Материалы по тегу: hpc
|
24.06.2026 [01:23], Владимир Мироненко
Европа получит 35 суперкомпьютеров на чипах NVIDIANVIDIA объявила о разработке по всей Европе 35 суперкомпьютеров на базе её чипов, которые позволят более 3 млн исследователей ускорить проведение научных исследований и внедрение промышленных инноваций в сфере ИИ. Это крупнейшее за год расширение в Европе сети суперкомпьютеров, охватывающее национальные суперкомпьютерные центры, ИИ-фабрики и академические исследовательские институты. Эти системы будут поддерживать исследования в области климатологии, здравоохранения, декарбонизации чистой энергетики, квантовых вычислений и фундаментальной науки. Работу большей части европейских ИИ-фабрик обеспечивают платформы Blackwell и Hopper, при этом с прошлого года было развернуто или анонсировано 800 Эфлопс вычислительных мощностей для ИИ. Эти суперкомпьютеры, включая обновлённый EuroHPC MareNostrum5 AI Барселонского суперкомпьютерного центра (BSC-CNS), Blue Swan (BavariaAI), IT4LIA, HammerHAI Центра высокопроизводительных вычислений в Штутгарте (HLRS) и ИИ-фабрика Mimer Национальной академической суперкомпьютерной инфраструктуры Швеции (NAISS), основаны на передовой ИИ-инфраструктуре NVIDIA, говорит компания. Так, суперкомпьютер MareNostrum 5 будет дооснащён системами GB300 NVL72 и GB200 NVL4, объединённых интерконнектом NVIDIA Quantum-X800 InfiniBand. Система, обеспечивающая производительность до 20 Эфлопс при обучении ИИ и 33 Эфлопс при ИИ-инференсе, позволит ускорить работу генеративного ИИ, климатическое моделирование, исследования в области здравоохранения и биотехнологий, устойчивого сельского хозяйства, энергетических систем и госсервисов. 
Источник изображения: NVIDIA Система Blue Swan (BavariaAI) добавит 1 тыс. ускорителей (GB200 NVL4 и Quantum-2 InfiniBand) суперкомпьютерным центрам FAU Erlangen и LRZ. Платформа обеспечит производительность до 11 Эфлопс при обучении ИИ и 22 Эфлопс при ИИ-инференсе. Она будет поддерживать инициативу Баварии по созданию базовых моделей, продвигая открытые мультимодальные модели для науки, государственного управления, исследований в области здравоохранения, робототехники и т.д. HammerHAI (HLRS) представляет собой первую в Германии ИИ-фабрику с более чем 850 GPU на базе GB200 NVL4 с Quantum-X800 InfiniBand. Суперкомпьютер HammerHAI, обеспечивающий производительность до 8 Эфлопс при обучении ИИ и 15 Эфлопс при ИИ-инференсе, обеспечит исследователям и промышленным пользователям безопасную ИИ-инфраструктуру для инженерного моделирования, инференса и научных исследования. Суперкомпьютер Mimer EuroHPC AI Factory (NAISS), размещённый в Линчёпингском университете (LiU, Швеция), будет использовать 100 систем GB200 NVL4 и сеть ConnectX-8. Обеспечивая производительность до 4 Эфлопс при обучении ИИ и около 7 Эфлопс при ИИ-инференсе, Mimer AI Factory будет способствовать развитию шведской ИИ-экосистемы в таких областях, как биологические науки, материаловедение, автономные системы, доверенный ИИ и т.д. Наконец, ИИ-фабрика IT4LIA с более чем 8 тыс. GPU на базе GB200 NVL4 с Quantum-X800 InfiniBand и ПО NVIDIA AI Enterprise обеспечивает производительность в размере 82 Эфлопс при обучении ИИ и 164 Эфлопс при ИИ-инференсе.
23.06.2026 [12:00], Игорь Осколков
Китайский суперкомпьютер LineShine стал самым производительным в мире и возглавил TOP500Июньский рейтинг самых производительных суперкомпьютеров мира TOP500 принёс неожиданный сюрприз — впервые за несколько лет в список попала новая, крупная машина LineShine из Китая. И не только попала, но и сразу заняла в нём первое место. Более того, она же первой публично преодолела порог FP64-производительности 2 Эфлопс, опираясь только на CPU. Импортонезависимая система LineShine достигла 2,198 Эфлопс в бенчмарке HPL, что составляет порядка 80 % от пиковой теоретической производительности (2,736 Эфлопс), что для столь крупной машины хороший результат. Не менее примечательно, что и в HPCG эта система тоже занимает первое место с результатом 22 Пфлопс, обгоняя El Capitan (17,41 Пфлопс) и Fugaku (16,00). В Green500, правда, она занимает аж 50 место, поскольку потребляет 42,2 МВт, что даёт около 52,07 Гфлопс/Вт. Но, во-первых, данный суперкомпьютер лишён ускорителей, а во-вторых — улучшать энергоэффективность сложнее, чем производительность. LineShine находится в Национальном суперкомпьютерном центре Шэньчжэня (NSCCSZ) и базируется на кастомным китайских 304-ядерных Arm-процессорах LX2 (1,55 ГГц) и платформе LingKun.Всего 13,79 млн ядер, объединённых проприетарным интерконнектом LingQi работающих под управлением ОС Kylin. В ИИ-бенчмарке HPL-MxP система заняла четвёртое место с показателем 7,92 Эфлопс, т.е. разница между FP64-вычислениями в традиционном Linpack и вычислениями со смешанной точностью составляет довольно скромные 3,6x, что опять-таки указывает на архитектуру без выделенных ИИ-ускорителей. 
Источник изображения: Markus Winkler / Unsplash Ещё один новичок в первой десятке TOP500 — итальянский суперкомпьютер Eni HPC7 с устоявшейся производительностью 571,5 Пфлопс (в пике 861,13 Пфлопс), который занял шестое место. Он построен на ровно той же платформе, что и бывший лидер списка El Capitan: узлы HPE Cray EX255a с APU AMD Instinct MI300A. При этом у Eni теперь сразу две машины в Топ-10, поскольку система HPC6 (477,9/606,97 Пфлопс) находится на восьмом месте. Они бы, к слову, могли бы оказаться непосредственными соседями, если бы Microsoft решила обновить тесты своего облачного суперкомпьютера Eagle. Ресурсы у неё точно есть, а вот желание трать драгоценное машинное время ИИ-ускорителей на бенчмарки вряд ли есть. Система Fugaku также остаётся в первой десятке, уже шестой год подряд. Впрочем, если бы не нежелание Китая делиться информацией о своих системах, дефицита в которых явно нет, апдейты к TOP500 были бы гораздо чаще и интереснее. Авторы рейтинга отдельно отмечают разнообразие аппаратных платформ, подчёркивая, что добраться до экзафлопса можно разными путями. Речь и про процессоры, и про ускорители, и про интерконнекты. Всего в новом списке TOP500 появилось 44 новых машины, а минимальный порог вхождения повысился до округлённо 2,66 Пфлопс. Для вхождения же в первую десятку нужно как минимум 434,9 Пфлопс. Среди поставщиков в Топ-10 с точки зрения производительности лидирует HPE (El Capitan, Frontier, Aurora, HPC7, HPC6 и Alps). По процессорам в лидерах снова AMD (El Capitan, Frontier, HPC7 и HPC6). NVIDIA представлена в трёх системах (JUPITER Booster, Eagle, and Alps), а Intel — в двух (Aurora и Eagle). Atos/Eviden/Bull и Fujitsu поставили по одной системе, JUPITER Booster и Fugaku соответственно. Ну а LineShine гордо стоит в стороне от всех основных вендоров. Новых заявок от российских компаний по-прежнему нет. А из новичков среди стран можно упомянуть Индонезию с системой на объекте ASEAN-Korea HPC (436 место) и Узбекистан с государственным суперкомпьютером (321 место).
23.06.2026 [11:33], Сергей Карасёв
В Японии появился гибридный квантово-классический суперкомпьютер Roquo производительностью 19,8 ПфлопсВ Центре вычислительных наук японского Института физико-химических исследований (R-CCS) введён в строй гибридный квантово-классический суперкомпьютер Roquo, названный в честь горы Рокко к северу от города Кобе. В создании НРС-системы приняли участие DTS, NVIDIA, Giga Computing, DDN и ScaleWorX. Roquo состоит из 135 вычислительных узлов на базе NVIDIA GB200 NVL4. В общей сложности задействованы 540 чипов Blackwell и 270 чипов NVIDIA Grace. Применяется интерконнект NVIDIA Quantum-X800 InfiniBand с общей пропускной способностью до 3,2 Тбит/с (установлены коммутаторы Q3400, поддерживающие скорость передачи данных 800 Гбит/с на порт). Реализовано жидкостное охлаждение. Заявленная производительность на операциях FP64 составляет 19,8 Пфлопс, а теоретическое пиковое быстродействие на операциях FP8 превышает 5 Эфлопс. Суперкомпьютер использует интерфейс SQC, что позволяет формировать гибридные среды с поддержкой традиционных и квантовых вычислений. 
Источник изображения: RIKEN В рамках проекта по созданию Roquo корпорация DTS осуществляла общую разработку платформы в соответствии с требованиями R-CCS. В свою очередь, NVIDIA предоставила базовые вычислительные и сетевые компоненты, тогда как Giga Computing отвечала за проектирование и производство серверов. DDN предоставила высокоскоростное файловое хранилище. Наконец, специалисты ScaleWorX осуществили общую системную интеграцию. Суперкомпьютер Roquo, как ожидается, поможет ускорить разработку и оценку эффективности новых квантовых алгоритмов. Кроме того, система будет использоваться для решения сложных задач, с которыми не в состоянии справиться классические НРС-комплексы.
22.06.2026 [12:53], Сергей Карасёв
Intersect360: годовой объём мирового рынка ИИ-инфраструктур превысил $300 млрдПо оценкам аналитической компании Intersect360 Research, затраты на глобальном рынке инфраструктур для дата-центров, ориентированных на ИИ-нагрузки, в 2025 году увеличились на 60,1 %, превысив $300 млрд. Ключевым драйвером отрасли выступают гиперскейлеры, продолжающие активно наращивать вычислительные мощности. Отмечается, что в абсолютном выражении доминирует именно сегмент гиперскейлеров, на который пришлось более $200 млрд расходов. В то же время затраты в области корпоративных ИИ-инфраструктур (включая HPC-направление) в 2025-м оказались на уровне $71,6 млрд. В дальнейшем, по мнению аналитиков, среднегодовой темп роста в сложных процентах (CAGR) на мировом рынке ИИ-инфраструктур будет исчисляться двузначными числами процентов. В результате, к 2030-му суммарные расходы преодолеют отметку в $500 млрд. В сегменте корпоративных ИИ-инфраструктур показатель прогнозируется в объёме более $130 млрд. Вместе с тем специалисты Intersect360 Research указывают на трансформацию рассматриваемой отрасли. В частности, наблюдается сдвиг в сторону облачных платформ для задач ИИ и суверенных дата-центров, оптимизированных для соответствующих нагрузок. 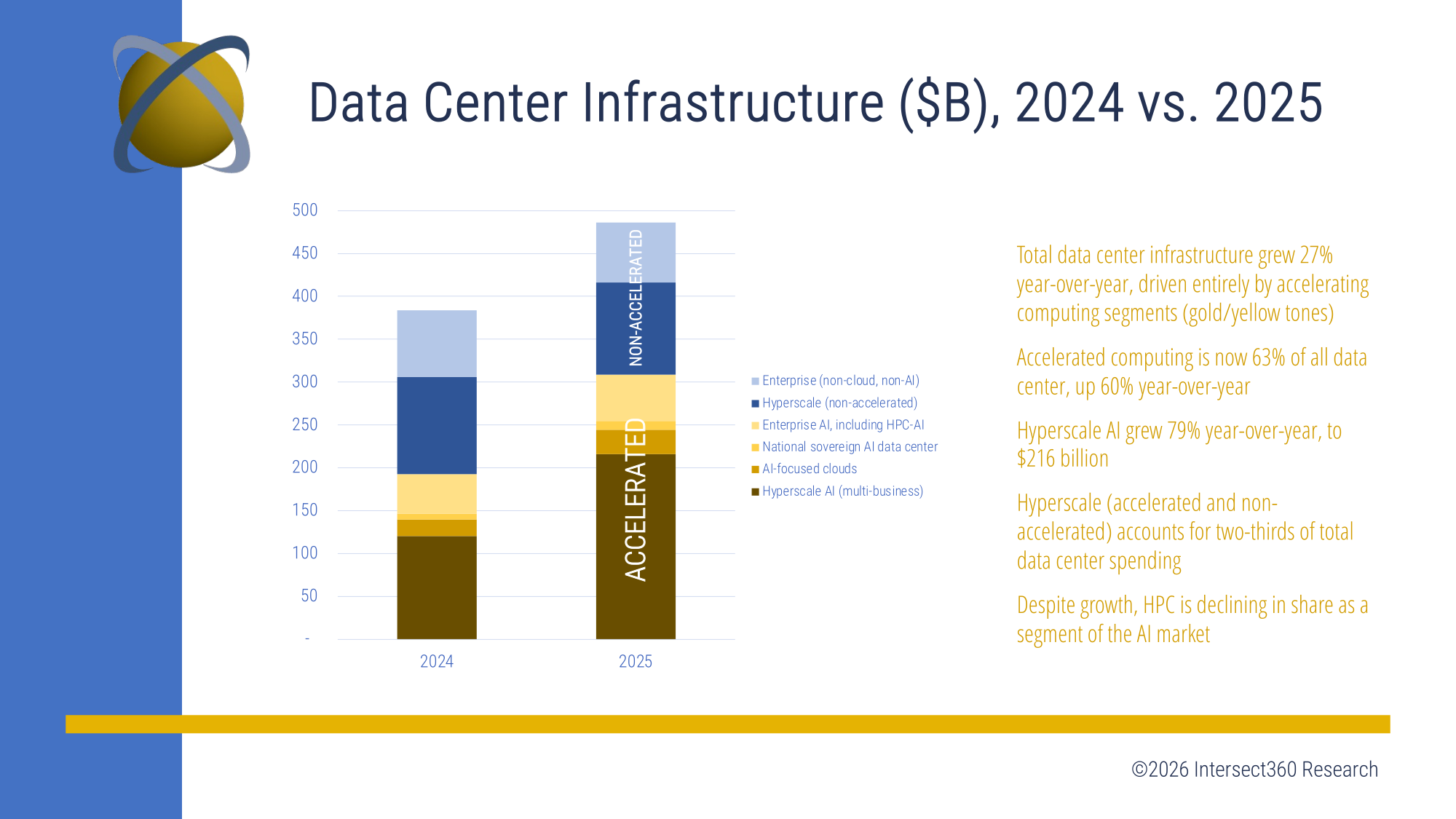
Источник изображения: Intersect360 Причём направление суверенных ЦОД демонстрирует самые высокие темпы роста, что связано со сформировавшейся геополитической обстановкой и санкционными ограничениями. Такие площадки функционируют полностью в пределах географических границ конкретной страны, что устраняет риски, обусловленные применением иностранных платформ.
В целом, указывают аналитики, до 2030 года основную часть прироста рынка обеспечат ускорители на базе GPU, высокопроизводительные серверы и облачные сервисы, оптимизированные для ИИ. При этом затраты в сегменте традиционной корпоративной инфраструктуры останутся на прежнем уровне или даже сократятся в реальном выражении.
20.06.2026 [15:45], Сергей Карасёв
В Словении запущена НРС-система FRIDA с ускорителями NVIDIA BlackwellЛюблянский университет в Словении (University of Ljubljana), по сообщению DataCenter Dynamics, запустил высокопроизводительную систему FRIDA, ориентированную на задачи ИИ и машинного обучения. Это не классический суперкомпьютер, а модульный контейнерный дата-центр, размещённый на крыше здания Факультета компьютерных и информационных наук (FRI) в Любляне. Известно, что в составе FRIDA задействованы 104 ускорителя на основе GPU. В частности, применяются изделия NVIDIA Blackwell B200 и B300. Суммарный объём GPU-памяти составляет 16,8 Тбайт. Комплекс оборудован гибридной воздушно-жидкостной системой охлаждения. Все вычислительные узлы связаны интерконнектом с высокой пропускной способностью. Отмечается, что производительность FRIDA при вычислениях с низкой точностью достигает 708 Пфлопс. Пиковое быстродействие при операциях с разреженными матрицами низкой точности заявлено на уровне 1,42 Эфлопс. FRIDA дополнит словенскую НРС-систему Vega, которая была введена в строй в 2021 году в рамках проекта Европейского совместного предприятия по развитию высокопроизводительных вычислений (EuroHPC JU). Эта машина, основанная на процессорах AMD и ускорителях NVIDIA, демонстрирует FP64-производительность на уровне 6,9 Пфлопс. 
Источник изображения: linkedin.com Vega задумывалась как универсальная платформа для сложных вычислений: она может применяться для решения задач в самых разных областях, включая биоинженерию и разработку новых лекарств, изучение климата и прогнозирование погоды, персонализированную медицину, создание новых материалов и пр. В свою очередь, система FRIDA ориентирована прежде всего на нагрузки, связанные с ИИ.
18.06.2026 [13:26], Сергей Карасёв
В Италии запущены квантовые компьютеры Nox и Sol, которые дополнят суперкомпьютер LeonardoЕвропейское совместное предприятие по развитию высокопроизводительных вычислений (EuroHPC JU) объявило о запуске квантового компьютера Sol, смонтированного на площадке суперкомпьютерного центра Cineca в Болонье (Италия). Система предоставит европейским пользователям новые инструменты для решения задач в области ИИ, НРС и квантовых технологий. Компьютер Sol, спроектированный компанией Pasqal, основан на нейтральных атомах. На первом этапе система будет использовать как минимум 140 кубитов в аналоговом режиме. На 2027 год запланировано обновление комплекса, включающее переход на гибридную аналогово-цифровую модель: предполагается, что это расширит сферу применения устройства. Квантовая платформа Sol интегрирована с итальянским суперкомпьютером Leonardo. Благодаря этому возможна организация квантово-классических вычислений для решения сложных задач, с которыми не в состоянии справиться традиционные суперкомпьютеры. При этом сама платформа Leonardo получила расширение LISA (Leonardo Improved Supercomputing Architecture) — это специальный раздел, оптимизированный для ИИ-нагрузок. Вычислительный блок, поставленный компанией Bull, объединяет 166 серверов, каждый из которых несёт на борту восемь ИИ-ускорителей на базе GPU (в сумме 1328 чипов). 
Источник изображения: Pasqal Кроме того, в Италии введён в строй квантовый компьютер Nox с 54 кубитами. Эта машина использует сверхпроводящую систему Radiance компании IQM. Как и Sol, комплекс Nox будет функционировать в связке с Leonardo, поддерживая гибридные квантово-классические вычисления. Реализация проектов по развёртыванию новых систем осуществлялась при финансовой поддержке Министерства просвещения, университетов и научных исследований Италии (MUR), Национального исследовательского центра Италии в области высокопроизводительных вычислений, больших данных и квантовых вычислений (ICSC), а также Европейского союза (через EuroHPC JU).
18.06.2026 [02:05], Сергей Карасёв
В США заработал суперкомпьютер Lynx с интерконнектом Cornelis Omni-Path CN5000В Ливерморской национальной лаборатории имени Лоуренса (LLNL) Министерства энергетики США (DOE) развёрнут вычислительный комплекс Lynx. Этот суперкомпьютер создан в рамках программы CTS-2 (Commodity Technology Systems) Национального управления ядерной безопасности США (NNSA). Полностью характеристики машины пока не раскрываются. Известно, что она состоит из 952 узлов на базе серверов Dell PowerEdge C6620 и PowerEdge R760 с процессорами Intel Xeon Sapphire Rapids. Ранее сообщалось, что каждый из узлов располагает 512 Гбайт DDR5. Особенностью Lynx является использование 400G-интерконнекта Cornelis Omni-Path CN5000. Данная технология оптимизирована специально для задач ИИ и НРС: она обеспечивает низкие задержки, минимизацию перегрузок, почти линейное масштабирование производительности обучения для больших языковых моделей (LLM) и более эффективный инференс. 
Источник изображения: Cornelis Новый суперкомпьютер предоставит дополнительные мощности для программы NNSA ASC по передовому моделированию и вычислениям (Advanced Simulation and Computing). Кроме того, использовать ресурсы системы планируется при решении широкого спектра задач в области национальной безопасности. «Lynx представляет собой важную веху в рамках усилий NNSA по оценке и внедрению HPC-технологий следующего поколения», — заявила администрация ASC.
16.06.2026 [16:21], Сергей Карасёв
В Кембриджском университете запущен AMD-суперкомпьютер ZenithВ Кембриджском университете (University of Cambridge) в Великобритании состоялась церемония запуска высокопроизводительного вычислительного комплекса Zenith, предназначенного для научных исследований с использованием ИИ. Инвестиции в проект составили около £36 млн ($48,3 млн). В создании суперкомпьютера приняли участие компании AMD и Dell Technologies. Полностью характеристики машины пока не раскрываются. Известно, что в её основу положены серверы PowerEdge, оборудованные процессорами AMD EPYC поколения Turin. Кроме того, задействованы ИИ-ускорители Instinct MI355X с 288 Гбайт памяти HBM3E (8 Тбайт/с). Вместе с тем AMD, Dell и Кембриджский университет объявили о планах создания на территории Великобритании Лаборатории инноваций в области суверенного ИИ (Sovereign AI Innovation Lab — SAIL). Инициатива, как ожидается, позволит расширить доступ к передовой ИИ-инфраструктуре и НРС-ресурсам для исследователей, медицинских организаций, государственных учреждений и других участников отрасли. На площадке SAIL компании смогут разрабатывать, оценивать и внедрять передовые технологии ИИ. Ключевой задачей SAIL названо формирование открытой ИИ-экосистемы на базе вычислительных платформ AMD, программного обеспечения AMD ROCm и облачных технологий. Отмечается, что благодаря появлению SAIL исследователи смогут масштабировать ИИ-решения с применением суверенной инфраструктуры, что ускорит инновации в таких областях, как здравоохранение, энергетика, экология, передовые инженерные разработки и пр. 
Источник изображения: University of Cambridge Одновременно AMD и Dell занимаются созданием ещё одного британского ИИ-суперкомпьютера — системы Sunrise. Этот проект финансируется Департаментом энергетической безопасности и достижения нулевого уровня выбросов (DESNZ) в составе Агентства по атомной энергии Великобритании (UKAEA).
15.06.2026 [12:58], Сергей Карасёв
В Сингапуре запущен суперкомпьютер ASPIRE 2B на базе NVIDIA H200 и AMD EPYC Turin с быстродействие 115 ПфлопсНациональный суперкомпьютерный центр Сингапура (NSCC) объявил о запуске вычислительного комплекса ASPIRE 2B с производительностью 115 Пфлопс. Систему планируется использовать для решения сложных задач в области климатологии и метеорологии, здравоохранения, разработки материалов, передового производства, ИИ и пр. В основу ASPIRE 2B положены 96-ядерные процессоры AMD EPYC 9655 поколения Turin: суммарное количество вычислительных ядер в составе суперкомпьютера достигает 184 320 (задействованы 1920 чипов). Быстродействие CPU-секции находится на уровне 12 Пфлопс. GPU-раздел машины объединяет 1536 ускорителей NVIDIA H200 со 141 Гбайт памяти HBM3e. Их суммарная пиковая производительность указана на отметке 103 Пфлопс. Объём системной памяти составляет 1072 Тбайт, вместимость подсистемы хранения данных — 63,5 Пбайт. Применяется интерконнект Slingshot с пропускной способностью 400 Гбит/с. Суперкомпьютер ASPIRE 2B планируется интегрировать с квантовой системой Helios компании Quantinuum, установка которой в Сингапуре запланирована на конец нынешнего года. Это позволит осуществлять гибридные квантово-классические вычисления в рамках комплексных проектов, связанных с молекулярным моделированием и созданием перспективных материалов. 
Источник изображения: NSCC Отмечается также, что NSCC меняет модель доступа пользователей к вычислительным ресурсам страны. Приоритет будет отдаваться национальным программам исследований и инноваций. Это должно способствовать ускорению развития передовых технологий и расширению сферы предпринимательства.
14.06.2026 [11:56], Сергей Карасёв
Великобритания потратит $1 млрд на ИИ-суперкомпьютер с британскими чипамиПравительство Великобритании анонсировало План развития аппаратного обеспечения в области ИИ (UK AI Hardware Plan). Речь идёт, в частности, о поддержке местных компаний, разрабатывающих чипы и полупроводниковые технологии для ИИ-систем. Кроме того, власти намерены предоставлять финансовую поддержку учёным, инженерам и техническим специалистам для ускорения вывода передовых продуктов на рынок. Планом предусмотрено выделение £750 млн (около $1 млрд) на разработку нового национального суперкомпьютера для задач ИИ. Эта система, как ожидается, будет развёрнута в Эдинбургском университете (University of Edinburgh) к 2030 году, став преемником флагманского суперкомпьютера ARCHER2 (на изображении). Технические подробности в будущем НРС-комплексе не раскрываются. Но известно, что около £400 млн ($535,6 млн) пойдёт на приобретение «чипов следующего поколения». В том числе £150 млн ($200,9 млн) планируется потратить на решения для инференса, а ещё £250 млн ($334,8 млн) — на специализированные процессоры. Предполагается, что в состав национального суперкомпьютера войдут чипы, разработанные в Великобритании. Тендер на создание системы будет объявлен в ближайшее время. 
Источник изображения: ARCHER2 В рамках плана £120 млн ($160,7 млн) пойдёт на финансирование новой программы инноваций в области аппаратного обеспечения для ИИ (AI Hardware Innovation Programme): британские компании получат средства на проектирование, разработку и тестирование передовых микросхем. Как минимум £20 млн ($26,8 млн) из указанной суммы пойдёт на развитие площадки Scaling Inference Lab, созданной Агентством перспективных исследований и изобретений Великобритании (ARIA) и размещённой на платформе CommonAI. На базе этой лаборатории британский стартап Oriole Networks в партнёрстве с AMD развернёт первую в мире крупномасштабную ИИ-систему, использующую исключительно фотонные сети. В составе комплекса планируется задействовать ускорители AMD Instinct и серверные процессоры AMD EPYC. План также предусматривает выделение £45 млн ($60,3 млн) на инициативы, связанные с подготовкой кадров и повышением квалификации специалистов в области разработки микрочипов. Намечено создание нового Центра подготовки докторантов в сфере проектирования микросхем (Centre for Doctoral Training in Chip Design) стоимостью £12 млн ($16 млн). |
|


