Материалы по тегу: hpc
|
14.06.2026 [11:56], Сергей Карасёв
Великобритания потратит $1 млрд на ИИ-суперкомпьютер с британскими чипамиПравительство Великобритании анонсировало План развития аппаратного обеспечения в области ИИ (UK AI Hardware Plan). Речь идёт, в частности, о поддержке местных компаний, разрабатывающих чипы и полупроводниковые технологии для ИИ-систем. Кроме того, власти намерены предоставлять финансовую поддержку учёным, инженерам и техническим специалистам для ускорения вывода передовых продуктов на рынок. Планом предусмотрено выделение £750 млн (около $1 млрд) на разработку нового национального суперкомпьютера для задач ИИ. Эта система, как ожидается, будет развёрнута в Эдинбургском университете (University of Edinburgh) к 2030 году, став преемником флагманского суперкомпьютера ARCHER2 (на изображении). Технические подробности в будущем НРС-комплексе не раскрываются. Но известно, что около £400 млн ($535,6 млн) пойдёт на приобретение «чипов следующего поколения». В том числе £150 млн ($200,9 млн) планируется потратить на решения для инференса, а ещё £250 млн ($334,8 млн) — на специализированные процессоры. Предполагается, что в состав национального суперкомпьютера войдут чипы, разработанные в Великобритании. Тендер на создание системы будет объявлен в ближайшее время. 
Источник изображения: ARCHER2 В рамках плана £120 млн ($160,7 млн) пойдёт на финансирование новой программы инноваций в области аппаратного обеспечения для ИИ (AI Hardware Innovation Programme): британские компании получат средства на проектирование, разработку и тестирование передовых микросхем. Как минимум £20 млн ($26,8 млн) из указанной суммы пойдёт на развитие площадки Scaling Inference Lab, созданной Агентством перспективных исследований и изобретений Великобритании (ARIA) и размещённой на платформе CommonAI. На базе этой лаборатории британский стартап Oriole Networks в партнёрстве с AMD развернёт первую в мире крупномасштабную ИИ-систему, использующую исключительно фотонные сети. В составе комплекса планируется задействовать ускорители AMD Instinct и серверные процессоры AMD EPYC. План также предусматривает выделение £45 млн ($60,3 млн) на инициативы, связанные с подготовкой кадров и повышением квалификации специалистов в области разработки микрочипов. Намечено создание нового Центра подготовки докторантов в сфере проектирования микросхем (Centre for Doctoral Training in Chip Design) стоимостью £12 млн ($16 млн).
14.06.2026 [11:51], Сергей Карасёв
В Австралии запущен суперкомпьютер MAVERIC на базе NVIDIA GB200 NVL72Университет Монаша (Monash University) в Австралии в партнёрстве с компаниями NVIDIA, Dell Technologies и ЦОД-оператором CDC Data Centres объявил о запуске суперкомпьютера MAVERIC (Monash AdVanced Environment for Research and Intelligent Computing). Новый НРС-комплекс смонтирован в Бруклинском центре CDC в Мельбурне. В основу системы положены серверы Dell PowerEdge XE9712 на платформе NVIDIA GB200 NVL72. Эти суперускорители объединяют 72 чипа B200 и 36 процессоров Grace. При этом каждое изделие B200 содержит 16 896 ядер CUDA, 528 тензорных ядер и 192 Гбайт памяти HBM3Е. MAVERIC использует передовую технологию жидкостного охлаждения с замкнутым контуром, благодаря чему отпадает необходимость в постоянном водоснабжении. Утверждается, что такое конструктивное решение не только снижает негативное влияние на окружающую среду, но и устанавливает новый стандарт для устойчивых высокопроизводительных вычислений. 
Источник изображения: Университет Монаша Показатели производительности MAVERIC не раскрываются. Но отмечается, что суперкомпьютер специально разработан для крупномасштабных задач ИИ и обработки больших объемов данных. Предполагается, что запуск машины поможет в решении важнейших глобальных проблем здравоохранения, включая раннюю диагностику рака, лечение хронических заболеваний, открытие новых лекарств и пр. Использовать ресурсы системы планируется и в других областях, включая моделирование климата и обработку конфиденциальной информации.
12.06.2026 [15:33], Сергей Карасёв
AMD, OQC и JPMorgan Chase создадут квантовую ИИ-платформуКомпания AMD, разработчик квантовых технологий Oxford Quantum Circuits (OQC) и финансовый конгломерат JPMorgan Chase объявили о заключении соглашения о сотрудничестве. Проект предусматривает создание нового дата-центра на основе квантовых вычислений для ИИ-задач. Формируемая площадка объединит квантовую систему Genesis, разработанную специалистами OQC, а также оборудование AMD для традиционных вычислений, в том числе ресурсоёмких нагрузок ИИ. Кроме того, будут задействованы специализированные программные инструменты для разработки ИИ-моделей, оптимизации и сравнительного анализа. Отвечать за строительство передового дата-центра будет OQC: объект разместится в Лондоне (Великобритания). Ввести систему в эксплуатацию планируется в течение ближайших 12 мес. На базе новой площадки партнёры намерены тестировать перспективные приложения, основанные на квантовых и гибридных квантово-классических вычислениях. Нагрузки будут запускаться в защищённой корпоративной среде, что обеспечит необходимый уровень безопасности. Главная цель проекта заключается в том, чтобы определить оптимальные способы совместного использования квантовых вычислений, алгоритмов ИИ и высокопроизводительной классической инфраструктуры для решения сложных задач. 
Источник изображения: AMD JPMorgan Chase станет первым пользователем платформы. Конгломерат намерен оценить производительность, масштабируемость и воспроизводимость гибридных квантово-классических рабочих процессов применительно к сектору финансовых услуг. В целом, проект знаменует собой переход от экспериментальных квантовых систем к безопасной, интегрированной инфраструктуре, разработанной для реальных рабочих процессов корпоративного уровня.
09.06.2026 [13:58], Руслан Авдеев
AMD поддержит суверенный ИИ в Великобритании, инвестировав в ИИ-отрасль страны £2 млрд
amd
dell
epyc
hardware
hpc
instinct
великобритания
ии
инвестиции
инференс
суперкомпьютер
финансы
фотоника
В следующие пять лет AMD рассчитывает инвестировать в усиление ИИ-экосистемы Великобритании до £2 млрд ($2,7 млрд), создав новую инфраструктуру, программы совместных исследований и подготовки кадров. По словам представителя техногиганта, новая стратегия согласуется с правительственным проектом AI Opportunities Action Plan и стратегией AI Hardware Strategy, с основным акцентом на суверенные ИИ-возможности, научные вычисления и передовые исследования, сообщает Converge! Digest. Ключевой компонент инициативы — расширение вычислительной ИИ-инфраструктуры. AMD и Dell Technologies поддерживают две новые суперкомпьютерные системы в Кембриджском университете. Суперкомпьютер Zenith AI, финансирование которого осуществляется Министерством науки, инноваций и технологий (DSIT) и структурой UK Research and Innovation (UKRI), строится как платформа для использования ИИ в науке. Система Sunrise создаётся совместно с Управлением по атомной энергии Великобритании для поддержки исследований в сфере термоядерных технологий. Оба суперкомпьютера будут использовать ускорители AMD Instinct, процессоры EPYC и ПО AMD для решения задач в сфере здравоохранения, климатологии, материаловедения, разработки научных ИИ-моделей и др. Также AMD анонсировала исследовательские партнёрства с Имперским колледжем Лондона и компанией Oriole Networks. В первом случае взаимодействие сосредоточено на вычислительных дисциплинах, здравоохранении, моделировании климата, ИИ-оптимизации, обработке значительных объёмов данных и др. В то же время AMD и Oriole Networks принимают участие в проекте Scaling Inference Lab британского агентства ARIA (Advanced Research and Invention Agency). Проект стоимостью £50 млн направлен на устранение ряда проблем современной ИИ-инфраструктуры. Он объединяет фотонную сетевую архитектуру PRISM компании Oriole, ускорители AMD Instinct, а также процессоры EPYC для оценки новых подходов к масштабированию задач ИИ-инференса с меньшей задержкой и повышенной энергоэффективностью. 
Источник изображения: Robert Bye/unsplash.com По словам Converge!, лондонский стартап Oriole Networks намерен преодолеть традиционные ограничения классических ИИ-кластеров. Если в стандартных сетях на основе InfiniBand или Ethernet многократные преобразования оптического сигнала в электрический и обратно создают дополнительные задержки, то архитектура PRISM (Photonic Routing Infrastructure for Scalable Models) заменяет активные электронные коммутаторы «пассивным» оптическим ядром маршрутизации. Прямые оптические соединения узлов позволяют сократить время простоя GPU, связанное с ожиданием обмена данными, что мешает масштабным ИИ-нагрузкам. PRISM обеспечивает обработку динамического ИИ-трафика без использования электрических буферов пакетов данных. Многомерная коммутация каналов позволяет перенастраивать соединения в режиме реального времени и оптимизировать сеть под интенсивный обмен данными, характерный для больших языковых моделей. Кроме того, Oriole утверждает, что её технология позволяет объединять до миллиона оконечных устройств. В конечном счёте сокращение энергопотребления сетевого ядра может составить до 81 %. Ключевым элементом архитектуры PRISM является независимость от конкретного типа используемых процессоров и ускорителей. Вместо использования проприетарных интерконнектов, «привязывающих» операторов к определённой аппаратной платформе, Oriole разделяет транспортный и вычислительный уровни инфраструктуры. Компания заявляет, что её технологии интегрируются в существующие стеки ПО через стандартные драйверы PCIe и специализированные библиотеки ускорения вроде NCCL для NVIDIA или RCCL для AMD. Благодаря этому можно поддерживать разные аппаратные платформы без трансформации базовых ИИ-фреймворков. Будущее внедрение технологии в рамках ARIA Scaling Inference Lab станет значимой проверкой её жизнеспособности для отрасли и продемонстрирует, способны ли полностью фотонные сети гарантировать предсказуемую производительность и обеспечивать открытость проприетарных вычислительных систем в промышленных масштабах.
01.06.2026 [21:33], Владимир Мироненко
Intel выпустит 192-ядерные процессоры Xeon Diamond Rapids на техпроцессе 18A-P в 2027 годуВместе с объявлением о выходе серии чипов Xeon 6+ (Clearwater Forest) компания Intel предоставила некоторые подробности о Xeon Diamond Rapids, выход которых намечен на 2027 год. Новый процессор будет выпускаться по техпроцессу 18A-P, усовершенствованной версии 2-нм техпроцесса. Компания сообщила, что Xeon Diamond Rapids получит на 50 % больше ядер, чем Granite Rapids-AP (6900P), т.е. 192 P-ядра. Это значительный прирост, но всё же меньше, чем у AMD, которая, как ожидается, уже в этом году предложит до 256 ядер Zen 6C в EPYC Venice. При этом Diamond Rapids не будет поддерживать Hyper-Threading (SMT). Эта технология вновь появится в Xeon Coral Rapids в 2028 году. Как сообщает The Register, на рендерах, представленных в пресс-релизе Intel, видно, что два I/O-чиплета обслуживают четыре вертикально расположенных вычислительных блока, собранных с использованием упаковки Foveros. Аналогичная компоновка используется в Clearwater Forest. Перенос L3-кеша на базовый тайл освобождает значительную площадь вычислительного чиплета. Здесь таковых четыре, по 48 ядер в каждом. The Register отметил, что в этом отношении Diamond Rapids похож на Fujitsu Monaka, который использует почти идентичную компоновку и 3.5D-упаковку Broadcom, хотя и с одним чиплетом I/O. А вот контроллеры памяти могут оказаться и на базовых тайлах, и в составе I/O-чиплетов. 
Источник изображений: Intel В отличие от Granite Rapids-SP, не стоит ожидать широкого распространения Diamond Rapids в корпоративных системах виртуализации или СХД. Как сообщила Intel, Diamond Rapids «оптимизирован для высоконагруженных IaaS-систем с высокой производительностью на поток», что ставит его в один ряд с процессорами 6900P, больше ориентированными на HPC-нагрузки. Intel уже говорила, что новинки получат 16-канальный контроллер памяти с поддержкой MRDIMM, что важно для таких задач. Чипы также будут поддерживать PCIe 6.0, предлагая высокую скорость и масштабируемость для сценариев с интенсивным использованием I/O.  Далее Intel представит Coral Rapids, вернув P-ядрам поддержку SMT. Ожидается, что линейка будет запущена в середине 2028 года с 8-канальными платформами, но, судя по недавним заявлениям генерального директора Лип-Бу Тана (Lip-Bu Tan), её выпуск, вероятно, будет ускорен из-за возросшего спроса на процессоры для рабочих нагрузок агентного ИИ.
01.06.2026 [12:20], Сергей Карасёв
Hyperion Research: объём мирового рынка НРС в 2025 году превысил $70 млрд, но темп роста замедлилсяПо оценкам компании Hyperion Research, глобальные расходы в области ИИ и НРС в 2025 году превысили $70 млрд, что примерно на $10 млрд больше по сравнению с предыдущим годом. Однако темпы роста замедлились до 16,9 % против 23,5 % в 2024-м, когда этот показатель оказался самым высоким за последние три десятилетия. Аналитики учитывают затраты на серверы, хранилища данных, программное обеспечение, услуги и облачные ресурсы, связанные с ИИ и НРС. В частности, в 2025 году на локальные серверы были потрачены $29,4 млрд, что на 16,7 % больше, чем годом ранее, когда продажи такого оборудования оценивались в $25,2 млрд при росте 23,4 % в годовом исчислении. В сегменте HPC-решений для локального развёртывания на долю HPE пришлось около 22,1 % продаж — $6,5 млрд против $7,2 млрд в 2024 году. У Dell отгрузки в денежном выражении за год поднялись с $3,9 млрд до $5,3 млрд, в результате чего доля составила 18,2 %. Lenovo и Inspur получили $1,8 млрд и $1,2 млрд соответственно. Далее в рейтинге ведущих игроков указанного сегмента находятся Sugon, Penguin, Atos, IBM, Fujitsu и NEC. 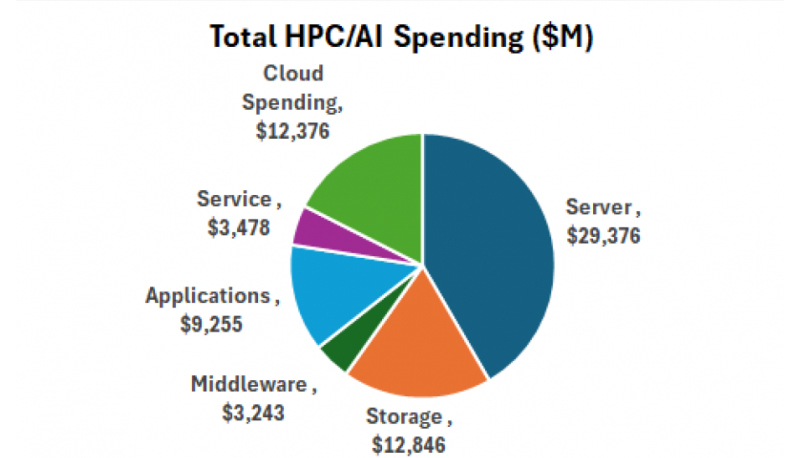
Источник изображения: Hyperion Research Системы хранения данных в 2025 году принесли поставщикам около $12,8 млрд — плюс 27,5 % по отношению к предыдущему году. Расходы в облачном сегменте оцениваются в $12,4 млрд, что на 29,7 % больше, чем в 2024-м. Приложения обеспечили $9,3 млрд, связующее ПО — $3,2 млрд, услуги — $3,5 млрд. Отмечается, что в 2021 году во всём мире были отгружены примерно 2,2 млн НРС-узлов. В 2024-м и 2025 годах показатель снизился до 500 тыс. узлов. При этом выручка в пересчёте на один узел резко возросла: в среднем с $10 тыс. до более чем $50 тыс. По прогнозам, общие затраты на локальные серверы составят около $32 млрд в 2026 году и достигнут примерно $54 млрд к 2030-му.
28.05.2026 [10:13], Руслан Авдеев
В Великобритании выставили на аукцион три суперкомпьютера Cray из 1990-хКомпания RWB Auctions Limited выставила на аукцион в Великобритании три суперкомпьютера Cray. По её данным, они предоставлены главой Amari Дэном Голдсмитом (Dan Goldsmith), сообщает Datacenter Dynamics. По словам Голдсмита, когда-то ему буквально в шутку предложили оборудование, поскольку никто не рассчитывал, что он действительно его купит. Но он купил и использовал дома около трёх лет. Включать машину можно было только на полчаса за раз, поскольку в комнате становилось чересчур жарко. По словам Голдсмита, теперь пришло время передать старые суперкомпьютеры новому поколению IT-энтузиастов, чтобы сохранить их для будущих поколений. На аукционе представлен первый суперкомпьютер Cray T3D. Система Typhoon в своё время эксплуатировалась в Эдинбургском центре параллельных вычислений (Edinburgh Parallel Computing Centre, EPCC) при Эдинбургском университете. В июне 1996 года она стала самым производительным суперкомпьютером Европы в рейтинге TOP500. Система, окрашенная в «томатно-красный» цвет, представляет собой однокорпусную модель Cray T3D-MC512 с 512 процессорами DEC Alpha 21064 с частотой 150 МГц и СЖО, использующей жидкость 3M Fluorinert. Система весом 771 кг изначально использовалась Cray для внутренних разработок, поэтому обладает уникальной конфигурацией. На пике производительность Typhoon достигала 76,8 Гфлопс, а сам он занимал 22-е место в мире по этому показателю. Последний раз этот суперкомпьютер попал в рейтинг TOP500 в июне 1999 года. По оценкам, в своё время система стоила порядка $15 млн, сегодня начальная ставка на неё составляет £60 тыс. ($80,672). 
Источник изображения: The Saleroom Также на аукцион выставлена модель Cray Y-MP4E. Машину из двух шасси с тремя векторными процессорами Cray применяли как фронтенд-систему для суперкомпьютера Cray T3D в Эдинбурге. Она окрашена в характерный красный цвет. По данным RWB, при стартовой ставке £2,4 тыс. ($3227) система представляет собой привлекательный вариант для коллекционеров и структур, интересующихся историей научных и технических вычислений. Наконец, выставлен и суперкомпьютер Cray Triton T-932 — полнофункциональная 32-процессорная конфигурация, одна из трёх сохранившихся систем, которых в своё время было около двадцати. Система весом 4 т первоначально работала в штаб-квартире GCHQ. Данный вариант Голдсмиту пришлось восстанавливать в течение двух лет при участии Cray. На момент запуска система стоила около $39 млн, сейчас начальная ставка составляет £40 тыс. ($53 785). Суперкомпьютеры редко выставляют на аукцион, но изредка это случается. Так, в 2024 году распродавалась коллекция одного из основателей Microsoft, ныне покойного Пола Аллена (Paul Allen). В частности, система Cray-1 1976-1978 гг. выпуска была продана за $1 млн, Cray-2 1985 года продан за $176 400. Суперкомпьютер CDC 6500 в своё время продали за $252 тыс., а в США два года назад за $480 тыс. была продана машина Cheyenne и т.п.
27.05.2026 [15:41], Сергей Карасёв
Bull поставила Финляндии суперкомпьютер Roihu с производительностью до 49 ПфлопсКомпания Bull, специализирующаяся на высокопроизводительных вычислениях, поставила Финляндии новейший национальный суперкомпьютер Roihu для ресурсоёмких задач, в том числе связанных с ИИ. Система позволит утроить доступные в стране вычислительные мощности. Соглашение о создании Roihu было заключено между компанией Eviden (дочерняя структура Atos) и Финским научным IT-центром CSC в конце 2024 года. Комплекс Roihu смонтирован в дата-центре в Каяани рядом с действующим суперкомпьютером LUMI. Новая НРС-система построена на гибридной платформе Eviden BullSequana XH3000. В общей сложности задействованы 486 узлов на основе CPU и 132 узла на базе GPU. Каждый CPU-узел несёт на борту два 192-ядерных процессора AMD EPYC 9965 поколения Turin, что в сумме даёт 186 624 ядра. При этом 414 узлов располагают 768 Гбайт памяти, а оставшиеся 72 — 1536 Гбайт. В свою очередь, каждый GPU-узел оснащён четырьмя суперчипами NVIDIA GH200. Общее количество GPU в составе суперкомпьютера составляет 528. Все эти CPU и GPU узлы комплектуются локальным SSD вместимостью 960 Гбайт. Кроме того, в состав Roihu входят четыре узла визуализации с двумя процессорами AMD EPYC Turin 9335 (32 ядра) и двумя ускорителями NVIDIA L40 в каждом, а также четыре высокопроизводительных узла с двумя чипами AMD EPYC Turin 9555 (64 ядра) и 6 Тбайт памяти. В комплектацию данных узлов включены два SSD ёмкостью 7,68 Тбайт каждый. Сетевая инфраструктура базируется на 200G-интерконнекте Infiniband NDR. 
Источник изображения: HPC Wire Для Roihu предусмотрено использование двух независимых хранилищ DDN EXAScaler Lustre на основе SSD: это раздел Scratch вместимостью 6 Пбайт и дополнительная секция объёмом 0,5 Пбайт для проектных приложений и личных каталогов пользователей. Пиковая скорость передачи данных у Scratch достигает 560 Гбайт/с при чтение и 280 Гбайт/с при записи. У второй секции эти значения составляют до 120 и 100 Гбайт/с соответственно. Общая FP64-производительность CPU-узлов оценивается в 10,5 Пфлопс, GPU — в 23,4 Пфлопс: в сумме это даёт 33,9 Пфлопс. Пиковое быстродействие достигает 49 Пфлопс. Суперкомпьютер Roihu станет доступен пользователям в июне нынешнего года. При этом действующие в Финляндии НРС-системы Puhti и Mahti будут полностью выведены из эксплуатации в августе 2026-го.
20.05.2026 [19:26], Руслан Авдеев
Суперкомпьютер по подписке: Bull предоставила Airbus инфраструктуру HPC-as-a-serviceЕвропейский аэрокосмический гигант Airbus получил доступ по подписке к суперкомпьютерной инфраструктуре, размещённой на площадках в Тулузе (в декабре 2025 года) и Гамбурге (в апреле 2026 года). Официальный запуск системы, производительность которой втрое выше, чем у предыдущего суперкомпьютера компании, состоялся 19 мая, сообщает The Register. Саму Bull французское государство приобрело у Atos несколько месяцев назад. Новая суперкомпьютерная система представляет собой модульную конструкцию: оборудование собиралось в контейнерах перед транспортировкой на площадки Airbus. Система основана на стоечной инфраструктуре BullSequana XH3000 и включает вычислительные модули на основе AMD EPYC Genoa и Turin. Кроме того, используются ИИ-ускорители NVIDIA, хранилища IBM Spectrum Scale и 400G-интерконнект NVIDIA InfiniBand NDR. выделяемое дата-центрами тепло будет применяться для теплоснабжения соседних зданий на подконтрольной Airbus территории. По имеющимся данным, Airbus потратит около €100 млн ($116 млн) в течение пяти лет за комплексное обслуживание. Bull выиграла контракт у HPE, которая ранее обслуживала интересы Airbus. Сообщается, что Airbus была клиентом HPE около 24 лет, после чего была инициирована закупка для замены существующей системы для повышения производительности втрое. Впрочем, Bull пока не сообщает, какая часть проекта уже реализована на сегодняшний день. 
Источник изображения: Airbus Хотя физически оборудование разнесено по двум площадкам, сообщается, что они функционируют как единый суперкомпьютер по модели HPC-as-a-Service (HPCaaS). Правда, пока рабочие нагрузки не распределяются между ними, а выполняются лишь на одной. При этом площадка выбирается в зависимости от имеющихся потребностей и ресурсов. Airbus давно нуждается в более мощном HPC-кластере, поскольку намерена использовать его для создания цифровых двойников для моделирования конструкций и полётов вертолётов и других летательных аппаратов. Вероятно, будет использоваться ПО CODA для вычислительной гидродинамики (CFD). Оно разработано Airbus совместно с Немецким аэрокосмическим центром (DLR) и Французской аэрокосмической лабораторией (ONERA). По некоторым данным, Bull также взаимодействует с Airbus для использования квантовых и ИИ-алгоритмов для удовлетворения вычислительных потребностей, но информация «строго конфиденциальна». Заявлено, что ввод в эксплуатацию распределённой суперкомпьютерной инфраструктуры состоялся всего через 14 мес. после подписания контракта. В декабре 2025 года сообщалось, что Airbus перенесёт критически важные нагрузки и приложения в суверенное европейское облако, но тогда речь шла о решениях ERP, CRM, PLM, MES и пр.
19.05.2026 [12:49], Руслан Авдеев
AMD и NVIDIA свернули не туда: следующий крупный американский суперкомпьютер может получить HPC-чипы NextSiliconБольшая часть самых мощнейших суперкомпьютеров мира в рейтинге TOP500 полагаются на ускорители на основе GPU, однако Национальные лаборатории США начали искать новые архитектуры чипов, обеспечивающие высокую производительность в FP64-расчётах, востребованных для симуляций Министерства энергетики США (DoE). Последнее занимается не только вопросами энергетиками, но и управляет одними из мощнейших суперкомпьютеров мира, в т.ч. для моделирования физики ядерного оружия, виртуальных экспериментов, касающихся биологического оружия, а также решения задач обеспечения общественного здоровья и безопасности, сообщает The Register. С запуска суперкомпьютера Titan в 2012 году всё больше систем стали использовать ускорители NVIDIA, а впоследствии и чипы AMD. Однако новый суперкомпьютер Spectra Сандийских национальных лабораторий (SNL), созданный Penguin Solutions и NextSilicon, использует другие решения. В сравнении с экзафлопсными системами уровня Frontier или El Capitan он занимает относительно мало места и состоит всего из 64 узлов. Spectra используют в качестве тестовой площадки для чипов Maverick-2, успешно прошедших все приёмочные испытания. Это открывает возможность их использования в боле крупных системах. 
Источник изображения: SNL Maverick-2 используют перенастраиваемую потоковую (dataflow) архитектуру. Фактически внутри чипа находится сеть связанных вычислительных блоков, работающих не по жёстко заданной схеме, а как узлы графа. В ходе выполнения задачи каждый блок можно настроить под отдельную задачу — сложение, умножение и т.п., благодаря чему происходит адаптация под разные типы вычислений с более эффективной обработкой потоков данных. Главная особенность — возможность одновременных вычислений и передачи данных. В NextSilicon утверждают, что это значительно повышает производительность и энергоэффективность в реальных задачах. Groq, Cerebras и SambaNova и ранее предлагали чипы на «потоковых» архитектурах, но все они были ориентированы на обучение и инференс ИИ, тогда как NextSilicon ориентируется именно на HPC. Подобные архитектуры очень сложны для программирования, поэтому разработчики обычно предлагают готовые сервисы, а не просто продают серверы на их основе. NextSilicon пытается решить подобную проблему, предложив собственный компилятор, позволяющий использовать имеющиеся программы на C, Python, Fortran и CUDA без серьёзной доработки. В Сандийских лабораториях уже проверили технологию на важных HPC-нагрузках, включая HPCG, LAMMPS и Sparta, подтвердив пригодность системы для научных вычислений. 
Источник изображения: NextSilicon Ставка разработчика на HPC контрастирует с вектором развития ИИ-ускорителей NVIDIA. В Rubin компания делает ставку на ИИ-вычисления, снижая «чистую» производительность FP64, полагаясь на эмуляцию посредством схемы Озаки. Если в некоторых HPC-задачах это работает, то в других эффективность подобных обходных решений весьма низкая. AMD помимо ориентированных на ИИ Instinct MI455X готовит и MI430X, где сохранены аппаратные HPC-блоки. Именно на подобные нагрузки ориентируется NextSilicon со своими наработками. Полных системных бенчмарков Maverick-2 и суперкомпьютера пока нет, но компания утверждает, что один такой ускоритель способен обеспечить порядка 600 Гфлопс в тесте HPCG (FP64). По данным стартапа, это сопоставимо по производительности с ведущими GPU, причём энергопотребление у новинки вдвое ниже. Для США главной проблемой может оказаться давление акционеров компаний, поставляющих чипы. Если ИИ сделал NVIDIA финансовым и технологическим гигантом, то рынок решений для HPC остаётся важным, но всё ещё нишевым направлением. Хотя стартапам вроде NextSilicon ещё предстоит доказать право своих продуктов на место под солнцем, Китай уже давно продемонстрировал, что GPU вовсе не обязательны для успешной конкуренции с лучшими суперкомпьютерами Запада. OceanLight и Tianhe-3 полагаются на кастомные процессоры и ускорители на базе DSP вроде Matrix 2000. Последние, по слухам, были созданы в ответ на запрет поставок Intel Xeon Phi в КНР. Также недавно появились данные о новом Arm-суперкомпьютере LineShine. |
|

