Материалы по тегу: hardware
|
15.12.2025 [09:18], Руслан Авдеев
Как ЦОД используют воду и почему никак не могут «напиться»После дебюта ChatGPT в 2022 году и взрывного роста рынка ЦОД вследствие этого, повышенное внимание стало уделяться воздействию последних на окружающую среду. Впрочем, беспокоиться стоит не только об электроэнергии. Любые, даже самые современные ЦОД используют колоссальные объёмы питьевой воды. В презентации техасской Strategic Thermal Labs упоминается, что в США дата-центры потребляют миллионы литров питьевой воды ежедневно для охлаждения оборудования. В некоторых случаях на долю ЦОД приходится до четверти потребления воды муниципалитетами. С распространением энергоёмких систем генеративного ИИ проблема только усугубилась. В апреле 2024 года сообщалось, что потребление воды китайскими ЦОД удвоится к 2030 году, дойдя до более чем 3 млрд м3/год. В августе того же года — что ЦОД в Вирджинии потребляют огромные объёмы питьевой воды, а развитие ИИ только усугубляет ситуацию. В ближайшие годы гиперскейлеры и прочие операторы ЦОД намерены построить гигаваттные ЦОД с миллионами ускорителей, поэтому воды потребуется ещё больше. Эксперты Калифорнийского университета в Риверсайде и Техасского университета в Арлингтоне предполагают, что мировой спрос на ИИ к 2027 году может привести к использованию 4,2–6,6 млрд м3/год. 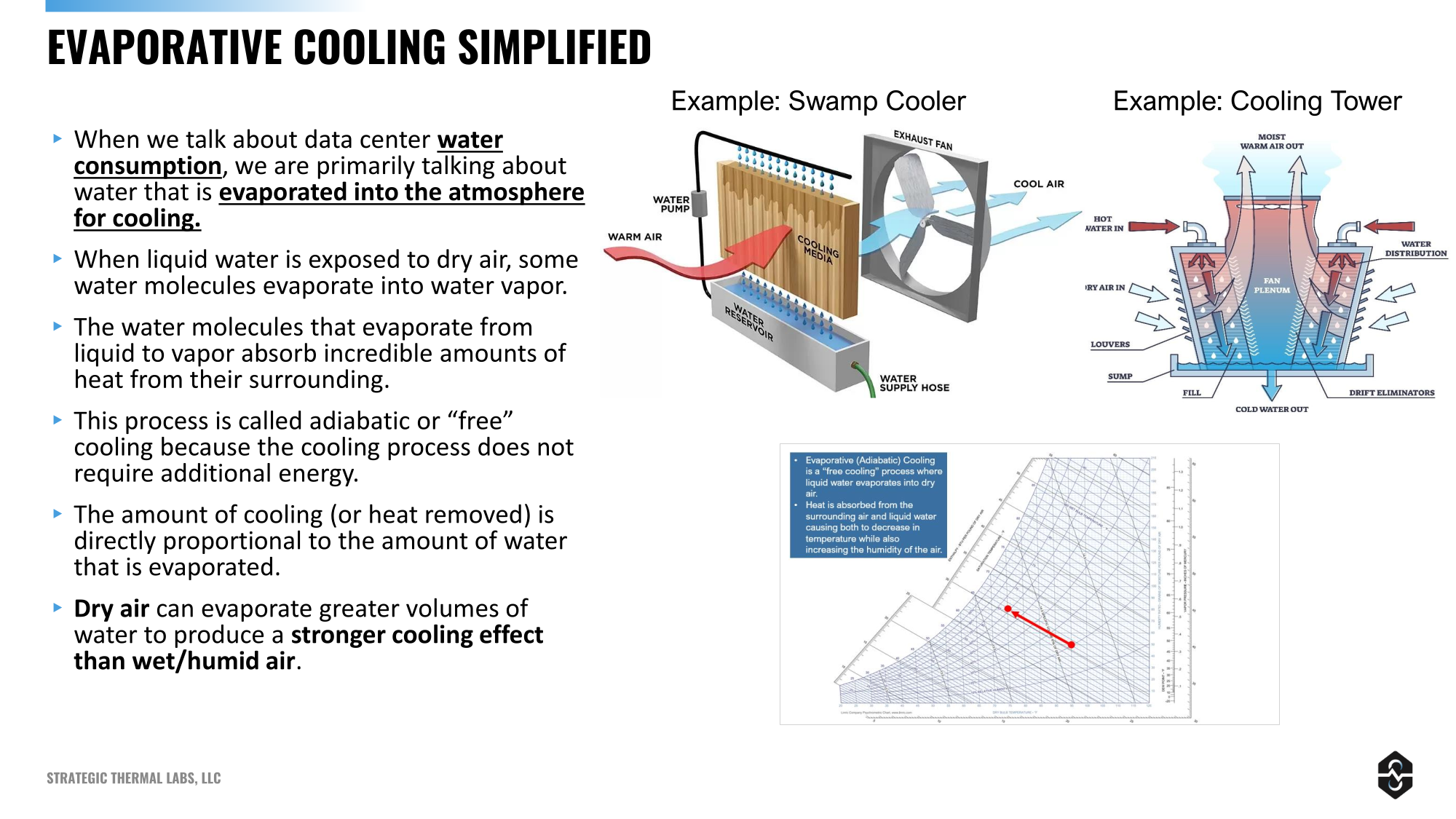
Источник изображения: Strategic Thermal Labs В первую очередь «виноваты» системы испарительного охлаждения, в которых вода берётся из местных источников и подаётся к оборудованию, где и испаряется, передавая тепло воздуху. Главной причиной популярности такой технологии среди операторов ЦОД стала высокая эффективность таких систем и отсутствие необходимости использовать для охлаждения много энергии. Испарения около 40 л/мин. достаточно для оборудования на 1,5 МВт, передаёт The Register со ссылкой на данные Strategic Thermal Labs. При этом испарительные системы обычно эффективнее всего работают в жарких и засушливых пустынных областях, где воды и так мало. Хуже того, 20–30 % воды в таких системах используются для промывки минеральных отложений и смывается в очистительные установки. Нейтрализация таких отложений — отдельная задача. Тем не менее, испарительные системы всё равно дешевле в эксплуатации в сравнении с альтернативами, у них выше КПД, а энергии они тратят мало. А, например, Digital Realty с помощью мониторинга и автоматизации насосов сократила использование воды в системах с испарительным охлаждением на 15 % — полностью исключить его практически невозможно. 
Источник изображения: Strategic Thermal Labs Любые технологии, даже не потребляющие воду напрямую, всё равно зависят от неё. Например, «сухие» охладительные системы тратят на порядки больше электричества в сравнении с испарительными, что потенциально увеличивает косвенные выбросы воды. Так, статистика свидетельствует, что порядка 89 % электроэнергии США получают от газовых, атомных и угольных электростанций, а многие из них применяют паровые турбины, расходующие чрезвычайно много воды. ЦОД, находящиеся в регионах с большими ресурсами ГЭС, солнечных и ветряных электростанций, обеспечивают меньшее косвенное потребление воды, чем те, что питаются, например, от ископаемого топлива. Примечательно, что при генерации энергии всё равно теряется намного больше воды, чем потребляется современными ЦОД. Согласно исследованию от 2016 года, порядка 83 % потребления воды ЦОД приходится на генерацию энергии. Другими словами, использование энергоёмких систем для «безводного» охлаждения ЦОД в итоге ведёт… к большему потреблению воды. Впрочем, речь может идти о «другой» воде в другом месте — электростанции могут быть очень далеко от ЦОД и часто получают воду из рек и озёр. Операторы ЦОД прекрасно это понимают, пытаясь скрыть расходы воды уровня Scope 2 и 3. 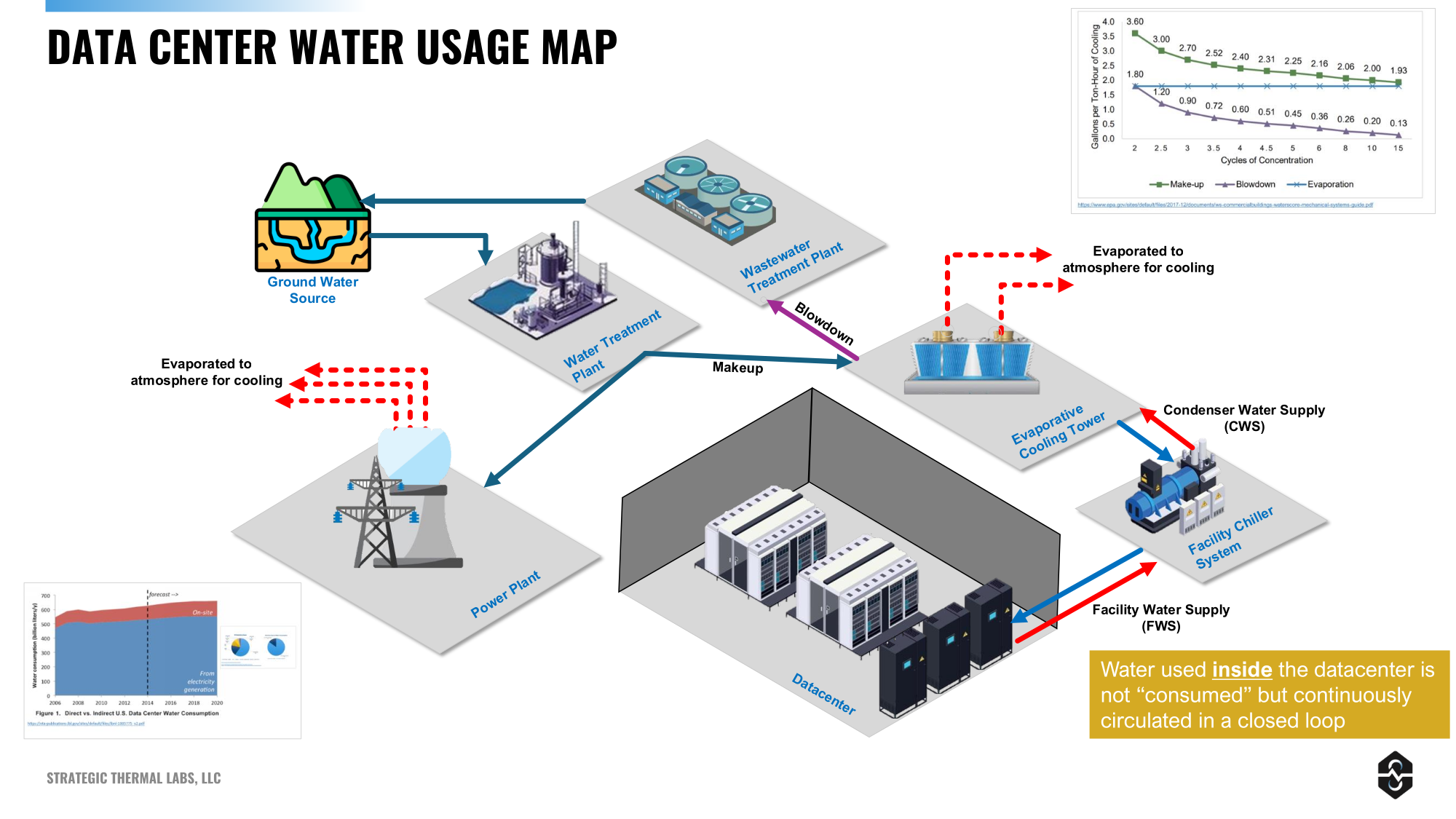
Источник изображения: Strategic Thermal Labs Для сокращения прямого и косвенного потребления целесообразно, например, использование фрикулинга везде, где это возможно. Впрочем, действительно комфортный для ЦОД климат, где нет жары, но нет и морозов, есть далеко не везде. В этом отношении выигравают страны Северной Европы, где много ГЭС и других возобновляемых источников. Поэтому даже если использовать вспомогательные чиллеры, косвенное потребление воды будет относительно небольшим, а тепло можно направлять на обогрев теплиц, зданий, бассейнов и т.п. Там, где фрикулинг нецелесообразен, возможен переход на СЖО — как DLC, так иммерсионные. Хотя «сухие» системы охлаждения потребляют больше энергии, чем испарительные, улучшение индекса PUE в итоге может компенсировать разницу. Например, переход на прямое жидкостное охлаждение чипов NVIDIA Blackwell может снизить PUE с 1,69–1,44 до 1,1 и ниже. Впрочем, баланс зависит от многих факторов. Та же NVIDIA пока не готова к погружным СЖО, да и средний по миру PUE с годами особо уже не меняется. 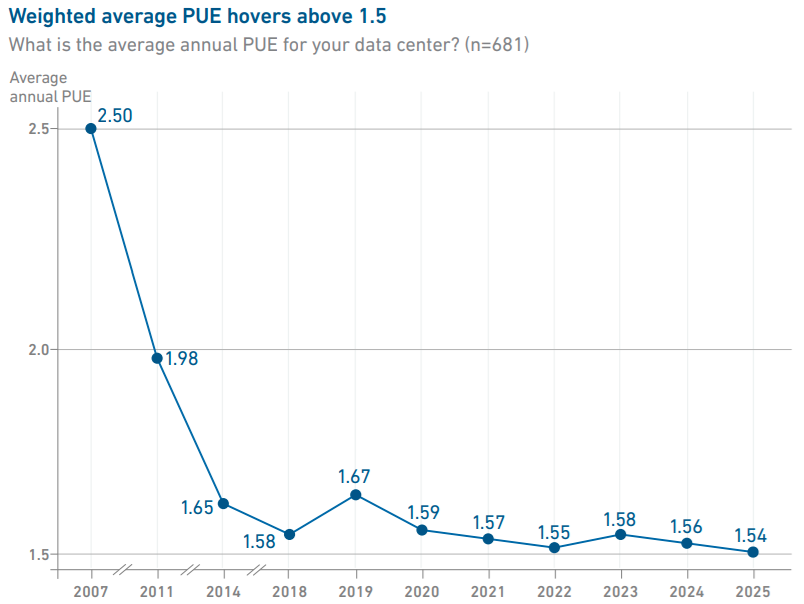
Источник изображения: Uptime Institute Хотя многие новые технологии охлаждения предусматривают внесение изменений в инфраструктуру объектов, в качестве альтернативы можно перераспределить нагрузки между ЦОД — примерно так же, как это делается в часы пиковых нагрузок на электросети, эффективность использования испарителей может меняться даже в зависимости от времени суток. Правда, многим, например колокейшн-провайдерам будет довольно трудно добиться эффективности из-за ограниченного контроля над серверами и нагрузками. Такой подход может не подойти и для инференса, где быстрое выполнение задач играет решающее значение. При этом обучение ИИ не имеет таких ограничений и проводиться удалённого на севере и в заданное время. Тюнинг моделей требует гораздо меньше вычислений, и такие задачи тоже можно планировать, например на ночь, когда температура ниже, как и объёмы испарения. Важнейшую роль играют источники воды для ЦОД. В некоторых регионах не хватает даже воды для питья. Эксперты предлагают операторам дата-центров инвестировать в опреснители, сети распределения воды, локальные очистные сооружения и др. для более широкого использования испарительных охладителей. По некоторым расчётам, опреснение и транспортировка воды с морского побережья всё ещё эффективнее, чем отказ от испарительных систем — даже с доставкой не трубопроводами, а в цистернах. Впрочем, Microsoft готовит ЦОД с почти нулевым расходом воды, а ранее экспериментировала со сбором дождевой воды. AWS обещала перевести ещё 100 дата-центров на использование очищенных сточных вод для охлаждения.
15.12.2025 [09:09], Сергей Карасёв
Квартальные продажи корпоративных SSD подскочили на 28 %, установив новый рекордПо данным компании TrendForce, суммарная выручка пяти ведущих поставщиков SSD корпоративного класса в III квартале уходящего года достигла $6,54 млрд, что стало новым рекордом (для 2025-го). Рост по отношению к предыдущему кварталу составил 28 %. Аналитики отмечают, что развитию рынка способствует сектор ИИ, где наблюдается дальнейший переход от обучения больших языковых моделей (LLM) к инференсу. На этом фоне североамериканские поставщики облачных услуг активно масштабируют ИИ-инфраструктуру, закупая высокопроизводительные SSD. Кроме того, отмечено повышение спроса на серверы общего назначения с твердотельными накопителями. Всё это привело к скачку цен на корпоративные SSD, а следовательно, и к увеличению объёма рынка. 
Источник изображения: Samsung Лидером отрасли является компания Samsung, которая выигрывает от широкого ассортимента устройств на основе чипов памяти TLC. В III четверти 2025 года продажи южнокорейского поставщика поднялись на 28,6 % по сравнению с предыдущим кварталом, достигнув приблизительно $2,44 млрд. При этом доля Samsung составила 35,1 %. На втором месте в рейтинге располагается SK Group (SK hynix и Solidigm), у которой выручка в квартальном исчислении выросла на 27,3 % — до $1,86 млрд, а доля зафиксирована в размере 26,8 %. Закрывает тройку Micron с $991 млн и прибавкой в 26,3 %: эта компания контролирует 14,3 % отрасли. Далее идут Kioxia и SanDisk с поставками в денежном выражении в объёме $978,4 млн и $269 млн и ростом на 30,4 % и 26,3 %: эти производители удерживают 14,1 % и 3,9 % сектора соответственно. Сообща пять перечисленных компаний занимают 94,2 % глобального рынка SSD корпоративного класса. 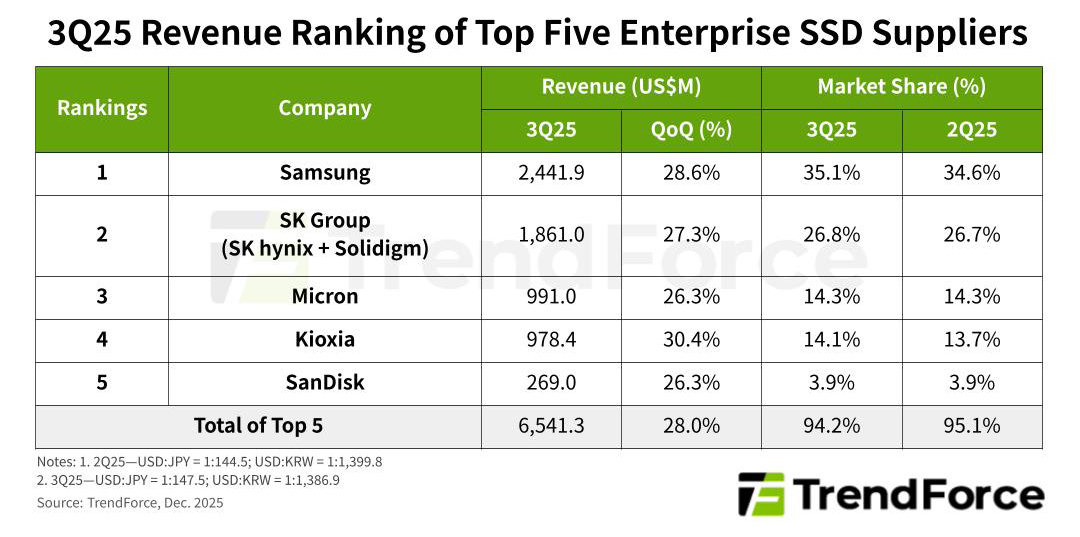
Источник изображения: TrendForce Аналитики TrendForce отмечают, что в IV квартале 2025-го ситуация на рынке значительно изменилась. Крупные поставщики чипов флеш-памяти NAND с осторожностью относятся к увеличению производства из-за ранее наблюдавшейся волатильности, в результате чего объём выпуска корпоративных SSD значительно отстаёт от спроса. Вместе с тем облака активно наращивают запасы, опасаясь дефицита SSD, который может негативно сказаться на темпах расширения ИИ-инфраструктуры. Таким образом, прогнозирует TrendForce, средние контрактные цены на корпоративные SSD в последней четверти года вырастут более чем на 25 % по сравнению с предыдущим кварталом, что потенциально может привести к новым рекордным показателям выручки поставщиков данной продукции.
14.12.2025 [19:14], Руслан Авдеев
Oracle опровергла сообщения о задержке строительства ИИ ЦОД для OpenAIВ пятницу агентство Bloomberg сообщило, что Oracle перенесла сроки завершения строительства некоторых ЦОД для OpenAI на 2028 год по причине нехватки рабочей силы и материалов — на год позже, чем планировалось. Позже информацию опровергла сама Oracle, попытавшись развеять опасения инвесторов, сообщило агентство Reuters. В компании объявили, что на всех площадках, необходимых для выполнения обязательств, задержек не наблюдалось, а работы на всех этапах выполняются в соответствии с графиком. Oracle утверждает, что полностью уверена в своей способности выполнять договоры и планы дальнейшего расширения. После публикации отчёта Bloomberg акции Oracle упали на 3,6 % после и так рекордного падения ранее, но позже частично компенсировали потери. Акции других ИИ-компаний тоже подешевели, в том числе пострадали ценные бумаги NVIDIA, AMD и Micron, в среднем на 2–4,5 %. Инвесторы опасаются роста расходов и слабых перспектив компании, всё больше попадающей в зависимость от OpenAI. Oracle, один из «малых гиперскейлеров», в 2025 году включилась в гонку по созданию ИИ-инфраструктуры благодаря сделке с OpenAI, предусматривавшей создание дата-центров на $300 млрд. При этом проект вынудил компанию активно привлекать заёмные средства. По данным Reuters, в последнее время инвесторы напуганы тем, что в гонке ИИ вперёд вырывается Google, а также растущей долговой нагрузкой Oracle, распродали часть акций и облигаций компании. В прошлый четверг стоимость страхования долгов Oracle от дефолта достигла самого высокого уровня за пять лет, в пятницу она снова подросла. С начала года цена акций компании выросла всего на 13 %, ценные бумаги полностью «растеряли» достижения сентября, когда отчёт о рекордном портфеле заказов на сумму более $450 млрд, в основном связанных с OpenAI, привёл к взлёту цены акций на 36 %. 
Источник изображения: Samuel Regan-Asante / Unsplash После публикации Bloomberg некоторые эксперты заявили, что новость свидетельствует о появлении проблем, выходящих за рамки только лишь проблем и задержке при выпуске чипов. Как заявили в TECHnalysis Research, опасения, связанные с задержками строительства ЦОД, доступностью электроэнергии и др. факторами становятся всё более значимыми. В компании заявляют, что рынок более чувствителен к новостям о задержках при реализации ИИ-проектов, поскольку инвесторы тщательно анализируют отдачу от инвестиций. На днях сообщалось, что рекордная выручка и оптимистичный прогноз NVIDIA снизили опасения по поводу роста ИИ-пузыря. Впрочем, эксперты Omdia не исключают того, что рынок ИИ может «лопнуть» — хотя вероятность этого считается не слишком высокой. Инвесторы стали всё более разборчивы в том, что касается ИИ-проектов, и всё реже готовы поощрять необдуманные траты на ИИ, даже с учётом того, что они делают ставку на долгосрочный потенциал соответствующих проектов.
14.12.2025 [14:46], Сергей Карасёв
Beelink ME Pro: компактный NAS с тремя M.2 NVMe, двумя отсеками LFF/SFF и портами 2.5GbE/5GbEКомпания Beelink, по сообщению ресурса NAS Compares, готовит сетевое хранилище небольшого форм-фактора ME Pro, построенное на аппаратной платформе Intel. Устройство поддерживает гибридные конфигурации на основе SSD и HDD. При этом пользователи могут установить собственную ОС с учётом своих предпочтений и выполняемых задач. Новинка может комплектоваться чипом Intel Processor N95 поколения Alder Lake-N или Intel Processor N150 семейства Twin Lake. Эти изделия содержат четыре ядра без поддержки многопоточности и интегрированный графический контроллер. В первом случае максимальная частота составляет 3,4 ГГц, показатель TDP — 15 Вт, во втором — 3,6 ГГц и 6 Вт. Объём оперативной памяти LPDDR5 равен 12 Гбайт и 16 Гбайт соответственно. Хранилище выполнено в корпусе с габаритами 165,91 × 121 × 115,95 мм, который разделён на две секции. В верхней находятся два лотка для накопителей LFF/SFF с интерфейсом SATA; поддерживается горячая замена. Нижняя часть отведена под материнскую плату Предусмотрены три коннектора М.2 для SSD (NVMe): один с интерфейсом PCIe 3.0 x2 для ОС (может применяться твердотельный модуль вместимостью 512 Гбайт или 1 Тбайт) и два с интерфейсом PCIe 3.0 x1 для кеша, виртуальных машин и пр. 
Источник изображений: Beelink NAS располагает сетевыми портами 5GbE (контроллер Realtek RTL8126) и 2.5GbE (Intel i226V) с разъёмами RJ45, портами USB 3.2, USB 2.0 (×2) и USB Type-C, интерфейсом HDMI с поддержкой видео в формате 4K (до 60 Гц). Имеется также комбинированный адаптер Wi-Fi / Bluetooth 5.4 в виде модуля M.2 2230 (MediaTek MT7920). Продажи Beelink ME Pro начнутся в текущем месяце. 
14.12.2025 [14:40], Руслан Авдеев
NVIDIA рассматривает увеличение выпуска ускорителей H200 из-за большого спроса на них в КитаеПо данным отраслевых источников, NVIDIA сообщила клиентам в Китае, что уже рассматрвиает возможность нарастить производство ИИ-ускорителей H200. По данным Reuters, объёмы заказов уже превышают доступный сегодня уровень производства. Ранее сообщалось, что руководство США рассматривает разрешение поставок H200 в КНР, а в минувший вторник президент страны объявил о том, что этот вопрос решён положительно. При этом власти будут получать комиссию в 25 % с продаж ускорителей в Китай. Спрос на современные ИИ-чипы в Китае столь высок, что NVIDIA допускает расширение их производства. В самой NVIDIA прокомментировали слух, заявив, что управляют цепочкой поставок таким образом, чтобы продажи авторизованным клиентам в Китае не повлияли на способность поставлять продукцию покупателям из США. Пока чипов H200 производится очень немного, поскольку NVIDIA сосредоточилась на выпуске передовых ускорителей Blackwell, а также будущего семейства — Rubin. Крупные китайские компании, включая Alibaba и ByteDance уже связались с NVIDIA на днях по поводу закупок H200 и, как утверждается, заинтересованы в размещении крупных заказов. Впрочем, пока неопределённость сохраняется, поскольку закупки H200 не одобрили в самом Китае. По словам источников, в прошлую среду китайские чиновники провели ряд экстренных совещаний для обсуждения вопроса и принятия решения о том, стоит ли в принципе разрешать поставки H200. 
Источник изображения: bruce mars/unsplash.com H200 поступили в массовое производство в 2024 году и являются самыми быстрыми ускорителями NVIDIA поколения Hopper. Высокий спрос на H200 в Китае обусловлен тем, что это самый производительный чип, который будет доступен китайскому бизнесу на данный момент. Он приблизительно вшестеро производительнее «урезанной» модели H20. Решение США принято на фоне стремления Китая активно развивать собственную полупроводниковую индустрию для ИИ-проектов. Поскольку продукция, сопоставимая с H200 в продаже пока отсутствует, в Китае уже возникли опасения, что выход американских чипов на локальный рынок может затормозить развитие местной отрасли. По мнению некоторых китайских экспертов, вычислительная мощность H200 в два-три раза выше, чем у самых передовых чипов из КНР — многие поставщики облачных услуг и корпоративные клиенты активно размещают заказы и лоббируют ослабление ограничений. При этом отмечается, что спрос в Китае в любом случае превышает возможности местного производства. По сведениям источников, в ходе экстренных совещаний предлагалось разрешить покупать каждый ускоритель H200 только при условии покупки определённого количества чипов китайского производства. При этом у китайских IT-гигантов теоретически остаётся запасной вариант — размещение H200 в собственных ЦОД за пределами Китая. Они и так обучают модели в дата-центрах вне КНР, пусть и не своих. Для NVIDIA же наращивать производственные мощности тоже непросто, поскольку она занята наладкой массового производства Rubin и конкурирует за мощности TSMC с компаниями уровня Google.
14.12.2025 [00:39], Владимир Мироненко
Контракт с Anthropic на $11 млрд не помог — акции Broadcom рухнули из-за слабого прогнозаBroadcom после публикации результатов за IV квартал и 2025 финансовый год в целом, завершившийся 2 ноября, столкнулась с самым значительным падением своих акций за последние 10 месяцев в связи с тем, что её прогноз продаж не оправдал ожиданий инвесторов. Сообщение генерального директора Broadcom Хока Тана (Hock Tan) об имеющемся портфеле заказов на продукцию для ИИ-инфраструктур на сумму $73 млрд, которая будет отгружена в течение следующих шести кварталов, явно разочаровало некоторых инвесторов, хотя Тан уточнил, что эти цифры являются «минимальными». «Мы ожидаем гораздо большего по мере поступления новых заказов на отгрузку в течение следующих шести кварталов, — сказал он. — Таким образом, наш срок выполнения заказа, в зависимости от конкретного продукта, может составлять от шести месяцев до года». Несмотря на то, что результаты за квартал и прогнозы Broadcom превзошли оценки Уолл-стрит, акции компании упали на торгах в Нью-Йорке в пятницу на 12 %, что стало самым большим падением в течение дня с конца января, пишет Bloomberg. Но даже с учётом этого падения её акции выросли более чем на 57 % за год (по данным Reuters). Акции ещё одного участника ИИ-рынка, Oracle, упали в пятницу на 4 % на фоне новостей о переносе сроков завершения строительства некоторых ЦОД, предназначенных для сервисов OpenAI. Это произошло вслед за обвалом на 11 % после публикации отчёта о результатах за последний финансовый квартал. 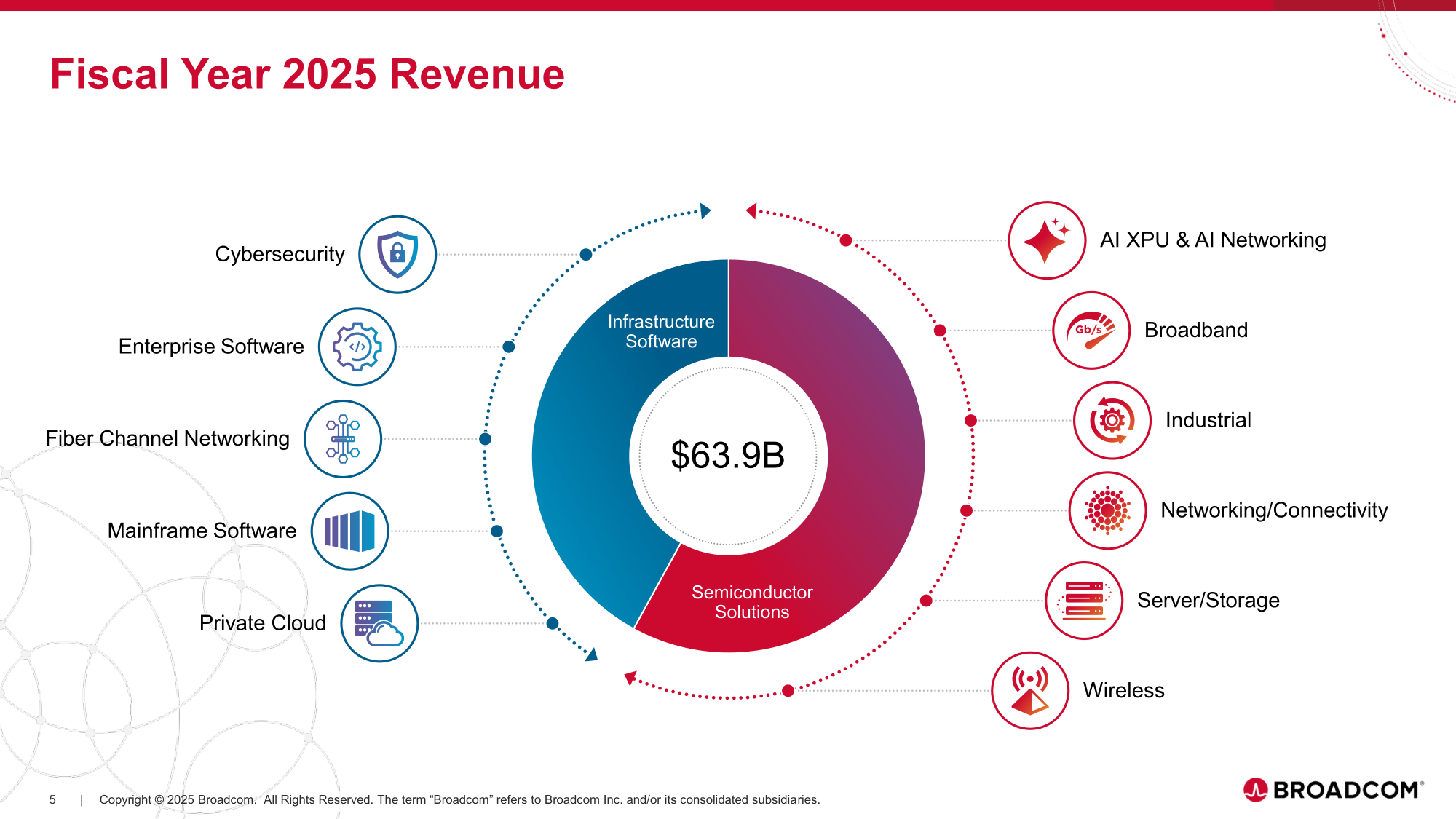
Источник изображений: Broadcom ИИ стал движущей силой фондового рынка и экономики в целом в этом году, поэтому любые негативные настроения на ИИ-рынке могут иметь далеко идущие последствия, отметил CNBC. В минувшую пятницу индекс Nasdaq упал примерно на 1,4 %, а S&P 500 снизился почти на 1 %, причём сильнее всего пострадали компании, тесно связанные с ИИ-инфраструктурой. Тан раскрыл имя нового клиента, о котором он сообщил в ходе отчёта за предыдущий квартал. Им оказался стартап Anthropic, от которого в IV квартале поступил заказ на $11 млрд на разработку кастомного ИИ-чипа после сделки на $10 млрд в III квартале. Тан также рассказал о подписании Broadcom ещё одного контракта на разработку XPU на $1 млрд, снова сразу не назвав имя заказчика.  Broadcom сообщила о росте выручки год к году на 28 % за отчётный квартал, до $18,02 млрд в основном за счёт увеличения продаж ИИ-чипов на 74 %, что превысило среднюю оценку аналитиков, опрошенных LSEG, в $17,49 млрд. Скорректированная прибыль (Non-GAAP) на разводнённую акцию составила $1,95, что тоже превысило среднюю оценку экспертов в $1,86. Чистая прибыль (GAAP) равняется $8,52 млрд или $1,74 на разводнённую акцию. Тан сообщил, что выручка от продаж ИИ-полупроводников удвоится в I финансовом квартале по сравнению с прошлым годом и составит $8,2 млрд, благодаря кастомным ИИ-ускорителям и коммутаторам Ethernet для ИИ-инфраструктуры. Кирстен Спирс (Kirsten Spears), финансовый директор Broadcom, указала в пресс-релизе, что в 2025 финансовом году скорректированная EBITDA выросла на 35 % год к году, до рекордных $43,0 млрд, а свободный денежный поток составил $26,9 млрд. Она предупредила, что «валовая маржа будет ниже» для некоторых ИИ-систем Broadcom, поскольку компании придётся закупать больше комплектующих для производства. Следует отметить, что снижение рентабельности, по крайней мере в краткосрочной перспективе, является одним из главных поводов для беспокойства инвесторов. «Сейчас планы многих по расходам кажутся настолько масштабными, что паниковать преждевременно», — считает, в свою очередь, Бен Рейтцес (Ben Reitzes), аналитик Melius Research.  Выручка группы полупроводниковых решений Semiconductor Solutions достигла $11,07 млрд, увеличившись на 35 % по сравнению с аналогичным периодом прошлого года. $6,7 млрд из этой суммы пришлись на ИИ-продукты. Менее чем за три года выручка Broadcom от аппаратного обеспечения для ИИ-инфраструктуры выросла в 10 раз. Бизнес по разработке инфраструктурного ПО принёс компании $6,94 млрд (рост год к году на 19 %). Тан сообщил, что большая часть этого роста связана с продажами решений VMware, которые, по его словам, обеспечат двузначный рост до 2026 года. Это является замедлением по сравнению с 26-% ростом в годовом исчислении, зафиксированным в 2025 финансовом году, отметил The Register. Однако рентабельность подразделения ПО выросла на 6 п.п. до 78 %, что отражает завершение процесса интеграции VMware в Broadcom. Что касается итогов за весь 2025 финансовый год, то выручка Broadcom составила $63,89 млрд (рост год к году на 24 %), чистая прибыль (GAAP) — $23,13 млрд (рост — 292 %), чистая прибыль на акцию — $4,77 (рост — 288 %). 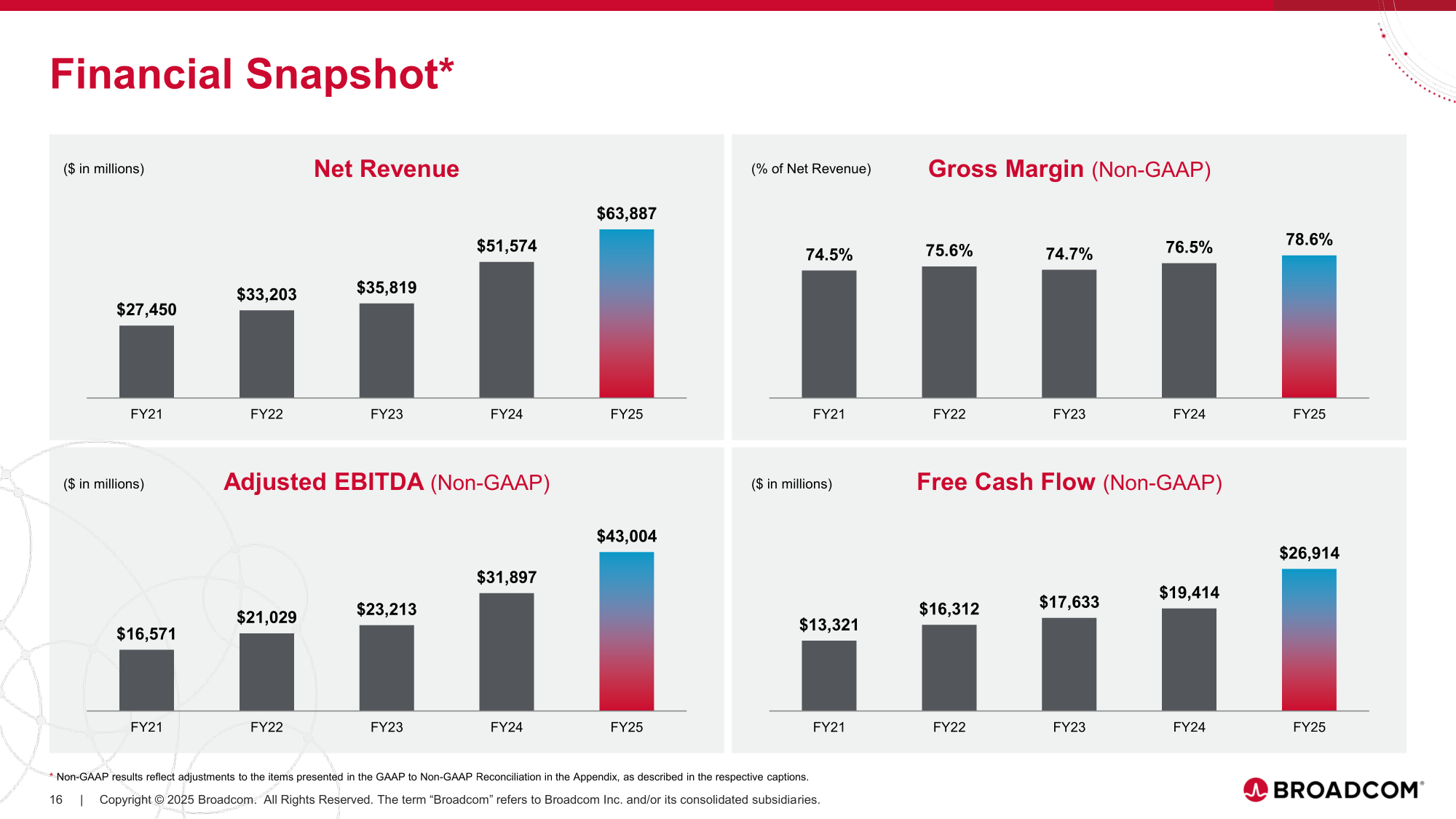 Тан прогнозирует, что полупроводниковый бизнес обеспечит Broadcom быстрый рост, и сообщил, что в I квартале 2026 финансового года компания ожидает получить выручку $19,1 млрд, что на 28 % больше, чем в предыдущем году. Хотя многие рассчитывали на сделку с OpenAI после объявления в октябре о новом клиенте, Тан развеял эти надежды, заявив инвесторам: «Мы не ожидаем многого в 2026 году». Broadcom также воздержалась от предоставления годового прогноза выручки от ИИ-продукции — Тан заявил, что это «постоянно меняющаяся цель». «Мне сложно точно определить, как будет выглядеть 2026 год», — сказал он. — Поэтому я бы предпочёл не давать вам никаких прогнозов». Вместе с тем он отметил, что прогнозы охлаждения спроса на ИИ-оборудования не сбудутся, сославшись на продолжающееся поступление заказов. «Мы никогда не видели таких объёмов заказов, как за последние три месяца», — сказал Тан инвесторам, добавив, что портфель заказов компании может вырасти ещё больше. Он отмахнулся от предупреждений инвесторов о возможных ограничениях в цепочке поставок, заявив, что Broadcom может получить необходимые мощности TSMC, уклонившись также от вопроса о влиянии стоимости оперативной памяти и указав на новый завод в Сингапуре как на источник необходимых мощностей по упаковке и сборке для удовлетворения спроса. Также гендиректор Broadcom выразил мнение, что время кремниевой фотоники ещё не наступило. Он заявил, что прежде, чем эта технология станет необходимой, должны пройти две волны инноваций. Первая — масштабирование интерконнектов на основе меди для стоечных систем. Вторая — подключаемая оптика — технология, объединяющая электронные и фотонные устройства.
13.12.2025 [23:26], Руслан Авдеев
Microsoft обязалась компенсировать рост спроса на облачные и ИИ-сервисы в США, построив новые ЦОД AzureMicrosoft поделилась планами расширения инфраструктуры на территории США на фоне стремительного роста спроса на облачные и ИИ-сервисы. Компания напомнила о создании площадок Fairwater в Висконсине и Атланте. Также появится облачный регион East US 3 в агломерации «Большой Атланты» в начале 2027 года. Дополнительно планируется раширить пять действующих регионов ЦОД по всей территории Соединённых Штатов. Сеть дата-центров в границах «Большой Атланты» уже использует одни из наиболее передовых ИИ-суперкомпьютеров в мире, но в начале 2027 года сеть ЦОД в Атланте расширится, чтобы поддержать интенсивные рабочие нагрузки региона East US 3. Регион разработают с фокусом на поддержку самых ресурсоёмких задач, включая ИИ-нагрузки. Регион получит несколько зон доступности (AZ), т.е. несколько ЦОД, расположенных на некотором расстоянии друг от друга (обычно до 100 км), оснащённых независимыми источниками питания, сетевой инфраструктурой и системами охлаждения. East US 3 проектируется с учётом обязательств Microsoft, связанных с сокращением углеродных выбросов, водопотребления, утилизацией отходов и устойчивым развитием. При строительстве East US 3 уделяется первостепенное внимание сохранению и восстановлению воды. Регион планируется сертифицировать по стандарту LEED Gold. 
Источник изображения: Microsoft Сейчас у компании в США есть регионов шесть регионов ЦОД с несколькими зонами доступности. Планируется добавить новые зоны к ряду других регионов. В 2026 году East US 2 в Вирджинии и South Central US в Техасе, где есть по три зоны доступности, получат новые AZ. Также компания добавит ещё несколько AZ на территори США: в начале 2026 года — к US Gov Arizona, к концу 2026 года — в North Central US, а в начале 2027 года — к West Central US. Microsoft, по её собственным сдлвам, имеет больше облачных регионов, чем любой другой облачный бизнес. Всего инфраструктура Microsoft включает более 70 регионов, 400 ЦОД, более 595 тыс. км подводных и наземных ВОЛС, а также более 190 периферийных точек присутствия. В октябре 2025 года сообщалось, что Microsoft не хватает ЦОД и серверов в США, причём не только для ИИ. Впрочем, компания развернула для OpenAI первый в мире ИИ-кластер на базе суперускорителей NVIDIA GB300 NVL72. Сейчас она запустила второй «самый передовой» ИИ ЦОД в мире Fairwater в дополнение к первому проекту. В ноябре появилась информация, что компания потратит более $60 млрд на аренду ИИ-мощностей у неооблаков. Всего капитальные затраты на ИИ ЦОД должны составить $80 млрд (и до $120 млрд в 2026 финансовом году).
13.12.2025 [15:53], Сергей Карасёв
Мировой рынок серверов бьёт рекорды благодаря ИИ: квартальная выручка превысила $110 млрд, а Китай резко нарастил свою долюКомпания International Data Corporation (IDC) обнародовала результаты исследования мирового рынка серверов в III квартале уходящего года. Продажи в денежном выражении достигли рекордных $112,4 млрд: это на 61,1 % больше по сравнению с аналогичным периодом прошлого года, когда отгрузки оценивались в $69,79 млрд. При этом продажи СХД показали минимальный рост год к году. Квартальная выручка от продаж серверов с архитектурой x86 увеличилась на 32,8 % — до $76,3 млрд. Системы с процессорами на других архитектурах принесли производителям $36,2 млрд, показав рост на 192,7 % в годовом исчислении. Более половины от общего объёма отрасли обеспечили серверы, оборудованные ускорителями: на фоне стремительного внедрения ИИ поставки таких машин в денежном выражении поднялись на 49,4 % по сравнению с III четвертью 2024 года. 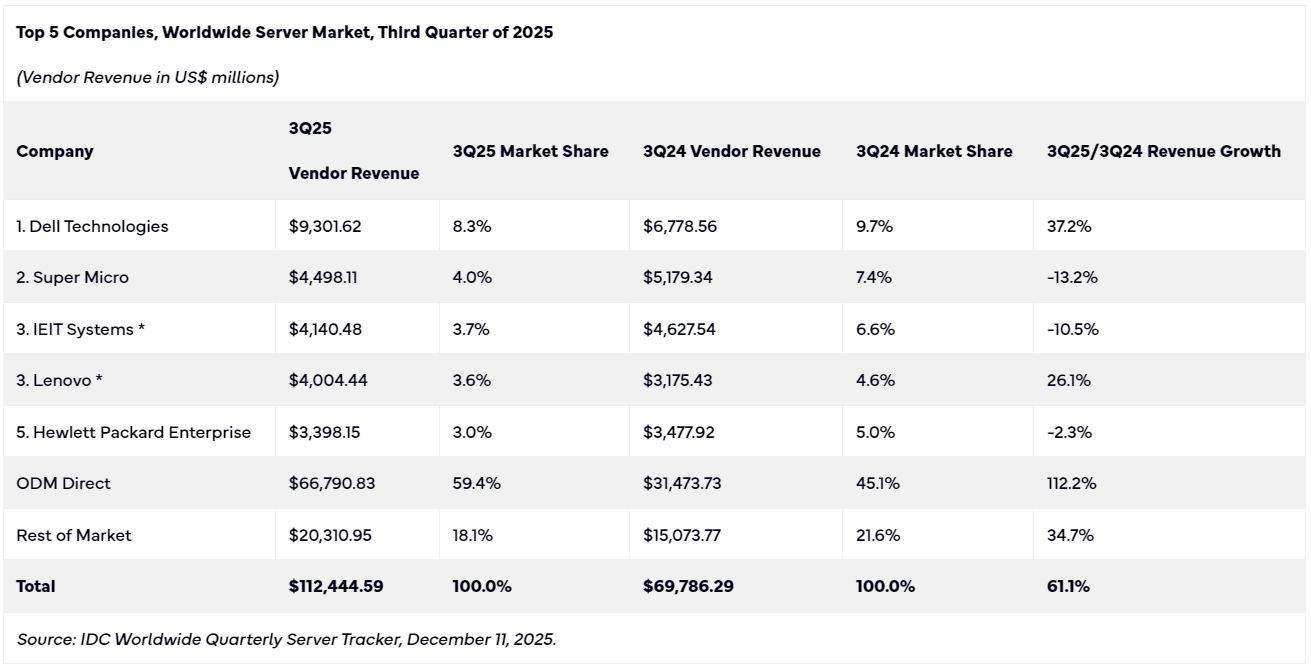
Источник изображения: IDC С географической точки зрения самые высокие темпы роста продемонстрировали США — плюс 79,1 % в годовом исчислении: этому способствовало увеличение продаж ИИ-серверов на 105,5 %. Канада показала прибавку в размере 69,8 %. В Китае зафиксировано увеличение поставок в денежном выражении на 37,6 %: при этом на КНР пришлась почти пятая часть квартальной выручки в мировом масштабе. В Азиатско-Тихоокеанском регионе (без учёта Китая и Японии) рост составил 37,4 %, в регионе ЕМЕА (Европа, Ближний Восток и Африка) — 31,0 %, в Японии — 28,1 %. В Латинской Америке продажи поднялись на 4,1 %. Рейтинг ведущих поставщиков серверов по итогам III квартала 2025 года возглавляет Dell Technologies с выручкой в размере $9,3 млрд и долей 8,3 %. На втором месте располагается Supermicro с $4,5 млрд и 4,0 %, а замыкает тройку IEIT Systems с $4,14 млрд и 3,7 %. На четвёртой и пятой строках находятся Lenovo и НРЕ, у которых выручка составила соответственно $4,0 млрд и $3,4 млрд, а рыночная доля — 3,6 % и 3,0 %. При этом у всех перечисленных компаний доли сократились по сравнению с III кварталом 2024 года.
13.12.2025 [14:31], Сергей Карасёв
Мировой рынок СХД вырос благодаря спросу на массивы All-Flash, а выиграли от этого Pure Storage, Huawei и NetAppПо данным International Data Corporation (IDC), продажи систем хранения данных (СХД) корпоративного класса в мировом масштабе достигли $7,97 млрд по итогам III квартала текущего года. Это на 2,1 % больше по сравнению с тем же периодом 2024-го, когда объём рынка оценивался в $7,81 млрд. Наибольший рост выручки год к году показали Pure Storage (+15,5 %), Huawei (+9,5 %) и NetApp (+2,8 %), а Dell Technologies (-4,9 %) и HPE (-7,5 %) показали падение Положительная динамика показана благодаря поставкам массивов All-Flash: их продажи в годовом исчислении увеличились в деньгах на 17,6 %. Связано это с растущим спросом на высокопроизводительные системы, ориентированные на ресурсоёмкие задачи в области ИИ. Вместе с тем спрос на гибридные СХД и на решения на базе HDD уменьшился по отношению к III четверти 2024 года на 9,8 % и 6,3 % соответственно. 
Источник изображения: Pure Storage В ценовом разрезе доминируют системы среднего класса стоимостью от $25 тыс. до $250 тыс. На такие продукты пришлось 67,5 % продаж, а их поставки увеличились год к году на 8,1 % в денежном исчислении. С другой стороны, спрос на СХД верхнего ценового диапазона (дороже $250 тыс.) снизился на 9,0 %, тогда как продажи изделий начального уровня (дешевле $25 тыс.) упали на 8,0 %. 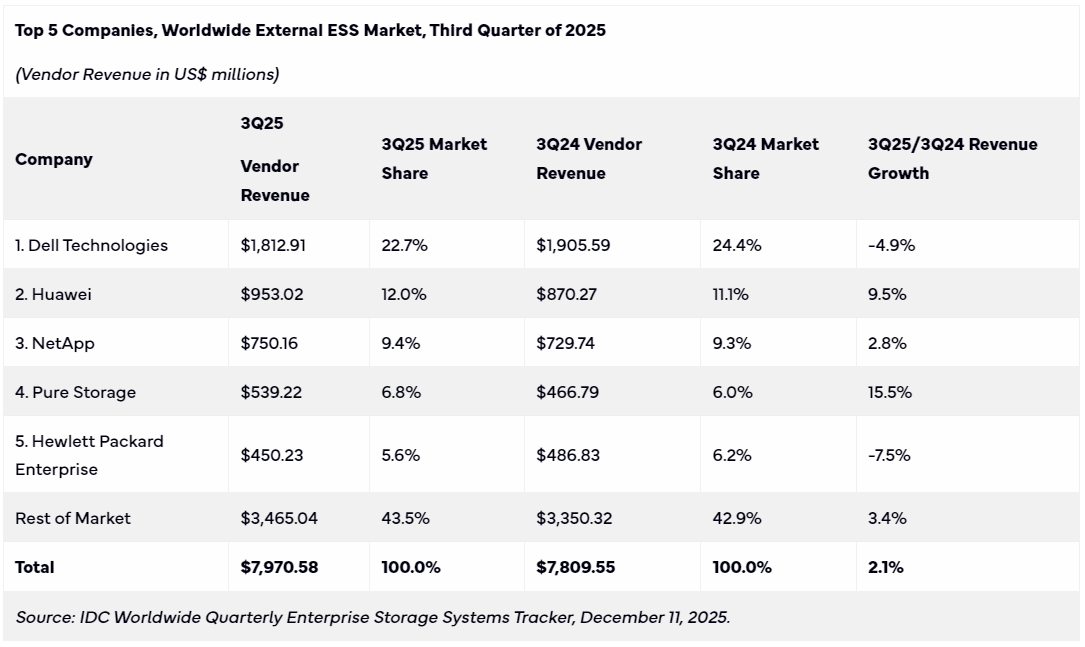
Источник изображения: IDC С географической точки зрения самый высокий рост отмечен в Японии, Канаде и регионе EMEA (Европа, Ближний Восток и Африка) — на 14,4 %, 12,6 % и 10,5 % соответственно. В Китае продажи поднялись на 9,5 % по отношению к III кварталу прошлого года, в Азиатско-Тихоокеанском регионе (без учёта КНР и Японии) — на 8,6 %. В Латинской Америке произошло снижение на 0,9 %, тогда как в США рынок сократился на 9,9 %. Лидером сектора является Dell Technologies с выручкой в размере $1,81 млрд и долей в 22,7 %. На втором месте располагается Huawei с $953,02 млн и 12,0 %, а замыкает тройку NetApp с $750,16 млн и 9,4%. Четвёртая строка в рейтинге досталась Pure Storage, продажи которой составили $539,22 млн, рыночная доля — 6,8 %. На пятой позиции находится НРЕ с $450,23 млн и 5,6 %. Все прочие отраслевые игроки вместе взятые получили $3,47 млрд, заняв 43,5 %.
12.12.2025 [21:35], Руслан Авдеев
Крошечные чипы для гигантской экономии: PowerLattice пообещала удвоить производительность ИИ-ускорителей на ваттЕсли энергоснабжение организовано неэффективно, на обеспечение работы ИИ-ускорителя мощностью 700 Вт может понадобиться и 1700 Вт. Решить это проблему поможет стартап PowerLattice, который миниатюризировал и переупаковал высоковольтные регуляторы, сообщает IEEE Spectrum. В компании утверждают, что её новые чиплеты позволяют снизить реальное энергопотребление наполовину, удвоив таким образом производительность на ватт. Чиплеты можно разместить максимально близко к вычислительным кристаллам. Традиционные системы питания ИИ-чипов преобразуют переменный ток из сети в постоянный, а затем понижают напряжение до уровня, подходящего ускорителям (порядка 1 В). При значительном падении напряжения сила тока на финальном участке пути к чипу резко возрастает для сохранения нужного уровня мощности. Именно здесь и происходят существенные энергопотери и тепловыделение, которые можно снизить, разместив питающую электронику как можно ближе к потребителю — на расстоянии в несколько миллиметров, а не сантиметров, т.е. буквально внутри чипа. 
Источник изображения: PowerLattice PowerLattice упаковала все необходимые компоненты в один чиплет размеров с пару ластиков, которые ставятся на карандаши. Чиплеты располагаются под подложкой корпуса вычислительного чипа. Одной из ключевых задач было уменьшение индукторов, помогающих поддерживать стабильное выходное напряжение. Пришлось применять специальный магнитный сплав, позволяющий очень эффективно использовать пространство, работая на высоких частотах, в сто раз выше, чем при использовании традиционного варианта. Уникальность решения в том, что сплав сохраняет лучшие магнитные свойства на высоких частотах, чем сопоставимые материалы. Утверждается, что полученные чиплеты более чем в 20 раз компактнее по площади, чем современные стабилизаторы. При этом толщина каждого из них составляет всего 100 мкм, что сопоставимо с толщиной волоса. Такие чиплеты действительно можно размещать очень близко к кристаллам процессора. При этом заказчики могут использовать несколько чиплетов в зависимости от прожорливости и требований конкретных чипов. Энергорасход можно снизить на 50 %, обещает компания, но эксперты пока сомневаются в этом — для достижения такого уровня экономии нужно динамическое управление электропитанием в режиме реального времени в зависимости от текущей нагрузки, что с решением PowerLattice может быть недостижимо. 
Источник изображения: PowerLattice Сейчас PowerLattice тестирует свой продукт на надёжность, а первые клиенты получат чиплеты приблизительно через два года. Intel тоже работает над модулем Fully Integrated Voltage Regulator, которая тоже помогает решить похожие проблемы. В самом стартапе Intel в качестве конкурента не рассматривается, поскольку подход у компаний разный, кроме того, Intel вряд ли будет предлагать свои решения конкурирующим производителям чипов. Эксперты утверждают, что ещё 10 лет назад у компании не было шансов на успех, поскольку поставщики процессоров давали гарантию на них только при покупке их же модулей питания. Например, Qualcomm продавала свои чипсеты только вкупе с чипами управления питанием её же производства. Однако сейчас всё чаще практикуется гетерогенный подход, когда заказчики комбинируют компоненты разных компаний для оптимизации своих систем. Хотя поставщики уровня Intel и Qualcomm, вероятно, будут иметь фору при работе с крупными клиентами, более мелкие разработчики чипов и ИИ-инфраструктуры, возможно, будут искать альтернативные модули управления электропитанием. |
|

