Материалы по тегу: hci
|
16.05.2026 [23:23], Владимир Мироненко
Acronis представила платформу Cyber Frame — альтернативу продуктам VMwareКомпания Acronis объявила о запуске Acronis Cyber Frame — HCI-платформы IaaS, разработанной для поставщиков управляемых услуг (MSP), поставщиков облачных услуг (CSP), хостинг-провайдеров и телекоммуникационных компаний. Acronis Cyber Frame позволяет партнёрам предоставлять, защищать, управлять и автоматизировать создание, предоставление и монетизацию инфраструктурных услуг на своих условиях, объединяя виртуальные машины, сети и хранилища с интегрированными в Acronis средствами киберзащиты, управления и автоматизации. Как утверждает разработчик, в условиях деградации устаревшей виртуализации, растущего давления на затраты со стороны гиперскейлеров и увеличения спроса на региональные и суверенные облачные решения, Acronis Cyber Frame предоставляет поставщикам услуг новый путь к восстановлению контроля над своей инфраструктурной стратегией и маржой. 
Источник изображений: Acronis Acronis подчеркнула, что с помощью платформы можно осуществить модернизацию устаревших кластеров VMware vSphere и снять риски, связанных с лицензированием, после изменений цен, инициированных Broadcom. «Cyber Frame позволяет мигрировать в облачную инфраструктуру, размещённую партнером, через Cyber Frame Local или Cyber Frame Cloud, размещённую Acronis, — заявила компания. — В типичной конфигурации из пяти узлов Cyber Frame Local обеспечивает валовую прибыль около 65% и рентабельность инвестиций за три года в размере 183 %, по сравнению с примерно 84 % у VMware». Acronis Cyber Frame предлагает две модели развёртывания. Вариант Cyber Frame Cloud обеспечивает партнёрам возможность быстро начать работу с размещённой на серверах Acronis платформой, предоставляя IaaS из региональных ЦОД Acronis без приобретения оборудования или эксплуатации собственной инфраструктуры. Благодаря вариантам развёртывания на серверах Acronis и поставщиков услуг, Cyber Frame помогает партнёрам решать вопросы размещения данных, локального контроля и обеспечения суверенитета. Версия Cyber Frame Cloud уже развёрнута в более чем 30 ЦОД Acronis по всему миру, и планируется расширение сети. 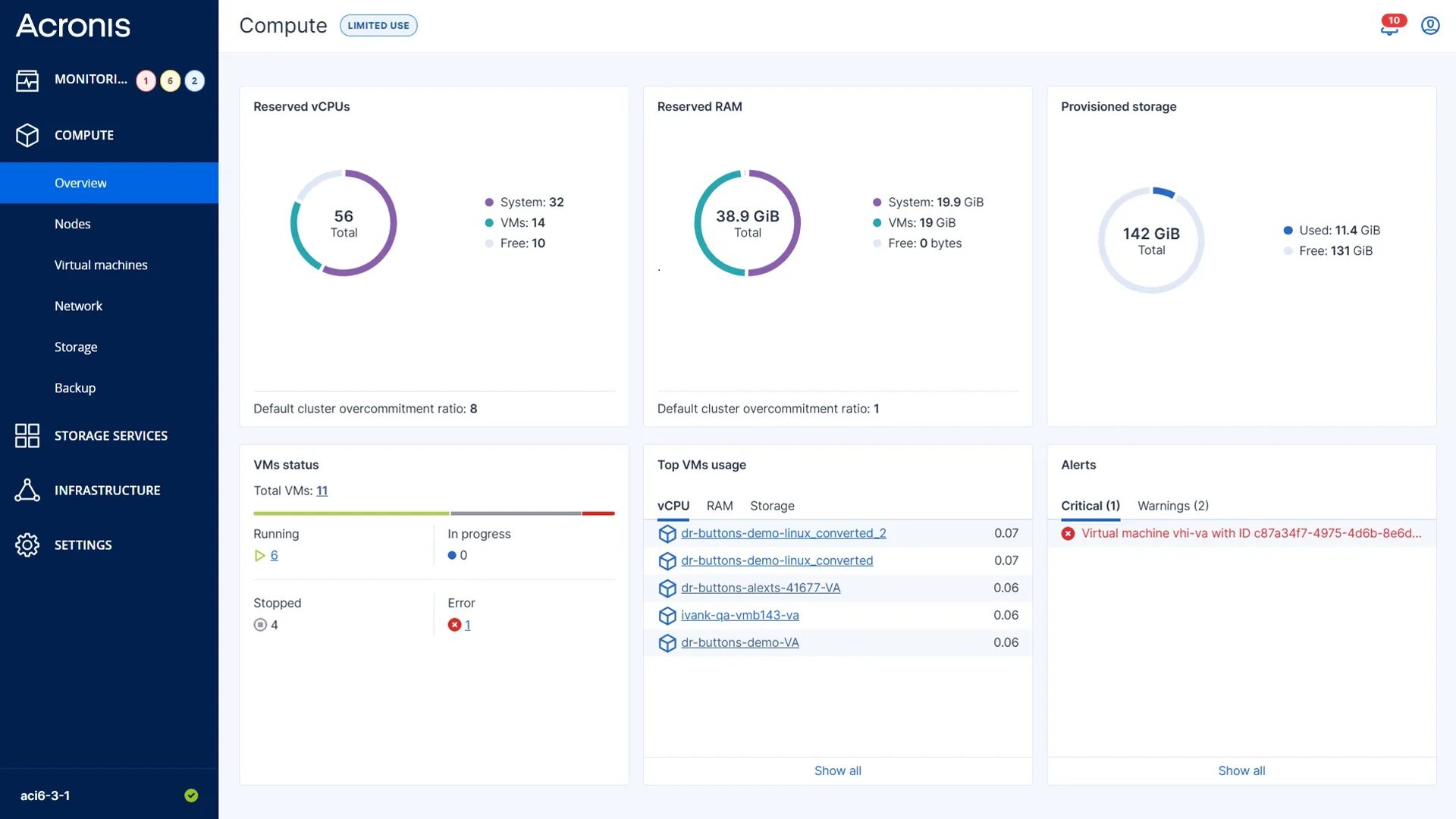 Компании также могут развернуть Cyber Frame Local в своём собственном ЦОД или среде колокации, чтобы получить полный контроль над инфраструктурой, экономикой, производительностью и местоположением данных. Cyber Frame поддерживает многопользовательский режим, самообслуживание клиентов, доставку под собственной торговой маркой, рабочие процессы PSA и интегрированное управление через облако Acronis Cyber Protect. Платформа построена в сотрудничестве с Virtuozzo на основе оптимизированных технологий OpenStack и KVM, без привязки к проприетарному гипервизору. Раннее Virtuozzo представила платформу V/IS для ИИ, которая поможет справиться с ростом цен на ПО VMware. Что не менее важно, Cyber Frame имеет встроенную защиту по умолчанию, то есть заказчики получают виртуальные машины со встроенным резервным копированием и аварийным восстановлением, защитой от угроз, а также возможностью удалённого мониторинга и управления (RMM) без необходимости использования для этих целей отдельных инструментов.
14.05.2026 [16:47], Владимир Мироненко
Virtuozzo предложила инфраструктурную систему V/IS для ИИ, которая поможет справиться с ростом цен на ПО VMwareКомпания Virtuozzo, специализирующаяся в области разработки ПО для инфраструктурных систем, представила своё видение эффективной ИИ-инфраструктуры, «созданной с помощью ИИ и использующей ИИ для обработки ИИ-нагрузок». V/IS представляет собой гиперконвергентную систему, объединяющую в единой архитектуре вычислительные ресурсы, хранилище данных и сети, включая операционную систему нового поколения, а также функции оркестрации, управления, автоматизации и защиты. V/IS включает следующие компоненты:

Источник изображений: Virtuozzo Virtuozzo также позиционирует свою платформу как способ для поставщиков услуг быстро запускать услуги AIaaS (AI-as-a-Service) и GPUaaS (GPU-as-a-Service). Инфраструктура поддерживает как обучение ИИ, так и задачи инференса, а интегрированные инструменты учёта и выставления счетов призваны помочь поставщикам быстрее монетизировать ресурсы GPU. В последней версии продукта Virtuozzo в панель администратора были добавлены функции учёта и управления GPU. 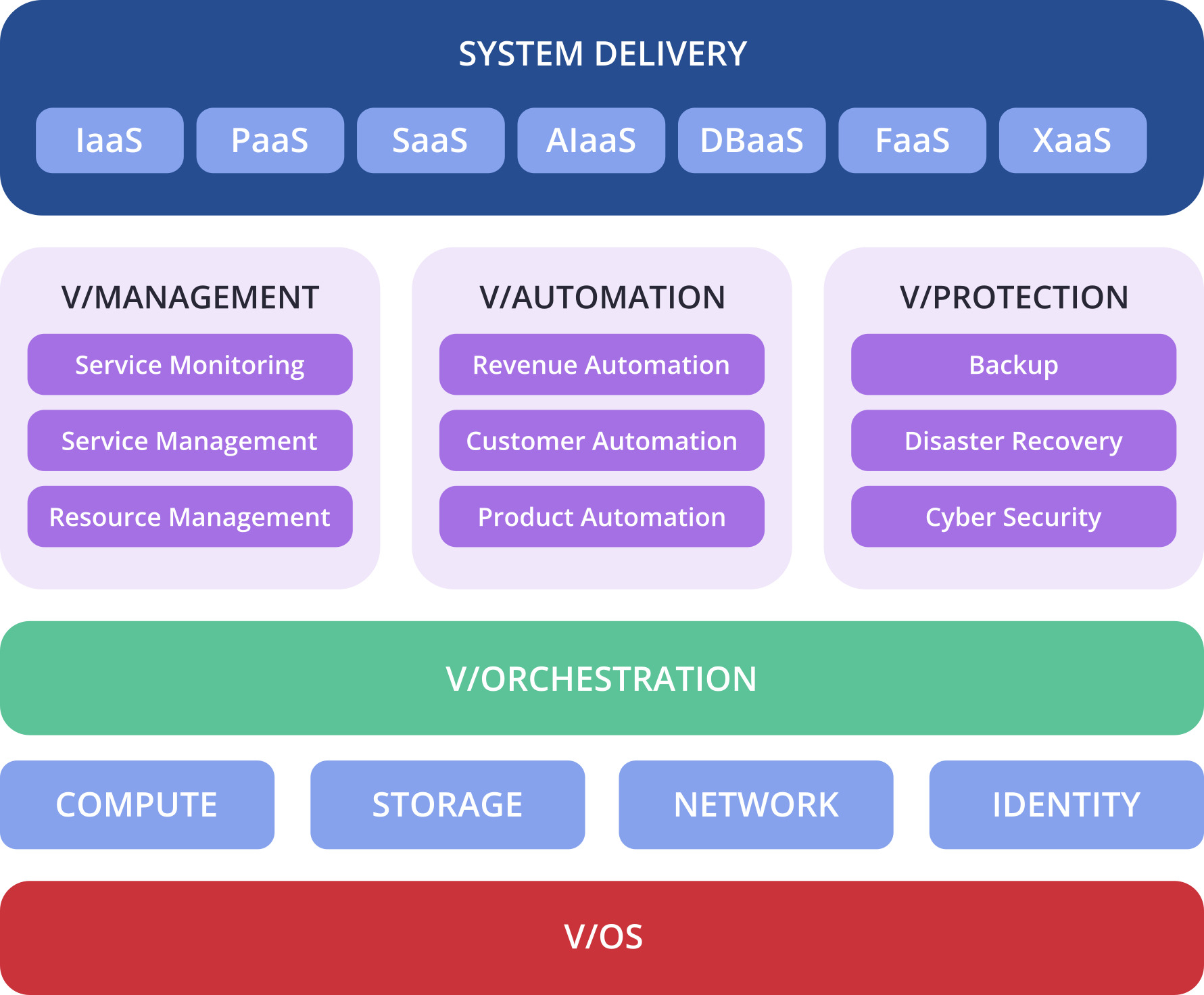 Компания заявила, что повышение эффективности использования GPU и инфраструктуры поможет организациям справиться с ростом цен на продукты VMware после приобретения VMware компанией Broadcom. Как сообщает Blocks & Files, штат Virtuozzo насчитывает более 250 сотрудников. Компания работает в более чем в 80 странах и имеет около 550 партнёров MSP и партнёров по каналам продаж.
16.04.2026 [09:36], Сергей Карасёв
Представлен российский ПАК виртуализации «Скала^р МДИ.В» для высоконагруженных системГруппа Rubytech анонсировала программно-аппаратный комплекс (ПАК) «Скала^р МДИ.В» — это модульная платформа виртуализации для размещения высоконагруженных сервисов и бизнес-приложений, в том числе в доверенных защищённых контурах органов государственного управления. Система пришла на смену модели «Скала^р МВ.С». Новинка, как утверждается, обеспечивает производительность гиперконвергентной подсистемы хранения данных до 2 млн IOPS (операций в секунду) на один вычислительный узел. При этом допускается масштабирование без простоев — добавлять новые серверы и хранилища можно без остановки работы. Платформа совместима с разными типами хранилищ данных — как с классическими аппаратными СХД, так и с современными гиперконвергентными программно-определяемыми решениями. С аппаратной точки зрения «Скала^р МДИ.В» состоит из определённого набора различных функциональных блоков — базового модуля, а также модулей виртуализации, хранения, коммутации/вычисления/хранения, безопасности, координации и пр. Часть из них входят во все конфигурации, тогда как другие добавляются по требованию заказчика. Базовый модуль используется для обеспечения сетевой связанности между компонентами, служебных функций, а также для организации выделенной сети управления. Его типовые характеристики включают два процессора с 24 ядрами (2,1 ГГц), 512 Гбайт оперативной памяти, двенадцать SSD вместимостью 1,92 Тбайт каждый, порты 100GbE, 10/25GbE и пр. 
Источник изображения: Rubytech Говорится о высокой надёжности: если один сервер выходит из строя, нагрузки автоматически переносятся на другой. Данные дублируются в разных местах, а в случае крупной аварии, например, отключения электричества в дата-центре, заказчик может быстро переключиться на резервные площадки в других регионах. Заявлено соответствие требованиям ФСТЭК России: новинка обеспечивает возможность хранения и обработки информации в государственных информационных системах до 1 класса защищённости включительно, в информационных системах при необходимости обеспечения 1 уровня защищённости персональных данных, значимых объектах критической информационной инфраструктуры 1-ой категории значимости. 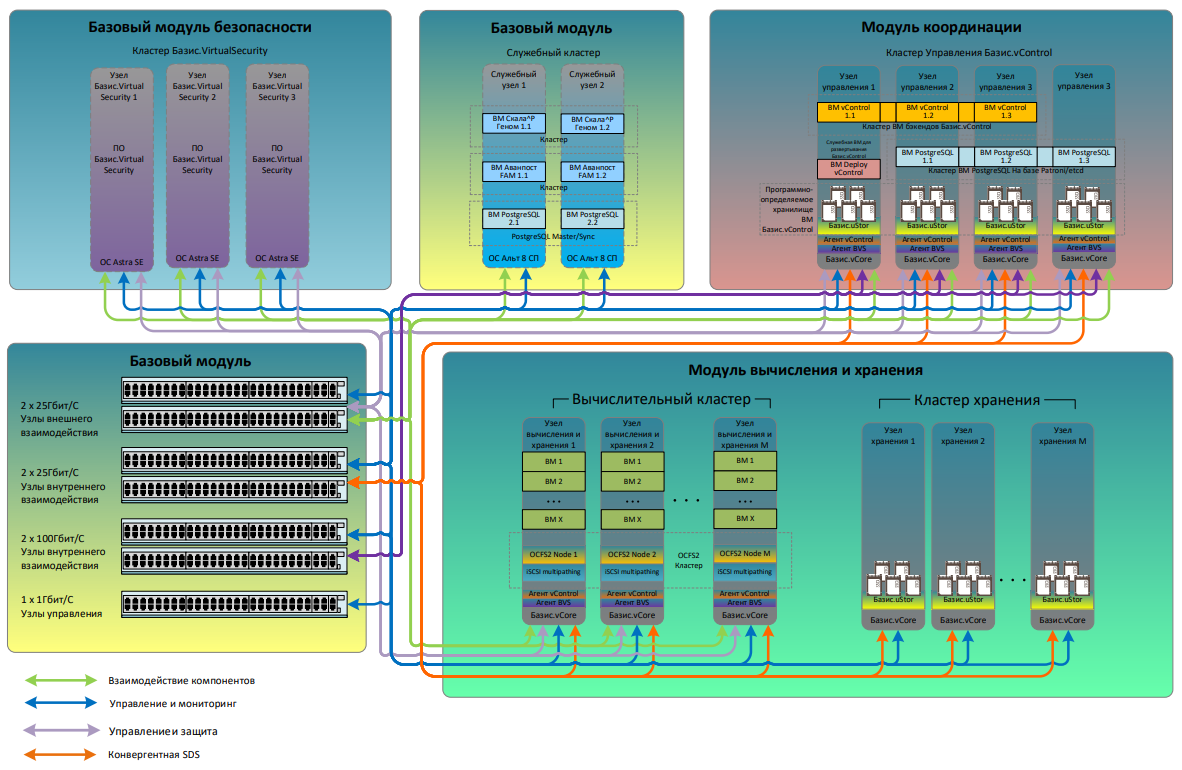
Источник изображения: Rubytech В составе программной части применяется платформа серверной виртуализации Basis Dynamix Standard. Все компоненты продукта протестированы на совместимость, а поддержка осуществляется по принципу «одного окна». Предусмотрены встроенные средства защиты «Базис.VirtualSecurity», Avanpost FAM и «Соболь». Управлять системой можно из единого центра через простой веб-интерфейс или программные инструменты «Скала^р Геном» и «Базис.vControl». Администраторы видят состояние всех серверов, хранилищ и виртуальных машин в одном окне и могут оперативно реагировать на любые изменения. Rubytech отмечает, что «Скала^р МДИ.В» функционирует в 5–6 раз быстрее аналогов при использовании современных технологий хранения данных (HCI-режим). ПАК подходит для работы с корпоративными системами, такими как ERP, CRM и базы данных. Кроме того, использовать решение можно для развёртывания ресурсоёмких сервисов и приложений, включая видеоаналитику и службы онлайн-трансляций.
15.04.2026 [09:16], Владимир Мироненко
HCI-платформа Arcfra AECP обещает наполовину снизить TCO по сравнению с VMware VCFПосле приобретения VMware компанией Broadcom и последовавшим за этим изменением лицензионной политики, сопровождаемым ростом цен, компании начали отказываться от продуктов VMware, подыскивая более приемлемые по стоимости альтернативы. В качестве одной из них ресурс Blocks & Files назвал Arcfra Enterprise Cloud Platform (AECP) — полнофункциональное программно-определяемое инфраструктурное решение сингапурского стартапа Arcfra, которое даже успело попасть в подборку Market Guide for Full-Stack Hyperconverged Infrastructure Software от Gartner. Решение AECP ориентировано на корпоративные облачные платформы. Оно объединяет вычислительные ресурсы, хранилище данных, сети, виртуализацию, оркестрацию контейнеров (Kubernetes), безопасность и возможности аварийного восстановления в единый программный стек и поддерживает развёртывание в локальных ЦОД, на периферии, на колокейшн-площадках или в распределённых облаках. AECP построено на облачной операционной системе Arcfra (ACOS) с модульными компонентами, такими как Arcfra Virtualization Engine (AVE), Arcfra Network Storage (ABS) и Arcfra Kubernetes Engine. AECP версии 6.3 обеспечивает более 11 млн IOPS, более 130 ГиБ/с и задержку менее 100 мкс на кластере из трёх узлов. По словам компании, платформа позволяет снизить общую стоимость владения (TCO) более чем на 50 % по сравнению с решением VMware VCF. 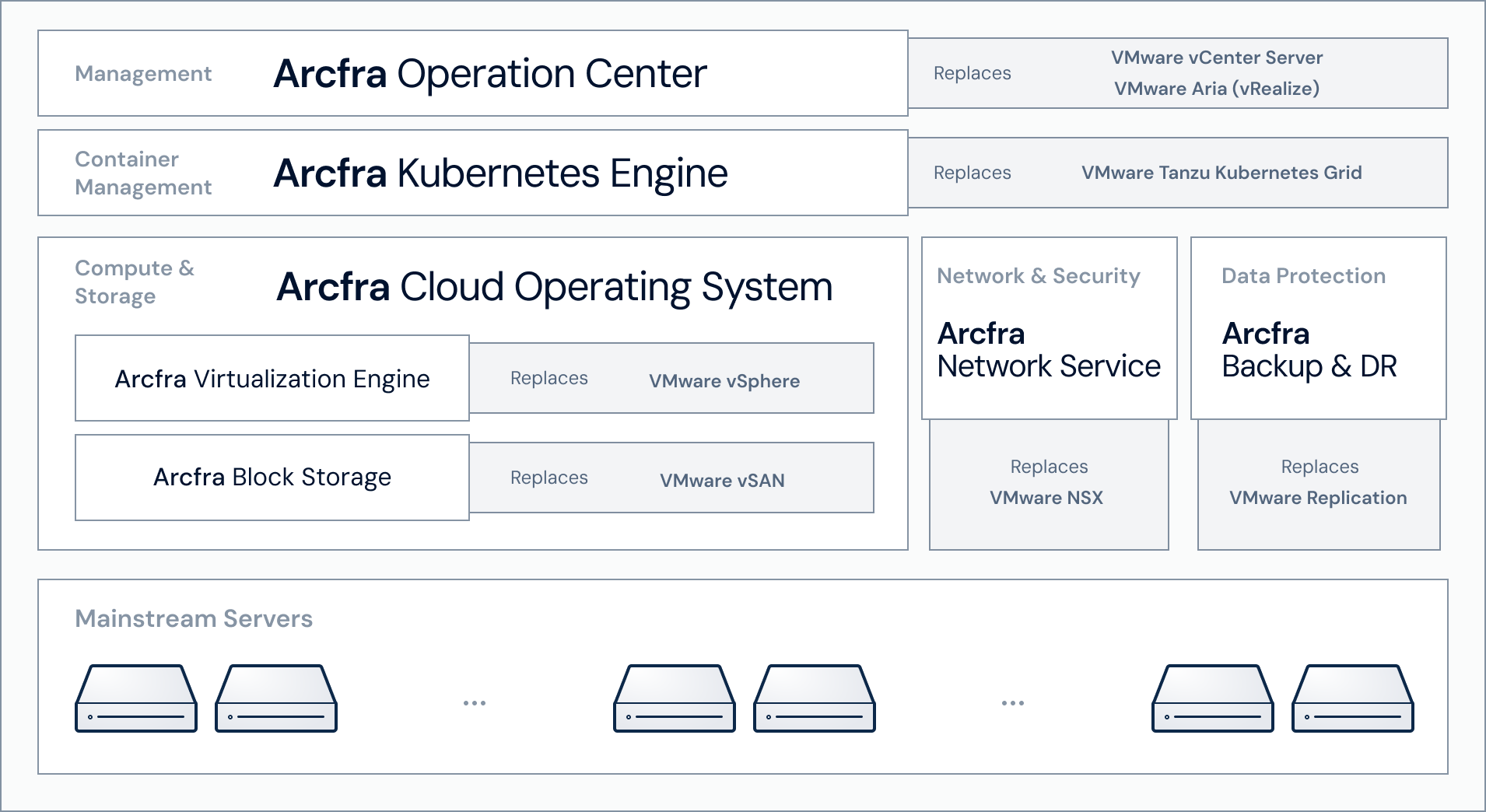
Источник изображения: Arcfra Blocks & Files полагает, что AECP и ACOS являются прямым развитием ПО компании SmartX, чей глобальный бизнес и интеллектуальную собственность приобрела Arcfra в 2024 году. SmartX продолжает работать в Китае, в то время как Arcfra фокусируется на деятельности за пределами Китая, в основном на Азиатско-Тихоокеанском регионе, предлагая клиентам альтернативу VMware, конкурирующую с решениями HPE Morpheus, Nutanix, Proxmox, Oracle Virtualization и Scale Computing. Среди её клиентов — Foxconn, платформы электронной коммерции Cafe24 и ConnectWave, а также банки, страховые компании и т.д. Arcfra также расширяет своё присутствие в Европе и Америке. В I квартале 2026 года Arcfra объявила о запуске Neutree, готовой к использованию open source платформы для организации MaaS (ИИ-модель как услуга). Эта платформа «объединяет управление моделями, инференс и рабочие процессы, чтобы сделать корпоративный ИИ более развёртываемым, управляемым и масштабируемым в реальных условиях».
14.10.2025 [10:00], Сергей Карасёв
«Базис» и MIND Software представляют первое в России коробочное HCI-решение для ускорения цифровой трансформации бизнесаКомпании MIND Software и «Базис» объявили о запуске первого в России полностью интегрированного HCI-решения. В его основу легла платформа для управления динамической инфраструктурой Basis Dynamix Standard, в которую встроена распределённая программно-определяемая система хранения данных MIND uStor. Разработанное MIND Software и «Базис» решение позволяет бизнесу создавать гиперконвергентную инфраструктуру (HCI, Hyper Converged Infrastructure), максимально сбалансированную по утилизации аппаратных ресурсов, без избыточных сервисов и точек отказа. Все необходимые для создания инструменты доступны заказчику «из коробки», без сложной настройки и длительного внедрения — для запуска системы достаточно нескольких кликов, и через 15 минут кластер полностью готов к работе. Управление гиперконвергентной инфраструктурой осуществляется из единой панели с графическим интерфейсом. Представленный продукт объединяет преимущества платформы Basis Dynamix Standard, такие как лёгкость развёртывания и гибкость управления, с надёжностью и экономичностью СХД MIND uStor. Новое HCI-решение позволяет значительно сократить время развёртывания ИТ-инфраструктуры и снизить операционные издержки, что особенно актуально для компаний, стремящихся ускорить цифровую трансформацию. 
Источник изображения: «Базис» / Денис Насаев Антон Груздев, генеральный директор MIND Software, отметил: «Интеграция MIND uStor и Dynamix Standard позволяет нам сделать современные технологии хранения данных более доступными и простыми во внедрении. Мы стремимся избавить заказчиков от сложностей с настройкой и дать им возможность сразу сосредоточиться на эффективности и масштабировании бизнеса». Дмитрий Сорокин, технический директор компании «Базис», добавил: «Поиск технологических партнёров и новых возможностей для развития продуктов — важная часть стратегии "Базиса". Мы давно и успешно сотрудничаем с MIND, и глубокая интеграция с MIND uStor — логичный шаг в развитии нашей платформы Dynamix Standard. Кроме того, мы видим значительный интерес бизнеса к HCI-платформам с прозрачной архитектурой и высокой степенью автоматизации, а значит, наше сотрудничество принесёт пользу рынку в целом».
09.10.2025 [18:30], Андрей Крупин
Российская платформа управления серверной виртуализацией VMmanager получила крупное обновлениеКомпания ISPsystem (входит в «Группу Астра») выпустила масштабное обновление платформы управления серверной виртуализацией VMmanager. VMmanager подходит для управления аппаратной и контейнерной виртуализацией, изоляции и абстрагирования виртуальной инфраструктуры от физической, а также для предоставления услуг облачного хостинга в форматах IaaS (инфраструктура как сервис) и SaaS (программное обеспечение как сервис). Решение поддерживает микросервисную архитектуру и построение отказоустойчивых кластеров (Unbreakable clusters), содержит библиотеку готовых ОС и приложений, позволяет создавать изолированные сети внутри кластера виртуальных машин (IP-fabric), выполнять проброс ресурсов физического графического процессора в виртуальную среду и решать прочие задачи. Также в составе программного комплекса представлены средства мониторинга виртуальной инфраструктуры для отслеживания ключевых метрик виртуальных машин и узлов. 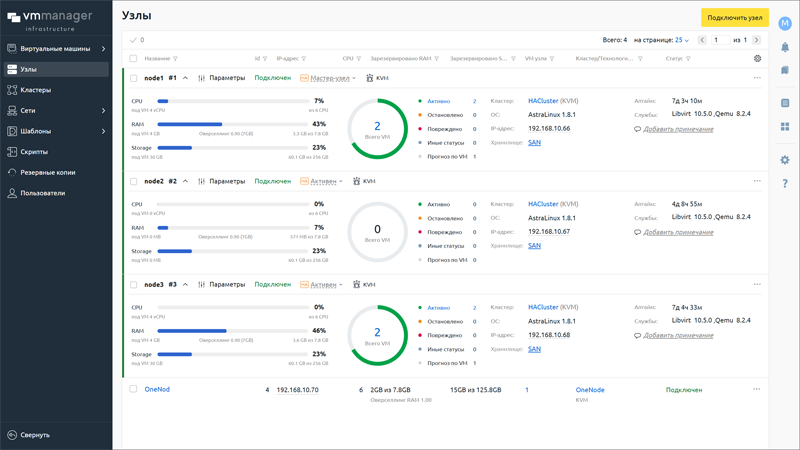
Платформа управления серверной виртуализацией VMmanager (источник изображения: ispsystem.ru/vmmanager) Ключевой особенностью нового релиза VMmanager стала реализация гиперконвергентного сценария (HCI) на основе программно-определяемого хранилища Ceph. Также продукт получил обновлённую ролевую модель доступа и ряд улучшений, повышающих гибкость и отказоустойчивость виртуальной инфраструктуры. В частности, сообщается о реализации функции паузы виртуальной машины, мгновенно освобождающей ресурсы CPU и обеспечивающей консистентность данных при резервном копировании, добавлении средств централизованного управления подключениями iSCSI, упрощающих работу с внешними дисковыми системами, и встраивании механизма контроля синхронизации времени, автоматизирующего настройку протокола NTP и предупреждающего о потенциальных сбоях в кластере. Ещё одним важным нововведением стала поддержка подключения графических ускорителей в режиме vGPU. Эта технология позволяет делить ресурсы одного физического GPU между несколькими виртуальными машинами, делая оборудование доступным для сценариев VDI, машинного обучения и рендеринга.
29.08.2025 [23:15], Владимир Мироненко
11,5 Пбайт в 2U: Novodisq представил блейд-сервер для ИИ и больших данныхСтартап Novodisq представил блейд-сервер формата 2U ёмкостью 11,5 Пбайт с функцией ускорения ИИ и др. задач. Гиперконвергентная кластерная система разработан для замены или дополнения традиционных решений NAS, SAN и публичных облачных сервисов. Новинка поддерживает платформы Ceph, MinIO и Nextcloud (также планируется поддержка DAOS), предлагая доступ по NFS, iSCSI, NVMe-oF и S3. Сервер содержит до 20 модулей Novoblade с фронтальной загрузкой. В каждом из них имеется до четырёх встроенных E2 SSD Novoblade объёмом 144 Тбайт каждый, на базе TLC NAND с шиной PCIe 4.0 x4. Накопители поддерживают NVMe v2.1 и ZNS, обеспечивая последовательную производительность чтения/записи до 1000 Мбайт/с, а на случайных операциях — до 70/30 тыс. IOPS. Надёжность накопителей составляет до 24 PBW. Энергопотребление: от 5 до 10 Вт. Система Novoblade предназначена для «тёплого» и «холодного» хранения данных. Модули Novoblade объединяют вычислительные возможности, ускорители и хранилища. Основной модулей являются гибридные SoC AMD Versal AI Edge Gen 2 (для ИИ-нагрузок) или Versal Prime Gen 2 (для традиционных вычислений) c FPGA, 96 Гбайт DDR5, 32 Гбайт eMMC, модулем TPM2 и двумя интерфейсам 10/25GbE с RoCE v2 RDMA и TSN. Энергопотребление не превышает 60 Вт. Есть функции шифрования накопителей, декодирования видео, ускорения ИИ-обработки, оркестрации контейнеров и т.д. Платформа специально разработана для задач с большими объёмами данных, таких как геномика, геопространственная визуализация, видеоархивация и периферийные ИИ-вычисления. Сервер может работать под управлением стандартных дистрибутивов Linux (RHEL и Ubuntu LTS) с поддержкой Docker, Podman, QEMU/KVM, Portainer и OpenShift. 
Источник изображений: Novodisq 2U-шасси глубиной 1000 мм рассчитано на установку до двадцати модулей Novodisq и оснащено двумя (1+1) БП мощностью 2600 Вт каждый (48 В DC). Возможно горизонтальное масштабирование с использованием каналов 100–400GbE. В базовой конфигурации шасси включает четыре 200GbE-модуля с возможностью горячей замены, каждый из которых имеет SFP28-корзины, а также управляемый L2-коммутатор. Предусмотрен набор средств управления, включая BMC с веб-интерфейсом, CLI и поддержкой API Ansible, SNMP и Redfish. Novoblade поддерживает локальное и удалённое управление, может интегрироваться в существующий стек или предоставляться с помощью инструментов «инфраструктура как код» (Infrastructure-as-Code).  По словам разработчика, система Novoblade обеспечивает плотность размещения примерно в 10 раз выше, чем у сервера на основе жестких дисков, и снижает энергопотребление на 90–95 % без необходимости в механическом охлаждении. Novodisq утверждает, что общая стоимость владения системой «обычно на 70–90 % ниже, чем у традиционных облачных или корпоративных решений в течение 5–10 лет».  «Это обусловлено несколькими факторами: уменьшенным пространством в стойке, низким энергопотреблением, отсутствием платы за передачу данных, минимальным охлаждением, длительным сроком службы и значительным упрощением управления. В отличие от облака, ваши расходы в основном фиксированы, а значит, предсказуемы, и, в отличие от традиционных систем, Novodisq не требует дорогостоящих лицензий, внешних контроллеров или постоянных циклов обновления. Вы получаете высокую производительность, долгосрочную надёжность и более высокую экономичность с первого дня», — приводит Blocks & Files сообщение компании.  Для сравнения, узлы Dell PowerScale F710 и F910 на базе 144-Тбайт Solidigm SSD ёмкостью 122 Тбайт, 24 отсеками в 2U-шасси и коэффициентом сжатия данных 2:1 обеспечивают почти 6 Пбайт эффективной емкости, что почти вдвое меньше, чем у сервера Novoblade.
24.06.2025 [20:49], Андрей Крупин
Российская гиперконвергентная платформа vStack HCP получила крупное обновлениеРазработчик решений для виртуализации vStack (входит в корпорацию ITG) выпустил новый релиз гиперконвергентной платформы vStack HCP 3.0. Комплекс vStack HCP представляет собой решение, объединяющее в единой платформе вычислительные ресурсы, хранение данных и управление сетями. Продукт разрабатывается с 2018 года, включён в реестр отечественного ПО, может быть развёрнут на стандартном серверном оборудовании и является альтернативой зарубежным средствам виртуализации и создания IT-инфраструктур. В качестве технологической базы в решении задействованы FreeBSD и ZFS, а также собственные разработки вендора для кластера, прикладного слоя, backend, API и frontend. Основу vStack составляют программно-определяемые модули: операционная система vStack OS, слой хранения vStack SDS, виртуализация сети vStack SDN и вычислительный слой vStack SDC. Для управления комплексом предусмотрен инструментарий vStack Management. 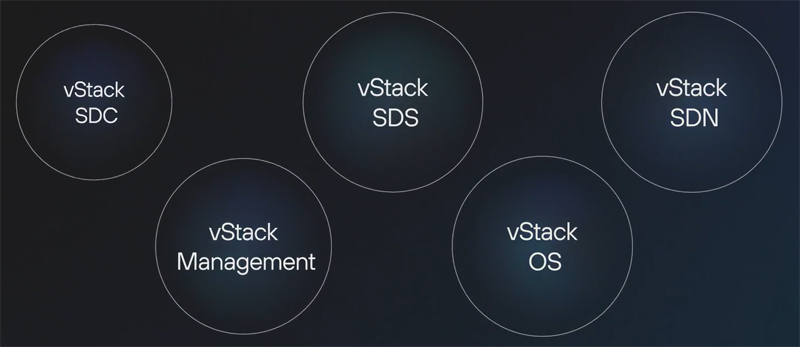
Технологический стек vStack HCP (здесь и далее источник изображений — ru.vstack.com) В vStack HCP версии 3.0 реализована модель избыточности 2N — кластер из двух серверов (high availability), который дополняет привычную модель N+. Такой подход позволяет создавать отказоустойчивые конфигурации с минимальным количеством серверов, сохраняя непрерывность работы приложений при сбое одного из узлов. 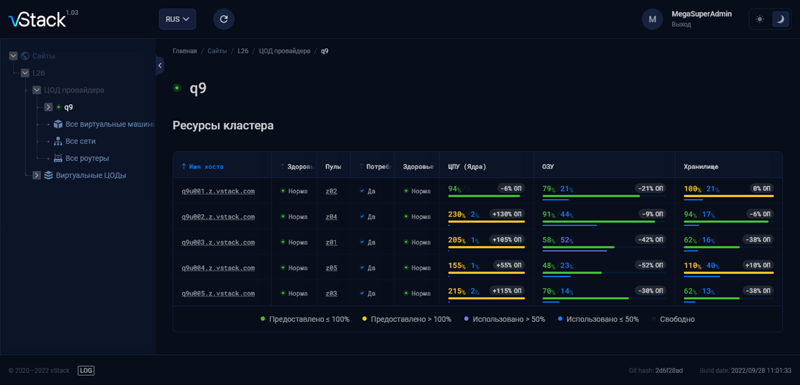
Интерфейс платформы Развитие получила сетевая часть платформы — был добавлен альтернативный виртуальный сетевой адаптер, работающий в пространстве ядра операционной системы. Слой хранения данных дополнился функциональностью Unified Storage, позволяющей отдавать ресурсы SDS внешним потребителям по NVMe over TCP и iSCSI. Для крупных проектов с объёмным файловым или архивным хранилищем добавлен механизм dRAID, который увеличивает скорость восстановления после отказа накопителя и повышает производительность дисковых пулов. В числе прочих доработок vStack HCP 3.0 — новая функция «Глобальная инфраструктура», предназначенная для объединения ресурсов нескольких кластеров в единое инфраструктурное пространство с централизованным управлением, а также улучшенные инструменты для миграции и репликации виртуальных машин. Полный список реализованных в платформе изменений представлен в прилагаемой к продукту документации.
15.05.2025 [11:49], Сергей Карасёв
vStack и TERA IT готовят HCI ПАК для бизнеса и госсектораРазработчик программного обеспечения vStack (входит в корпорацию ITG) и российский IT-дистрибьютор TERA (TERA IT Distributor) анонсировали совместный проект по выпуску отечественных программно-аппаратных комплексов (ПАК) для виртуализации и управления инфраструктурой. Устройства, как ожидается, заинтересуют клиентов из различных отраслей — от малого бизнеса до крупных государственных предприятий. В качестве аппаратной основы ПАК будут использоваться собственные платформы «Система ИКС» дистрибьютора TERA, включая серверы, СХД и сетевые устройства. Программная составляющая ПАК предполагает применение гиперконвергентной платформы vStack с полной интеграцией слоев вычислений, хранения и сети в единой панели управления. Такая HCI-архитектура, как утверждается, позволит повысить надёжность благодаря сокращению количества точек отказа. Кроме того, упростится администрирование, что позволит уменьшить штат обслуживающего персонала. В зависимости от потребностей заказчика будут предлагаться ПАК в четырёх конфигурациях. Это, в частности, варианты на серверах ИКС S-серии, которая включает компактные одно- и двухпроцессорные системы с пониженным энергопотреблением. Подходят для задач малого и среднего бизнеса, в том числе для соответствия требованиям по хранению данных (СОРМ-3, закон «Яровой»). Корпоративным клиентам, которые работают с виртуализированными инфраструктурами, будут предложены модели на серверах ИКС D- и F-серии — это сбалансированные двухпроцессорные системы с большим объёмом RAM и поддержкой NVMe-накопителей. 
Источник изображения: vStack Для высоконагруженных сред и дата-центров подойдут версии с серверами ИКС L- и H-серии с высокой плотностью вычислений. В 2026–2027 гг. появятся ПАК с серверами ИКС Z-серии (в разработке), ориентированные на госсектор и соответствующие требованиям локализации. «Мы видим стабильный рост спроса на российские IT-продукты, особенно в сфере виртуализации и управления инфраструктурой. Совместный ПАК с TERA даёт компаниям возможность выстраивать надёжные и гибкие IT-системы без привязки к зарубежным технологиям», — говорит генеральный директор vStack.
15.08.2024 [00:10], Владимир Мироненко
Только не упоминай VMware: Dell Technologies и Nutanix представили совместные HCI-решенияDell Technologies и Nutanix объединили усилия для повышения простоты, гибкости и масштабируемости гибридных облачных инфраструктур с помощью двух новых решений — Dell XC Plus и Dell PowerFlex with Nutanix Cloud Platform, сообщил ресурс SiliconANGLE. Новинки, как ожидается, помогут предприятиям более эффективно управлять приложениями и рабочими нагрузками в средах Nutanix. Новые программно-аппаратные комплексы будут поставляться Dell. Dell XC Plus представляет собой готовую гиперконвергентную платформу на базе программного стека Nutanix Cloud Platform и серверов Dell PowerEdge. По словам компаний, Dell XC Plus обеспечивает бесперебойное управление в рамках единой структуры, предлагая клиентам больше выбора и контроля для удовлетворения меняющихся ИТ-требований. Платформа, по словам компаний, предоставляет безопасную, устойчивую и гибкую ИТ-среду, централизованное управление гибридным облаком, автоматизацию, оптимизацию планирования ресурсов и повышение производительности посредством ИИ-алгоритмов. 
Источник изображения: Dell В свою очередь, решение Dell PowerFlex with Nutanix Cloud Platform объединяет программно-определяемую инфраструктуру Dell с гипервизором Nutanix AHV и Cloud Platform. Dell PowerFlex — масштабируемая vSAN и гиперконвергентная система с поддержкой нескольких гипервизоров. PowerFlex станет первым внешним хранилищем, поддерживаемым и интегрированным с Nutanix Cloud Platform. Ключевые атрибуты этой новой интеграции включают защиту корпоративных данных и аварийное восстановление, сетевые функции и защиту. Nutanix и Dell подписали партнёрское соглашение в мае, пытаясь побудить клиентов Broadcom VMware перейти на совместную платформу Dell-Nutanix. Dell и Nutanix сообщили, что решение Dell PowerFlex with Nutanix Cloud Platform в настоящее время находится в разработке и будет доступно для раннего доступа клиентам в конце этого года, в то время как Dell XC Plus доступно уже сейчас. Примечательно, что в анонсе новых решений имя VMware не упоминается ни разу. |
|

