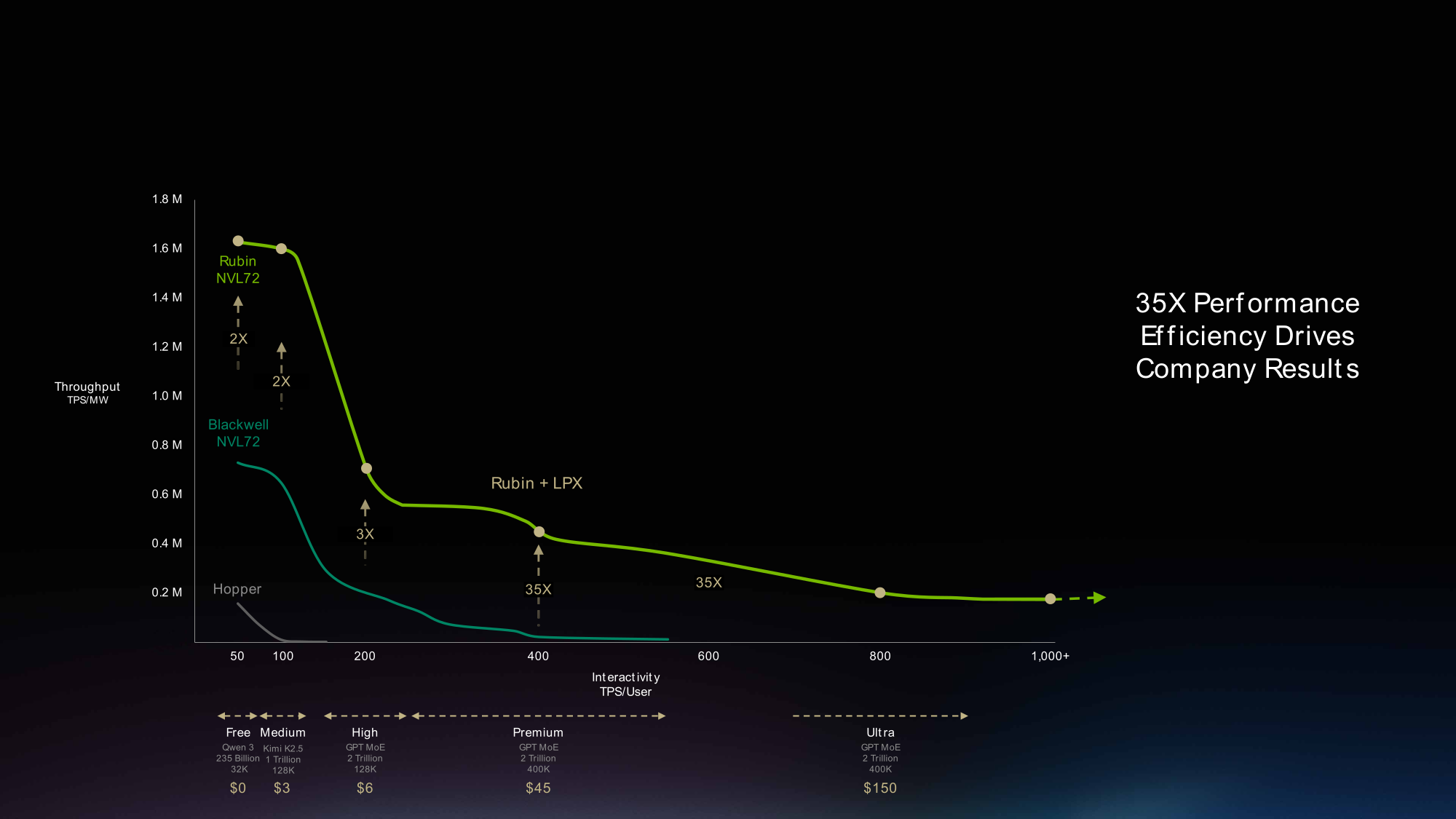
Для обработки новых рабочих нагрузок требуется инфраструктура, способная обеспечить как высокую пропускную способность инференса, так и низкую задержку. Объединение Vera Rubin NVL72 с Groq 3 LPX как раз и формирует гетерогенную архитектуру, сочетающую производительность крупномасштабной ИИ-фабрики с быстрой генерацией токенов. Vera Rubin NVL72 с Groq 3 LPX обеспечивают более высокую пропускную способность при более высоких уровнях интерактивности — в 35 раз быстрее по сравнению с системами Grace Blackwell NVL72 при 400 TPS на пользователя.

С платформой Vera Rubin ИИ-предприятия могут получать до пяти раз больше дохода на МВт по сравнению с GB200 NVL72 и до 10 раз — за счёт сопряжения Vera Rubin NVL72 с LPX для наиболее чувствительных к задержкам и высокопроизводительных интерактивных рабочих нагрузок, таких как агентное кодирование и мультиагентные системы. LPX предоставляет ЦОД возможность развернуть выделенный канал интерактивного инференса с низкой задержкой наряду с Vera Rubin NVL72 в рамках общей инфраструктуры.
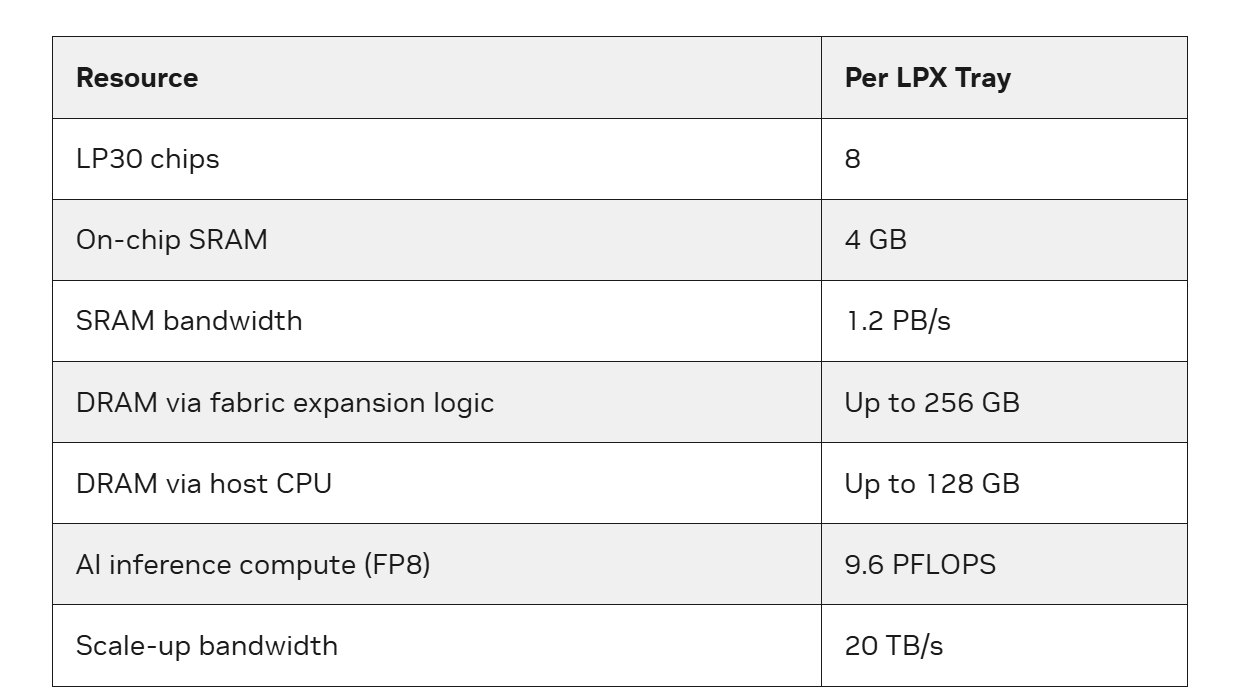
160-КВт стоечный суперускоритель NVIDIA Groq 3 LPX содержит 256 ИИ-чипов Groq 3 (LP30) с 96 млрд транзисторов в каждом — 32 узла высотой 1U с СЖО, объединяющих по восемь ускорителей LPU, x86 CPU, до 128 Гбайт RAM (возможно расширение до ещё плюс 256 Гбайт) и сетевые компоненты в бескабельной конструкции MGX, что упрощает развёртывание в стойке и обеспечивает тесную связь между вычислениями и коммуникацией. С2С-интерконнект RealScale обеспечивают прямую связь LPU внутри узла, между узлами и между стойками. На системном уровне LPX создан для использования в режимах инференса, где затраты на координацию и джиттер могут быстро стать заметными для пользователей.
ИИ-ускоритель NVIDIA Groq 3 (LP30)
NVIDIA Groq 3 LPU разработан для обеспечения быстрой и предсказуемой генерации токенов за счёт тесного взаимодействия вычислений, памяти и обмена данными под управлением компилятора. Вместо оптимизации для достижения максимальной арифметической производительности LPU делает упор на детерминированное выполнение, высокую пропускную способность встроенной памяти и явное перемещение данных. Делая перемещение данных явным и программируемым, LPU позволяет перекрывать операции доступа к памяти, вычисления и обмен данными, не полагаясь на аппаратную эвристику и скрывая задержки.

Определяющей характеристикой LPU является детерминизм. В отличие от обычных процессоров, где динамическое планирование, поведение кеша и конкуренция за доступ к памяти вносят вариативность во время выполнения, LPU работают без вариативности, и каждый функциональный блок работает синхронно. Этот детерминизм достигается за счёт удаления аппаратных блокировок и переноса принятия всех решений на плечи компилятора. Компилятор использует плезиохронный C2C-протокол, который устраняет естественный дрейф таймингов и настраивает сотни ускорителей LPU так, чтобы они действовали как единая скоординированная система. Такая модель исполнения обеспечивает:
- Точную координацию между памятью и вычислениями.
- Явный контроль времени выполнения команд.
- Снижение джиттера при переменных рабочих нагрузках.
- Стабильную задержку времени до первого токена и задержку получения каждого последующего токена даже при малой нагрузке.
Как отметил ресурс Storagereview, по своей сути, LPU — это очень большой векторный процессор. Фундаментальной единицей как вычислений, так и обмена данными является 320-элементный вектор (320 байт INT8, 640 байт FP16). Каждая операция на чипе, будь то арифметическая операция, доступ к памяти, преобразование данных или межчиповая передача, выполняется с этими векторами фиксированного размера, что упрощает планирование и синхронизацию.

Чип включает исполнительные модули для разных классов операций:
- Матричный модуль (MXM) обеспечивают возможность плотного умножения и накопления для тензорных операций, работающих с фиксированными типами данных с предсказуемой пропускной способностью. Каждый из 8 чипов Groq 3 LP30 обеспечивает до 1,2 Пфлопс (FP8), что в сумме даёт до 9,6 Пфлопс (FP8) на один узел LPX или до 315 Пфлопс (согласно спецификациям NVIDIA) на стойку.
- Векторный модуль (VXM) отвечает за поточечную арифметику, преобразование типов и функции активации. VXM содержит массив АЛУ, которые компилятор автоматически объединяет в цепочки для формирования составных операций (например, редукция, затем активация, затем приведение типов) за один проход.
- Коммутационный модуль (SXM) выполняет структурированное перемещение и преобразование данных, включая перестановку, вращение и транспонирование векторов.
Центральным элементом LPU является блок MEM с плоской архитектурой памяти на основе SRAM — без кешей, иерархии и понятия промаха как такового, в котором 500 Мбайт SRAM служит в качестве основного рабочего хранилища с пропускной способностью 150 Тбайт/с. Вместо того чтобы полагаться на аппаратно управляемые кеши, компилятор и среда выполнения помещают активный рабочий набор, включая веса, активации и состояние KV, во встроенную память и явно перемещают данные. Это уменьшает непредсказуемые задержки и помогает обеспечить низкую и стабильную задержку, сохраняя наиболее чувствительные к задержке данные доступными для вычисления. Компилятор напрямую обращается к физическим адресам банков памяти, зная точное положение всех данных на протяжении всего выполнения расчёта.
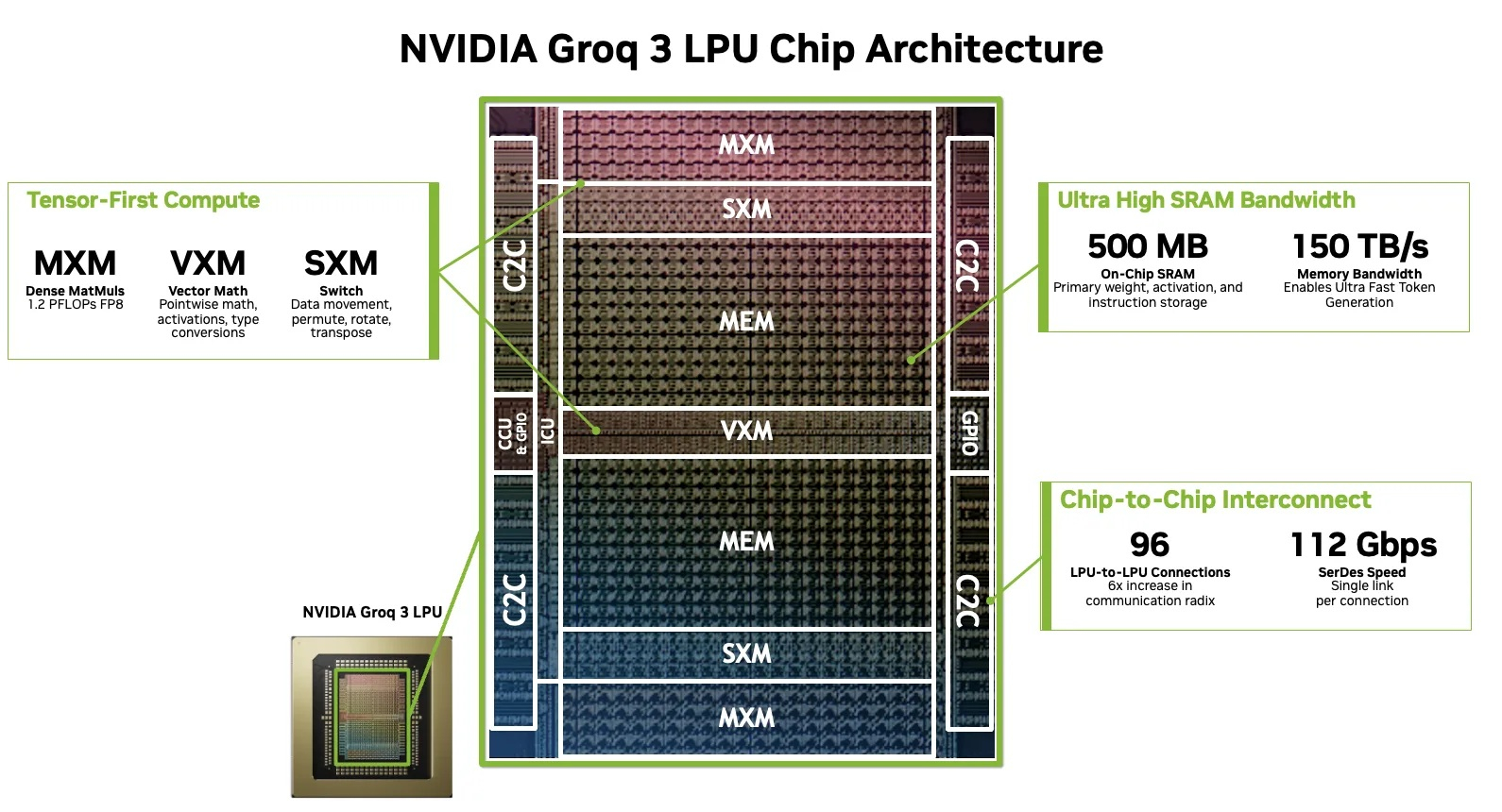
Для масштабирования LPU используют высокоскоростные C2C-каналы, предназначенные для детерминированного обмена данными. Каждый LPU имеет 96 каналов RealScale C2C, работающих на скорости 112 Гбит/с каждый, что обеспечивает оптимизированную топологию масштабирования LPX с совокупной двунаправленной пропускной способностью 2,5 Тбайт/с и предсказуемым временем передачи данных. Это особенно важно для конвейеров распределённого инференса, где в противном случае потери пропускной способности могут стать основным источником задержки. Из этих 96 каналов каждого LPU по 4 канала выделено для межстоечного взаимодействия (32 линка на узел, 14 Тбайт/с на стойку). Остальные линки уходят на All-to-All подключения внутри узла (Dragonfly) и между узлами — более 20 Тбайт/с на узел и 640 Тбайт/с на стойку.

При этом важно отметить, что Groq RealScale в корне отличается от интерконнекта NVLink. Последний является кеш-когерентным и объединяет CPU и GPU, тогда как RealScale обеспечивает программно-планируемое, детерминированное, точечное соединение. Сетевые каналы явно управляются компилятором, т.е. нет никакой адаптивной маршрутизации, а пакеты не содержат заголовков источника/назначения. Каналы синхронизированы по фазе и работают с фиксированной задержкой. Для связи с остальным компонентами предлагаются более традиционное 400GbE-подключение, а также один ConnectX-9 SuperNIC или DPU BlueField-4.
Инференс
NVIDIA отметила, что инференс вовсе не единообразная рабочая нагрузка. Предварительное заполнение и декодирование в рамках запроса предъявляют различные требования к оборудованию, и эти требования меняются в зависимости от объёма одновременно обрабатываемых данных, длины контекста и структуры модели. Некоторые этапы, включая механизмы внимания и разреженные MoE, могут стать очень чувствительными к пропускной способности памяти и перемещению данных, в то время как другие эффективно масштабируются на оборудовании с оптимизированной пропускной способностью при наличии достаточного параллелизма. При интерактивном декодировании многие операции выполняются с очень небольшими объёмами данными, что делает задержку гораздо более чувствительной к зависаниям, конфликтам и джиттеру.
Нет смысла оптимизировать весь конвейер только для одного режима. Гетерогенная система сочетает в себе оба подхода, обеспечивая интерактивную производительность с низкой задержкой и высокую производительность ИИ-фабрики. В результате получилась архитектура с двумя движками: GPU обеспечивают высокую производительность при предварительном заполнении с учётом контекста и выполнении декодирования с учётом внимания, в то время как LPU ускоряют чувствительные к задержкам компоненты декодирования, такие как исполнение FFN/MoE, обеспечивая специализированный путь, оптимизированный для быстрой генерации токенов.
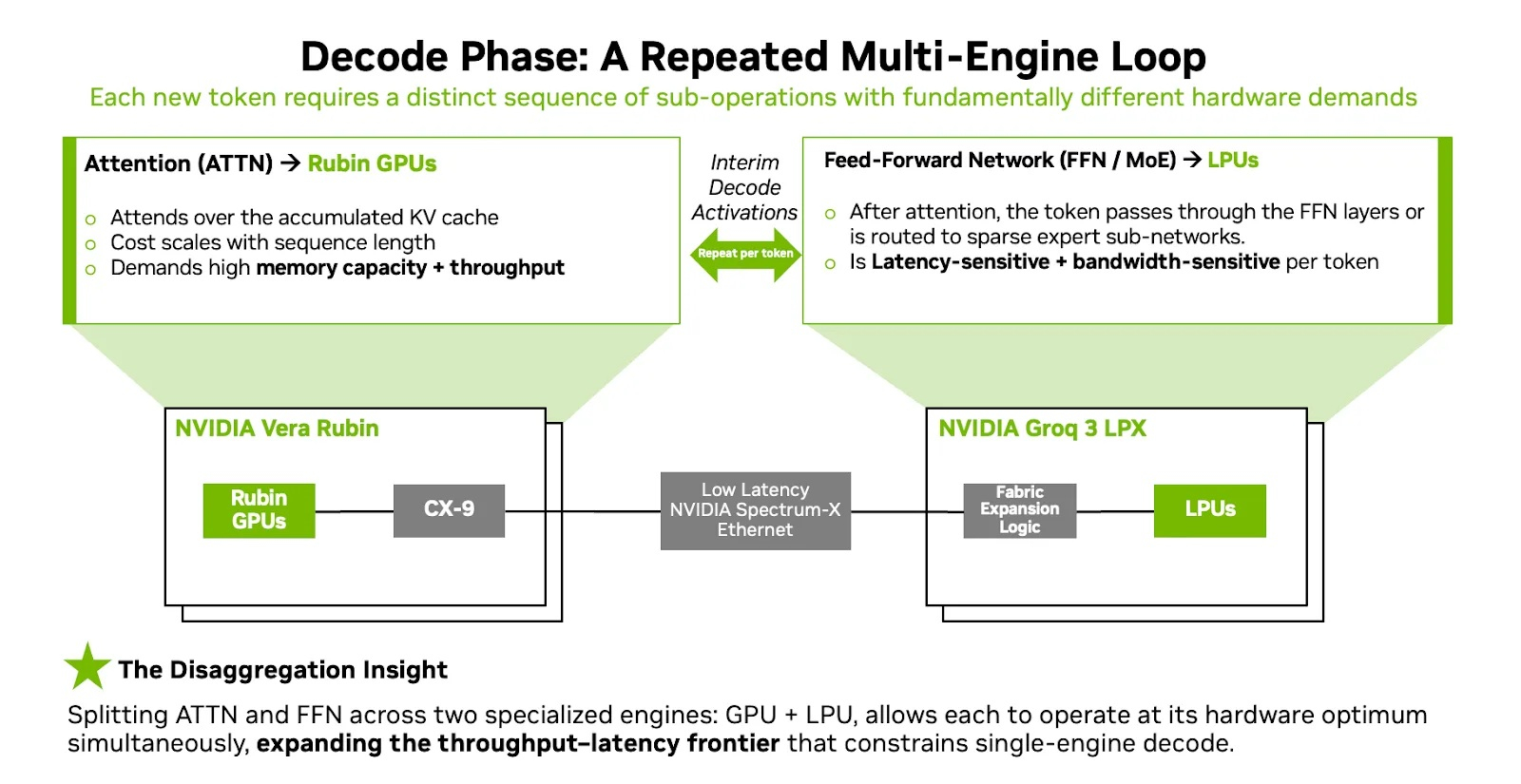
На этапе предварительного заполнения основное внимание уделяется обработке больших входных данных и созданию KV-кеша рабочей нагрузки, которая выигрывает от плотных параллельных вычислений и большого объёма памяти. Vera Rubin NVL72 эффективно справляется с этим этапом, особенно для рабочих нагрузок с длительным контекстом и MoE-моделей, когда контекст может быть большим и сильно меняться. В свою очередь, декодирование — повторяющийся цикл для каждого токена, и в разных фазах этого цикла могут быть разные узкие места.
GPU выполняют работу по декодированию, которая в наибольшей степени выигрывает от пропускной способности и большого объёма памяти, например, от полнотекстового доступа к накопленному KV-кешу. В свою очередь, LPX ускоряет выполнение операций декодирования, чувствительных к задержкам, таких как FFN/MoE и другие поточечные операции. Это разделение, часто называемое фазовой дезагрегацией декодирования или дезагрегацией внимания и FFN (AFD), отделяет механизм внимания от FFN (Feed-Forward Networks) в рамках декодирования и обменивается промежуточными активациями для каждого токена, поэтому каждый движок выполняет ту часть цикла, для которой он лучше всего подходит.
На практике это означает, что с ростом размера контекстного окна GPU «абсорбируют» всё возрастающие объёмы накопленных данных и всё усложняющиеся вычисления над ними, тогда как нагрузка на LPU остаётся постоянной. Это позволяет решить ключевую проблему всех ИИ-ускорителей, опирающихся на SRAM — фиксированный и очень небольшой объём памяти. Количество LPU, необходимых для обработки FFN-операций, теперь зависит только от архитектуры модели, а не от длины контекста.
NVIDIA Dynamo
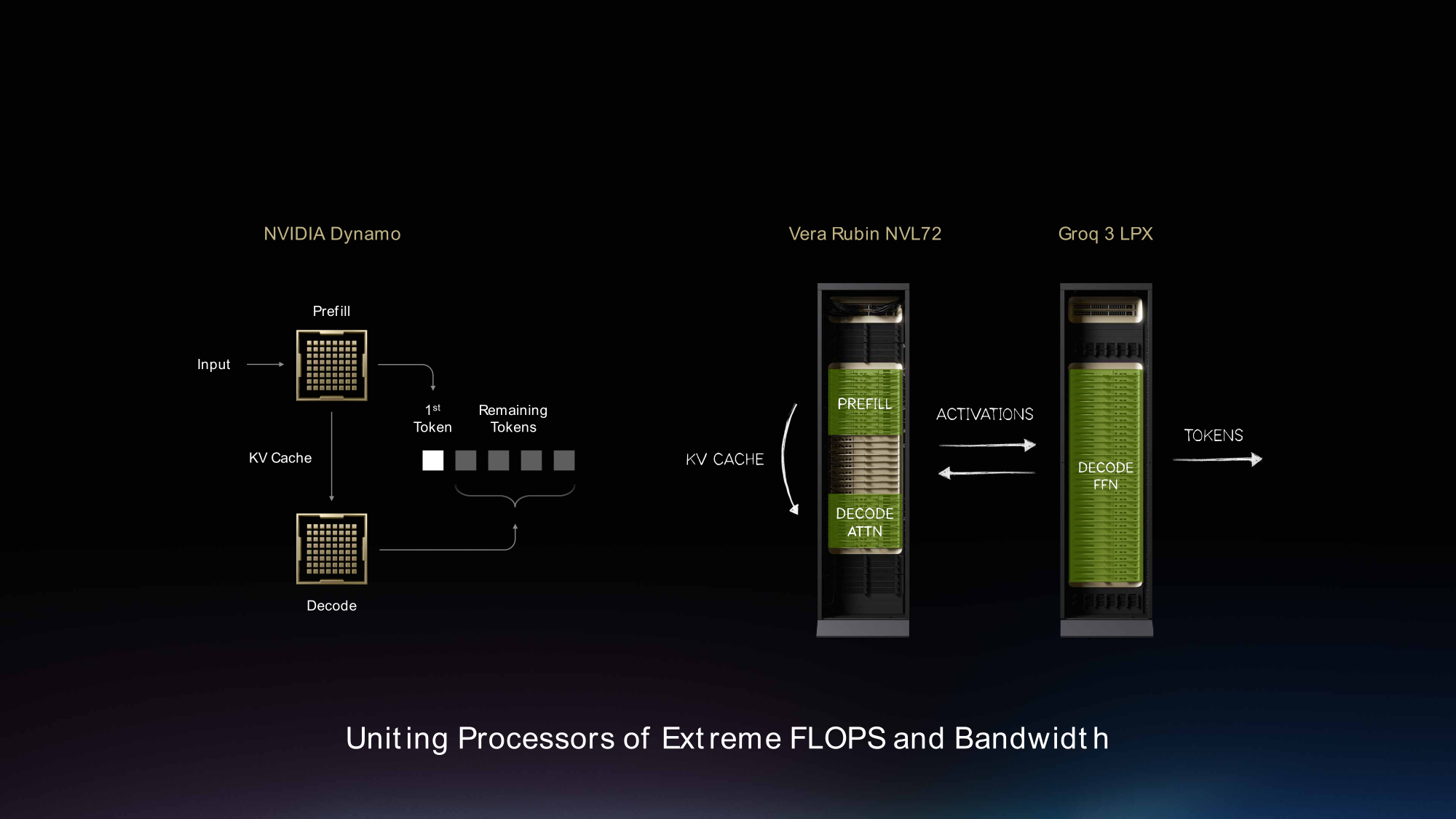
Для практического использования гетерогенного декодирования требуется ПО, которое может классифицировать запросы, распределять работу по целевым параметрам задержки, перемещать промежуточные активации с минимальными затратами и поддерживать стабильную конечную задержку при интенсивном и изменчивом трафике. NVIDIA Dynamo обеспечивает необходимый уровень оркестрации, координируя обслуживание запросов и декодирование, говорит NVIDIA.
Dynamo направляет данные в рамках предзаполнения GPU для обработки большого контекста и создания KV-кеша. Во время декодирования Dynamo управляет циклом AFD, в котором обрабатыватся накопленный KV-кеш, промежуточные активации передаются в LPU для выполнения FFN/MoE, а выходные данные возвращаются в GPU для продолжения генерации токенов. В результате обеспечивается единый согласованный канал обслуживания, а не две разрозненные системы.
Dynamo также обеспечивает маршрутизацию с учётом состояния KV-кеша (запросы попадают на рабочие процессы, которые уже имеют соответствующий кеш), планирование на основе целевых значений задержки (чтобы интерактивные сессии не попадали в длинные очереди) и управление передачей данных. Благодаря этому Dynamo помогает избежать длинных очередей на интерактивные сеансы, уменьшает джиттер между клиентами и поддерживает стабильную конечную задержку при изменении параллелизма и формы запросов.

Всё более важным методом для сокращения задержек при инференсе LLM становится и спекулятивное декодирование. Этот подход использует уменьшенную черновую модель для заблаговременной генерации нескольких токенов-кандидатов, в то время как более крупная целевая модель параллельно проверяет эти токены. Когда прогнозы совпадают, можно получить сразу несколько готовых токенов, что значительно увеличивает количество эффективных токенов в секунду и сокращает задержку ответа.
В такой архитектуре LPX хорошо подходит для работы с черновиками. Детерминированная модель исполнения и высокая пропускная способность памяти SRAM обеспечивают быструю генерацию токенов-черновиков — позволяя черновой модели работать быстрее проверяющей, которая запускается на GPU. Такое разделение позволяет выполнять спекулятивное декодирование на разнородных процессорах, а не запускать генерацию черновиков и верификацию на одном и том же оборудовании.
Источники:

