Материалы по тегу: сбой
|
26.06.2026 [16:45], Руслан Авдеев
Британская больница Queen Alexandra объявила о критическом инциденте — чиллеры её ЦОД отказали на фоне рекордной жарыНа фоне рекордной жары больница Queen Alexandra Hospital в британском Портсмуте (Portsmouth) объявила о критическом инциденте в своём ЦОД. В расположенном на территории больницы объекте перестали функционировать чиллеры, что вызвало сбои в работе цифровых сервисов, сообщает Datacenter Dynamics. В результате пришлось перенести часть плановых приёмов и процедур, а посетителей предупреждают, что в госпитале «очень жарко». При этом в Великобритании температура воздуха достигает 35 °C и более из-за мощного антициклона и климатических изменений антропогенного характера. Британские метеорологи объявили красный уровень опасности в связи с экстремальной жарой. В 2022 году лондонские дата-центры тоже столкнулись со сбоями из-за жары. Тогда даже пришлось поливать из шланга охлаждающее оборудование на крышах. 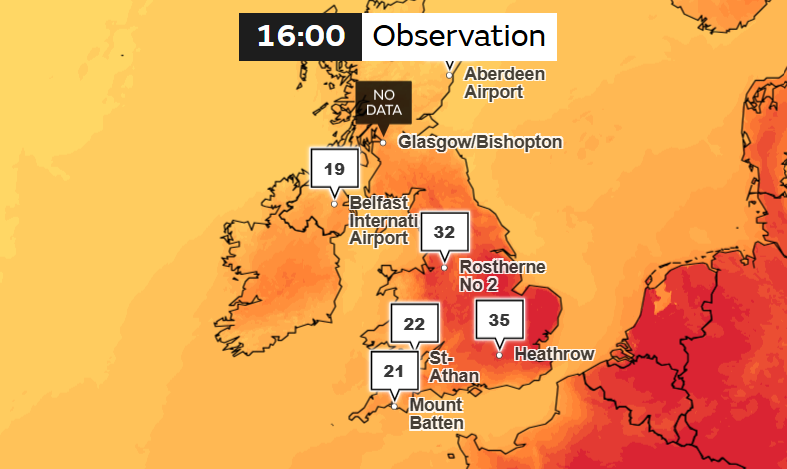
Источник изображения: Met Office Согласно заявлению больницы, текущий сбой в работе охлаждающих мощностей привёл к росту температуры в ряде помещений, что сказалось и на работе цифровых систем, и критически важных служб больницы, в т.ч. операционных, отделений диагностики и др. По словам организации Portsmouth Hospitals University NHS Trust, курирующей больницу, специалисты прилагают все усилия для ремонта повреждённого оборудования и обеспечения дальнейшего оказания медицинской помощи. Ранее расследование Национаной системы здравоохранения (NHS) показало, что сбой в работе двух лондонских больницы из-за жары в 2022 году обошёлся в £1,4 млн ($1,7 млн). Тогда из строя вышли дата-центры, поддерживавшие работу больниц, находившихся в ведении Guy’s and St Thomas’ NHS Foundation Trust. В результате зарегистрировано более 100 задержек с оказанием медицинской помощи, а один из пациентов не дождался своевременной трансплантации органа, что принесло «умеренный вред» его здоровью. На полное восстановление сервисов ушло шесть недель. Ещё в декабре 2025 года исследование Rest of World показало, что около 80 % всех дата-центров мира построены в не слишком подходящих климатических условиях. В июне компания First Street, занимающаяся финансовым моделированием климатических рисков, пришла к тем же выводам, объявив, что 79 % мировых мощностей ЦОД подвержены «серьёзным климатическим угрозам». В категории с наибольшим уровнем климатического риска — Северная Вирджиния, Джохор и Марсель.
25.06.2026 [14:43], Руслан Авдеев
Пожар из-за литиевых АКБ в индийском ЦОД STT GDC нанёс масштабный ущерб Google и другим компаниямНедавний пожар в одном из дата-центров в Индии привёл к значительному ущербу и затронул интересы сразу нескольких клиентов. В начале июня Tata Communications опубликовала краткую информацию для акционеров, сообщив о возгорании на площадке в здании Next-Gen Tower, расположенном в районе Greater Kailash-1 в Нью-Дели, сообщает Datacenter Dynamics. Пожар, причиной которого, как предварительно считается, стало возгорание литиевых аккумуляторов, своевременно взяли под контроль пожарные, поэтому никто не пострадал. Дата-центр STT Delhi 2 мощностью всего 1,1 МВт используется STT GDC. В результате инцидента пострадали сервисы Google Cloud, поскольку возгорание заставило отключить сетевое оборудование, обеспечивавшее работу локальной точки присутствия Google. Полностью работу сетевых сервисов восстановить до сих пор не удалось. В обновлении 23 июня Google сообщала, что её команда получила доступ к пострадавшей площадке и будет наращивать сетевые мощности в течение недели. Компания оптимизировала доступную ёмкость и намерена расширить магистральную ёмкость в Дели. Она продолжает отслеживать проблемы с задержками и потерями пактов данных. Следующий отчёт об инциденте будет выпущен в понедельник. 
Источник изображения: Dave Hoefler/unsplash.com По данным СМИ, пожар вызвал «масштабный ущерб», письма об этом направлены клиентам и аналитикам. В частности, Matrix Cellular, занимающаяся международными SIM-картами, заявила, что имеет трудности с восстановлением данных за 20 лет, потерянных в результате пожара. По оценкам индийского интернет-провайдера R2 Net, ущерб компании составил $2 млн, а сейчас она теряет из-за сбоя корпоративных клиентов. Ранее пожары в ЦОД привели к крупным сбоям телеком-систем целых стран в Бангладеш и Иране. Также европейские сервисы Google Cloud серьёзно пострадали в 2023 году в результате пожара в парижском ЦОД Global Switch. Tata продала 74 % бизнеса ЦОД в Индии и Сингапуре компании STT GDC в 2016 году и до сих пор хранит оставшуюся часть акций. Совместное предприятие управляет десятками дата-центров в Индии. Услуги в сфере информационно-телекоммуникационных технологий до сих пор предоставляются Tata из десятков ЦОД по всему миру, многие из которых арендованы. В том числе речь идёт об облачных сервисах. Недавно было объявлено о намерении вернуться к бизнесу в сфере ЦОД и построить до 1 ГВт мощностей в Индии при посредничестве дочерней структуры HyperVault.
18.06.2026 [16:38], Руслан Авдеев
Сирия подозревает, что подводный интернет-кабель, связывающий страну с Египтом, повреждён в результате «систематического саботажа»По данным принадлежащей сирийскому государству телеком-структуры Syrian Telecommunications Company (SyTC), подводный кабель, связывающий Сирию и Египет, оборван — на его ремонт уйдёт некоторое время. Хотя официальных виновников не называли, СМИ сообщают, что власти в Дамаске называют причиной происшествия «систематическую кампанию саботажа», сообщает Tom’s Hardware. Пока трафик направляется через другую подводную магистраль, ведущую на Кипр, и через наземный кабель, пролегающий через Турцию. Тем не менее, инцидент сказался на качестве связи во всей стране. Несмотря на критическую важность кабелей для любого государства, эта инфраструктура довольно уязвима и зачастую кабели буквально лежат на морском дне или заглублены в грунт на 0,5–1,5 м. В результате их довольно легко повредить преднамеренно или даже случайно, в том числе рыболовными тралами, якорями и др. Охранять подобные цифровые магистрали довольно сложно, поскольку они тянутся на огромные расстояния, а для полноценной охраны каждого километра нет ресурсов ни у одного государства в мире. 
Источник изображения: JOE Planas/unspalsh.com По данным Datacenter Dynamics, в последние годы кабели несколько раз повреждались судами, которые западные СМИ относят к т.н. «теневому флоту». Например, в конце января 2025 года зафиксировано повреждение подводного оптоволоконного кабеля компании LVRTC, соединяющего Латвию и Швецию. Ещё раньше получили повреждения четыре интернет-кабеля и один силовой. А ещё раньше, в ноябре 2024 года, были повреждены интернет-кабели, связывающие Финляндию и Германию, Литву и Швецию. Впрочем, финские спецслужбы сомневаются, что Россия стала бы преднамеренно повреждать кабели. Повреждения неоднократно регистрировались и на Ближнем Востоке, особенно в Красном море, являющемся ключевым узлом связи между Европой и Азией. Тайвань также наращивает патрулирование подконтрольной акватории вблизи 24 подводных кабелей, особенно в свете того, что сотни внесённых в «чёрный список» связанных с материковым Китаем судов постоянно находятся вблизи от островной инфраструктуры и один из инцидентов даже закончился тюремным заключением для китайского капитана.
15.06.2026 [17:56], Руслан Авдеев
Индийские клиенты Google Cloud уже неделю мирятся со сбоями сети из-за пожара в ЦОД в ДелиКлиенты облачных сервисов Google Cloud с ресурсами, размещёнными в Индии, вынуждены иметь дело с повышенными задержками в течение почти недели. Возвращения к нормальной работе пока не предвидится, сообщает The Register. По данным самой Google, 9 июня пожар в одном из сторонних ЦОД в Дели, используемому компанией, вынудил срочно отключить питание сетевого оборудования. В результате была изолирована одна из локальных точек присутствия (POP), доступная ёмкость сети в местной городской агломерации значительно снизилась. Отключение привело к периодическому повышению задержек и потере пакетов данных при работе с Google Cloud из Дели, Ченнаи, Мумбаи и окружающих районов. Как отметила компания, клиенты «могут испытывать» слегка увеличившиеся задержки и «неоптимальную» сетевую маршрутизацию в Google Cloud до тех пор, пока пострадавший объект полностью не восстановится. 
Источник изображения: Lai Man Nung/unsplash.com Google применила меры по «оптимизации трафика», которые, как утверждают в компании, уже позволили улучшить производительность «для некоторых клиентов Cloud», и теперь компания пытается добавить дополнительные пиринговые соединения. Также компания работает над улучшением региональной пиринговой ёмкости в Ченнаи, чтобы помочь крупным интернет-провайдерам Индии и надеется, что работа будет закончена в среду, 17 июня. Ранее пожары в ЦОД привели к крупным сбоям телеком-систем целых стран в Бангладеш и Иране. Также европейские сервисы Google Cloud серьёзно пострадали в 2023 году в результате пожара в парижском ЦОД Global Switch.
08.06.2026 [10:43], Владимир Мироненко
В Yandex Cloud произошёл сбой в расчёте начисленийВ минувшую пятницу, 5 июня, на платформе Yandex Cloud произошёл сбой, из-за которого в расчёте начислений за ресурсы из Marketplace наблюдались ошибки, а у ряда пользователей были произведены несанкционированные списания за неиспользуемые ресурсы. В Yandex Cloud подтвердили факт сбоя и предупредили пользователей о приостановке обработки биллинга. «Обнаружена ошибка в расчёте начислений для части ресурсов. Для предотвращения некорректных списаний обработка биллинга была временно остановлена. После устранения причины будут выполнены необходимые корректировки начислений», — сообщили в компании. Как указано в описании инцидента, сбой затронул следующие зоны: ru-central1-e, ru-central1-a, ru-central1-b и ru-central1-d. 
Источник изображения: Yandex Cloud Спустя несколько часов было объявлено об устранении сбоя и начале разблокировки ранее остановленных ресурсов. Компания сообщила, что «команда работает над разблокировкой ошибочно заблокированных биллинг-аккаунтов и корректным отображением детализации», а также что «формируются списки, по которым в ближайшее время будут выполнены возвраты». К концу дня, в 23:56, компания сообщила, что работа систем биллинга восстановлена. До этого Yandex Cloud объявила, что был выполнен возврат всех ошибочно списанных средств. В комментариях на сайте Хабре пользователи отметили, что ошибочные списания в Yandex Cloud были незначительными — в пределах 6–6,5 тыс. руб. Впрочем, в Сети попадаются сообщения о якобы списании заметно более крупных сумм.
04.06.2026 [10:07], Руслан Авдеев
Великобритания намерена усилить защиту подводных кабелей, опасаясь российских подлодок и судовВ связи с вероятным ростом активности недружественных ВМС вблизи британских территориальных вод власти Соединённого Королевства намерены усилить защиту инфраструктуры. Правда, как сообщает The Register, пока парламентарии предлагают за нанесение ущерба штрафовать или отправлять виновных в тюрьму, избегая прямой обороны. Ранее большинство обрывов подводных ВОЛС происходили в ходе рыболовецких рейдов или из-за срыва якорей, а не в результате диверсий. Например, оператор Virgin намеревался отсудить у владельцев одного из траулеров более $1 млн, причём спустя десять лет после инцидента. О новых законодательных инициативах рассказала министр цифровой экономики Лиз Ллойд (Liz Lloyd). Речь идёт о возможном ужесточении штрафов за неосторожное повреждение подводных кабелей, а также о введении обязанностей для операторов кабелей по обеспечению безопасности инфраструктуры. Кроме того, власти требуют чрезвычайных полномочий, позволяющих обязать бизнес лучше защищать свою инфраструктуру. По информации издания, ВМС и ВВС Великобритании, в частности, подозревают российские подводные лодки и суда в изучении британских кабельных магистралей. Теперь правительство пересматривает вопрос о том, достаточно ли надёжны меры обеспечения безопасности и устойчивости Великобритании. В 2025 году Объединённый комитет по стратегии национальной безопасности (Joint Committee on the National Security Strategy, JCNSS) британского парламента заявил правительству, что оно «чересчур робко» подходит к защите кабельных сетей страны. 
Источник изображения: David Clode/unsplash.com В числе предложенных мер — ужесточение законодательства. Владельцы и операторы судов, которые по неосторожности повредили подводные кабели, будут подвергаться более суровым наказаниям, а на телеком-операторов смогут возложить новые обязательства по предотвращению и выявлению инцидентов, а также реагированию на них. Министр отметила, что в Великобритании уже есть надёжные механизмы защиты подводных кабелей, но «стоять на месте» в условиях всё большей нестабильности невозможно. Ллойд заявила, что защита кабелей становится как никогда важной для экономики, безопасности и повседневной жизни. Сегодня Великобритания подключена к миру 64 кабелями, а в случае обрыва специальные ремонтные суда прибывают на место приблизительно в течение восьми дней. В 2025 году ВМС Великобритании представили программу «Атлантический бастион» (Atlantic Bastion), призванную дополнить корабли для охоты на подводные лодки автономными беспилотниками. Власти надеются, что у подводных лодок противника не останется в Северной Атлантике мест для укрытия. На развитие программы, пока пребывающей на ранней стадии, уже выделено £14 млн. Кроме того, Великобритания, США и Австралия на днях объявили о разработке сенсорных и боевых модулей для подводных беспилотников в рамках военного партнёрства AUKUS. Ожидается, что это поможет дополнительно защищать инфраструктуру на морском дне. В январе 2025 года НАТО также анонсировала программу Baltic Sentry по защите подводных кабелей. В рамках программы будут задействованы фрегаты, самолёты, беспилотники и другие средства наблюдения стран альянса.
27.05.2026 [19:08], Руслан Авдеев
$800 млрд под угрозой: половине запланированных в США ЦОД угрожают стихийные бедствияСогласно исследованию MS Amlin, страхующей риски самих страховых компаний, порядка половины запланированных в США дата-центров вполне могут пострадать от разрушительных штормов, землетрясений и других стихийных бедствий, сообщает Datacenter Dynamics. Сегодня строительство ЦОД в США постепенно смещается на юг страны, где, как полагает компания, застройщикам всё сильнее грозят торнадо, крупный град, сильные штормы, ураганы и др. катастрофические погодные явления, довольно часто случающиеся в этом регионе. По данным MS Amlin, в США более 670 проектов ЦОД находятся на стадии строительства или планирования, из них 56 % строятся без учёта рисков разрушительных природных явлений. Рискам подвержены почти $800 млрд инвестиций. Около 51 % этих ЦОД строится без оглядки на высокие риски сильных конвективных штормов (SCS), ещё 27 % строят или намерены строить в штатах с высокими рисками зимних бурь, 21 % — в зонах с высокими рисками появления ураганов, 3 % — с высокими рисками землетрясений. Статистика свидетельствует, что SCS являются основной причиной расходов страховых компаний. Только в прошлом году их потери в США составили $52 млрд, при этом с 2008 года потери от них растут на 8 % ежегодно. Подчёркивается, что в целом США является регионом с наибольшими затратами в мире, связанными со стихийными бедствиями. 
Источник изображения: Library of Congress/unspalsh.com Компания подчёркивает, что риски могут помочь в развитии новых ниш. Когда активы подобного типа сосредоточены в опасных регионах, открываются большие возможности для рынка специализированного страхования, но риски необходимо должным образом контролировать и понимать. Обычно дата-центры застрахованы в рамках действующих программ для бизнеса — от страхования имущества до киберугроз, кредитных и политических рисков. Тем не менее стремительное развитие индустрии ЦОД, связанное с бумом ИИ, требует специальных страховок, поскольку вся отрасль с трудом успевает за изменениями. При этом дата-центры нередко подвергаются новым рискам, которые страховым компаниям трудно оценивать Страховой бизнес сталкивается и с дополнительной угрозой — всё больше дорогих активов концентрируется в относительно небольших локациях. Кроме того, для одного объекта может предлагаться сразу несколько страховых полиса. Так, строительство дата-центра требует взаимодействия множества заинтересованных сторон, при этом на одном и том же объекте разным участникам могут быть проданы разные страховые продукты. Стоит отметить, что проблема касается не только США. Исследование Rest of World показало, что почти 7 тыс. из 8808 дата-центров в мире построены в не самых комфортных, согласно стандартам ASHRAE, климатических условиях. Большинство находятся «за пределами оптимального температурного диапазона» для охлаждения, а 600 — в слишком жарких местах. Экономические, политические и даже сетевые реалии часто важнее для строителей и операторов, чем, например, экологическая целесообразность.
25.05.2026 [21:15], Руслан Авдеев
Accenture и OneView Commerce получили контракт на замену скандально известного ПО Fujitsu Horizon для Почты ВеликобританииПочтовая служба Великобритании Royal Mail заключила с Accenture и OneView Commerce контракт на £410 млн для замены проблемного ПО Horizon, ставшего причиной одной из крупнейших судебных ошибок в истории страны, сообщает The Register. Accenture стала победителем тендера на замену ПО компании Fujitsu, с 1996 года отвечавшего за работу POS-системы и финансовой отчётности почты в соответствии с принципом Walk In Take Over (WITO). Это означает, что подрядчик берёт под контроль действующую систему, обслуживая её, но параллельно внедряя новую — готовится полная трансформация делопроизводства. В частности, будет обеспечено управление миграцией на новое SaaS-решение, сумма сделки составит £269 млн на пять лет (с возможностью дважды дополнительно продлять контракт на год). Менее известная OneView Commerce выступает поставщиком SaaS-решений для розничной торговли. Эта компания также выиграла тендер на поставку ПО стоимостью £141 млн. Программное обеспечение должно «трансформировать технологическую платформу розничной торговли почты в соответствии с меняющимися бизнес-требованиями, операционными процессами и потребностями клиентов». Новую систему поместят в облако с возможностью отладки под нужды почты. Ожидается, что она будет включать POS-терминалы для обслуживания посетителей, мобильные сервисы, службы взаимодействия с клиентами и аналитические сервисы, а также киоски самообслуживания и т.п. 
Источник изображения: Federico Di Dio photography/unsplash.com В 1999 году Почта Великобритании начала внедрять систему Horizon компании Fujitsu для бухгалтерского учёта и дважды обновляла это ПО. Со временем выяснилось, что с 1999 по 2015 гг. более 700 сотрудников почты неправомерно привлекли к ответственности из-за ошибок в Horizon, в том числе уголовной. Расследование уже показало, высокопоставленные сотрудники почты и представители подрядчиков — Fujitsu и ICL должны были знать о дефектах в Horizon. При этом представители Почты и Fujitsu пытаются переложить вину друг на друга, а многие пострадавшие до сих пор не могут дождаться компенсаций. Попутно выяснилось, что и прошлые версии ПО для Почты, Capture и ECCO/ECCO+, также содержали аналогичные ошибки. В мае 2025 года Почта Великобритании отказалась от планов создания собственной замены ПО компании Fujitsu и объявила тендер на £410 млн, победителями которого и стали Accenture и OneView Commerce. В числе не прошедших конкурсный отбор — IBM и Escher Software. Последняя занимается поставками ПО для розничной торговли и электронной коммерции.
19.05.2026 [13:53], Руслан Авдеев
Иран намекнул на уязвимость подводных кабелей в Ормузском проливе, пригрозив ввести сборы за их использованиеИран пригрозил нарушить работу подводных кабелей в Ормузском проливе. Аккаунт в одной из социальных сетей, ассоциированный с иранским военным командованием, на днях опубликовал послание «Мы будем взимать сборы на интернет-кабели», сообщает The Register. Вероятно, это угроза обязать операторов кабелей платить за то, чтобы кабели продолжали работать. Обычно такие кабели стараются разместить поглубже, чтобы до них было сложнее добраться, но пролив не так глубок, да и у Ирана имеются средства легко повредить их. Иран может использовать подводные интернет-кабели в качестве ещё одного «козыря» для укрепления политических позиций — помимо блокады Ормузского пролива. Отмечается, что в случае, если с кабелями что-то произойдёт, пострадают банковские сети, военная связь, облачные ИИ-системы, онлайн-сервисы и коммерция. В первую очередь речь о ближневосточных государствах. Многие кабели, обеспечивающие связь стран Персидского залива, проходят через Ормузский пролив. При этом некоторые имеют дублирующие маршруты, а также посадочные станции в Омане, восточнее пролива. Кроме того, многие страны региона имеют сухопутные ВОЛС, некоторые из которых тоже связаны с посадочными станциями в Омане. Как сообщает The Register, если Иран выберет уничтожение кабелей в проливе, то соседние страны совсем без связи не останутся, но связность и ширина каналов резко снизятся. 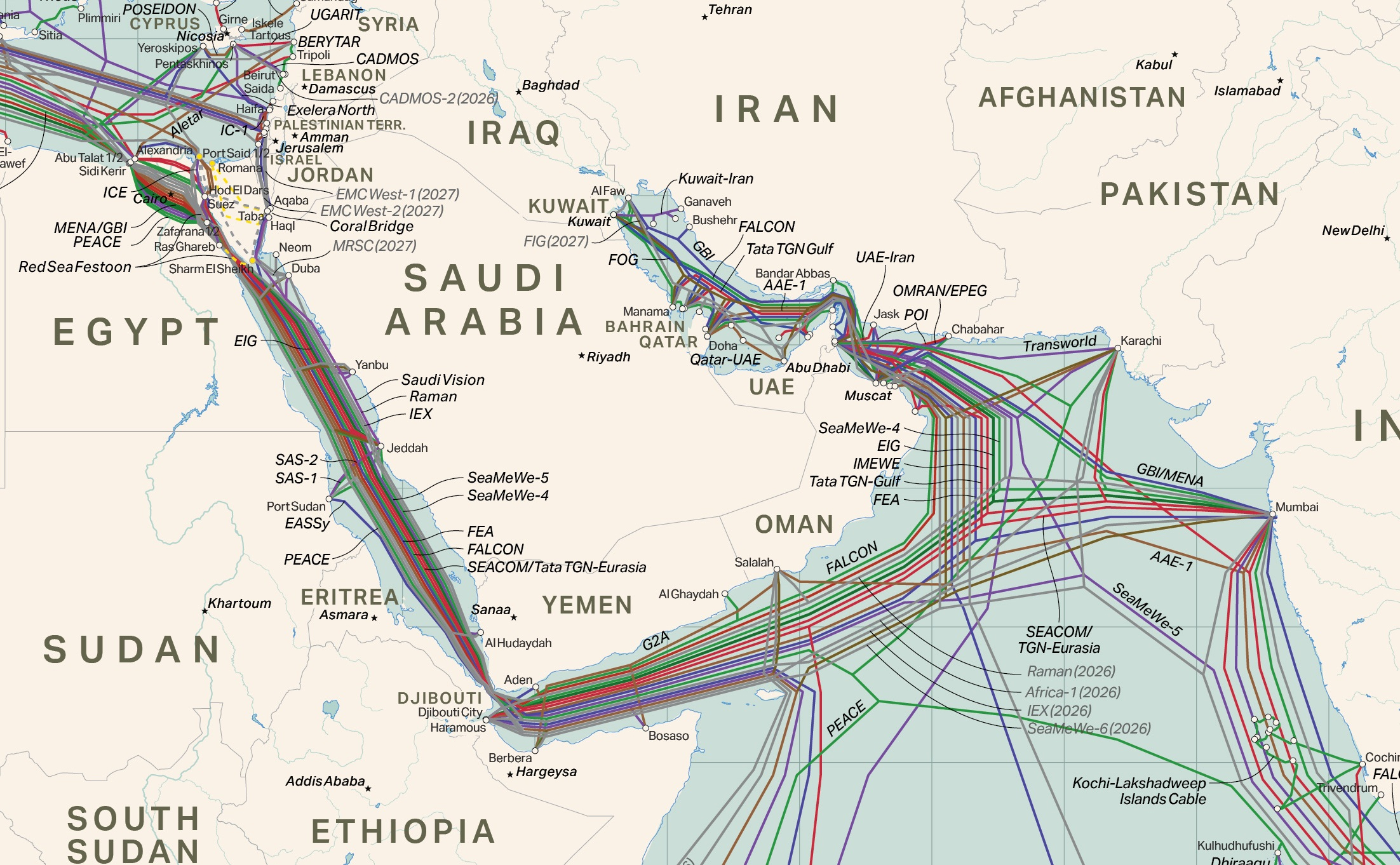
Источник изображения: TeleGeography Для многих было бы заманчивым объявить краткие заявления в социальных сетях пустыми угрозами, если бы не прежние атаки Ирана по дата-центрам AWS в ОАЭ и Бахрейне с комментариями о том, что их мощности использовались в военных целях. Позже Иран грозил нанести непоправимый ущерб и строящемуся кампусу OpenAI в ОАЭ. В Иране, очевидно, понимают, что атаки на информационную инфраструктуру могут помочь военным усилиям страны, а блокада Ормузского пролива означает контроль над движением не только судов, но и потоков данных в регионе.
14.05.2026 [15:33], Руслан Авдеев
Uptime Institute: сбои в дата-центрах стали реже, но значительнееСогласно новому отчёту Uptime Institute, за последнюю пятилетку отказоустойчивость ЦОД значительно выросла. При этом сбои в работе дата-центров по-прежнему происходят, а устранение их обходится всё дороже и времени на это уходит в среднем всё больше, сообщает The Register. Согласно докладу, половина опрошенных представителей операторов ЦОД за последние три года отметили значительные или масштабные сбои. Это наиболее низкий уровень с 2020 года, т.е. инфраструктура становится всё надёжнее. При этом операторам ЦОД всё сложнее повышать прописанный в SLA уровень надёжности — хотя отказы случаются реже, дальнейшее улучшение показателей требует всё больших усилий. Усилия по повышению времени безотказной работы отчасти сводятся на нет усложнением систем и условий эксплуатации, вызванными повсеместным внедрением ресурсоёмкой инфраструктуры для обучения и инференса ИИ. Повышенная плотность размещения оборудования в стойках, перепады нагрузок и другие факторы способны увеличить вероятность каскадных отказов. Кроме того, нехватка генераторов, распределительных устройств, трансформаторов, систем охлаждения и др. заставляет операторов ЦОД иногда использовать б/у или непроверенное оборудование. Предполагается, что именно это могло привести к сбоям в некоторых ЦОД. 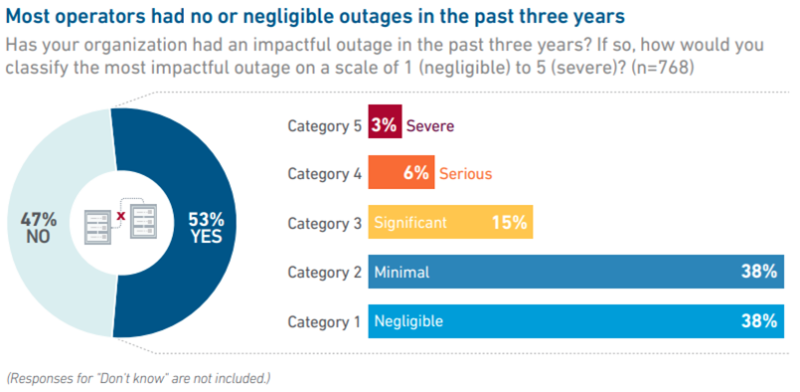
Источник изображения: Uptime Institute Основной причиной критических неполадок называются сбои электроснабжения, хотя в этом отношении наметились определённые улучшения — если в 2024 году на проблемы с электроснабжением приходилось 54 % самых серьёзных отключений, то в 2025 году речь шла уже о 45 %. При этом ситуация может измениться, поскольку электросети на местах испытывают всё большую нагрузку из-за ввода в эксплуатацию новых ЦОД. Хотя сбои энергосетей не станут главной причиной отключений в будущем, они скажутся на доступности локальной генерации — при сбоях сети ЦОД не всегда успевают переключиться на ДГУ и иные резервные источники питания. 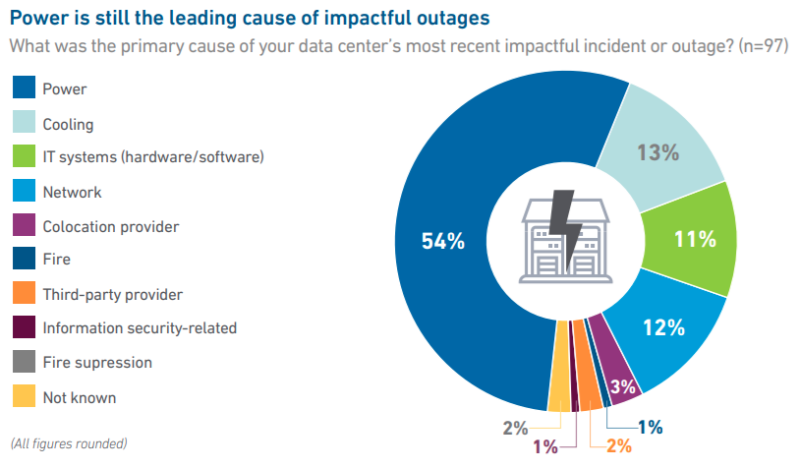
Источник изображения: Uptime Institute В поле зрения экспертов Uptime попадает не только перегрузка электросетей. По словам экспертов, многие сбои ЦОД связаны с обрывами оптоволокна и другими неполадками. Поскольку инфраструктура ЦОД становится всё более распределённой, сбои за пределами дата-центров играют всё большую роль. Даже если сам ЦОД работает корректно, неправильная сетевая конфигурация, например, может привести к перебоям с предоставлением услуг клиентам. SDN и автоматическое перераспределение трафика позволяет снизить риски, и всё больше компаний не сталкиваются с простоями вообще. Около 20 % опрошенных не регистрировали в последние три года сбоев IT-сервисов, что значительно лучше, чем годом ранее. 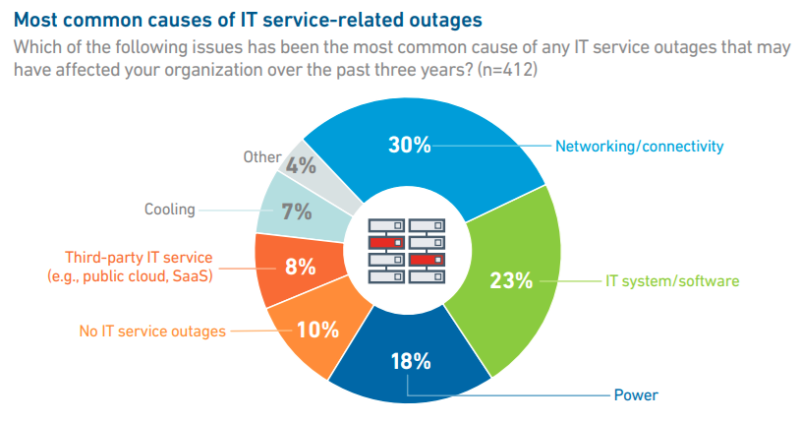
Источник изображения: Uptime Institute Обеспечение устойчивости на уровне ПО помогает смягчить эффекты от локальных инцидентов, включая обрывы оптоволоконных кабелей, за счёт распределения рабочих нагрузок между рядом связанных площадок. Впрочем, такие системы довольно сложны сами по себе. Более того, на примере ударов беспилотниками по ЦОД в ОАЭ и Бахрейне можно увидеть, что распределение нагрузок имеет малую эффективность, если сбой касается сразу нескольких площадок. Хотя в 2025 году Uptime Institute зарегистрировала меньше сбоев, чем годом ранее, в отчёте полагают, что сбои могут длиться в целом дольше. 55 % инцидентов, информация о которых сообщалось публично, разрешаются в течение 12 часов, но доля инцидентов продолжительностью более 48 часов увеличивается вот уже второй год подряд. При этом многие из них связаны с теми же повреждениями ВОЛС. По информации Uptime, в отчётный период это происходило более чем вдвое чаще, чем ранее. При этом по мере роста длительности простоя растут и убытки от инцидентов, особенно в случае с ИИ-инфраструктурой. По данным Uptime, в настоящее время 20 % простоев обходится дороже $1 млн. Ожидается, что соответствующий показатель в ближайшие годы будет только увеличиваться. |
|

