Материалы по тегу: intel
|
02.08.2019 [14:32], Геннадий Детинич
Intel хоронит шину Omni-PathДовольно неожиданно компания Intel отказалась от развития интерконнекта Omni-Path, которую она продвигала в серверных и HPC-платформах сначала для соединения узлов, в том числе для гиперконвергентных систем. Первое поколение шины Omni-Path с пропускной способностью до 100 Гбит/с на порт появилось несколько лет назад. Но ожидаемого второго поколения решений с пропускной способностью до 200 Гбит/с уже не будет. 
Ускорители Intel Xeon Phi с интегрированными контроллером и шиной Omni-Path Информацию о прекращении разработки и выпуска продукции Intel OmniPath Architecture 200 (OPA200) компания подтвердила, например, нашим коллегам с сайта HPCwire. Компания продолжит поддержку и поставку решений с шиной OPA100, но поставок продуктов с архитектурой OPA200 на рынок больше не будет. В принципе, сравнительно слабая поддержка шины Intel OmniPath со стороны клиентов рынка высокопроизводительных систем намекала на нечто подобное. Большей популярностью у строителей суперсистем и не только продолжает пользоваться InfiniBand и её новое HDR-воплощение с той же пропускной способностью до 200 Гбит/с. В свете ликвидации OPA200 становится понятно, почему Intel схватилась с NVIDIA за право поглощения компании Mellanox. Но не вышло: приз ушёл к NVIDIA. «Вообще, половина инсталляций в TOP500 использует Ethernet, но в основном 10/25/40 Гбит/с, и лишь совсем чуть-чуть может похвастаться 100 Гбит/с. InfiniBand установлен почти в 130 машинах, а Omni-Path есть чуть больше чем в 40. Остальное — проприетарные разработки». Что остаётся Intel? У лидера рынка микропроцессоров есть I/O-активы. Компания около 8 лет активно выстраивает направление для развития коммуникаций в ЦОД. За это время она поглотила разработчика коммутационных ASIC компанию Fulcrum Microsystems, подразделение по разработке адаптеров и коммутаторов InfiniBand компании QLogic и коммуникационное подразделение компании Cray. Относительно свежей покупкой Intel стала компания Barefoot Networks, разработчик решений для Ethernet-коммутаторов. Похоже, Intel решила вернуться к классике: InfiniBand (что менее вероятно) и Ethernet (что более вероятно), а о проприетарных шинах в виде той же Omni-Path решила забыть. В конце концов, Ethernet-подразделение компании славится своими продуктами. Новое поколения Intel Ethernet 800 Series способно заменить OPA100.
02.04.2019 [20:00], Геннадий Детинич
Intel представила процессоры Xeon D-1600: почта, телеграф, мостыВ 2015 году компания Intel представила процессоры Xeon семейства D. Первой появилась серия Xeon D-1500. Процессоры Xeon D получили архитектуру уровня Intel Core (Broadwell), став на ступеньку выше Xeon на архитектуре Atom. Целевое назначение Xeon D при этом не изменилось ― они всё так же были ориентированы на создание микросерверов, встраиваемых решений, систем для хранения данных малого и среднего уровней и сетевого оборудования. В 2018 году компания выпустила серию Xeon D-2100 на архитектуре Skylake. Тем самым в семейство Xeon D добавились решения повышенной производительности. Сегодня Intel представила третью серию Xeon D ― процессоры D-1600, которые возвращают нас к истокам семейства, главной целью которого был захват рынка производительной периферии с акцентом на плотность и сниженное потребление.  Процессоры Intel Xeon D-1600 получили меньшее число ядер, чем у их предшественников в лице Xeon D-1500. Диапазон числа физических ядер у моделей Xeon D-1600 сократился с 4–16 до 2–8. Максимальный тепловой пакет при этом остался тем же ― 65 Вт, тогда как минимальное значение TDP снизилось с 35 Вт до 27 Вт. Снижение числа ядер и сохранение максимального уровня TDP говорит о росте производительности в пересчёте на одно ядро. Во многом это достигается за счёт прироста как базовой частоты (в 1,2–1,5 раза), так и за счёт увеличения частоты при автоматическом разгоне до 3,2 ГГц, тогда как модели Xeon D-1500 в режиме турбо ограничивались частотой до 2,7 ГГц. Определённым образом Intel откатилась назад по шкале эволюции, понизив градус многоядерности в пользу наращивания однопоточной производительности. Собственно, этого требует позиционирование новой серии и активное развитие виртуализации сетевых функций (NFV). Для этого стала важнее скорость реакции сетевой платформы, что хорошо отрабатывается повышением тактовых частот.  Архитектурных изменений в моделях Xeon D-1600 не очень много, если они вообще есть (пока предполагаем, что архитектура осталась прежней ― Broadwell). Интегрированный контроллер памяти остался двухканальным с поддержкой модулей DDR4 с частотой до 2400 МГц суммарным объёмом до 128 Гбайт. Также поддерживается память DDR3L-1600. Уточним, процессоры Xeon D ― это однокристальная платформа, фактически SoC, что чрезвычайно удобно для тех областей, на которые нацелены эти решения.  Встроенные в процессоры интерфейсы представлены 24 линиями PCIe 3.0, 8 линиями PCIe 2.0, 6 портами SATA 6 Гбит/с, 4 портами USB 3.0, 4 портами USB 2.0 и 4 портами Ethernet 10 Гбит/с. Кстати, об Ethernet. На кристалл Xeon D-1600 интегрирован контроллер Intel серии Ethernet 700. На это намекают не только четыре интерфейса Ethernet 10GbE, но также поддержка технологии Intel QuickAssist.  У старшей серии Xeon D-2100 модели Xeon D-1600 взяли то, чего не было у моделей Xeon D-1500 ― это поддержка технологии Intel QuickAssist (QAT). Технология QAT поддержана в моделях Xeon D-1600 с индексом «N». Наличие QAT означает, что процессор несёт встроенный аппаратный ускоритель для работы с криптографией, компрессией и обработки сетевого трафика. Поддерживается целый ряд популярных алгоритмов, что существенно разгружает вычислительные ядра и даёт ощутимый прирост производительности. Например, обработка трафика TLS/IPSec плюс компрессия происходит со скоростью 30 Гбит/с плюс 30 000 операций в секунду, как и расшифровка ключами RSA с такой же производительностью. 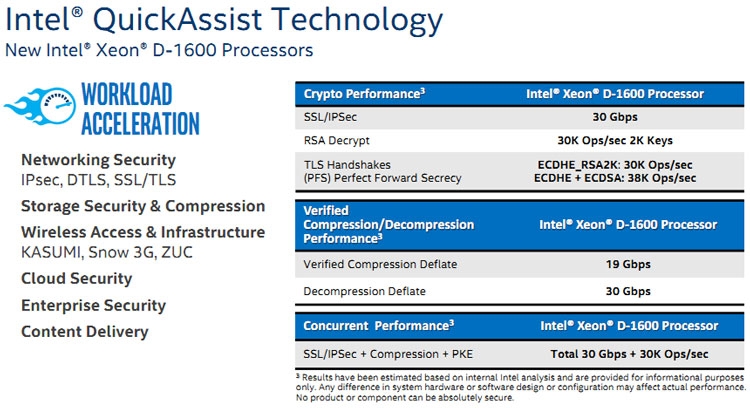 Поставки процессоров Xeon D-1600 компания Intel начнёт во втором квартале текущего года. Решения на основе новинок попадут на рынок к середине года или во второй его половине. По представлениям Intel, вычислительное и коммуникационное оборудование на базе Xeon D-1600 станет оптимальным выбором для развёртывания инфраструктуры для реализации и поддержки сотовой связи поколения 5G, а также для организации периферийных (пограничных) вычислений, когда обработка сырых данных (видео, сбор информации с датчиков, включая автомобильную электронику) происходит на месте и минимизирует пересылку в центры по обработке информации. Кроме того, они могут быть использованы в системах хранения данных. 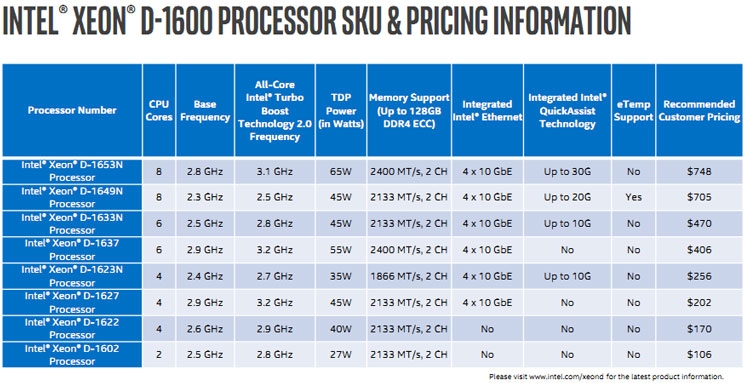 Процессоры Intel Xeon D 1600 представлены в рамках большого обновления решений для ЦОД, которое включает «взрослые» Intel Xeon Cascade Lake AP и SP с поддержкой памяти Optane в формате DDR4-модулей и новых инструкций для ИИ, модульные FPGA Agilex и сетевые контроллеры 100GbE Intel Ethernet 800. Подробности по ссылкам ниже.
31.01.2019 [20:33], Сергей Карасёв
Intel ставит крест на процессорах ItaniumКорпорация Intel опубликовала документ, по сути, знаменующий закат эпохи процессоров Itanium, на которые некогда возлагались большие надежды.  В обнародованном уведомлении речь идёт о грядущем прекращении производства чипов Itanium 9700, известных под кодовым именем Kittson. Массовые поставки этих изделий были начаты в 2017 году. Семейство включает четыре модели — Itanium 9720, Itanium 9740, Itanium 9750 и Itanium 9760 с четырьмя и восемью вычислительными ядрами. В документе Intel говорится, что приём заказов на все перечисленные процессоры прекратится через год — 30 января 2020-го. Поставки будут полностью свёрнуты 29 июля 2021 года. 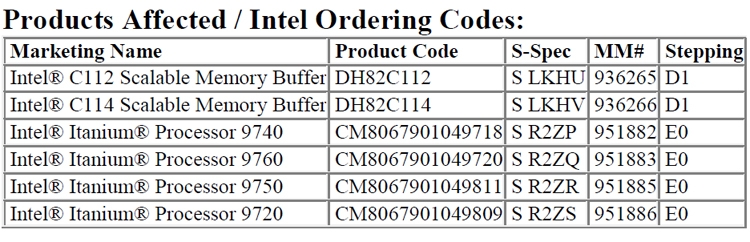 Таким образом, Intel ставит крест на решениях Itanium. Ещё в момент выхода Kittson говорилось, что эти изделия станут последними в семействе Itanium. Добавим, что впервые чипы Itanium дебютировали в мае 2001 года. Но продажи чипов оказались менее успешными, чем предполагалось. Основными причинами этому были проблемы с производительностью и малое количество оптимизированного программного обеспечения.
18.08.2016 [09:50], Валерий Косихин
IDF 2016: Intel анонсировала Knights Mill — новую архитектуру ускорителей Xeon Phi для задач глубинного обученияНа конференции Intel Developer Forum, которая в данный момент проходит в Сан-Франциско, была названа следующая версия архитектуры MIC (Many Integrated Cores), основанные на которой продукты пополнят семейство ускорителей параллельных вычислений Xeon Phi — Knights Mill. От Intel давно не поступало новостей касательно планов по развитию этой линейки устройств. На сегодняшний день Intel выпустила два поколения Xeon Phi — Knights Corner в 2013 году и Knights Landing в 2016-м. Согласно предыдущим заявлениям, третье поколение получит кодовое название Knights Hill, а соответствующие чипы будут производиться по технологической норме 10 нм. В кратком выступлении, которое Intel посвятила анонсу Knights Mill, не пояснили, как новинка соотносится с прошлыми планами. Возможно, что Knights Mill является промежуточной остановкой на пути к Knights Hill. По другой версии, новый продукт олицетворяет ответвление от основного пути развития, предназначенное для специфической ниши — глубинного обучения.  Глубинное обучение — одно из направлений задач машинного обучения, которое предполагает моделирование абстрактных понятий за счет построения многократно ветвящихся графов. На практике это применяется в программах компьютерного зрения, распознавания объектов, человеческой речи и т.п. Определяющий признак, который сделает Knights Mill подходящей платформой для глубинного обучения — то, что Intel довольно расплывчато обозначила термином «переменная точность». Скорее всего, речь идет о поддержке формата чисел с плавающей запятой FP16 (половинная точность) либо других форматов с еще меньшей разрядностью. FP16 является приоритетным форматом для задач глубинного обучения, поскольку они не требуют более высокой точности, а процессор достигает более высокой пропускной способности при условии, что FP16 поддерживается им «в железе». Поддержка половинной точности реализована в GPU последнего поколения от AMD и NVIDIA, и ускорители вычислений Tesla на базе архитектуры Pascal специально оптимизированы для высокой скорости в работе с FP16. Появление чипов Knights Mill упрочит позиции Intel в конкуренции с NVIDIA на этом рынке. При этом разработчики указывают на ряд преимуществ архитектуры MIC по сравнению с графическими процессорами. Xeon Phi, начиная с поколения Kings Landing, существуют в сокетном форм-факторе, который позволяет загружать ОС непосредственно с MIC без необходимости в отдельном CPU традиционной архитектуры. Также, наряду с массивом высокоскоростной набортной памяти MCDRAM (разновидность HBM) Knights Landing, как и его потомок Knights Mill, может напрямую адресовать внешние модули DDR4 SDRAM. NVIDIA Tesla не может похвастаться такими функциями.  Массовое производство чипов Knights Mill намечено на 2017 г. Судя по графику на слайде Intel (который, впрочем, вряд ли отражает какие-либо твердые числа), Knights Mill удвоит показатели быстродействия, характерные для предыдущего поколения Xeon Phi. Это, в свою очередь, сигнализирует о применении техпроцесса 10 нм, и в таком случае не исключено, что Knights Mill — это просто новое название для ранее анонсированной архитектуры Knights Hill.
20.06.2016 [19:30], Илья Гавриченков
Intel представила процессоры Xeon Phi Knights LandingМногоядерные ускорители вычислений Intel Xeon Phi продолжают своё развитие. Об их очередном поколении с кодовым именем Knights Landing разработчик рассказывает уже почти три года, а с конца прошлого года даже поставляет образцы систем с ними своим избранным партнёрам. Однако до официального анонса дело дошло только сейчас. В рамках проходящей в эти дни в Германии конференции ISC High Performance 2016 компания Intel официально объявила о выходе принципиально новых Xeon Phi на базе дизайна Knights Landing, ключевое свойство которых заключается в том, что теперь это — не сопроцессоры, а полноценные x86-процессоры, способные взять на себя роль центрального компонента системы. Иными словами, новые Xeon Phi могут работать полностью самостоятельно, не нуждаясь ни в каком дополнительном управляющем CPU. И это очень важное улучшение, так как проведённое коренное изменение архитектуры ликвидирует узкое место — шину PCI Express, которую используют для передачи данных предшествующие и конкурирующие ускорители вычислений, например, базирующиеся на GPU. 
Источник изображений: Intel Knights Landing воплощают собой уже третье поколение многоядерной x86-архитектуры Intel. Предыдущее поколение, известное под кодовым именем Knights Corner, базировалось на Pentium-подобных ядрах P54C. Новая же версия ускорителей переехала на модифицированную 14-нм микроархитектуру Airmont, известную по процессорам Atom. Однако в Knights Landing ядра Airmont попарно объединены в модули, которые включают также мегабайтный L2-кеш и четыре блока VPU (Vector Processing Unit), отвечающих за поддержку векторных инструкций AVX-512. Всего в новых процессорах Xeon Phi содержится до 36 таких модулей, то есть, общее число ядер в ускорителе может достигать 72. При этом каждое ядро дополнительно поддерживает технологию Hyper-Threading и способно выполнять до четырёх потоков одновременно, что наделяет Xeon Phi впечатляющим арсеналом средств для работы с параллельными вычислениями. Учитывая, что в Knights Landing производительность на поток по сравнению с Knights Corner выросла примерно втрое только за счёт смены микроархитектуры, обновление ускорителей Xeon Phi дало им возможность дотянуться до планки в 3 Тфлопс. Процессоры Knights Landing снабжены также интегрированной памятью MCDRAM с пропускной способностью до 500 Гбайт/с и объёмом 16 Гбайт, которая может взаимодействовать с системной шестиканальной DDR4-памятью по нескольким принципиально различным алгоритмам. Упоминания заслуживает и реализация в новых Xeon Phi отдельного двухпортового 100 Гбит/с-контроллера Omni-Path, который предполагается использовать для высокоскоростного объединения узлов, основанных на Knights Landing, в вычислительные кластеры. Объявленная сегодня линейка процессоров Xeon Phi поколения Knights Landing включает четыре модели с числом ядер от 64 до 72 и частотой от 1,3 до 1,5 ГГц.  Стоит отметить, что в настоящее время для заказчиков доступны лишь три младшие модели: Xeon Phi 7250, 7230 и 7210. Самая же мощная 72-ядерная версия ускорителя, Xeon Phi 7290, обещана к сентябрю. Также пока Intel не поставляет варианты с интегрированным контроллером Omni-Path, который по плану появится в перечисленных моделях в октябре этого года. Высокая производительность процессоров Xeon Phi, простая масштабируемость систем на их основе, а также полная совместимость с x86-экосистемой и знакомым всем средствами разработки, делает новинки отличным вариантом для использования в массе областей, где требуются параллельные высокопроизводительного вычисления. И особенно Intel подчёркивает применимость построенных на Xeon Phi кластеров в системах машинного обучения и искусственного интеллекта, то есть тех областях, где в последнее время высокую активность развила NVIDIA, реализующая свои ускорители семейства Tesla. В подтверждение лидирующих характеристик Knights Landing, компания Intel приводит информацию о кратном превосходстве системы на базе Xeon Phi 7250 над системой, в которой используется конкурирующий ускоритель вычислений NVIDIA Tesla K80 и пара центральных процессоров Xeon E5-2697 v4.  При этом, Intel говорит не только о достигающем пятикратного размера преимуществе Xeon Phi в производительности. Согласно информации компании, конфигурация с процессором Xeon Phi 7250 оказывается в восемь раз экономичнее и в девять — дешевле. Учитывая всё сказанное, Intel ожидает, что внедрение новых Xeon Phi пойдёт очень быстрыми темпами. До конца года производитель намеревается продать более ста тысяч процессоров, а готовые системы на базе Knights Landing будут поставлять более 50 компаний, включая Dell, Fujitsu, Hitachi, HP, Inspur, Lenovo, NEC, Oracle, Quanta, SGI, Supermicro, Colfax и другие. Кстати, в этом списке место нашлось и для российского интегратора — группы компаний РСК — которая собирается поставлять высокоплотные кластерные решения на базе Xeon Phi, оснащённые системами жидкостного охлаждения. |
|
|||||||||||||








