Материалы по тегу: trainium
|
19.06.2026 [13:49], Владимир Мироненко
Amazon начала переговоры о продаже своих ИИ-ускорителей Trainium сторонним ЦОДAmazon ведёт переговоры о продаже своих ИИ-ускорителей Trainium другим компаниям для использования в их ЦОД. Об этом сообщил Питер ДеСантис (Peter DeSantis), старший вице-президент по ИИ, разработке чипов и квантовым вычислениям Amazon, выступая на конференции VivaTech в Париже (Paris, Франция), о чём пишет Bloomberg. Он отказался назвать потенциальных клиентов, лишь отметив растущий за пределами США спрос на вычислительные ресурсы, управляемые локально. Как сообщается, переговоры о продаже чипов находятся на ранней стадии. Начались они после ежегодного послания генерального директора Amazon Энди Джасси (Andy Jassy) акционерам в апреле, в котором он заявил, что Amazon рассматривает возможность продажи собственных ИИ-чипов сторонним компаниям, что усилит конкуренцию с NVIDIA и AMD. ДеСантис также рассказал, что решение о продаже чипов не вызывает у руководства Amazon опасений, что это ударит по доходам AWS от облачных сервисов. «В сфере ИИ наблюдается огромный дефицит ресурсов, — сказал он. — Меня это не беспокоит». 
Источник изображения: Amazon Рост спроса, особенно в Европе, привёл к призывам уменьшить зависимость от американских технологий или полностью отказаться от них. Комментируя призывы, ДеСантис заявил, что бизнес AWS никак не пострадал от этой тенденции. По его словам, ускорители Trainium3, поставки которых начались в начале этого года, «в значительной степени распроданы», и уже есть большой интерес к новому поколению Trainium4, которое, как ожидается, дебютирует в следующем году. ДеСантис также отметил высокий спрос на Arm-процессоры Graviton, которые в больших масштабах будут использовать Meta✴, Pinterest, Snowflake и Uber. За последние три года, по словам Десантиса, Amazon добавила в свои вычислительные системы больше процессоров Graviton, чем любого другого типа чипов. Что касается Trainium, то у Amazon есть очень крупные контракты с Anthropic и OpenAI. Вместе с тем в качестве альтернативы GPU NVIDIA компания будет предлагать не только свои ускорители, но и царь-чипы Cerebras. 
Источник изображения: Amazon Как сообщает TechCrunch, AWS до сих пор не спешила с продажей своих ИИ-чипов по многим причинам. Самая главная заключается в том, что прибыль, которую она получает от них, имеет каскадный характер. Хотя AWS взимает плату с клиентов за токены ИИ, обрабатываемые этими чипами в её облаке, она также может взимать плату за множество других услуг, необходимых компаниям для их ИИ-приложений, включая хранение данных, безопасность, сетевые услуги и мониторинг. Таким образом, число компаний, желающих занять долю рынка ИИ-ускорителей, на котором доминирует NVIDIA, продолжает увеличиваться. Напомним, что в апреле генеральный директор Alphabet Сундар Пичаи (Sundar Pichai) заявил, что Google начнёт поставлять TPU «избранной группе клиентов» для использования в их собственных ЦОД. Немалая часть из них достанется Anthropic. При этом важно отметить, что, как и в случае с AWS, Google является не только поставщиком, но и инвестором ИИ-стартапа.
15.06.2026 [13:47], Владимир Мироненко
Pinterest заключила с AWS самую крупную инфраструктурную сделку, планируя потратить $4 млрд на облачные сервисы, Graviton и TrainiumФотохостинг Pinterest объявил о значительном расширении сотрудничества с AWS, начавшемся в 2010 году. Согласно новому соглашению, Pinterest выплатит AWS в период до 2031 года $4 млрд за использование её сервисов, что является крупнейшим инфраструктурным проектом в истории Pinterest. В рамках расширенного соглашения Pinterest планирует диверсифицировать использование инфраструктуры AWS для поддержки растущих потребностей в ИИ, одновременно улучшая соотношение цены и производительности. В частности, компания планирует использовать ускорители AWS Trainium для размещения и запуска больших языковых моделей и моделей визуального и языкового анализа, которые обеспечивают персонализированный визуальный поиск и поиск с помощью ИИ. Также Pinterest намерена расширить использование Arm-процессоров Graviton, которые уже обеспечивают работу примерно трети её вычислительной инфраструктуры, для запуска большего количества систем, поддерживающих поиск контента для пользователей фотохостинга, ежемесячная аудитория которого превышает 600 млн. 
Источник изображения: Amazon «Это расширенное соглашение с AWS дает нам гибкость в вычислениях, возможность выбора оборудования и эффективность инфраструктуры для ускорения нашего видения ИИ для следующего поколения визуального поиска в Pinterest», — сообщил Мэтт Мадригал (Matt Madrigal), технический директор Pinterest. В рамках соглашения Pinterest также планирует продолжить модернизацию инфраструктуры, переходя от традиционных сред на основе EC2 к архитектуре на основе Kubernetes в EKS. Это позволит повысить скорость разработки, а также операционную надёжность и эффективность инфраструктуры глобальной платформы Pinterest. Ранее Amazon заключила соглашение о стратегическом партнёрстве с OpenAI, в рамках которого инвестирует в OpenAI $50 млрд. В свою очередь, OpenAI обязалась использовать около 2 ГВт мощностей на базе ускорителей Trainium, включая Trainium3 и чипы следующего поколения Trainium4, которые появятся в 2027 году. Ещё одно крупное соглашение подписано с Anthropic. Также у Amazon есть соглашение с Snowflake, которая планирует потратить в течение пяти лет $6 млрд на инфраструктурные проекты, в том числе на Graviton и ИИ-ускорители. Кроме того, Uber объявила этой весной о планах перенести определённые нагрузки на чипы Graviton и Trainium нового поколения, а Meta✴ получит «десятки миллионов» ядер Graviton5.
11.04.2026 [23:18], Владимир Мироненко
Глава Amazon допустил продажу собственных чипов сторонним заказчикамНа этой неделе генеральный директор Amazon Энди Джасси (Andy Jassy) опубликовал ежегодное послание акционерам, в котором отметил высокий спрос на чипы собственной разработки. Если бы компания выделила их производство в отдельный бизнес с продажей чипов как самой AWS, так и сторонним клиентам, то его годовой оборот мог бы составить $50 млрд. Он допустил, что в будущем компания будет продавать их целыми партиями. Джасси также сообщил, что два крупных клиента AWS обратились с просьбой выкупить всю мощность инстансов на Graviton на 2026 год, но компания отклонила эти запросы, и уточнил, что расчётная годовая выручка (Revenue Run Rate, RRR) Amazon на собственных чипах (Graviton, Trainiu, Nitro) составляет $20 млрд. По словам Джасси, 98 % из 1000 крупнейших клиентов EC2 используют чипы Graviton, а мощности ускорителей Trainium2 и Trainium3 «почти полностью зарезервированы». Также уже зарезервирована значительная часть мощностей на базе Trainium4, до массовой доступности которого ещё около 18 мес. Согласно прогнозу Джасси, Trainium сэкономит компании «десятки миллиардов долларов капитальных затрат в год и обеспечит преимущество в несколько сотен базисных пунктов операционной прибыли по сравнению с использованием чипов других компаний для выполнения вычислений». Он также отметил, что, хотя расчётный годовой доход AWS в IV квартале 2025 года составил $142 млрд, 85 % глобальных ИТ-затрат по-прежнему приходится на решения on-premise. «Это изменится», — заявил Джасси. 
Источник изображения: AWS Спустя три года после начала волны развёртывания ИИ, годовой доход AWS (Revenue Run Rate, RRR) от ИИ в I квартале 2026 года превысил $15 млрд и продолжает расти. «И все же у нас по-прежнему есть ограничения по мощности, которые приводят к неудовлетворенному спросу», — говорит гендиректор Amazon. Он сообщил, что AWS будет расти ещё быстрее, если будет обеспечен большим объёмом электроэнергии. В 2025 году AWS получила 3,9 ГВт новых мощностей и намерена удвоить общую подведённую мощность к концу 2027 года. AWS запустила один из крупнейших в мире ИИ-кластеров с около 500 тыс. чипов Trainium2, который будет использоваться ИИ-стартапом Anthropic. А первым из технологических гигантов разрешил использовать собственные чипы вне его инфраструктуры стала Google, благодаря чему Anthropic приобретёт около 1 млн Google TPU v7 (Ironwood) для запуска на контролируемых ею объектах (в Fluidstack). Примерно 400 тыс. чипов компания получит напрямую от Broadcom в составе стоечных систем.
14.03.2026 [18:42], Владимир Мироненко
Царь-ускорители Cerebras в облаке AWS пятикратно ускорят инференс ИИAmazon Web Services (AWS) и Cerebras Systems объявили о сотрудничестве, «которое позволит создать в ближайшие месяцы самые быстрые решения для инференса в системах генеративного ИИ и рабочих нагрузок машинного обучения». Решение, которое будет развёрнуто на платформе Amazon Bedrock в ЦОД AWS, объединяет серверы на базе ускорителей Trainium, системы Cerebras CS-3 на базе царь-чипов WSE-3 и DPU EFA. Ожидается, что эта технология увеличит скорость генерации результатов ИИ-моделями в пять раз. Позже в этом году AWS предложит ведущие open source решения машинного обучения и собственные ИИ-модели Amazon Nova, использующие оборудование Cerebras. Как отметил Дэвид Браун (David Brown), вице-президент по вычислительным и машинным сервисам AWS, при инференсе критическим узким местом для ресурсоёмких рабочих нагрузок, таких как помощь в кодировании в реальном времени и интерактивные приложения, остаётся скорость: «Решение, которое мы разрабатываем совместно с Cerebras, решает эту проблему: разделяя нагрузку по инференсу между Trainium и CS-3 и соединяя их с помощью EFA, каждая система делает то, что у неё лучше всего получается. В результате инференс будет на порядок быстрее и производительнее, чем сегодня». 
Источник изображения: Amazon Совместное решение использует «дезагрегацию вывода» — метод, который разделяет ИИ-инференс на два этапа: этап интенсивной обработки подсказок, или «предварительного заполнения» (процесс обработки запроса LLM), и этап генерации выходных данных, известный как «декодирование», на котором модель формирует ответ на вопрос пользователя. 
Источник изображений: Cerebras Предварительное заполнение является параллельным, вычислительно интенсивным процессом и не требует большой пропускной способности памяти. Декодирование, с другой стороны, является последовательным процессом с минимальными требованиями к вычислительным ресурсам, но интенсивно использует пропускную способность памяти. Декодирование обычно занимает большую часть времени при инференсе, поскольку каждый выходной токен должен генерироваться последовательно, отметила AWS. 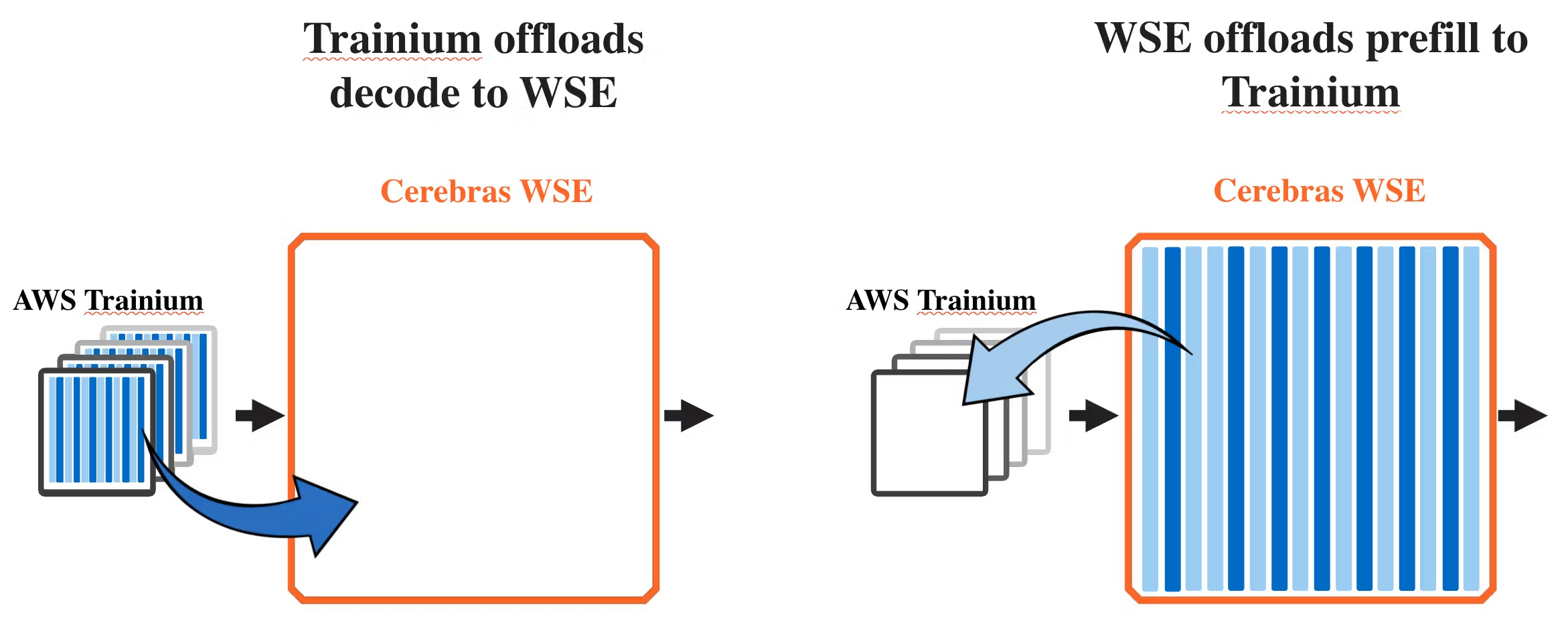 Задачи предварительного заполнения и декодирования обычно выполняются одним и тем же чипом. В дезагрегированной архитектуре AWS чипы Trainium обеспечивают этап предварительного заполнения, а чипы WSE-3 выполняют декодирование. «Дезагрегированный подход идеален, когда у вас большие, стабильные рабочие нагрузки, — сообщил в блоге директор по маркетингу продукции Cerebras Джеймс Ванг (James Wang). — Большинство клиентов используют смешанные рабочие нагрузки с различными коэффициентами предварительного заполнения/декодирования, где традиционный агрегированный подход по-прежнему идеален. Мы ожидаем, что большинство клиентов захотят иметь доступ к обоим вариантам».  Одним из главных преимуществ WSE-3 является то, что он может передавать данные между своими логическими схемами и цепями памяти быстрее, чем многие другие чипы. По данным Cerebras, WSE-3 обеспечивает внутреннюю пропускную способность памяти в 21 Пбайт/с, что значительно превышает пропускную способность NVLink для ускорителей от NVIDIA. Впрочем, у NVIDIA теперь есть ускорители Groq, которые тоже помогают ускорить инференс. Несколько недель назад Cerebras заключила с OpenAI сделку на $10 млрд по поставке чипов общей мощностью 750 МВт до 2028 года. Сделка была объявлена в период между двумя раундами финансирования, которые в совокупности принесли Cerebras более $2 млрд. Ожидается, что компания подаст заявку на IPO уже во II квартале 2026 года. Сделки с AWS и OpenAI могут способствовать повышению интереса инвесторов к листингу, отметил SiliconANGLE.
27.02.2026 [22:55], Владимир Мироненко
Amazon вложит в OpenAI $50 млрд, OpenAI в ответ потратит $100 млрд на 2 ГВт мощностей TrainiumOpenAI и Amazon объявили о заключении соглашения о стратегическом партнёрстве с целью ускорения инноваций в области ИИ для предприятий, стартапов и конечных потребителей по всему миру. В рамках многолетнего соглашения Amazon инвестирует в OpenAI $50 млрд — $15 млрд первым траншем, а затем еще $35 млрд в ближайшие месяцы при выполнении определённых условий. AWS и OpenAI совместно создадут среду выполнения с сохранением состояния (Stateful Runtime Environment) на базе моделей OpenAI, которая будет доступна в Amazon Bedrock для создания приложений и агентов генеративного ИИ. Подобное окружение позволяет разработчикам сохранять контекст, запоминать предыдущую работу, работать с различными программными инструментами и источниками данных, а также получать доступ к вычислительным ресурсам. Новинка будет интегрирована с Amazon Bedrock AgentCore и инфраструктурными сервисами, чтобы приложения и ИИ-агенты клиентов работали согласованно с остальными приложениями инфраструктуры, работающими в AWS. AWS также станет эксклюзивным сторонним поставщиком облачных услуг для платформы OpenAI Frontier, позволяющей компаниям создавать, развёртывать и управлять командами ИИ-агентов, работающих в реальных бизнес-системах с общим контекстом. По мере перехода компаний от экспериментов к внедрению ИИ в производство, Frontier упрощает быструю, безопасную и глобальную интеграцию ИИ-технологий в существующие рабочие процессы. Кроме того, OpenAI и Amazon будут сотрудничать в разработке пользовательских моделей для работы с приложениями Amazon, ориентированными на клиентов. 
Источник изображения: Amazon AWS и OpenAI также сообщили о расширении ещё на $100 млрд более раннего соглашения о многолетнем стратегическом партнёрстве стоимостью $38 млрд, в рамках которого AWS обязалась предоставлять OpenAI в течение семи лет доступ к ускорителям NVIDIA. Расширенное соглашение со сроком действия 8 лет включает в себя обязательство OpenAI использовать около 2 ГВт мощностей на базе ускорителей Trainium, чтобы поддерживать спрос на Stateful Runtime, Frontier и другие рабочие нагрузки. Это обязательство распространяется как на чипы Trainium3, так и на чипы следующего поколения Trainium4, которые появятся в 2027 году и получат технологию NVIDIA NVLink. Сегодняшний день оказался богатым на события для OpenAI. Компания объявила о привлечении $110 млрд инвестиций в рамках раунда финансирования с предварительной оценкой её рыночной стоимости в $730 млрд, что значительно больше оценки в $500 млрд в октябре 2025 года. Лидером раунда стала Amazon с инвестициями в $50 млрд, за ней следуют NVIDIA и SoftBank, инвестировавшие по $30 млрд. Компания заявила, что ожидает, что к раунду присоединятся и другие инвесторы. Ранее Anthropic, ключевой конкурент OpenAI, закрыл раунд финансирования на $30 млрд, подняв капитализацию до $380 млрд. У компании долгие и тесные отношения с AWS, которая развернула для стартапа один из крупнейших в мире ИИ-кластеров Project Rainier. Впрочем, Anthropic тоже старается диверсифицировать поставки вычислительных мощностей — она заключила контракты с Microsoft (на чипы NVIDIA), а также с Google (на TPU).
16.02.2026 [11:16], Руслан Авдеев
Попутного ветра: AWS резко сократила развёртывание СЖО для Trainium3, решив обойтись преимущественно воздушным охлаждениемAmazon Web Services (AWS) резко увеличит долю воздушного охлаждения в серверах на базе ускорителей Trainium3. Производство серверов намерены нарастить во II квартале 2026 года, но жидкостное охлаждение в них будут применять далеко не так активно, как ожидалось, сообщает DigiTimes. Если ранее планировалось применять системы жидкостного и воздушного охлаждения с соотношением 1:1, то теперь на первые будет приходиться лишь 10 % от общего числа, что способно замедлить внедрение СЖО в ЦОД. При этом ранее отраслевые эксперты прогнозировали, что проникновение СЖО на рынок ИИ-серверов вырастет с менее 20 % в 2025 году до более 50 % в 2026-м. Это должно было случиться за счёт расширения поставок GPU- и ASIC. AWS даже смогла разработать в рекордно короткие сроки собственную платформу СЖО, что привело к падению акций Vertiv, одного из бенефициаров ИИ-бума. Новый подход к оборудованию Trainium3 ставит под вопрос будущее и динамику перехода к жидкостному охлаждению. Тем не менее, рост производства Tranium 3 в любом случае поддержит спрос на продукцию ключевых партнёров AWS: Wiwynn, Accton, Auras, Taiwan Microloops и Nan Juen International (Repon). Вероятно, спрос позволит загрузить производственные мощности до конца 2026 года. По мнению аналитиков, решение AWS во многом связано с TDP ускорителей на уровне 800 Вт (хотя раньше говорили об 1000 Вт) — для них, вероятно, достаточно и для современного воздушного охлаждения, что снижает необходимость перехода на более дорогие и сложные СЖО. 
Источник изображений: AWS По данным AWS, Trainium3 приблизительно на 40 % производительнее в сравнении с ускорителями предыдущего поколения. Также компания объявила о капитальных затратах до $200 млрд на расширение ИИ-инфраструктуры, в т.ч. производство собственно ускорителей — на 2027 год запланированы поставки уже Trainium4. Так или иначе, даже после снижения доли СЖО спрос на компоненты у партнёров должен увеличиться за счёт роста производства в целом. Рост популярности жидкостного охлаждения в ИИ ЦОД в последние годы во многом обусловлен ростом TDP ускорителей NVIDIA. Если у H200 показатель был на уровне около 700 Вт, то у B200 — порядка 1000 Вт, а у B300 — уже 1400 Вт. Для будущих архитектур с двумя чипами значения будут ещё выше. В результате операторам ЦОД требуется эффективный отвод тепла, что могут обеспечить СЖО. Кроме того, это позволяет повысить плотность размещения оборудования.  В сегменте ASIC рост TDP заметно ниже. Так, для Trainium2 речь шла об около 500 Вт, у Trainium3 — всего 800 Вт, поэтому воздушное охлаждение — вполне рабочий вариант, за исключением некоторых сценариев, например, с высокой плотностью размещения оборудования. Также источники в цепочке поставок подчёркивают, что жидкостные системы дороже устанавливать и обслуживать в сравнении с современными воздушными вариантами. При этом экосистема производства и обслуживания СЖО часто оценивается как «менее зрелая». Благодаря этому организовать поставки серверов с воздушным охлаждением можно быстрее, и они будут более стабильными. Беспокойство операторов ЦОД может вызывать и репутация жидкостных систем. Например, в конце января Wave Power объявила о том, что некоторые проданные компоненты СЖО для ИИ-систем привели к повреждению оборудования, поэтому компании пришлось выложить $4,5 млн, чтобы заключить мировое соглашение. По мнению экспертов, утечки в СЖО — довольно распространённое явление, не привязанное к конкретному вендору, но каждый подобный инцидент свидетельствует о потенциальных проблемах, которые заказчикам приходится принимать в расчёт.  Хотя системы жидкостного охлаждения технически предпочтительнее для самых энергоёмких нагрузок благодаря высокой эффективности теплоотвода, потенциалу снижения показателя PUE и способности обеспечить экономию пространства, на примере Trainium3 можно оценить, как совокупность факторов, включая совокупную стоимость владения (TCO) и операционные риски влияют на сроки внедрения СЖО. Изменение планов AWS может повлиять на всю индустрию ИИ ЦОД, которая может замедлить повсеместный переход на жидкостное охлаждение, по крайней мере, в краткосрочной перспективе. Вместе с тем даже для ИИ-платформ нынешнего поколения гиперскейлеры разработали гибридные варианты охлаждения, позволяющие использовать современные системы в старых ЦОД, не рассчитанных изначально на крупномасштабные СЖО. Так, Meta✴ «растянула» суперускорители NVIDIA GB200 на шесть стоек вместо одной, чтобы разместить там теплообменники, а Microsoft с той же целью «пристроила» к стойке с оборудованием модуль шириной в ещё пару стоек. Google же предпочитает для своих TPU именно СЖО.
17.12.2025 [16:41], Владимир Мироненко
Amazon не прочь инвестировать $10 млрд в OpenAI и дать стартапу фирменные ИИ-ускорители TrainiumAmazon ведет переговоры с OpenAI о возможных инвестициях более $10 млрд в стартап, предоставлении ему ускорителей серии Trainium и сдаче в аренду дополнительных вычислительных мощностей, сообщила газета The Financial Times. По словам её источников, знакомых с ситуацией, в случае заключения сделки капитализация OpenAI может превысить $500 млрд. Впрочем, переговоры находятся на ранней стадии и говорить об этом пока рано. Переговоры проходят после пересмотра первоначальной сделки стартапа с его ранним инвестором Microsoft. Компании реструктурировали свои отношения, что позволило OpenAI заключить соглашения об использовании вычислительных мощностей конкурирующих с Microsoft облачных провайдеров. В частности, стартап подписал сделку с Amazon, обязавшись потратить $38 млрд на аренду ИИ-ускорителей NVIDIA в течение семи лет. Обсуждаемое сейчас соглашение об инвестициях и облачных сервисах будет заключено в дополнение к этому соглашению. Ранее OpenAI обязался использовать сервисы Azure на $250 млрд. Microsoft сохраняет эксклюзивные права на передовые модели OpenAI до 2032 года. На данный момент стартапом заключены соглашения на сумму $1,5 трлн с NVIDIA, Oracle, AMD и Broadcom на поставку чипов и услуги вычислительной инфраструктуры. Циклический характер заключённых OpenAI сделок, а также отсутствие понятных механизмов коммерциализации ИИ и обоснованных расчётов стартапа по обеспечению окупаемости инвестиций, вызывает обеспокоенность некоторых инвесторов, считающих, что ИИ-индустрия находится на пути к формированию пузыря. 
Источник изображения: Amazon OpenAI не единственная, кто заключает сделки с поставщиками. Например, разработчик ИИ-моделей Anthropic, привлёк в общей сложности около $26 млрд инвестиций от Amazon, Google, Microsoft и NVIDIA, используя их оборудование и сервисы. Amazon является одним из крупнейших инвесторов Anthropic. С 2023 года она вложила в стартап около $8 млрд. Обсуждаемая с Amazon сделка также знаменует собой еще один шаг в попытках OpenAI диверсифицировать чипы, используемые для обучения и запуска своих моделей. Источники сообщили, что Amazon и OpenAI также обсуждают коммерческое сотрудничество, связанное с маркетплейсом технологического гиганта. Стартап стремится закрепиться в сфере электронной коммерции и уже заключил сделки с Etsy, Shopify и Instacart с целью создания новых источников дохода.
03.12.2025 [13:25], Сергей Карасёв
AWS представила ИИ-ускорители Trainium3: 144 Гбайт памяти HBM3E и 2,52 Пфлопс в режиме FP8Облачная платформа Amazon Web Services (AWS) анонсировала ускорители Trainium3 для задач ИИ, а также серверы Trainium3 UltraServer (Trn3 UltraServer). Эти машины, как утверждается, превосходят решения предыдущего поколения — Trainium2 UltraServer — в 4,4 раза по производительности, в 4 раза по энергоэффективности и почти в 4 раза по пропускной способности памяти. Чипы Trainium3 изготавливаются по 3-нм технологии TSMC. Они оснащены 144 Гбайт памяти HBM3E с пропускной способностью до 4,9 Тбайт/с. По сравнению с Trainium2 объём памяти увеличился в 1,5 раза, её пропускная способность — в 1,7 раза. Ранее сообщалось, что энергопотребление новых ускорителей может достигать 1 кВт. 
Источник изображений: AWS Изделие Trainium3 предназначено для высокоплотных и сложных параллельных рабочих нагрузок с использованием расширенных типов данных (MXFP8 и MXFP4). По утверждениям AWS, на операциях FP8 быстродействие достигает 2,52 Пфлопс. Для сравнения, AMD Instinct MI355X показывает результат в 10,1 Пфлопс, а чип поколения NVIDIA Blackwell — 9 Пфлопс. Как уточняет The Register, ускорители Trainium3 используют структурированную разрежённость (structured sparsity) формата 16:4, что фактически поднимает производительность в четыре раза — до 10 Пфлопс — на таких задачах, как обучение ИИ-моделей.   Системы Trainium3 UltraServer объединяют 144 ускорителя Trainium3, которые соединены посредством интерконнекта NeuronSwitch-v1: эта технология, по оценкам AWS, увеличивает пропускную способность в два раза по сравнению с машинами UltraServer предыдущего поколения. Усовершенствованная сетевая архитектура Neuron Fabric сокращает задержки при передаче данных между чипами до менее чем 10 мкс. Каждая система Trainium3 UltraServer оперирует 20,7 Тбайт памяти HBM3E с общей пропускной способностью 706 Тбайт/с. Заявленная производительность достигает 362 Пфлопс в режиме FP8. 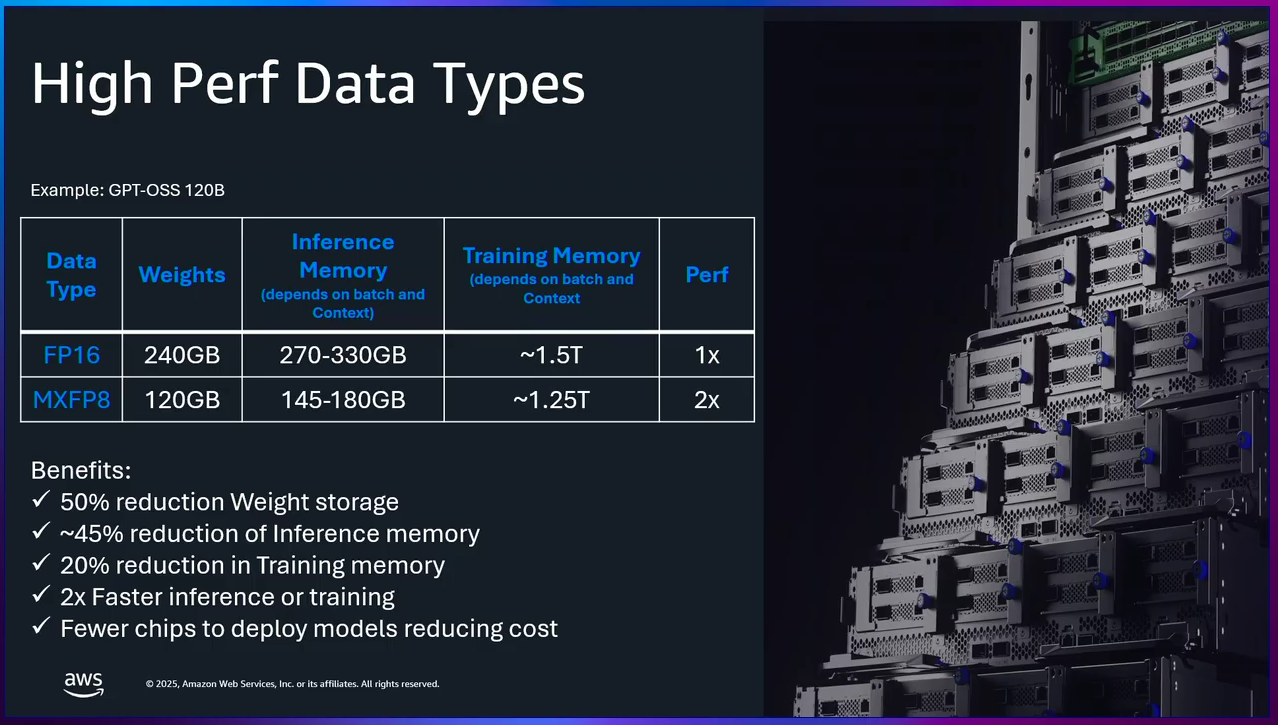  Применённые в Trainium3 технологии, как заявляет AWS, дают возможность создавать приложения ИИ с практически мгновенным откликом. Платформа EC2 UltraClusters 3.0 позволяет объединять тысячи систем UltraServer, содержащих до 1 млн ускорителей Trainium, что в 10 раз больше, чем в случае изделий предыдущего поколения. При этом следующее поколение ускорителей Trainium4 получит интерконнект NVLink Fusion шестого поколения.
03.12.2025 [01:28], Владимир Мироненко
AWS «сдалась на милость» NVIDIA: анонсированы ИИ-ускорители Trainium4 с шиной NVLink FusionAWS готовит Arm-процессоры Graviton5, которые составят компанию ИИ-ускорителям Trainium4 с интерконнектом NVLink Fusion, фирменными EFA-адаптерам и DPU Nitro 6 с движком Nitro Isolation Engine. Но что более важно, все они будут «упакованы» в стойки стандарта NVIDIA MGX. Amazon и NVIDIA объявили о долгосрочном партнёрстве, в рамках которого ИИ-ускорители Trainium4 получит шину NVIDIA NVLink Fusion шестого поколения (по-видимому, 3,6 Тбайт/с в дуплексе), которая позволит создать стоечную платформу нового поколения, причём, что интересно, на базе архитектуры NVIDIA MGX, которая передана в OCP. Пикантность ситуации в том, что AWS годами практически игнорировала OCP, самостоятельно создавая стойки, их компоненты, включая СЖО, и архитектуру ИИ ЦОД в целом. Даже в нынешнем поколении стоек с GB300 NVL72 отказалась от референсного дизайна NVIDIA. NVIDIA же напирает на то, что для гиперскейлерам крайне трудно заниматься кастомными решениями — циклы разработки стоечной архитектуры занимают много времени, поскольку помимо проектирования специализированного ИИ-чипа, гиперскейлеры должны озаботиться вертикальным и горизонтальным масштабированием, интерконнектами, хранилищем, а также самой конструкцией стойки, включая лотки, охлаждение, питание и ПО. 
Источник изображения: NVIDIA Вместе с тем управление цепочкой поставок отличается высокой сложностью, так как требуется обеспечить согласованную работу десятков поставщиков, ответственных за десятки тысяч компонентов. И даже одна задержка поставки или замена одного компонента может поставить под угрозу весь проект. Платформа NVIDIA если не устраняет целиком, то хотя бы смягчает эти проблемы, предлагая готовые стандартизированные решения, которые могут поставлять множество игроков рынка. 
Источник изображения: NVIDIA По словам NVIDIA, в отличие от других подходов к масштабированию сетей, NVLink — проверенная и широко распространённая технология. В сочетании с фирменным ПО NVLink Switch обеспечивает увеличение производительности и дохода от ИИ-инференса до трёх раз, объединяя 72 ускорителя в одном домене. Пользователи, внедрившие NVLink Fusion, могут использовать любую часть платформы — каждый компонент может помочь им быстро масштабироваться для удовлетворения требований интенсивного инференса и обучения моделей агентного ИИ, говорит NVIDIA. 
Источник изображения: AWS Что касается самих ускорителей Trainium4, то в сравнении с Trainium3 они будут вшестеро быстрее в FP4-расчётах, втрое быстрее в FP8-вычислениях, а пропускная способность памяти будет увеличена вчетверо. Впрочем, пока собственные ускорители Amazon не всегда могут составить конкуренцию чипам NVIDIA. Любопытно и то, что в рассказе о Trainium3 компания отметила о переходе от PCIe к UALink в коммутаторах NeuronSwitch для фирменного интерконнекта NeuronLink, объединяющего до 144 чипов Trainium. Однако после крупных инвестиций NVIDIA в Synopsys развитие UALink как открытой альтернативы NVLink теперь под вопросом.
21.11.2025 [14:14], Руслан Авдеев
AWS и Humain построят в Эр-Рияде кампус AI Zone, где развернут до 150 тыс. ИИ-ускорителей NVIDIA GB300 и Amazon TrainiumAWS и инвестиционная компания Humain из Саудовской Аравии объявили о планах развёртывания в кампусе AI Zone в Эр-Рияде до 150 тыс. ИИ-ускорителей. В рамках расширенного партнёрства компании намерены предоставлять вычислительные мощности и ИИ-сервисы из Саудовской Аравии клиентам со всего мира. Первый в своём роде в Саудовской Аравии кампус AI Zone будет применяться для обучения ИИ и инференса, с доступом к новейшей ИИ-инфраструктуре на основе ускорителей NVIDIA GB300 и Amazon Trainium. Клиенты смогут быстро переходить от стадии концепции к непосредственно работам, а «железо» и ПО NVIDIA будут бесшовно интегрированы с инфраструктурой и сервисами AWS. Поддержка Amazon Bedrock, AgentCore и SageMaker обеспечит клиентам немедленный доступ к базовым моделям в рамках единой платформы без необходимости управления базовой инфраструктурой. Для расширения возможностей AI Zone компания Humain присоединится к программе AWS Solution Provider Program. Это поможет реализации совместного плана, анонсированного в мае 2025 года и предусматривающего инвестиции более $5 млрд в ИИ-инфраструктуру, сервисы AWS, обучение и развитие ИИ-специалистов в Саудовской Аравии. Представитель AWS в регионе EMEA заявил, что объединяя локальный опыт и инвестиции Humain с решениями AWS в сфере ИИ, а также аппаратные решения NVIDIA, инновационную платформу Amazon Bedrock и решения для бизнес-пользователей, включая Amazon Quick Suite, партнёры создают инновационный центр мирового уровня, способный обслуживать клиентов по всему миру. AWS и Humain также ускорят внедрение ИИ в государственном и частном секторах, в том числе развитие LLM с поддержкой арабского языка, включая ALLAM, и создание единого маркетплейса ИИ-агентов для правительственных сервисов. 
Истчоник изображения: backer Sha/unsplash.com Для подготовки квалифицированных кадров AWS обучит 100 тыс. граждан Саудовской Аравии работе с облачными технологиями и специфике генеративного ИИ в рамках программы Amazon Academy, отдельно планируется поддержать программу повышения квалификации для 10 тыс. женщин. Усилия направлены на подготовку кадров для «ИИ-центричной» экономики, которая, по прогнозам, к 2030 году внесёт в ВВП страны вклад в объёме $130 млрд. Подобные проекты стали возможны во многом благодаря визиту в США наследного принца Саудовской Аравии Мохаммеда бин Салмана (Mohammed bin Salman). Визит способствовал ряду соглашений американских компаний с саудовским бизнесом и Humain в частности — с участием AMD, xAI, NVIDIA и др., а также открыл дорогу для поставок в королевство передовых ИИ-чипов. |
|

