Материалы по тегу: облако
|
03.06.2026 [13:49], Владимир Мироненко
Новые Arm-инстансы Azure Cobalt 200 оптимизированы для ИИ-агентов и в полтора раза быстрее ВМ Azure Cobalt 100Microsoft объявила о доступности предварительной версии Arm-инстансов Azure Cobalt 200, разработанных с нуля для масштабируемых, облачно-ориентированных и основанных на Linux ИИ-нагрузок с использованием агентов и обеспечивающих до 50 % более высокую производительность по сравнению с Cobalt 100. Компания сообщила, Cobalt 200 объединил её новейшие разработки — от «кремния» до серверов и сервисов — в области безопасности, сетей, хранения данных и разгрузки, что позволяет превосходить традиционные вычислительные решения на базе Arm. Совместная оптимизация аппаратного и программного обеспечения позволяет расширять возможности масштабирования, повышать безопасность и снижать затраты при использовании ИИ-инференса, конвейеров передачи данных, а также веб-сервисов и API, обеспечивающих работу современных сервисов. Microsoft отметила, что агенты отличаются от традиционных рабочих нагрузок тем, что они рассуждают, принимают последовательные решения и непрерывно работают в больших масштабах, что требует принципиально иного профиля вычислений. Cobalt 200 создан именно для этой среды и обеспечивает 50-% прирост производительности для таких нагрузок, делая агентов более быстрыми, функциональными и экономически эффективными в масштабах предприятия. 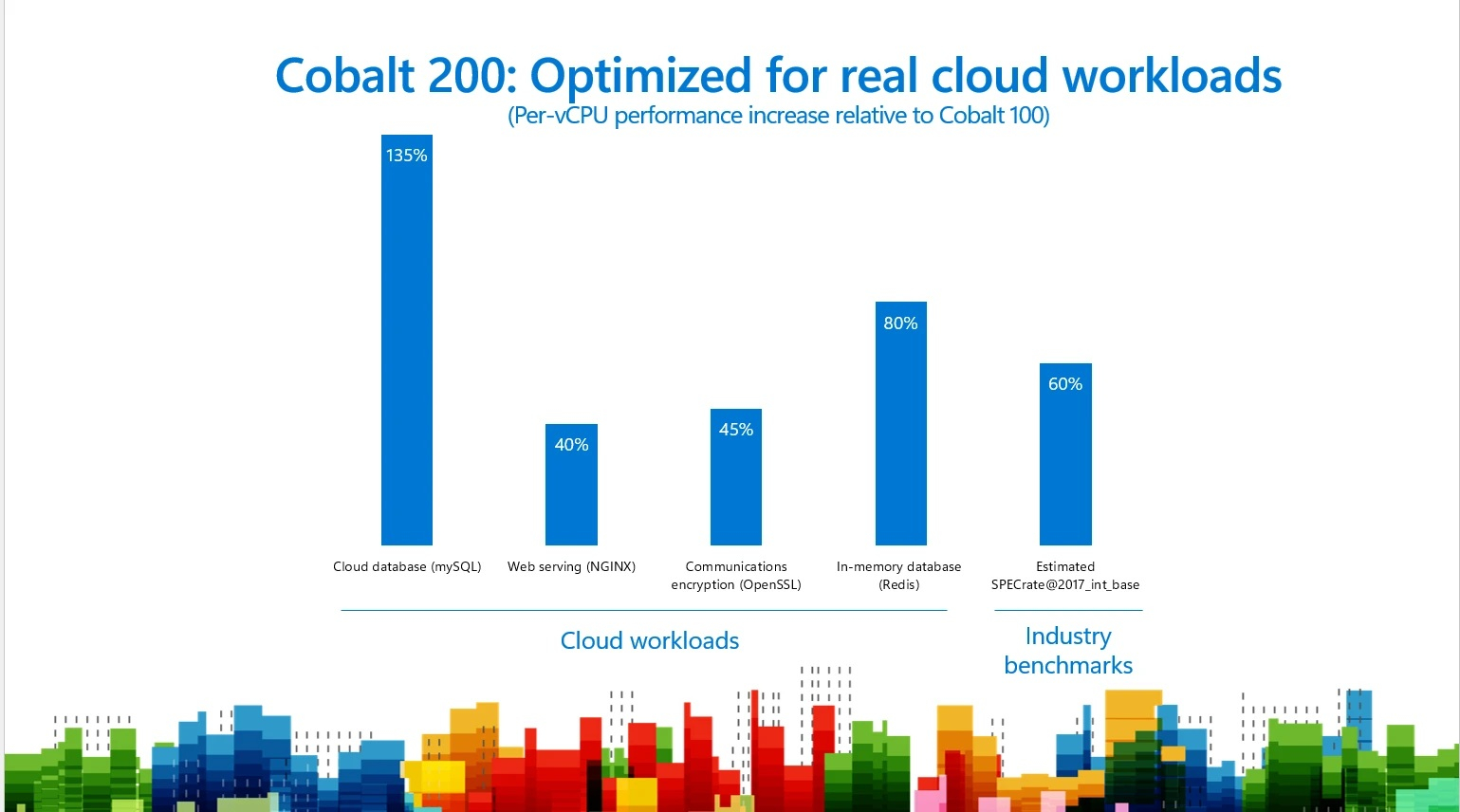
Источник изображений: Microsoft Его предшественник, Cobalt 100, доступен в 32 регионах ЦОД Azure по всему миру. Такие компании, как Databricks и Snowflake, используют Cobalt 100 для оптимизации своей облачной инфраструктуры, а такие клиенты, как Amadeus, OneTrust, Siemens, Sprinklr и Temenos, добились значительного повышения производительности и эффективности, сообщила Microsoft. На собственных облачных сервисах компании ВМ Azure Cobalt 100 обеспечивают повышение производительности до 45 % при использовании на 35 % меньшего количества вычислительных ядер по сравнению с предыдущей вычислительной платформой. Microsoft Defender for Endpoint (MDE) продемонстрировал повышение производительности на 40 % в своём инструменте управления данными. Ключевые преимущества инстансов Cobalt 200:
Компания отметила, что Cobalt 200 обеспечивает производительность на ядро и масштабируемость, необходимые для современных нагрузок агентного ИИ. Каждое ядро Cobalt 200 представляет собой полноценное физическое ядро, дополненное ёмким L2-кешем и повышенной пропускной способностью памяти на ядро. Эти конструктивные особенности обеспечивают более высокую изоляцию и стабильную производительность под нагрузкой, что позволяет агентным рабочим нагрузкам размещать больше песочниц агентов в одной виртуальной машине, одновременно удовлетворяя требованиям к задержке и пропускной способности.
Инстансы Cobalt 200 обеспечивают значительное улучшение по сравнению с Cobalt 100 в наиболее важных для продуктовой среды рабочих нагрузках, в том числе рост производительности до 135 % для облачных баз данных, до 40 % — для веб-серверов, до 45 % — для задач шифрования связи и до 80 % — для нагрузок кеширования. Инстансы Cobalt 200 полностью совместимы с инстансами Cobalt 100, что делает миграцию бесшовной. Основные платформы и языки программирования для разработчиков, включая C++, .NET, Java, Python и Rust, уже предлагают версии, разработанные специально для Arm. В числе собственных сервисов Microsoft, использующих ВМ Cobalt 200 — Dataverse и базы данных Azure. Напомним, что ранее Google объявила, что портировала около 30 тыс. внутренних нагрузок на Arm-архитектуру с использованием собственных Arm-чипов Axion и планирует перенести ещё порядка 70 тыс. В свою очередь, Oracle ещё несколько лет назад завершила миграцию всех своих облачных сервисов на Arm, как и AWS, также получившая заказы на поставку Graviton от Snowflake, Anthropic и Meta✴. Microsoft отметила, что запуск инстансов Cobalt 200 позволил ей расширить портфель Arm-инстансов для поддержки более широкого набора рабочих нагрузок. Если на базе Cobalt 100 предлагаются семейства ВМ общего назначения (Dp, Dpl) и оптимизированные по памяти (Ep), то Cobalt 200 позволил добавить ещё два семейства инстансов: Mpsv4 с увеличенным объёмом памяти и Lpsv5 с плотным локальным хранилищем. Новинки уже доступны в формате предварительных версий. Инстансы будут доступны в следующих регионах: West US3, East US2, Central US, Sweden Central, East US, West US2, Spain Central и Indonesia Central. Об их доступности в других регионах будет объявлено позже.
29.05.2026 [13:36], Руслан Авдеев
Meta✴ раздумывает, не потягаться ли с AWS и другими облакамиMeta✴, вероятно, попытается выйти на рынок облачных вычислений, составив конкуренцию таким опытными игроками как AWS, Microsoft Azure и Google Cloud, сообщает Datacenter Dynamics. По данным CNBC, информацию подтвердил в ходе ежегодного собрания акционеров глава компании Марк Цукерберг (Mark Zuckerberg), объявив, что руководство техногиганта «определённо обсуждает» выход на новый рынок. По его словам, почти еженедельно компания сталкивается с запросами со стороны бизнесов относительно возможной доступности API-сервисов для клиентов и вычислительных мощностей в аренду. Пока Meta✴ не предлагает никому со стороны облачные сервисы, хотя капитальные затраты на вычислительные мощности сопоставимы с аналогичными расходами известных облачных провайдеров. Во время последнего финансового отчёта Meta✴ сообщала, что прогнозы по капзатратам на год выросли до $120–135 млрд. Это связано с ожиданиями роста цен на комплектующие в текущем году и, в меньшей мере, дополнительными затратами для поддержки мощностей ЦОД в будущем году. Дополнительно заключено соглашение с Nebius на $27 млрд и с CoreWeave — на $21 млрд. Есть и многомиллиардное соглашение с AWS касательно Arm-процессоров Graviton5. 
Истчоник изображения: Meta✴ Дополнительно планируется сократить многих сотрудников, высвободив средства для инвестиций в ИИ ЦОД. Ранее компания уже заявила, что намерена уволить 10 % персонала, после чего без работы останутся порядка 8 тыс. человек. Дополнительно компания отказалась от найма 6 тыс. человек, а ещё 7 тыс. будут вынуждены сменить профиль деятельности для участия в новых ИИ-инициативах. В начале года Meta✴ сформировала подразделение Meta✴ Compute, занимающееся наращиванием мощностей своих дата-центров. По словам Цукерберга, в текущем десятилетии компания намерена построить десятки гигаватт, а в будущем — сотни гигаватт или даже более. Впрочем, по словам Цукерберга, сейчас компания не занимается подготовкой облачных решений, а выход на рынок станет актуальным лишь тогда, когда у Meta✴ появится избыток мощностей — отчасти именно это якобы вселяет в топ-менеджмент уверенность при принятии решений об инвестициях в новые ЦОД.
28.05.2026 [23:48], Владимир Мироненко
Yandex B2B Tech, Selectel и MetaMentor представили ИИ ПАК по подпискеYandex B2B Tech совместно с Selectel и MetaMentor представила AIaaS (AI-as-a-Service) ПАК для on-premise развёртывания по подписке платформы Yandex AI Studio. Рещение позволит компаниям быстро развернуть ИИ-проект с размещением инфраструктуры в собственном контуре и соблюдением регуляторных требований и внутренних политик. ПАК включает три компонента: ИИ-платформу Yandex AI Studio, GPU-серверы Selectel и услуги MetaMentor по внедрению, настройке и интеграции решения в ИТ-контур компании. Как сообщается в пресс-релизе, в новом формате доступны все основные возможности Yandex AI Studio: генеративные модели, инструменты для работы с данными и файлами, файловый поиск и визуальные интерфейсы для создания ИИ-агентов даже без навыков программирования. Также в решение могут быть включены ИИ-инструменты для офисной работы. Selectel предоставляет в аренду GPU-инфраструктуру с размещением на площадке заказчика и обязательством по обслуживанию и обновлению оборудования. В частности, доступны платформы NVIDIA HGX A100/B200/B300, RTX PRO 6000 и др., а также ИИ-сервер собственной разработки Selectel. На подготовку и доставку оборудования клиенту уйдёт до пяти рабочих дней. 
Источник изображения: Selectel На MetaMentor лежит задача помочь подготовить решение к запуску, включая интеграцию платформы с корпоративными системами заказчика и помощь в создании ИИ-агентов под его задачи. В дальнейшем MetaMentor продолжит системно сопровождать проект, оказывая техническую и клиентскую поддержку по всем вопросам, а также обновляя ПО. Yandex Cloud, Selectel и MetaMentor выводят новый продукт на рынок on-premises платформенного ПО на базе ИИ, который, по данным совместного исследования Yandex Cloud и AHD, составил в России в 2025 году около 16 млрд руб. Значительная часть компаний уже развёртывает ИИ в локальном контуре, поэтому новое решение может вызвать интерес среди заказчиков.
28.05.2026 [16:41], Руслан Авдеев
SB Energy подаст заявку на IPO в США, а сама SoftBank готовит японское GPU-облако AI Data Center GPU CloudДочерняя структура SoftBank — компания SB Energy планирует подать заявку на IPO в США. Тем временем сама SoftBank. запускает с октября 2026 года облачное решение AI Data Center GPU Cloud, сообщает Datacenter Dynamics. По данным SB Energy, дочерняя структура намерена подать на IPO на фоне растущего спроса инвесторов на вложения в компании, строящие энергетическую инфраструктуру, особенно для рынка ИИ ЦОД. Компания уже привлекла более $1,8 млрд на строительство инфраструктуры, в том числе от OpenAI. Изначально SB Energy основали в 2021 году как застройщика солнечных электростанций и аккумуляторных энергохранилищ. Так, в октябре 2024 года она заключила серию «солнечных» контрактов в Техасе для энергоснабжения дата-центров Google в формате PPA (Power Purchase Agreement). Головная SB Energy Global основана в 2015 году и ориентирована на проекты за пределами Японии. Недавно SB Energy диверсифицировала свои энергетические и инфраструктурные предложения, начав предлагать решения на природном газе и поддерживать строительство цифровой инфраструктуры для ЦОД. Например, в январе она подписала договор о строительстве кампуса Stargate в округе Майлам (Milam County) в Техасе мощностью 1,2 ГВт и управлении им. В марте SoftBank объявила о планах строительства многогигаваттного кампуса ЦОД на федеральной земле в Огайо. В частности, SB Energy должна построить 10 ГВт новых генерирующих мощностей, включая 9,2 ГВт на природном газе. Энергией будет обеспечиваться 10-ГВт ЦОД на площадке Portsmouth Site в округе Пайк (Pike County). Строительство должно начаться до конца 2026 года. 
Источник изображения: Jakub Żerdzicki/unsplash.com Тем временем SoftBank Corp. намерена запустить в Японии облачный проект AI Data Center GPU Cloud в октябре 2026 года. Он станет частью неооблачного бизнеса SoftBank и будет основано на стеке Infrinia AI Cloud OS, бета-версия уже доступна. ИИ-облако будет работать на ИИ-инфраструктуре SoftBank в дата-центрах в Японии, в т.ч. решениях NVIDIA GB200 NVL72, хотя компания не уточняла, какие ЦОД она будет использовать. При этом Infrinia AI Cloud OS обеспечит сервисы Kubernetes-as-a-Service и Inference-as-a-Service. Сегодня SoftBank управляет ЦОД с помощью дочернего подразделения IDC Frontier. В апреле 2025 года компания начала строительство 1-ГВт кампуса в Томакомай (Tomakomai) на о. Хоккайдо. Также у неё имеются дата-центры в Токийской агломерации, в регионе Тохоку (Tohoku), Кансай (Kansai) и на острове Кюсю. Также компания намерена построить 150-МВт ЦОД на территории недавно закрытого LCD-завода Sharp. SoftBank представила Infrinia AI Cloud OS в январе 2026 года. Компания утверждает, что ПО максимизирует производительность ИИ-ускорителей, в то же время обеспечивая лёгкое внедрение облачных сервисов. Также SoftBank предлагает в Японии облачный сервис с использованием платформы Oracle Alloy. Получивший название Cloud PF Type A сервис также будет базироваться в дата-центрах SoftBank, с площадками как на востоке, так и на западе Японии. В Японии есть и другая альтернатива американским гиперскейлерам — в 2025 году alt и Highreso запустили в стране собственное GPU-облако.
28.05.2026 [16:14], Руслан Авдеев
ByteDance разрабатывает собственные CPU для поддержки своей ИИ-инфраструктурыКитайский техногигант ByteDance работает над собственными CPU, чтобы поддержать растущие потребности в ИИ-инфраструктуре на фоне того, что цены на чипы растут, а дефицит поставок мешает расширению бизнеса, сообщает Reuters со ссылкой на три источника, знакомых с вопросом. Компания работает с двумя архитектурами, Arm и «открытой» RISC-V, и пока взвешивает, какой именно дизайн лучше всего закроет потребностям собственных ЦОД в долгосрочной перспективе. Инициатива косвенно свидетельствует о быстром смене приоритетов индустрии с обучения ИИ на инференс — современным ИИ-агентам всё больше нужны CPU, работающие в тандеме с ИИ-ускорителями. Google, Amazon, Microsoft и Alibaba разрабатывают собственные облачные CPU для снижения затрат и оптимизации производительности своих систем для конкретных задач. Также это в некоторой степени помогло ключевым производителям CPU — Intel и AMD выступить «лидерами сопротивления» доминированию NVIDIA в сфере ИИ. ByteDance намерена внедрять процессоры собственной разработки в собственных серверах и ЦОД для поддержки своих внутренних операций. По имеющимся данным, она готовит масштабную премьеру агентных продуктов, включая платформу Coze. AWS уже давно портировала значительную часть внутренних нагрузок на чипы Graviton, которые всё чаще пользуются спросом и у сторонних заказчиков, включая Meta✴ и Uber. Google тоже активно переносит нагрузки на чипы Axion. 
Истчоник изображения: ByteDance Пекинский бизнес обратился к нескольким партнёром, чтобы те помогли компании в реализации проекта и те должны не только помочь с разработкой чипов, но и обеспечить «бронирование» производственных мощностей Проект пока находится на ранней стадии реализации и, кроме данных источников, информации пока нет. Инициатива ByteDance ставит компанию в один ряд с многочисленными технологическими компаниями, решившими, что выпускать собственные чипы будет выгоднее несмотря на сложность их разработки. Стремление разрабатывать собственные полупроводники происходит на фоне того, что Intel ещё в феврале предупредила китайских клиентов о возможном росте сроков поставок CPU до шести месяцев. В апреле компания объявила, что спрос на её CPU со стороны ИИ-компаний был таким высоким в I квартале, что производитель распродал даже запасы предназначавшихся к списанию, ранее считавшихся неликвидными, чипов. На днях AMD предупредила об ухудшении положения на рынке CPU — спрос превышает прогнозы и проблемы со своевременными поставками сохранятся. Сегодня ByteDance закупает CPU у Intel и AMD, которые уже значительно подняли цены, рост квартал к кварталу в последние месяцы составил 10–35 %, что лишь подтолкнуло ByteDance к разработке собственных альтернатив. NVIDIA также развивает активность на рынке CPU и надеется, что новые Arm-процессоры Vera, которые оказались конкурентоспособны EPYC и Xeon, обеспечат компании доступ к новому рынку объёмом в $200 млрд. Сама Arm тоже планирует заработать миллиарды долларов на CPU Arm AGI, фактически конкурируя с собственными заказчиками.
27.05.2026 [22:48], Владимир Мироненко
Avanpost открыла публичное тестирование облачного сервиса Avanpost Identity CloudКомпания Avanpost объявила о запуске облачного сервиса Avanpost Identity Cloud и о старте его публичного тестирования. Его участникам предоставляется пробный период с доступом ко всем функциям сервиса до 1 сентября, с неограниченным числом пользователей и возможностью выстроить защиту корпоративного доступа: от базовой многофакторной аутентификации до тарифа E-Passport. Компания отметила, что Avanpost Identity Cloud построен как продолжение on-premise практики Avanpost, при этом возможности и архитектурные принципы корпоративного решения перенесены в облако без потери уровня защиты. Для каждого клиента разворачивается независимое окружение со степенью изоляции, сопоставимой с выделенным on-premise решением. Защищённую интеграцию платформы с корпоративными системами заказчика обеспечивает компонент Access Bridge. Сервис отличается гибкостью развёртывания с возможностью адаптации под любую архитектуру. Поддержка офлайн-аутентификации обеспечивает непрерывность работы даже при сбоях связи, а централизованное управление из единой административной консоли упрощает эксплуатацию — благодаря использованию принципа plug-and-play нет надобности в ручной настройке локальных компонентов. Критически важные секреты приложений (LDAP, RADIUS) обрабатываются внутри контура заказчика, обеспечивая высокий уровень безопасности. 
Источник изображения: Towfiqu barbhuiya/unsplash.com Пользователям Avanpost Identity Cloud предлагаются четыре тарифных плана с возможностью перехода по мере расширения числа и сложности выполняемых задач: Start, Expert, E-passport и Zero Trust. С 1 сентября 2026 года будет доступна выгодная ежемесячная тарификация по уникальным пользователям с оплатой по факту использования сервиса.
27.05.2026 [10:21], Руслан Авдеев
Безумству храбрых: французский инженер троллит IT-гигантов сатирическими ИИ-нарезками с индюкомФранцузский разработчик и SRE (Site Reliability Engineer) Амин Раити (Amine Raiti) объявил настоящую войну облачным гиперскейлерам, включая AWS, Google Cloud и Microsoft Azure. Он потребовал от них отказа от огромных комиссий за прекращение использования услуг. В противном случае гиперскейлерам грозит бесконечный поток сгенерированного ИИ сатирического музыкального контента, сообщает The Register. Раити, работающий в некой финансовой организации, находящейся под надзором европейского центробанка, выбрал оружием генерируемые ИИ песни, сатирические стихи и музыкальные пародии, от K-pop до финской польки и музыки в стиле Шопена, назвав свою кампанию «Операция индюк» (Operation Dindon). Идея появилась, когда Раити работал управленцем в одной из французских Adtech-компаний. Бизнес был связан многолетними облачными договорами, которые действовали даже на фоне падения выручки компании и сокращения штата. Хотя конкретные облачные провайдеры в тех увольнениях не обвиняются, именно тогда привязка к вендору якобы перестала быть для Раити абстрактной технической проблемой. Требования организатора интернет-протеста чрезвычайно просты: гиперскейлеры должны дать клиентам возможность отказаться от многолетних соглашений, если бизнес заходит в финансовый тупик, прекратить взимать огромные средства за выгрузку данных из своих облаков и обеспечить отказ от проприетарных сервисов гиперскейлеров без огромных трат на миграцию. Журналистам Раити привёл вопиющие примеры. По его словам, одна конфигурация AWS NAT Gateway может обойтись в €6,7 тыс. ($7777) ежегодно за функциональность, которую, по его словам, администраторы Linux-систем обеспечивали ещё в конце 1990-х гг. Управляемые Kubernetes-сервисы могут обходиться ежегодно в €14 тыс. ($16251) и более. 
Источник изображения: Amine Raiti / LinkedIn В отличие от обычных разговоров, не уходящих дальше отдельных IT-команд или публикации постов в LinkedIn, Раити превратил свой протест в настоящее представление, создав сатирический музыкальный сериал «Легенда об индюке» (The Legend of Dindon). Главный герой — вымышленный индюк, регулярно попадающий в зависимость от облачных сервисов и не способный выбраться из ловушек. Каждая серия посвящена отдельной проблеме: скрытым расходам, юридическим привязкам к вендорам или, например, завышенным тарифам. В начале мая Раити опубликовал т.н. «Железный ультиматум» (Iron Ultimatum) на 11 языках, адресовав его AWS, Google и Microsoft. Организатор музыкальных протестов готов даже выпустить хвалебный поэтический сборник с похвалами в адрес облачных компаний, если те проведут значимые реформы. Если нет — операция продлится бессрочно, благо, создание одного трека занимает около двух минут, а обойдётся это не дороже €50/мес. «Коллекция» Раити уже включает порядка 50 сгенерированных ИИ треков. Сами облачные гиганты пока не ответили на ультиматум и до объявленного «дедлайна» в сентябре остаётся довольно много времени. Впрочем, нередко они и сами обвиняют друг друга в огромных платежах за отказ от сервисов и выгрузку данных.
27.05.2026 [09:30], Сергей Карасёв
РТК-ЦОД запустил сервис Unit-colocation в «Облаке КИИ»РТК-ЦОД представил услугу Unit-colocation на базе своего «Облака КИИ»: она предполагает возможность размещения клиентского оборудования в ЦОД компании с последующим подключением к безопасной облачной платформе. «Облако КИИ» предназначено для размещения критической информационной инфраструктуры. В составе этой платформы задействованы аппаратные решения, внесенные в реестр Минпромторга, а также программное обеспечение из реестра Минцифры России. Сам ЦОД соответствует уровню Tier III, что гарантирует работу инженерных систем в случае чрезвычайных ситуаций. Благодаря услуге Unit-colocation заказчики смогут формировать гибридную ИТ-инфраструктуру со своими серверами, расположенными в «Облаке КИИ». В рамках сервиса клиентское оборудование размещается в монтажных шкафах в зоне внешних подключений (ЗВП) дата-центра — вне пределов аттестованного контура «Облака КИИ», но в контролируемой зоне. Подключение серверов выполняется в соответствии с резервируемой и отказоустойчивой схемой — через коммутаторы сетевого доступа 1 GE и оптические порты с пропускной способностью от 1 до 25 Гбит/с. Клиенты смогут выбрать наиболее подходящие для себя сетевые интерфейсы в соответствии с потребностями. Реализованная модель, как утверждается, обеспечивает высокий уровень связности клиентского оборудования с инфраструктурой «Облака КИИ». 
Источник изображения: unsplash.com / Homa Appliances «Наша новая услуга Unit-colocation обеспечивает объединение "Облака КИИ", частных корпоративных сетей и публичных облаков в единую IT-инфраструктуру организации. Такая схема гарантирует заказчику отказоустойчивость функционирования его гибридных IT-ресурсов и позволяет гибко ими управлять, а также аттестовать информационные системы на соответствие требованиям регуляторов», — говорит Алексей Суравикин, директор продуктового офиса «Перспективные продукты» РТК-ЦОД. Ожидается, что гибридная инфраструктура, сочетающая собственное оборудование и защищённое облако, заинтересует клиентов из госсектора и операторов персональных данных, а также крупные компании и организации из сфер финансов, промышленности, ТЭК, здравоохранения и транспорта. Заявку на подключение можно оформить на официальном сайте РТК-ЦОД.
26.05.2026 [23:24], Руслан Авдеев
Сделка Anthropic и Microsoft расширит спрос на ИИ ASIC и повлияет на цепочки поставок для облачного рынкаКак сообщает The Information, Anthropic ведёт с Microsoft переговоры об использовании фирменных ускорителей последней для работы с ИИ-моделями Claude. Подобный шаг способен ускорить широкое внедрение Maia 200 и поддержать спрос на ASIC по всей «облачной» цепочке поставок, сообщает DigiTimes. Выиграют и поставщики компонентов для облачного рынка, от Global Unichip до Marvell с Broadcom. Как сообщают отраслевые источники, Anthropic фактически стала главным драйвером спроса на ASIC. В отличие от OpenAI, которая ранее заключала крупные долгосрочные сделки по покупке чипов, закупки Anthropic обычно соответствовали актуальному спросу на вычислительные мощности. Тем не менее, в последние месяцы она тоже повысила активность. Во-первых, компания заключила соглашение на использование ASIC с Google и (AWS), арендовала ИИ-мощности у xAI и, теперь, возможно, будет арендовать их у Microsoft. Эксперты считают, что это свидетельствует о значительном росте популярности Claude, из-за чего выросла необходимость в вычислительных ресурсах. По словам источников, Anthropic активно применяет ASIC разных поставщиков — они предпочтительнее для компании, чем более дорогие ИИ-ускорители NVIDIA, что позволяет обеспечить эффективность расходов. Подобная стратегия позволяет компании избежать зависимости от единственного поставщика, что усиливает переговорные позиции компании и снижает для неё риски, связанные с концентрацией доступных вычислительных ресурсов у одного партнёра. 
Источник изображения: Microsoft Благодаря сделке Microsoft может поддержать собственные разработки ASIC, пока уступающие по многим параметрам решениям Google и AWS. Те уже некоторое время сдают ИИ-чипы собственной разработки в аренду. Если Microsoft удастся повторить подобный успех, компания сможет сократить расходы на расширение выпуска чипов и расширить их закупки, что создаст дополнительные стимулы для фактических производителей ASIC и их партнёров. На фоне роста внимания ИИ-бизнеса к ASIC, эксперты прогнозируют увеличение соответствующего рынка. По некоторым оценкам, если их будут использовать только облачные провайдеры, закупки на рынке останутся ограниченными, но рост спроса со стороны крупных клиентов облачных платформ может существенно помочь развитию всей ниши. Текущий вектор её развития указывает на то, что спрос будет расти и дальше. В феврале сообщалось, что Anthropic планирует увеличить к 2029 году расходы на облака до $80 млрд.
26.05.2026 [09:00], Сергей Карасёв
Гибкие настройки безопасности и новые инструменты для работы с шаблонами — «Базис» обновил конструктор Basis Automation Studio до версии 2.4Компания «Базис», лидер российского рынка ПО управления динамической инфраструктурой, представила версию 2.4 конструктора платформенных сервисов Basis Automation Studio — модуля, входящего в расширенную версию облачной платформы Basis Dynamix Cloud Control. Свежий релиз предлагает интеграцию со средством защиты виртуализации Basis Virtual Security, гибкую ролевую модель и поддержку работы с внешними системами версионирования через веб-портал. Basis Automation Studio представляет собой среду автоматизации развёртывания сервисов с инструментами визуального проектирования виртуальной инфраструктуры на основе готовых компонентов и связей между ними. В состав конструктора входит расширяемый каталог шаблонов виртуальных инфраструктур и платформенных сервисов, а также расширяемая библиотека компонентов с образцами популярного ПО — ClickHouse, Consul, Docker, MariaDB, PostgreSQL и других. Алгоритм развёртывания построен на архитектуре TOSCA с использованием языков YAML, Ansible, Python и Bash. Управление правами и доступомОдной из ключевых доработок релиза стала интеграция конструктора с решением защиты Basis Virtual Security. Конструктор использует Basis Virtual Security в качестве единого провайдера идентификации, что даёт администраторам возможность централизованно управлять учётными записями и правами доступа пользователей, а также обеспечивает поддержку технологии единого входа (Single Sign-On, SSO). В результате можно централизованно применять политики безопасности, что снижает нагрузку на администраторов, а пользователей платформы избавляет от необходимости вводить учётные данные при переходе между компонентами экосистемы «Базиса». 
Источник изображений: «Базис» В Basis Automation Studio 2.4 — в дополнение к имеющейся ролевой модели — была представлена её расширенная версия, которая позволяет тонко настраивать права доступа пользователей: администратор может собирать собственные роли из атомарных разрешений и назначать их в нужном объёме конкретным пользователям. Миграция на новую модель уже выполнена на уровне архитектуры конструктора. Интеграция с внешними Git-репозиториямиВ новой версии Basis Automation Studio появилась возможность загружать компоненты и шаблоны сервисов из Git-репозиториев. Загрузка и обновление компонентов и шаблонов сервисов осуществляется, используя графический интерфейс, по выбранному Git-тегу с возможностью пакетной загрузки. Поддерживаются разные способы аутентификации (пароль, токен). Загруженный компонент шаблон сервиса поддерживает версионирование (с возможностью обновления «вперед и назад»).  Тем самым продолжается развитие веб-портала как единой точки работы с конструктором. Ранее в портал были добавлены инструменты создания и редактирования компонентов и шаблонов. В новой версии конструктора добавилась интеграция с внешними Git-репозиториями. Это позволяет встроить разработку TOSCA-шаблонов в привычные для команд процессы работы с исходным кодом, обеспечить отслеживаемость изменений и упростить совместную работу над каталогом сервисов. В новом релизе также была добавлена оценка ресурсов для развёрнутых сервисов. Это позволяет пользователям анализировать ресурсные требования сервисов и точнее планировать их эксплуатацию. «Ключевая задача, которую Basis Automation Studio решает для бизнеса — упрощение процесса развёртывания ИТ-систем и сервисов внутри виртуального ЦОД. Поэтому мы развиваем продукт сразу в нескольких направлениях, связанных с решением этой задачи. В частности, мы уже реализовали централизацию управления доступом через интеграцию с другим нашим продуктом, Basis Virtual Security, а также более гибкое разграничение прав пользователей и включение конструктора в стандартные процессы разработки через поддержку Git в веб-портале», — отметил Дмитрий Сорокин, технический директор компании «Базис». |
|

