Материалы по тегу: nvidia
|
02.06.2026 [11:12], Сергей Карасёв
HPE представила сервер ProLiant Compute DL394 Gen12 на платформе NVIDIA VeraКомпания HPE анонсировала сервер ProLiant Compute DL394 Gen12 для ресурсоёмких нагрузок в области ИИ и обработки данных. Система выполнена на аппаратной платформе NVIDIA Vera. Изделия Vera насчитывают 88 ядер Olympus, совместимых с набором инструкций Arm v9.2. Возможна одновременная обработка до 176 потоков инструкций. Поддерживается до 1,5 Тбайт LPDDR5X с пропускной способностью до 1,2 Тбайт/с. Характеристики ProLiant Compute DL394 Gen12 пока полностью не раскрываются. Известно, что новинка выполнена в форм-факторе 2U. HPE отмечает, что изделия Vera благодаря монолитной конструкции позволяют решить проблему неоднородного доступа к памяти, которая может наблюдаться при использовании традиционных чиплетных архитектур с большим количеством ядер. Эта особенность приводит к переменным задержкам и непредсказуемой производительности. В случае Vera каждому вычислительному ядру предоставляется полоса пропускания до 14 Гбайт/с, что даёт возможность обрабатывать данные на стабильно высокой скорости. 
Источник изображения: HPE В сервере реализованы средства управления HPE Integrated Lights-Out (HPE iLO 7). Говорится о защите от будущих кибератак, основанных на квантовых вычислениях, в соответствии с требованиями Национального института стандартов и технологий США (NIST). Средства HPE Compute Ops Management (COM) обеспечивают унифицированное управление серверной инфраструктурой из единой консоли. ProLiant Compute DL394 Gen12 может применяться для агентного ИИ, обработки больших объёмов транзакций и других задач. В продажу сервер поступит осенью текущего года.
02.06.2026 [10:04], Руслан Авдеев
NVIDIA усилила DPU BlueField-4 мониторингом работы ИИ-агентов в реальном времениNVIDIA Vera BlueField-4 STX (BF-4 STX) обеспечит ИИ-системам защиту ИИ-агентов, контекстной памяти и доступа к файлам непосредственно на аппаратном уровне, сообщает Blocks & Files. DPU поддерживает программную платформу DOCA (Data Center Infrastructure-on-a-Chip Architecture), обеспечивающую доступ по принципу Zero Trust, а также ведёт мониторинг и контроль деятельности ИИ-агентов для предотвращения утечки данных, несанкционированного доступа и других угроз. Решение разработано в рамках создания платформы NVIDIA Vera Rubin. Решение использует три интегрированные библиотеки безопасности и микросервисы DOCA, работающие в процессоре и памяти DPU. В частности, речь идёт о микросервисе DOCA Vault, благодаря которому доступ к нужным файлам с необходимыми правами получают только авторизованные ИИ-нагрузки. DOCA Argus обеспечивает прозрачность действий ИИ-агентов и рабочих нагрузок, а DOCA Flow помогает изолировать сетевой трафик и защитить конфиденциальные данные в экосистемах с многочисленными арендаторами ресурсов. 
Источник изображения: NVIDIA Благодаря BF-4 STX серверы и СХД могут анализировать и контролировать взаимодействие ИИ-агентов, данных и контекстной памяти в потоке данных. По информации NVIDIA, обнаружение угроз происходит до 1000 раз быстрее, чем в существующих средах без агентного мониторинга, а контроль работы осуществляется на скоростях до 800 Гбит/с. Свои решения в сфере безопасности интегрируют с Vera BlueField-4 STX компании Akamai, Armis, Check Point, Cisco, CrowdStrike, EQTY, F5, Fortinet, Palo Alto Networks, TrendAI, Xage Security и Zscaler. Платформы на базе STX предлагают провайдеры систем хранения данных: Cloudian, DDN, Dell, Everpure, Hitachi Vantara, HPE, IBM, MinIO, NetApp, Nutanix, VAST Data и WEKA. Системы на базе STX уже разрабатывают Asus, Foxconn, Gigabyte Technology, Supermicro, Wistron и Wiwynn. Заказчикам помогают внедрять соответствующие решения интеграторы Accenture, Deloitte и World Wide Technology.
01.06.2026 [16:04], Руслан Авдеев
США принимают меры, чтобы заблокировать поставки ИИ-чипов NVIDIA китайским компаниямМинистерство торговли США в воскресенье приняло меры, чтобы закрыть потенциальную лазейку, потенциально позволяющую экспортировать компаниям передовые чипы NVIDIA подразделениям китайских техногигантов, находящимся за пределами КНР, сообщает Reuters. Предполагается, что лучшие американские чипы поступали филиалам китайских компаний, расположенным в странах вроде Малайзии, Индонезии и даже Японии. Новое руководство опубликовали на сайте Министерства торговли, после того как, по данным источников, в Вашингтоне появился документ, посвящённый данной лазейке. В документе, пока не имеющем авторства, сообщается, что «шлюзы незаметно открылись». Другими словами, постепенно снизилась эффективность ограничений. Пока нет данных, как много чипов экспортировали в год, когда, как пишет Reuters, «администрация Трампа оставила дверь открытой» Один из осведомлённых отраслевых источников сообщил, что речь идёт о сотнях тысяч ускорителей. В руководстве Бюро промышленности и безопасности (BIS) сообщило, что обеспечит обязательное лицензирование для структур со штаб-квартирами в Китае, даже если их подразделения расположены за его пределами. Фактически, как сообщает бюро, руководство разъясняет требования к лицензированию, действующие с 2023 года. Представитель NVIDIA заявил, что новое руководство ничего не изменит для компании, добавив, что не может поставлять чипы, поскольку Министерство торговли недвусмысленно установило в своём документе лицензионные ограничения для компании. 
Источник изображения: Nick Fewings/unspalsh.com Фактически Министерство торговли само создало лазейку, когда объявило в мае 2025 года, что не будет соблюдать правило AI Diffusion Rule, принятое в последние дни прошлой администрации США — оно фактически делило мир на страны, которым можно продавать ИИ-ускорители без ограничений и те, которым можно, но с оговорками или вовсе нельзя. По словам экспертов, оставленная лазейка позволяла зарубежным подразделениям китайских компаний покупать чипы NVIDIA Blackwell безо всяких лицензий. В результате китайские компании покупают эти чипы и, похоже, в больших масштабах. Эксперты уверены, что новое руководство закроет лазейку, но останется другая. В частности, к TSMC и другим контрактным производителям отсутствуют требования проверять, что заказываемые у них передовые ИИ-чипы не предназначены для подставных структур, работающих на китайских покупателей. Сообщается, что в новом руководстве этот недочёт по-прежнему не устранен. Кроме того, если чипы уже установлены, новый документ не требует от операторов ЦОД прекратить использование таких чипов или остановить обслуживание передового оборудования вроде серверов. Ранее сообщалось, что Китай довольно активно прибегает к контрабанде ИИ-ускорителей, а также пользуется услугами компаний за рубежом, чтобы обойти американские санкции. Кроме того, страна наращивает производство собственных ускорителей и достигла соглашения с США о поставках относительно устаревших NVIDIA H200.
01.06.2026 [12:35], Сергей Карасёв
Двухтонный ИИ: Dell начала поставки первых стоек NVIDIA Vera Rubin NVL72Компания Dell Technologies поставила свою первую стойку NVIDIA Vera Rubin NVL72. Получателем системы стала компания CoreWeave — неоооблачный провайдер, который активно расширяет инфраструктуру для ресурсоёмких нагрузок ИИ. 
Источник изображений: Dell Стойка содержит 72 ускорителя Rubin и 36 процессоров Vera на архитектуре Arm. Суммарный объём памяти HBM4 составляет 20,7 Тбайт, системной памяти LPDDR5X — 54 Тбайт. Реализовано жидкостное охлаждение горячей водой (+45 °C). Сама стойка в собранном виде весит около 1,8 т и потребляет до 230 кВт. Заявленная ИИ-производительность достигает 3,6 Эфлопс в режиме NVFP4 при инференсе, что примерно в пять раз превышает показатель Blackwell. На задачах обучения быстродействие NVFP4 составляет 2,5 Эфлопс.  Отмечается, что Dell успешно провела все необходимые диагностические тесты Vera Rubin NVL72, по результатам которых система готова к дальнейшему развёртыванию на площадке заказчика. CoreWeave намерена использовать новый кластер для расширения своей инфраструктуры НРС. Масштабный вывод платформы на рынок намечен на II половину текущего года.  Между тем сама NVIDIA объявила о начале массового производства решений поколения Vera Rubin. В числе партнёров, объявивших о поддержке этих систем, названы Dell Technologies, HPE, Lenovo и Supermicro, а также AIC, Aivres, ASRock Rack, ASUS, Cloudian, Compal, DDN, Everpure, Foxconn, GIGABYTE, Hitachi Vantara, Hyve Solutions, IBM, Inventec, MinIO, MiTAC Computing, MSI, NetApp, Nutanix, Pegatron, Quanta Cloud Technology (QCT), VAST Data, WEKA, Wistron и Wiwynn. Вместе с тем CoreWeave, а также Lambda и Oracle Cloud Infrastructure одними из первых начнут развёртывание стоек Vera Rubin в своих ИИ-инфраструктурах.
28.05.2026 [23:48], Владимир Мироненко
Yandex B2B Tech, Selectel и MetaMentor представили ИИ ПАК по подпискеYandex B2B Tech совместно с Selectel и MetaMentor представила AIaaS (AI-as-a-Service) ПАК для on-premise развёртывания по подписке платформы Yandex AI Studio. Рещение позволит компаниям быстро развернуть ИИ-проект с размещением инфраструктуры в собственном контуре и соблюдением регуляторных требований и внутренних политик. ПАК включает три компонента: ИИ-платформу Yandex AI Studio, GPU-серверы Selectel и услуги MetaMentor по внедрению, настройке и интеграции решения в ИТ-контур компании. Как сообщается в пресс-релизе, в новом формате доступны все основные возможности Yandex AI Studio: генеративные модели, инструменты для работы с данными и файлами, файловый поиск и визуальные интерфейсы для создания ИИ-агентов даже без навыков программирования. Также в решение могут быть включены ИИ-инструменты для офисной работы. Selectel предоставляет в аренду GPU-инфраструктуру с размещением на площадке заказчика и обязательством по обслуживанию и обновлению оборудования. В частности, доступны платформы NVIDIA HGX A100/B200/B300, RTX PRO 6000 и др., а также ИИ-сервер собственной разработки Selectel. На подготовку и доставку оборудования клиенту уйдёт до пяти рабочих дней. 
Источник изображения: Selectel На MetaMentor лежит задача помочь подготовить решение к запуску, включая интеграцию платформы с корпоративными системами заказчика и помощь в создании ИИ-агентов под его задачи. В дальнейшем MetaMentor продолжит системно сопровождать проект, оказывая техническую и клиентскую поддержку по всем вопросам, а также обновляя ПО. Yandex Cloud, Selectel и MetaMentor выводят новый продукт на рынок on-premises платформенного ПО на базе ИИ, который, по данным совместного исследования Yandex Cloud и AHD, составил в России в 2025 году около 16 млрд руб. Значительная часть компаний уже развёртывает ИИ в локальном контуре, поэтому новое решение может вызвать интерес среди заказчиков.
27.05.2026 [15:41], Сергей Карасёв
Bull поставила Финляндии суперкомпьютер Roihu с производительностью до 49 ПфлопсКомпания Bull, специализирующаяся на высокопроизводительных вычислениях, поставила Финляндии новейший национальный суперкомпьютер Roihu для ресурсоёмких задач, в том числе связанных с ИИ. Система позволит утроить доступные в стране вычислительные мощности. Соглашение о создании Roihu было заключено между компанией Eviden (дочерняя структура Atos) и Финским научным IT-центром CSC в конце 2024 года. Комплекс Roihu смонтирован в дата-центре в Каяани рядом с действующим суперкомпьютером LUMI. Новая НРС-система построена на гибридной платформе Eviden BullSequana XH3000. В общей сложности задействованы 486 узлов на основе CPU и 132 узла на базе GPU. Каждый CPU-узел несёт на борту два 192-ядерных процессора AMD EPYC 9965 поколения Turin, что в сумме даёт 186 624 ядра. При этом 414 узлов располагают 768 Гбайт памяти, а оставшиеся 72 — 1536 Гбайт. В свою очередь, каждый GPU-узел оснащён четырьмя суперчипами NVIDIA GH200. Общее количество GPU в составе суперкомпьютера составляет 528. Все эти CPU и GPU узлы комплектуются локальным SSD вместимостью 960 Гбайт. Кроме того, в состав Roihu входят четыре узла визуализации с двумя процессорами AMD EPYC Turin 9335 (32 ядра) и двумя ускорителями NVIDIA L40 в каждом, а также четыре высокопроизводительных узла с двумя чипами AMD EPYC Turin 9555 (64 ядра) и 6 Тбайт памяти. В комплектацию данных узлов включены два SSD ёмкостью 7,68 Тбайт каждый. Сетевая инфраструктура базируется на 200G-интерконнекте Infiniband NDR. 
Источник изображения: HPC Wire Для Roihu предусмотрено использование двух независимых хранилищ DDN EXAScaler Lustre на основе SSD: это раздел Scratch вместимостью 6 Пбайт и дополнительная секция объёмом 0,5 Пбайт для проектных приложений и личных каталогов пользователей. Пиковая скорость передачи данных у Scratch достигает 560 Гбайт/с при чтение и 280 Гбайт/с при записи. У второй секции эти значения составляют до 120 и 100 Гбайт/с соответственно. Общая FP64-производительность CPU-узлов оценивается в 10,5 Пфлопс, GPU — в 23,4 Пфлопс: в сумме это даёт 33,9 Пфлопс. Пиковое быстродействие достигает 49 Пфлопс. Суперкомпьютер Roihu станет доступен пользователям в июне нынешнего года. При этом действующие в Финляндии НРС-системы Puhti и Mahti будут полностью выведены из эксплуатации в августе 2026-го.
27.05.2026 [00:56], Владимир Мироненко
Серверные Arm-процессоры NVIDIA Vera обогнали современные Intel Xeon и AMD EPYC в некоторых тестахПортал Phoronix провёл тестирование серверного Arm-процессора NVIDIA Vera, разработанного специально для обеспечения функционирования агентного ИИ, взяв для сравнения одно- и двухсокетные конфигурации на базе Intel Xeon 6980P (Granite Rapids-AP), а также AMD EPYC Turin: 9755, 9575F и 9475F. Также в сравнительное тестирование включили процессоры NVIDIA первого поколения Grace на базе ядер Arm Neoverse V2 (Demeter). Сообщается, что NVIDIA дала добро на проведение на этом предрелизном чипе тестов только для определённых рабочих нагрузок, соответствующих предполагаемым задачам/областям применения Vera в ЦОД, включая стандартные рабочие нагрузки, такие как компиляция, STREAM, кодирование видео, Python/Java и производительность СУБД. Исходя из среднего геометрического значения результатов тестов NVIDIA Vera занял первое место, превысив почти на 11 % лучшие результаты самых передовых разработок AMD, и примерно на 55,3 % показатели лучшей односокетной конфигурации Intel Xeon. Он также превзошёл в тестах двухсокетные конфигурации, что говорит о проблемах масштабирования некоторых рабочих нагрузок на нескольких сокетах. Эти ограниченные тесты отражают превосходство NVIDIA Vera по сравнению с любой архитектурой на базе Arm, с TDP 450 Вт для процессора и 50 Вт для пула памяти объемом 768 Гбайт. 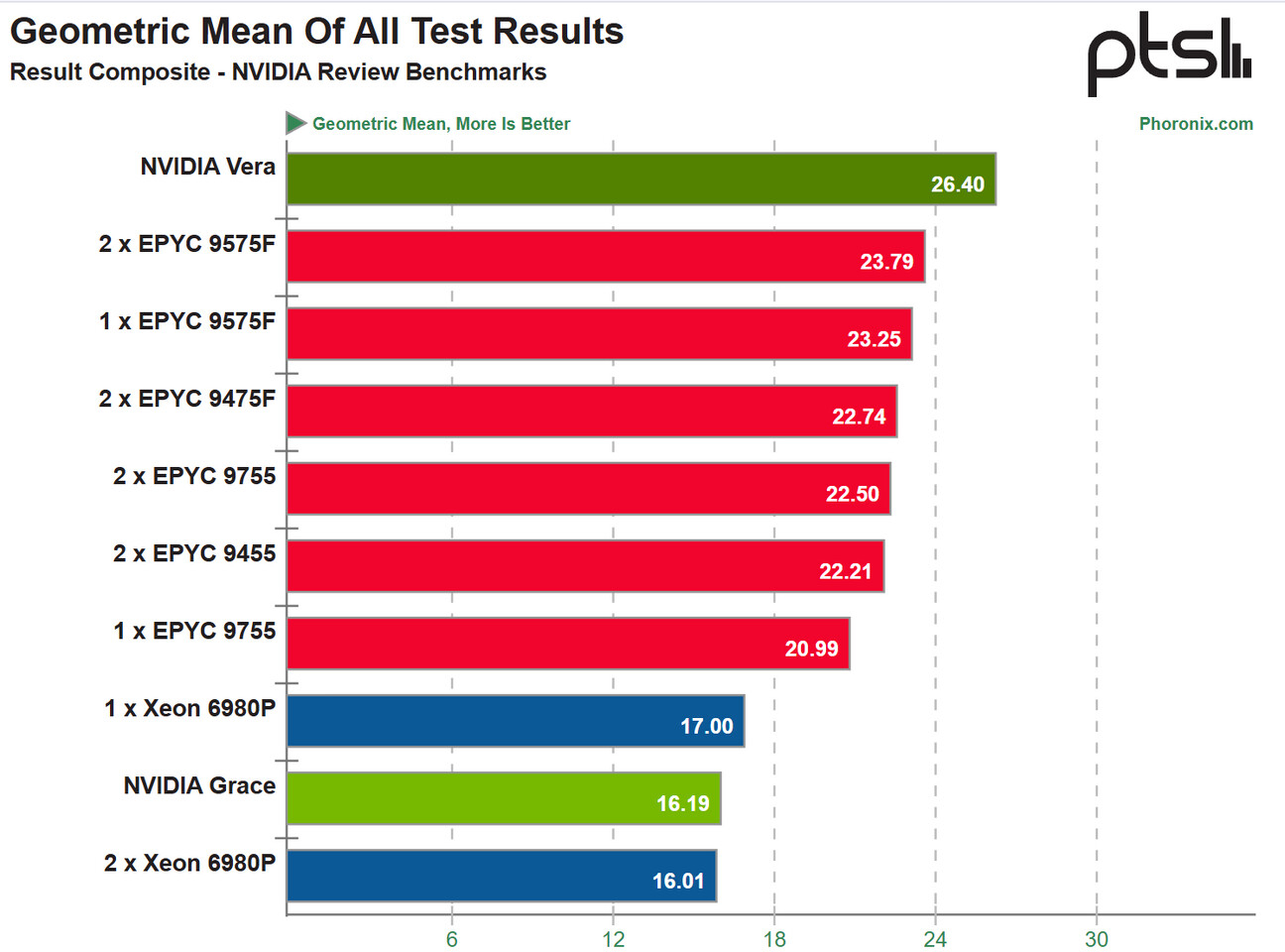
Источник изображения: Phoronix Предполагается, что NVIDIA продаст процессоров Vera и Grace на сумму около $20 млрд, охватив общий потенциальный рынок (TAM) в $200 млрд. NVIDIA сотрудничает со всеми крупными гиперскейлерами для поставки стоек с процессорами Vera (чаще всего в составе Vera Rubin), также наблюдается множество развёртываний у поставщиков инфраструктуры для их собственных задач и предложений для сторонних клиентов. Такой подход позволит NVIDIA выйти на огромный рынок процессоров, став одним из лидеров уже в этом году.
24.05.2026 [12:26], Сергей Карасёв
Dell представила рабочую станцию Pro Precision 7 R1 формата 1U с ускорителем NVIDIA RTX Pro BlackwellКомпания Dell Technologies анонсировала рабочую станцию Pro Precision 7 R1, рассчитанную на монтаж в стойку. Новинка, построенная на аппаратной платформе Intel, предназначена для ИИ-инференса, задач визуализации, 3D-рендеринга, индустриальных приложений и пр. Устройство комплектуется «настольным» процессором Core Ultra Series 2. Объём оперативной памяти DDR5 ECC может достигать 128 Гбайт. Во фронтальной части расположены два отсека для накопителей: могут устанавливаться NVMe SSD и HDD суммарной вместимостью до 64 Тбайт. Рабочая станция несёт на борту ускоритель NVIDIA RTX PRO 6000 Blackwell Workstation Edition. Установлены два блока питания мощностью 800 Вт с резервированием. Верхняя граница заявленного диапазона рабочих температур находится на отметке +35 °C. Устройство, как отмечается, может эксплуатироваться в условиях плотной компоновки стоек, в том числе на периферии сети. Прочие технические характеристики пока не раскрываются. 
Источник изображения: Dell Technologies Ключевым преимуществом рабочей станции Pro Precision 7 R1 компания Dell называет именно стоечное исполнение. Благодаря этому могут применяться централизованные модели развёртывания, что повышает безопасность, а также улучшает управляемость и эффективность использования ресурсов. Вместо распределения компьютеров между отдельными членами команды, организации могут объединять вычислительные ресурсы в защищённых дата-центрах, предоставляя при этом пользователям удалённый доступ к необходимым мощностям. В продажу новинка поступит в июле нынешнего года.
21.05.2026 [20:43], Владимир Мироненко
NVIDIA получила рекордную выручку благодаря ИИ-ускорителям и готовится освоить рынок серверных CPUNVIDIA объявила финансовые результаты за I квартал 2026 финансового года, закончившийся 26 апреля 2026 года. Несмотря на то, что результаты превзошли ожидания аналитиков по выручке и прибыли, а также был предложен более оптимистичный прогноз на II квартал, акции компании упали более чем на 2 %, вернувшись затем к прежнему уровню. Аналитик EMarketer Джейкоб Борн (Jacob Bourne) сообщил ресурсу SiliconANGLE, что неизбежное превышение прогнозов по прибыли уже было учтено в цене ещё до объявления результатов, отсюда и сдержанная реакция на отчёт. Компания сообщила о рекордной выручке в размере $81,62 млрд, что на 20 % больше, чем в предыдущем квартале, и на 85 % больше, чем годом ранее. Также это выше прогноза аналитиков, опрошенных LSEG, в размере $78,86 млрд (по данным CNBC). Скорректированная чистая прибыль на разводнённую акцию (Non-GAAP) составила $1,87, что на 18 % больше, чем в предыдущем квартале и на 140 % больше, чем годом ранее, а также больше консенсус-прогноза аналитиков Уолл-стрит в размере $1,76. Чистая прибыль (GAAP) выросла год к году на 211 % до $58,32 млрд или $2,39 на разводнённую акцию. 
Источник изображений: NVIDIA В текущем финансовом квартале NVIDIA прогнозирует выручку в размере около $91 млрд ± 2 %, что выше прогноза Уолл-стрит в $87,39 млрд. NVIDIA не учитывает в своем прогнозе выручку от ускорителей для ЦОД в Китае. Финансовый директор NVIDIA Колетт Кресс (Colette Kress) сообщила, что компания не получила никакой выручки от продажи чипов в Китай в отчётном квартале. Хотя ускорители H200 одобрены для экспорта в США, «мы пока не получили никакой выручки, и мы не уверены, будет ли разрешён импорт в [Китай]», — сказала Кресс. Продажи чипов компании в Китае находятся в подвешенном состоянии. Дональд Трамп (Donald Trump) одобрил продажу чипов NVIDIA в Китае, но заявил, что Си Цзиньпин (Xi Jinping) заблокировал их, пишет The Guardian. В интервью CNBC Хуанг осторожно оценил перспективы скорого открытия китайского рынка, который когда-то приносил компании пятую часть дохода от поставок решений для ЦОД. По его словам NVIDIA сообщила инвесторам, что «не стоит ожидать ничего» в отношении разрешений на продажу передовых чипов в страну. «У меня нет никаких ожиданий, поэтому мы ставим перед всеми нашими аналитиками и инвесторами цель ничего не инвестировать и ничего не ожидать», — сказал Хуанг. Он добавил, что NVIDIA по-прежнему будет стремиться вернуться в Китай, если ситуация улучшится. «Мы будем более чем рады обслуживать этот рынок, — сказал Хуанг. — У нас там много клиентов, много партнёров, и мы работаем там уже 30 лет». 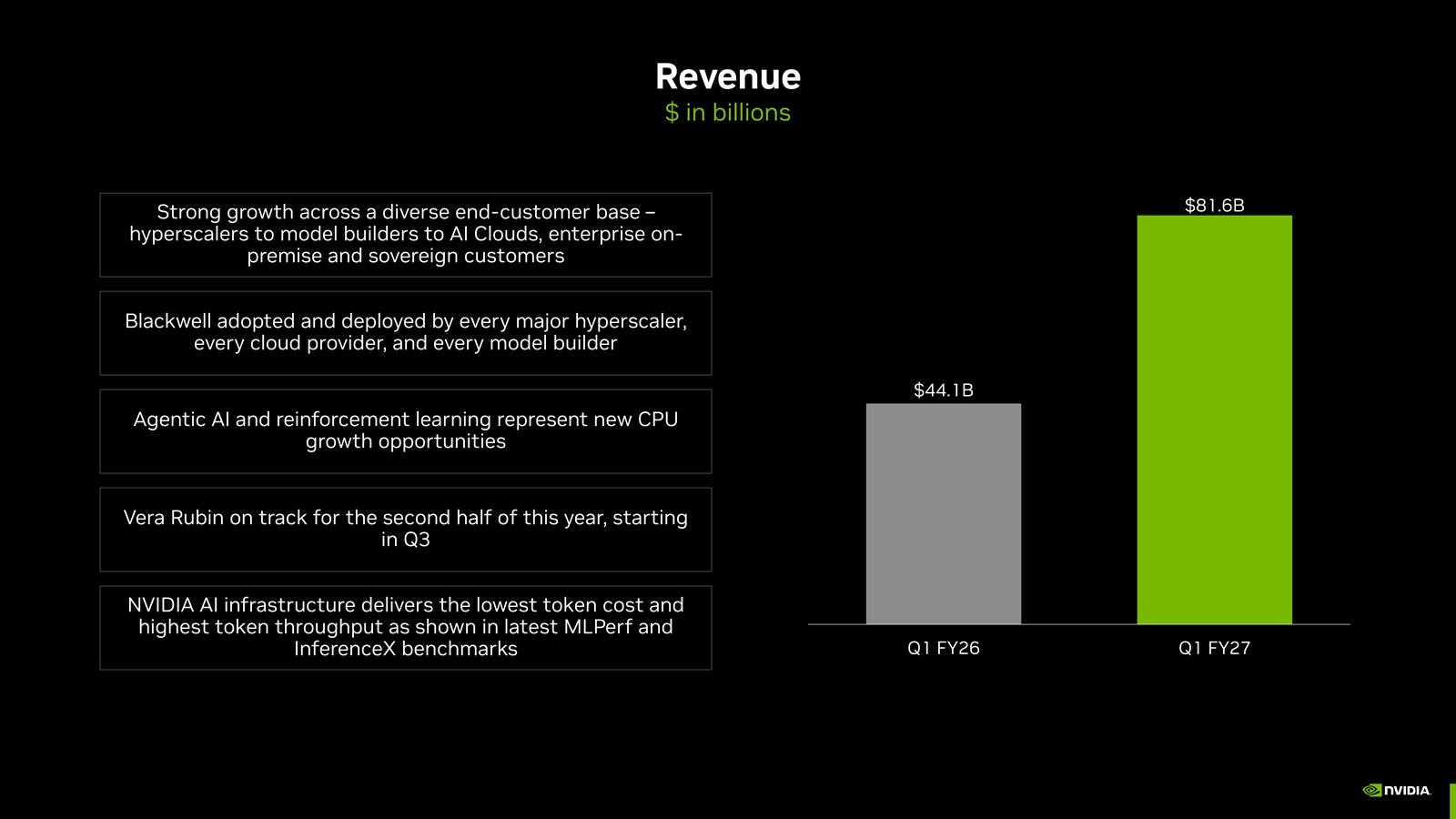 NVIDIA объявила о переходе на новую систему отчётности, которая, как утверждается, лучше отражает текущие и будущие факторы роста компании. NVIDIA будет отчитываться по двум сегментам — ЦОД и периферийные вычисления (Edge Computing). В свою очередь, сегмент ЦОД включает два субрынка: гиперскейлеры (Hyperscale) и ACIE, который включает в себя облачные решения для ИИ, промышленного и корпоративного рынков. Решения для гиперскейлеров будут включать доходы от публичных облаков и крупнейших мировых компаний, работающих в потребительском сегменте, в то время как ACIE учитывает возможности роста NVIDIA в различных специализированных ЦОД и ИИ-фабриках в разных отраслях и странах. Подразделение ЦОД обеспечило общую выручку в размере $75,2 млрд, что на 92 % больше, чем в предыдущем году. Аналитики Уолл-стрит прогнозировали $73,47 млрд. По словам Кресс, выручка от гиперскейлеров составила 50 % от продаж в сегменте ЦОД в этом квартале. Остальные 50 % поступили из различных источников, включая «облачные решения для ИИ, промышленные, корпоративные и государственные клиенты». Согласно предыдущему формату отчётности, выручка от вычислительных мощностей для ЦОД достигла рекордных $60,4 млрд, что на 77 % больше, чем годом ранее, и на 18 % больше по сравнению с предыдущим кварталом. Выручка от сетевого оборудования для ЦОД достигла рекордных $14,8 млрд, что на 199 % больше, чем годом ранее, и на 35 % больше по сравнению с предыдущим кварталом. 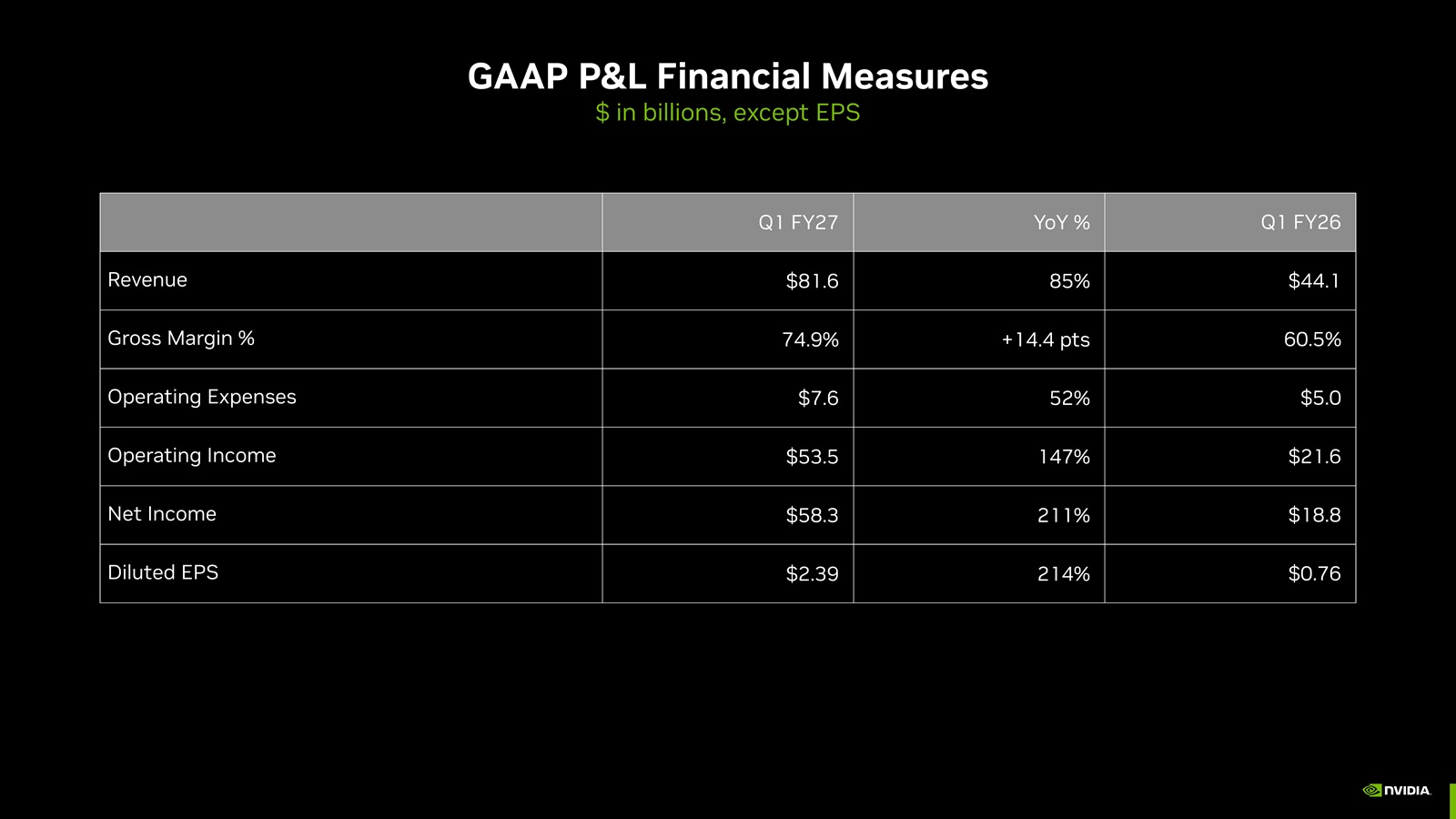 В сегменте Edge Computing будут учитываться продажи устройств обработки данных для агентного и физического ИИ, включая ПК, игровые консоли, рабочие станции, базовые станции AI-RAN, робототехнику и автомобильную промышленность. Этот сегмент принёс компании выручку в размере $6,4 млрд за квартал, что на 29 % больше, чем годом ранее. Гендиректор NVIDIA Дженсен Хуанг (Jensen Huang) объяснил решение о пересмотре способа отчётности по выручке, заявив, что это поможет аналитикам и инвесторам лучше понимать компанию. «Это самый простой способ понять наш бизнес, — сказал Хуанг. — Каждое из направлений имеет разные структуры во многих отношениях. У них разные операционные системы. Они работают по-разному, и мы выходим на рынок совершенно по-разному в каждом из них». В отчёте по форме 10-Q компания NVIDIA признала, что ситуация на рынке ЦОД изменилась, и её собственные клиенты потенциально могут стать конкурентами в полупроводниковой отрасли, разрабатывая специализированные компьютерные чипы, адаптированные под их собственные нужды. «Некоторые из наших клиентов разрабатывают собственные ASIC и другие продукты, включая проекты, оптимизированные для определенных рабочих нагрузок, которые могут не требовать всех функций и возможностей, предоставляемых нашими системами для ЦОД», — сообщила NVIDIA. Хотя она не назвала конкретных клиентов, известно, что такие компании, как Google, Amazon, Meta✴ и Microsoft разрабатывают собственные специализированные ASIC.  NVIDIA также указала, что другие клиенты «могут предлагать облачные сервисы, конкурирующие с нашими облачными сервисами для ИИ, и мы можем не суметь занять достаточную долю рынка для достижения масштаба, необходимого для выполнения наших бизнес-целей». «Если мы не сможем успешно конкурировать в этой среде, спрос на наши продукты, услуги и технологии может снизиться, что может негативно повлиять на наш бизнес», — отметила компания, добавив, что эти компании также могут «оказать влияние на нашу способность закупать достаточные производственные мощности и дефицитные исходные материалы в условиях ограниченных поставок, что может нанести ущерб нашему бизнесу». Колетт Кресс сообщила, что строительство ИИ ЦОД ускорилось, что привело к значительному росту стоимости инфраструктуры за последние несколько месяцев. Цена аренды ускорителя H100 выросла на 20 % с начала года, в то время как цены на облачные решения A100 за тот же период выросли почти на 15 %. Она добавила, что клиенты продолжают получать прибыль даже после истечения срока службы своих GPU. 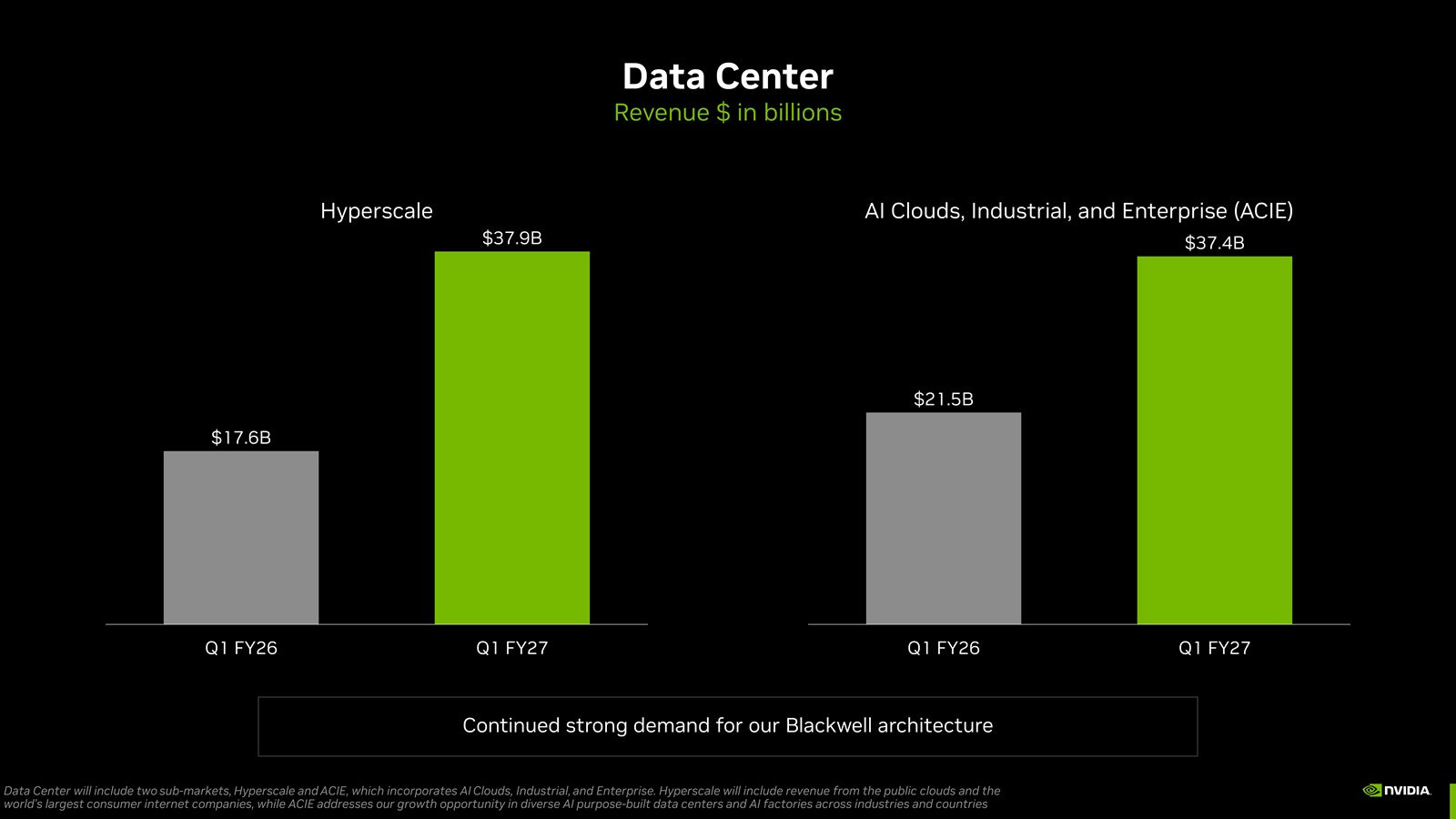 Кресс заявила, что NVIDIA не удовлетворена тем, что является мировым лидером только в области GPU, и также хочет стать «ведущим поставщиком CPU». В настоящее время в этой области доминируют такие конкуренты, как Intel и Advanced Micro Devices. По её словам, новые процессоры Vera открыли для компании «совершенно новый счёт в $200 млрд». «Все крупные производители систем для гиперскейлеров и системных провайдеров сотрудничают с нами для внедрения этой технологии», — сказала она, добавив, что, по её прогнозам, объём продаж процессоров в этом году составит около $20 млрд. Аналитик Хольгер Мюллер (Holger Mueller) из Constellation Research отметил размеры прибыли, полученной от инвестиций NVIDIA в стартапы (около $90 млрд) и другие финансовые операции, что способствовало увеличению чистой прибыли на $11,5 млрд. «Эти операции не даются бесплатно, поскольку компания использовала в пять раз больше денежных средств, чем год назад, на инвестиции, и примерно на 40 % больше финансирования», — сказал Мюллер. «Это означает, что у компании меньше свободных денежных средств, чем год назад. Это не вызывает серьёзных опасений, но подчеркивает, как изменилась эта компания. Теперь вопрос в том, как долго NVIDIA сможет продолжать расти на таком уровне? Всё внимание приковано к результатам Vera Rubin во II половине года», — добавил он.
20.05.2026 [09:09], Владимир Мироненко
От теории к практике ИИ: Dell анонсировала масштабное обновление платформы AI Factory with NVIDIA
dell
nvidia
software
ии
конфиденциальность
оркестрация
охлаждение
рабочая станция
сервер
схд
частное облако
Компания Dell Technologies объявила о масштабном обновлении платформы AI Factory with NVIDIA, призванном помочь предприятиям перейти от планирования к практическому применению ИИ. Платформа отличается модульной архитектурой данных для ИИ, где их преобразование, обработка и хранение работают вместе как специально разработанный стек. Компания отметила, что AI Factory используют более 5 тыс. клиентов по всему миру, и обновлённая версия платформы обеспечит более интегрированный подход к управлению данными и инфраструктурой, что позволит сократить время, необходимое для развёртывания решений ИИ. Одним из ключевых анонсов мероприятия стала презентация Dell Deskside Agentic AI. Это новое предложение, которое объединяет рабочие станции Dell, эталонный программный стек NemoClaw от NVIDIA и среду выполнения OpenShell, позволяя предприятиям создавать, запускать и управлять автономными агентами на системах, хранящих данные локально или на периферии сети, а не полагаться исключительно на облачную инфраструктуру. Dell позиционирует это предложение как решение для контроля затрат, снижения задержки и суверенитета данных, особенно для разработки ПО, исследований и регулируемых сред. Локальный подход разработан для таких секторов, как разработка ПО, академические исследования и регулируемые отрасли, позволяя этим группам хранить данные внутри компании и преобразовывать переменные расходы на облачные сервисы в предсказуемые инвестиции в инфраструктуру. Dell заявила, что этот подход позволит достичь паритета затрат с публичными облаками в течение трёх месяцев. 
Источник изображений: Dell Dell также интегрирует NVIDIA OpenShell во все продукты портфеля Dell AI Factory, чтобы обеспечить «безопасную песочницу для запуска, создания, тестирования и тонкой настройки агентов» локально. Это обеспечивает Dell единый уровень среды выполнения и политик, охватывающий все уровни — от настольных рабочих станций до серверов Dell PowerEdge XE, с поддержкой Ubuntu и Red Hat AI. Dell также продвигает эталонную архитектуру Dell-NVIDIA AI-Q 2.0, работающую на базе Dell AI Data Platform with NVIDIA, как готовую к продуктовому развёртыванию основу для многоагентных рабочих процессов в таких секторах, как финансовые услуги, производство и госсектор, где требуется более жёсткий контроль над данными и операциями. Dell объявила о ряде улучшений платформы Dell AI Data Platform. В ней были расширены возможности механизма оркестрации данных Dell AI Data Platform путём глубокой интеграции MetadataIQ со всем портфелем хранилищ Dell, начиная с PowerScale — файлового механизма в рамках Dell AI Data Platform with NVIDIA — и расширяя его на другие платформы в будущем. 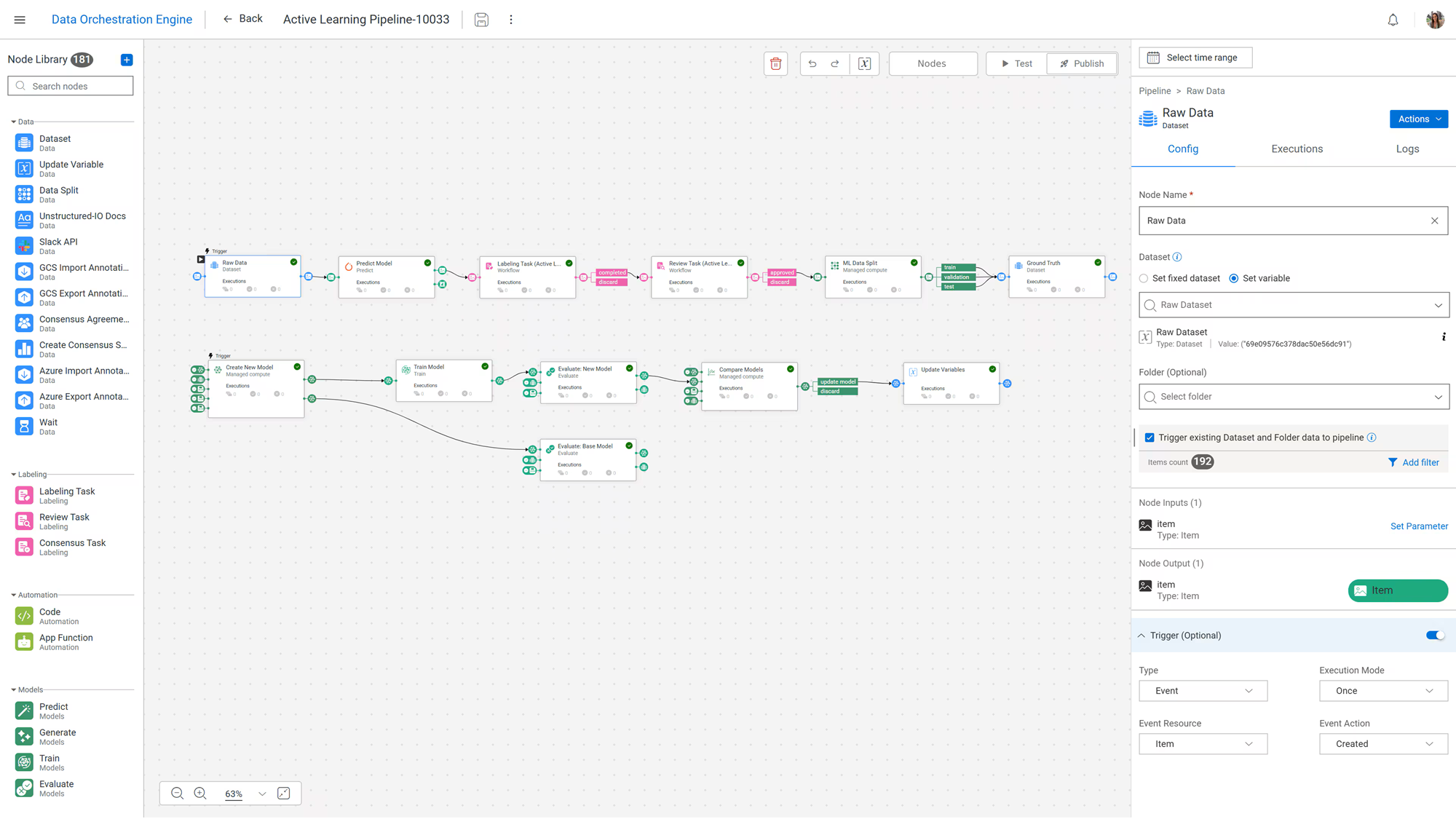 Уровень оркестрации теперь поддерживает индексирование миллиардов неструктурированных файлов и их привязку к управляемым конвейерам обработки данных. Благодаря партнёрству со Starburst и NVIDIA платформа предлагает аналитику SQL с ускорением на GPU через улучшенный Dell Data Analytics Engine, до шести раз быстрее на оборудовании NVIDIA Blackwell и с будущей поддержкой NVIDIA Vera. Это позволяет ускорить получение данных как для традиционной аналитики, так и для ресурсоёмких приложений ИИ с использованием агентов. Возможности хранения данных были расширены с помощью новой системы ObjectScale X7700, которая обеспечивает на 45 % большую ёмкость, чем предыдущее поколение, с гибким масштабированием вычислительных ресурсов и хранилища. В будущем появится поддержка флеш-накопителей объёмом 245 Тбайт, что более чем втрое увеличит плотность хранения. Благодаря интеграции с NVIDIA Omniverse корпоративные хранилища данных могут быть напрямую связаны с цифровыми двойниками и физическими рабочими процессами ИИ.  По мере роста объёма данных для ИИ, объектное хранилище становится логичным местом для обучающих данных, контрольных точек и долгосрочных баз знаний. Dell ObjectScale — объектный движок в рамках Dell AI Data Platform с NVIDIA — создан для выполнения этой роли, обладая высокопроизводительной архитектурой облачного масштаба и, по словам компании, лучшей в отрасли киберустойчивостью. Dell ObjectScale на серверах PowerEdge R7725xd также получил сертификацию NVIDIA Foundation, что означает его пригодность для высокоскоростного доступа к данным в средах с большим количеством GPU. Dell также расширила перечень инфраструктурных решений, запустив PowerRack, готовую систему стоечного масштаба, которая объединяет вычислительные ресурсы, сети, хранилище данных, охлаждение и управление в предварительно спроектированные блоки для развёртывания систем ИИ и HPC. Сообщается, что система может быть полностью настроена и введена в эксплуатацию в течение 6,5 ч. после доставки.  Как отметил ресурс Techzine, это не новая концепция, поскольку Dell поставляла комплексные решения и раньше, но компания расширяет возможности PowerRack по трём направлениям. Сетевой вариант обеспечивает коммутационную способность 800 Тбит/с благодаря восьми новым коммутаторам PowerSwitch SN6600 на стойку. Это в первую очередь предназначено для так называемого трафика east-west, поддерживающего рабочие нагрузки ИИ-инференса. Dell также интегрирует PowerFlex (решение «4-в-1») в свою архитектуру хранения данных Exascale, обеспечивая поддержку блочного, файлового и объектного хранения в стоечном исполнении через PowerFlex, PowerScale, Lightning File System и ObjectScale для нагрузок ИИ, HPC и ресурсоёмких корпоративных рабочих нагрузок. Dell также представила Pro Precision 7 R1 — стоечную рабочую станцию высотой 1U с ускорителями NVIDIA RTX PRO Blackwell Max-Q Workstation Edition и объёмом хранилища до 64 Тбайт. Обновлённые версии Dell Integrated Rack Controller и OpenManage Enterprise расширяют возможности на уровне стойки. В то же время новый PowerCool CDU C7000 разработан для отвода тепла от платформ NVIDIA следующего поколения в компактном стоечном форм-факторе. Это первый CDU для установки в стойку, отвечающий потребностям в охлаждении платформы NVIDIA Vera Rubin NVL72 в компактном форм-факторе 4U (19″) и расширяющий возможности охлаждения Dell и поддержку использования горячей воды с температурой до +40 °C.  Сообщается, что Dell PowerRack для вычислительных систем уже доступна, PowerRack для сетей будет доступна в сентябре 2026 года, а для хранилищ — во II половине 2026 года. Также уже доступны решение Dell Deskside Agentic AI, поддержка NVIDIA OpenShell, NVIDIA AI-Q 2.0 для Dell AI Factory и эталонная архитектура Dell-NVIDIA AI-Q 2.0. В свою очередь, Dell Pro Precision 7 R1 будет доступна в июле 2026 года, Data Orchestration Engine с MetadataIQ — во II квартале 2026 года, CDU — в III квартале 2026 года, а Data Analytics Engine with Starburst — в I квартале 2027 года. |
|

