NVIDIA представила NVIDIA Dynamo, преемника NVIDIA Triton Inference Server — программную среду с открытым исходным кодом для разработчиков, обеспечивающую ускорение инференса, а также упрощающую масштабирование рассуждающих ИИ-моделей в ИИ-фабриках с минимальными затратами и максимальной эффективностью. Глава NVIDIA Дженсен Хуанг (Jensen Huang) назвал Dynamo «операционной системой для ИИ-фабрик».
NVIDIA Dynamo повышает производительность инференса, одновременно снижая затраты на масштабирование вычислений во время тестирования. Сообщается, что благодаря оптимизации инференса на NVIDIA Blackwell эта платформа многократно увеличивает производительность рассуждающей ИИ-модели DeepSeek-R1.

Источник изображений: NVIDIA
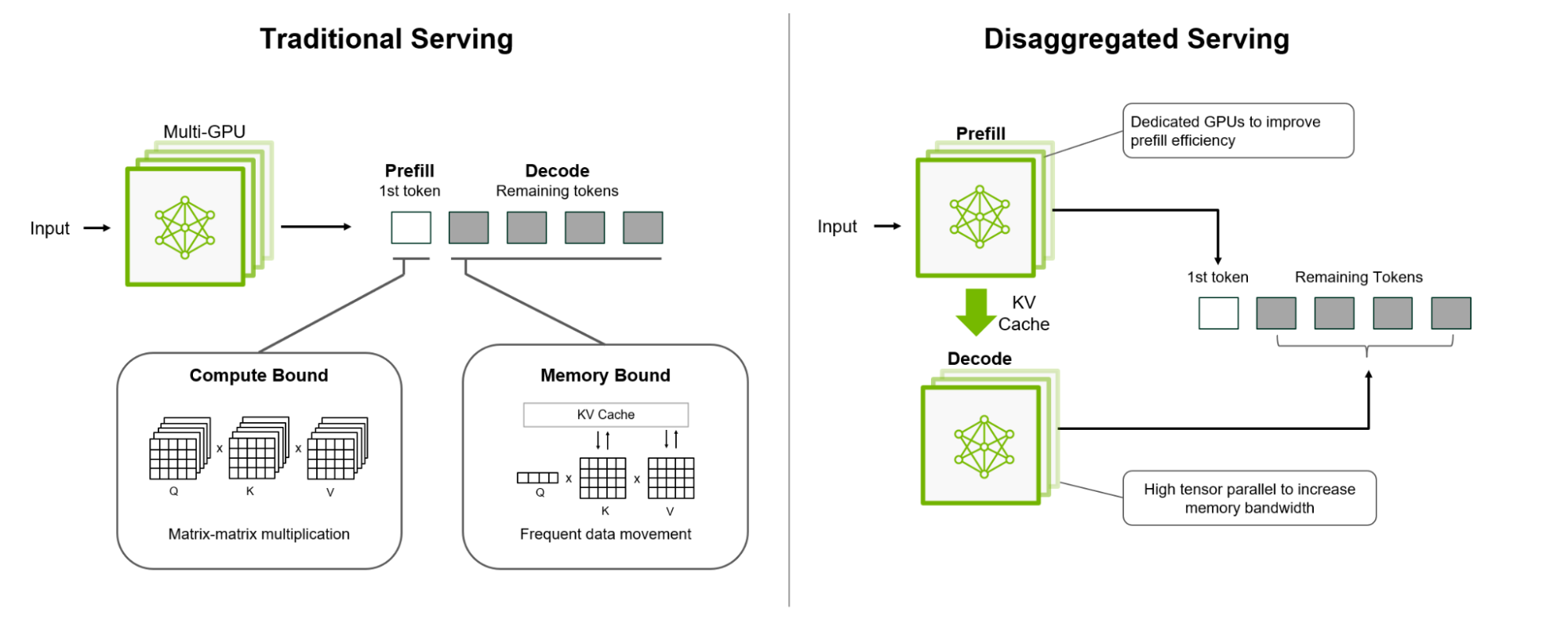
Платформа NVIDIA Dynamo, разработанная для максимизации дохода от токенов для ИИ-фабрик (ИИ ЦОД), организует и ускоряет коммуникацию инференса на тысячах ускорителей, и использует дезагрегированную обработку данных для разделения фаз обработки и генерации больших языковых моделей (LLM) на разных ускорителях. Это позволяет оптимизировать каждую фазу независимо от её конкретных потребностей и обеспечивает максимальное использование вычислительных ресурсов.
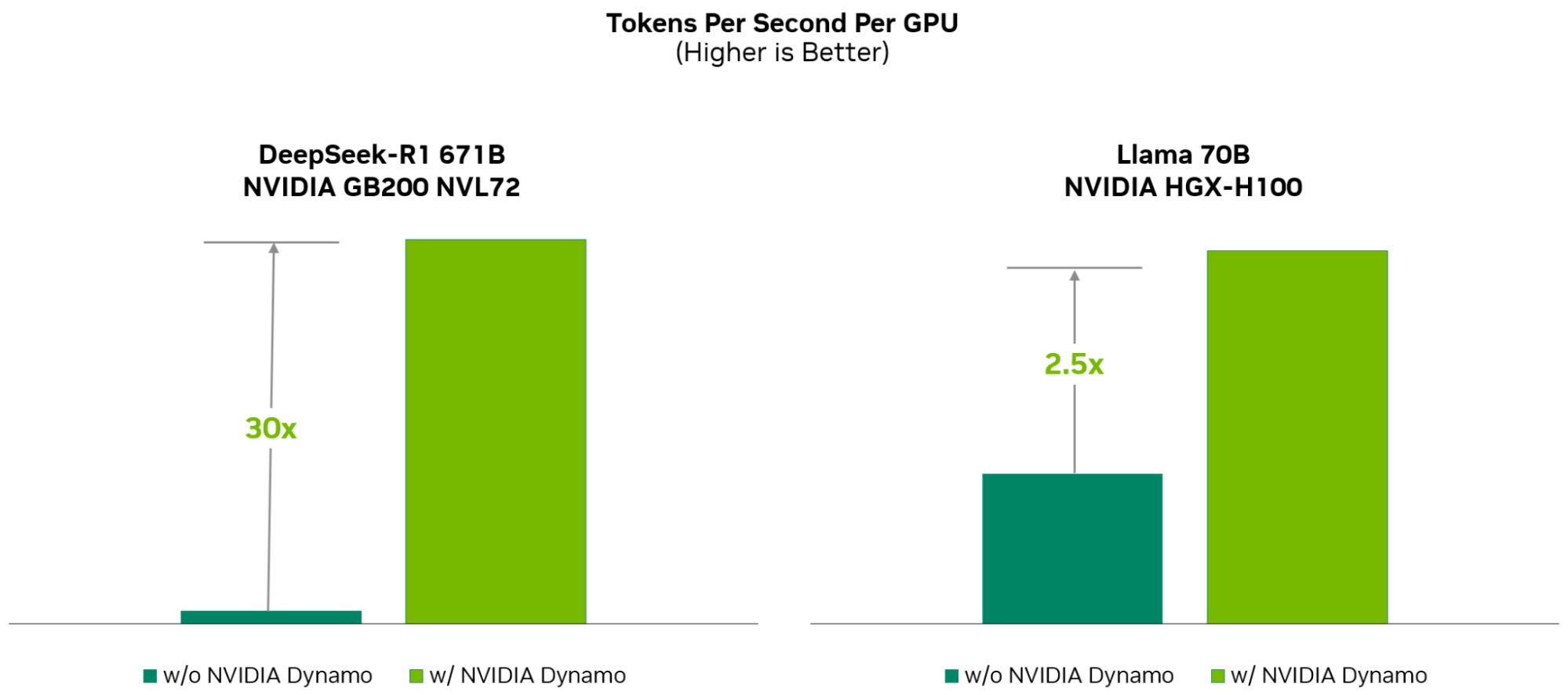
При том же количестве ускорителей Dynamo удваивает производительность (т.е. фактически доход ИИ-фабрик) моделей Llama на платформе NVIDIA Hopper. При запуске модели DeepSeek-R1 на большом кластере GB200 NVL72 благодаря интеллектуальной оптимизации инференса с помощью NVIDIA Dynamo количество генерируемых токенов на каждый ускоритель токенов увеличивается более чем в 30 раз, сообщила NVIDIA.
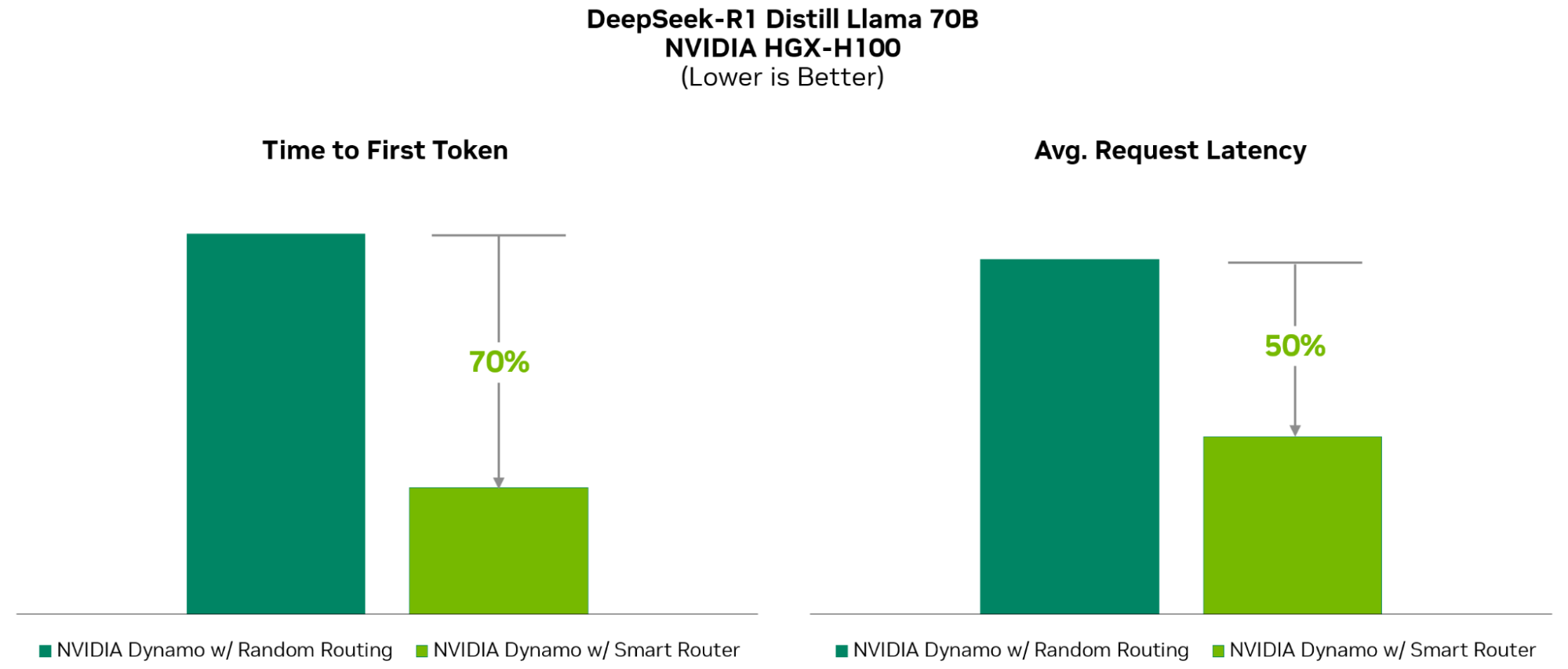
NVIDIA Dynamo может динамически перераспределять нагрузку на ускорители в ответ на меняющиеся объёмы и типы запросов, а также закреплять задачи за конкретными ускорителями в больших кластерах, что помогает минимизировать вычисления для ответов и маршрутизировать запросы. Платформа также может выгружать данные инференса в более доступную память и устройства хранения данных и быстро извлекать их при необходимости.
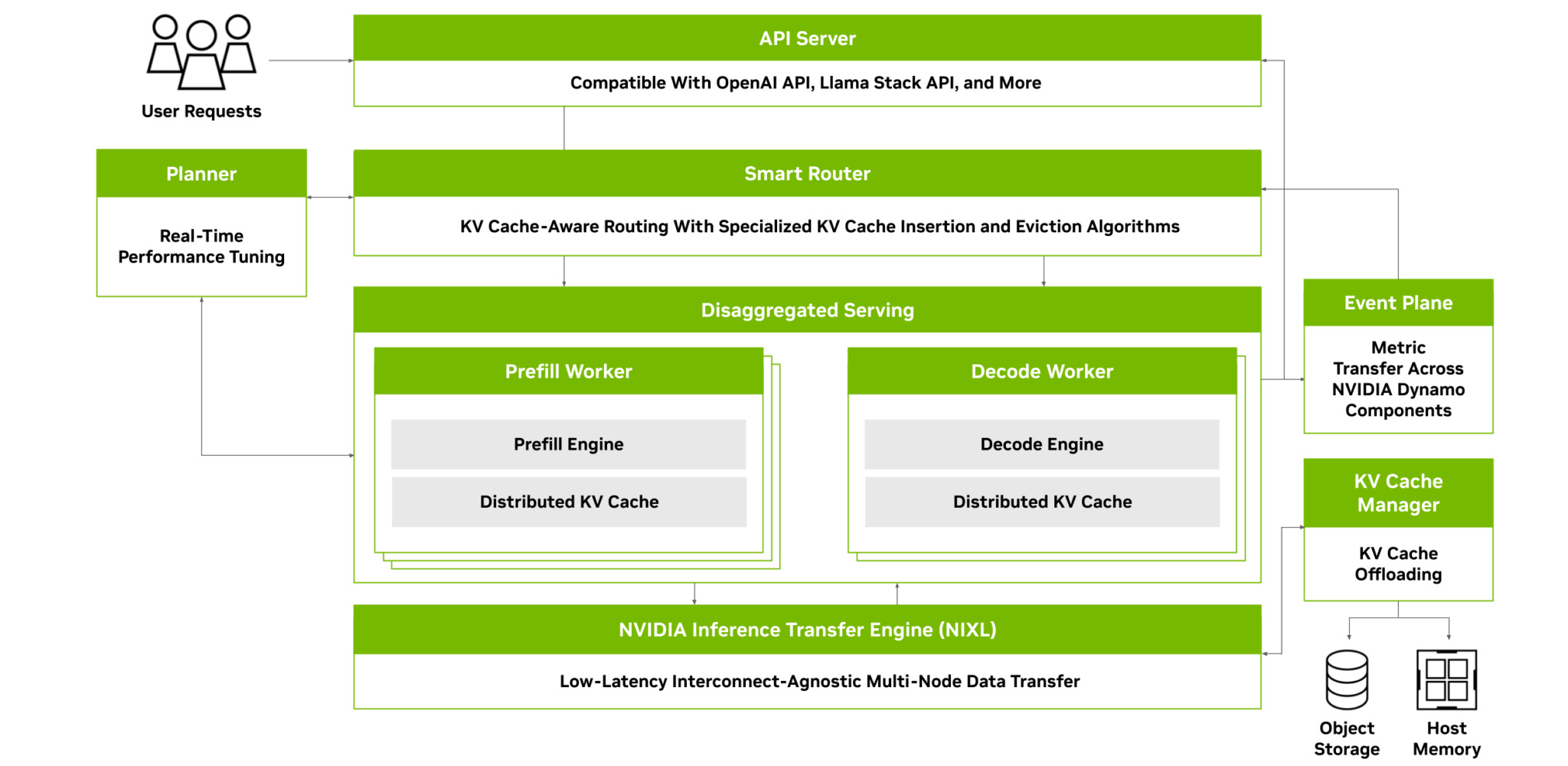
NVIDIA Dynamo имеет полностью открытый исходный код и поддерживает PyTorch, SGLang, NVIDIA TensorRT-LLM и vLLM, что позволяет клиентам разрабатывать и оптимизировать способы запуска ИИ-моделей в рамках дезагрегированного инференса. По словам NVIDIA, это позволит ускорить внедрение решения на различных платформах, включая AWS, Cohere, CoreWeave, Dell, Fireworks, Google Cloud, Lambda, Meta✴, Microsoft Azure, Nebius, NetApp, OCI, Perplexity, Together AI и VAST.
NVIDIA Dynamo распределяет информацию, которую системы инференса хранят в памяти после обработки предыдущих запросов (KV-кеш), на множество ускорителей (до тысяч). Затем платформа направляет новые запросы на те ускорители, содержимое KV-кеша которых наиболее близко к новому запросу, тем самым избегая дорогостоящих повторных вычислений.
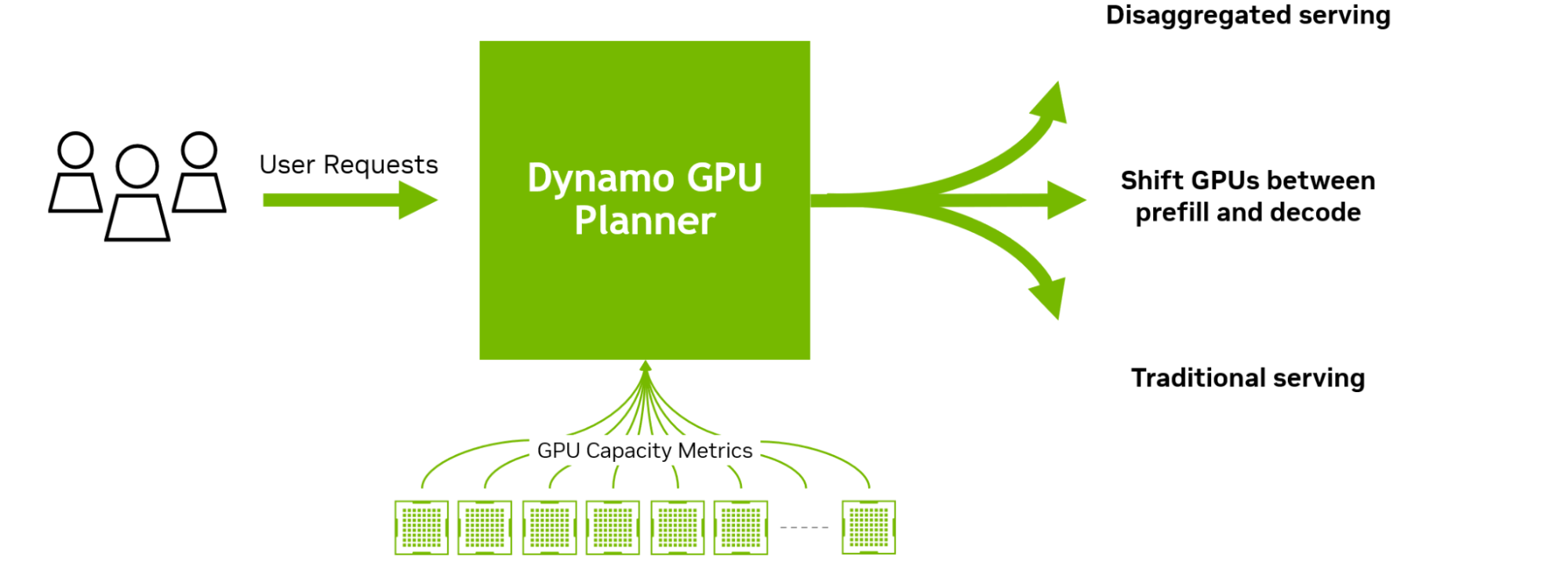
NVIDIA Dynamo также обеспечивает дезагрегацию обработки входящих запросов, которое отправляет различные этапы исполнения LLM — от «понимания» запроса до генерации — разным ускорителям. Этот подход идеально подходит для рассуждающих моделей. Дезагрегированное обслуживание позволяет настраивать и выделять ресурсы для каждой фазы независимо, обеспечивая более высокую пропускную способность и более быстрые ответы на запросы.
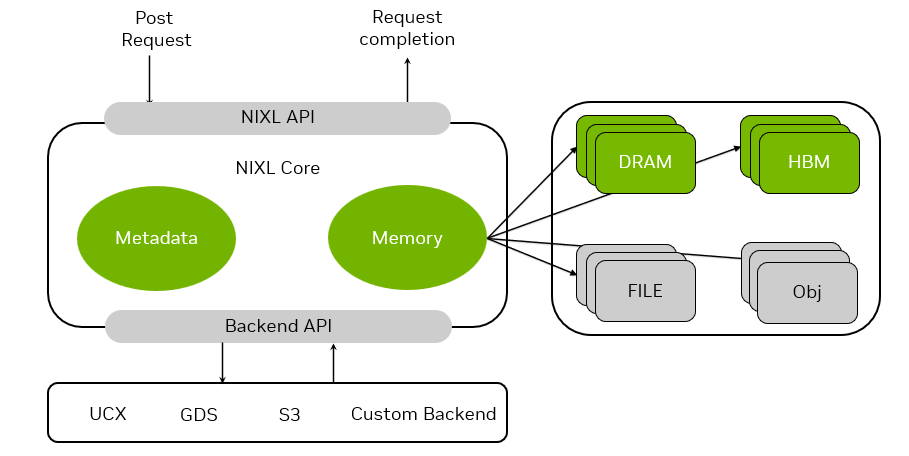
NVIDIA Dynamo включает четыре ключевых механизма:
- GPU Planner: механизм планирования, который динамически меняет количество ускорителей в соответствии с меняющимися запросами, устраняя возможность избыточного или недостаточного выделения ресурсов.
- Smart Router: маршрутизатор для LLM, который распределяет запросы по большим группам ускорителей, чтобы минимизировать дорогостоящие повторные вычисления повторяющихся или перекрывающихся запросов, высвобождая ресурсы для обработки новых запросов.
- Low-Latency Communication Library: оптимизированная для инференса библиотека, которая поддерживает связь между ускорителями и упрощает обмен данными между разнородными устройствами, ускоряя передачу данных.
- Memory Manager: механизм, который прозрачно и интеллектуально загружает, выгружает и распределяет данные инференса между памятью и устройствами хранения.
Платформа NVIDIA Dynamo будет доступна в микросервисах NVIDIA NIM и будет поддерживаться в будущем выпуске платформы NVIDIA AI Enterprise.
Источник:

