Материалы по тегу: tesla
|
26.06.2026 [12:38], Руслан Авдеев
Tesla предложила запитать ЦОД от домашних аккумуляторов и электромобилей — в США насчитали 16 ГВт таких мощностейSunrun, Renew Home и Tesla заключили партнёрское соглашение. Оно позволит задействовать более 16 ГВт энергии, доступной домохозяйствам по всей территории США. Это электричество предложат гиперскейлерам и коммунальным компаниям, сообщает Datacenter Dynamics. Партнёры анонсировали соглашение, в рамках которого будут привлечены ресурсы уже используемых домашних аккумуляторных энергосистем, возможности умных термостатов и электромобилей, способных отдавать электроэнергию обратно в сеть (V2G). Партнёры объявили, что покупателям энергомощностей не потребуется новое оборудование, выделение земельных участков, новых водных ресурсов или постройка новой инфраструктуры. Более того, мощности можно будет получить уже через несколько месяцев, а не через годы. Совокупную мощность будут формировать за счёт сотен тысяч домашних аккумуляторных энергохранилищ, операторами которых выступают Sunrun и Tesla. Кроме того, проекту помогут более 8 млн умных термостатов под управлением Renew Home. В результате будет сформирована крупнейшая виртуальная «распределённая электростанция» в стране. По словам Sunrun, электросети XIX века не могут обеспечить электроснабжение инноваций 2026 года. Когда ЦОД нужно снизить энергопотребление из-за больших нагрузок на электросети в определённое время суток, новая система сможет выделять дополнительные энергоресурсы, в то же время «защищая американские семьи» от косвенной оплаты создания новой инфраструктуры. 
Источник изображения: Zaptec/unspalsh.com Гиперскейлеров уже приглашают присоединиться к проекту, поскольку мощности будут предоставляться в первую очередь тем, кто раньше принял предложение. В Вирджинии партнёры уже сегодня готовы предоставить более 300 МВт, к 2030 году этот показатель, вероятно, вырастет до 500 МВт. Часть мощности партнёры резервируют для предложенного энергокомпанией PJM механизма Reliability Backstop Process. Это, возможно, позволит высвободить более 1 ГВт мощности немедленно, а в последующие годы добавятся и дополнительные мощности для сглаживания пиковых нагрузок и быстрого реагирования на запросы вспомогательных сервисов. По словам Tesla, американская энергосистема испытывает всё большее давление из-за роста числа ЦОД, электрификации и роста производства. Ни одно инфраструктурное решение по отдельности не способно решить проблему достаточно быстро. Sunrun, Renew Home и Tesla рассчитывают использовать аккумуляторы, умные термостаты и электромобили в миллионах американских домов, готовых внести вклад в энергосистему. Использование распределённых энергосистем и виртуальных электростанций для освобождения мощностей становится всё более востребованным. Ранее в июне Google заключила соглашение с оператором виртуальных электростанций Voltus на 100 МВт. В рамках сделки последняя объединит мощности от аккумуляторов, умных термостатов и прочих энергоресурсов с возможностью гибкого управления в единую виртуальную электростанцию, финансируемую Google.
24.04.2026 [11:15], Руслан Авдеев
Tesla развернула ИИ-кластер Cortex 2 на территории Gigafactory в ТехасеTesla ввела в эксплуатацию кластер Cortex 2 для обучения ИИ, расположенный на территории кампуса Gigafactory Texas. Это знаменует новый шаг на пути компании к расширению собственных вычислительных мощностей для создания систем автономного вождения, робототехники и других задач в сфере ИИ, сообщает Converge Digest. В презентации для акционеров, посвящённой итогам I квартала 2026 года, компания указала, что кластер Cortex 2 находится на стадии «раннего масштабирования». Установленная годовая производительность составляет эквивалент более 130 тыс. ИИ-ускорителей NVIDIA H100. Кроме того, имеется ещё и кластер Cortex 1, эквивалентный 100 тыс. H100. По данным Tesla, Cortex 2 уже выполняет задачи обучения моделей. Кроме того, компания разрабатывает и архитектуру Dojo 3 для суперкомпьютеров нового поколения, чтобы снизить затраты на обучение в будущем. Развитие ИИ-инфраструктуры Tesla напрямую связывается с с масштабированием планов по созданию роботизированных такси и Optimus. В материалах отчёта также упоминается, что расширение вычислительных мощностей осуществляется в рамках более масштабного плана развития в сфере аккумуляторных технологий, материалов и сервисов мобильности. 
Источник изображения: Tesla Кроме того, в отчёте указано на запуск в апреле системы FSD (Supervised) версии 14.3, улучшении «обучения с подкреплением» и обработки в системах машинного зрения, задержка инференса сокращена на 20 %. Кроме того, т.н. Digital Optimus обозначен как следующий этап развития ИИ-платформы Tesla. Также раскрыты планы компании в полупроводниковой отрасли. Было заявлено, что Tesla расширяет сферу производства и намерена заняться выпуском полупроводников, начиная с мощностей Research Fab на территории Gigafactory в Техасе. Сообщалось, что в апреле компания окончательно завершила разработку чипа нового поколения AI5. Также объявлено, что партнёрство со SpaceX направлено на создание «крупнейшего в истории» завода по выпуску чипов, с вертикальной интеграцией, включающей логические микросхемы, память и передовые технологии упаковки. Утверждение о масштабе, конечно, является словами самой Tesla, но оно косвенно свидетельствует о том, насколько агрессивно компания сейчас связывает ИИ-вычисления, разработку чипов и производственную стратегию.
15.03.2026 [11:15], Сергей Карасёв
Выпуск ИИ-чипов DeepX DX-M2 отложен из-за проблем у TeslaИзменение графика разработки ИИ-ускорителя Tesla следующего поколения, по сообщению ресурса DigiTimes, привело к тому, что южнокорейская компания DeepX вынуждена отложить выпуск своих чипов DX-M2, массовое производство которых изначально было запланировано на II квартал 2027 года. Отмечается, что задержки возникли с разработкой изделия Tesla AI6. Предполагается, что это решение будет применяться для поддержания разнообразных нагрузок в инфраструктуре Tesla, включая платформы автономного вождения, системы человекоподобного робота Optimus и дата-центры для ИИ-задач. В 2025 году Tesla подписала контракт с Samsung на изготовление AI6 вплоть до декабря 2033-го: стоимость соглашения составляет $16 млрд. Первоначальный договор предусматривал производство около 16 тыс. пластин в месяц, однако затем Tesla запросила дополнительно 24 тыс. пластин, что в сумме предполагает объем до 40 тыс. пластин ежемесячно. Для Tesla AI6 планируется применение 2-нм техпроцесса Samsung. По такой же методике будут выпускаться чипы DeepX DX-M2. Для обоих этих изделий оговорено использование услуги Multi-Project Wafer (MPW), при которой на одной кремниевой пластине в рамках получения прототипов размещаются изделия нескольких разных заказчиков. Такой подход позволяет снизить затраты на разработку перед организацией массового производства.  Однако, по информации DigiTimes, с выходом Tesla AI6 на этап MPW возникли задержки. С чем именно связаны сложности, не уточняется. Отраслевые эксперты полагают, что пересмотр графика может быть обусловлен изменением сроков инвестиций в автономные транспортные средства, роботизированные платформы и суперкомпьютеры с ИИ. Компания Samsung отказалась от комментариев, сославшись на конфиденциальность проектов заказчиков. Между тем из-за задержек Tesla выпуск чипов DeepX DX-M2 по программе MPW, который планировалось начать в апреле, переносится на более поздний срок. В соответствии с новым графиком, тестирование качества этих решений будет организовано не ранее III квартала текущего года. Ожидается, что DX-M2 обеспечит ИИ-производительность на уровне 80 TOPS при максимальном энергопотреблении примерно 5 Вт. Чип поддерживает память LPDDR5X. Утверждается, что процессор способен работать с ИИ-моделями, насчитывающими до 100 млрд параметров.
20.01.2026 [21:58], Владимир Мироненко
Tesla возобновит строительство ИИ-суперкомпьютеров DojoГендиректор Tesla (Elon Musk) Илон Маск объявил в соцсети Х о решении компании возобновить работу над Dojo3, третьим поколением суперкомпьютерных систем, о чём сообщает Data Center Dynamics. Команда, занимавшаяся проектом Dojo, была расформирована в прошлом году в связи с тем, что компания отдала предпочтение ИИ-чипам, используемых в бортовых системах электромобилей. Также ранее было объявлено, что компания будет полагаться на чипы внешних партнёров. Вместе с тем компания возвращается к проекту Dojo, поскольку, по словам Маска, достигнуты успехи в разработке чипа AI5, что создало определённый запас прочности. Маск объявил, что однокристальный чип AI5 обеспечит производительность на уровне NVIDIA Hopper, при этом двухкристальный AI5 будет равен по мощности чипу с Blackwell. Он предложил всем заинтересованным в участии в проекте и «работе над созданием самых массово производимых в мире микросхем» отправить сообщение Tesla, указав в трёх пунктах самые сложные технические проблемы, которые они решили. Илон Маск также сообщил, что разработка чипа Tesla AI5 почти завершена, а чип AI6 находится на «ранней стадии» разработки, добавив, что компания также планирует создать чипы AI7, AI8 и AI9. По его словам, нынешний чип Tesla AI4 позволит достичь «уровня безопасности при автономном вождении, намного превышающего человеческий», а AI5 сделает электромобили Tesla «почти идеальными», также значительно улучшив функционирование человекоподобного робота Optimus. «AI6 для Optimus и ЦОД. AI7/Dojo3 будут использовать ИИ для космических вычислений», — написал Маск. В ноябре 2025 года он заявил, что существует «чёткий путь к удвоению производительности по всем показателям для AI6 в течение 10–12 мес. после выпуска AI5», а теперь он намерен сократить срок создания каждого нового поколения ИИ-чипов до 9 мес. Хотя сам миллиардер не стал называть сроки производства чипа AI5, ИИ-чат-бот Grok сообщил пользователям в ответ на запросы, что ограниченное производство AI5 ожидается в 2026 году, а массовое производство запланировано на 2027 год. 
Источник изображения: Tesla В конце прошлого года Маск заявил акционерам Tesla, что компании, вероятно, потребуется построить «гигантскую фабрику» для производства своих ИИ-чипов, чтобы хотя бы частично удовлетворить в них потребности компании. Tesla уже сотрудничает с TSMC и Samsung, которые производят чипы AI5 и AI6 на заводах в Аризоне и Тайване, а также в Южной Корее и Техасе соответственно. На том же собрании акционеров Маск сказал, что, вероятно, стоит обсудить вопрос производства и с Intel. Как отметил Techpowerup, в августе прошлого года появились сообщения о присоединении к компании Маска Intel в качестве ключевого партнёра по упаковке чипов, что ознаменовало отход Tesla от прежней зависимости от TSMC в вопросах производства. Сообщается, что Intel будет управлять сборкой и тестированием, используя свою технологию EMIB. Это лучше подходит для больших блоков Tesla Dojo, объединяющих несколько чипов площадью 654 мм² в одном корпусе. В свою очередь, Samsung будет производить обучающие чипы D3 на своем заводе в Техасе с помощью 2-нм техпроцесса, оставив Intel контроль над процессами упаковки. Такое разделение труда решает проблему ограничений производственных мощностей и предоставляет Tesla большую гибкость в настройке схем межсоединений. Для автомобильных чипов AI5 компании Samsung и TSMC создадут разные версии, хотя Tesla стремится обеспечить одинаковую производительность в обоих случаях. Предполагается, что AI5 будет потреблять 150 Вт, при этом соответствуя по производительности NVIDIA H100, у которого TDP составляет до 700 Вт. Это было достигнуто путём удаления графических подсистем общего назначения и оптимизации архитектуры специально для ИИ-алгоритмов Tesla.
23.12.2025 [15:03], Руслан Авдеев
Google купит Intersect Power за $4,75 млрд, получив несколько гигаватт энергии для своих ИИ ЦОДGoogle объявила о покупке за $4,75 млрд американского девелопера энергетической инфраструктуры Intersect Power, сообщает Datacenter Dynamics. Google также возьмёт на себя долги приобретаемой компании. Сделка будет закрыта в I половине 2026 года. В рамках сделки «материнская» Google структура — Alphabet получит портфолио как строящихся, так и находящихся в разработке активов Intersect на несколько гигаватт. Google уже является миноритарным акционером Intersect. Google сообщает, что Intersect не только позволит расширить мощности и более гибко строить генерирующие мощности с учётом потребностей новых дата-центров, но и переосмыслить энергетические проекты, чтобы стимулировать инновации и обеспечить лидерство США в связанных сферах. При этом Intersect останется отдельным юридическим лицом, а некоторые активы в Техасе и Калифорнии будут функционировать как независимый бизнес, поддерживаемый TPG Rise Climate, Climate Adaptive Infrastructure и Greenbelt Capital Partners. После сделки Intersect получит новые технологии для наращивания и диверсификации поставок энергии. Компанией продолжит управлять действующий глава Шелдон Кимбер (Sheldon Kimber). В то же время предусмотрено сотрудничество с командой Google, занимающейся технической инфраструктурой. В числе прочего речь идёт о ранее анонсированной инициативе по созданию дата-центра и энергоплощадки в техасском округе Хаскелл (Haskell, Техас). 
Источник изображения: Intersect Power Intersect Power специализируется на экологически чистой энергетике. Её портфолио включает солнечные энергетические установки и аккумуляторные энергохранилища на 2,4 ГВт∙ч, в первую очередь в Техасе и Калифорнии. В 2024 году компания впервые начала взаимодействовать с Google для разработки технологий размещения источников возобновляемой энергии и энергохранилищ при новых ЦОД по всей территории США. В рамках первоначального соглашения Intersect согласилась построить объекты «зелёной» энергетики для Google, которая намеревалась закупать энергию для кампусов ЦОД и стать якорным арендатором в новых технопарках. Также Intersect тесно взаимодействует с другими участниками технологической экосистемы, наиболее значимым из которых является Tesla. По данным Intersect, компания заключила соглашение о покупке аккумуляторных энергохранилищ Tesla Megapack на 17,7 ГВт∙ч, что делает её одним из крупнейших заказчиков такого рода в США.
27.11.2025 [09:05], Руслан Авдеев
xAI потратит $375 млн на аккумуляторное хранилище Tesla Megapack и построит солнечную электростанцию для ИИ ЦОД ColossusКомпания xAI намерена разместить аккумуляторные энергохранилища Tesla Megapack стоимостью более $375 млн при суперкомпьютерном кластере Colossus 2, сообщает Datacenter Dynamics. 
Источник изображения: xAI Утверждается, что ЦОД Colossus способен вместить до 350 тыс. ИИ-ускорителей. По некоторым данным, для обеспечения энергоснабжения Colossus II компания xAI намерена импортировать в США целую электростанцию. Ранее в 2025 году она столкнулась в некоторыми проблемами после того, как стало известно о размещении большого количества газовых генераторов на территории кампуса Colossus 1. Попутно компания установила 168 Tesla Megapack. Недавно xAI также подала заявку на создание солнечной электростанции на территории площадью почти 37 га к северу и югу от ЦОД Colossus 1. 
Источник изображения: Tesla В 2024 году стартап Маска запустил свой первый суперкомпьютер Colossus в новом ЦОД на территории бывшего производства Electrolux в Мемфисе. Сообщается, что в дата-центре мощностью 250 МВт установлены порядка 200 тыс. ИИ-ускорителей. Впрочем, по словам Маска, в конечном итоге он намерен развернуть в Мемфисе 1 млн. передовых ИИ-чипов. 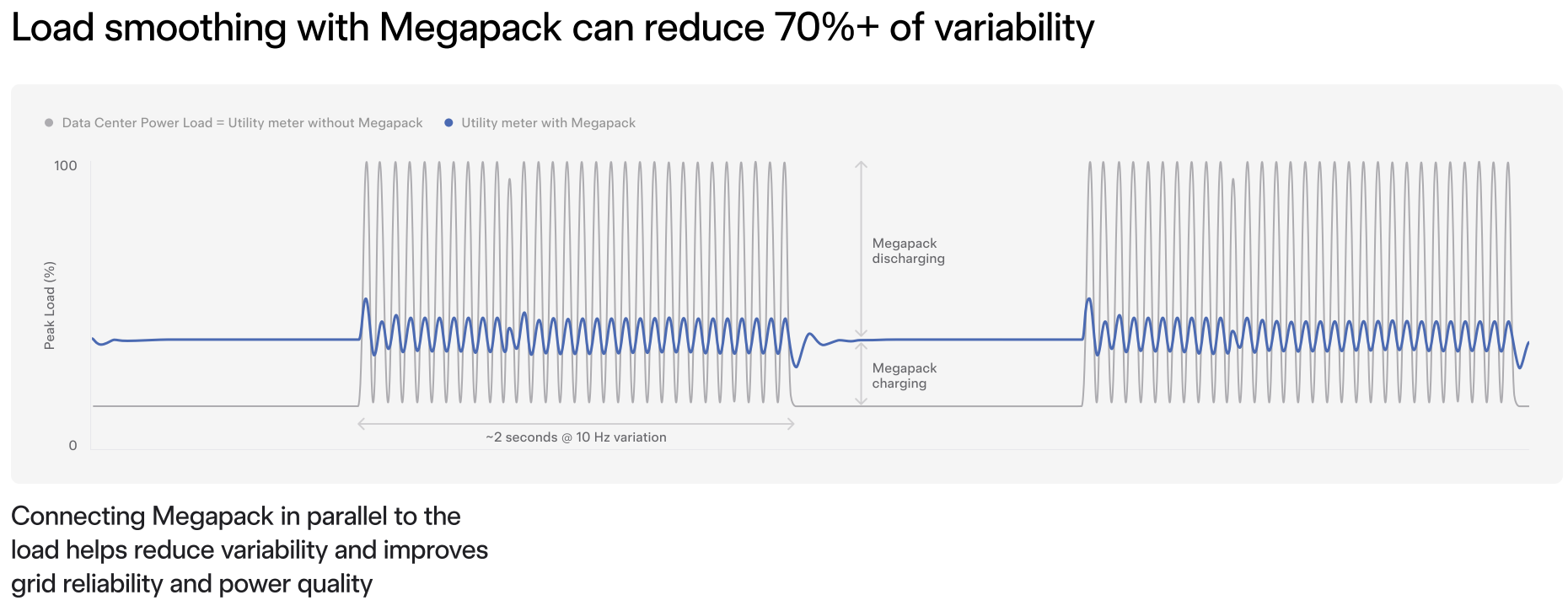
Источник изображения: Tesla Megapack — это модульные, крупногабаритные контейнерные системы на литий-ионных аккумуляторах, разработанные Tesla для коммунальных и коммерческих нужд. Каждый модуль Megapack имеет ёмкость до 4 МВт∙ч. Не так давно Tesla стала продвигать BESS Megapack в качестве оптимального решения для питания ИИ ЦОД. Дело не только и не столько в возможности резервного питания от АКБ, сколько в возможности сглаживания всплесков энергопотребления ИИ ЦОД во время обучения моделей. А для тех, кто хочет сэкономить, Redwood Materials, основанная одним из соучредителей Tesla, предлагает энергохранилища на базе б/у аккумуляторов электромобилей.
12.11.2025 [17:12], Руслан Авдеев
Конкуренция на рынке аккумуляторных энергохранилищ США скажется на ЦОД — у КНР более дешёвые и качественные АКБ
catl
hardware
jefferies
tesla
дефицит
ибп
ии
китай
прогноз
санкции
сша
цод
электропитание
энергетика
Аккумуляторные энергохранилища (BESS) в скором будущем могут стать стандартом для дата-центров по мере расширения инфраструктуры ИИ ЦОД. Тем не менее американских экспертов настораживает существующая на рынке тенденция — аккумуляторные решения из США во многом уступают китайским аналогам, сообщает The Register. В распоряжение издания попали материалы аналитической компании Jefferies. В отчёте подчёркивается, что гиперскейлеры, строящие ИИ ЦОД, всё больше рассматривают BESS в качестве неотъемлемой части энергетической инфраструктуры. Они всё чаще обращаются к проектам локальной генерации или испытывают проблемы с присоединением к энергосетям, поэтому BESS рассматривается как дополнительный ресурс, позволяющий управлять нагрузками, ускорить подключение и получить избыточные резервы энергии. Аккумуляторные системы используют в качестве резервных наряду с генераторами и другими вариантами получения энергии вроде твёрдооксидных топливных элементов. В Jefferies ожидают, что применение BESS будет расти в связи с трудностями коммунальных служб, которым трудно справиться с ростом спроса на электричество со стороны владельце электромобилей и расширением рынка дата-центров. В отчёте отмечается, что аккумуляторные решения — одна из немногих безуглеродных технологий, которым пророчат процветание при новой администрации США, даже за пределами рынка ЦОД. В следующее десятилетие будут развёрнуты минимум 20 ГВт аккумуляторных энергохранилищ. Наиболее вероятным будет применение литий-железо-фосфатных (LFP или LiFePO4) решений с 2–4-часовым циклом. При этом операторы ЦОД, вероятно, найдут китайские решения более привлекательными как по качеству, так и по цене, но это достаточно рискованный выбор в политической плоскости. 
Источник изображения: CATL Наиболее перспективными в Jefferies называют китайских поставщиков CATL и Sungrow. Китайские системы значительно дешевле и совершеннее с точки зрения плотности хранения энергии и эффективности в целом, а последние данные свидетельствуют о росте китайского экспорта. Аналитики полагают, что Китай сохранит преимущество на рынке США и останется весьма конкурентоспособным. Так, в отчёте подчёркивается, что даже налоговая льгота в 40–50 % для произведённых в США систем всё равно не способна сделать китайские альтернативы неконкурентоспособными. Некоторые штаты и коммунальные службы в США, возможно, избегают китайских BESS из-за угроз кибербезопасности. Jefferies называет решения Tesla и Fluence Energy приемлемыми альтернативами. Наилучшие позиции из американских поставщиков для ИИ ЦОД занимает Tesla с решениями Megapack и Megablock. Ожидаемо, что одним из немногих кампусов ЦОД, объявивших о партнёрстве с Tesla, стала xAI (Colossus 1 и Colossus 2), рассчитывающая на ёмкость Megapack в 655 МВт∙ч. В отчёте прогнозируется рост рынка энергохранилищ в 2026 году на уровне менее 10 % из-за вступления в силу ограничений, касающихся иностранных юридических лиц, «вызывающих озабоченность» (FEOC). Кроме того, ситуация не улучшают и тарифные войны, которые на некоторое время привели к увеличению пошлин на импорт в США китайских аккумуляторов более чем на 150 %. Прогнозируется, что спрос на ЦОД на окажет значительного влияния на рынок BESS в 2026 году, поскольку развитие ИИ-технологий всё ещё находится на начальной стадии, но в 2027 году Jefferies ожидает существенного роста.
08.08.2025 [11:50], Руслан Авдеев
Tesla отказалась от развития ИИ-суперкомпьютеров DojoTesla распускает команду, стоявшую за суперкомпьютером Dojo, сообщает TechCrunch со ссылкой на Bloomberg. Как сообщают анонимные источники, глава проекта Питер Бэннон (Peter Bannon) покидает компанию, а оставшихся участников команды переведут на работу с другими вычислительными проектами Tesla. О закрытии Dojo стало известно после ухода из Tesla порядка 20 сотрудников, основавших собственный ИИ-стартап DensityAI, который займётся разработкой чипов, аппаратного и программного обеспечения для ИИ ЦОД, связанных с робототехникой, ИИ-агентами и автомобильными приложениями. DensityAI основана бывшим руководителем Dojo Ганешем Венкатарамананом (Ganesh Venkataramanan), причём в не самый удачный для Tesla момент, поскольку глава компании Илон Маск (Elon Musk) ранее настоял на том, чтобы акционеры рассматривали компанию как бизнес, занимающийся ИИ и робототехникой. Решение о закрытии Dojo стало значительным изменением стратегии. Ранее Маск утверждал, что суперкомпьютер станет краеугольным камнем для удовлетворения амбиций компании в сфере ИИ и основная цель — добиться полной автономии машин благодаря способности Dojo обрабатывать огромные массивы видеоданных. В 2023 году Morgan Stanley посчитал, что Dojo может поднять капитализацию Tesla на $500 млрд за счёт новых источников дохода — проектов роботакси и программных сервисов. 
Источник изображения: Tesla В 2024 году Маск сообщил, что команда Tesla, занятая искусственным интеллектом, «удвоит ставку» на Dojo перед презентацией роботакси. Тем не менее разговоры о Dojo уже в августе того же года постепенно сошли на нет, когда Маск начал продвигать ИИ-кластер Cortex (на базе ускорителей NVIDIA) при штаб-квартире Tesla в Остине (Техас). Проект Dojo включал в себя как суперкомпьютер, так и предполагал собственное производство ИИ-ускорителей. Ещё в 2021 году Tesla во время официального анонса Dojo представила чип D1, который должен был бы использоваться совместно с ускорителями NVIDIA для обеспечения работы Dojo. Также сообщалось, что ведутся работы над чипом D2, в котором будут устранены недостатки предшественника. По данным источников Bloomberg, теперь Tesla намерена сделать ставку преимущественно на NVIDIA, а также других сторонних партнёров вроде AMD, а Samsung будет выпускать чипы на заказ. В прошлом месяце с Samsung подписан контракт на выпуск инференс-чипов AI6, которые будут работать как с автопилотами Tesla, так и использоваться в роботах Optimus и дата-центрах. Ранее Маск намекнул, что в случае с Dojo 3 (D3) и инференс-чипом AI6, речь, возможно, будет идти о едином чипе. Недавно совет директоров Tesla предложил Маску пакет акций на $29 млрд, чтобы тот оставался в Tesla и продвигал ИИ-разработки компании, вместо того чтобы отвлекаться на другие бизнесы.
30.06.2025 [16:19], Руслан Авдеев
Б/у автоаккумуляторы запитали ИИ ЦОД с 2 тыс. ускорителейВ США заработал дата-центр на 2 тыс. ускорителей, оснащённый энергохранилищем с аккумуляторами, ранее применявшимися в электромобилях. Речь идёт о совместном проекте Redwood Materials и Crusoe — участнице проекта Stargate, курируемого компанией OpenAI, сообщает Bloomberg. Проект Crusoe и Redwood был реализован за четыре месяца. Спрос на «чистую» энергию растёт, подстёгиваемый ростом числа ИИ ЦОД. Благодаря аккумуляторным энергохранилищам можно запасать энергию, поступающую от магистральных электросетей и возобновляемых источников впрок с последующей стабильной подачей для питания серверов. Дата-центр на 2 тыс. ускорителей находится в кампусе Sparks в Неваде — именно там компания утилизирует аккумуляторы электромобилей в промышленных масштабах. По словам её представителя, новая система на 12 МВт использует сотни старых АКБ общей ёмкостью 62 МВт∙ч, а солнечные панели помогают напитать их энергией. По словам Redwood, это крупнейшая микросеть в Северной Америке, но компания уже нацелена на реализацию в 20–100 раз масштабнее. Redwood основана одним из соучредителей Tesla Джей Би Страубелом (JB Straubel) в 2017 году. Компания занимается выпуском материалов для аккумуляторов и переработкой отработавших АКБ. Это один из крупнейших переработчиков аккумуляторов в Северной Америке. Модули АКБ, характеристики которых уже не позволяют использовать их в электромобилях, всё ещё годятся для создания энергохранилищ, например, в сочетании с проектами ветряной и солнечной энергетики. Именно эта сфера применения станет основной для проектов нового подразделения — Redwood Energy. 
Источник изображения: Redwood Materials Компания сравнивает такие проекты с «домом престарелых для батарей». Такие АКБ вдвое дешевле новых Li-Ion систем, но обеспечивают почти ту же производительность. В прошлом году Redwood выручила $200 млн на переработке АКБ и теперь ожидает значительного увеличения денежных поступлений во II половине 2025 года по мере развёртывания новых энергохранилищ. Как сообщил представитель Crusoe (Crusoe Energy), одним из важных факторов при реализации энергетических проектов является скорость, поскольку многие компании, подавшие заявки на подключение к сетям, оказываются в очередях на 5–10 лет. ИИ-суперкомпьютер Colossus компании xAI, которая вместе с Tesla принадлежит Илону Маску (Elon Musk), оснащён аккумуляторами Tesla MegaPack. Подобные BESS компания теперь предлагает и другим ЦОД.
11.02.2025 [13:47], Руслан Авдеев
Tesla запустила суперкомпьютер Cortex с 50 тыс. ускорителей NVIDIA H100, а общие затраты компании на ИИ уже превысили $5 млрдКомпания Tesla завершила ввод в эксплуатацию ИИ-кластера из 50 тыс. ИИ-ускорителей NVIDIA H100 в IV квартале прошлого года. В презентации для акционеров отмечалось, что кластер Cortex заработал на принадлежащем Tesla объекте Gigafactory в Остине (Техас), сообщает Datacenter Dynamics. Информация впервые появилась в отчёте компании за IV квартал и 2024 финансовый год. Новый кластер не имеет отношения к суперкомпьютеру Dojo, предназначенному для технологий автономного вождения FSD, имеющего собственную архитектуру и оснащенного кастомными чипами D1. При этом в презентации, посвящённой отчёту, Dojo не упоминается вообще. Хотя компания не уточняет, когда именно в IV квартале началось развёртывание системы, на конференции по финансовым вопросам в октябре 2024 года представитель Tesla заявил, что компания находится «на пути к развёртыванию 50 тыс. ускорителей в Техасе к концу текущего месяца». По имеющимся данным, проект реализован с опозданием, поскольку Илон Маск уволил руководителя строительством ещё в апреле, а также приказал передать xAI 12 тыс. ускорителей H100, изначально предназначавшихся Tesla. 
Источник изображения: Tesla В презентации сообщается, что именно Cortex уже помог в создании «автопилота» FSD V13 (Supervised). Новая версия повысила безопасность и комфорт вождения благодаря увеличению объёма данных в 4,2 раза, повышению разрешения видеопотока, а также другим усовершенствованиям. Заодно компания сообщила о продолжении работ над программной и аппаратной частями робота Optimus, в т.ч. рук нового поколения и механизмов передвижения. Также осуществлялось обучение выполнению дополнительных задач перед началом пилотного производства в 2025 году. Что касается доходов компании в IV квартале, в конце января Илон Маск (Elon Musk) сообщил, что бизнес продолжает инвестировать в обучающую инфраструктуру за пределами штаб-квартиры в Техасе. В конце января сообщалось, что Tesla наращивает вычислительные мощности для обучения Optimus. По словам миллиардера, на обучение Optimus необходимо потратить, как минимум, в 10 раз больше ресурсов в сравнении с полноценным обучением систем автомобиля. Капитальные затраты Tesla в 2024 году составили $10 млрд, столько же компания намерена потратить в ближайшие два года, хотя большая часть затрат придётся на инфраструктуру для электромобилей. В отчёте о доходах за IV квартал упоминалось, что общие капитальные затраты компании, связанные с ИИ, включая инфраструктуру, превысили $5 млрд. |
|

