Материалы по тегу: nvidia
|
20.05.2026 [09:09], Владимир Мироненко
От теории к практике ИИ: Dell анонсировала масштабное обновление платформы AI Factory with NVIDIA
dell
nvidia
software
ии
конфиденциальность
оркестрация
охлаждение
рабочая станция
сервер
схд
частное облако
Компания Dell Technologies объявила о масштабном обновлении платформы AI Factory with NVIDIA, призванном помочь предприятиям перейти от планирования к практическому применению ИИ. Платформа отличается модульной архитектурой данных для ИИ, где их преобразование, обработка и хранение работают вместе как специально разработанный стек. Компания отметила, что AI Factory используют более 5 тыс. клиентов по всему миру, и обновлённая версия платформы обеспечит более интегрированный подход к управлению данными и инфраструктурой, что позволит сократить время, необходимое для развёртывания решений ИИ. Одним из ключевых анонсов мероприятия стала презентация Dell Deskside Agentic AI. Это новое предложение, которое объединяет рабочие станции Dell, эталонный программный стек NemoClaw от NVIDIA и среду выполнения OpenShell, позволяя предприятиям создавать, запускать и управлять автономными агентами на системах, хранящих данные локально или на периферии сети, а не полагаться исключительно на облачную инфраструктуру. Dell позиционирует это предложение как решение для контроля затрат, снижения задержки и суверенитета данных, особенно для разработки ПО, исследований и регулируемых сред. Локальный подход разработан для таких секторов, как разработка ПО, академические исследования и регулируемые отрасли, позволяя этим группам хранить данные внутри компании и преобразовывать переменные расходы на облачные сервисы в предсказуемые инвестиции в инфраструктуру. Dell заявила, что этот подход позволит достичь паритета затрат с публичными облаками в течение трёх месяцев. 
Источник изображений: Dell Dell также интегрирует NVIDIA OpenShell во все продукты портфеля Dell AI Factory, чтобы обеспечить «безопасную песочницу для запуска, создания, тестирования и тонкой настройки агентов» локально. Это обеспечивает Dell единый уровень среды выполнения и политик, охватывающий все уровни — от настольных рабочих станций до серверов Dell PowerEdge XE, с поддержкой Ubuntu и Red Hat AI. Dell также продвигает эталонную архитектуру Dell-NVIDIA AI-Q 2.0, работающую на базе Dell AI Data Platform with NVIDIA, как готовую к продуктовому развёртыванию основу для многоагентных рабочих процессов в таких секторах, как финансовые услуги, производство и госсектор, где требуется более жёсткий контроль над данными и операциями. Dell объявила о ряде улучшений платформы Dell AI Data Platform. В ней были расширены возможности механизма оркестрации данных Dell AI Data Platform путём глубокой интеграции MetadataIQ со всем портфелем хранилищ Dell, начиная с PowerScale — файлового механизма в рамках Dell AI Data Platform with NVIDIA — и расширяя его на другие платформы в будущем.  Уровень оркестрации теперь поддерживает индексирование миллиардов неструктурированных файлов и их привязку к управляемым конвейерам обработки данных. Благодаря партнёрству со Starburst и NVIDIA платформа предлагает аналитику SQL с ускорением на GPU через улучшенный Dell Data Analytics Engine, до шести раз быстрее на оборудовании NVIDIA Blackwell и с будущей поддержкой NVIDIA Vera. Это позволяет ускорить получение данных как для традиционной аналитики, так и для ресурсоёмких приложений ИИ с использованием агентов. Возможности хранения данных были расширены с помощью новой системы ObjectScale X7700, которая обеспечивает на 45 % большую ёмкость, чем предыдущее поколение, с гибким масштабированием вычислительных ресурсов и хранилища. В будущем появится поддержка флеш-накопителей объёмом 245 Тбайт, что более чем втрое увеличит плотность хранения. Благодаря интеграции с NVIDIA Omniverse корпоративные хранилища данных могут быть напрямую связаны с цифровыми двойниками и физическими рабочими процессами ИИ.  По мере роста объёма данных для ИИ, объектное хранилище становится логичным местом для обучающих данных, контрольных точек и долгосрочных баз знаний. Dell ObjectScale — объектный движок в рамках Dell AI Data Platform с NVIDIA — создан для выполнения этой роли, обладая высокопроизводительной архитектурой облачного масштаба и, по словам компании, лучшей в отрасли киберустойчивостью. Dell ObjectScale на серверах PowerEdge R7725xd также получил сертификацию NVIDIA Foundation, что означает его пригодность для высокоскоростного доступа к данным в средах с большим количеством GPU. Dell также расширила перечень инфраструктурных решений, запустив PowerRack, готовую систему стоечного масштаба, которая объединяет вычислительные ресурсы, сети, хранилище данных, охлаждение и управление в предварительно спроектированные блоки для развёртывания систем ИИ и HPC. Сообщается, что система может быть полностью настроена и введена в эксплуатацию в течение 6,5 ч. после доставки.  Как отметил ресурс Techzine, это не новая концепция, поскольку Dell поставляла комплексные решения и раньше, но компания расширяет возможности PowerRack по трём направлениям. Сетевой вариант обеспечивает коммутационную способность 800 Тбит/с благодаря восьми новым коммутаторам PowerSwitch SN6600 на стойку. Это в первую очередь предназначено для так называемого трафика east-west, поддерживающего рабочие нагрузки ИИ-инференса. Dell также интегрирует PowerFlex (решение «4-в-1») в свою архитектуру хранения данных Exascale, обеспечивая поддержку блочного, файлового и объектного хранения в стоечном исполнении через PowerFlex, PowerScale, Lightning File System и ObjectScale для нагрузок ИИ, HPC и ресурсоёмких корпоративных рабочих нагрузок. Dell также представила Pro Precision 7 R1 — стоечную рабочую станцию высотой 1U с ускорителями NVIDIA RTX PRO Blackwell Max-Q Workstation Edition и объёмом хранилища до 64 Тбайт. Обновлённые версии Dell Integrated Rack Controller и OpenManage Enterprise расширяют возможности на уровне стойки. В то же время новый PowerCool CDU C7000 разработан для отвода тепла от платформ NVIDIA следующего поколения в компактном стоечном форм-факторе. Это первый CDU для установки в стойку, отвечающий потребностям в охлаждении платформы NVIDIA Vera Rubin NVL72 в компактном форм-факторе 4U (19″) и расширяющий возможности охлаждения Dell и поддержку использования горячей воды с температурой до +40 °C.  Сообщается, что Dell PowerRack для вычислительных систем уже доступна, PowerRack для сетей будет доступна в сентябре 2026 года, а для хранилищ — во II половине 2026 года. Также уже доступны решение Dell Deskside Agentic AI, поддержка NVIDIA OpenShell, NVIDIA AI-Q 2.0 для Dell AI Factory и эталонная архитектура Dell-NVIDIA AI-Q 2.0. В свою очередь, Dell Pro Precision 7 R1 будет доступна в июле 2026 года, Data Orchestration Engine с MetadataIQ — во II квартале 2026 года, CDU — в III квартале 2026 года, а Data Analytics Engine with Starburst — в I квартале 2027 года.
19.05.2026 [17:00], Руслан Авдеев
Arm-процессоры NVIDIA Vera поставили в ведущие ИИ-лаборатории мира — Oracle развернёт сотни тысяч таких CPUПервые CPU Vera, разработанные компанией NVIDIA, поставили в Anthropic, OpenAI, Oracle Cloud Infrastructure (OCI) и SpaceX/xAI. Процессоры специально разработаны с учётом особенностей «агентных» ИИ-систем и отличаются от обычных CPU. Это первый кастомный процессор NVIDIA, специально разработанный для агентных систем. Он обеспечивает оркестрацию, вызов инструментов, RL-нагрузки, анализ данных, «песочницы» для агентов и др. Процессор предназначен для ИИ-лабораторий, облачных провайдеров и компаний, масштабно работающих с агентными ИИ-системами. Модель получила 88 кастомных ядер Olympus, а пропускная способность памяти составляет 1,2 Тбайт/с. Глава NVIDIA Дженсен Хуанг (Jensen Huang) позиционирует Vera как новый многомиллиардный вектор развития компании. Как сообщает NVIDIA, агентный ИИ создаёт намного более высокую нагрузку на вычислительную инфраструктуру, от компиляции и тестирования программного кода до анализа данных, поиска файлов и др. При этом ИИ-агенты не просто используют ускорители, но и требуют оркестрации, управления агентными «песочницами», и т. п., это работа для CPU. Поток параллельных задач перегружает не рассчитанные на это CPU, но характеристики Vera позволяют повысить эффективность ИИ-фабрик целиком. 
Источник изображения: NVIDIA OCI намерена развернуть сотни тысяч CPU Vera для обеспечения работы нового поколения корпоративного ИИ. Это первый облачный провайдер, намеренный внедрить Vera в таких масштабах. Для корпоративных клиентов это означает, что будет создана агентная ИИ-инфраструктура уровня, недоступного другим облачным провайдерам. Ранее сообщалось, что Oracle строит «вчерашние» ЦОД, не имея на это достаточно средств и теперь, компания, похоже, готова опровергнуть этот тезис. 
Источник изображения: NVIDIA Процессор не только является самостоятельным CPU, но и лежит в основе платформы Vera Rubin NVL72, где он посредством NVLink-C2C второго поколения связан с парой GPU Rubin. Стоит отметить, что работы с Vera фактически ведутся уже давно. Например, ещё в марте HPE представила узлы на базе NVIDIA Vera для платформы Cray Supercomputing GX5000.
18.05.2026 [20:00], Руслан Авдеев
NVIDIA представила платформу Fleet Intelligence для мониторинга парка ИИ-ускорителей
dcim
nvidia
software
ии
информационная безопасность
кластер
конфиденциальность
мониторинг
облако
оркестрация
телеметрия
цод
NVIDIA представила управляемую платформу Fleet Intelligence, предназначенную для мониторинга состояния крупных кластеров ускорителей, используемых в ИИ-инфраструктуре. Сервис уже доступен бесплатно для клиентов, использующих продукты NVIDIA на основе ускорителей семейств Hopper, Blackwell и Vera Rubin. NVIDIA позиционирует платформу как независимый слой телеметрии и мониторинга, позволяющий отслеживать работу с гетерогенными инфраструктурными средами, независимо от стека оркестрации или планировщика задач. Платформа применяет «лёгкий», интегрируемый в хост-систему агент, который передаёт телеметрию с ИИ-ускорителей в облачную службу Fleet Intelligence, работающую в экосистеме платформы NGC (NVIDIA GPU Cloud). Агент применяет несколько технологий NVIDIA, включая службу мониторинга ускорителей — GPUd, инструмент управления и диагностики чипов DCGM (NVIDIA Data Center GPU Manager) и средства проверки целостности оборудования и ПО NVIDIA Attestation SDK. Компания также выложила код агента Fleet Intelligence на GitHub, что позволит операторам ИИ-инфраструктуры самостоятельно оценить механизмы телеметрии. Fleet Intelligence ведёт сбор данных о степени загруженности ускорителей, пропускной способности памяти, энергопотреблении системы, состоянии интерконнектов NVLink, температуре системы, ошибках ECC, а также показателях состояния аппаратной составляющей. Это помогает операторам ЦОД организовать раннее выявление недоиспользованных ресурсов и ошибок и снизить простои крупных ИИ-кластеров. 
Источник изображений: NVIDIA Одними из основных свойств платформы стали возможности проверки целостности и аттестации на основе технологий защищённых вычислений NVIDIA Confidential Computing. Fleet Intelligence проводит криптографическую валидацию прошивок ИИ-ускорителей и целостность среды выполнения с помощью корневых сертификатов доверия NVIDIA, а также сервиса удалённой проверки оборудования NRAS (NVIDIA Remote Attestation Service). Платформа может подтвердить, что ускорители используют утверждённую прошивку и использует манифесты целостности Reference Integrity Manifests, привязанные к определённым версиям vBIOS. 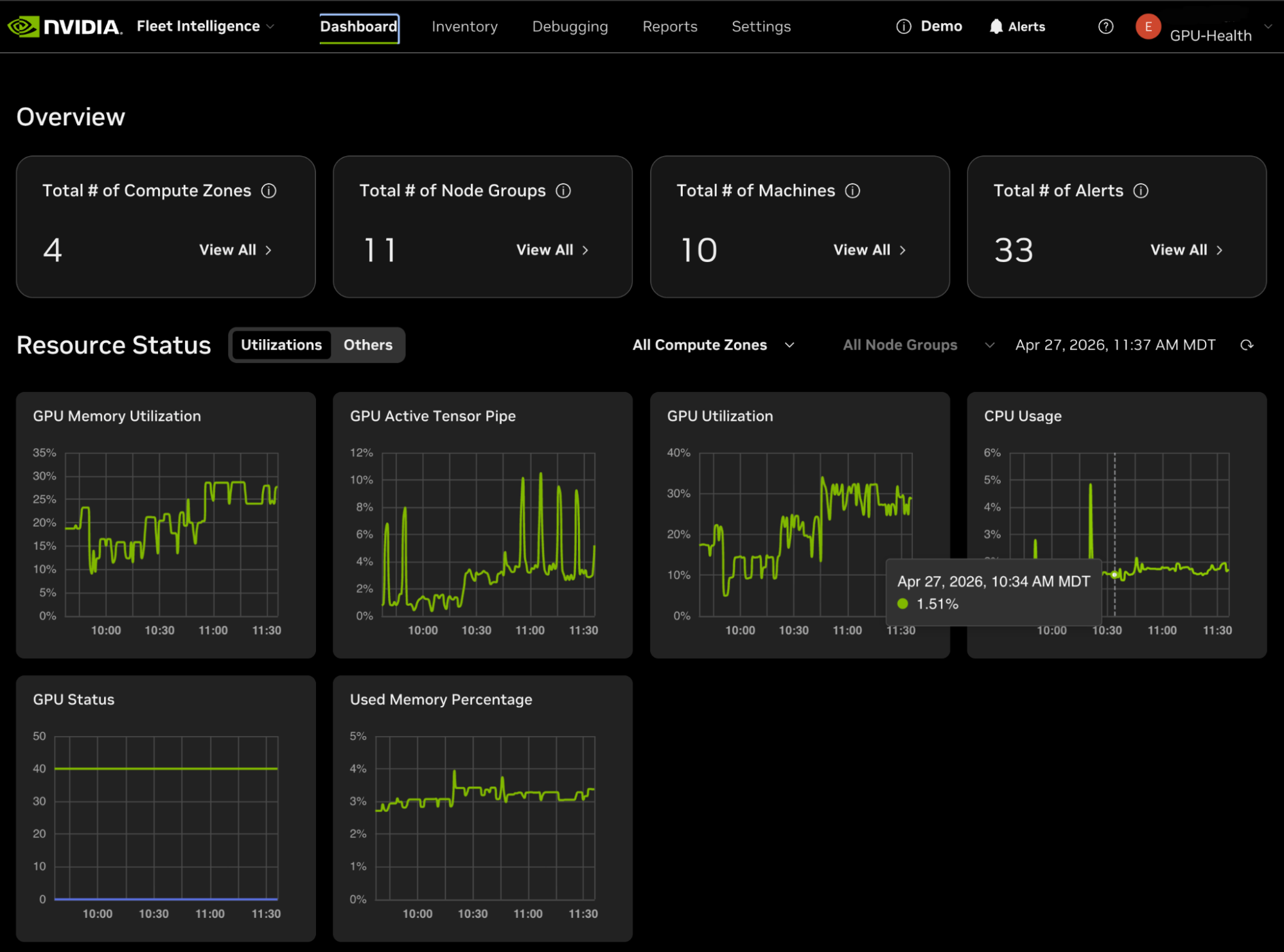 По словам NVIDIA, при разработке Fleet Intelligence применяли опыт эксплуатации облачных платформ NVIDIA DGX Cloud, использовавших сотни тысяч ИИ-ускорителей. В числе корпоративных пользователей, получивших ранний доступ к платформе — Lambda и Iren, обе предоставляли обратную связь в ходе работ. Премьера Fleet Intelligence свидетельствует, что амбиции NVIDIA простираются далеко за пределы простой разработки ИИ-ускорителей, компания развивает ПО и инструменты управления для ИИ-фабрик. Это дополнение уже имеющегося стека компании, включающего системы DGX, интерконнекты NVLink, сетевые продукты Spectrum-X, платформу оркестрации Mission Control и решения для защищённых вычислений.  Добавление масштабной телеметрии и предиктивной аналитики отражает растущий спрос гиперскейлеров и корпоративных клиентов на максимальное использование ресурсов ускорителей. Кроме того, премьера платформы является отражением роста конкуренции на рынке систем мониторинга и эксплуатации ИИ-инфраструктуры. Облачные операторы и другие компании, включая AMD, Intel и т.п., строят собственные платформы для телеметрии, диагностики и управления крупными ИИ-кластерами. Возможность NVIDIA интегрировать аппаратную телеметрию, проверку надёжности прошивок и операционную аналитику напрямую в инфраструктурный стек усиливает позиции компании в роли вертикально интегрированного поставщика ИИ-инфраструктуры.
15.05.2026 [00:29], Владимир Мироненко
США разрешили покупку NVIDIA H200 десяти китайским компаниям, но сделки застопорилисьВ преддверии визита президента США Дональда Трампа (Donald Trump) в Китай правительство страны разрешило десятку китайских компаний приобрести ИИ-ускорители NVIDIA H200, но их поставки пока так и не начались, сообщили источники агентства Reuters, знакомые с ситуацией. Как сообщается, глава NVIDIA Дженсен Хуанг (Jensen Huang) присоединился к американской делегации, и, как ожидается, предпримет усилия, чтобы разрешить зашедшую в тупик ситуацию с поставками. До ужесточения экспортных ограничений США компания NVIDIA контролировала около 95 % китайского рынка передовых чипов и на Китай приходилось 13 % её выручки. После ввода ограничений поставки чипов NVIDIA в Поднебесную практически сошли на нет. По оценкам Хуанга, объём ИИ-рынка в стране в этом году составит $50 млрд. Согласно данным источников, в число компаний, получивших разрешение на покупку H200, вошли Alibaba, Tencent, ByteDance и JD.com. Также добро получили несколько дистрибьюторов, включая Lenovo и Foxconn. Покупателям разрешено приобретать чипы либо напрямую у NVIDIA, либо через избранных посредников, и каждый получивший одобрение клиент может приобрести до 75 тыс. чипов в соответствии с условиями лицензирования США. Из всех названных компаний лишь Lenovo подтвердила Reuters факт получения лицензии на покупку американских чипов, остальные оставили без ответа запрос о комментариях. 
Источник изображения: NVIDIA По словам источников, несмотря на одобрение США, поставки H200 застопорились из-за отказа китайских фирм от сотрудничества после указания властей КНР. Это подтвердил министр торговли Говард Лютник (Howard Lutnick), заявивший на слушаниях в Сенате в прошлом месяце, что правительство Китая пока не позволяет компаниям покупать чипы, стремясь сосредоточить инвестиции на отечественной промышленности. Хотя китайские ИИ-чипы уступают решениям той же NVIDIA, китайские компании, как, например, DeepSeek, всё чаще полагаются на отечественные чипы, включая разработанные Huawei. Их переход на чипы Huawei подчёркивает шаткое положение NVIDIA в Китае. Хуанг неоднократно говорил, что экспортный контроль США подрывает позиции компании на местном рынке. При этом, по оценкам некоторых экспертов, у NVIDIA уже скопился запас из примерно 700 тыс. нереализованных H200. Следует отметить, что осуществление поставок H200 затруднено множеством требований с обеих сторон. В частности, США в январе одобрили правила, согласно которым от китайских покупателей требуется продемонстрировать наличие «достаточных мер безопасности» и подтвердить отказ от использования чипов в военных целях. NVIDIA также должна подтвердить наличие достаточных запасов чипов для американских клиентов. В свою очередь, Государственный совет КНР недавно издал два постановления о безопасности цепочек поставок, что побудило правительство заняться выявлением и устранением потенциальной зависимости от иностранных технологий в КИИ.
08.05.2026 [09:14], Сергей Карасёв
NVIDIA и Iren объединили усилия для создания ИИ-инфраструктуры мощностью до 5 ГВтКомпании NVIDIA и Iren (ранее Iris Energy) объявили о стратегическом партнёрстве с целью ускорения развёртывания инфраструктуры ИИ следующего поколения. Речь идёт о создании объектов суммарной мощностью до 5 ГВт, рассчитанных на наиболее ресурсоёмкие нагрузки. В рамках проекта планируется использовать платформу NVIDIA DSX. Это эталонная архитектура ИИ-фабрик, которая охватывает все уровни инфраструктуры — от отдельных ускорителей до сети. Благодаря DSX операторы крупных дата-центров могут максимизировать энергоэффективность, отказоустойчивость, масштабируемость и производительность ИИ-кластеров. При этом ускоряется их построение и снижаются эксплуатационные расходы. Цель нового партнёрства заключается в том, чтобы сократить время развёртывания крупномасштабных ИИ-фабрик путём объединения архитектуры DSX с опытом Iren в области энергетики, землепользования, ЦОД и инфраструктурных решений. Флагманским объектом будущей сети станет кампусе Iren Sweetwater мощностью 2 ГВт в Техасе (США). В перспективе реализуемый проект позволит предоставлять вычислительные мощности для задач ИИ корпоративным клиентам по всему миру. 
Источник изображения: Iren Генеральный директор NVIDIA Дженсен Хуанг (Jensen Huang) отмечает, что фабрики ИИ становятся одним из основополагающих компонентов мировой экономики. Однако развёртывание таких систем в масштабе требует глубокой интеграции по всему стеку — от вычислительных ресурсов и ПО до сетей и электропитания. Iren, по словам Хуанга, обладает необходимым опытом для выполнения этих комплексных работ. По условиям подписанного соглашения, Iren предоставит NVIDIA право на приобретение до 30 млн своих обыкновенных акций сроком на пять лет по цене $70/шт. Это даёт NVIDIA возможность инвестировать до $2,1 млрд при соблюдении определённых условий, включая требования регулирующих органов.
07.05.2026 [15:03], Сергей Карасёв
TotalEnergies создаст суперкомпьютер Pangea 5 за €100 млнФранцузская нефтегазовая компания TotalEnergies объявила о заключении соглашения с Dell Technologies и NVIDIA на создание нового суперкомпьютера под названием Pangea 5. Ожидается, что его ввод в эксплуатацию позволит увеличить вычислительные мощности TotalEnergies в шесть раз по сравнению с нынешними показателями (точные данные не приводятся). Технические подробности о будущей НРС-системе не раскрываются. Отмечается лишь, что в составе комплекса будут применяться «специализированные процессоры, рассчитанные на массово-параллельные вычисления». Речь идёт об ускорителях NVIDIA на основе GPU, а также о решениях InfiniBand и пр. Машина получит гибридное хранилище DDN ExaScaler. Инвестиции в проект Pangea 5 оцениваются в €100 млн. Суперкомпьютер расположится в Научно-техническом центре Жана Феже в По (Jean Féger Scientific and Technical Center at Pau — CSTJF) на юго-западе Франции. Там же смонтирована нынешняя машина Pangea 4, запущенная в июле 2024 года. По сравнению с этим комплексом при сопоставимой производительности общее энергопотребление Pangea 5 будет ниже примерно на 40 %, а потребление энергии системой охлаждения — меньше в пять раз. Тепло, генерируемое новым суперкомпьютером, планируется использовать для отопления зданий CSTJF, в которых работают более 2,5 тыс. человек. 
Источник изображения: TotalEnergies Компания TotalEnergies будет использовать Pangea 5 для ресурсоёмких вычислений с применением передовых методов сейсморазведки для повышения точности визуализации недр и ускорения геологоразведочных работ. Кроме того, суперкомпьютер поможет в реализации проектов, связанных с ИИ. Запуск вычислительного комплекса намечен на следующий год.
06.05.2026 [22:12], Владимир Мироненко
Corning построит в США три завода по выпуску оптоволокна для ИИ ЦОД с чипами NVIDIANVIDIA и Corning объявили о долгосрочном партнёрстве с целью расширения производства в США решений для оптической связи для ИИ-инфраструктуры. Corning построит в Северной Каролине и Техасе три завода по производству средств оптической связи для ЦОД, что позволит создать по меньшей мере 3000 рабочих мест и обеспечить десятикратное увеличение производственных мощностей Corning по выпуску оптики в США. Также это увеличит мощности Corning по производству оптоволокна в США более чем на 50 %, что будет способствовать удовлетворению растущего спроса отрасли. По мере развёртывания ИИ-инфраструктуры оптическая связь становится её важным компонентом. «ИИ является движущей силой крупнейшего в наше время развития инфраструктуры и уникальной возможностью оживить американское производство и цепочки поставок, — заявил основатель и генеральный директор NVIDIA Дженсен Хуанг (Jensen Huang). — Вместе с Corning мы создаем будущее вычислительной техники с использованием передовых оптических технологий — создаём основу для ИИ-инфраструктуры, в которой интеллект развивается со скоростью света». Как сообщает Sherwood News, в рамках сделки Corning предоставила NVIDIA два типа варрантов: предварительно финансируемый (Pre-funded) варрант на покупку до 3 млн акций за $500 млн, а также традиционные варранты, предоставляющие NVIDIA право на покупку до 15 млн акций Corning по цене $180 на сумму до $3,2 млрд, тем самым получая выгоду от того, что цена акций Corning превысит этот уровень в течение трёх лет (если только это партнёрство не будет расторгнуто или Corning не совершит «фундаментальную сделку» до этого). 
Источник изображения: Corning После анонса партнёрства с NVIDIA акции Corning взлетели на более чем на 19 %, сообщает Reuters. Corning также повысила свои долгосрочные цели по продажам в связи с растущим спросом на оптику для ИИ-инфраструктуры. Ранее Corning заявила, что ожидает увеличить годовую регулярную выручку (ARR) до $20 млрд к концу этого года. Компания также планирует к концу 2028 года увеличить годовой оборот до $30 млрд, а к концу 2030 года — до $40 млрд. В январе Corning заключила сделку с Meta✴ на поставку оптоволоконных кабелей для ИИ ЦОД на сумму до $6 млрд в течение периода до 2030 года. Также компания будет выпускать полое волокно (HFC) для дата-центров Microsoft Azure. Ранее NVIDIA инвестировала $4 млрд в поставщиков лазеров и фотоники для ИИ ЦОД Lumentum и Coherent, а также зарезервировала у всех ключевых поставщиков значительную часть мощностей по производству EML-лазеров, необходимых для выпуска оптических модулей связи, что отразилось на доступности компонентов для остальных компаний.
06.05.2026 [11:52], Руслан Авдеев
Nscale развернёт более 66 тыс. ИИ-ускорителей NVIDIA Rubin в Португалии в интересах MicrosoftБританская Nscale рассчитывает развернуть на территории португальской площадки Start Campus более 66 тыс. ИИ-ускорителей NVIDIA Rubin в интересах крупного клиента — компании Microsoft. Речь идёт об одном из крупнейших развёртываний NVIDIA Vera Rubin NVL72 в Европе. Это значительно расширит действие договора между Microsoft и Nscale. В его рамках первая брала на себя обязательства развернуть 12,6 тыс. NVIDIA GB300 в ЦОД в Синеше (Sines, Португалия). Ускорители поколения Blackwell Ultra разместятся в первом построенном здании Start Campus, а в рамках нового, расширенного соглашения Nscale намерена инвестировать в проект ещё €230 млн ($268,9 млн) в общую для кампуса инфраструктуру и ещё €465 млн ($543,7 млн) — в строительство нового здания мощностью 200 МВт на территории того же кампуса. Развёртывание ИИ-ускорителей Rubin компания Nscale начнёт в конце 2027 года. По словам представителя Nscale, речь идёт об одной из крупнейших инвестиций в ИИ-инфраструктуру в истории Португалии и одну из наиболее значимых для Евросоюза. Косвенно это отражает рост спроса на сервисы Nscale. По данным руководства Start Campus, Синиш — один из ведущих европейских хабов для внедрения ИИ, укрепляющий способность Европы реализовать суверенные проекты на основе устойчивости, отказоустойчивости, а также долгосрочного планирования. 
Источник изображения: Start Campus Предполагается, что Start Campus в Синише будет иметь мощность 1,2 ГВт. Первый ЦОД SIN01 мощностью 26 МВт запущен в январе 2025 года. Всего запланировано строительство шести зданий. Ожидается, что кампус будет полностью обеспечен возобновляемой энергией, разработчики рассчитывают добиться PUE 1,1 и WUE 0 благодаря использованию для охлаждения океанских вод. Ранее сообщалось, что Microsoft намерена инвестировать $10 млрд в ИИ ЦОД на территории кампуса. Microsoft и Nscale уже реализуют ряд проектов, в т.ч. в Норвегии, Великобритании и США. Ранее компания объявила, что Microsoft в рамках партнёрства будут предоставлены в общей сложности 116 тыс. ИИ-ускорителей NVIDIA GB300. В апреле 2026 года Microsoft заключила соглашение о поставке ещё 30 тыс. ускорителей NVIDIA Rubin в Норвегию.
04.05.2026 [10:46], Руслан Авдеев
Трудный выбор: телеком-операторы хотят и ИИ внедрить, и сэкономить, и избежать привязки к одному поставщикуТелеком-оператор Orange заявил о намерении найти оптимальный вариант для будущих сетей радиодоступа (RAN) на фоне развития ИИ-технологий. Компания предполагает, что ставка на ИИ поможет повысить эффективность мобильных сетей, сообщает блог IEEE ComSoc. Orange уже использует специально разработанные для 5G аппаратные и программные решения Nokia, до недавних пор необходимости в продуктах NVIDIA в сетях компании не было. Тем не менее, последняя сблизилась с Nokia в октябре 2025 года, приобретя 3 % долю в рамках инвестиций в объёме $1 млрд. Сейчас Nokia разрабатывает AI-RAN решения, оптимизированные для использования с ИИ-ускорителями. В немалой степени интерес Orange к ИИ-ускорителям объясняется довольно высокой стоимостью специализированных чипов (ASIC), традиционно применяемых в RAN. Их можно заменить ускорителями «общего назначения». Оправдать разработку и производство кастомных чипов довольно трудно, поскольку их цена высока, а рынок под эти продукты довольно мал и продолжает сокращаться. По данным Omdia, ежегодные расходы телеком-операторов сократились с $45 млрд в 2022 году до приблизительно $35 млрд и больше не растут, а применять такие чипы за пределами телеком-отрасли нецелесообразно. 
Источник изображения: Sophia Kunkel/unsplash.com В теории массовые продукты NVIDIA позволяют быстро и относительно экономично масштабировать RAN-сети 5G/6G и улучшить их экономику. При этом кастомные ASIC хоть и дорого, зато эффективнее и энергоэкономичнее для своих задач, а ИИ-ускорители, вероятно, чересчур производительны и энергоёмки. При этом NVIDIA остаётся финансово мощным игроком с высокой маржинальностью, что делает её привлекательным партнёром. Впрочем, Orange ожидает, что Nokia и NVIDIA разработают нечто намного более компактное, чем ускорители для дата-центров класса Blackwell, для шасси AirScale. В то же время Orange изучает возможность замены традиционных алгоритмов L1-уровня для использования ИИ-решений и повышения спектральной эффективности. 
Источник изображения: MingJun He/unspalsh.com Замена ASIC на ИИ-ускорители или CPU обсуждается не впервые. Так, Ericsson и Samsung уже давно предлагают облачные RAN-решения на процессорах Intel. Кроме того, ПО для таких процессоров при желании относительно легко переделать для использование с чипами на архитектуре x86 других производителей или даже Arm. Впрочем, пока крупнейшие поставщики оборудования, включая Ericsson и Huawei, продолжают активно вкладывать средства в собственные ASIC. Под вопросом положение и самой Intel, поскольку компания переживает не лучшие времена, а её сетевое подразделение NEX проходит через серию трансформаций. Использование ИИ-ускорителей тоже имеет значимые изъяны. В случае NVIDIA операторы будут зависеть от экосистемы CUDA, что ограничит возможность использования ПО с другим «железом». Orange признаёт опасность «привязки» к одному вендору, но считает, что преимущества масштабируемых архитектур «общего назначения» перевешивают риски, поскольку позволяют снизить совокупную стоимость владения (TCO). Впрочем, Orange не отказались бы от архитектуры, позволяющей сменить поставщика в случае необходимости. По данным IEEE ComSoc, Nokia всё-таки надеется, что значительная часть ПО, написанного для ускорителей NVIDIA, в будущем будет неким образом оптимизировано для использования с другими аппаратными платформами, в том числе и с CPU. Пока же почти монопольное положение NVIDIA оставляет участникам рынка немного альтернатив. Ericsson же пока остаётся верна кастомным ASIC. Для топ-менеджеров телеком-отрасли выбор, сделанный в следующие пару лет, может оказаться решающим для всей отрасли, поскольку на подходе уже сети 6G, внедрение которых должно начаться в 2030 году.
02.05.2026 [13:22], Сергей Карасёв
AMD EPYC и NVIDIA RTX Pro Blackwell: QNAP представила хранилище QAI-h1290FX для ИИ-задачКомпания QNAP Systems анонсировала сервер хранения QAI-h1290FX, предназначенный для решения ИИ-задач на периферии. Устройство подходит для работы с большими языковыми моделями (LLM), генеративными приложениями, поисковыми сервисами на базе RAG и пр. 
Источник изображений: QNAP Systems Новинка построена на платформе AMD с процессором EPYC Rome 7302P (16C/32T; до 3,3 ГГц). Объём оперативной памяти DDR4 ECC в базовой конфигурации составляет 128 Гбайт, в максимальной — 1 Тбайт. Во фронтальной части расположены 12 отсеков для SFF-накопителей U.2 с интерфейсом PCIe 4.0 x4 (NVMe) или SATA-3 с возможностью горячей замены.  Система оснащена тремя слотами PCIe 4.0 x16 и одним слотом PCIe 4.0 x8. Возможна установка GPU-ускорителя NVIDIA RTX Pro 6000 Blackwell Max-Q Workstation Edition с 96 Гбайт памяти GDDR7 или NVIDIA RTX Pro 4500 Blackwell с 32 Гбайт памяти GDDR7. В первом случае обеспечивается возможность использования LLM с более чем 70 млрд параметров, во втором — 30 млрд параметров. Применена ОС QuTS hero h5.2.9. Упомянуты такие предустановленные ИИ-инструменты, как AnythingLLM, OpenWebUI, Ollama, Stable Diffusion, ComfyUI, n8n и vLLM. 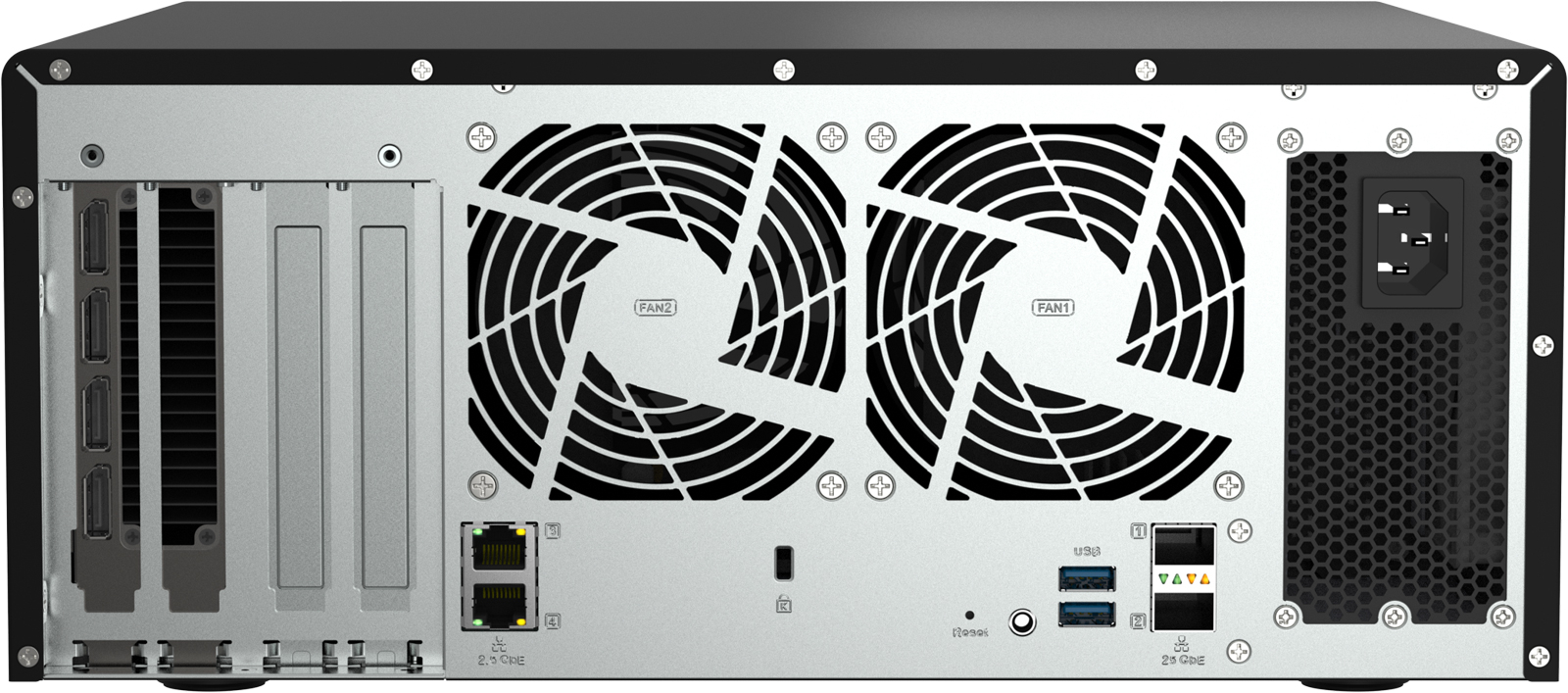 Устройство располагает двумя портами 2.5GbE и двумя 25GbE-портами SFP28 (SmartNIC), а также тремя разъёмами USB 3.0 Type-A (один находится спереди, два — сзади). Дополнительно может быть установлен сетевой адаптер 100GbE. Габариты сервера составляют 150 × 368 × 362 мм, масса — 10,4 кг. Диапазон рабочих температур — от 0 до +40 °C. Задействованы два вентилятора охлаждения диаметром 92 мм и блок питания мощностью 750 Вт. Производитель предоставляет на новинку пятилетнюю гарантию. |
|

