Материалы по тегу: nvme-of
|
24.04.2026 [11:05], Сергей Карасёв
Гибридная СХД TrueNAS V160 обеспечивает пропускную способность до 60 Гбайт/сКомпания TrueNAS (ранее — iXsystems) анонсировала гибридную систему хранения V160, предназначенную для задач ИИ, машинного обучения и работы с базами данных. Новинка позволяет формировать платформы с оптимальным сочетанием производительности и стоимости, что важно в условиях стремительного роста цен на SSD. СХД выполнена в форм-факторе 4U. Применены два контроллера TrueNAS пятого поколения на основе неназванного 32-ядерного процессора AMD EPYC с 768 Гбайт оперативной памяти DDR5 каждый. Доступны 24 отсека для NVMe SSD или SAS HDD вместимостью соответственно до 122,8 Тбайт и 26 Тбайт (7200 об/мин). Система позволяет задействовать до 24 Тбайт адаптивного кеша. Заявленная пропускная способность в зависимости от выбранной конфигурации достигает 60 Гбайт/с. Допускается подключение до шести дисковых полок с NVMe SSD или до четырнадцати полок с SAS HDD на 102 отсека, что позволяет создавать конфигурации, насчитывающие более 1400 накопителей. При использовании исключительно SSD суммарная вместимость может достигать 20 Пбайт, в случае HDD — 35 Пбайт. 
Источник изображения: TrueNAS Сетевые порты имеют следующую конфигурацию: 4 × 100/200GbE, 2 × 400GbE, 4 × FC16, 2 × FC32. Реализована поддержка протоколов SMBv2, SMBv3, NFSv3, NFSv4 w/RDMA, iSCSI, iSER, FC, NVMe-oF/RDMA, S3. Питание обеспечивают два блока с сертификатом 80 Plus Titanium, резервированием и возможностью горячей замены. Заявленная доступность СХД превышает 99,999 %. В качестве программной платформы применяется TrueNAS Enterprise 25.10 (используется файловая система OpenZFS). Доступны файловое, блочное и объектное хранилища со сжатием и дедупликацией. Говорится о совместимости с VMware, Proxmox, Hyper-V, Xen, OpenShift, Kubernetes.
19.03.2026 [12:01], Сергей Карасёв
NetApp выпустила СХД EF50 и EF80 типа All Flash для задач ИИКомпания NetApp анонсировала новые СХД семейства EF-Series, ориентированные на ресурсоёмкие нагрузки, в том числе на задачи ИИ, приложения HPC и транзакционные базы данных. Дебютировали модели EF50 и EF80 типа All Flash в форм-факторе 2U с возможностью установки 24 SSD (NVMe). Устройства оснащены двумя активными контроллерами. Говорится о поддержке Fibre Channel (FC), NVMe/RoCE, iSCSI1 и InfiniBand, а также параллельных файловых систем, таких как Lustre и BeeGFS. Возможно формирование массивов RAID 0/1/5/6/10. Развитые функции защиты данных и диагностические инструменты, по заявлениям NetApp, обеспечивают доступность более 99,9999 %. Старшая из двух новинок, EF80, располагает 64 Гбайт памяти на контроллер, 12 портами 200Gb NVMe/IB, NVMe/RoCE, 24 портами 64Gb NVMe/FC и 24 портами 64Gb SCSI FC. Заявленная максимальная скорость передачи данных при чтении составляет 110 Гбайт/с, при записи — 57 Гбайт/с. Показатель IOPS достигает 5 млн. Максимальное энергопотребление находится на уровне 1758 Вт, типовое — 1235 Вт. 
Источник изображения: NetApp Версия EF50 получила 32 Гбайт памяти на контроллер. Реализованы 16 портов 64Gb NVMe/FC и 16 портов 64Gb SCSI FC. Скорость при чтении — до 41 Гбайт/с, при записи — до 30 Гбайт/с. Величина IOPS составляет до 1,7 млн. Максимальное энергопотребление равно 1451 Вт, типовое — 1041 Вт. Обе СХД обеспечивают внутреннюю вместимость до 1,5 Пбайт, а энергоэффективность находится на отметке 63,7 Гбайт/с на кВт. Применяется программная платформа SANtricity OS 12.0; при этом обеспечивается совместимость с клиентскими ОС Windows Server, Linux и macOS.
27.02.2026 [09:59], Сергей Карасёв
Nimbus Data представила универсальную All-Flash СХД FlashMaxКомпания Nimbus Data анонсировала платформу хранения FlashMax класса All-Flash, разработанную для современных дата-центров с высокими нагрузками. Решение позволяет одновременно использовать блочные, файловые и объектные хранилища данных в одной системе, что упрощает построение разнородной инфраструктуры и повышает эффективность. В семейство FlashMax вошли модели F500, F700 и F900. Все они оснащены двумя контроллерами с возможностью горячей замены. Реализована поддержка протоколов NVMe-oF (TCP и RoCEv2), iSCSI, Fibre Channel, NFS, SMB, AFP, FTP, TFTP и S3. Упомянуты такие функции, как дедупликация, сжатие, контрольные суммы и аппаратное шифрование. В составе устройств применяются стандартные накопители NVMe SSD в SFF-формате. Модель FlashMax F500 стандарта 2U рассчитана на 24 накопителя суммарной вместимостью до 3 Пбайт. Возможно подключение одного модуля расширения E240 (также 2U), который также может комплектоваться 24 SSD. Таким образом, суммарная «сырая» ёмкость достигает 6 Пбайт, эффективная — 30 Пбайт. Показатель IOPS составляет до 2,2 млн, пропускная способность — до 30 Гбайт/с. Доступны следующие сетевые интерфейсы: 2 × 10GbE SFP+ и 3 × 100GbE или 6 × 25GbE или 4 × FC32. 
Источник изображения: Nimbus Data Вариант FlashMax F700 типоразмера 2U в базовом исполнении рассчитан на 24 накопителя, но может использовать до четырёх полок E240 (в сумме до 120 SSD). «Сырая» вместимость — до 15 Пбайт, эффективная — до 75 Пбайт. Значение IOPS достигает 6,8 млн, пропускная способность — 100 Гбайт/с. Предусмотрены два порта 10GbE, а также 4 × 400GbE или 8 × 200GbE или 16 × FC64. Старшая версия, FlashMax F900, содержит базовый узел 2U и два дополнительных 2U-модуля, а максимальная конфигурация включает до шести модулей E240. В сумме это даёт до 168 SSD с общей «сырой» ёмкостью до 21 Пбайт и эффективной вместимостью до 100 Пбайт. Прочие характеристики аналогичны модели FlashMax F700. В устройствах применяется технология DirectLink — интерконнект на базе PCIe, который напрямую соединяет модули расширения с контроллерами ввода-вывода. Это обеспечивает высокую производительность и минимизирует задержки. Диапазон рабочих температур простирается от +5 до +40 °C. Клиентам предоставляется круглосуточная поддержка в режиме 24/7/365, а срок гарантии достигает 10 лет.
11.02.2026 [16:48], Владимир Мироненко
All-Flash СХД IBM FlashSystem 5600, 7600 и 9600 получили автономное ИИ-управлениеIBM представила системы хранения данных FlashSystem класса All-Flash следующего поколения 5600, 7600 и 9600, которые, как утверждается, обеспечивают до 40 % большую эффективность обработки данных, ёмкость и производительность по сравнению с предыдущим поколением. Компания назвала выход сразу трёх новых систем самым значительным обновлением FlashSystem за последние шесть лет. IBM сообщила, что расширяя существующие возможности FlashSystem с помощью агентного ИИ, она переосмысливает отказоустойчивость за счёт постоянной защиты, автономного анализа угроз и индивидуальных рекомендаций по восстановлению. Генеральный директор IBM Storage Сэм Вернер (Sam Werner) описывает новую FlashSystem как постоянно доступный интеллектуальный слой, использующий автономных ИИ-агентов для повышения производительности, безопасности и снижения затрат. Он отметил, что IBM позиционирует этот релиз как шаг к созданию СХД, которая будет служить стратегическим партнёром по ИИ для ИТ-руководителей, а не статическим хранилищем, требующим постоянного ручного контроля. 
Источник изображений: IBM FlashSystems — это классические двухконтроллерные массивы, работающие под управлением ОС SAN Volume Controller и поддерживающие блочное хранение данных. В новых системах установлен флеш-накопитель пятого поколения FlashCore Module ёмкостью до 105,6 Тбайт, разработанный для обеспечения аппаратного ускорения обнаружения программ-вымогателей в реальном времени, сокращения объёма данных, аналитики и управления, с расширенной телеметрией и стабильно низкой задержкой. Система FlashSystem 5600 ориентирована на организации, которым требуются функции корпоративного класса в компактном форм-факторе. Заявлена эффективная ёмкостью до 2,5 Пбайт, пропускная способность до 30 Гбайт/с и производительность до 2,6 млн IOPS (чтение 4K-блоками) в одном 1U-шасси. Узел включает два 12-ядерных Intel Xeon и 256 или 512 Гбайт RAM. Общее количество IO-портов не превышает 16: 10/25/40/100GbE с поддержкой iSCSI и NVMe/TCP или FC32/64 с NVMe/FC (такие же опции и у старших моделей). Система разработана для развёртывания в условиях ограниченного пространства, таких как периферийные узлы, удалённые офисы и небольшие ЦОД.  IBM FlashSystem 7600 предназначена для высокопроизводительных масштабируемых сред с растущими рабочими нагрузками, обеспечивает до 7,2 Пбайт эффективной ёмкости в одной системе форм-фактора 2U, 55 Гбайт/с и до 4,3 млн IOPS. 7600 предназначена для работы с большими виртуализированными средами, аналитическими платформами и консолидированными приложениями, требующими большей ёмкости и более быстрого отклика. Узел содержит два 16-ядерных AMD EPYC и 768 Гбайт или 1,5 Тбайт RAM. IBM FlashSystem 9600 создана для критически важных операций, требующих экстремальной производительности и максимальной масштабируемости, обеспечивает до 11,8 Пбайт эффективной ёмкости в одной системе форм-фактора 2U, до 86 Гбайт/с и до 6,3 млн IOPS. Количество портов — до 32. Узлы включают два 48-ядерных AMD EPYC и 1,5 или 3 Тбайт RAM. Типичные сценарии использования системы включают основные банковские системы, ERP-платформы и приложения на основе ИИ, требующие скорости и расширенной безопасности. По данным компании, использование FlashSystem 9600 позволяет снизить эксплуатационные расходы на 57 % за счёт ИИ и консолидации по сравнению с предыдущим поколением.  IBM сообщила, что IBM FlashSystem уменьшает требуемый объём хранилища на 30–75 % в зависимости от модели за счёт оптимизированного размещения и консолидации по сравнению с предыдущим поколением. У FlashSystem 7600 и 9600 есть интерактивные светодиодные панели, позволяющие отслеживать состояние системы. IBM также представила FlashSystem.ai, новый набор интеллектуальных сервисов обработки данных на основе ИИ, предназначенных для управления, мониторинга, диагностики и решения проблем на всём пути передачи данных. FlashSystem.ai обеспечивает бесперебойную работу в режиме самообслуживания, автоматизируя ручные и подверженные ошибкам задачи. Благодаря модели, обученной на десятках миллиардов точек данных, собранных с помощью расширенной телеметрии и многолетнего опыта реального работы с данными, платформа может выполнять тысячи автоматизированных решений в день, которые ранее требовали человеческого контроля.  Помимо автоматизации, IBM подчеркивает адаптивное поведение СХД. Функции агентного ИИ позволяют понимать шаблоны приложений в течение нескольких часов, объяснять свои рассуждения и учитывать отзывы администраторов для улучшения предложений с течением времени. В последних FlashSystem, по утверждению IBM, FlashSystem.ai может сократить время, затрачиваемое на документацию по аудиту и соответствию требованиям, вдвое благодаря объяснимым рассуждениям ИИ. Системы разработаны для проактивной настройки и интеллектуального размещения рабочих нагрузок, обеспечивая беспрепятственное перемещение данных между конфигурациями хранения, включая массивы сторонних производителей. IBM также утверждает, что ее новый метод обнаружения угроз, обученный на десятках миллиардов точек телеметрических данных, может снизить количество ложных срабатываний до менее 1 %. Компания также заявила, что платформа, используя FlashCore, может обеспечить обнаружение программ-вымогателей и оповещение с помощью ИИ менее чем за 60 с, а также выполнить автономные действия по восстановлению на аппаратном уровне.
21.01.2026 [13:03], Сергей Карасёв
Dell представила All-Flash СХД PowerStore 5200Q для QLC SSDКомпания Dell расширила ассортимент СХД серии PowerStore, анонсировав модель 5200Q типа All-Flash. Новинка позволяет сформировать интеллектуальное хранилище, обеспечивающее ускорение работы с блочными, файловыми и виртуальными томами. Устройство выполнено на аппаратной платформе Intel. Применены два контроллера, функционирующие в режиме «активный — активный». В общей сложности задействованы четыре неназванных процессора Xeon с 96 вычислительными ядрами, работающими на частоте 2,2 ГГц. Объём оперативной памяти составляет 1152 Гбайт. СХД имеет типоразмер 2U. Во фронтальной части расположены 25 отсеков для SFF-накопителей NVMe. Могут применяться SSD на основе чипов памяти QLC вместимостью 15,36 и 30,72 Тбайт. Питание обеспечивают два блока с резервированием. В общей сложности могут быть использованы до 24 сетевых Front-end-портов в следующей конфигурации: 16 × FC16/32, 24 × 10GbE, 24 × 10/25GbE или 8 × 100GbE. Секция Back-end включает порты 100GbE QSFP. Кроме того, предусмотрен выделенный сетевой порт управления 1GbE. Говорится о поддержке протоколов FC, NVMe/FC, iSCSI, NVMe/TCP, NFSv3/4/4.1/4.2; CIFS SMB 2/3.0/3.02/3.1.1, FTP и SFTP.  В связке с СХД могут функционировать до трёх модулей расширения формата 2U, рассчитанных на 24 накопителя SFF (NVMe) каждый. Таким образом, в общей сложности система с учётом устройств расширения может содержать до 93 накопителей SFF и четыре изделия NVRAM. В составе кластера количество SSD может достигать 372 штук при суммарной вместимости 23,6 Пбайт с учётом компрессии. В качестве программной платформы применяется PowerStore OS.
24.11.2025 [09:09], Сергей Карасёв
IBM утроила вместимость СХД Storage Scale System 6000 — до 47 Пбайт на стойкуКорпорация IBM объявила о выпуске обновлённой СХД Storage Scale System 6000, предназначенной для работы с ресурсоёмкими ИИ-приложениями, а также с нагрузками, которым требуется интенсивный обмен большими объёмами информации. Платформа Storage Scale System 6000 дебютировала в конце 2024 года. Устройство типоразмера 4U оснащено двумя контроллерами, работающими в режиме «активный — активный». Применяются процессоры AMD EPYC Genoa 7642 (48C/96T; 2,3–3,3 ГГц; 225 Вт) или EPYC Embedded 9454 (48C/96T; 2,75–3,8 ГГц; 290 Вт), а максимальный объём оперативной памяти в расчёте на систему составляет 3072 Гбайт. Допускается установка 48 NVMe-накопителей. Также поддерживаются фирменные FCM-модули со сжатием на лету. Вместимость оригинальной версии достигала 2,2 Пбайт (при использовании комбинации SSD на 30 и 60 Тбайт). При подключении девяти дополнительных JBOD-массивов показатель вырастал до 15 Пбайт. Заявленная производительность — до 13 млн IOPS. Пропускная способность при чтении — до 330 Гбайт/с, при записи — до 155 Гбайт/с. 
Источник изображения: IBM В случае обновлённой модификации Storage Scale System 6000 реализована поддержка QLC-накопителей вместимостью до 122 Тбайт. Кроме того, представлены новые модули расширения All-Flash Expansion Enclosure стандарта 2U, рассчитанные на 26 двухпортовых накопителей QLC. В результате, общая ёмкость СХД в конфигурации в виде стойки 42U достигает 47 Пбайт, что примерно втрое больше по сравнению с оригинальным вариантом. При этом быстродействие поднялось до 28 млн IOPS, а пропускная способность в режиме чтения — до 340 Гбайт/с. В состав All-Flash Expansion Enclosure входят DPU NVIDIA BlueField-3 (до 4 шт.). Каждый модуль расширения может обеспечить пропускную способность до 100 Гбайт/с. Решение оптимизировано для обучения больших языковых моделей, инференса, НРС-задач и пр. В продажу изделие поступит в декабре; тогда же станет доступно улучшенное ПО для СХД — IBM Storage Scale System 7.0.0.
01.10.2025 [15:40], Владимир Мироненко
YADRO анонсировала поддержку NVMe over TCP — более доступной и производительной альтернативы FC и iSCSIКомпания YADRO объявила о предстоящем выходе технологии NVMe over TCP (Non-Volatile Memory Express с транспортным протоколом TCP), которая станет доступна с осенним релизом v3.2 СХД TATLIN.UNIFIED. Новое решение YADRO позволяет снизить задержки, увеличить производительность и достигнуть максимальной простоты работы с данными. Уже сейчас его можно протестировать в режиме предварительного доступа. Компания отметила, что работа по протоколу Fibre Channel (FC) становится сложнее из-за выросшей стоимости использования и сложности обслуживания оборудования, в то время как протокол iSCSI часто не отвечает требованиям задач бизнеса из-за ограничений по производительности и проблем с надёжностью и отказоустойчивостью. Согласно данным внутреннего тестирования, при использовании NVMe/TCP ускорение операций ввода-вывода по сравнению с FC составило до 30 %, сокращение задержек — 25 %. По сравнению с iSCSI новое решение обеспечивает производительность выше на 62 %. NVMe over TCP снижает нагрузку на операционную систему, упрощает процесс обнаружения изменений в хранилище и легко интегрируется с ОС на базе ядра Linux, позволяя оптимизировать скорость работы с ресурсоёмкими задачами и высоконагруженными корпоративными приложениями. Встроенная функция многопутевого ввода-вывода (Native NVMe Multipath) обеспечивает стабильную работу даже при подключении тысячи ресурсов/логических томов. 
Источник изображения: YADRO Также следует отметить доступную стоимость внедрения и простоту эксплуатации новой технологии. Для перехода на неё с iSCSI не требуется дополнительное оборудование, а при переходе с FC компания предлагает заказчикам решение на базе сетевых коммутаторов KORNFELD, которые поддерживают NVMe/TCP и интегрированы с СХД TATLIN для построения единой end-to-end NVMe-инфраструктуры. В настоящее время YADRO ведёт проработку интеграции технологии с решениями технологических партнёров. Некоторые из них уже выпустили или готовят к выпуску в ближайшее время собственных решений с использованием NVMe over TCP. Компания отметила, что помимо NVMe/TCP в релизе 3.2 будет представлен целый ряд улучшений, включая поддержку LACP на виртуальных портах для файлового доступа, VLAN на виртуальных портах для блочного и файлового доступа и Root squash для файловых ресурсов. Также будут увеличены лимиты ресурсов на систему и повышена производительность и безопасность.
29.08.2025 [23:15], Владимир Мироненко
11,5 Пбайт в 2U: Novodisq представил блейд-сервер для ИИ и больших данныхСтартап Novodisq представил блейд-сервер формата 2U ёмкостью 11,5 Пбайт с функцией ускорения ИИ и др. задач. Гиперконвергентная кластерная система разработан для замены или дополнения традиционных решений NAS, SAN и публичных облачных сервисов. Новинка поддерживает платформы Ceph, MinIO и Nextcloud (также планируется поддержка DAOS), предлагая доступ по NFS, iSCSI, NVMe-oF и S3. Сервер содержит до 20 модулей Novoblade с фронтальной загрузкой. В каждом из них имеется до четырёх встроенных E2 SSD Novoblade объёмом 144 Тбайт каждый, на базе TLC NAND с шиной PCIe 4.0 x4. Накопители поддерживают NVMe v2.1 и ZNS, обеспечивая последовательную производительность чтения/записи до 1000 Мбайт/с, а на случайных операциях — до 70/30 тыс. IOPS. Надёжность накопителей составляет до 24 PBW. Энергопотребление: от 5 до 10 Вт. Система Novoblade предназначена для «тёплого» и «холодного» хранения данных. Модули Novoblade объединяют вычислительные возможности, ускорители и хранилища. Основной модулей являются гибридные SoC AMD Versal AI Edge Gen 2 (для ИИ-нагрузок) или Versal Prime Gen 2 (для традиционных вычислений) c FPGA, 96 Гбайт DDR5, 32 Гбайт eMMC, модулем TPM2 и двумя интерфейсам 10/25GbE с RoCE v2 RDMA и TSN. Энергопотребление не превышает 60 Вт. Есть функции шифрования накопителей, декодирования видео, ускорения ИИ-обработки, оркестрации контейнеров и т.д. Платформа специально разработана для задач с большими объёмами данных, таких как геномика, геопространственная визуализация, видеоархивация и периферийные ИИ-вычисления. Сервер может работать под управлением стандартных дистрибутивов Linux (RHEL и Ubuntu LTS) с поддержкой Docker, Podman, QEMU/KVM, Portainer и OpenShift. 
Источник изображений: Novodisq 2U-шасси глубиной 1000 мм рассчитано на установку до двадцати модулей Novodisq и оснащено двумя (1+1) БП мощностью 2600 Вт каждый (48 В DC). Возможно горизонтальное масштабирование с использованием каналов 100–400GbE. В базовой конфигурации шасси включает четыре 200GbE-модуля с возможностью горячей замены, каждый из которых имеет SFP28-корзины, а также управляемый L2-коммутатор. Предусмотрен набор средств управления, включая BMC с веб-интерфейсом, CLI и поддержкой API Ansible, SNMP и Redfish. Novoblade поддерживает локальное и удалённое управление, может интегрироваться в существующий стек или предоставляться с помощью инструментов «инфраструктура как код» (Infrastructure-as-Code).  По словам разработчика, система Novoblade обеспечивает плотность размещения примерно в 10 раз выше, чем у сервера на основе жестких дисков, и снижает энергопотребление на 90–95 % без необходимости в механическом охлаждении. Novodisq утверждает, что общая стоимость владения системой «обычно на 70–90 % ниже, чем у традиционных облачных или корпоративных решений в течение 5–10 лет».  «Это обусловлено несколькими факторами: уменьшенным пространством в стойке, низким энергопотреблением, отсутствием платы за передачу данных, минимальным охлаждением, длительным сроком службы и значительным упрощением управления. В отличие от облака, ваши расходы в основном фиксированы, а значит, предсказуемы, и, в отличие от традиционных систем, Novodisq не требует дорогостоящих лицензий, внешних контроллеров или постоянных циклов обновления. Вы получаете высокую производительность, долгосрочную надёжность и более высокую экономичность с первого дня», — приводит Blocks & Files сообщение компании.  Для сравнения, узлы Dell PowerScale F710 и F910 на базе 144-Тбайт Solidigm SSD ёмкостью 122 Тбайт, 24 отсеками в 2U-шасси и коэффициентом сжатия данных 2:1 обеспечивают почти 6 Пбайт эффективной емкости, что почти вдвое меньше, чем у сервера Novoblade.
04.06.2025 [09:44], Сергей Карасёв
YADRO представила All-Flash СХД Tatlin.AFAРоссийская компания YADRO представила высокопроизводительную систему хранения данных Tatlin.AFA, предназначенную для решения задач крупных корпоративных клиентов. Утверждается, что это первое в России решение типа All-NVMe с возможностью установки SSD с интерфейсом PCIe 4.0/5.0 и поддержкой End-to-end NVMe. Устройство выполнено в форм-факторе 2U и оснащено двумя контроллерами в режиме Symmetric Active–Active. Каждый из контроллеров оборудован двумя процессорами Intel Xeon поколения Emerald Rapids. Объём памяти DDR5 ECC составляет 1,5 Тбайт. Предусмотрены дублированные батареи для обеспечения сохранности данных в кеше. СХД располагает 24 отсеками для NVMe SSD стандарта U.2 / U.3 вместимостью до 30 Тбайт каждый, что в сумме даёт до 720 Тбайт «сырой» ёмкости. Кроме того, могут быть подключены два модуля расширения S24N, каждый из которых также содержит два двухпроцессорных контроллера, 24 слота для накопителей и два 200GbE-порта с RocE. Таким образом, общая вместимость в конфигурации с двумя модулями S24N превышает 2 Пбайт. Заявленное быстродействие на операциях ввода/вывода в секунду (IOPS) составляет более 2 млн, а пропускная способность достигает 50 Гбайт/с. Поддерживаются протоколы FC, iSCSI, NVMe/TCP, NVMe/RoCE. Заявлена совместимость с VMWare Sphere 7.x / 8.x, «РЕД ОС Виртуализация», «Альт Сервер Виртуализация», ECP Veil / SE, zVirt 3.x / 4.x, «Горизонт ВС», BASIS (DE), ОС Windows Server 2016/2019/2022, Oracle Linux 7.x/8.x/9.x, Rocky Linux 9.x, SUSE Linux 12/15, Ubuntu Server, IBM AIX 7.2 / 7.3 (VIOS), Astra Linux 1.x, «РЕД ОС» 7.3/7.3.1/8.0, «Альт Сервер». 
Источник изображения: YADRO В зависимости от конфигурации доступны до 16/32 портов 10/25GbE, до 16 портов 100GbE или до 20 портов FC16/32/64. Предусмотрены пять слотов PCIe 5.0 x16 для сетевых адаптеров. Установлены два блока питания мощностью 3200 Вт с резервированием 1+1, поддержкой горячей замены и аккумуляторным модулем. Диапазон рабочих температур простирается от +10 до +30 °C. Упомянута собственная технология T-RAID с поддержкой различных схем защиты, резервирования компонентов и моментальных снимков. Реализованы следующие уровни защиты T-RAID: 8 + 1, 8 + 2, 8 + 3, 8 + 4, 8 + 5, 8 + 6, 8 + 7, 8 + 8, 10 + 1, 10 + 2, 10 + 3, а также 14 + 1 и 14 + 2. Использует программная платформа Tatlin.OS.
16.04.2025 [13:01], Сергей Карасёв
Pure Storage анонсировала младшую All-Flash СХД FlashArray//RC20 для периферийных развёртыванийКомпания Pure Storage анонсировала СХД FlashArray//RC20 типа All-Flash, оптимизированную для сравнительно небольших рабочих нагрузок и периферийных развёртываний. Новинка, как утверждается, предлагает такие преимущества, как энергетическая эффективность, гибкость, безопасность и отказоустойчивость. Решение выполнено в форм-факторе 3U. Суммарная «сырая» вместимость установленных накопителей может варьироваться от 148 до 260 Тбайт, тогда как эффективная ёмкость с дедупликацией и сжатием достигает 918 Тбайт. Реализована поддержка NVME-oF (Fibre Channel, RoCE, TCP). Платформа использует б/у контроллеры, которые прошли проверку и обновление у Pure Storage. По заявлениям Pure Storage, система FlashArray//RC20 обеспечивает экономию физического пространства до 95 % по сравнению с гибридными массивами на основе SSD и HDD. Потребление энергии может быть снижено на 85 % по отношению к конкурирующим изделиям All-Flash. 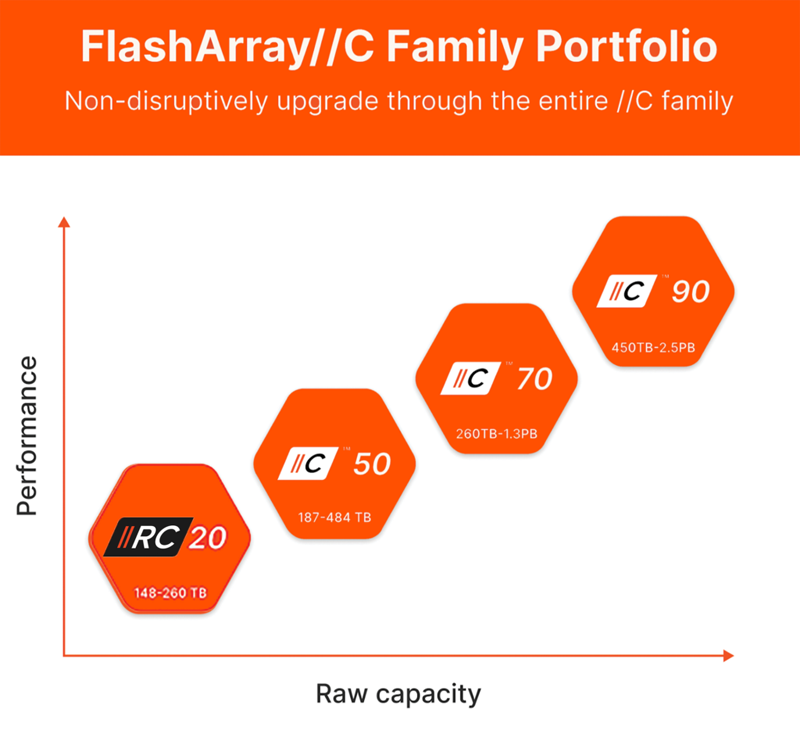
Источник изображения: Pure Storage Pure Storage предлагает набор решений по кибербезопасности, включая специализированные инструменты на основе ИИ и асинхронную репликацию. По умолчанию активированы средства SafeMode, определяющие ряд политик для защиты данных. В частности, неизменяемые снимки SafeMode предотвращают уничтожение информации даже в случае компрометации учётных данных администратора. Заявленное пиковое энергопотребление составляет 720–888 Вт. Компания Pure Storage подчёркивает, что в отличие от других систем начального уровня, FlashArray//RC20 может быть обновлена до более мощных версий в семействе FlashArray//C без необходимости прерывания работы. В целом, новинка предлагает экономичный вариант миграции с гибридных СХД на платформы All-Flash. |
|

