Материалы по тегу: nvme-of
|
10.04.2025 [11:27], Сергей Карасёв
SSD с «хвостиком»: Kioxia представила «оптические» SSD для дата-центров следующего поколенияКомпании Kioxia, AIO Core и Kyocera объявили о разработке прототипа SSD с оптическим интерфейсом, совместимого с PCIe 5.0. Изделие ориентировано на дата-центры следующего поколения, рассчитанные на ресурсоёмкие нагрузки, включая приложения ИИ с высокой интенсивностью обмена данными. О разработке «оптических» твердотельных накопителей Kioxia сообщала в августе прошлого года. Речь идёт об использовании оптического интерфейса подключения вместо традиционного электрического. Новый подход позволяет устранить влияние посторонних электромагнитных помех. При этом длина соединения может достигать 40 м с последующим увеличением до 100 м. В представленном прототипе SSD задействованы оптический трансивер IOCore разработки AIO Core и технология оптоэлектронной интеграции Optinity компании Kyocera. Реализованная оптическая система, как утверждается, позволяет устройству функционировать на скоростях интерфейса PCIe 5.0. 
Источник изображения: Kioxia Разработка «оптического» SSD осуществляется в рамках японского проекта JPNP21029 «Развитие технологий зелёных центров обработки данных следующего поколения». Он субсидируется Организацией по развитию новых энергетических и промышленных технологий (NEDO). Цель инициативы заключается в сокращении энергопотребления ЦОД более чем на 40 % по сравнению с нынешними площадками. В рамках проекта Kioxia отвечает за SSD нового типа, тогда как AIO Core и Kyocera создают оптоэлектронные компоненты. Предполагается, что появление «оптических» SSD откроет новые возможности в плане проектирования дата-центров. Представленная технология позволит значительно увеличить физическое расстояние между вычислительными и запоминающими устройствами, обеспечивая при этом энергоэффективность и высокое качество сигнала.
02.04.2025 [18:50], Сергей Карасёв
QSAN представила СХД серии XN5 типа All-NVMe с процессорами Intel XeonКомпания QSAN Technology анонсировала системы хранения данных (СХД) семейства XN5, предназначенные для работы с ресурсоёмкими нагрузками, связанными с ИИ, машинным обучением, виртуализацией и другими вычислительными процессами. Устройства выполнены в форм-факторе 2U на аппаратной платформе Intel. Новинки относятся к решениям All-NVMe: они рассчитаны на работу с SSD формата SFF U.2 с интерфейсом PCIe 4.0. Во фронтальной части предусмотрены 26 отсеков для таких накопителей, а суммарная внутренняя ёмкость может достигать 798 Тбайт. Поддерживается горячая замена SSD. Анонсированы модели XN5226D-12C и XN5226S-12C. Первая оснащена двумя контроллерами в режиме «активный — активный» с двумя неназванными 12-ядерными процессорами Xeon. В базовую комплектацию входят 32 Гбайт памяти DDR4 с возможностью расширения до 2 Тбайт. Также предусмотрены четыре слота расширения PCIe 4.0 x8, два порта 2.5GbE RJ45 и восемь портов 25GbE SFP28. Модификация XN5226S-12C, в свою очередь, оснащена одним контроллером, одним 12-ядерным процессором Xeon, 16 Гбайт ОЗУ (расширяется до 1 Тбайт), двумя слотами PCIe 4.0 x8, одним портом 2.5GbE RJ45 и четырьмя портами 25GbE SFP28. 
Источник изображения: QSAN Technology Устройства могут комплектоваться адаптерами 10GbE SFP+, 10GbE RJ45, FC16 и FC32 с двумя или четырьмя портами. Поддерживается подключение модулей расширения с SFF SSD и LFF HDD с интерфейсом SAS: в максимальной конфигурации количество накопителей достигает 546 штук, а суммарная ёмкость — до 16,8 Пбайт. Возможно формирование массивов RAID 0/1/5/6/10/50/60/5EE/6EE/50EE/60EE. В качестве программной платформы используется QSM 4. Заявлена поддержка протоколов CIFS, NFS, FTP, WebDAV, iSCSI, FCP, NVMe-oF. За электропитание отвечают два блока мощностью 850 Вт с сертификатом 80 Plus Platinum. Охлаждение обеспечивается системой воздушного охлаждения. Габариты составляют 88 × 438 × 573 мм, масса — 19,6 кг (без установленных накопителей). На устройства предоставляется пятилетняя гарантия.
27.03.2025 [09:11], Алексей Степин
Seagate представила свежие прототипы NVMe HDDSeagate представила своё видение СХД для ИИ-фабрик. Компания отмечает, что объёмы данных, используемых при обучении современных моделей, огромны и, согласно Seagate, хранить их целиком на флеш-массивах невыгодно для большинства предприятий и стартапов. Ответом являются гибридные массивы, сочетающие флеш-память и традиционную дисковую механику. Идея таких СХД не нова сама по себе, но реализация, предлагаемая Seagate, лишена атавизмов — проприетарных контроллеров, преобразования протоколов и всего прочего, на чём держится традиционная инфраструктура SAS/SATA. Основой новой архитектуры станет стандарт NVMe с единым драйвером, который вкупе со средствами ОС позволит слаженно работать SSD и HDD. Это важное отличие от уже имеющихся решений, например, от StorONE, где HDD действительно могут быть использованы в составе хранилища NVM-oF, но подключаются они всё равно по SAS/SATA. На уровне отдельных механических дисков сам по себе переход на NVMe выигрыша не принесёт, поскольку ограничивающим фактором останется время поиска дорожки, но на уровне массива с поддержкой GPUDirect и NVMe-oF выигрыш будет существенным. NVMe-oF упростит масштабирование таких систем и позволит реализовать распределённую архитектуру хранения данных в полной мере, отмечает Blocks & Files. 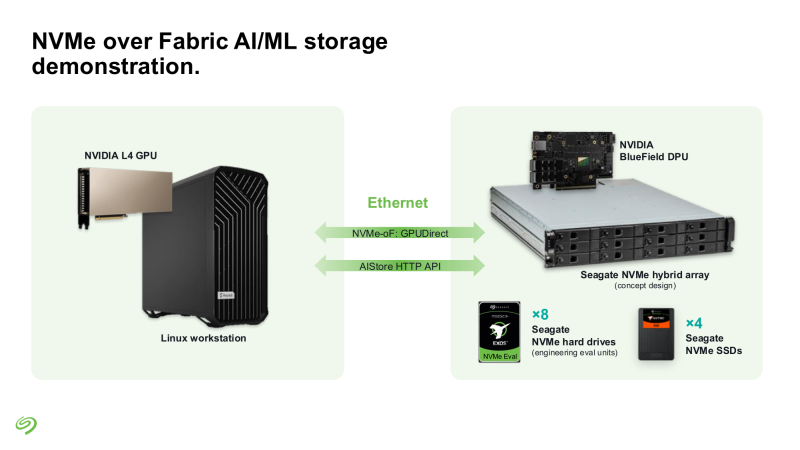
Источник изображений: Seagate Гибридные массивы в этой схеме напрямую подключаются к GPU-серверам. За счёт агрегации доступа ко множеству накопителей скорость может быть существенно увеличена (о чём говорила когда-то и Toshiba), а простота подключения будет достигнута за счёт единого стандарта — NVMe. В новых массивах предусмотрено место для DPU, благодаря которым и будет реализована поддержка RDMA и GPUDirect. На конференции NVIDIA GTC 2025 Seagate уже продемонстрировала прототип такого массива на базе BlueField-3 и MiniIO AIStore v2.0. 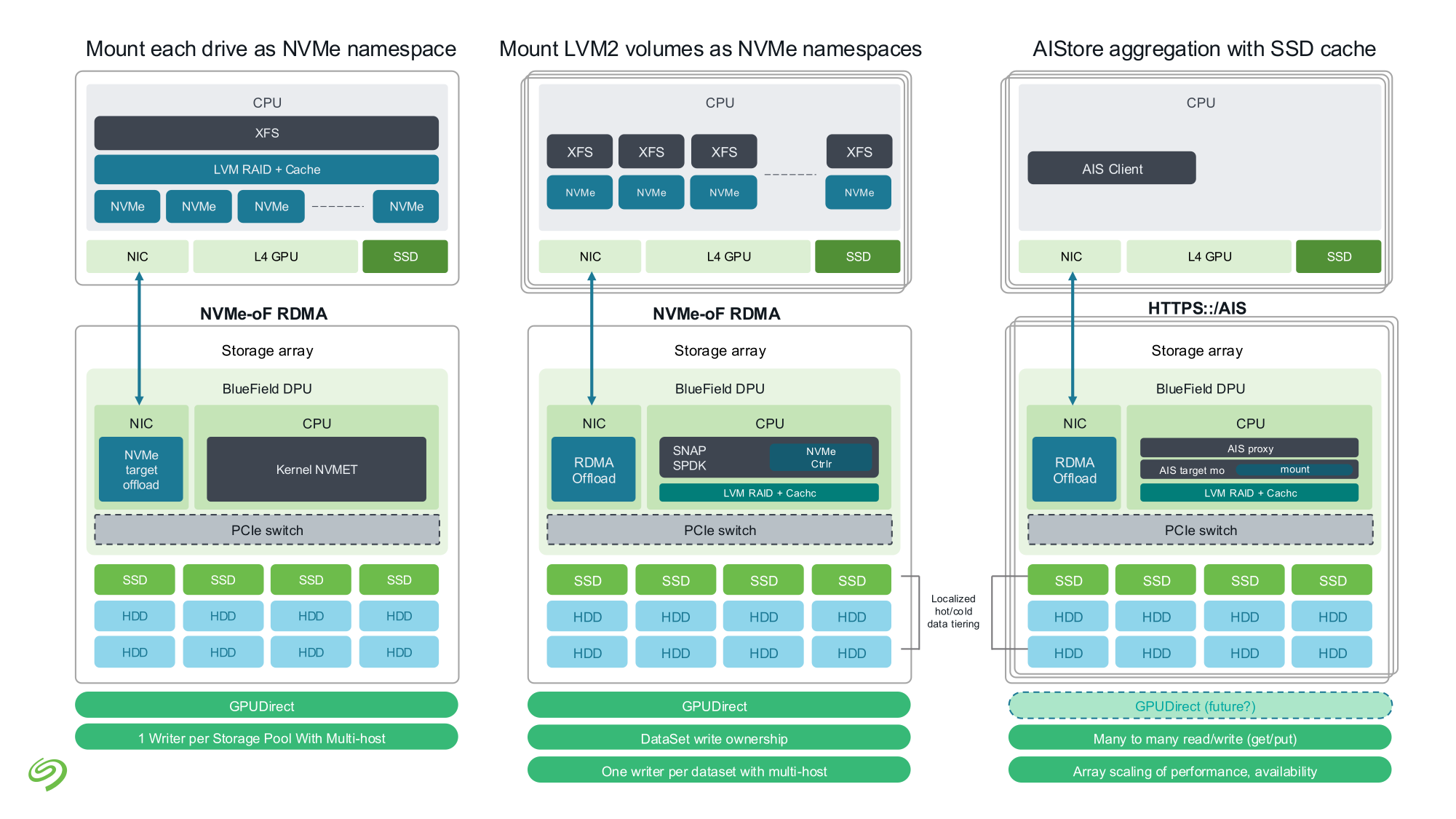 Данный прототип был оснащён восемью инженерными образцами NVMe HDD и четырьмя NVMe SSD. Даже будучи на уровне концепта, он показал, что прямое сообщение между ускорителями и подсистемой хранения данных позволяет снизить латентность доступа в ИИ-сценариях. Также благотворное влияние на производительность при обучении ИИ-моделей оказывает применение средств динамического кеширования и иерархизации (tiering). 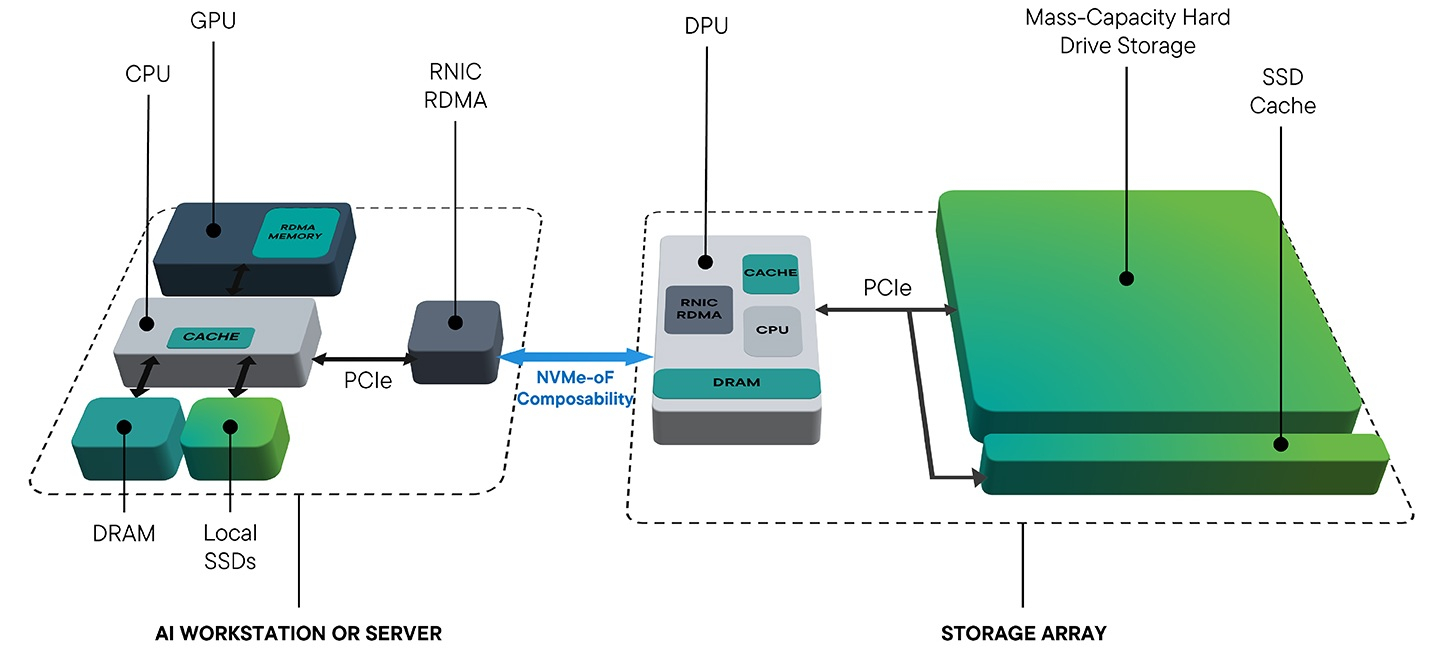 Seagate считает, что у традиционных жёстких дисков с интерфейсом NVMe есть большое будущее, и они найдут своё место во многих отраслях, от медицины и финансовой аналитики до самоуправляемого транспорта и ИИ-фабрик гиперскейлеров. В сравнении с SSD называются следующие преимущества:
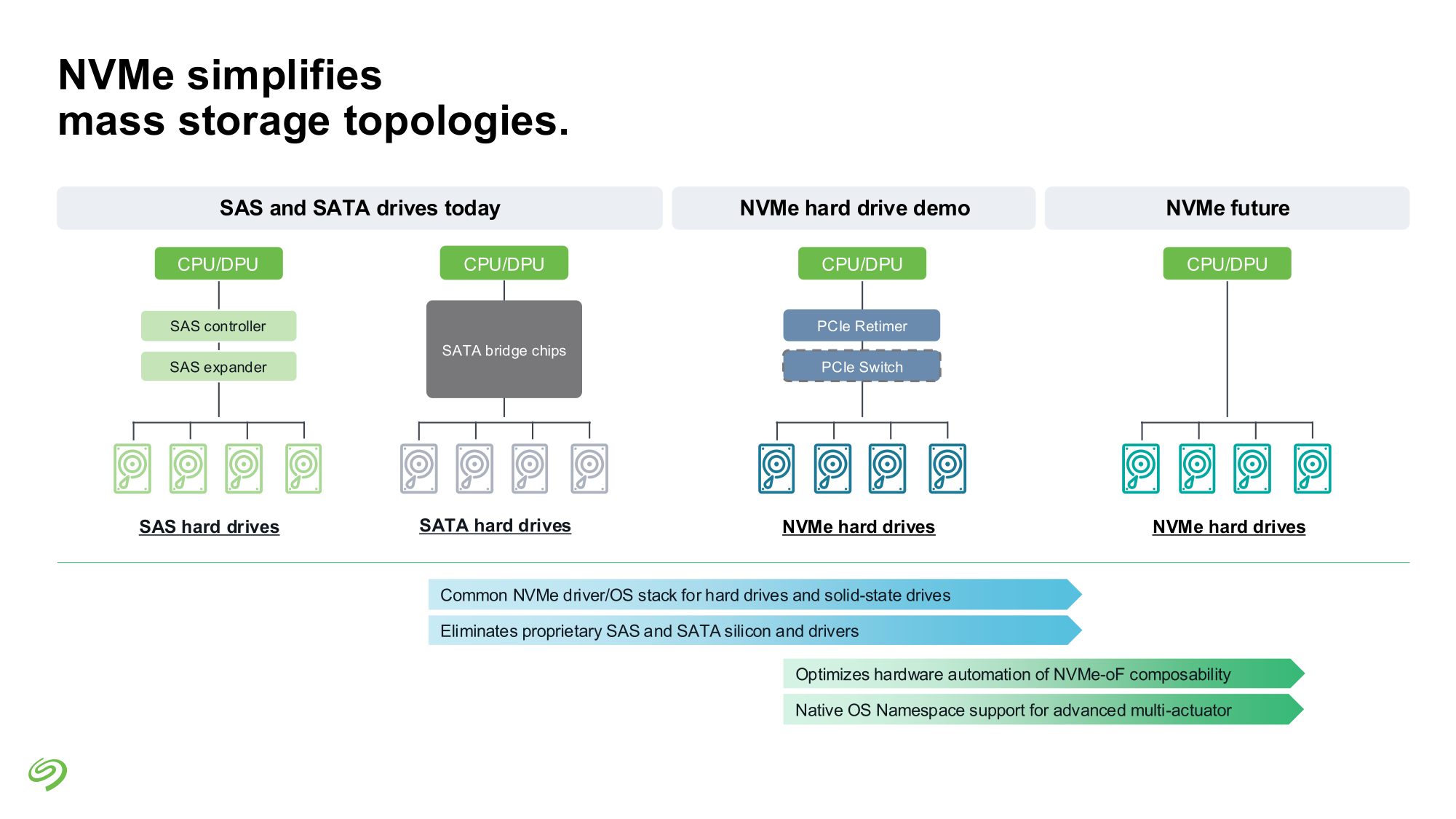 В планах компании значится создание NVMe HDD на базе HAMR объёмом до 36 Тбайт и более на платформе Mozaic, а также разработка референсных архитектур и дальнейшее продвижение технологии NVMe-oF. Надо сказать, что опыт создания жёстких дисков с этим интерфейсом у Seagate есть — ещё в ноябре 2021 году компания продемонстрировала дисковую полку с 12 LFF HDD, доступ к которой осуществлялся с помощью PCIe 3.0. За основу была взята модель Exos объёмом 18 Тбайт.  Toshiba и Western Digital на тот момент инициативу Seagate не поддержали, и на данный момент ситуация пока остаётся прежней — два других крупных производителя HDD хранят молчание о планах по внедрению NVMe в механические накопители. Если конкуренты всё-таки предложат свою альтернативу, потенциальные заказчики смогут избежать привязки к вендору, да и на популяризации самой технологии NVMe-массивов это скажется благотворно. Тем более что поддержка HDD уже давно прописана в стандарте NVMe 2.0.
06.03.2025 [13:45], Сергей Карасёв
1,5 Пбайт в 2U и 120 Гбайт/с: PEAK:AIO представила обновлённое All-Flash хранилище AI Data ServerБританский стартап PEAK:AIO анонсировал обновлённую платформу хранения данных AI Data Server, предназначенную для поддержания ресурсоёмких нагрузок ИИ. Сервер в форм-факторе 2U на основе SSD производства Solidigm обеспечивает 1,5 Пбайт «сырой» вместимости. PEAK:AIO утверждает, что благодаря новому программному стеку NVMe устраняются «узкие места Linux», что обеспечивает высокую производительность для приложений ИИ с интенсивным использованием данных. AI Data Server — это программно-определяемое хранилище на стороннем оборудовании. В частности, применяется сервер Dell PowerEdge R7625, оборудованный сетевыми адаптерами NVIDIA ConnectX-7. Заявленная пропускная способность достигает 120 Гбайт/с. Система комплектуется накопителями Solidigm D5-P5336 вместимостью 61,44 Тбайт. Эти изделия выполнены на 192-слойных чипах флеш-памяти QLC 3D NAND и оснащены интерфейсом PCIe 4.0 x4 (NVMe 2.0). Скорость последовательного чтения/записи достигает 7000/3000 Мбайт/с, показатель IOPS при произвольном чтении — 1 005 000. Сервер комплектуется 24 накопителями, что в сумме обеспечивает около 1,5 Пбайт ёмкости. 
Источник изображения: PEAK:AIO Платформа AI Data Server может использоваться для решения различных задач в специфичных областях, таких как здравоохранение, исследования и периферийные приложения ИИ. Подобные нагрузки требуют наличия высокопроизводительного хранилища, но зачастую доступ к инфраструктуре ЦОД у организаций из указанных отраслей ограничен. Система AI Data Server позволяет устранить данный пробел: она может масштабироваться от единичных узлов до кластеров, рассчитанных на огромные озера данных ИИ.
16.02.2025 [15:21], Сергей Карасёв
NetApp представила All-Flash СХД ASA A-Series начального и среднего уровнейВ сентябре 2024 года компания NetApp анонсировала высокопроизводительные СХД ASA A1K, ASA A90 и ASA A70 типа All-Flash, оптимизированные для блочного хранения. А теперь дебютировали модели ASA A20, ASA A30 и ASA A50, относящиеся к начальному и среднему уровням. Устройства также предназначены для блочного хранения. Применяется архитектура с двумя контроллерами в режиме «активный — активный», а доступность данных заявлена на уровне 99,9999 %. Все новинки имеют стоечное исполнение 2U с 24 внутренними отсеками для SSD. Реализована 12-узловая конфигурация: максимальное количество накопителей у ASA A20, ASA A30 и ASA A50 составляет соответственно 720, 432 и 288. Это обеспечивает суммарную вместимость до 48, 29 и 19 Пбайт с учётом компрессии. Могут применяться NVMe SSD ёмкостью до 15,36 Тбайт. 
Источник изображения: NetApp Возможно использование до 32 портов Ethernet (вплоть до 100GbE). Доступны восемь слотов расширения PCIe. Говорится о поддержке NVMe/TCP, NVMe/FC, FC, iSCSI, а также платформ Windows Server, Linux, Oracle Solaris, AIX, HP-UX, VMware, macOS, ESX. Позднее в текущем году NetApp предложит клиентам решение ONTAP Autonomous Ransomware Protection на базе искусственного интеллекта (ARP/AI) для блочных хранилищ. Кроме того, с целью снижения операционных рисков заказчиков NetApp запустит сервис обнаружения программ-вымогателей (Ransomware Detection Program). Если такое вторжение не удастся идентифицировать, NetApp поможет клиентам с восстановлением информации с помощью инструментов NetApp Professional Services без первоначальной оплаты. Стоимость новых СХД начинается с $25 тыс.
24.11.2024 [09:54], Сергей Карасёв
AIC и ScaleFlux представили JBOF-массив на основе NVIDIA BlueField-3Компании AIC и ScaleFlux анонсировали систему F2026 Inference AI для ресурсоёмких приложений ИИ с интенсивным использованием данных. Решение выполнено в форм-факторе 2U. В оснащение входят два DPU NVIDIA BlueField-3, которые могут работать на скорости до 400 Гбит/с. Эти изделия способны ускорять различные сетевые функции, а также операции, связанные с передачей и обработкой больших массивов информации. Во фронтальной части F2026 Inference AI расположены 26 отсеков для высокопроизводительных вычислительных SSD семейства ScaleFlux CSD5000 (U.2). Накопители с интерфейсом PCIe 5.0 (NVMe 2.0b) имеют вместимость 3,84, 7,68, 15,36, 30,72, 61,44 и 122,88 Тбайт, а с учётом компрессии эффективная ёмкость может достигать приблизительно 256 Тбайт. Реализована поддержка TCG Opal 2.02 и шифрования AES-256, NVMe Thin Provisioned Namespaces Virtualization (48PF/32VF), ZNS, FDP. Платформа F2026 Inference AI представляет собой JBOF-массив, способный на сегодняшний день хранить 1,6 Пбайт информации (эффективный объём). В следующем году показатель будет доведён до 6,6 Пбайт. Утверждается, что сочетание BlueField-3 и энергоэффективной технологии хранения ScaleFlux помогает минимизировать энергопотребление, а также повысить долговечность и надёжность. Результаты проведённого тестирования F2026 Inference AI демонстрируют пропускную способность при чтении до 59,49 Гбайт/с, при записи — более 74,52 Гбайт/с. Благодаря объединению средств хранения, сетевых функций и инструментов безопасности в одну систему достигается снижение эксплуатационных расходов, что позволяет оптимизировать совокупную стоимость владения (TCO). 
Источник изображения: AIC Новинка является лишь одной из вариаций решений на базе F2026. Платформа, в частности, поддерживает работу других DPU, включая Kalray 200 и Chelsio T7. Также упоминается вариант шасси на 32 накопителя EDSFF E3.S/E3.L.
12.11.2024 [12:34], Сергей Карасёв
ITPOD представила All-Flash СХД с поддержкой NVMe/TCPРоссийский поставщик решений корпоративного класса ITPOD анонсировал собственное семейство СХД с поддержкой протокола NVMe/TCP. Импортозамещающие устройства, как утверждается, подходят как для небольших, так и для крупных компаний. В серию вошли три модели типа All-Flash — ITPOD FF-100, ITPOD FF-300 и ITPOD FF-500 с поддержкой соответственно 24, 48 и 72 NVMe-накопителей. Максимальная сырая ёмкость достигает 367 Тбайт, 734 Тбайт и 1,1 Пбайт, эффективная — 1,5 Пбайт, 3 Пбайт и 4 Пбайт соответственно. Все новинки используют два контроллера в режиме Active–Active. Допускается установка TLC SSD вместимостью 3,2, 6,4 и 12,8 Тбайт, а также накопителей QLC SSD на 15,3 Тбайт. Поддерживаются протоколы iSCSI, NVMe/TCP и NFS. Возможно подключение двух NVMe-полок без дополнительных коммутаторов. 
Источник изображений: ITPOD Есть два порта 1GbE и выделенный сетевой порт управления 1GbE. Кроме того, предусмотрены четыре слота расширения для установки адаптеров 10GbE SFP+ (4 порта), 25GbE SFP28 (два порта) или 40/100GbE QSFP28 (два порта). Диапазон рабочих температур — от +10 до +35 °C. Аппаратная платформа, судя по всему, заказана у Gooxi.  Версия начального уровня ITPOD FF-100 несёт на борту 512 Гбайт памяти и обеспечивает производительность до 400 тыс. IOPS. Вариант среднего уровня ITPOD FF-300 оснащён 1024 Гбайт памяти, а значение IOPS достигает 600 тыс. Наиболее производительная модель ITPOD FF-500 комплектуется 1536 Гбайт памяти и имеет показатель IOPS до 1 млн. Все устройства наделены 64 Гбайт памяти NVRAM.  СХД устойчивы к отказам до трёх накопителей, поддерживают транзакционную целостность и автоматическое восстановление данных. Все ключевые компоненты имеют резервирование, обеспечивая непрерывную эксплуатацию. В семейство СХД ITPOD также войдут гибридные модели на основе SSD и HDD, но их характеристики пока не раскрываются. Системы подойдут для компаний, работающих с большими массивами данных, аналитикой, облачными технологиями и другими информационными системами.
29.09.2024 [14:31], Сергей Карасёв
NetApp представила All-Flash СХД ASA A-Series с эффективной ёмкостью до 67 ПбайтКомпания NetApp анонсировала новые высокопроизводительные СХД семейства ASA A-Series класса All-Flash, оптимизированные для блочного хранения. Дебютировали модели ASA A1K, ASA A90 и ASA A70, которые, как утверждается, обеспечивают доступность данных на уровне 99,9999 %. Все новинки имеют 12-узловую конфигурацию и используют два контроллера в режиме «активный — активный». Модель ASA A1K получила исполнение 2 × 2U (плюс дисковая полка NS224 на 24 накопителя), а варианты ASA A90 и ASA A70 — 4U с 48 внутренними отсеками для SSD. У всех СХД максимальная конфигурация может включать 1440 накопителей. Эффективная ёмкость достигает 67 Пбайт с учётом компрессии 5:1. Доступны 18 слотов расширения PCIe. Говорится о поддержке 24 портов 200GbE и 36 портов 100GbE/40GbE. Младшая версия также поддерживает 48 портов 25GbE/10GbE/1GbE, две другие — 56. Среднее энергопотребление составляет 2718 Вт (с полкой NS224) у ASA A1K, 1950 Вт у ASA A90 и 1232 Вт у ASA A70. 
Источник изображения: NetApp Заявлена совместимость с NVMe/TCP, NVMe/FC, FC, iSCSI, а также с платформами Windows Server, Linux, Oracle Solaris, AIX, HP-UX, VMware. Вместе с выпуском новых СХД компания NetApp усовершенствовала свой сервис Data Infrastructure Insights (ранее Cloud Insights) с целью улучшения возможностей мониторинга и анализа. Клиентам предоставляются дополнительные инструменты по управлению оптимизацией и надежностью инфраструктуры хранения данных, что позволяет повысить эффективность и производительность. Вместе с тем средства NetApp ONTAP Autonomous Ransomware Protection with AI (ARP/AI) обеспечивают обнаружение программ-вымогателей с точностью 99 %.
21.08.2024 [09:41], Сергей Карасёв
Nimbus Data представила ExaDrive EN — первый в мире многопротокольный Ethernet SSDКомпания Nimbus Data анонсировала накопители семейства ExaDrive EN с Ethernet-подключением: это, как утверждается, первые в мире многопротокольные U.2 SSD, поддерживающие NVMe-oF и NFS. Устройства ориентированы на поставщиков облачных услуг и операторов масштабных ИИ-платформ. Попытки создания SSD с Ethernet предпринимались и ранее, например, Kioxia представила накопители EM6 ещё в 2021 году. Но, как заявляет Nimbus Data, возможности таких изделий были ограничены. Отмечается, что предыдущие решения фактически представляли собой обычные NVMe SSD с конвертером NVMe-to-Ethernet на базе ASIC либо внутри самого накопителя, либо на внешнем адаптере. Nimbus Data заявляет, что такая схема сопряжена с нехваткой необходимого ПО и снижением вычислительной мощности. В результате подобные продукты предлагают лишь базовый блочный доступ, работают медленнее традиционных SSD и не могут в полной мере использовать возможности, которые предоставляет технология Ethernet. В устройствах Nimbus Data ExaDrive EN используется иной подход, говорит компания. В накопителях применяется SoC с архитектурой Arm, обеспечивающая вычислительные ресурсы для поддержки функций, выходящих за рамки простого блочного хранилища. Кроме того, Nimbus Data портировала на Arm свой софт HALO, создав тем самым «основу для интеллектуального Ethernet SSD с уникальными возможностями». То есть речь идёт уже о SmartSSD с сетевым интерфейсом. 
Источник изображения: Nimbus Data Среди ключевых особенностей ExaDrive EN названы встроенная поддержка протоколов NFS и NVMe/TCP, шифрование AES-256 и подсчёт контрольных сумм для автоматического устранения повреждений данных. Устройства соответствуют спецификации SNIA Native NVMe-oF Drive v1.1, что гарантирует совместимость с EBOF (Ethernet Bunch of Flash). В дальнейшем функциональность будет расширяться: станут доступны сжатие, поддержка параллельных файловых систем и S3-совместимого объектного хранилища. Используя устройства ExaDrive EN, организации могут задействовать дезагрегацию для создания более эффективной и масштабируемой инфраструктуры данных. Хосты подключаются к таким SSD с помощью клиентов NVMe-oF/TCP и NFS, поддержка которых есть в популярных ОС. Накопителями можно управлять и разделять их на виртуальные пространства имен с помощью веб-интерфейса HALO, CLI или RESTful API. Таким образом, при формировании масштабных хранилищ отпадает необходимость в приобретении дополнительных серверов, сетевых карт, коммутаторов и другого оборудования. В сочетании с масштабируемыми файловыми системами накопители ExaDrive EN можно объединить в единое глобальное пространство экзабайтного уровня. На первом этапе накопители ExaDrive EN будут доступны в версии вместимостью 16 Тбайт на основе флеш-памяти TLC: такие изделия поступят в продажу в IV квартале 2024 года. В 2025-м появятся варианты большей ёмкости.
11.08.2024 [22:03], Сергей Карасёв
Western Digital представила NVMe-oF-платформу OpenFlex Data24 4000 вместимостью до 368 ТбайтКомпания Western Digital анонсировала платформу хранения данных OpenFlex Data24 4000 класса NVMe-oF JBOF с возможностью установки 24 NVMe SSD стандарта U.2. Например, могут применяться накопители Ultrastar DC SN655 вместимостью 15,36 Тбайт, что в сумме даст около 368 Тбайт ёмкости. Система выполнена в форм-факторе 2U с размерами 85,5 × 491,1 × 628,65 мм. Задействованы хост-адаптеры RapidFlex на основе фирменных ASIC A2000 с возможностью использования в общей сложности до 12 портов 100GbE. Говорится о поддержке TCP и RoCEv2. Производительность RoCEv2 достигает 27 млн операций ввода/вывода в секунду (IOPS) при произвольном чтении данных блоками по 4 Кбайт и 3 млн операций при произвольной записи. Скорость последовательного чтения и записи — до 135 и 92 Гбайт/с соответственно. В случае TCP показатель IOPS составляет до 21 млн при произвольном чтении и до 3 млн при произвольной записи. Скорость последовательного чтения и записи — до 113 и 86 Гбайт/с. 
Источник изображения: Western Digital Устройство OpenFlex Data24 4000 несёт на борту чип BMC с ядром Arm; имеется выделенный порт 1GbE для удалённого мониторинга и управления. Диапазон рабочих температур — от +10 до +35 °C. Питание обеспечивают два блока мощностью 800 Вт с сертификатом Titanium. Производитель предоставляет пятилетнюю гарантию. |
|

