NVIDIA неожиданно анонсировала чип Rubin CPX — GPU нового класса, спроектированный для масштабных задач ИИ-инференса и работы с моделями, использующими длинный контекст. Поставки решения планируется организовать в конце 2026 года.
Чип Rubin CPX выполнен в виде монолитного кристалла и оснащён 128 Гбайт памяти GDDR7. Заявленная ИИ-производительность достигает 30 Пфлопс в режиме NVFP4. Предусмотрены по четыре блока NVENC и NVDEC для кодирования и декодирования видеоматериалов. Новинка дополнит другие ускорители компании. Оркестрацией нагрузок будет заниматься платформа NVIDIA Dynamo, распределяющая нагрузки между подходящими для каждой задачи ускорителями.

Источник изображений: NVIDIA
Изделие Rubin CPX предназначено для использования вместе с Arm-процессорами Vera и ускорителями Rubin в составе новой стоечной платформы NVIDIA Vera Rubin NVL144 CPX. Эта система будет объединять 144 чипа Rubin CPX, 144 чипа Rubin и 36 процессоров Vera (88 кастомных 3-нм Arm-ядер). Говорится об использовании суммарно 100 Тбайт памяти с агрегированной пропускной способностью 1,7 Пбайт/с. Общая производительность на операциях NVFP4 — до 8 Эфлопс, что примерно в 7,5 раза больше по сравнению с системами NVIDIA GB300 NVL72. Задействована система жидкостного охлаждения. Кроме того, NVIDIA планирует выпуск двухстоечного решения, включающего стойку Vera Rubin NVL144 CPX и «обычную» стойку Vera Rubin NVL144.

«Платформа Vera Rubin ознаменует собой новый скачок производительности в области вычислений ИИ, предлагая как GPU следующего поколения Rubin, так и чип нового класса CPX. Это первый CUDA GPU, специально разработанный для ИИ с длинным контекстом, когда модели одновременно обрабатывают миллионы токенов», — отмечает Дженсен Хуанг (Jensen Huang), основатель и генеральный директор NVIDIA.
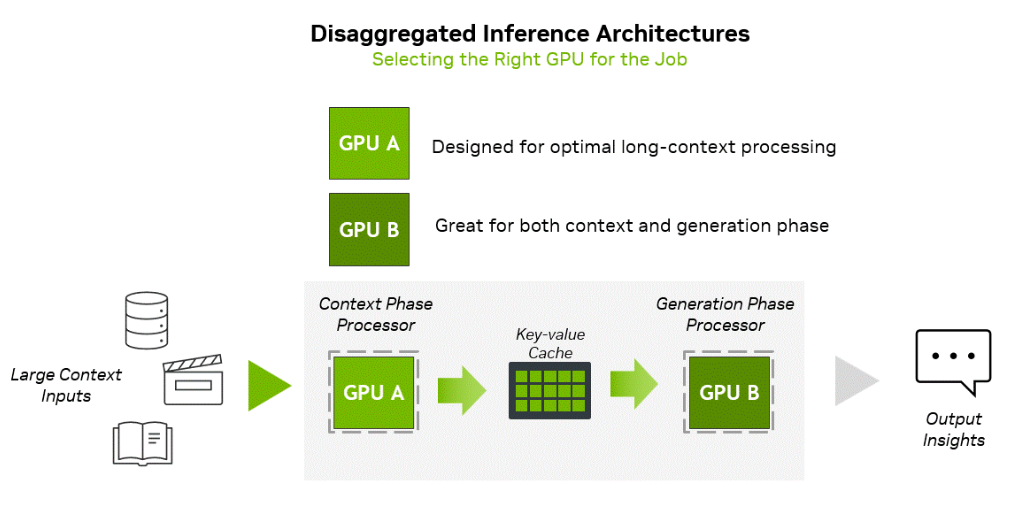
Основная задача Rubin CPX — работа с контекстом в больших моделях и создание KV-кеша. Эта операция ограничена вычислительными способностями чипа, тогда как генерация токенов зависит уже от пропускной способности памяти и интерконнекта для быстрого обмена данными. NVIDIA предложила разделить эти этапы и на аппаратном уровне. CPX лишён HBM, зато операции возведения в степень он делает втрое быстрее, чем Blackwell Ultra.

Источник:

