Материалы по тегу: cxl
|
23.11.2024 [12:38], Сергей Карасёв
Стартап Enfabrica выпустил чип ACF SuperNIC для ИИ-кластеров на базе GPUКомпания Enfabrica, занимающаяся разработкой инфраструктурных решений в сфере ИИ, объявила о доступности чипа Accelerated Compute Fabric (ACF) SuperNIC, предназначенного для построения высокоскоростных сетей в рамках кластеров ИИ на основе GPU. Кроме того, стартап провёл очередной раунд финансирования. Напомним, Enfabrica предлагает CXL-платформу ACF на базе ASIC собственной разработки, которая позволяет напрямую подключать друг к другу любую комбинацию GPU, CPU, DDR5 CXL и SSD, а также предоставляет 800GbE-интерконнект. Утверждается, что ACF SuperNIC может обеспечить улучшенную масштабируемость и производительность с более низкой совокупной стоимостью владения для распределённых рабочих нагрузок ИИ по сравнению с другими решениями, доступными на рынке. Изделие ACF SuperNIC (ACF-S) позволяет использовать от четырёх до восьми самых современных ускорителей в расчёте на серверную систему. Чип обеспечивает поддержку 800GbE, 400GbE и 100GbE, 32 сетевых портов и 160 линий PCIe. Благодаря этому становится возможным формирование ИИ-кластеров, насчитывающих более 500 тыс. GPU. 
Источник изображения: Enfabrica Программный стек ACF-S поддерживает стандартные коммуникационные и сетевые операции RDMA через набор библиотек, совместимых с существующими интерфейсами. Фирменная технология Resilient Message Multipathing (RMM) повышает отказоустойчивость кластера ИИ и удобство обслуживания. RMM устраняет простои из-за сбоев и отказов сетевых соединений, повышая эффективность. Функция Collective Memory Zoning обеспечивает снижение задержек. Поставки чипов ACF SuperNIC начнутся в I квартале 2025 года. Что касается нового раунда финансирования, то по программе Series C привлечено $115 млн. Раунд возглавила фирма Spark Capital с участием новых инвесторов — Maverick Silicon и VentureTech Alliance. Кроме того, средства предоставили существующие инвесторы в лице Atreides Management, Sutter Hill Ventures, Alumni Ventures, IAG Capital и Liberty Global Ventures.
05.09.2024 [11:21], Сергей Карасёв
Innodisk представила CXL-модули памяти объёмом 64 Гбайт для ИИ-серверовКомпания Innodisk анонсировала модуль памяти CXL (Compute Express Link), разработанный с прицелом на системы ИИ и облачные дата-центры. Массовые поставки изделия планируется организовать в I квартале 2025 года. Спрос на ИИ-серверы быстро растет. Согласно прогнозам Trendforce, в 2024 году такие системы займут примерно 65 % глобального рынка серверов (в деньгах). По словам Innodisk, сейчас ИИ-системам требуется не менее 1,2 Тбайт оперативной памяти для эффективной работы. Традиционные изделия DDR не всегда способны удовлетворить предъявляемые требования, что приводит к таким проблемам, как недоиспользование ресурсов CPU и увеличение задержек, говорит компания. Модули CXL призваны устранить подобные ограничения. 
Источник изображения: Innodisk Напомним, CXL — это высокоскоростной интерконнект, обеспечивающий взаимодействие хост-процессора с акселераторами, буферами памяти, устройствами ввода/вывода и пр. Решение Innodisk использует интерфейс PCIe 5.0 x8 и имеет ёмкость 64 Гбайт. Модуль обеспечивает пропускную способность до 32 Гбайт/с. Говорится о совместимости с CXL 1.1/2.0. Устройство выполнено в форм-факторе E3.S 2T и оснащено коннектором EDSFF 2C. Диапазон рабочих температур простирается от 0 до +70 °C. Отмечается, что в случае установки четырёх модулей Innodisk CXL на 64 Гбайт каждый в сервер, который несёт на борту восемь DIMM по 128 Гбайт, общий объём памяти может быть увеличен на четверть, а общая пропускная способность — на 40 %. При этом CXL обеспечивает пулинг памяти, что позволяет оптимизировать совместное использование ресурсов и повысить общую эффективность системы.
13.08.2024 [11:19], Сергей Карасёв
MSI представила сервер S2301 с поддержкой CXL на базе AMD EPYC TurinКомпания MSI в ходе выставки Future of Memory and Storage 2024 (FMS) анонсировала сервер S2301, предназначенный для работы с резидентными базами данных, НРС-приложениями, платформами для автоматизации проектирования электроники (EDA) и пр. Сервер поддерживает стандарт CXL 2.0 на основе интерфейса PCIe. Технология обеспечивает высокоскоростную передачу данных с малой задержкой между хост-процессором и такими устройствами, как серверные ускорители, буферы памяти и интеллектуальные IO-блоки. На основе CXL 2.0 функционирует высокопроизводительный механизм доступа к памяти, который позволяет модулям расширения напрямую взаимодействовать с иерархией памяти CPU. При этом дополнительные блоки памяти работают так, как если бы они были частью собственной памяти системы. Подключив к серверу модули расширения CXL, можно с высокой эффективностью масштабировать ресурсы для обработки сложных задач. 
Источник изображения: MSI Сервер MSI S2301 поддерживает установку двух процессоров AMD EPYC поколения Turin. Доступны 24 слота для модулей ОЗУ. Возможно применение CXL-модулей в форм-факторе E3.S 2T (PCIe 5.0 x8). Такие решения, в частности, в августе 2023 года представила компания Micron Technology. Устройства имеют вместимость 128 и 256 Гбайт. Кроме того, память DRAM с поддержкой CXL 2.0 предлагает Samsung. Во фронтальной части нового сервера располагаются отсеки для SFF-модулей. Говорится об использовании софта Memory Machine X разработки MemVerge, который оптимизирует затраты и помогает улучшить производительность ИИ-приложений и других ресурсоёмких рабочих нагрузок путём интеллектуального управления памятью.
03.07.2024 [23:49], Сергей Карасёв
Panmnesia расширит память GPU с помощью DRAM или даже SSDЮжнокорейский стартап Panmnesia сообщил о разработке специализированного CXL-решения, которое позволяет расширять встроенную память ускорителей на базе GPU путём подключения внешних блоков DRAM или даже SSD. Отмечается, что современным приложениям ИИ и НРС требуется значительный объём быстрой памяти, но возможности ускорителей в этом плане ограничены. Сложность расширения памяти актуальных ускорителей заключается в том, что в таких изделиях отсутствуют логическая структура CXL и компоненты, поддерживающие DRAM и/или SSD. Кроме того, подсистемы кеша и памяти GPU не распознают никаких расширений. В лучшем случае предлагается механизм унифицированной виртуальной памяти (UVM) для совместного доступа к содержимому памяти и CPU, и GPU. Однако этот механизм довольно медленный. 
Источник изображений: Panmnesia Panmnesia обошла существующие ограничения путём создания собственного root-комплекса, совместимого со стандартом CXL 3.1 и предоставляющего несколько root-портов. Он и обеспечивает поддержку внешней памяти через PCIe. При этом задействован особый декодер HDM (Host-managed Device Memory), отвечающий за работу с адресными пространствами. Это сложное решение в каком-то смысле «обманывает» подсистему памяти ускорителя, заставляя ее рассматривать внешнюю PCIe-память как доступную напрямую. 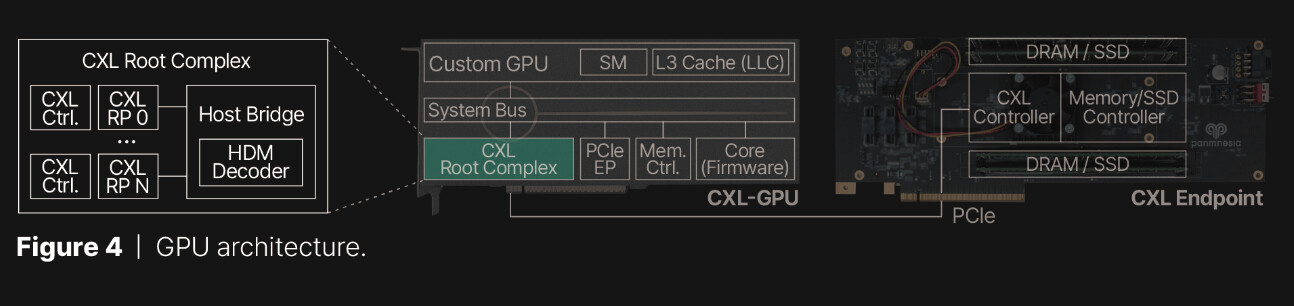 Прототип, основанный на кастомизированном GPU, в ходе тестов продемонстрировало задержки менее 100 нс при передаче данных в обоих направлениях. При этом решение Panmnesia предоставляет более гранулярный доступ к памяти в сравнении с UVM. Быстродействие CXL-системы Panmnesia оказалось в 3,22 раза выше в пересчёте на IPC по сравнению с UVM.
08.03.2024 [00:03], Алексей Степин
Broadcom готовит чипы для PCIe 6.0/7.0 с поддержкой AMD Infinity FabricОдним из столпов, на которых зиждется господство NVIDIA в мире ускорителей, является NVLink — высокоскоростной интерконнект, позволяющий чипам общаться напрямую не только в составе одного узла, но и за его пределами. AMD пытается ответить на это продвижением XGMI/Infinity Fabric, и в предварительном обзоре Instinct MI300 были затронуты вопросы топологии серверов в исполнении «красных». Ещё тогда, в момент анонса MI300, компания Broadcom объявила о поддержке данного интерконнекта в будущих поколениях своих PCIe-коммутаторов, а сейчас ресурс ServeTheHome поделился новыми подробностями. XGMI действительно станет коммутируемым, что упростит масштабирование систем на базе ускорителей AMD Instinct. Интерконнект получил официально название AFL (Accelerated Fabric Link). В основе AFL по-прежнему будет лежать PCI Express, в данном случае речь идёт уже о PCI Express 7.0. Поддержка данной технологии дебютирует в PCIe-коммутаторах Broadcom Atlas 4. В дополнение к ним будут выпущены и новые ретаймеры Vantage 7, которые также получат поддержку CXL 4.0. 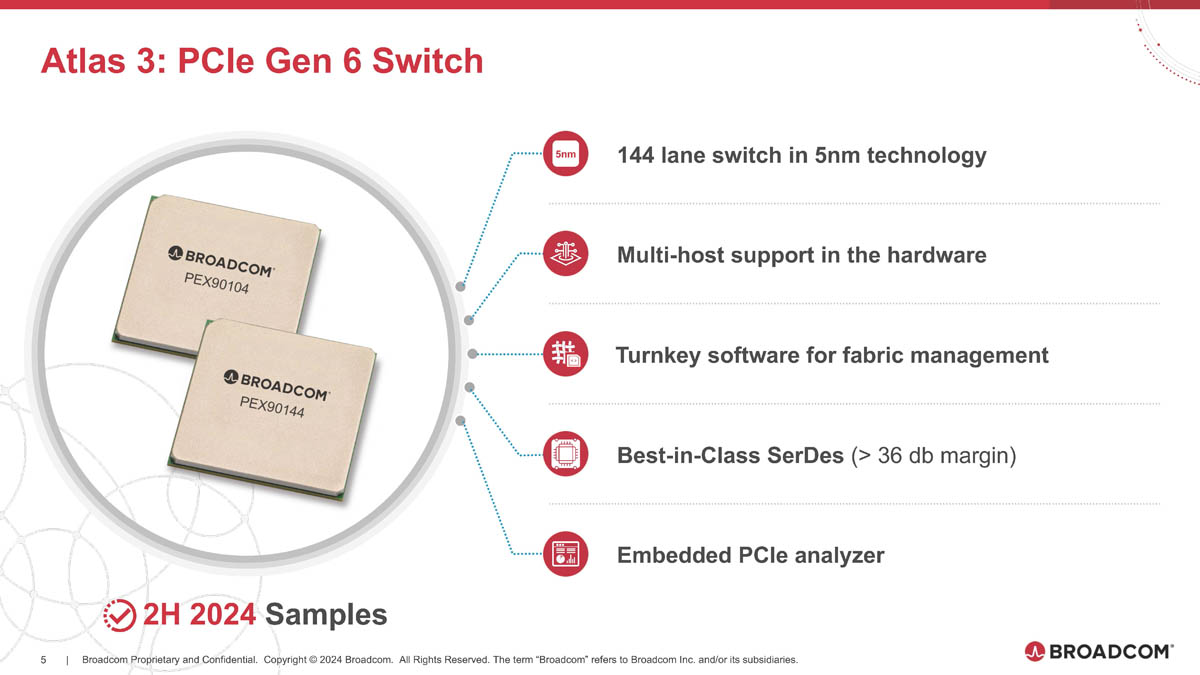
Источник здесь и далее: Broadcom via ServeTheHome Но перед этим Broadcom начнёт поставки образцов чипов-коммутаторов Atlas 3 со 144 линиями PCIe 6.0 во II половине 2024 года, а серверы с такими коммутаторами появятся в 2025 году. Поддержка CXL здесь будет расширена до версии 3.1.  Что касается ретаймеров, то здесь Broadcom уже нанесла ответный удар Astera Labs, анонсировав чипы серий Vantage 5 и Vantage 6 для экосистем PCI Express 5.0 и PCI Express 6.0 соответственно. Они будут выпускаться в вариантах с 8 и 16 линиями с опцией бифуркации и поддержкой CXL 2.0 и 3.1. Broadcom заявляет о более низком энергопотреблении, достигнутом за счёт применения 5-нм техпроцесса, лучших в индустрии блоках SerDes и расширенных средствах диагностики, интегрированных в новые ретаймеры. 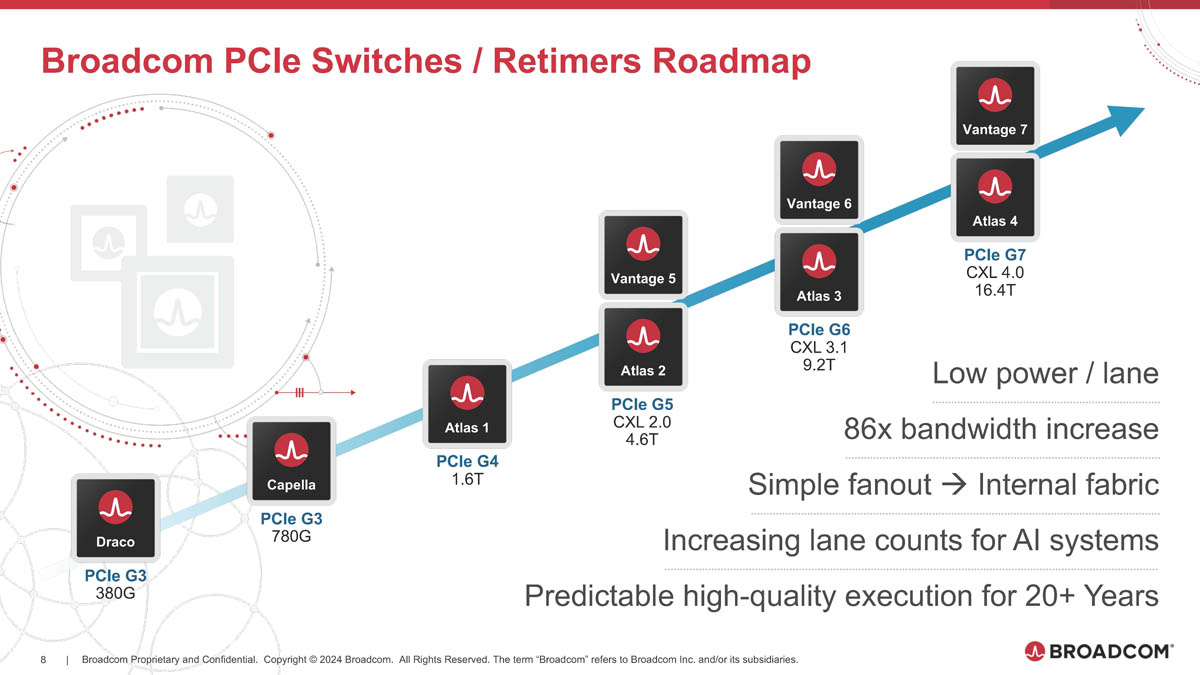 Экономичность здесь играет важную роль: хотя даже 7-нм ретаймер потребляет немного, таких микросхем в составе каждого GPU-сервера несколько, что при дальнейшем масштабировании выливается весьма серьёзные цифры. К тому же меньшая нагрузка ляжет и на систему охлаждения, ведь если CPU и ускорители могут обслуживаться СЖО, то остальные компоненты в таких серверах по-прежнему охлаждаются обычными вентиляторами.  Что касается SerDes-блоков, то они позволят на 40 % удлинить соединения при сохранении стабильной работы. Ну а наличие продвинутого диагностического программного обеспечения с расширенными возможностями упростит разработку, отладку и ремонт систем нового поколения.  Ретаймеры Vantage 5 будут использоваться в комплекте с коммутаторами Atlas 2 в решениях Broadcom уже сегодня, они обеспечат поддержку CXL 2.0, ну а системы с Vantage 6 и поддержкой CXL 3.1, как уже упоминалось, должны увидеть свет в следующем году.  Astera Labs есть о чём беспокоиться: если на данный момент её ретаймерам почти нет альтернативы, то уже в ближайшем будущем ситуация может коренным образом измениться, поскольку Broadcom явно осознала всю важность этого компонента в экосистеме PCI Express и оценила солидный объём потенциальной клиентской базы.
14.08.2023 [17:37], Алексей Степин
CXL-пул Panmnesia втрое быстрее RDMA-систем и может предложить 6 Тбайт RAMНа конференции Flash Memory Summit южнокорейская компания Panmnesia продемонстрировала свою версию CXL-пула DRAM объёмом 6 Тбайт на базе программно-аппаратного стека собственной разработки. Новинка продемонстрировала более чем троекратное превосходство над системой, построенной на базе технологии RDMA, в нагрузках, связанной с работой рекомендательной ИИ-системы Meta✴. Panmnesia разработана в сотрудничестве с Корейским инститом передовых технологий (KAIST). О более раннем варианте разработок KAIST в этой области мы рассказывали в 2022 году. Коммерческий вариант комплекса поддерживает CXL 3.0 и состоит из CXL-процессора, коммутатора и модулей расширения памяти. Все модули выполнены в форм-факторе, чрезвычайно напоминающем FHFL-карты. Модули устанавливаются в универсальное шасси, при этом их можно произвольно комбинировать. 
Источник изображений здесь и далее: Panmnesia Демо-платформа содержала два процессорных модуля, три модуля коммутации и шесть 1-Тбайт модулей памяти. Модули памяти построены на базе обыкновенных DIMM-планок и поддерживают их замену и расширение. Реализован не только режима CXL.mem, но и CXL.cache и CXL.io. При этом компания предлагает не только готовые IP-решения, но и их кастомизацию под конкретного заказчика, что поможет оптимизировать цикл создания продукта и снизить общую стоимость разработки и валидации. 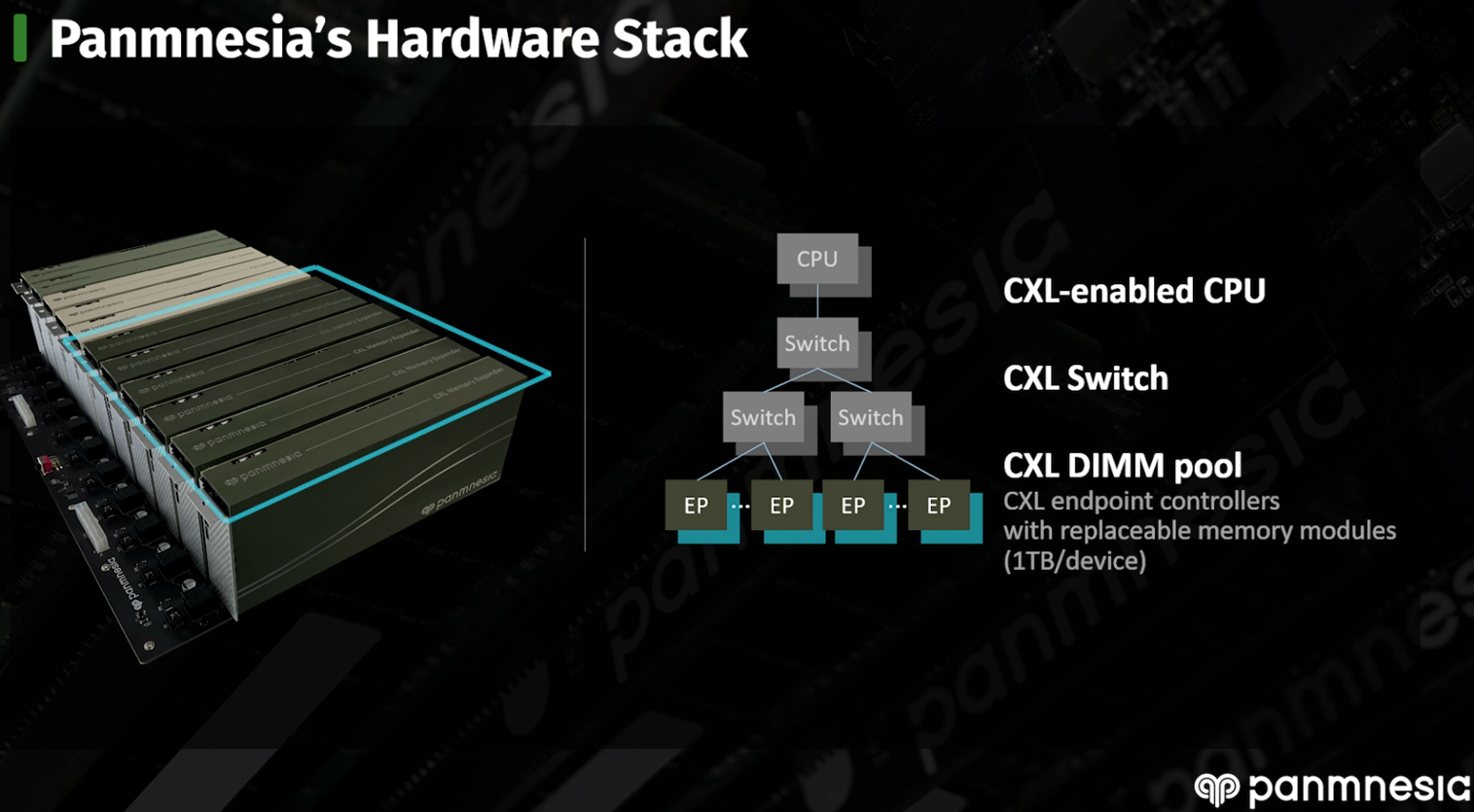 Фирменное ПО базируется на Linux и содержит необходимые драйверы, а также специализированную виртуальную машину, с помощью которой пространство памяти представляется в виде безпроцессорного NUMA-узла. Поверх этих компонентов функционирует пользовательская часть, отвечающая за эффективное размещение и предвыборку (prefetching) данных. По ряду параметров Panmnesia можно назвать лидером в области CXL-решений. В частности, по объёму DRAM она уже обгоняет совместное решение Samsung, MemVerge, H3 и XConn, а использование DIMM-модулей только придаёт ей гибкости. Развитая программная часть, как утверждается, упрощает и удешевляет интеграцию в существующую инфраструктуру ЦОД. Спектр применения, как и у всех систем CXL-пулинга, крайне широкий и включает в себя не только ИИ-сценарии, но и любые задачи, требующие большого объёма оперативной памяти.
10.08.2023 [00:10], Алексей Степин
XConn Technologies представила гибридный коммутатор CXL 2.0/PCIe 5.0XConn Technologies представила первый, по её словам, в индустрии гибридный чип-коммутатор CXL 2.0/PCIe 5.0 XC50256, получивший кодовое название Apollo. Утверждается, что он обеспечивает самую низкую латентность port-to-port, а также самое низкое энергопотребление в отрасли. Коммутатор способен работать с 256 линиями интерфейса и разработан с учётом потребностей, характерных для мира ИИ и машинного обучения, а также HPC-сегмента. Чип Apollo совместим с существующей инфраструктурой CXL 1.1, но поддерживает и режим 2.0, включая актуальные режимы CXL.mem или CXL.cache. 
Источник изображений здесь и далее: XConn Technologies Но наиболее интересной особенностью Apollo является возможность работы нового коммутатора в гибридном режиме — он способен одновременно обслуживать CXL и PCI Express, что в ряде случаев позволит избежать использования дополнительных коммутаторов под каждый стандарт, а значит, и снизить стоимость и сложность разработки конечной системы. 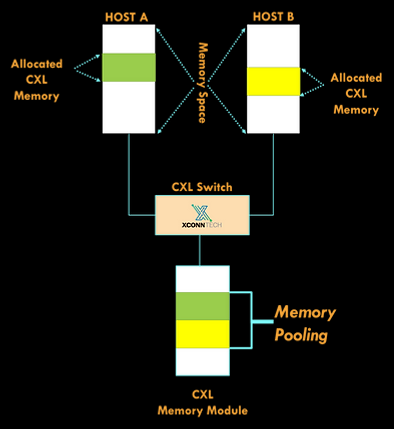
Новый коммутатор поддерживает подключение нескольких хостов к единому CXL-пулу памяти Также компания анонсировала другой коммутатор, XC51256. Он также работает с 256 линиями, но поддерживает только PCI Express 5.0. Тем не менее, это самый высокоплотный PCIe-коммутатор на сегодня, поскольку большинство решений конкурентов обеспечивает в лучшем случае вдвое меньше линий PCI Express, утверждает XConn. ТXC51256 идеален для построения систем класса JBOA (Just-a-Bunch-Of-Accelerators). В настоящее время образцы Apollo XC50256 и XC51256 уже доступны для заказчиков.
09.08.2023 [18:28], Алексей Степин
Lightelligence представила оптический CXL-интерконнект PhotowaveКомпания Lightelligence, специализирующаяся в области фотоники и оптических вычислений, анонсировала любопытную новинку — систему оптического интерконнекта для ЦОД нового поколения. Решение под названием Photowave реализовано на базе стандарта CXL и призвано упростить и сделать более надёжными системы с композитной инфраструктурой, заменив традиционные медные кабели оптоволокном. Решение Photowave — дальнейшее развитие парадигмы Lightelligence, уже представившей ранее первый оптический ускоритель Hummingbird для ИИ-систем. Сердцем Photowave является оптический трансивер oNET на базе фирменных технологий компании. Согласно заявлениям Lightelligence, уровень задержки составляет менее 20 нс на уровне адаптера, кабель добавляет к этой цифре менее 1 нс. 
Источник изображений здесь и далее: Lightelligence Серия Photowave включает в себя трансиверы в разных форм-факторах — как в виде традиционной платы расширения PCI Express, так и в виде карты OCP 3.0 SFF. Платы трансиверов поддерживают CXL 2.0/PCIe 5.0 с числом линий от 2 до 16. Пропускная способность каждой линии составляет 32 Гбит/с.  Как уже упоминалось, главная задача Photowave — создание эффективных и надёжных композитных инфраструктур в ЦОД нового поколения, где благодаря всесторонней поддержки CXL будет достигнута высокая степень дезагрегации вычислительных ресурсов, а также памяти и хранилищ.
24.03.2023 [20:28], Алексей Степин
Kioxia анонсировала серверные SSD на базе XL-FLASH второго поколенияПо мере внедрения новых версий PCI Express растут и линейные скорости SSD. Не столь давно 3-4 Гбайт/с было рекордно высоким показателем, но разработчики уже штурмуют вершины за пределами 10 Гбайт/с. Компания Kioxia, крупный производитель флеш-памяти и устройств на её основе, объявила на конференции 2023 China Flash Market о новом поколении серверных накопителей, способных читать данные со скоростью 13,5 Гбайт/с. Новые высокоскоростные SSD будут построены на базе технологии XL-FLASH второго поколения. Первое поколение этих чипов компания (тогда Toshiba) представила ещё в 2019 году. В основе лежат наработки по BiCS 3D в однобитовом варианте, что позволяет устройствам на базе этой памяти занимать нишу Storage Class Memory (SCM) и служить заменой ушедшей с рынка технологии Intel Optane. 
Источник здесь и далее: Twitter@9550pro Как уже сообщалось ранее, XL-FLASH второго поколения использует двухбитовый режим MLC, но в любом случае новые SSD Kioxia в полной мере раскроют потенциал PCI Express 5.0. Они не только смогут читать данные на скорости 13,5 Гбайт/с и записывать их на скорости 9,7 Гбайт/с, но и обеспечат высокую производительность на случайных операциях: до 3 млн IOPS при чтении и 1,06 млн IOPS при записи. Время отклика для операций чтения заявлено на уровне 27 мкс, против 29 мкс у XL-FLASH первого поколения.  Kioxia полагает, что PCI Express 5.0 и CXL 1.x станут стандартами для серверных флеш-платформ класса SCM надолго — господство этих интерфейсов продлится минимум до конца 2025 года, лишь в 2026 году следует ожидать появления первых решений с поддержкой PCI Express 6.0. Активный переход на более новую версию CXL ожидается в течение 2025 года. Пока неизвестно, как планирует ответить на активность Kioxia другой крупный производитель флеш-памяти, Samsung Electronics, которая также располагает высокопроизводительной разновидностью NAND под названием Z-NAND.
09.08.2022 [18:09], Игорь Осколков
Китайская компания Biren представила ИИ-ускоритель BR100, который обгоняет по производительности NVIDIA A100Шанхайская компания Biren Technology, основанная в 2019 году и уже получившая более $280 млн инвестиций, официально представила серию ускорителей BR100, которые способные потягаться с актуальными решениями от западных IT-гигантов. Утверждается, что это первое изделие подобного класса, созданное в Поднебесной. Компания уже подписала соглашение о сотрудничестве с ведущим производителем серверов Inspur. Новинка содержит 77 млрд транзисторов, использует чиплетную компоновку, изготавливается по 7-нм техпроцессу на TSMC и имеет 2.5D-упаковку CoWoS. Для сравнения — грядущие NVIDIA H100 имеют такую же упаковку, но включают 80 млрд транзисторов и изготавливаются по более современному техпроцессу TSMC N4. При этом BR100 примерно вдвое производительнее 7-нм NVIDIA A100 и примерно вдвое же медленнее H100. Впрочем, Biren приводит только данные о вычислениях пониженной точности, да и в целом говорит о том, что новинка предназначена в первую очередь для ИИ-нагрузок. 
Изображения: Biren В серию входят два решения: BR100 и BR104. Оба варианта оснащаются интерфейсом PCIe 5.0 x16 с поддержкой CXL. Первый вариант имеет OAM-исполнение с TDP на уровне 550 Вт. Он позволяет объединить до восьми ускорителей на UBB-плате, связав их между собой фирменным интерконнектом BLink (512 Гбайт/с) по схеме каждый-с-каждым. BR100 полагается 300 Мбайт кеш-памяти и 64 Гбайт HBM2e (4096 бит, 1,64 Тбайт/c). 
BR100 Также он способен одновременно кодировать до 64 потоков FullHD@30 HEVC/H.264, а декодировать — до 512. Кроме того, доступно создание до 8 аппаратно изолированных инстансов Secure Virtual Instance (SVI) по аналогии с NVIDIA MIG. Заявленная производительность составляет 256 Тфлопс для FP32-вычислений, 512 Тфлопс для TF32+ (по-видимому, подразумевается некая совместимость с фирменным форматом NVIDIA TF32), 1024 Тфлопс для BF16 и, наконец, 2048 Топс для INT8. 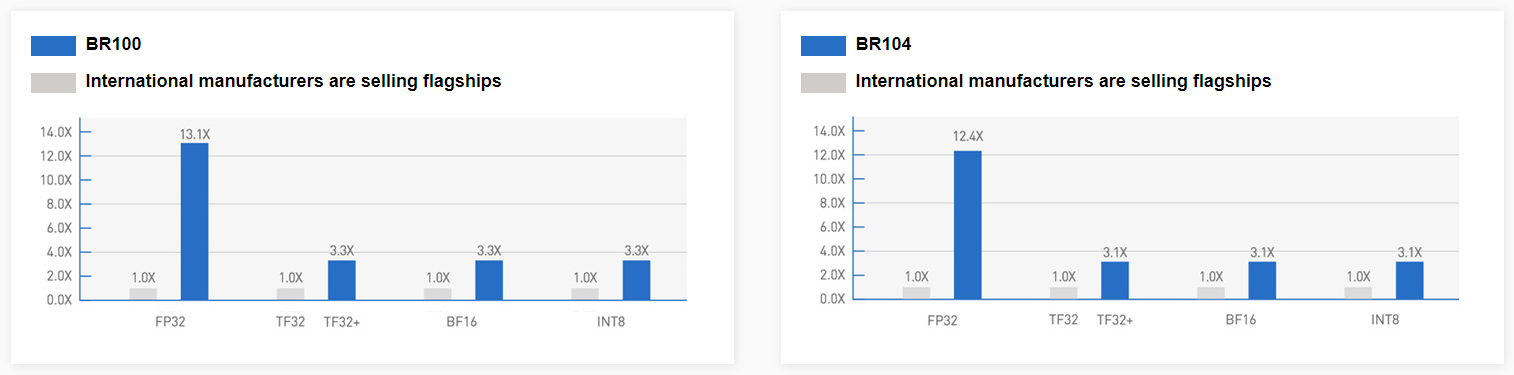 
BR104 BR104 представляет более традиционную FHFL-карту с TDP на уровне 300 Вт. По производительности она ровно вдвое медленнее старшей версии BR100, способна обрабатывать вдвое меньшее количество видеопотоков и предлагает только до 4 SVI-инстансов. BR104 имеет 150 Мбайт кеш-памяти, 32 Гбайт HBM2e (2048 бит, 819 Гбайт/c) и три 192-Гбайт/с интерфейса BLink. Для работы с ускорителями компания предлагает собственную программную платформу BIRENSUPA, совместимую с популярными фреймворками PyTorch, TensorFlow и PaddlePaddle. |
|

