Материалы по тегу: hpc
|
08.05.2026 [09:14], Сергей Карасёв
NVIDIA и Iren объединили усилия для создания ИИ-инфраструктуры мощностью до 5 ГВтКомпании NVIDIA и Iren (ранее Iris Energy) объявили о стратегическом партнёрстве с целью ускорения развёртывания инфраструктуры ИИ следующего поколения. Речь идёт о создании объектов суммарной мощностью до 5 ГВт, рассчитанных на наиболее ресурсоёмкие нагрузки. В рамках проекта планируется использовать платформу NVIDIA DSX. Это эталонная архитектура ИИ-фабрик, которая охватывает все уровни инфраструктуры — от отдельных ускорителей до сети. Благодаря DSX операторы крупных дата-центров могут максимизировать энергоэффективность, отказоустойчивость, масштабируемость и производительность ИИ-кластеров. При этом ускоряется их построение и снижаются эксплуатационные расходы. Цель нового партнёрства заключается в том, чтобы сократить время развёртывания крупномасштабных ИИ-фабрик путём объединения архитектуры DSX с опытом Iren в области энергетики, землепользования, ЦОД и инфраструктурных решений. Флагманским объектом будущей сети станет кампусе Iren Sweetwater мощностью 2 ГВт в Техасе (США). В перспективе реализуемый проект позволит предоставлять вычислительные мощности для задач ИИ корпоративным клиентам по всему миру. 
Источник изображения: Iren Генеральный директор NVIDIA Дженсен Хуанг (Jensen Huang) отмечает, что фабрики ИИ становятся одним из основополагающих компонентов мировой экономики. Однако развёртывание таких систем в масштабе требует глубокой интеграции по всему стеку — от вычислительных ресурсов и ПО до сетей и электропитания. Iren, по словам Хуанга, обладает необходимым опытом для выполнения этих комплексных работ. По условиям подписанного соглашения, Iren предоставит NVIDIA право на приобретение до 30 млн своих обыкновенных акций сроком на пять лет по цене $70/шт. Это даёт NVIDIA возможность инвестировать до $2,1 млрд при соблюдении определённых условий, включая требования регулирующих органов.
07.05.2026 [16:26], Владимир Мироненко
200 Тфлопс в FP64: AMD поделилась первыми подробностями об Instinct MI430XAMD поделилась информацией о производительности Instinct MI430X. Это не ИИ-ускоритель — чип ориентирован на задачи в сегменте высокопроизводительных вычислений (HPC): вычисления с двойной точностью (FP64) остаются чрезвычайно важными в науке, моделировании и многих других приложениях, пишет ресурс ComputerBase. AMD официально подтвердила выпуск чипа прошлой осенью, когда уже получила первые крупные заказы. Теперь компания демонстрирует первые показатели решения с 432 Гбайт HBM4. Обладая производительностью более 200 TFLOPS в нативном режиме FP64, он будет «более чем в шесть раз быстрее» ускорителя NVIDIA Rubin. Однако следует отметить, что сравнение несколько некорректно. Во-первых, Rubin — это чистый ИИ-ускоритель, ориентированный на FP4 и аналогичные форматы, а не на FP64. Во-вторых, AMD прямо не уточняет, идёт ли речь о векторных и/или матричных вычислениях. Хотя, вероятно, речь всё-таки о векторных расчётах, поскольку в режиме эмуляции со схемой Озаки Rubin, как обещает NVIDIA, будет выдавать те же 200 Тфлопс в FP64. 
Источник изображений: AMD При этом реального конкурента, кроме Instinct M430X, у Rubin в FP64 нет. С другой стороны, Rubin, в свою очередь, по всей видимости, превосходит MI430X в приложениях FP4 — AMD пока не раскрыла его возможности в таких вычислениях. Кроме того, компания сама говорила о возможности поддержки схемы Озаки (Ozaki) для чипов Instinct. Фактически AMD в своих же чипах «отклонилась от курса», решив наращивать ИИ-производительность. В Instinct MI355X FP64-производительность и векторных, и матричных вычислений была на уровне 78,6 Тфлопс, тогда как вышедший ранее MI325X выдавал 81,6 Тфлопс, а ещё более «древний» MI300X — 81,7 Тфлопс.  О решении AMD нарастить нативную FP64-производительность ускорителя Instinct MI430X стало известно этой весной. До этого компания усомнилась в эффективности эмуляции научных расчётов на тензорных ядрах NVIDIA. NVIDIA же давно сделала ставку исключительно на ИИ, отказавшись от развития в новейших ускорителях FP64-блоков, но учёные указывают на то, что отказ от поддержки этого направления грозит лидерству США в HPC и дальнейшим инновациям. В Министерстве энергетики США (DoE) также отметили, что FP64-вычисления по-прежнему «очень важны» для «Миссии Генезис» (Genesis Mission) и для реализации её цели — ускорения научных открытий с помощью ИИ.  AMD добилась больших успехов в сегменте HPC, поставляя оборудование для самых быстрых в мире суперкомпьютеров. Именно этот рынок является целевым для Instinct MI430X, о чем свидетельствуют первые заказы, включая машину Discovery Национальной лаборатории Ок-Ридж (ORNL) в США и Alice Recoque во Франции. Как сообщается, производительность Alice Recoque составит более 1 Эфлопс в FP64, что сделает его одной из самых быстрых HPC-систем в Европе.
07.05.2026 [15:03], Сергей Карасёв
TotalEnergies создаст суперкомпьютер Pangea 5 за €100 млнФранцузская нефтегазовая компания TotalEnergies объявила о заключении соглашения с Dell Technologies и NVIDIA на создание нового суперкомпьютера под названием Pangea 5. Ожидается, что его ввод в эксплуатацию позволит увеличить вычислительные мощности TotalEnergies в шесть раз по сравнению с нынешними показателями (точные данные не приводятся). Технические подробности о будущей НРС-системе не раскрываются. Отмечается лишь, что в составе комплекса будут применяться «специализированные процессоры, рассчитанные на массово-параллельные вычисления». Речь идёт об ускорителях NVIDIA на основе GPU, а также о решениях InfiniBand и пр. Машина получит гибридное хранилище DDN ExaScaler. Инвестиции в проект Pangea 5 оцениваются в €100 млн. Суперкомпьютер расположится в Научно-техническом центре Жана Феже в По (Jean Féger Scientific and Technical Center at Pau — CSTJF) на юго-западе Франции. Там же смонтирована нынешняя машина Pangea 4, запущенная в июле 2024 года. По сравнению с этим комплексом при сопоставимой производительности общее энергопотребление Pangea 5 будет ниже примерно на 40 %, а потребление энергии системой охлаждения — меньше в пять раз. Тепло, генерируемое новым суперкомпьютером, планируется использовать для отопления зданий CSTJF, в которых работают более 2,5 тыс. человек. 
Источник изображения: TotalEnergies Компания TotalEnergies будет использовать Pangea 5 для ресурсоёмких вычислений с применением передовых методов сейсморазведки для повышения точности визуализации недр и ускорения геологоразведочных работ. Кроме того, суперкомпьютер поможет в реализации проектов, связанных с ИИ. Запуск вычислительного комплекса намечен на следующий год.
29.04.2026 [15:34], Сергей Карасёв
Китай анонсировал 2,5-Эфлопс Arm-суперкомпьютер LineShine на домашних процессорахКитайский национальный суперкомпьютерный центр в Шэньчжэне (NSCCSZ) анонсировал проект вычислительного комплекса LineShine (LingSheng), производительность которого после полноценного ввода в эксплуатацию окажется на уровне 2 Эфлопс. Особенностью системы является то, что её конфигурация предполагает применение исключительно CPU-серверов — без ускорителей на базе GPU. Как отмечает ресурс HPC Wire, LineShine будет создаваться в несколько этапов. Одна из секций нового суперкомпьютера получит серверы Huawei Kunpeng с десятками тысяч вычислительных ядер. Предусмотрено использование 428 узлов хранения с суммарной вместимостью 650 Пбайт. Заявленная пропускная способность — 10 Тбайт/с. Вторая секция LineShine предполагает применение 20480 вычислительных узлов, каждый из которых будет оснащён двумя процессорами LX2 на архитектуре Armv9. Конструкция чипов LX2 включает два вычислительных кристалла со 152 ядрами (в сумме 304 ядра) и восемь стеков памяти HBM (32 Гбайт, 4 Тбайт/с). Каждый кристалл использует 128 Гбайт внешней памяти DDR. За обмен данными между блоками DDR и HBM отвечает специальный механизм SDMA. Каждый кристалл поделён на четыре NUMA-домена (38 ядер и 4 Гбайт HBM). Узлы соединены между собой высокоскоростным интерконнектом LingQi, обеспечивающим пропускную способность до 1,6 Тбит/с на узел. Говорится о поддержке режимов FP64/FP32/FP16/INT8. Заявленная производительность LX2 достигает 60,3 Тфлопс на операциях FP64 и 120,6 Тфлопс на операциях FP32. Таким образом, пиковая теоретическая FP64-производительность составляет 2,47 Эфлопс. 
Источник изображения: South China Morning Post Для сравнения, самый быстрый на сегодняшний день суперкомпьютер в мире по версии TOP500 — американский комплекс El Capitan — обладает быстродействием 1,809 Эфлопс с пиковым значением 2,821 Эфлопс, но в нём применяются как CPU, так и ускорители (AMD Instinct MI300A). Таким образом, LineShine станет самым мощным НРС-комплексом, построенным исключительно на базе CPU. Другой особенностью машины станет то, что в её составе будут применяться только китайские компоненты, включая процессоры, накопители и сетевое оборудование. При этом официально КНР не участвует в TOP500 уже пять лет, да и в целом не любит рассказывать о своих самых мощных суперкомпьютерах. Нужно отметить, что в Китае действует другой суперкомпьютер экзафлопсного класса — система China New-generation Intelligent Supercomputer (CNIS). Этот комплекс имеет гетерогенную конфигурацию с 5632 вычислительными узлами. Каждый из них наделён двумя 64-бит серверными процессорами на базе CISC с 64 ядрами (2,4 ГГц) и восемью ускорителями GPGPU с архитектурой SIMT с 64 Гбайт HBM (1,8 Тбайт/с). Задействованы 8-канальная подсистема памяти DDR5-6400. Каждый GPGPU обеспечивает пиковую производительность 32,7 Тфлопс в режиме FP64, 65,5 Тфлопс на операциях FP32 и 470 Тфлопс в режиме FP16, что в сумме даёт пиковую теоретическую FP64-произвоидительность на уровне 1,47 Эфлопс.
26.04.2026 [15:38], Руслан Авдеев
Oklo, NVIDIA и LANL задействуют ИИ для разработки плутониевого топлива и создания передовой атомной инфраструктурыЗанимающаяся разработкой малых модульных реакторов (SMR) американская компания Oklo совместно с NVIDIA и Лос-Аламосской национальной лабораторией США (LANL) займутся научно-прикладными проектами. Они выделят ресурсы на развитие атомной инфраструктуры, исследования с помощью ИИ и разработок, связанных с созданием ядерного топлива — в лаборатории, расположенной в штате Нью-Мексико, сообщает Datacenter Dynamics. В соглашении оговорено сотрудничество в области ИИ, цифровых двойников, моделирования и симуляция для развития критической инфраструктуры и ускоренного внедрения атомной энергетики. По словам Oklo, соглашение касается как внедрения реакторов, так и HPC, а также использования экспертных знаний мирового уровня в области науки о топливе и материаловедении. Предполагается, что это будет способствовать созданию плутониевого топлива для реактора Pluto, выбранного Министерством энергетики США (DoE) в рамках плана Reactor Pilot Program. Также инициатива направлена на обеспечение надёжного энергоснабжения в рамках миссии Genesis, которую прозвали новым Манхэттенским проектом. В рамках партнёрства компании обучат ИИ-модели на данных в области физики и химии — с их помощью будет поддерживаться проверка качества топлива и научно-исследовательские работы, касающиеся энергоносителей на основе плутония. Также ИИ будет способствовать исследованиям в области выработки электроэнергии, обеспечения надёжности энергосистем, резервирования и стабилизации энергоснабжения для поддержки развития ИИ ЦОД в национальной лаборатории. 
Источник изображения: Oklo Находящаяся в Нью-Мексико Лос-Аламосская национальная лаборатория США принимала участие в исходном Манхэттенском проекте. Сегодня лаборатория — один из ключевых научных центров Министерства энергетики США, занимающихся ядерными исследованиями. Американская Oklo разрабатывает 75-МВт SMR Aurora Powerhouse. Реактор планируют ввести в эксплуатацию в 2027 году. Oklo входит в число 11 ключевых атомных компаний, отобранных для участия в пилотной программе DoE, посвящённой новым ядерным реакторам и разработке передового ядерного топлива. Oklo — один из наиболее активных разработчиков SMR по количеству заключённых сделок, в основном для питания ЦОД. Совокупный объём заказов уже превысил 14 ГВт, хотя часть сделок не имеет обязательной юридической силы. Среди самых значимых сделок: поставка ЦОД Switch до 12 ГВт до 2044 года; 1,2 ГВт для Meta✴ до 2030 года; 500 МВт для Equinix и до 100 МВт для Prometheus Hyperscale (Wyoming Hyperscale). В последние годы NVIDIA активно взаимодействовала с компаниями, реализующими атомные энергетические проекты, а также инвестировала в них средства. В частности, речь идёт о проектах компаний TerraPower и Commonwealth Fusion Systems (CFS), занимающихся в атомных разработках, в т.ч. в сфере термоядерного синтеза. В январе NVIDIA заключила партнёрское соглашение с CFS и Siemens для «строительства» цифровой копии термоядерного реактора CFS. Это должно помочь упростить начало его коммерческой эксплуатации.
21.04.2026 [20:48], Владимир Мироненко
В ВТБ призвали к партнёрству с Китаем для развития суверенного ИИРазвивать суверенные технологий ИИ в России, включая использование больших языковых моделей (LLM) и вычислительных мощностей, необходимо в партнёрстве с дружественными странами, прежде всего, с Китаем, заявил заместитель руководителя технологического блока ВТБ. Он подчеркнул, что при этом важно учитывать необходимость защиты данных россиян, которые используются при обучении ИИ. Топ-менеджер отметил, что открытые LLM, разработанные китайскими компаниями, работают «чуть лучше», чем российские модели, но их использование несёт определенные риски для технологического суверенитета, так как они созданы за пределами России. Использование российских моделей, в частности, от «Яндекса» и Сбера, снимает часть этих рисков. Вместе с тем топ-менеджер ВТБ считает, необходимо использовать лучшие технологии, чтобы не оказаться в числе отстающих: «Для того, чтобы наши модели были не хуже, мы стараемся обучать их на обезличенных данных. И считаем, что партнёрство с Китаем — это правильный возможный вариант, они действительно сейчас по многим направлениям лидируют». Это также относится к развитию суперкомпьютеров, необходимых для ИИ: «Если взять вычислительные мощности, которые есть за рубежом и которые есть у нас, понятно, что те суперкомпьютеры, которые сейчас работают, в первую очередь в США, многократно превышают те мощности, которые есть в России. И это тоже проблема». 
Источник изображения: Hanson Lu/unsplash.com Он добавил, что в рамках кооперации уже запущены большие совместные лаборатории с китайскими коллегами. Также начинают осуществлять сборку серверов в России с китайскими GPU: «Это — будущее, так как без кооперации не обойтись. Мы большая и сильная страна, но есть другие большие и сильные страны, вместе с которыми мы достигнем больших результатов». Также было отмечено, что применение ИИ-технологий в финансовом секторе усложняется в связи с необходимостью выполнения требований по соблюдению банковской тайны и защите персональных данных. Поэтому, для того чтобы использовать самые эффективные и популярные большие языковые модели, но при этом не допустить утечку данных, в ВТБ используют их on-premise, ограничивая их применение защищённым банковским контуром. «На сегодняшний день к такому режиму работы готовы наши российские большие языковые модели, в том числе YandexGPT и GigaChat», — сообщил топ-менеджер.
20.04.2026 [19:29], Сергей Карасёв
AMD поможет в развитии экосистемы ИИ во ФранцииКомпания AMD и власти Франции объявили о расширении сотрудничества в области ИИ. Соответствующий документ подписан в Париже в Министерстве экономики, финансов, промышленности, энергетики и цифрового суверенитета. Речь идёт о реализации Национальной стратегии Франции в области ИИ. Многолетнее сотрудничество с AMD направлено на укрепление местной экосистемы ИИ посредством развития соответствующей вычислительной инфраструктуры, организации исследовательских и образовательных программ. В частности, AMD планирует предоставлять учёным, разработчикам и стартапам оборудование, необходимое ПО и экспертную поддержку в рамках своих инициатив AMD University Program, AMD AI Developer Program и AMD AI Academy. Ещё одним направлением работ станет углубление взаимодействия между AMD, французским национальным агентством высокопроизводительных вычислений (GENCI), французско-нидерландским Консорциумом Жюля Верна и Французской комиссией по альтернативным источникам энергии и атомной энергии (CEA). Стороны реализуют проект суперкомпьютера Alice Recoque — второй в Европе НРС-системы экзафлопсного класса после JUPITER. Ранее сообщалось, что в основу Alice Recoque войдут серверы с 256-ядерными процессорами AMD EPYC Venice и ускорителями Instinct MI430X (432 Гбайт HBM4). Монтаж системы стоимостью более €550 млн начнётся в 2026 году. 
Источник изображения: AMD В рамках проекта Alice Recoque планируется создание Центра передового опыта (Center of Excellence), который обеспечит экспертные знания, обучение и поддержку для максимально эффективного использования ресурсов нового суперкомпьютера. Появление центра также будет способствовать развитию более широкой экосистемы ИИ-фабрик во Франции.
20.04.2026 [09:49], Сергей Карасёв
Заработало «единое окно» для доступа к европейским суперкомпьютерам EuroHPC Federation PlatformЕвропейское совместное предприятие по развитию высокопроизводительных вычислений (EuroHPC JU) объявило о запуске системы EuroHPC Federation Platform (EFP), призванной упростить доступ к суперкомпьютерам Европы. Платформа выступает в качестве единой точки доступа к вычислительным ресурсам. EuroHPC JU активно развивает инфраструктуру НРС и ИИ: она объединяет суперкомпьютеры мирового уровня, включая первый в Европе комплекс экзафлопсного уровня — JUPITER. Каждая из этих машин имеет собственные процедуры, сервисы и технические инструменты для аутентификации и авторизации пользователей, распределения ресурсов, планирования задач и предоставления сервисов. С одной стороны, это отражает разнообразие доступных приложений и функций, но, с другой стороны, создаёт сложности для клиентов при работе с различными НРС-системами. 
Источник изображения: EuroHPC JU EFP решает указанную проблему: платформа предоставляет единый доступ к ряду действующих суперкомпьютеров EuroHPC JU с применением унифицированного метода аутентификации, авторизации и идентификации (AAI). Иными словами, EFP выступает в качестве «единого окна» для исследователей, корпораций, малых и средних предприятий, а также государственных органов, которым требуются вычислительные мощности для реализации тех или иных проектов. Платформа устраняет фрагментацию благодаря наличию федеративного каталога ПО и упрощает межсистемные процессы, такие как выделение ресурсов и передача данных. В результате, улучшается доступность европейских суперкомпьютеров и повышается удобство их эксплуатации. «Запуск платформы знаменует собой начало пути к более взаимосвязанной и интегрированной европейской экосистеме суперкомпьютерных вычислений, расширяя возможности научного, индустриального и академического сообществ и укрепляя инновационный потенциал Европы», — говорит исполнительный директор EuroHPC JU. В перспективе в состав платформы EFP будут интегрированы европейские ИИ-фабрики, квантовые компьютеры и другие ресурсы, включая озёра данных. В целом, система EFP разработана как безопасное, масштабируемое и гибкое решение.
15.04.2026 [13:56], Сергей Карасёв
Во Франции запущен квантовый компьютер Lucy с 12-кубитным фотонным процессоромЕвропейское совместное предприятие по развитию высокопроизводительных вычислений (EuroHPC JU) сообщило о запуске квантового компьютера Lucy, расположившегося во Франции недалеко от Парижа. Данное событие, как отмечается, стало очередным шагом в рамках реализации комплексной программы Европы по созданию суверенной суперкомпьютерной инфраструктуры мирового класса. Церемония открытия Lucy состоялась в TGCC (Très Grand Center de Calcul) — одном из крупнейших суперкомпьютерных центров Франции, который управляется Комиссариатом по атомной энергии и альтернативным источникам энергии (CEA). Проект реализован при поддержке Французского национального агентства по высокопроизводительным вычислениям (GENCI). Lucy — это современный квантовый компьютер MOSAIQ-12, разработанный специалистами компании Quandela. Система оснащена фотонным процессором с 12 физическими кубитами. Важной особенностью комплекса является то, что он функционирует при комнатной температуре, не требуя сложного и дорогостоящего охлаждения. Устройство состоит из модульных волоконно-оптических компонентов, монтируемых в стойку: это упрощает интеграцию с существующей НРС- инфраструктурой. 
Источник изображения: EuroHPC JU Строительство Lucy обошлось в €8,5 млн, из которых половину предоставило предприятие EuroHPC JU, а другую половину — власти Франции. Устройство, смонтированное на площадке TGCC, будет объединено с французским суперкомпьютером Joliot-Curie, что позволит осуществлять гибридные квантово-классические вычисления. Использовать Lucy планируется в технологических и научных областях, таких как материаловедение, метеорология, энергетика и передовые инженерные разработки. На сегодняшний день EuroHPC JU приобрело шесть квантовых компьютеров, которые расположатся по всей Европе. Три из таких систем уже введены в эксплуатацию: это PIAST-Q в Познани (Польша), VLQ в Остраве (Чехия) и Euro-Q-Exa в Мюнхене (Германия).
08.04.2026 [09:22], Владимир Мироненко
Стране нужен FP64: AMD пообещала повысить HPC-производительность ускорителей Instinct MI430XПосле анализа ограничений эмуляции FP64-вычислений с использованием схемы Озаки разработчики AMD пришли к выводу, что в настоящее время нет замены «сырой» производительности FP64. Как сообщил научный сотрудник AMD Николас Малайя (Nicholas Malaya) ресурсу HPCwire, чтобы обеспечить точность традиционных задач моделирования и симуляции, компания намерена нарастить нативную FP64-производительность ускорителя Instinct MI430X. Ускоритель станет основой суперкомпьютера Discovery, который будет установлен в Национальной лаборатории Ок-Ридж (ORNL) в 2028 году. Как отметил Кацухиса Озаки (Katsuhisa Ozaki) и два других японских исследователя, схема Ozaki — это многообещающая новая техника эмуляции, призванная позволить учёным выполнять высокоточные умножения матриц на оборудовании с поддержкой INT8/FP8, к которому относятся современные ИИ-ускорители, путём многократных вычислений с более низкой точностью. Текущие реализации Ozaki-I и Ozaki-II имеют ограничения, которые исключают их использование в реальных условиях, сообщил Малайя. Он указал на две основные проблемы. Во-первых, ПО не соответствует стандарту IEEE и не даёт того же результата, что и запуск кода на реальном оборудовании с поддержкой FP64. «В некоторых случаях это нормально, — сказал он. — Но во многих распространённых матрицах, которые мы наблюдали, влияние на точность довольно существенно.». Во-вторых, схема Озаки нацелена на квадратные матрицы. Если таковые в расчётах не используется, то итоговая производительность оказывается ниже, чем у нативного FP64-исполнения, говорит Малайя. 
Источник изображения: AMD Кроме того, HPC-приложения традиционно опираются на векторные вычисления, а не на тензорные или матричные, которые характерны для ИИ-нагрузок. Фактически ситуация ещё хуже — менее 10 % реальных HPC-приложений внесли изменения в DGEMM-коды, которые позволяют воспользоваться преимуществами Ozaki. «Насколько мне известно, с Ozaki-I, Ozaki-II или любой другой существующий метод нельзя применить к векторным инструкциям, — говорит Малайя. — Это ключевой нюанс, который, как мне кажется, упускается». На DGEMM действительно уходит много вычислительных ресурсов, что позволяет использовать схему Ozaki, «но она не решает 90 % HPC-задач». AMD собирается поддерживать эмуляцию Ozaki на своих чипах, сообщил Малайя. «Нет причин этого не делать. Это ПО. <…> И у вас могут быть библиотеки, которые позволяют динамически переключаться между нативными расчётами и Ozaki и, вероятно, оценивать его», — сказал он, добавив, что программную эмуляцию можно иметь в виду в качестве резервного варианта для FP64-вычислений. Но в конечном итоге Ozaki не является работоспособной альтернативой «железу» с FP64, сказал Малайя, уточнив, что не он один так считает. 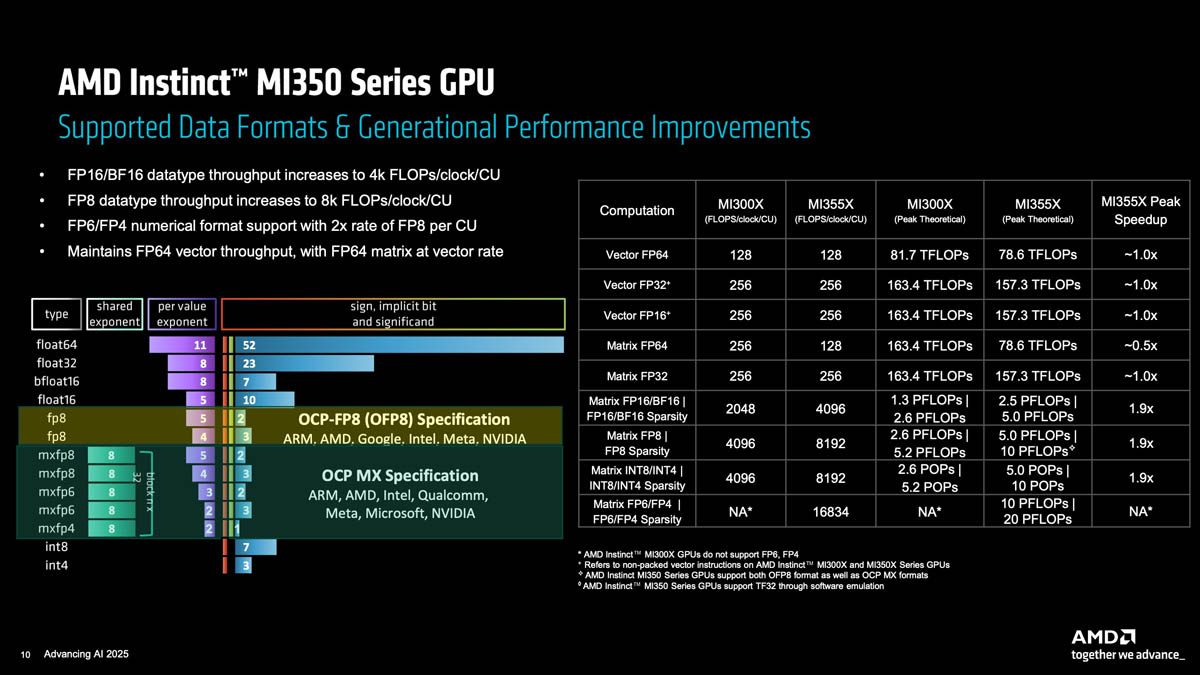
Источник изображения: AMD В настоящее время компания разрабатывает MI430X, специализированную версию ускорителя следующего поколения MI450, который будет обладать значительной FP64-производительностью. По словам Малайи, она будет значительно больше, чем у ускорителя MI355X, который обеспечивает 78,6 Тфлопс. По факту, это меньше, чем у предыдущей модели MI325X, которая обеспечивала 81,7 Тфлопс — в обоих случаях речь и про векторные, и про матричные FP64-вычисления. В любом случае, у всех этих чипов — от MI325 до MI430 — производительность больше, чем у чипов NVIDIA. И Hopper (34 Тфлопс), и Blackwell (40 Тфлопс) уже были медленнее в векторных FP64-вычислениях, но у Hopper хотя бы были нативные 67 Тфлопс в матричных расчётах, тогда как Blackwell в этом случае уже перешёл к схеме Озаки с «ненативными» 150 Тфлопс. Про Blackwell Ultra, где FP64-производительность упала до 1,3 Тфлопс, NVIDIA в данном контексте вообще не вспоминает, но обещает, что у Rubin будет 33 Тфлопс в векторных FP64-расчётах и 200 Тфлопс в матричных (тоже с Озаки). 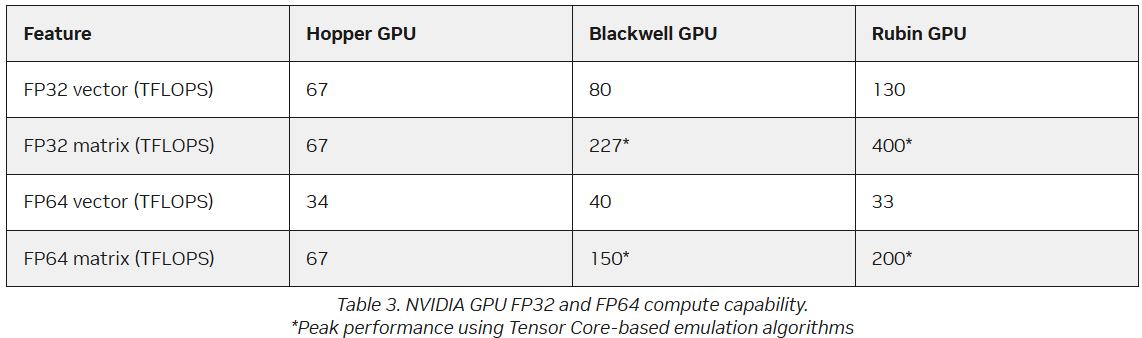
Источник изображения: NVIDIA NVIDIA обосновывает отказ от развития аппаратных FP64-блоков тем, что увеличение собственно вычислительной мощности FP64 на самом деле не ускорит научные приложения, поскольку на практике они упрутся в возможности регистров, кешей и HBM. Rubin обеспечит пропускную способность HBM до 22 Тбайт/с, что в 2,8 раза больше, чем у Blackwell. Instinct MI325X предлагает 6 Тбайт/с, MI355X — 8 Тбайт/с, а у MI430X будет уже 19,6 Тбайт/с, сообщил Малайя. По словам Малайи, лучше всего синхронно «вкладываться» и в HBM, и в количество операций с плавающей запятой. «На самом деле важен коэффициент байт/флопс. С нашей точки зрения, необходимо поддерживать гораздо более близкое соотношение к тому, что мы видим в современных продуктах, — сказал он. — Необходимо значительно приблизиться к этому соотношению с точки зрения увеличения производительности FP64, чтобы сохранить тот же уровень, как это называют, арифметической интенсивности». 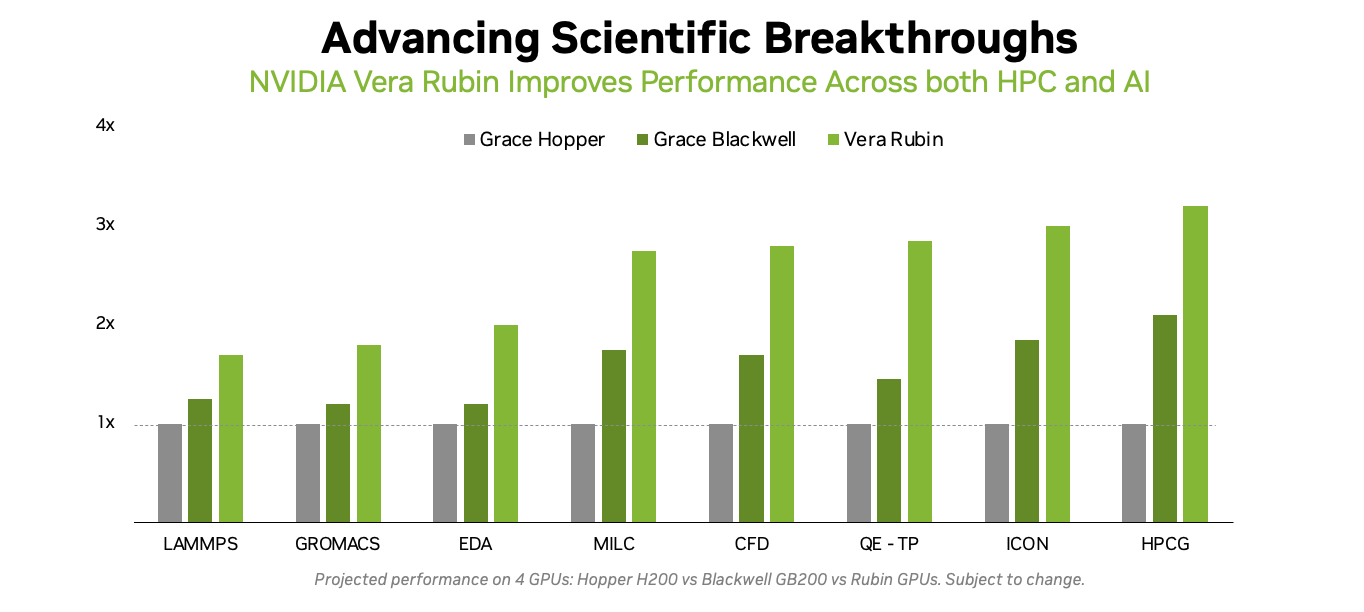
Источник изображения: NVIDIA Поскольку AMD обеспечит 2,5-кратное увеличение ПСП HBM от MI355 до MI430X, аналогичное 2,5-кратное увеличение производительности FP64 также будет оправдано. Таким образом можно примерно прикинуть, что MI430X может обеспечить производительность FP64 от 192 до 204 Тфлопс в зависимости от того, какой из них будет базовым: более новый MI355 или более быстрый MI325, сообщил HPCwire, добавив, что это всего лишь предположение, поскольку компания пока не сообщила точные характеристики будущих чипов. Кроме того, не до конца ясно, будет ли FP64-производительность одинакова для векторных и матричных расчётов. FP64-вычисления «очень важны» для «Миссии Генезис» (Genesis Mission), заявил ранее заместитель министра энергетики США (DoE) по науке и инновациям Дарио Гил (Darío Gil). Он отметил, что и глава AMD Лиза Су (Lisa Su), и глава NVIDIA Дженсен Хуанг (Jensen Huang), выразили твёрдую приверженность FP64, подтвердив, что поддержка формата будет продолжаться. «FP64 имеет решающее значение для поддержки рабочих нагрузок моделирования и симуляции, не только для дальнейшего развития традиционных научных исследований, но и для предоставления исходных данных для обучения новых ИИ-моделей», — добавил Гил. 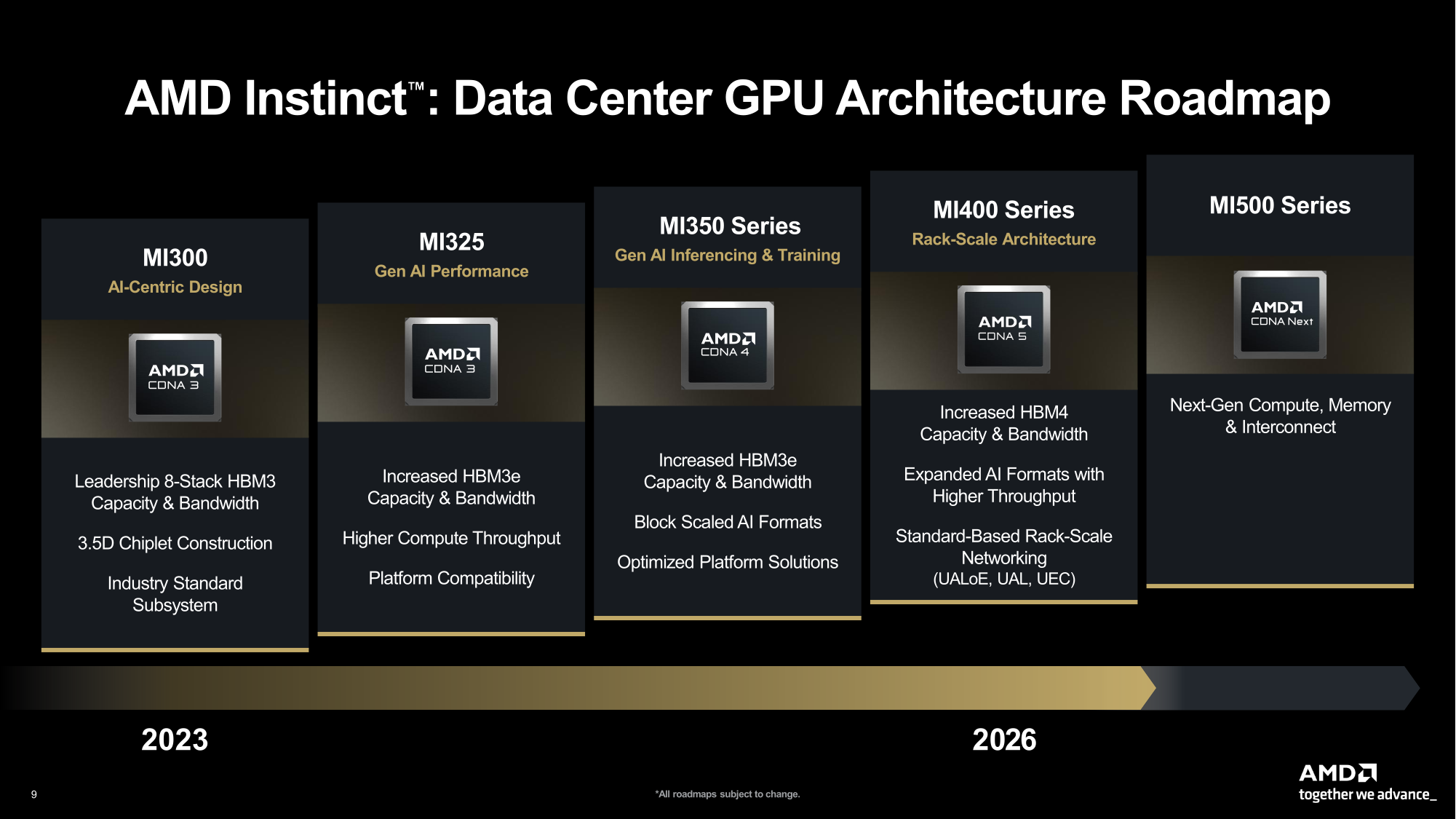
Источник изображения: AMD «Всегда существует баланс между тем, сколько требуется FP64- и FP16-вычислений», — сказал Малайя. «AMD утверждает, что нам необходимо поддерживать широкий спектр типов данных в зависимости от их потребностей. Не получится, чтобы всем были нужны FP64, которых хватит для всего.», — отметил он. Малайя сообщил, что всегда бывают исключения. Например, ИИ-симуляции сворачивания белков, такие как AlphaFold и Openfold, используют FP32. Да и некоторым традиционным HPC-задачам, таким как молекулярная динамика, не требуется FP64-точность. Тем не менее, сейчас существует значительный неудовлетворенный спрос на FP64, утверждает учёный. «Что касается высокопроизводительных вычислений, мы считаем, что им по-прежнему потребуется много FP64, — сказал он. — Будут использоваться некоторые коды, которые полностью ограничены пропускной способностью памяти, и им не нужно так много. Но есть, например, коды вычислительной химии и некоторые другие, которые действительно имеют высокую арифметическую интенсивность, и они будут использовать FP64». |
|

