Материалы по тегу: cpu
|
16.06.2026 [09:46], Сергей Карасёв
NextSilicon готовит 128-ядерные серверные RISC-V-процессоры для ИИ и НРСКомпания NextSilicon сообщила о том, что её вычислительные ядра Arbel с архитектурой RISC-V лягут в основу процессоров корпоративного класса, ориентированных на задачи ИИ и НРС. Организовать серийное производство таких изделий планируется в I квартале 2028 года. NextSilicon проектировала Arbel с чистого листа, а первоначальной целью было создание хост-процессора для ИИ-ускорителей Maverick-3. Конструкция Arbel предусматривает наличие массивного конвейера инструкций шириной 10 команд и буфера переупорядочивания на 480 записей. Возможно выполнение 16 скалярных инструкций за цикл. Задействованы четыре интегрированных 128-бит векторных блока для обеспечения высокой производительности при параллельной обработке данных, включая нагрузки, связанные с ИИ-инференсом. 
Источник изображения: NextSilicon Сообщается, что создаваемые процессоры будут доступны в модификациях с 64 и 128 ядрами Arbel. Тактовая частота заявлена на отметке 3,4 ГГц. Тестовые изделия Arbel предполагали применение 5-нм технологии TSMC. Серийные решения будут изготавливаться по более совершенной методике для удовлетворения растущих требований к энергоэффективности и повышению плотности размещения компонентов в дата-центрах. Упомянут алгоритм прогнозирования ветвлений TAG. Говорится о полноценной поддержке профиля RVA23, который стандартизирует ISA. В RVA23 предусмотрены такие функции, как векторные операции, инструкции с плавающей запятой и атомарные инструкции, а также поддержка гипервизоров. Заявлена совместимость со стандартными дистрибутивами Linux. Ожидается, что рынок чипов с архитектурой RISC-V для дата-центров и НРС-платформ будет демонстрировать среднегодовой темп роста на уровне 33,1 % в период с 2025 по 2034 год. В результате его объём превысит $200 млрд.
01.06.2026 [21:33], Владимир Мироненко
Intel выпустит 192-ядерные процессоры Xeon Diamond Rapids на техпроцессе 18A-P в 2027 годуВместе с объявлением о выходе серии чипов Xeon 6+ (Clearwater Forest) компания Intel предоставила некоторые подробности о Xeon Diamond Rapids, выход которых намечен на 2027 год. Новый процессор будет выпускаться по техпроцессу 18A-P, усовершенствованной версии 2-нм техпроцесса. Компания сообщила, что Xeon Diamond Rapids получит на 50 % больше ядер, чем Granite Rapids-AP (6900P), т.е. 192 P-ядра. Это значительный прирост, но всё же меньше, чем у AMD, которая, как ожидается, уже в этом году предложит до 256 ядер Zen 6C в EPYC Venice. При этом Diamond Rapids не будет поддерживать Hyper-Threading (SMT). Эта технология вновь появится в Xeon Coral Rapids в 2028 году. Как сообщает The Register, на рендерах, представленных в пресс-релизе Intel, видно, что два I/O-чиплета обслуживают четыре вертикально расположенных вычислительных блока, собранных с использованием упаковки Foveros. Аналогичная компоновка используется в Clearwater Forest. Перенос L3-кеша на базовый тайл освобождает значительную площадь вычислительного чиплета. Здесь таковых четыре, по 48 ядер в каждом. The Register отметил, что в этом отношении Diamond Rapids похож на Fujitsu Monaka, который использует почти идентичную компоновку и 3.5D-упаковку Broadcom, хотя и с одним чиплетом I/O. А вот контроллеры памяти могут оказаться и на базовых тайлах, и в составе I/O-чиплетов. 
Источник изображений: Intel В отличие от Granite Rapids-SP, не стоит ожидать широкого распространения Diamond Rapids в корпоративных системах виртуализации или СХД. Как сообщила Intel, Diamond Rapids «оптимизирован для высоконагруженных IaaS-систем с высокой производительностью на поток», что ставит его в один ряд с процессорами 6900P, больше ориентированными на HPC-нагрузки. Intel уже говорила, что новинки получат 16-канальный контроллер памяти с поддержкой MRDIMM, что важно для таких задач. Чипы также будут поддерживать PCIe 6.0, предлагая высокую скорость и масштабируемость для сценариев с интенсивным использованием I/O.  Далее Intel представит Coral Rapids, вернув P-ядрам поддержку SMT. Ожидается, что линейка будет запущена в середине 2028 года с 8-канальными платформами, но, судя по недавним заявлениям генерального директора Лип-Бу Тана (Lip-Bu Tan), её выпуск, вероятно, будет ускорен из-за возросшего спроса на процессоры для рабочих нагрузок агентного ИИ.
01.06.2026 [15:26], Владимир Мироненко
Intel объявила о выходе Xeon 6+ Clearwater Forest — первых 2-нм серверных процессоровIntel объявила о выходе серии чипов Xeon 6+ (Clearwater Forest), первых процессоров для ЦОД, созданных на основе Intel 18A, самого передового технологического процесса компании. Как отметил ресурс The Register, процессоры Intel Xeon Clearwater Forest изначально были разработаны для телекоммуникационных приложений, SaaS и высокопроизводительных веб-приложений. Но с расширением использования агентных решений, как OpenClaw, роль процессоров в ИИ-инфраструктуре значительно возросла. В такой же мере вырос на них спрос. При выполнении задачи эти чипы могут отправлять множество запросов для сбора информации из интернета, запуска и отладки кода, запросов к базам данных и взаимодействия с API. Все эти запросы выполняются на ядрах CPU, количество которых у Intel Xeon 6+ составляет до 288. Это на 200 ядер больше на сокет, чем у новых процессоров NVIDIA Vera, и более чем в два раза больше, чем у недавно анонсированного Arm AGI — оба ориентированы непосредственно на агентный ИИ. 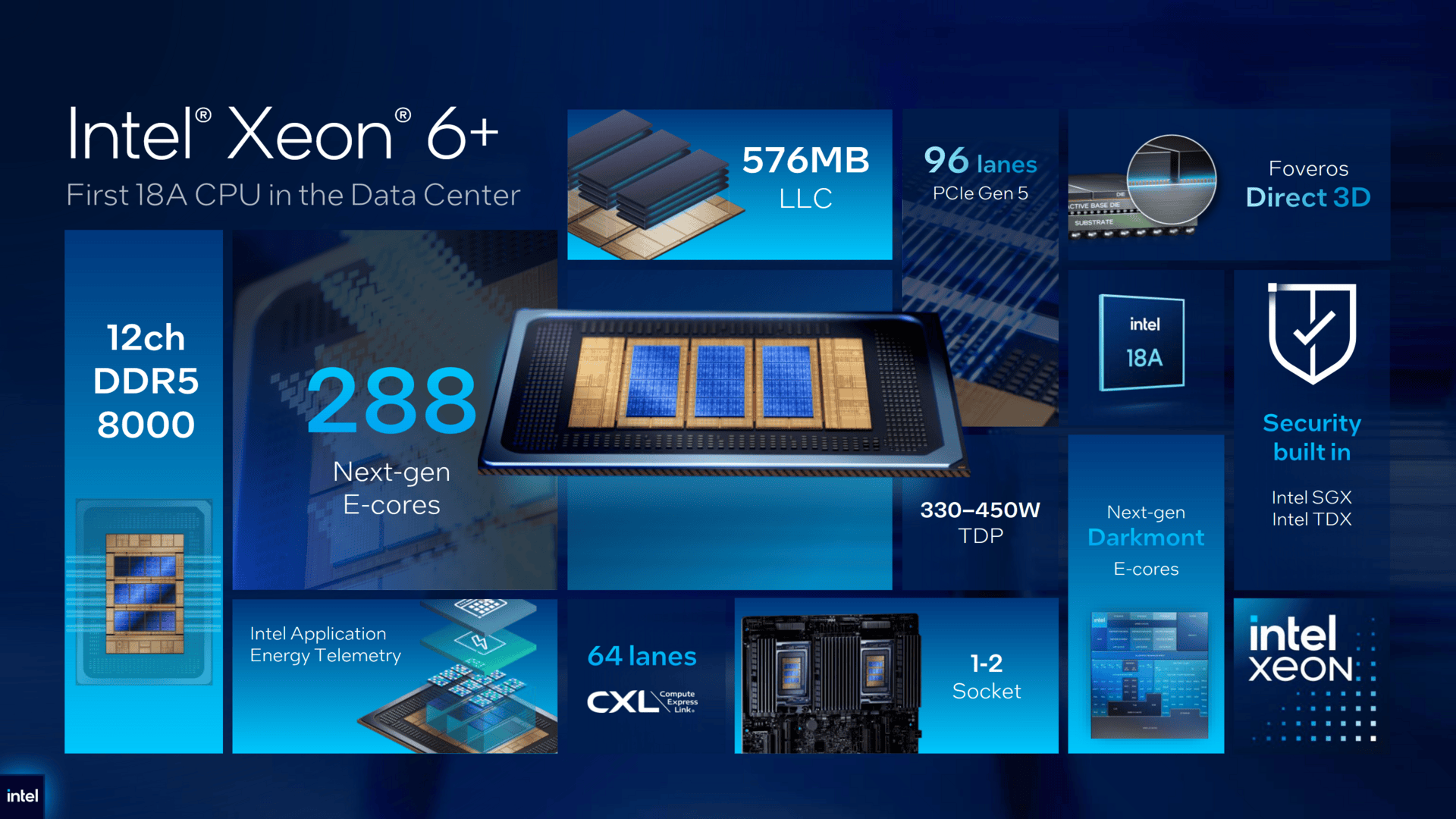
Источник изображений: Intel В максимальной конфигурации 6900E+ включает 12 чиплетов E-Core (Intel 18A с RibbonFET и PowerVia), 3 базовых тайла (Intel 3) и 2 чиплета I/O (Intel 7). 12 EMIB-тайлов объединяют все чиплеты в единую 2.5D-упаковку с использованием технологии Foveros Direct 3D, обеспечивая сверхнизкую задержку передачи данных по всему чипу. Совместимость с существующими платформами Xeon 6900P/6900E (Granite Rapids-AP/Sierra Forest-AP) означает, что Clearwater не потребует от OEM-производителей разработки совершенно новой платформы. Чип может быть установлен в существующие плат, что упрощает его внедрение. Применение архитектуры E-ядер свидетельствует о сосредоточенности Clearwater Forest на повышении энергоэффективности. Новая функция Intel AET («Телеметрия энергопотребления приложений») позволяет операторам ЦОД отслеживать энергопотребление каждого ядра и каждого приложения на аппаратном уровне. Это упрощает системным администраторам выявление проблемных рабочих нагрузок и повышение энергоэффективности путём оптимизации ПО или просто модификации окружения.  E-ядра Darkmont нового чипа работают на более низких частотах, чем P-ядра чипа Intel Xeon 6, и в отличие от них не имеют поддержки AVX-512, AMX и Hyper-Threading. Но по сравнению с первым поколением E-ядер Intel Xeon, представленных на два года назад, ядра Clearwater обеспечивают на 17 % больше инструкций за такт в дополнение к более высокой частоте в режиме Boost. Также рабочим нагрузкам агентного ИИ может пойти на пользу обилие выделенных ускорителей. В чиплеты I/O встроены 16 ускорителей (по 8 на чиплет), предназначенных для криптографических операций, перемещения данных, сжатия/распаковки, балансировки и т.д. Доступны четыре варианта Xeon 6+ в шести конфигурациях, причем две топовые модели выпускаются в конфигурациях с ограниченным энергопотреблением, более низкими базовыми и турбо-частотами всех ядер, но с идентичными характеристиками. Сравнивая новинки с процессорами Sierra Forest предыдущего поколения, Intel сообщила, что 6900E+ обеспечивают прирост производительности на 126 %. При этом производительность на Вт увеличивается на 55 %, что, по оценкам Hot Hardware, означает, что они также потребляют примерно на 46 % больше энергии. Это вполне приемлемо с учётом того, ядер стало в два раза больше, а L3-кеш вырос в пять раз. 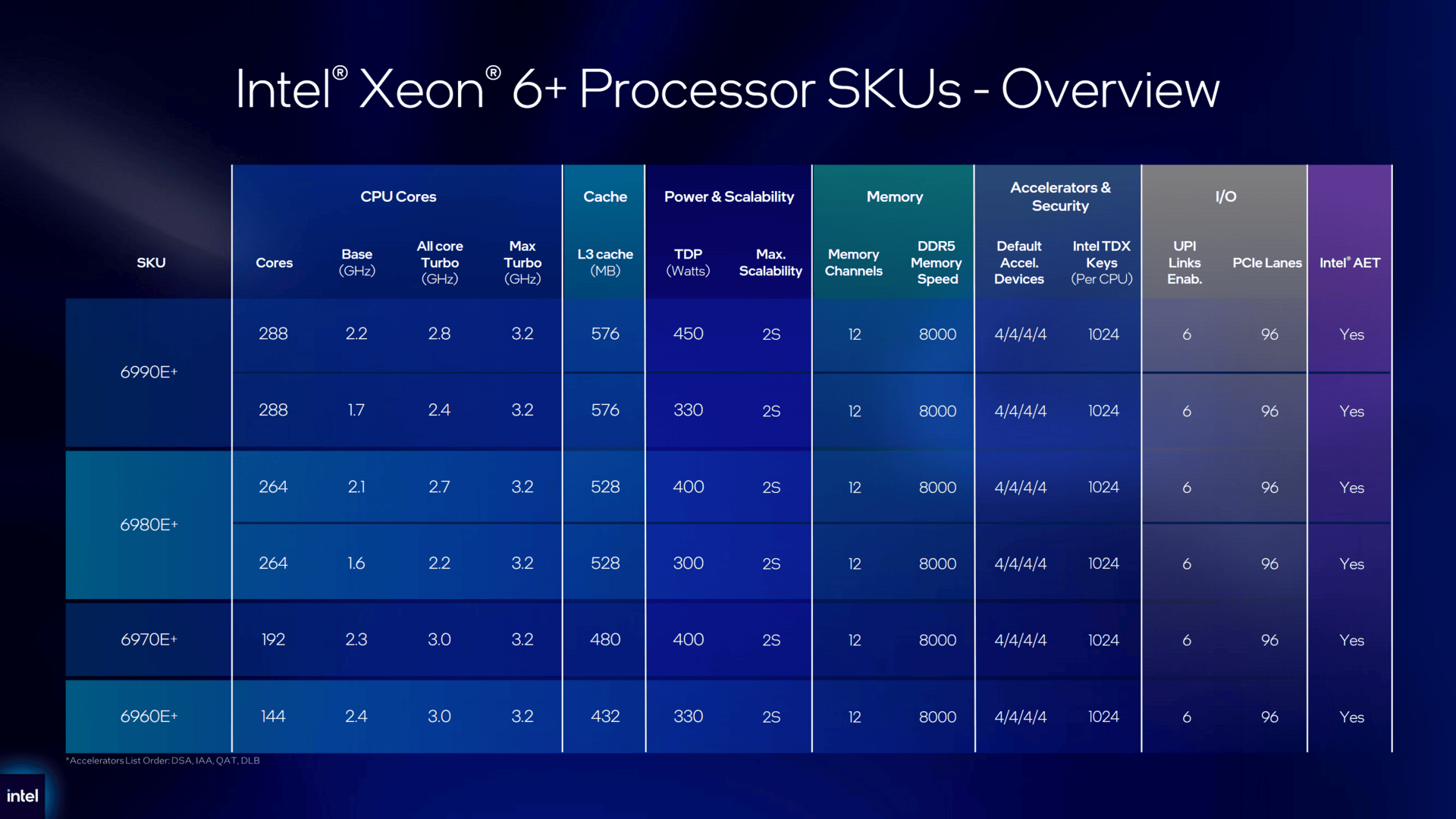 Также Intel заявила, что процессоры Xeon 6990E+ обеспечивают в 1,3 раза более высокую среднюю производительность на поток и в 1,3 раза более высокую среднюю производительность/поток/Вт по сравнению с AMD EPYC 9965 (Turin), сообщил Data Center Dynamics. Ранее Intel сообщила, что тесты Clearwater Forest в реальных условиях эксплуатации показали, что Ericsson благодаря их использованию получит 30-% увеличение производительности при том же количестве ядер, 60-% повышение производительности на Вт и 38-% снижение энергопотребления в стойке во время работы. Новые процессоры будут поддерживаться крупными производителями серверов, включая Amax, ASRock, ASUS, Dell, Foxconn, Giga Computing, Gigabyte, HPE, Inventec, Lenovo, Mitac, MSI, Pegatron, QCT и Supermicro. «Мы наблюдаем значительный спрос на все большее количество процессоров», — отметил в ходе пресс-конференции Кеворк Кечичян (Kevork Kechichian), исполнительный вице-президент и генеральный менеджер Intel Data Center Group.
28.05.2026 [16:14], Руслан Авдеев
ByteDance разрабатывает собственные CPU для поддержки своей ИИ-инфраструктурыКитайский техногигант ByteDance работает над собственными CPU, чтобы поддержать растущие потребности в ИИ-инфраструктуре на фоне того, что цены на чипы растут, а дефицит поставок мешает расширению бизнеса, сообщает Reuters со ссылкой на три источника, знакомых с вопросом. Компания работает с двумя архитектурами, Arm и «открытой» RISC-V, и пока взвешивает, какой именно дизайн лучше всего закроет потребностям собственных ЦОД в долгосрочной перспективе. Инициатива косвенно свидетельствует о быстром смене приоритетов индустрии с обучения ИИ на инференс — современным ИИ-агентам всё больше нужны CPU, работающие в тандеме с ИИ-ускорителями. Google, Amazon, Microsoft и Alibaba разрабатывают собственные облачные CPU для снижения затрат и оптимизации производительности своих систем для конкретных задач. Также это в некоторой степени помогло ключевым производителям CPU — Intel и AMD выступить «лидерами сопротивления» доминированию NVIDIA в сфере ИИ. ByteDance намерена внедрять процессоры собственной разработки в собственных серверах и ЦОД для поддержки своих внутренних операций. По имеющимся данным, она готовит масштабную премьеру агентных продуктов, включая платформу Coze. AWS уже давно портировала значительную часть внутренних нагрузок на чипы Graviton, которые всё чаще пользуются спросом и у сторонних заказчиков, включая Meta✴ и Uber. Google тоже активно переносит нагрузки на чипы Axion. 
Истчоник изображения: ByteDance Пекинский бизнес обратился к нескольким партнёром, чтобы те помогли компании в реализации проекта и те должны не только помочь с разработкой чипов, но и обеспечить «бронирование» производственных мощностей Проект пока находится на ранней стадии реализации и, кроме данных источников, информации пока нет. Инициатива ByteDance ставит компанию в один ряд с многочисленными технологическими компаниями, решившими, что выпускать собственные чипы будет выгоднее несмотря на сложность их разработки. Стремление разрабатывать собственные полупроводники происходит на фоне того, что Intel ещё в феврале предупредила китайских клиентов о возможном росте сроков поставок CPU до шести месяцев. В апреле компания объявила, что спрос на её CPU со стороны ИИ-компаний был таким высоким в I квартале, что производитель распродал даже запасы предназначавшихся к списанию, ранее считавшихся неликвидными, чипов. На днях AMD предупредила об ухудшении положения на рынке CPU — спрос превышает прогнозы и проблемы со своевременными поставками сохранятся. Сегодня ByteDance закупает CPU у Intel и AMD, которые уже значительно подняли цены, рост квартал к кварталу в последние месяцы составил 10–35 %, что лишь подтолкнуло ByteDance к разработке собственных альтернатив. NVIDIA также развивает активность на рынке CPU и надеется, что новые Arm-процессоры Vera, которые оказались конкурентоспособны EPYC и Xeon, обеспечат компании доступ к новому рынку объёмом в $200 млрд. Сама Arm тоже планирует заработать миллиарды долларов на CPU Arm AGI, фактически конкурируя с собственными заказчиками.
27.05.2026 [00:56], Владимир Мироненко
Серверные Arm-процессоры NVIDIA Vera обогнали современные Intel Xeon и AMD EPYC в некоторых тестахПортал Phoronix провёл тестирование серверного Arm-процессора NVIDIA Vera, разработанного специально для обеспечения функционирования агентного ИИ, взяв для сравнения одно- и двухсокетные конфигурации на базе Intel Xeon 6980P (Granite Rapids-AP), а также AMD EPYC Turin: 9755, 9575F и 9475F. Также в сравнительное тестирование включили процессоры NVIDIA первого поколения Grace на базе ядер Arm Neoverse V2 (Demeter). Сообщается, что NVIDIA дала добро на проведение на этом предрелизном чипе тестов только для определённых рабочих нагрузок, соответствующих предполагаемым задачам/областям применения Vera в ЦОД, включая стандартные рабочие нагрузки, такие как компиляция, STREAM, кодирование видео, Python/Java и производительность СУБД. Исходя из среднего геометрического значения результатов тестов NVIDIA Vera занял первое место, превысив почти на 11 % лучшие результаты самых передовых разработок AMD, и примерно на 55,3 % показатели лучшей односокетной конфигурации Intel Xeon. Он также превзошёл в тестах двухсокетные конфигурации, что говорит о проблемах масштабирования некоторых рабочих нагрузок на нескольких сокетах. Эти ограниченные тесты отражают превосходство NVIDIA Vera по сравнению с любой архитектурой на базе Arm, с TDP 450 Вт для процессора и 50 Вт для пула памяти объемом 768 Гбайт. 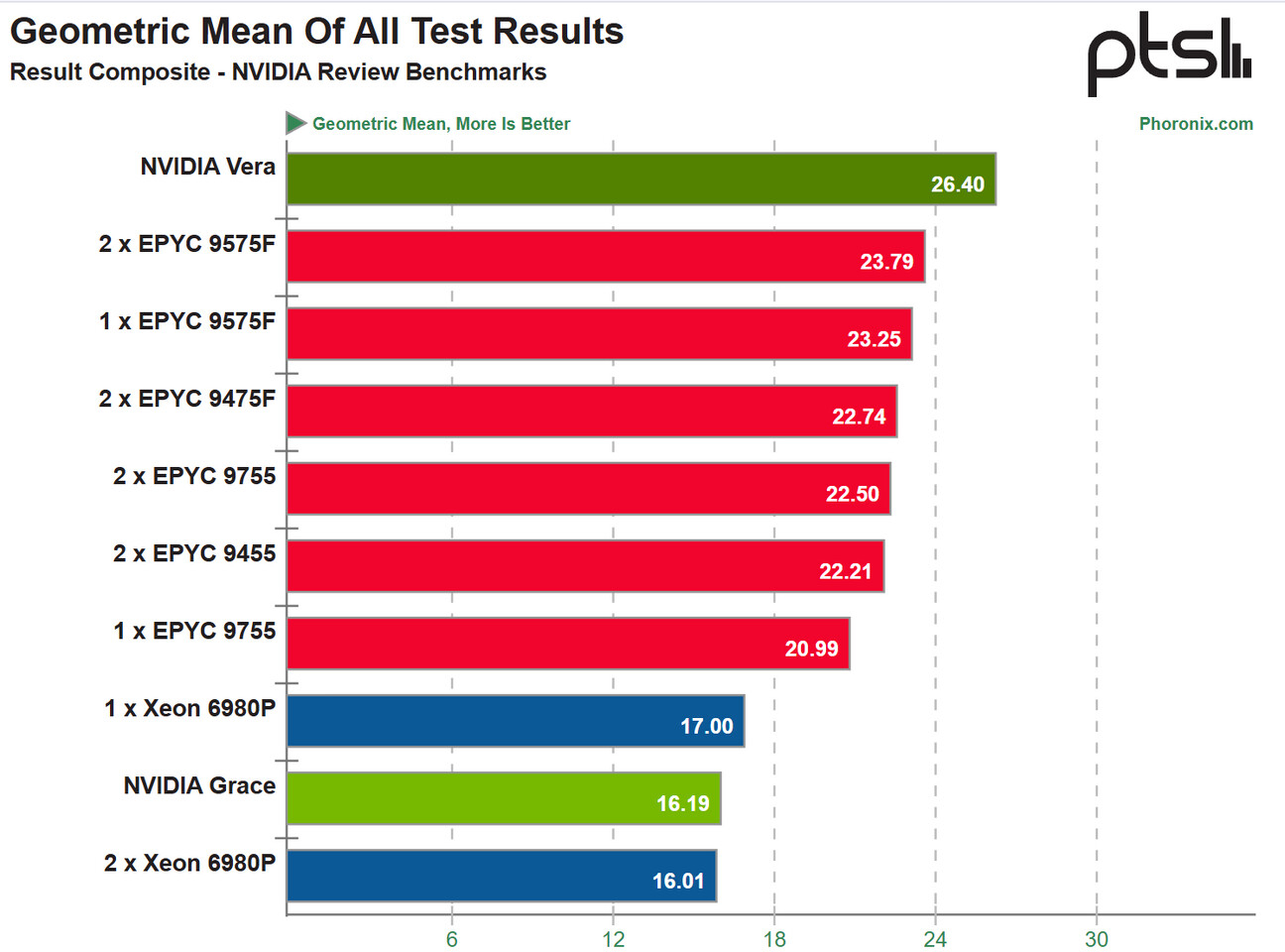
Источник изображения: Phoronix Предполагается, что NVIDIA продаст процессоров Vera и Grace на сумму около $20 млрд, охватив общий потенциальный рынок (TAM) в $200 млрд. NVIDIA сотрудничает со всеми крупными гиперскейлерами для поставки стоек с процессорами Vera (чаще всего в составе Vera Rubin), также наблюдается множество развёртываний у поставщиков инфраструктуры для их собственных задач и предложений для сторонних клиентов. Такой подход позволит NVIDIA выйти на огромный рынок процессоров, став одним из лидеров уже в этом году.
26.05.2026 [15:10], Владимир Мироненко
Европейский Arm-процессор SiPearl Rhea1 для суперкомпьютеров стал на шаг ближе к массовому выпускуФранцузская компания SiPearl объявила об успешном включении Arm-процессора Rhea1, разработанного для использования в суверенных суперкомпьютерах, в частности — в первом европейском суперкомпьютере экзафлопсного класса JUPITER. «Первые результаты очень позитивны, подтверждая, что европейский высокопроизводительный энергоэффективный процессор работает так, как и было задумано», — сообщается в пресс-релизе SiPearl. Компания добавила, что в рамках 12-недельного процесса функциональной проверки в лабораториях будет проведена проверка всех аппаратных и программных функций, интерфейсов и характеристик производительности Rhea1. Как ожидается, продажи Rhea1 начнутся в конце 2026 года. SiPearl отметила, что Rhea1 является самым сложным серверным процессором, когда-либо разработанным в Европе. Он включает 80 ядер Arm Neoverse V1 (Zeus), четыре стека памяти HBM2e (64 Гбайт), а также четыре канала памяти DDR5 (2DPC). Поддерживаются 104 линии PCIe 5.0 в виде шести комплексов x16 и двух x4. 
Источник изображений: SiPearl Сообщается, что Rhea1 является ключевым компонентом для всеобъемлющего вычислительного/ИИ-стека. Помимо производительности, клиенты ожидают от него безопасности без бэкдоров и аварийных выключателей, энергоэффективности, гибкости и развитой программной экосистемы.  «С помощью Rhea1 мы выполняем миссию, возложенную Европейским союзом на консорциум European Processor Initiative (EPIC), а затем и на SiPearl: вернуть в Европу высокопроизводительные процессорные технологии и связанный с ними опыт», — заявил Филипп Ноттон (Philippe Notton, на фото выше), генеральный директор и основатель SiPearl, отметив, что «не может быть цифрового суверенитета без суверенного оборудования».
20.05.2026 [14:13], Руслан Авдеев
Российские процессоры «Иртыш» на китайской архитектуре LoongArch заподозрили в недостаточном уровне «отечественности»Минпромторг РФ настаивает на привлечении новых экспертов к проверке российских процессоров «Иртыш», разработанных «Трамплин электроникс». В министерстве считают, что такие процессоры, положенные в основу оборудования для критической информационной инфраструктуры (КИИ), потенциально создают угрозу национальной безопасности страны, сообщает CNews со ссылкой на письмо Минпромторга в Торгово-промышленную палату (ТПП) РФ. Подчёркивается, что в России уже разработаны опытные образцы серверов на процессорах «Иртыш». Минпромторг ссылается на сообщения СМИ о том, что в 2025 году «Трамплин Электроникс» приобрела право на использование иностранной архитектуры LoongArch, принадлежащей китайской Loongson, а её чипы практически повторяют процессоры серии C3600. Минпромторг подчёркивает недопустимость попадания в реестр российской продукции чипов на готовых схематических решениях, разработанных за границей. Опрошенные изданием эксперты говорят, что присвоение таким чипам статуса отечественных может негативно сказаться на развитии российской микроэлектроники. 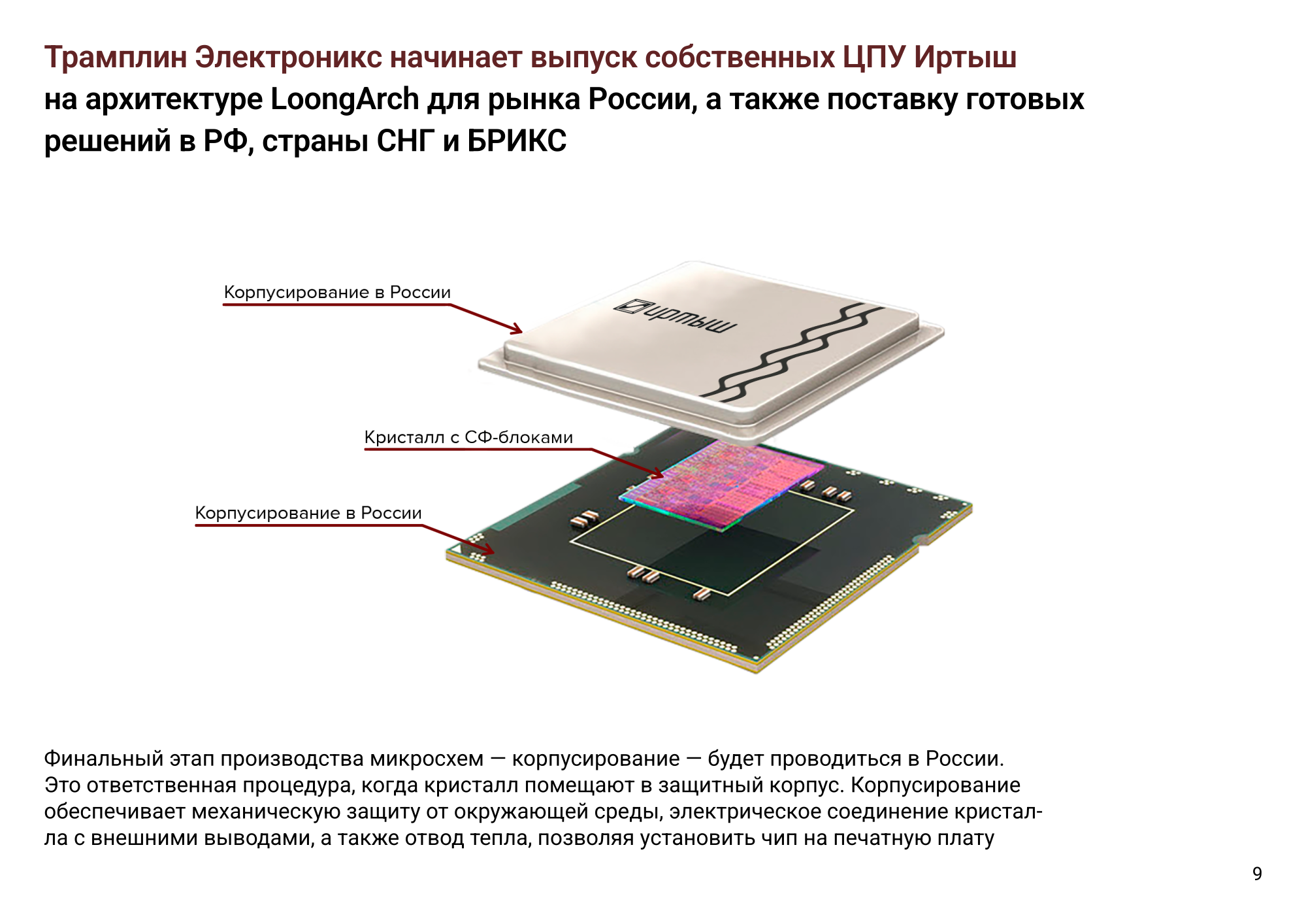
Источник изображения: «Трамплин электроникс» «Трамплин электроникс» посетовала на «попытки заранее сформировать позицию и мнение экспертов» и заявила CNews, что утверждения о полной идентичности «Иртыш» китайским чипам голословны и сделаны без учёта собственных проектных и конструкторских работ, выполненных на территории РФ, включая «интеграцию, адаптацию, производство и испытания», выразив уверенность в компетентности и объективности экспертизы ТПП и готовность продемонстрировать «и лицензии, и глубину освоения технологий, а также контроль жизненного цикла процессоров». 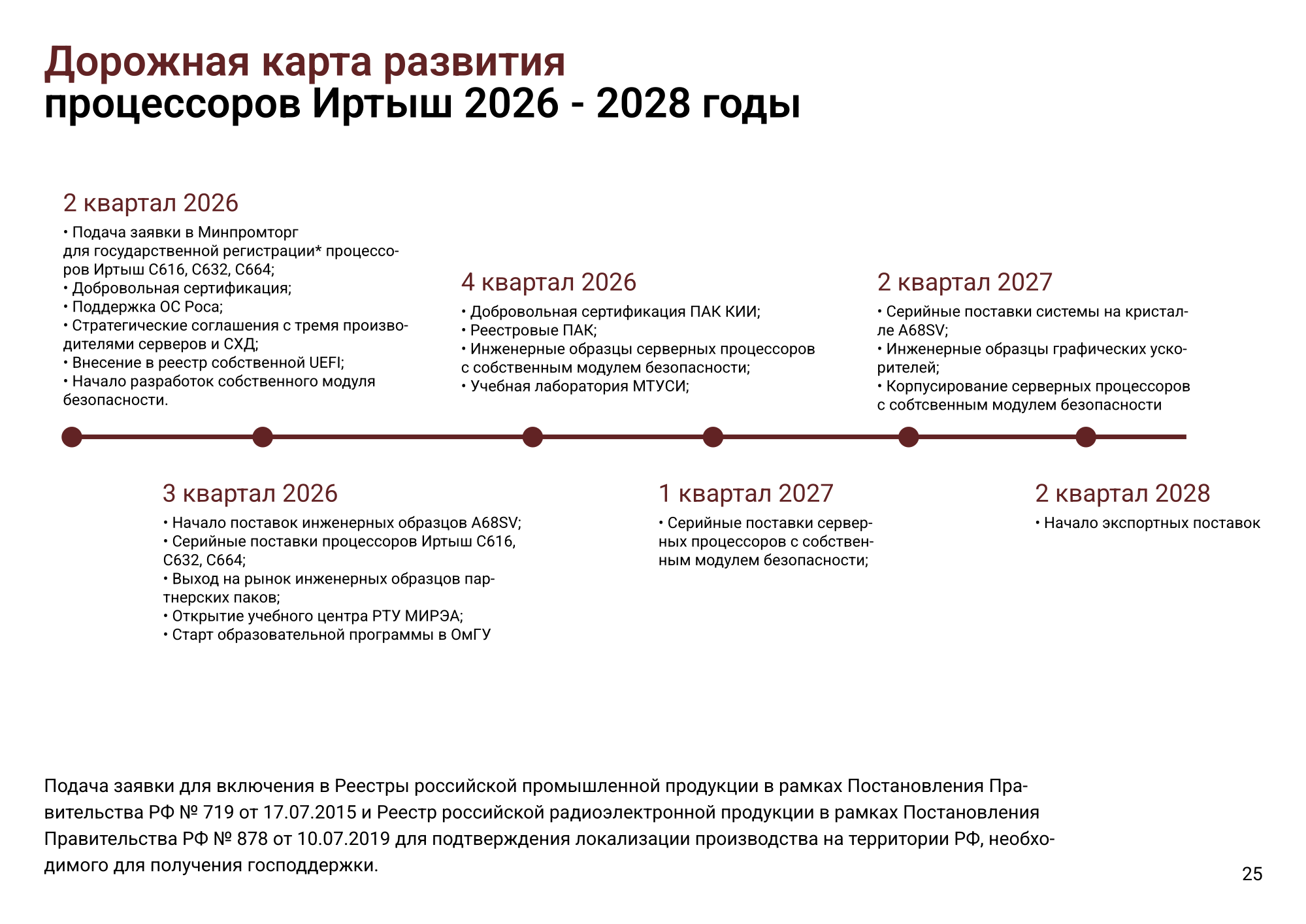 Вместе с тем экспертами отмечается, что за год существования «Трамплин электроникс» разработать собственные решения физически невозможно. При этом в 2022 КНР запретил экспорт чипов Loongson в другие страны, включая РФ. Компания намерена начать серийные поставки процессоров «Иртыш» C616, C632 и C664 в III квартале 2026 года. Корпусирование процессоров будет проводиться в России, но где производятся сами чипы, не уточняется.
19.05.2026 [22:42], Владимир Мироненко
До 84 ядер и 384 Мбайт L3-кеша: AMD опубликовала подробности о телеком-процессорах EPYC 8005 (Sorano)В феварле AMD анонсировала процессоры EPYC 8005 с кодовым именем Sorano для телеком-оборудования, созданные на смену EPYC 8004 Siena, выпущенным в 2023 году. Информация о новых чипах была очень скудной, и лишь сейчас компания опубликовала более подробные сведения об EPYC 8005. Как отметила AMD, серверные процессоры AMD EPYC 8005 на базе ядер Zen 5 разработаны для обеспечения высокой производительности, низкого энергопотребления и компактных размеров с целью ускорения реализации возможностей на периферии сети, в телекоммуникационной отрасли и облачных хранилищах. 
Источник изображений: AMD Возглавляет серию EPYC 8635P — 84-ядерный/168-поточный процессор с Boost-частотой 4,5 ГГц, базовой частотой 1,6 ГГц, 384 Мбайт кеша L3 и TDP по умолчанию 225 Вт. Также в новой серии представлены 64-ядерный EPYC 8535P, 48-ядерный EPYC 8435P, 32-ядерный EPYC 8325P, 24-ядерный EPYC 8225P, 16-ядерный EPYC 8125P и 8-ядерный EPYC 8025P. Следует отметить, что на данный момент в серии EPYC 8005 нет вариантов с суффиксом PN, как это было в серии EPYC 8004, что означает возможность их использования в системах, соответствующих стандартам NEBS. 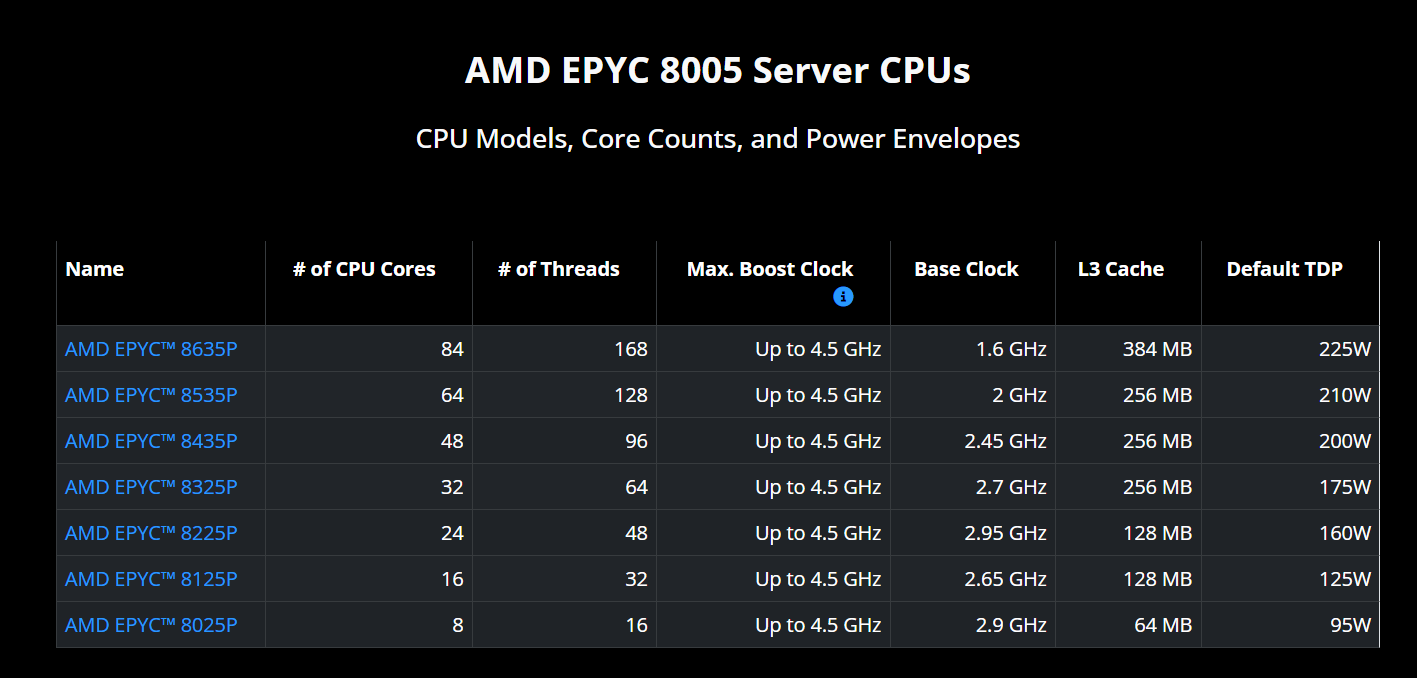 Как отметил ресурс Phoronix, теперь доступен хороший выбор односокетных серверных процессоров AMD EPYC Zen 5 с TDP от 70 до 225 Вт. Эти процессоры призваны напрямую конкурировать с серией Intel Xeon 6 SoC (Granite Rapids-D), которые насчитывают до 72 P-ядер, но дополнительно снабжены функцией vRAN Boost и встроенным 100/200GbE-контроллером. Впрочем, сама AMD сравнивает новинки и с Arm-процессорами NVIDIA Grace. 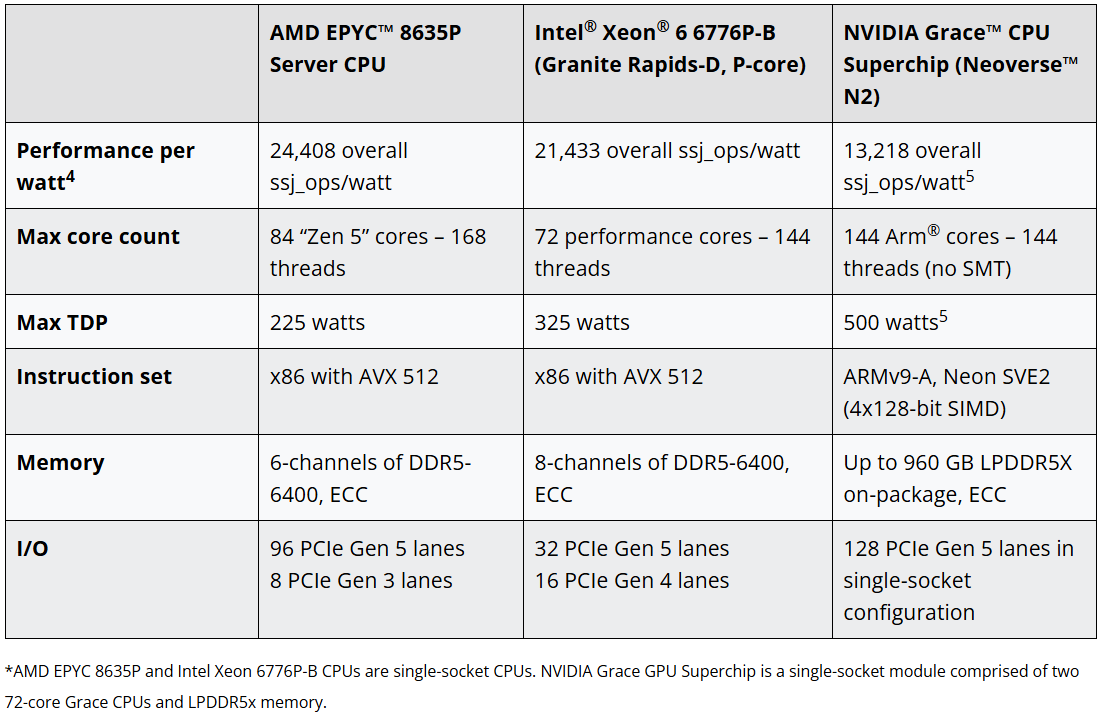
14.05.2026 [18:02], Владимир Мироненко
Благодаря спросу на ИИ AMD нарастила долю на рынке серверных CPU, а Intel потихоньку теснит ArmAMD добилась значительных успехов в сегменте серверных процессоров в I квартале 2026 года. По оценкам Mercury Research, на EPYC пришлось 46,2 % рынка серверных процессоров в денежном выражении, что стало новым историческим максимумом у компании в этой категории продукции. При этом в количественном выражении доля AMD EPYC в общем объёме продаж в сегменте гораздо меньше — 27,4 % (последовательный рост на 230 базисных пунктов), что указывает на их гораздо более высокую среднюю цену продажи (ASP) по сравнению с конкурентами. Общий объём поставок серверных процессоров увеличился примерно на 6 % последовательно и примерно на 19 % год к году. Больше половины рынка серверных чипов в количественном выражении (54,9 %, снижение на 370 базисных пунктов по сравнению с предыдущим кварталом) принадлежит Intel. И судя по её доле рынка в денежном выражении в размере 53,8 % и доле в количественном выражении, можно с уверенностью предположить, что средняя цена серверных процессоров Intel Xeon ниже, чем у AMD EPYC. По данным Mercury Research, на Arm-процессоры для ЦОД приходится около 17,7 % (последовательный рост на 140 базисных пунктов), что составляет почти пятую часть от общего объёма поставок в I квартале 2026 года. Вместе с тем, не уточняется, идёт ли речь о продукции Ampere и других производителей Arm-процессоров, или же о собственных разработках таких компаний, как Google, AWS или Microsoft. 
Источник изображения: AMD В 2026 году ключевым трендом на рынке ИИ стало активное внедрение ИИ-агентов и мультиагентных систем, что обусловило высокий спрос на процессоры и успех AMD. При развёртывании агентного ИИ растёт роль CPU, что привело к изменению конфигурации вычислительных систем от традиционного соотношения, когда один процессор работает в паре с четырьмя или даже восемью ускорителями, в сторону соотношения один к одному. Благодаря возросшему спросу AMD сейчас продаёт каждый произведённый процессор, а Intel реализует заинтересованным клиентам даже то, что ранее списывалось как брак. Вместе с тем в настоящее время AMD удаётся добиваться более высоких средних цен на свою продукцию.
14.05.2026 [10:56], Сергей Карасёв
SiFive представила RISC-V-ядра Performance P570 Gen 3 для IoT-приложенийКомпания SiFive анонсировала производительные процессорные ядра Performance P570 третьего поколения (Gen 3) с архитектурой RISC-V. Они ориентированы на требовательные периферийные ИИ-приложения, потребительские и коммерческие решения интернета вещей (IoT) и пр. Новые ядра используют 64-бит архитектуру RISC-V с поддержкой внеочередного исполнения инструкций. Допускаются конфигурации, насчитывающие до четырёх ядер в кластере. При этом возможно использование до четырёх кластеров, что в сумме даёт до 16 вычислительных ядер. Используется общий кеш L3 на уровне кластера и опциональный общий кеш L2. Для Performance P570 Gen 3 заявлена поддержка широкого спектра типов данных: INT8, INT16, INT32, INT64, FP16, FP32, FP64 и BFloat16. Заявлена полная совместимость с профилем RVA23, который стандартизирует набор инструкций ISA. Реализованы такие функции, как векторные операции, инструкции с плавающей запятой и атомарные инструкции, которые востребованы в сферах НРС и ИИ. Добавлены расширения для повышения производительности и улучшения безопасности, включая Smepmp, Zvkng, Zvksg, Zicfilp, Zicfiss, Zfbfmin, Zvfbfmin, Zvfbfwma и Zvdot4a8i. Упомянута возможность работы с современными ОС, включая Android, Ubuntu 26.04 LTS и платформы Red Hat. 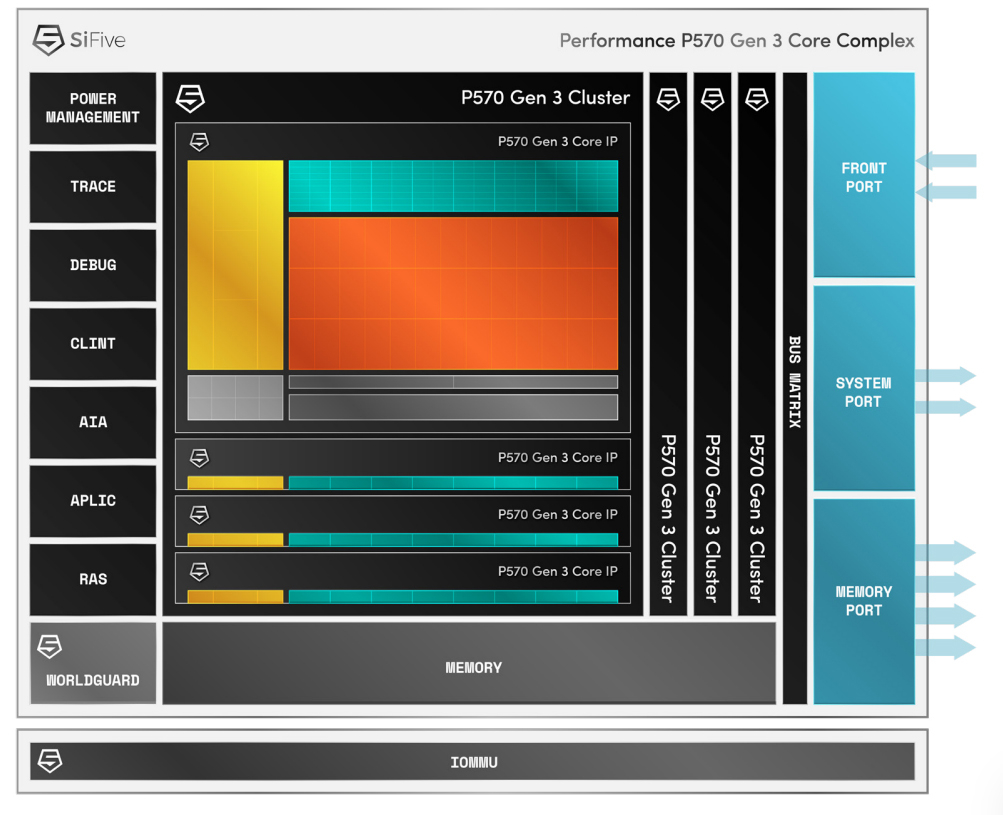
Источник изображения: SiFive В тесте Geekbench 6 ядра Performance P570 Gen 3 демонстрируют примерно вдвое более высокую производительность в расчёте на 1 ГГц по сравнению с изделиями P550. При выполнении определённых ИИ-задач, таких как распознавание объектов, достигается 21-кратный прирост быстродействия благодаря 128-битному векторному конвейеру VLEN. Если сравнивать с ядрами P470 Gen2, то у P570 выигрыш в производительности составляет 30 % и 350 %. В традиционных CPU-нагрузках, по данным SpecInt 2006/2017, ядра P570 показывают прирост быстродействия на 7–13 % по сравнению с P550 при сопоставимых значениях с P470. Кроме того, обеспечивается повышение энергетической эффективности. У ядер Performance P570 Gen 3 динамическое энергопотребление (мВт/ГГц) снижено на 13 % и 5 % по сравнению с P550 и P470 соответственно, а потери мощности (мВт) уменьшены на 51 % и 5 %. |
|

