Материалы по тегу: hpc
|
25.07.2026 [22:28], Андрей Крупин
«АМДтехнологии» и «Е-Флопс» развернули «двухконтурный» суперкомпьютер для ИИ- и HPC-задачПроизводитель серверных решений «Е-Флопс» и инжиниринговая компания «АМДтехнологии» разработали HPC-комплекс для решения ИИ-задач. Проект был реализован по заказу российского банка, входящего в Топ-10 крупнейших финансовых организаций страны, имя которого не уточняется. Созданное отечественными инженерами изделие состоит из 22 вычислительных узлов, базирующихся ускорителях NVIDIA H100 80GB и x86-процессорах, обеспечивающих пиковую производительность 11792 Тфлопс (FP64) для научных расчётов и 700 Пфлопс (FP8/INT8) для задач ИИ. Машина включает 4224 процессорных ядра, 33792 Гбайт RAM вычислительных узлов и 14080 Гбайт памяти GPU, а также 2973696 ядер CUDA и 92928 тензорных ядер. Каждый ускоритель получил 200G-интерфейс InfiniBand NDR. Локальное подключение обеспечивается 25GbE-интерфейсами, для управления задействована 10GbE-сеть. Вычислительный комплекс состоит из внутреннего и внешнего сегментов. Внутренний сегмент размещён внутри безопасного периметра банка без выхода в интернет, он ориентирован исключительно на решения задач ИИ. Внешний сегмент находится вне периметра информационной инфраструктуры банка и предназначен для HPC-нагрузок. 
Источник изображения: NVIDIA В соответствии с требованиями заказчика реализованы две независимых подсистемы хранения данных: внутреннего и внешнего сегментов. Во внешнем контуре установлена выделенная СХД с поддержкой иерархического хранения: «горячие» данные размещаются на SSD «сырой» ёмкостью 61 Тбайт, а «холодные» — на массивах HDD ёмкостью 2 Пбайт. Для его подключения используется InfiniBand NDR. Во внутреннем сегменте используется распределённое гиперконвергентное хранилище, которое масштабируется линейно вместе с ростом числа вычислительных узлов. Говорится об FC32 SAN для доступа к объектной СХД. ПО включает средства мониторинга и управления (в том числе NVIDIA DCGM), систему визуализации и анализа данных на базе открытых пакетов, а также платформу оркестрации Kubernetes с модулями Multus и Cilium. Внешний сегмент дополнительно поддерживает планировщик Slurm. Управляющие серверы работают в среде Proxmox. Суперкомпьютер уже введён в эксплуатацию и развёрнут в сертифицированном ЦОД одного из крупнейших провайдеров. Все серверы, коммутаторы, СХД внешнего сегмента, патч-панели размещены в 16 серверных шкафах с использованием воздушного охлаждения и организацией холодного и горячего коридоров. В вычислительный комплекс, по требованию заказчика, заложена возможность дальнейшего увеличения количества вычислительных узлов до 42, а также наращивание сетевой инфраструктуры.
20.07.2026 [21:41], Владимир Мироненко
Microsoft внедрит новейшую платформу AMD Helios AI в облако AzureAMD объявила о расширении стратегического партнёрства с Microsoft, охватывающего ускорители, процессоры, сетевое оборудование и ПО на платформе Azure. AMD начнёт поставки Helios клиентам, включая Microsoft, во II половине 2026 года, но именно Microsoft первой среди «большой тройки» облаков публично заявила о массовом развёртывании новой платформы. В рамках партнёрства Microsoft внедрит в ЦОД Azure платформу AMD Helios AI с EPYC Venice и MI455X. Эти решения будут лежать в основе трёх будущих семейств инстансов Azure: HDv2 для обработки данных, HXv2 для автоматизации проектирования электроники (EDA) и ND MI455X v7 для рабочих нагрузок ИИ-инференса. Инстансы HDv2, разработанные совместно с AMD, предназначены для самых ресурсоёмких задач, связанных с ИИ, включая подготовку данных, поиск, обучение с подкреплением и координацию агентов. Благодаря почти 500 физическим ядрам в составе AMD EPYC Venice, 4 Тбайт RAM, 32 Тбайт локального NVMe-хранилища и 400GbE DPU Azure Boost, HDv2 способны удовлетворить потребности самых требовательных клиентов в области ИИ, отметила Microsoft. Инстанcы HXv2 развивают сильные стороны виртуальных машин HX, запущенных в партнёрстве с AMD в 2023 году. HXv2 тоже предлагает дифференциацию для рабочих нагрузок моделирования на уровне RTL и тоже использует технологию 3D V-Cache, вместе с тем получив значительные улучшения в части производительности ядер и памяти в однопоточных задачах. ВМ HXv2 будут оснащены 176 ядрами процессоров EPYC Venice с тактовой частотой более 5 ГГц, наполовину большим кешем, доступному каждому ядре, и порядка 2 или 4 Тбайт RAM. 
Источник изображения: Microsoft При этом Azure HXv2 поддерживает более широкий спектр технических вычислительных задач, включая научное моделирование, инженерный анализ и другие приложения с распределённой памятью. Значительно повышенная производительность на ВМ и на ядро, а также наличие 800G-подключения InfiniBand, позволяют проводить крупномасштабные симуляции на основе MPI и делают HXv2 идеальным решением для широкого круга клиентов, использующих HPC, сообщила Microsoft. В свою очередь, инстансы ND MI455X v7 разработаны для ИИ-инференса в производственных масштабах — для рабочих нагрузок рассуждений, поиска и агентных вычислений, лежащих в основе современных ИИ-сервисов. Сотрудничество также распространяется на сетевой уровень. DPU Pensando уже активно используются Microsoft, а теперь компании интегрируют Azure Boost с технологиями AMD для повышения производительности сети, эффективности и обработки подключений в облачном масштабе. Сотрудничество расширяет доступ к ИИ-инфраструктуре AMD в Azure. Разработчики передовых моделей смогут использовать инфраструктуру на базе AMD для обучения и обслуживания крупномасштабных ИИ-моделей, а корпоративные клиенты могут развёртывать и масштабировать рабочие нагрузки ИИ в производственной среде с помощью управляемых вычислительных ресурсов Azure Foundry.
18.07.2026 [13:06], Сергей Карасёв
Для ИИ и для «квантов»: В Японии заработали суперкомпьютеры RIKYU и ROQUO на базе NVIDIA GB200 NVL4В Центре вычислительных наук Института физико-химических исследований Японии (RIKEN Center for Computational Science, R-CCS) началась эксплуатация высокопроизводительных комплексов RIKYU и ROQUO, выполненных на аппаратной платформе NVIDIA. Обе системы ориентированы на ресурсоёмкие задачи ИИ. В частности, RIKYU может применяться для разработки открытых фундаментальных моделей, а также проведения исследований в сферах наук о жизни, материаловедения и пр. Задействованы 400 узлов Supermicro PIO-121GL-NBIB-01 на базе NVIDIA GB200 NVL4 (два процессора Grace и четыре ускорителя Blackwell, объединенных посредством NVLink). Применяются жидкостное охлаждение и 800G-интерконнект InfiniBand XDR. Кроме того, в состав суперкомпьютера входят 16 узлов Supermicro SYS-212HA-TN с процессорами Intel Xeon 6980P (Granite Rapids-AP), 1,5 Тбайт памяти и хранилищем с накопителями NVMe SSD. Производительность в режиме FP64 достигает 59,63 Пфлопс, в режиме FP8 — 15,539 Эфлопс. 
Источник изображения: RIKEN В свою очередь, суперкомпьютер ROQUO спроектирован с прицелом на гибридные квантово-классические вычисления. Он получил 135 вычислительных узлов на основе NVIDIA GB200 NVL4. Интерконнект NVIDIA Quantum-X800 InfiniBand обеспечивает пропускную способность до 3,2 Тбит/с. Применено жидкостное охлаждение. Быстродействие в режиме FP64 находится на отметке 19,8 Пфлопс с пиковым значением 21 Пфлопс. Производительность в режиме FP8 превышает 5 Эфлопс. Вычислительный комплекс может функционировать в связке с квантовыми системами Quantinuum Reimei и IBM Quantum System Two. В целом, новые суперкомпьютеры формируют единую исследовательскую платформу, в составе которой RIKYU обеспечивает ресурсы для научных задач с использованием ИИ, а ROQUO позволяет сочетать классические ИИ-вычисления с квантовыми методами. Такая связка даёт учёным гибкий инструментарий для работы со сложными моделями и для решения комплексных задач.
17.07.2026 [17:12], Владимир Мироненко
Евросоюз объявил об успешном завершении второго этапа EPI для укрепления технологического суверенитетаВ Люксембурге состоялся заключительный обзор Европейской инициативы по процессорам (EPI), финансируемой EuroHPC. По итогам было объявлено об успешном завершении второго этапа проекта — EPI SGA2, целью которого было содействие укреплению технологического суверенитета Европы. В рамках обзора была проведена демонстрация уникальных технологий и микросхем, разработанных на обоих этапах проекта EPI. В частности, был продемонстрирован первый Arm-процессор SiPearl Rhea1, работающий с полным ПО для HPC. Чип запустили на тестовой плате со стандартным дистрибутивом Linux, работающим с высокоскоростной памятью HBM и соответствующими аппаратными счетчиками мониторинга производительности. Он успешно прошёл тесты HPL и STREAM, демонстрируя готовность всей аппаратной и программной экосистемы Rhea1 к высокопроизводительным вычислениям для систем экзафлопсного уровня. Также было проведено пять демонстраций, наглядно подтверждающих, что технология RISC-V, используемая EPI, перешла от отдельных блоков к полному программному стеку, реальному оборудованию и реальным приложениям и инструментам, которыми может воспользоваться обычный пользователь. Так, был развёрнут полный кластер на ускорителе VEC. Был показан новейший RTL-код (ядро RISC-V с внеочередным выполнением инструкций от Semidynamics, улучшенный векторный блок от Барселонского суперкомпьютерного центра) для запуска на FPGA в инфраструктуре MEEP. Было запущено реальное научное приложение Mini-Fall3D для оценки диффузии пыли в атмосфере, распараллеленное с помощью OpenMP и MPI, скомпилированное с использованием инструментария EPI LLVM и профилированное с помощью стандартных инструментов (PAPI, Extrae/Paraver). Запуски показали масштабируемость, продемонстрировав выполнения скалярных и векторных задач на разных узлах. Источник изображения: european-processor-initiative.eu Также был продемонстрирован готовый ИИ-чип EPAC 1.5 на базе RISC-V, подключённый к Arm-хосту через PCIe. Компилятор проекта генерирует один двоичный файл, содержащий код как Arm, так и RISC-V. Код RISC-V передаётся по PCIe через DMA, динамически загружается, выполняется, а результаты копируются обратно. Это демонстрирует оригинальную идею EPI по созданию гетерогенных систем с разными ISA и операционными средами, эффективно работающих вместе на реальном оборудовании. Kalray показала успешную доработку и оптимизацию ПО для своих KVX-процессоров на базе VLIW, которые также могут работать в режиме RISC-V. Menta продемонстрировала результаты оптимизации своей EDA Origami для больших eFPGA, которые позволили кратно ускорить разработку чипов и схем. Наконц, было продемонстрировано успешное использование технологии сжатия памяти в реальном времени ZeroPoint (DenseMem) на EPAC 1.5. Подводя итоги длившегося три года этапа SGA1 и четырёхлетнего SGA2, руководители проекта отметили, что путь к европейскому суверенитету в цифровых технологиях лежит в дальнейшем развитии этих результатов. Для этого научные партнёры проекта опубликуют результаты обширных исследований проекта, а промышленные партнёры продолжат дальнейшее развитие IP-блоков, полученных в его рамках.
13.07.2026 [08:48], Владимир Мироненко
HPC и отопление: Scaleway приобрёл QarnotБазирующийся в Париже облачный провайдер Scaleway объявил о приобретении французского стартапа Qarnot, специализирующегося на HPC-решениях для инженерных, имитационных и исследовательских задач. Благодаря сделке Scaleway добавит специализированные возможности HPC своей платформе облачных вычислений и ИИ, которая, по её словам, всё более востребована промышленными и финансовыми организациями. «Приобретение ещё больше укрепляет позиции Scaleway как единственного суверенного европейского поставщика облачных услуг, предлагающего облачные вычисления, ИИ и HPC в рамках единой платформы», — отметила Scaleway. Scaleway сообщила, что её с Qarnot деятельность регулируется европейской юрисдикцией, что обеспечит их клиентам иммунитет от экстерриториального законодательства. Также обе компании роднит приверженность стандартам OCP для проектирования и развёртывания своей инфраструктуры, от архитектуры серверов до операционных практик. Вместе они способствуют совместимости, снижают зависимость от проприетарных технологий и препятствуют привязке клиентов к определённым технологиям. Решение Qarnot HPCaaS обеспечивает доступ к тысячам HPC-инстансов, позволяя одновременно запускать несколько кластеров и без труда масштабировать рабочие нагрузки. 
Источник изображения: Scaleway Также для Scaleway представляют интерес разработки Qarnot в области утилизации тепла, выделяемого серверами. Благодаря запатентованной Qarnot технологии прямого жидкостного охлаждения, до 95 % тепла, выделяемого HPC-серверами, может быть рекуперировано и перенаправлено в сети централизованного теплоснабжения, на общественные объекты и промышленные предприятия без ущерба для вычислительной производительности. В Брешиа (Brescia, Италия) Qarnot в партнёрстве с A2A интегрировала HPC-инфраструктуру с городской сетью централизованного теплоснабжения. Среди клиентов Qarnot — компании MaiaSpace, Alpine Racing, Natixis, ATR Aircraft. В 2020 году она привлекла около $6,5 млн, в дополнение к $2,5 млн, полученным от Data4 Group несколькими годами ранее. В начале 2023 года Qarnot привлекла ещё €35 млн ($37,5 млн) для расширения своей деятельности. В 2025 году компания получила дополнительное финансирование через Европейский инновационный совет. В свою очередь, Scaleway стала одним из победителей тендера Европейской комиссии на предоставление суверенных облачных услуг.
10.07.2026 [18:50], Владимир Мироненко
Европейские ИИ-гигафабрики ÆTHER получат суверенные чипы Axelera и SiPearlЕвропейский консорциум ÆTHER (AETHER) сообщил о подаче заявки на участие в предстоящем тендере Европейской комиссии по созданию ИИ-гигафабрик (AI Gigafactory), объявленном в рамках стратегии ЕС в области цифрового и промышленного суверенитета, о чём пишет HPCwire. Сообщается, что консорциум объединил ведущих европейских игроков в энергетике, строительстве, облачных вычислениях, полупроводниках, высокопроизводительных вычислениях и ИИ, поставивших цель «продемонстрировать, что Европа обладает всеми необходимыми знаниями для проектирования, строительства, электроснабжения, эксплуатации и масштабирования инфраструктуры ИИ». ÆTHER объявил о начале активных переговоров по приобретению двух промышленных площадок в районе Страсбурга (Strasbourg, Франция) для строительства ЦОД. Ожидается, что сделка по приобретению первой площадки, FR-SXB1, будет завершена к концу октября, с последующим вводом в эксплуатацию в 2027 года. Приобретение второй площадки FR-SXB2 должно быть завершено к концу декабря, а к работе ЦОД приступит спустя несколько месяцев. Обе площадки имеют подключения к энергосети и необходимые разрешения. 
Источник изображения: SiPearl Два ЦОД первоначально обеспечат суммарную мощность в 42 МВт. Спустя 12 мес. будет добавлено ещё 40 МВт, с конечной целью увеличения мощности до 400 МВт. Сообщается, что к концу июля французскому оператору системы передачи электроэнергии RTE будут представлены предложения по обеспечению большей мощности на площадке FR-SXB1. Строительство ЦОД возглавит компания Nhood при поддержке Damthieu Bard и Equans. Аппаратное обеспечение будет предоставлено компанией 2CRSi (партнёр AMD и NVIDIA), занимающейся производством серверов, поставщиком ИИ-ускорителей Axelera AI и разработчиком CPU SiPearl. За энергоснабжение будут отвечать ÉS Group, Projex и Haffner Energy. «Объединив высокопроизводительные процессоры SiPearl с ускорителями Axelera в HPC-серверах 2CRSi, мы предоставим комплексное аппаратное решение, способное обрабатывать самые требовательные ИИ-задачи, с дополнительным преимуществом европейского суверенитета. Мы рады играть активную роль в консорциуме ÆTHER, что подтверждает важнейшую роль Европы в глобальной гонке за ИИ», — заявила SiPearl. Объявленный в феврале 2025 года проект ЕС AI Continent Action Plan по созданию ИИ-гигафабрик стоимостью €20 млрд ($22,8 млрд) предусматривает строительство от трёх до пяти крупных суперкомпьютерных кластеров по всему континенту, каждый из которых будет оснащен 100 тыс. ИИ-чипов для обучения самых современных и сложных моделей.
10.07.2026 [11:34], Сергей Карасёв
Национальный научный фонд США выделил $10 млн на суперкомпьютер Bridges-3 с AMD EPYC и NVIDIA B200Национальный научный фонд США (NSF), по сообщению Datacenter Dynamics, выделил $10 млн Питтсбургскому суперкомпьютерному центру (PSC) на создание вычислительного комплекса следующего поколения Bridges-3. Монтаж системы начнётся в начале следующего года. Новый суперкомпьютер станет преемником нынешней машины Bridges-2 (на изображении). Этот комплекс имеет гетерогенную архитектуру с узлами разных типов под различные задачи. В частности, задействованы 504 узла Regular Memory с 256/512 Гбайт оперативной памяти и двумя процессорами AMD EPYC 7742 каждый. Кроме того, присутствуют узлы Extreme Memory, несущие на борту по четыре чипа Intel Xeon Platinum 8260M Cascade Lake и 4 Тбайт ОЗУ. Наконец, применяются GPU-узлы в нескольких конфигурациях — в том числе с ускорителями NVIDIA H100 и NVIDIA L40S. 
Источник изображения: PSC Технические характеристики Bridges-3 пока полностью не раскрываются. Но известно, что созданием вычислительного комплекса займётся HPE. Система получит серверы на основе неназванных процессоров AMD с «большим количеством ядер». Будут применяться ИИ-ускорители NVIDIA B200. Упомянуты интерконнект InfiniBand и хранилище типа All-Flash на базе Lustre. Бруно Абреу (Bruno Abreu), заместитель научного директора PSC и главный специалист проекта Bridges-3 отмечает, что проектируемая система сохранит все ключевые возможности своего предшественника, получив при этом современные CPU и GPU, обеспечивающие существенное повышение производительности для задач моделирования, симуляции, анализа данных и ИИ. Суперкомпьютер расположится в новом дата-центре PSC. Ввод Bridges-3 в эксплуатацию намечен на лето 2027 года.
28.06.2026 [22:32], Владимир Мироненко
Платформа HPE Supercomputing Programming Software упростит работу с мультивендорными системами ИИ и HPC
amd
hpc
hpe
intel
nvidia
open source
software
ии
контейнеризация
конфиденциальность
разработка
утилизация
Компания HPE представила новую унифицированную программную платформу HPE Supercomputing Programming Software, предназначенную для того, чтобы помочь клиентам справляться с растущей сложностью работы с HPC-средами мультивендорных систем, обеспечивая согласованность между системами HPE. HPE отметила, что разработка приложений для работы на HPC-платформах, таких как кластеры HPE Cray GX5000, требует от разработчиков использования языков программирования и фреймворков, специфичных для конкретной архитектуры чипа. Клиенты используют пакеты, предлагаемые AMD, Intel или NVIDIA, и т.д., и задача клиента — убедиться, что они совместимы с её платформой Cray. HPE будет сотрудничать с производителями чипов для объединения их инструментов разработки в рамках новой платформы, заявил Джим Лухан (Jim Lujan), вице-президент по системной инженерии HPE в интервью HPCwire. По его словам, с помощью HPE Supercomputing Programming Software компания предоставит, по сути, контейнеры с поддержкой их экосистем. HPE берёт на себя обеспечение первой линии поддержки, когда у клиентов возникают проблемы — вместо того, чтобы просто переправлять сообщения производителям чипов, сказал Лухан. Он также отметил, что HPE всё больше переходит на open source, дополняя проприетарные компоненты софтом из открытой экосистемы, что расширяет возможности клиентов. Нынешнее обновление поддерживает Kubernetes, а также открытые инструменты разработки AMD и NVIDIA. 
Источник изображения: HPE HPE Supercomputing Programming Software предлагает простой подход к многовендорным средам и процессу интеграции, помогая ускорить циклы развёртывания и минимизировать риск нестабильности системы. Платформа поддерживает серверы HPE ProLiant, включая модели HPE ProLiant DL и XD, оптимизированные для различных задач обучения, настройки и ИИ-инференса, что обеспечивает согласованный и упрощённый опыт работы на разных платформах для крупных предприятий. Новый программный стек также обеспечивает больше возможностей для разработки клиентами приложений ИИ и HPC с многопользовательским режимом, важность которого возросла в основном из-за требований суверенитета, предъявляемых компаниями, организациями и государственными учреждениями, находящимися за пределами США. HPE добавила многопользовательский режим в инструмент Smart Update Manager (SUM), чтобы клиенты могли изолировать свои данные, а также его поддержку в уже поставленных потребителям коммутаторах Slingshot 400 и СХД Cray E2000. «В последнее время наблюдается большой спрос на многопользовательский режим и его поддержку, — сообщил Лухан. — Мы всегда поддерживали множество пользователей, но теперь есть желание добиться большей изоляции данных и их разделения для некоторых наших клиентов». HPE также расширила свою программу вывода из эксплуатации систем, включив в нее серверы с воздушным охлаждением для ИИ и HPC. Согласно данным компании, в в 2025 году 85 % серверов, прошедших через центры обновления, были переработаны и возвращены в активное использование, а 1,7 Эбайт данных были надёжно удалены.
26.06.2026 [12:44], Сергей Карасёв
Два кристалла, 304 ядра и 32 Гбайт HBM: подробности об Arm-чипах LX2 в китайском суперкомпьютере LineShineКитайский национальный суперкомпьютерный центр в Шэньчжэне (NSCCSZ) обнародовал дополнительную информацию о вычислительном комплексе LineShine, который возглавил свежий рейтинг самых мощных НРС-систем мира TOP500. FP64-производительность LineShine в тесте Linpack достигает 2,198 Эфлопс. В основу LineShine положены китайские 304-ядерные процессоры LX2 с архитектурой Arm. Конструкция этих изделий включает два вычислительных кристалла, каждый из которых содержит 152 ядра Armv9 с поддержкой Scalable Vector Extension (SVE) и Scalable Matrix Extension (SME). Тактовая частота составляет 1,55 ГГц. Каждый из кристаллов, в свою очередь, разделён на четыре NUMA-домена по 38 ядер. В состав каждого домена входят 4 Гбайт памяти HBM и 32 Гбайт памяти DDR5. Таким образом, в общей сложности используются 32 Гбайт HBM и 256 Гбайт DDR5. Энергопотребление LX2 находится на уровне 690 Вт. 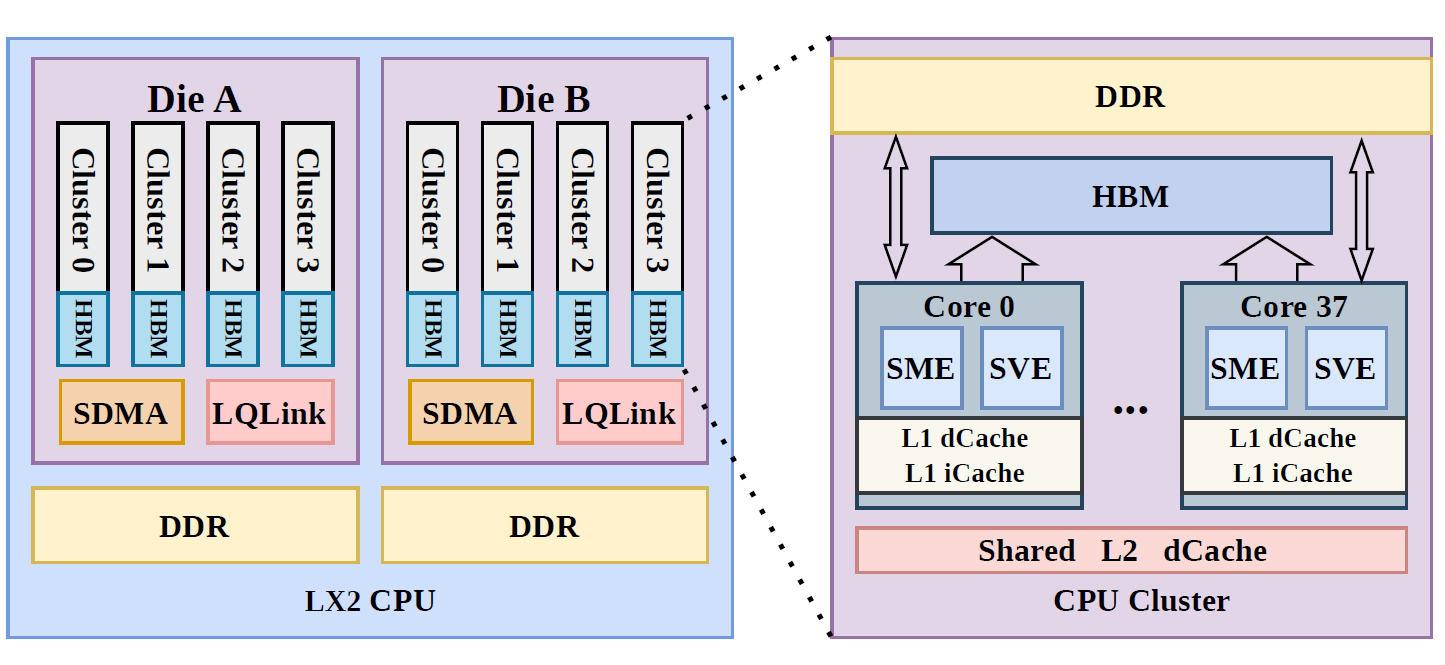
Источник изображения: NSCCSZ В составе LineShine два процессора LX2 формируют один вычислительный узел. Восемь таких узлов входят в один blade-сервер, а 16 серверов — в одно шасси. В одной стойке задействованы два шасси, что в сумме обеспечивает 512 процессоров. В целом, суперкомпьютер насчитывает около 90 стоек и примерно 14 млн вычислительных ядер. Энергопотребление LineShine достигает 42,2 МВт. Реализовано полностью жидкостное охлаждение на основе двусторонних водоблоков. Платформа использует проприетарный интерконнект LingQi, который обеспечивает пропускную способность между узлами до 1,6 Тбит/с. Технология LingQi поддерживает 2 млн портов и может масштабироваться до более чем 100 тыс. узлов. Вместимость подсистемы хранения данных LineShine составляет 200 Пбайт. Каждая стойка получает питание от шины постоянного тока LVDC на 380 В, обеспечивая вычислительную мощность до 580 кВт.
26.06.2026 [12:23], Владимир Мироненко
Cornelis и NextSilicon создадут эталонные архитектуры для ИИ и HPCCornelis и NextSilicon объявили о сотрудничестве с целью разработки эталонных архитектур для ИИ и HPC. В рамках проекта компании приступили к оценке возможности использования 400G-интерконнекта Cornelis CN5000 в паре с вычислительной платформой NextSilicon Maverick-2. На первом этапе проверяется совместная работа интерконнекта и вычислительных ресурсов в различных конфигурациях, причём партнёры начали с проверенных комбинаций. Компании планируют расширить тестирование на интерконнект CN6000 со скоростью 800 Гбит/с, запуск которого запланирован на II половину 2026 года. Обе компании нацелены на решение проблемы в своей сфере. Стандартный Ethernet не рассчитан на обработку небольших, чувствительных к задержке сообщений, которые генерируются в больших масштабах при выполнении задач ИИ-инференса и симуляции HPC. Возникает перегрузка, и дорогостоящие вычислительные ресурсы простаивают в ожидании данных. CN5000 разработан для устранения этого простоя. 
Источник изображений: Cornelis Networks Вычислительные ресурсы простаивают при обработке нерегулярных, зависящих от данных рабочих нагрузок, которые доминируют в ИИ и HPC. Израильская компания NextSilicon построила ускоритель Maverick-2 на основе своей интеллектуальной вычислительной архитектуры (ICA) — программно-определяемой архитектуры с управлением потоками данных (dataflow), в которой вычисления запускаются не последовательными инструкциями, а по факту поступления данных. Платформа переконфигурируется для каждой рабочей нагрузки во время выполнения без изменения существующего кода. Сочетание подходов Cornelis и NextSilicon позволяет решить обе проблемы, обеспечивая передачу данных и поддерживая постоянную работу вычислительных ресурсов. Совместные эталонные архитектуры предоставят OEM-партнерам план создания систем, которые они смогут построить и вывести на рынок.  «Операторы постоянно говорят нам, что их самые дорогие системы простаивают, ожидая подключения к сети, — говорит Лиза Спелман (Lisa Spelman), генеральный директор Cornelis. — Мы создали CN5000, чтобы положить конец этому ожиданию. NextSilicon бросает вызов аналогичной проблеме в вычислительной сфере, поэтому это сотрудничество является естественным шагом. Вместе мы можем показать партнерам и клиентам, что дают бесперебойная сеть и вычислительная архитектура, ориентированная на рабочие нагрузки, в рамках единого решения». Наряду с HPC, сотрудничество также будет направлено на переход в ИИ-инференсе к моделям смешанных экспертов (MoE) и агентному ИИ. Инференс в продуктовых средах для этих рабочих нагрузок больше не выполняется как одна модель на одном ускорителе. Он разделяется на этапы, и данные перемещаются между этапами по сети. Дезагрегированный инференс делает сетевую инфраструктуру частью вычислительного пути. Он применим для сети, которая обрабатывает небольшие, импульсные, чувствительные к задержкам сообщения без перегрузки, и вычислительных ресурсов, которые адаптируются к каждому этапу конвейера. |
|

