Материалы по тегу: nvidia
|
14.06.2026 [11:51], Сергей Карасёв
В Австралии запущен суперкомпьютер MAVERIC на базе NVIDIA GB200 NVL72Университет Монаша (Monash University) в Австралии в партнёрстве с компаниями NVIDIA, Dell Technologies и ЦОД-оператором CDC Data Centres объявил о запуске суперкомпьютера MAVERIC (Monash AdVanced Environment for Research and Intelligent Computing). Новый НРС-комплекс смонтирован в Бруклинском центре CDC в Мельбурне. В основу системы положены серверы Dell PowerEdge XE9712 на платформе NVIDIA GB200 NVL72. Эти суперускорители объединяют 72 чипа B200 и 36 процессоров Grace. При этом каждое изделие B200 содержит 16 896 ядер CUDA, 528 тензорных ядер и 192 Гбайт памяти HBM3Е. MAVERIC использует передовую технологию жидкостного охлаждения с замкнутым контуром, благодаря чему отпадает необходимость в постоянном водоснабжении. Утверждается, что такое конструктивное решение не только снижает негативное влияние на окружающую среду, но и устанавливает новый стандарт для устойчивых высокопроизводительных вычислений. 
Источник изображения: Университет Монаша Показатели производительности MAVERIC не раскрываются. Но отмечается, что суперкомпьютер специально разработан для крупномасштабных задач ИИ и обработки больших объемов данных. Предполагается, что запуск машины поможет в решении важнейших глобальных проблем здравоохранения, включая раннюю диагностику рака, лечение хронических заболеваний, открытие новых лекарств и пр. Использовать ресурсы системы планируется и в других областях, включая моделирование климата и обработку конфиденциальной информации.
11.06.2026 [11:30], Руслан Авдеев
OpenAI рассматривает аренду 10-ГВт кампуса ИИ ЦОД в Огайо, который обойдётся в $500 млрд — NVIDIA готова финансово помочьКомпания OpenAI ведёт «продвинутые» переговоры об аренде кампуса ЦОД на 10 ГВт на юге Огайо. Возможно, сделка получит финансовую поддержку со стороны NVIDIA, сообщает Network World. С учётом сегодняшних цен на чипы, электроэнергию и строительные работы возведение кампуса обойдётся минимум в $500 млрд. Отмечается, что условия аренды объекта всё ещё обсуждаются, а вопросы финансирования, получения разрешений и сроков развёртывания мощностей пока не решены. Известно, что OpenAI будет контролировать вычислительное оборудование в рамках 20-летнего договора аренды и начнёт выплаты после ввода объекта в эксплуатацию. Первый этап проекта должен быть запущен в 2028 году. NVIDIA будет поставлять оборудование и выступит гарантом как выполнения арендатором финансовых обязательств, так и финансирования строительства инфраструктуры. Это свидетельствует о трансформации стратегии развития ИИ: стороны заключают всё более долгосрочные соглашения для обеспечения гарантированных мощностей на фоне стремительно растущего спроса. По словам Counterpoint Research, подобные «симбиотические» сделки становятся нормой по мере роста ИИ-инфраструктуры. Данное соглашение о финансировании позволит расширить взаимодействие OpenAI и NVIDIA, договорённость о котором официально достигнута в 2025 году. В сентябре компании объявили о совместном введении в эксплуатацию не менее 10 ГВт систем NVIDIA. Последняя сообщила, что рассчитывала поэтапно инвестировать до $100 млрд в OpenAI. На первом этапе планируется использовать платформу NVIDIA Vera Rubin. 
Источник изображения: Ambre Estève/unsplash.com Гарантии, предоставленные NVIDIA по соглашению об аренде, дополнительно укрепляют связи между ней и OpenAI. Как полагает Greyhound Research, когда поставщик чипов гарантирует финансирование аренды и строительства, характер отношений меняется — теперь речь идёт не о взаимодействии вендора и клиента, а об отношениях спонсора и арендатора. Это имеет значение и для корпоративных клиентов OpenAI: они выбирают не только конкретные ИИ-модели, но и зависимость от экономического «центра притяжения», с которым связаны производство чипов, энергетика, капитал и даже внимание регуляторов. Вероятно, речь идёт о кампусе, строительство которого Министерство энергетики США анонсировало ещё в марте. Речь идёт о переоборудовании территории бывшего предприятия Portsmouth Gaseous Diffusion Plant возле Пайктона (Piketon, Огайо). В рамках названного партнёрства подконтрольная SoftBank компания SB Energy обязалась построить от 10 ГВт новых энергомощностей, включая минимум 9,2 ГВт с питанием от генераторов на природном газе. Кроме того, планируется потратить миллиарды долларов на ЛЭП. На тот момент министерство не называло вероятного арендатора. Для корпоративных клиентов структура сделки подчёркивает необходимость оценивать не только возможности предлагаемых ИИ-моделей и стоимость услуг. Им следует добиваться условий соглашений, предусматривающих сохранение гибкости инфраструктуры: она не должна зависеть от одного поставщика вычислительных решений. По мнению экспертов, OpenAI стоит диверсифицировать доступные мощности и предлагать ресурсы на основе более экономически эффективных облачных платформ, таких как AWS или Google Cloud. Компаниям придётся подбирать облачную инфраструктуру под конкретные нагрузки. Кроме того, проекты подобного масштаба реализуются на протяжении многих лет до достижения полной мощности и сопряжены со значительными рисками и высокой степенью неопределённости.
09.06.2026 [18:19], Руслан Авдеев
NVIDIA поможет SK hynix, Naver, Doosan, SK Telecom и LG расширить ИИ-инфраструктуру Южной КореиNVIDIA анонсировала новые партнёрства с южнокорейскими технологическими гигантами. В их числе — поставщик чипов памяти SK hynix, интернет-гигант Naver, транснациональный конгломерат Doosan Group, а также SK Telecom и LG, сообщает Silicon Angle. Сделки последовали за поездкой в Южную Корею главы NVIDIA Дженсена Хуанга (Jensen Huang). Прибыв в конце прошлой недели, он провёл выходные за встречами с руководителями южнокорейских технологических компаний. SK hynix подписала с NVIDIA соглашение о многолетнем технологическом партнёрстве, основное внимание в рамках которого уделяется совершенствованию чипов памяти нового поколения для использования в передовых ИИ ЦОД. В рамках договора компания будет взаимодействовать с NVIDIA для обеспечения стабильных поставок памяти для ИИ-индустрии. Кроме того, она попытается расширить присутствие в смежных нишах «персонального ИИ» и «физического ИИ» — например, в сфере автономной робототехники и транспорта. По словам Хуанга, стабильные поставки памяти имеют ключевое значение для ускорения строительства и масштабирования ИИ-фабрик, которые возглавят новую промышленную революцию под предводительством ИИ. Также партнёры намерены сотрудничать в области «технологий симуляции» для разработки полупроводников. SK hynix будет применять библиотеку NVIDIA CUDA-X и фреймворк PhysicsNeMo для повышения скорости и эффективности симуляций, используемых при разработке и производстве передовых чипов. Это включает технологии автоматизированного проектирования (т. н. Technology Computer-Aided Design, TCAD) для анализа характеристик полупроводниковых техпроцессов и технологии вычислительной литографии для создания схем микрочипов. 
Источник изображения: NVIDIA Дополнительно родственная SK hynix компания SK Telecom рассчитывает построить в Южной Корее новое ИИ-облако гигаваттного масштаба на основе ИИ-ускорителей и инфраструктурных решений NVIDIA. Первый из нескольких ИИ ЦОД в составе этого облака должен быть введён в эксплуатацию в начале следующего года. С Naver и Doosan компания тоже договорилась о дополнительных проектах в сфере ИИ ЦОД. В случае с Naver взаимодействие стартует в Седжоне (Sejong), где расположен один из крупнейших в Азии ИИ ЦОД — Naver GAK Sejong. Компании намерены нарастить возможности объекта, а позже заняться строительством дополнительных ИИ-фабрик гигаваттного уровня, хотя будущее этих планов зависит от того, сможет ли Naver обеспечить необходимые закупки оборудования и доступ к электроэнергии. Doosan, разрабатывающая интеллектуальную робототехнику и выпускающая компоненты для GPU NVIDIA, поможет последней задействовать её энергетические решения в своих платформах для ЦОД. Doosan же рассчитывает применять технологии физического ИИ NVIDIA в своих роботах. Наконец, NVIDIA и LG Group строят ИИ-фабрику для ускорения развития нового поколения бизнесов LG, драйвером которых выступит ИИ, — от робототехники до автономного вождения, технологий ЦОД и облачных GPU-сервисов. ИИ-фабрика обеспечит LG инфраструктурой для обучения ИИ, симуляций, оценки и внедрения ИИ-приложений в ключевых сегментах бизнеса. Совместно компании объединят разработку ИИ-моделей, генерацию данных для физического ИИ, моделирование и обучение робототехники, развёртывание решений на периферии и создание цифровых двойников в масштабах целых предприятий в единый рабочий процесс для создания систем физического ИИ. Партнёрство с южнокорейскими компаниями должно помочь расширить присутствие NVIDIA в Южной Корее — одном из мировых технологических лидеров. Кстати, SK hynix и её конкурент Samsung Electronics являются двумя из трёх крупнейших производителей чипов памяти в мире, продукция которых имеет жизненно важное значение для ИИ ЦОД. В ноябре 2025 года сообщалось, что NVIDIA продаст Южной Корее 260 тыс. ускорителей для создания суверенной ИИ-инфраструктуры.
08.06.2026 [09:00], Владимир Мироненко
FirstVDS запустил vGPU-серверы на базе NVIDIA L40S и сравнил их с физическими GPU в реальных тестахПровайдер FirstVDS запустил тарифы с виртуальными GPU (vGPU) на базе NVIDIA L40S. Теперь в линейке два варианта: можно арендовать физическую видеокарту целиком (доступно с ноября 2025 года) или получить гарантированную долю виртуальной видеокарты. Компания также сравнила обе технологии в тестах и опубликовала результаты: скорость инференса LLM, генерацию видео и потребление видеопамяти. Доступны четыре тарифа vGPU — от 4 до 16 Гбайт видеопамяти. Технология vGPU делит физическую видеокарту на несколько профилей с фиксированной долей ресурсов. Серверы работают на виртуализации KVM с процессорами AMD EPYC. Стоимость — от 299 рублей в сутки. Для сравнения: тарифы с физическим GPU (Passthrough) стартуют от 1150 руб./сутки. В них доступны RTX 4090 и 5090, L4 и L40S — вся видеокарта полностью закрепляется за одной виртуальной машиной. За последние полгода спрос на GPU-серверы вырос кратно — в первую очередь из-за задач, связанных с LLM, генерацией изображений и видео. Но не каждому проекту нужна 100 % мощность физической карты. Разработчики, Data Science-команды и небольшие студии часто ищут более доступный вход с предсказуемой долей ресурсов. vGPU как раз закрывает этот запрос. Никита Попов, директор по продукту FirstVDS: «В ноябре мы закрыли потребность в сырой мощности, запустив GPU Passthrough. Но рынку нужен не только потолок производительности, но и адекватная юнит-экономика. vGPU закрывает именно этот сегмент — снижает порог входа до 300 руб. в сутки. Мы прогнали бенчмарки. Сравнивать виртуалку с выделенной картой в лоб бессмысленно — физика берет свое, чудес не бывает. Наша цель была другой: четко очертить границы применимости. Показать механику, при которой vGPU вытягивает нагрузку, и где проходит черта, за которой пора брать полноценное железо». Что показало тестированиеКомпания протестировала две конфигурации: GPU Passthrough (L40S, 48 Гбайт, 16 ядер CPU) и vGPU 16 Гбайт (8 ядер CPU). В сценариях использовались инференс LLM через llama.cpp (модели Qwen 2.5 и 3.6) и генерация видео через ComfyUI с шаблоном Wan2.2 TI2V 5B Hybrid. Результаты в целом предсказуемы: физическая карта ожидаемо обгоняет виртуальные GPU по производительности. Но обнаружилось два важных нюанса. Во-первых, при тестировании моделей среднего размера (qwen2.5-14b в двух вариантах квантизации — q3_k_m и q4_0) на vGPU-16 и Passthrough оказалось, что при полной загрузке модели в видеопамять скорость генерации токенов практически не отличается. Разница возникает только в смешанном режиме CPU+GPU (до 30–40 слоёв), где vGPU-16 сдерживает вдвое меньшее количество ядер процессора. 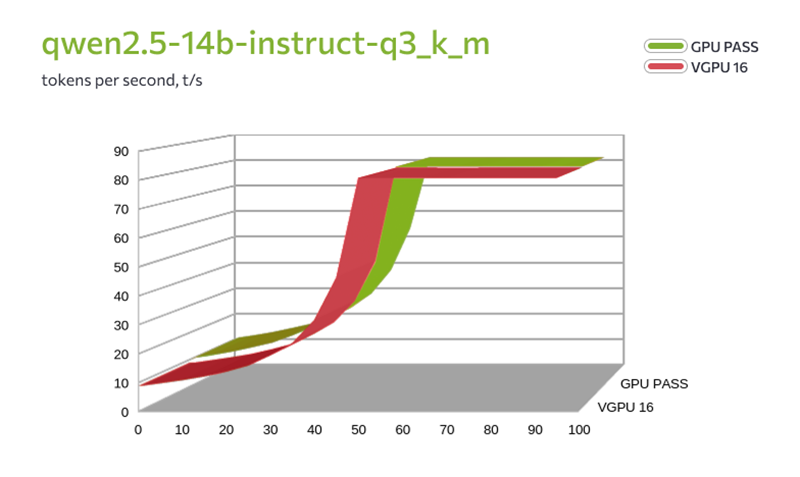
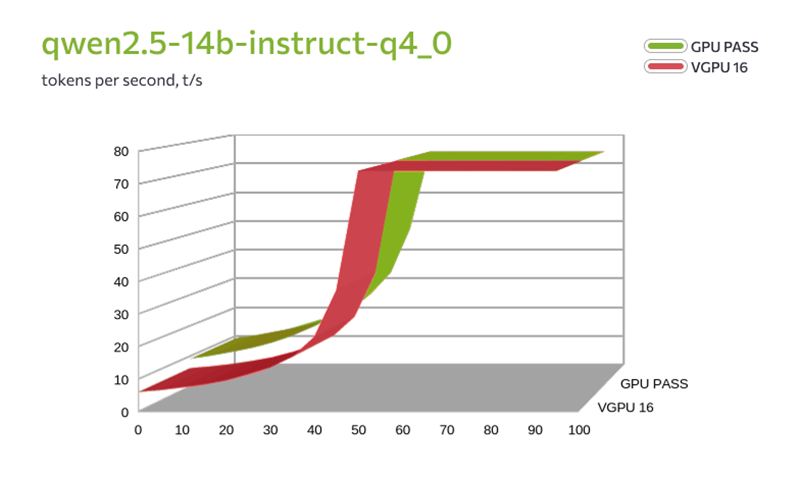
Сравнение скорости генерации токенов (qwen2.5-14b) в зависимости от количества слоёв, загруженных в GPU. Passthrough vs vGPU 16 Гбайт Во-вторых, более крупные модели (Qwen3.6-35B) в vGPU-16 полностью не загружаются — памяти не хватает, они работают только в смешанном режиме CPU+GPU со снижением скорости. Генерация видео (ComfyUI) на vGPU-16 тоже работает, но с оговорками: пришлось отключать часть функций и добавлять swap — иначе приложение аварийно завершалось. Время генерации на vGPU-16 ожидаемо выше, чем на Passthrough (для 5-секундного ролика — 293 с против 144). Таким образом, несмотря на общее преимущество физической карты, виртуальный GPU способен решать определённые задачи — например, инференс средних языковых моделей при полной загрузке в видеопамять. Это делает vGPU осмысленным выбором, когда важнее доступная цена. Для более тяжёлых сценариев (крупные модели, комфортная генерация видео без доработок) производительности vGPU может не хватить. Подробные результаты тестирования — в отдельной статье. О компанииFirstVDS — российский провайдер виртуальных серверов. В портфеле — готовые и гибкие конфигурации VPS/VDS: от высокопроизводительных CPU-серверов (линейка «CPU.Турбо 2.0» до 5,7 ГГц) до GPU-решений (Passthrough и vGPU). Также доступны S3-хранилище, домены, SSL и техподдержка 24/7. Дата-центры в Москве, Нидерландах и Казахстане. Более 20 лет на рынке.
06.06.2026 [21:50], Владимир Мироненко
Google будет выплачивать SpaceX ежемесячно $920 млн за аренду чипов NVIDIAGoogle заключила сделку с SpaceX по поводу аренды вычислительных мощностей ЦОД xAI, в рамках которой будет ежемесячно выплачивать $920 млн в период с октября 2026 года по июнь 2029 года, сообщил ресурс The Wall Street Journal. Согласно заявлению, поданному SpaceX в Комиссию по ценным бумагам и биржам США (SEC), её контрактом с Google предусмотрен доступ к 110 тыс. ускорителей NVIDIA и другим компонентам. Стоимость услуги — примерно $11 млрд в год до июня 2029 года. Если SpaceX не предоставит к 30 сентября 2026 года зарезервированные мощности, Google может расторгнуть договор после месячного льготного периода или принять предложение о любом доступном оборудовании по пропорционально сниженной цене. Также любая из сторон может расторгнуть соглашение, начиная со следующего года, уведомив об этом за 90 дней. «Это краткосрочное, своевременное соглашение, призванное обеспечить нам промежуточные мощности для удовлетворения растущего спроса клиентов на нашу агентскую платформу Gemini Enterprise, который оказался даже выше, чем мы ожидали», — заявил представитель Google Cloud. Google была одним из первых инвесторов SpaceX. Исполнительный директор Google Дональд Харрисон (Donald Harrison) входит в совет директоров SpaceX. Эксперты отмечают довольно высокую стоимость аренды и даже подозревают Google в том, что сделка призвана увеличить стоимость акций во время IPO SpaceX, поскольку Google принадлежит довольно значительная доля в SpaceX. 
Источник изображения: xAI Ранее компании обсуждали возможность сотрудничества по размещению ЦОД в космосе, пишет The Wall Street Journal. Google планирует запустить собственные орбитальные ЦОД к 2027 году в рамках проекта Project Suncatcher. Для создания этих спутников компания сотрудничает с Planet Labs. Как отметил ресурс TNW, сделка примечательна тем, что у Google есть собственные, двольно значительные вычислительные мощности. По некоторым оценкам, она является крупнейшим в мире владельцем вычислительных мощностей для ИИ, во многом благодаря своим ИИ-ускорителям TPU. Компания направит более $180 млрд на капитальные затраты в этом году и ожидает, что эта цифра «значительно увеличится» в 2027 году. Alphabet на этой неделе объявила о продаже акций на $85 млрд для финансирования этих расходов. Сделка с Alphabet по структуре похожа на соглашение, объявленное SpaceX и Anthropic в конце мая. Им предусмотрена выплата Anthropic $1,25 млрд в месяц до 2029 года за вычислительные мощности в ЦОД Colossus и Colossus II в Мемфисе (Memphis), причём точно так же предусмотрено досрочное расторжение договора. Сначала Anthropic объявила о планах арендовать 220 тыс. чипов NVIDIA у SpaceX, а затем расширила сделку до 325 тыс. чипов NVIDIA (по данным CNBC).
04.06.2026 [10:29], Сергей Карасёв
NVIDIA разработала CPO-коммутатор Quantum-X InfiniBand Photonics Q3450-LD со 144 портами 800GСтартап Lambda, развивающий неооблачную ИИ-платформу, поделился подробностями о коммутаторе Quantum-X InfiniBand Photonics Q3450-LD, разработанном компанией NVIDIA для крупных дата-центров, ориентированных на ресурсоёмкие нагрузки ИИ. Устройство, анонсированное в прошлом году, выполнено в форм-факторе 4U по технологии CPO (Co-Packaged Optics). Реализованы 144 порта 800G InfiniBand (коннекторы MPO — Multi-fiber Push-On). Заявленная неблокируемая коммутационная способность составляет 115,2 Тбит/с. Коммутаторы CPO не требуют традиционных подключаемых трансиверов. Применяются 18 съёмных внешних модулей источников света, каждый из которых обслуживает восемь портов MPO. 
Источник изображений: Lambda Рич Андервуд (Rich Underwood), системный архитектор высокопроизводительных вычислений в компании Lambda, отмечает, что для традиционного 72-портового коммутатора необходимы 72 трансивера, каждый из которых потребляет примерно 25 Вт. Исключение этих компонентов из системы обеспечивает существенную экономию энергии. Коммутатор NVIDIA Photonics CPO потребляет 3,95 кВт против 7,0 кВт у стандартного устройства сопоставимого класса. Таким образом, достигается экономия 3,05 кВт на каждый коммутатор: эта мощность может быть перераспределена на другие задачи, в частности, на питание ИИ-ускорителей.  Кроме того, использование CPO позволяет повысить надёжность. Для дата-центра со 128 тыс. GPU требуется приблизительно 655 тыс. дискретных модулей трансиверов. Каждый из них является потенциальной точкой отказа. Технология CPO полностью исключает этот класс компонентов, а следовательно, повышает стабильность работы и минимизирует количество сбоев. Устройство Quantum-X InfiniBand Photonics Q3450-LD оснащено двухконтурным жидкостным охлаждением. Для питания служит шина постоянного тока 48 В.
03.06.2026 [15:14], Руслан Авдеев
ЦОД проекта Microsoft Fairwater заработал в Висконсине, и он уже готов принять NVIDIA Vera RubinКомпания Microsoft запустила новую ИИ-фабрику проекта Fairwater в Висконсине. Ввод в эксплуатацию состоялся раньше запланированного срока, на объекте заработали сотни тысяч ИИ-систем NVIDIA Grace Blackwell, в частности NVIDIA GB200. Объект подключён к аналогичной ИИ-фабрике в Джорджии. В результате сформирована масштабируемая распределённая вычислительная система для самых требовательных передовых ИИ-моделей. Благодаря совместной работе над системами электроснабжения, охлаждения и сетевой инфраструктурой NVIDIA Spectrum-X Ethernet, а также новому сетевому протоколу Multipath Reliable Connection (MRC) с распределением пакетов данных по множественным маршрутам, архитектура Fairwater позволяет оптимизировать «экономику токенов» — стоимость обработки и генерации данных искусственным интеллектом. Дополнительно Microsoft завершила проверку платформы NVIDIA Vera Rubin. Облачный гигант подтвердил готовность платформы к развёртыванию в дата-центрах Microsoft Azure. NVIDIA Vera Rubin может использоваться наряду с системами Blackwell без необходимости модернизации инфраструктуры. Она обеспечивает производительность при инференсе до 10 раз выше на каждый затраченный мегаватт потребляемой мощности по сравнению с платформой-предшественницей. Интегрированная технология NVIDIA Confidential Computing защищает модели и данные в процессе работы ИИ-агентов. 
Источник изображения: NVIDIA Платформа NVIDIA Dynamo представляет собой программное решение для высокопроизводительного инференса, ускоряющее запуск и эксплуатацию ИИ-моделей. Кроме того, она ускоряет запуск моделей в среде AKS (Azure Kubernetes Service). Технология NVIDIA Grove отвечает за распределённую оркестрацию инференса в инфраструктуре Kubernetes. Речь идёт о запуске новой ИИ-фабрики Fairwater в США. Не так давно в эксплуатацию ввели объект в Атланте, хотя строительство в Висконсине началось довольно давно. В конце апреля глава Microsoft Сатья Наделла (Satya Nadella) заявил, что кампус строится ударными темпами и будет введён в эксплуатацию раньше намеченного срока.
03.06.2026 [15:09], Руслан Авдеев
Ayar Labs присоединилась к экосистеме NVIDIA NVLink Fusion с собственной CPO-технологиейAyar Labs присоединилась к экосистеме NVIDIA NVLink Fusion. Технология Co-Packaged Optics (CPO), предлагаемая компанией, позиционируется как решение для подключения будущих стоечных ИИ-систем на основе масштабируемой гетерогенной вычислительной архитектуры NVIDIA, сообщает Converge! Digest. Новый шаг объединяет технологию оптических интерконнектов Ayar Labs с оптическими и SerDes-технологиями NVIDIA. Это позволит крупным компаниям и разработчикам ИИ-систем интегрировать оптические соединения в ИИ-инфраструктуру на базе NVLink Fusion. ИИ-кластерам нового поколения необходимо обеспечить эффективную передачу огромных объёмов информации по мере увеличения гетерогенности систем и количества используемых ускорителей. Обычные интерконнекты практически достигли предела в контексте плотности пропускной способности, дальности действия, задержек и энергопотребления. Ayar Labs пытается преодолеть эти ограничения, интегрируя оптические модули с вычислительными. Это позволит нарастить как пропускную способность, так и дальность действия, одновременно снизив потребление электроэнергии. 
Источник изображения: Ayar Labs В рамках партнёрства с NVIDIA компания Ayar Labs намерена сотрудничать с клиентами и партнёрами по экосистеме, чтобы поддержать развёртывание своих CPO-решений в архитектурах на основе NVLink Fusion. Такая платформа позволяет интегрировать специализированные процессоры и ИИ-ускорители в стоечные системы NVIDIA, сохраняя совместимость с более широкой экосистемой NVLink. Благодаря оптической связи архитекторы систем получат ещё один вариант для проектирования крупных ИИ-фабрик. Объявление последовало за раундом финансирования серии E, в котором Ayar Labs, с 2015 года занимающаяся оптическими IO-технологиями для ИИ и HPC, привлекла $500 млн. В раунде приняла участие и компания NVIDIA. По словам Converge!, речь идёт о новой вехе для рынка CPO-технологий, поскольку этот шаг Ayar Labs приближает массовое внедрение таких решений в ИИ-инфраструктуру. Технология CPO годами рассматривалась как преемник подключаемых оптических модулей с высоким энергопотреблением и медных интерконнектов, и именно сегодня кластеры ИИ-ускорителей достигли такой производительности, что CPO становится всё более привлекательным вариантом для ИИ-систем. Решение NVIDIA включить Ayar Labs в экосистему NVLink Fusion свидетельствует о признании в отрасли ИИ того факта, что будущие системы могут потребовать использования оптики не только между стойками, но и внутри них. NVIDIA NVLink Fusion позволяет создавать кастомные ИИ-платформы со сторонними чипами и другими компонентами. Ранее NVIDIA заключила соглашения в отношении NVLink с Arm, AWS, Fujitsu, Intel, Marvell, MediaTek и SiFive.
03.06.2026 [10:59], Сергей Карасёв
Dell представила серверы PowerEdge на базе NVIDIA Vera для агентного ИИКомпания Dell Technologies сообщила об обновлении семейства решений AI Factory with NVIDIA, ориентированных на внедрение ИИ. Дебютировали серверы PowerEdge R9822 и PowerEdge M9822 на аппаратной платформе NVIDIA Vera, предназначенные в том числе для развёртывания ИИ-агентов. Процессоры Vera содержат 88 ядер Olympus (176 потоков инструкций), совместимых с набором инструкций Arm v9.2. Возможно использование до 1,5 Тбайт LPDDR5X с пропускной способностью до 1,2 Тбайт/с. Сервер PowerEdge R9822 выполнен в форм-факторе 3U и оснащён воздушным охлаждением. Система подходит для различных сценариев использования — от агентных приложений и аналитики данных до задач общего назначения, обрабатываемых посредством CPU. Машина может интегрироваться в инфраструктуры существующих дата-центров. В свою очередь, модель PowerEdge M9822 наделена системой прямого жидкостного охлаждения. Этот сервер обеспечивает высокую плотность мощности в средах, оптимизированных для ИИ-агентов и НРС. 
Источник изображения: Dell Прочие характеристики новинок пока не раскрываются. Но отмечается, что платформа Dell AI Factory with NVIDIA поддерживает такие сетевые технологии, как Spectrum-X Ethernet и Quantum-X800 InfiniBand. Могут использоваться программные решения NVIDIA AI Enterprise, мультимодальные языковые модели NVIDIA Nemotron, среда OpenShell и пр. В продажу по всему миру серверы PowerEdge R9822 и PowerEdge M9822 поступят в сентябре текущего года. Нужно отметить, что решения на платформе NVIDIA Vera готовят и другие ведущие поставщики серверного оборудования. В частности, такие системы недавно анонсировала компания HPE.
02.06.2026 [17:57], Владимир Мироненко
Intel с партнёрами разработает эталонный дизайн ИИ-стоек с чипами Xeon для ODM- и OEM-производителей
clearwater forest
foxconn
granite rapids
hardware
intel
nvidia
odm
oem
sambanova systems
xeon
ии
инференс
стойка
Intel совместно с SambaNova и Foxconn объявила о намерении создать референс-дизайн стоечной ИИ-инфраструктуры на базе процессоров Intel Xeon для ЦОД, гиперскейлеров и центров интеллектуального управления. Как сообщает The Register, подход основан на ранее разработанной Intel совместно с SambaNova концепции дезагрегированного ИИ. Архитектура распределяет ресурсоёмкие операции предварительного заполнения между ускорителями NVIDIA, используя чипы SambaNova для ресурсоёмких операций декодирования, что позволяет увеличить выход токенов для каждого пользователя в 2–3 раза. Генеральный директор Intel Лип-Бу Тан (Lip-Bu Tan) представил два примера таких проектов. Один предназначен для агентных нагрузок, чувствительных к задержкам, а другой — для обеспечения максимальной плотности вычислений. Обе конфигурации поддерживают до 128 процессоров Intel: либо 128-ядерных Granite Rapids-AP, либо 288-ядерных Clearwater Forest, что в сумме составляет от 16 384 P-ядер до 36 864 E-ядер, а также до 384 Тбайт DDR5 при энергопотреблении 100 кВт. Тан сообщил, что системы на основе этого референс-дизайна будут широко доступны у ODM- и OEM-партнёров компании. В рамках сотрудничества Foxconn предоставит возможности системной интеграции для новой стоечной ИИ-инфраструктуры. Компания также планирует выпускать вариант стоечной инфраструктуры с высокой плотностью процессоров для рабочих нагрузок, не требующих дополнительного ускорения, включая оптимизированные по стоимости задачи инференса, обработку данных и гибридный ИИ. Intel объявила, что облачный провайдер Vector Core Compute, созданный Vista Equity Partners и Cambium Capital, станет одним из первых, кто развернёт эту платформу, а Together.AI — её первым коммерческим клиентом. 
Источник изображения: Intel Также на выставке Computex 2026 компании Intel, SambaNova, Vista Equity Partners и Cambium Capital представили первую реальную демонстрацию дезагрегированной системы инференса, использующей процессоры Intel Xeon 6 для оркестрации, блоки RDU SambaNova SN40 для декодирования и NVIDIA Blackwell для предварительного заполнения, работающую в ЦОД Vector Core Compute в Лос-Анджелесе. Напомним, что ранее NVIDIA объявила о запуске аналогичной стоечной платформы, включающей 256 88-ядерных процессоров Vera, ускорители Rubin и LPU Groq 3. Arm также работает над парой референс-дизайнов стоечных систем для агентных рабочих нагрузок на основе своих новых процессоров Arm AGI: 36-кВт системой с воздушным охлаждением и 8160 ядрами, а также 200-кВт системой с жидкостным охлаждением и 45 696 ядрами. |
|

