Материалы по тегу: ии
|
23.04.2026 [11:38], Сергей Карасёв
Selectel представил российский «AI-Сервер» с поддержкой до 16 GPUРоссийский провайдер облачной инфраструктуры Selectel анонсировал «AI-Сервер» — высокопроизводительную систему формата 8U, ориентированную на ресурсоёмкие нагрузки, такие как обучение ИИ-моделей, инференс, рендеринг, финансовое моделирование, виртуальные рабочие столы и аналитика в реальном времени. В состав платформы входят плата Selectel SSE-MB-201 и специализированное шасси SSECH-812. Задействованы два процессора Intel Xeon 6 6500/6700 поколения Granite Rapids-SP. Поддерживается до 8 Тбайт оперативной памяти DDR5-6400 в виде 32 модулей. Могут быть установлены 12 накопителей с интерфейсом NVMe/SAS/SATA, а также два SSD типоразмера M.2 с интерфейсом PCIe 5.0. Упомянуты контроллер BMC AST2600, модуль TPM 2.0, 176 линий PCIe (PCIe 5.0 / CXL и OCP 3.0) и два сетевых порта 1GbE. Сервер допускает монтаж до 16 ускорителей на базе GPU формата FHFL двойной ширины или до восьми ускорителей FHFL тройной ширины. В частности, могут применяться карты NVIDIA H100, H200, RTX Pro 6000 Blackwell Server Edition и др. Питание обеспечивают семь блоков мощностью 2000 Вт с сертификатом 80 Plus Platinum. 
Источник изображений: Selectel Selectel разрабатывает BIOS и BMC собственными силами: это, как утверждается, даёт полный контроль над процессом и возможность оперативно вносить изменения и дорабатывать функциональность в соответствии с запросами заказчиков. Подчёркивается, что усиленные подсистемы питания и охлаждения рассчитаны на высокую плотность ускорителей и длительную работу под нагрузкой. Конструкция упрощает обслуживание и эксплуатацию сервера в ЦОД.  «Запуск нового AI-сервера является частью стратегии Selectel по формированию собственного портфеля серверных решений, включая специализированные инфраструктурные продукты для задач в сфере ИИ. Новая аппаратная платформа обеспечит стабильную, быструю и предсказуемую работу AI-моделей в реальных условиях с полным контролем над данными и производительностью», — говорит компания.
23.04.2026 [09:09], Руслан Авдеев
Войн нет, энергии хватает, народ дружелюбный: Scala Data Centers призвала присмотреться к ИИ ЦОД в БразилииБразилия стремится привлечь инвестиции ИИ-бизнесов, полагаясь на геополитические преимущества региона. В частности, местный строитель ЦОД Scala Data Centers предлагает свои объекты иностранным бизнесам, в первую очередь из США и Китая, сообщает Datacenter Knowledge. В конце 2026 года должно начаться строительство т.н. Scala AI City, проект уже одобрен властями. Поддерживаемая DigitalBridge Group компания начала переговоры с техногигантами из США и КНР, желая привлечь в «ИИ-суперкампус» размером с город крупного клиента. Как утверждает Scala, нестабильность на Ближнем Востоке подчёркивает привлекательность бразильского рынка, изолированного от зон крупных конфликтов. По данным Scala, первый этап строительства обойдётся приблизительно в $500 млн, которые пойдёт непосредственно на инфраструктуру. В несколько раз больше потратит сам арендатор — облачный провайдер на ИИ-оборудование. Предполагается, что американские и китайские провайдеры могли бы использовать в Scala AI City отдельные ЦОД, не рискуя безопасностью своих данных. Компания уже получила разрешение на получение до 5 ГВт электроэнергии в окрестностях Порту-Алегри (Porto Alegre) в штате Риу-Гранди-ду-Сул — приблизительно столько потребляет Сан-Паулу или Лондон. 
Источник изображения: Scala Data Centers Наличие в Южной Америке многочисленных возобновляемых источников энергии и оптоволоконных магистралей, а также энергосеть с многочисленными перекрёстными подключениями делают Бразилию оптимальным региональным игроком в контексте бума ИИ ЦОД. Удары беспилотников по дата-центрам в ОАЭ и Бахрейне в целом заставляют компании переосмысливать принципы размещения в мире критической инфраструктуры. Власти штатов и муниципалитетов Бразилии всеми силами стремятся привлечь инвестиции в ЦОД, это должно стимулировать местную экономику и способствовать созданию технологических центров. Для сравнения, во многих штатах США бизнес и политики сталкиваются с недовольством общественности — иногда доходит до стрельбы и изгнания чиновников. Scala Data Centers была сформирована DigitalBridge в 2020 году после покупки ЦОД-активов у бразильской UOL Diveo. Японская SoftBank Group купила DigitalBridge приблизительно за $4 млрд в 2025 году. В текущем году компания планирует расширить и другие проекты ЦОД в Бразилии. Так, кампус в Сан-Паулу, куда уже инвестировано порядка R$12 млрд ($2,4 млрд), будет расширен до 600 МВт.
23.04.2026 [01:20], Владимир Мироненко
Для обучения и инференса — Google анонсировала ИИ-ускорители TPU 8t и TPU 8iGoogle представила два TPU восьмого поколения: TPU 8t (Sunfish) для обучения ИИ и TPU 8i (Zebrafish) для ИИ-инференса. Компания и раньше экспериментировала с различными вариантами TPU, в частности, со своими чипами пятого поколения V5p и V5e, но последние поколения, такие как Trillium и Ironwood, в основном следовали единому подходу. По словам Амина Вахдата (Amin Vahdat), старшего вице-президента и главного технолога Google по ИИ и инфраструктуре, TPU 8t и TPU 8i — результат десятилетней разработки (первые TPU были анонсированы в мае 2016 г.), специально созданные для обеспечения работы суперкомпьютеров следующего поколения с высокой эффективностью и масштабируемостью. Вахдат описывает TPU 8t как «мощную платформу для обучения», созданную для «сокращения цикла разработки моделей с месяцев до недель». Она предлагает в 2,8 раза лучшее соотношение цены и производительности, чем предыдущее поколение. 
Источник изображений: Google В TPU 8t используются векторные, матричные и SparseCore-ядра, дополненные 128 Мбайт SRAM и 216 Гбайт HBM3e (6,5 Тбайт/с). FP4-производительность составляет до 12,6 Пфлопс (также поддерживаются BF16/FP8/INT8). Для вертикального масштабирования используется межчиповый интерконнект (ICI) со скоростью 19,2 Тбит/с (в каждую сторону), для горизонтального — 400 Гбит/с. Кластер с TPU 8t может масштабироваться до 9,6 тыс. чипов, предлагая 2 Пбайт памяти HBM, 121 Эфлопс и вдвое большую межчиповую пропускную способность по сравнению с Ironwood, позволяя самым сложным моделям использовать единый, огромный пул памяти. 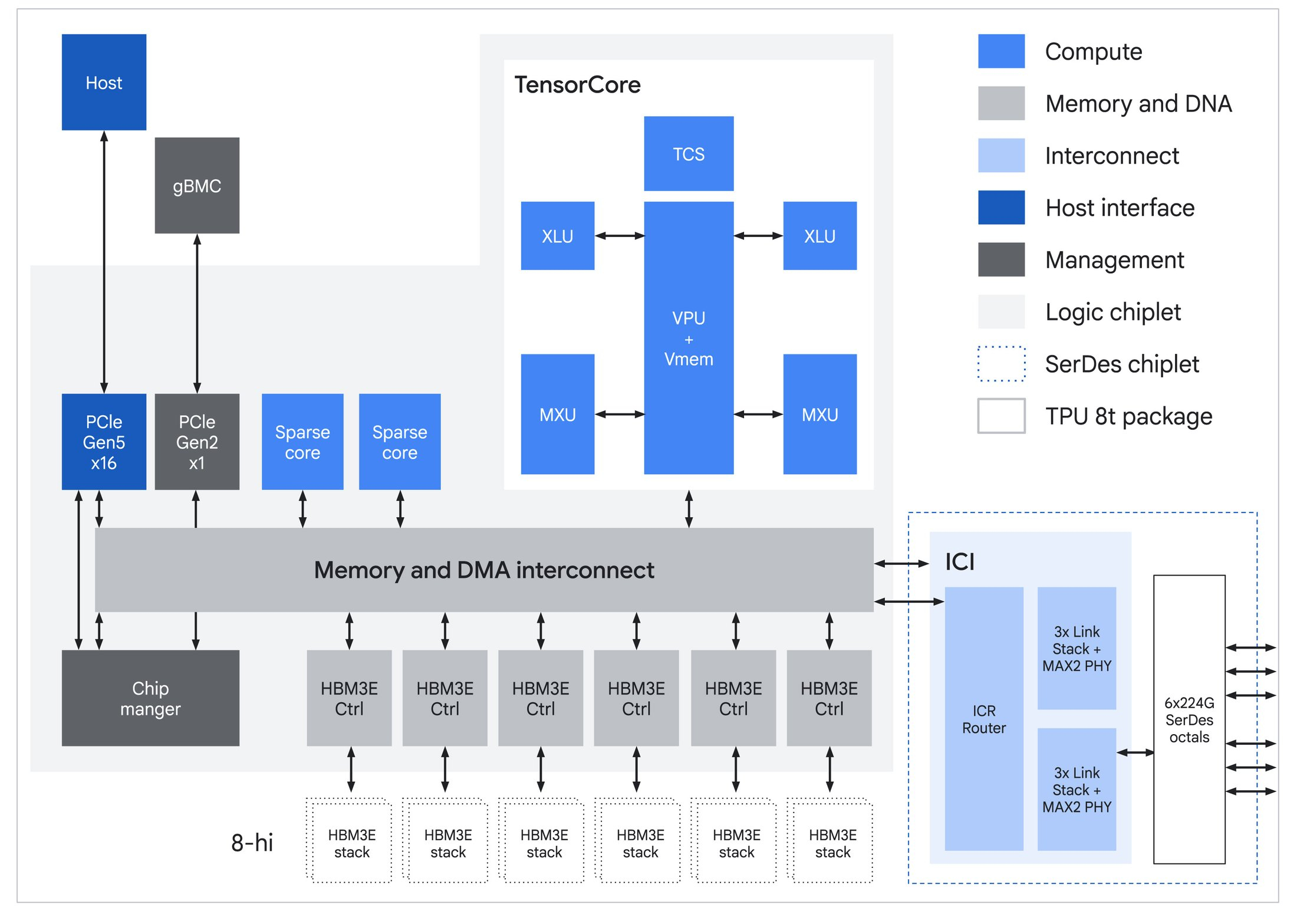 8t-кластеры объдиняет сеть Virgo Network, которая использует плоскую двухуровневую неблокирующую топологию, обеспечивает четырёхкратное увеличение пропускной способности в ЦОД и построена на коммутаторах с высокой степенью защиты, что сокращает количество сетевых уровней. В рамках одного ЦОД Virgo Network позволяет объединить до 134 тыс. чипов, что даёт до 47 Пбит/с неблокирующих соединений и более 1,6 Ифлопс с почти линейным масштабированием. А в рамках нескольких ЦОД в единый кластер можно объединить более 1 млн TPU. 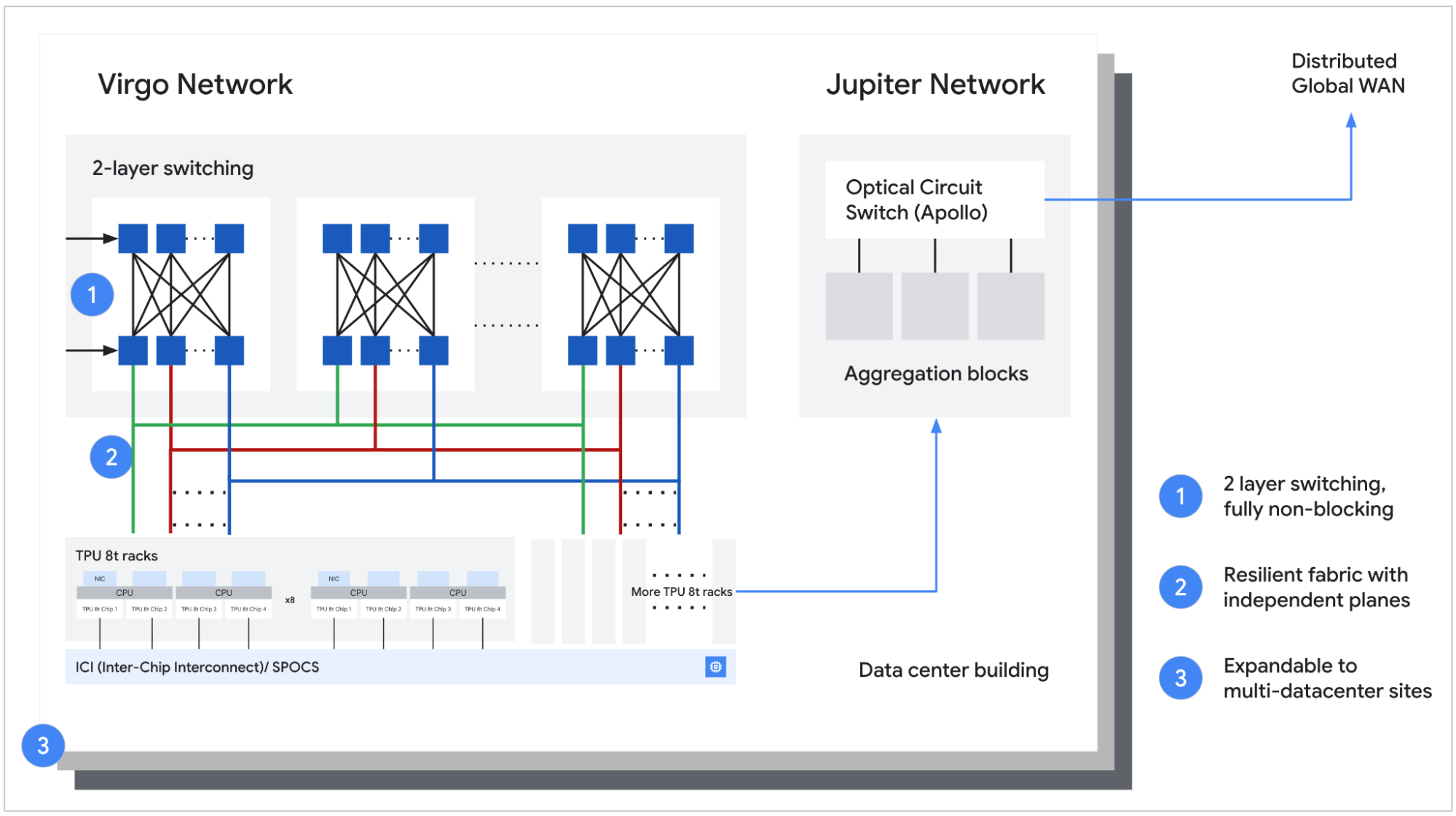 В TPU 8t используются технологии TPUDirect RDMA и TPUDirect Storage. TPU Direct RDMA обеспечивает прямую передачу данных между HBM и NIC, минуя CPU и DRAM хоста, а TPUDirect Storage напрямую связывает память TPU и СХД, таким как 10T Lustre, которая обеспечивает до 10 Тбайт/с, что даёт на порядок более быстрый доступ к хранилищу в сравнении с Ironwood и позволяет доставлять петабайты данных к ускорителям. 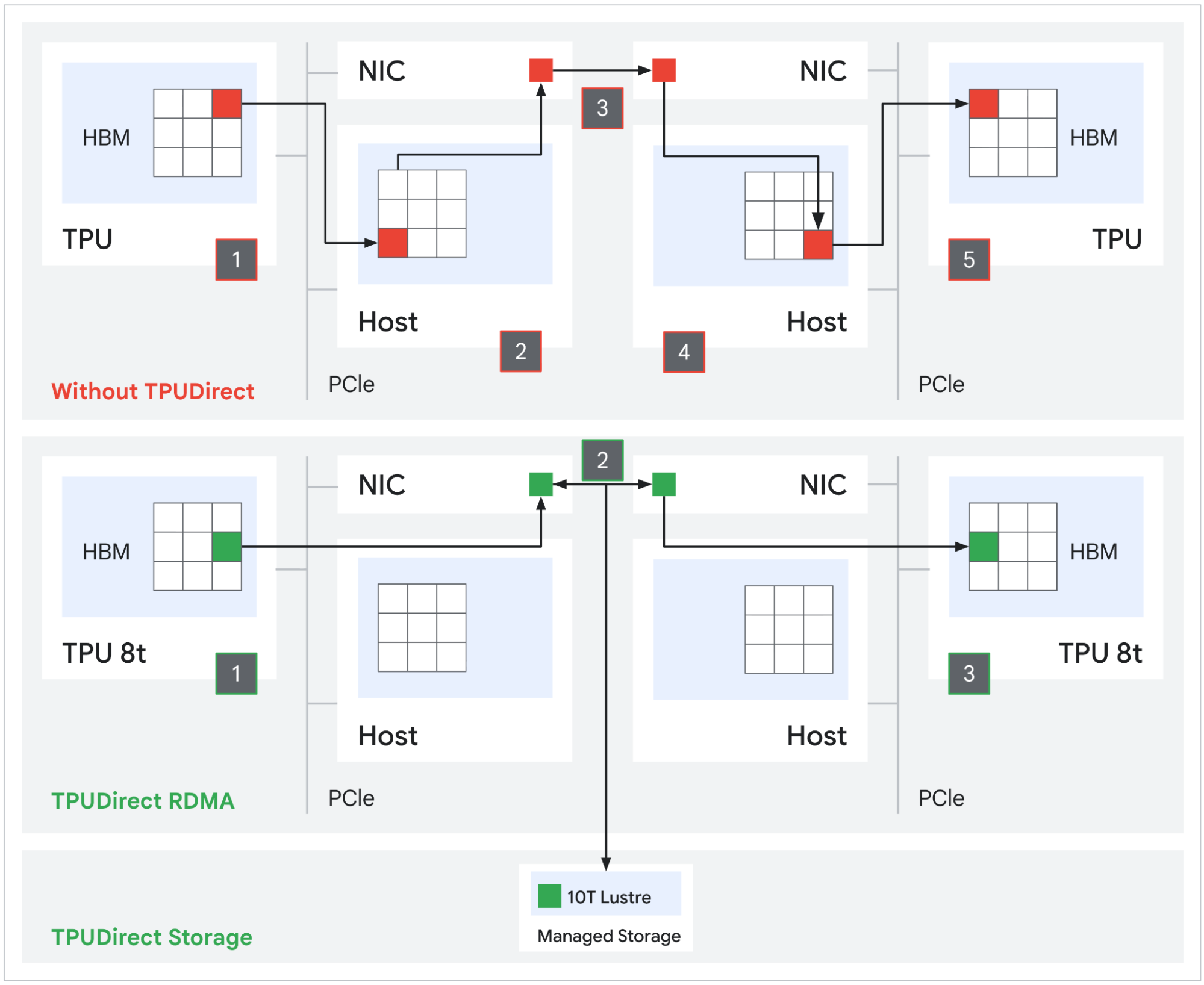 Кроме того, TPU 8t получили расширенные возможности RAS. К ним относятся телеметрия в реальном времени для десятков тысяч чипов, автоматическое обнаружение неисправных каналов ICI и перенаправление трафика без прерывания задания, а также оптическая коммутация каналов (OCS), которая перенастраивает оборудование в случае сбоев без участия человека. Всё это позволяет довести уровень утилизации чипа до 97 %.  В свою очередь, TPU 8i создан для обработки «сложной, совместной, итеративной работы множества специализированных агентов», которые появляются с развитием агентного ИИ. TPU 8i использует 288 Гбайт памяти HBM (8,6 Тбайт/с) в паре с 384 Мбайт SRAM — втрое больше, чем в предыдущем поколении. По словам Google, такой объём SRAM помогает TPU 8i удерживать большую часть KV-кеша на кристалле, что значительно сокращает время простоя ядер во время декодирования длинных контекстов. Компания отказалась от SparseCores в пользу нового встроенного механизма ускорения коллективных операций (CAE), снижая задержки на уровне кристалла и разгружая коллективные коммуникации, которые в противном случае привели бы к простою тензорных ядер чипа, отметил The Register. 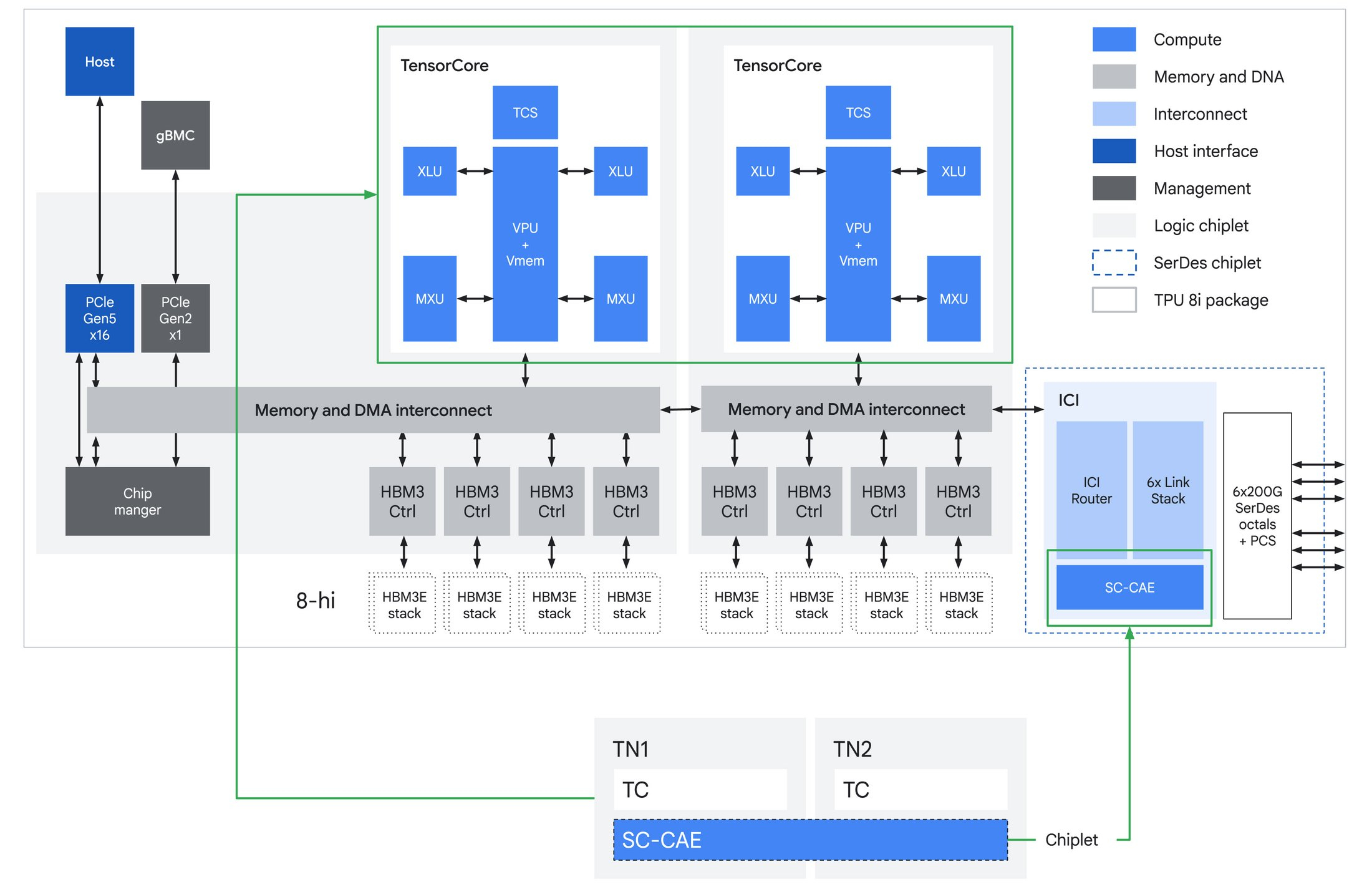 TPU 8i масштабируется до 1152 чипов в одном кластере (впрочем, в каждый момент активно не более 1024): 11,6 Эфлопс и 331,8 Тбайт HBM. ICI у 8i такой же, что у 8t, однако для объединения чипов используется топология Boardfly вместо 3D-тора, поскольку для MoE-инференса важно меньшее количество сетевых переходов между чипами. Эти инновации обеспечивают на 80 % лучшую производительность на доллар по сравнению с предыдущим поколением, позволяя предприятиям обслуживать почти вдвое больше клиентов при тех же затратах, сообщила компания. 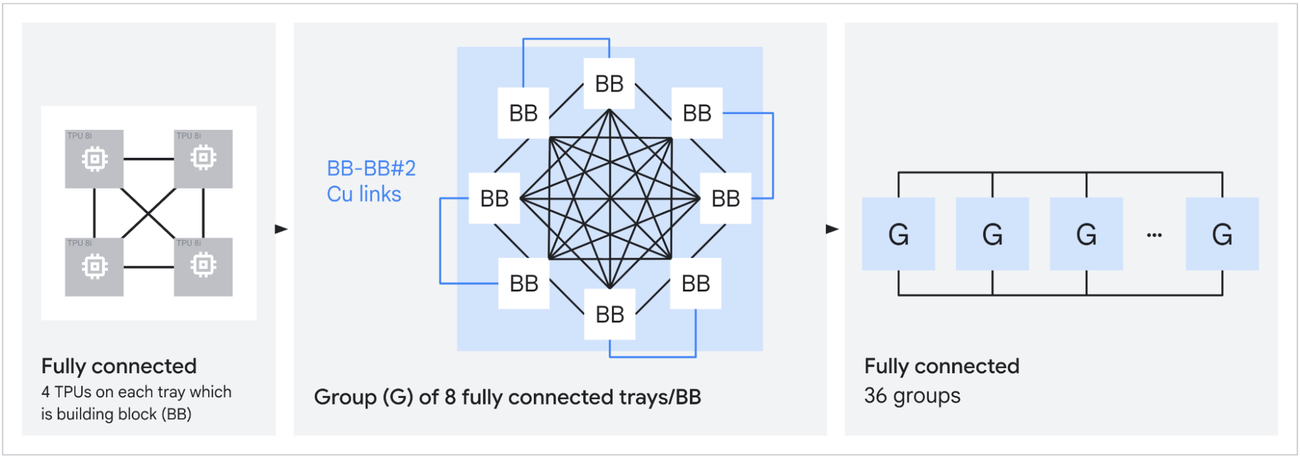 Как TPU 8t, так и 8i работают на базе собственного Arm-процессора Axion и поддерживают СЖО. Компания также заявила, что оптимизировала эффективность всей системы для обеспечения интегрированного управления питанием, которое может регулировать потребление энергии в зависимости от спроса в реальном времени, что приводит к повышению производительности на ватт до двух раз по сравнению с Ironwood. 
Фото: Sundar Pichai TPU 8 станут общедоступными на Google Cloud Platform позже в этом году в виде отдельных инстансов или как часть полнофункциональной платформы AI Hypercomputer, которая объединяет все сетевые ресурсы, хранилище, вычислительные мощности и ПО, необходимые для развёртывания или обучения LLM в масштабе. Также ожидается, что вскоре Google представит TPU v8e (Humufish). 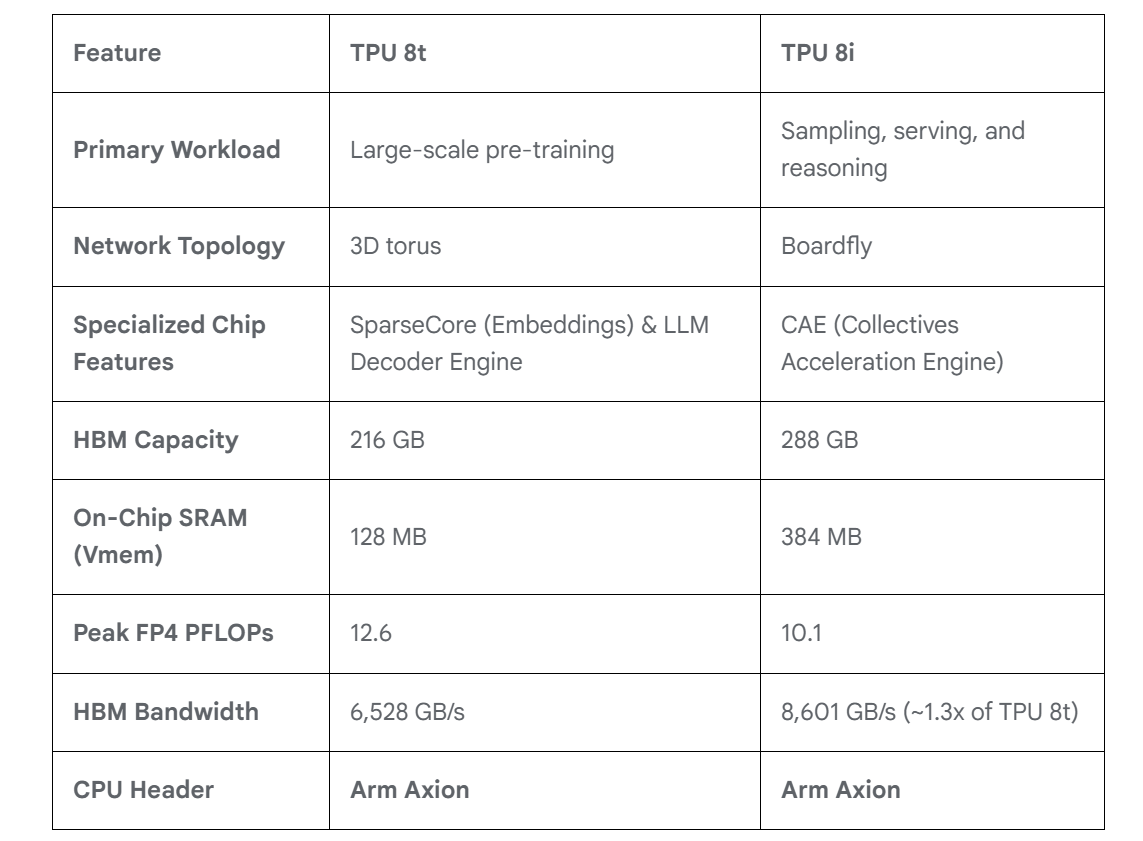
22.04.2026 [15:37], Руслан Авдеев
Anthropic ищет аналитика для оценки геополитических рисков и угроз персоналу, офисам и дата-центрамКомпания Anthropic ищет «аналитика в области геополитической разведке» (Geopolitical Intelligence Analyst), готового оценивать риски для её сотрудников и бизнес-процессов со стороны государств, сообщает Datacenter Dynamics. Специалист войдёт в состав глобальной команды компании, занимающейся вопросами безопасности, разведки и защиты. Предполагается, что аналитик станет «проводить сбор и анализ развединформации из всех источников» — для выявления, оценки и выстраивания приоритетов в сфере геополитических рисков и угроз со стороны государственных структур «для компании Anthropic, её персонала и деятельности». В том числе речь идёт о поиске возникающих очагов напряжённости геополитического уровня, политических изменений и макро-трендов, способных повлиять на работу Anthropic или стратегическое позиционирование компании. Согласно тексту вакансии, предполагается подготовка аналитики для руководства Anthropic, от срочных сводок до стратегических оценок регионов и стран. Предусмотрен учёт международной обстановки при принятии компанией решений, мониторинг потенциальных кризисов, политических изменений и глобальных тенденций. Необходима оценка рисков для поездок сотрудников, международной экспансии, размещения объектов и др. Также потребуется взаимодействие с внешними экспертами, государственными структурами и отраслевыми партнёрами — для обмена информацией об угрозах компаниям, действующих на рынке передовых ИИ-решений. Ожидается, что соискатель будет иметь степень бакалавра в области международных отношений, политологии или смежных дисциплин, иметь 5–8 лет опыта анализа геополитических рисков, независимо действовать с минимальным контролем со стороны руководства, а также работать по гибкому графику, постоянно находясь на связи в случае международных кризисов и важных геополитических событий в целом. 
Источник изображения: mostafa meraji/unspalsh.com Сейчас компания работает из США, её штаб-квартира находится в Сан-Франциско, а дата-центры строятся по всей стране. Имеются офисы в Германии, Франции, Ирландии, Индии и Швейцарии. Дополнительно компания рассчитывает открыть региональные штаб-квартиры в Великобритании и Австралии. Также в Европе и Австралии планируется аренда ЦОД. Геополитические риски глобальной инфраструктуре ЦОД нельзя игнорировать, поскольку только в последние недели Иран поразил несколько дата-центров американских компаний в ОАЭ и Бахрейне, а также пригрозил атаковать строящийся в рамках проекта OpenAI Stargate гигантский ЦОД G42 в ОАЭ. OpenAI сталкивалась с угрозами и в США, хотя речь шла об отдельных лицах, а не собственно государстве. Так, нападению дважды подвергся дом главы компании Сэма Альтмана (Sam Altman). Сама Anthropic тоже стала жертвой угроз, но в её случае к этому приложили руку непосредственно американские власти. Пентагон назвал Anthropic угрозой для цепочки поставок после того, как компания отказалась предоставлять услуги на условиях военного ведомства, требовавшего организовать массовое наблюдение и поддержку использования полностью автономного оружия. Ситуацией попытались воспользоваться британцы, которые готовят Anthropic предложение по расширению присутствия в Соединённом Королевстве. В частности, якобы будет предложено расширение офиса Anthropic в Лондоне и «двойной листинг».
22.04.2026 [13:12], Владимир Мироненко
xAI готова купить ИИ-стартап Cursor за $60 млрд или заплатить $10 млрд в рамках партнёрстваSpaceX, которая не так давно слилась с xAI, заявила, что заключила соглашение о сотрудничестве с ИИ-стартапом Cursor, получив право приобрести его за $60 млрд в конце этого года или заплатить $10 млрд за совместную работу. Компания Илона Маска сообщила в соцсети Х, что сейчас работает с Cursor над созданием «лучшего в мире ИИ для программирования и работы со знаниями». «Сочетание передового продукта Cursor и его распространения среди опытных инженеров-программистов с суперкомпьютером Colossus компании SpaceX, эквивалентным миллиону H100, позволит нам создать самые полезные в мире модели», — отметила SpaceX. Colossus — кластер суперкомпьютеров xAI в Мемфисе (Memphis), который компания позиционирует как крупнейший в мире. 
Источник изображения: Cursor Илон Маск (Elon Musk), основатель и генеральный директор SpaceX, в феврале объединил компанию со своим ИИ-стартапом xAI в рамках сделки, оцененной им в $1,25 трлн. Эта сделка должна помочь в реализации планов компании по запуску ЦОД на орбите. Теперь он готовится вывести объединённую компанию на биржу в рамках рекордного IPO, которое, как ожидается, состоится в июне. Генеральный директор Cursor Майкл Труэлл (Michael Truell) заявил, что он «рад сотрудничать с командой SpaceX для масштабирования (ИИ-модели) Composer». «Значительный шаг на нашем пути к созданию лучшего места для программирования с использованием ИИ», — отметил он, сообщает CNBC. По данным источников CNBC, Cursor ведёт переговоры о привлечении финансирования в размере $2 млрд при её оценке более чем в $50 млрд. Ожидается, что одним из лидеров предстоящего раунда финансирования станет Andreessen Horowitz, также в нём примут участие NVIDIA и Thrive Capital. Andreessen и NVIDIA также ранее поддержали xAI. Для Маска эта сделка означает шанс догнать конкурентов в области ИИ — OpenAI, создавшую ИИ-агента Codex, и Anthropic, разработчика LLM Claude. Впрочем, некоторые эксперты отмечают, что фактическое использование вычислительных мощностей Colossus гораздо ниже, чем у конкурентов, поэтому такая сделка гораздо важнее для xAI, чем для Cursor.
22.04.2026 [10:45], Сергей Карасёв
Foxconn наладит массовое производство CPO-коммутаторов в III квартале 2026 годаТайваньский контрактный производитель электроники Foxconn начал пробные поставки коммутаторов с интегрированной оптикой CPO (Co-Packaged Optics). Об этом, как сообщает DigiTimes, рассказал Брэнд Ченг (Brand Cheng), председатель совета директоров Foxconn Industrial Internet (FII) — подразделения, которое специализируется на сетевых продуктах для облачных платформ. По его словам, отгрузки образцов CPO-коммутаторов FII организовала в I квартале 2026-го, тогда как их массовое производство запланировано на III четверть текущего года. Ожидается, что спрос на такое оборудование будет стремительно расти. По данным отраслевых исследований, продажи CPO-коммутаторов увеличатся с примерно 23 тыс. единиц в 2026 году до более чем 200 тыс. штук в 2030-м. Таким образом, прогнозируемый показатель CAGR (среднегодовой темп роста в сложных процентах) составляет 144 %. Как отмечает Ченг, FII рассчитывает на годовой объём продаж CPO-коммутаторов более 10 тыс. штук. По оценкам компании, выпуск таких устройств обеспечит существенно более высокую валовую прибыль по сравнению с нынешними продуктами 400–800G. Подчёркивается, что экосистема технологий CPO развивается в комплексе с архитектурами NVIDIA QuantumX и SpectrumX, а также Broadcom Tomahawk. Речь идёт о проектировании специализированных чипсетов и оптических компонентов, внедрении передовых технологий упаковки, системной интеграции и пр. По сложности такие решения значительно превосходят традиционные сетевые устройства. 
Источник изображения: Foxconn Ченг также сообщил о масштабировании производства ИИ-ускорителей NVIDIA GB200 и GB300. Кроме того, наблюдается рост заказов на выпуск ASIC-изделий со стороны крупнейших облачных провайдеров: ожидается, что отгрузки таких продуктов значительно увеличатся во II половине года. Ченг подчеркнул, что более 60 % основных элементов серверных ИИ-стоек теперь производится собственными силами. Компания сформировала необходимые запасы компонентов, в том числе чипов памяти, для выполнения заказов в сфере ИИ, включая выпуск GB200 и GB300. В 2025 году выручка FII составила ¥902,89 млрд ($132,36 млрд), что на 48,2 % больше, чем годом ранее. При этом чистая прибыль поднялась на 51,99 %, достигнув ¥35,286 млрд ($5,17 млрд). Выручка в облачном сегменте составила ¥602,679 млрд ($88,35 млрд), увеличившись на 88,7 % в годовом исчислении: на неё пришлось почти 70 % от общего объёма поступлений.
22.04.2026 [01:35], Владимир Мироненко
MWS: в России продолжается олигополизация IT-рынка, а самым конкурентным рынком ПО остаётся рынок ИИСогласно исследованию MWS Cloud, на российском ИТ-рынке (ПО и оборудование) продолжается процесс олигополизации. В частности, на рынке ПО в 2026 году на Топ-5 компаний приходилось 58 %, тогда как годом ранее их доля составляла 56,8 %, а в 2022 — 52,8 %. Лидером по олигополизации оказался рынок платёжных систем, где доля Топ-5 игроков составила 93 %, а самым конкурентным — рынок ИИ, где их доля равна 36 %. В 2026 году на рынке облаков на Топ-5 игроков придётся 74 % рынка, тогда как в 2022 году на них приходилось 63 %. На рынке ERP и бухучёта на Топ-5 компаний придётся 67 % (в 2022 году — 66 %), HR и ИБ-сервисов — 62 % (в 2022 году — HR — 57 %, ИБ-сервисов — 55 %), ПО для взаимодействия с клиентами — 59 % (33 %), систем управления данными — 56 % (51 %), управления бизнесом — 54 % (53 %), производственного ПО — 51 % (50 %), систем продуктивности — 44 % (38 %), платформенного ПО — 42 % (38 %). 
Источник изображения: MWS Аналогичная ситуация наблюдается и на рынке оборудования в России. На Топ-5 компаний в среднем приходится 57,6 % рынка (в 2025 году — 54,8 %). Наибольшая доля Топ-5 компаний отмечена на рынке СХД — 75 % (62 % в 2022 году); далее следуют рынок серверов — 58 % (51 %), сетевого оборудования и ИБ — 57 % (в 2022 году 5 7% — на рынке сетевого оборудования, 56 % — на рынке ИБ-оборудования), оборудования для ЦОД — 41 % (59 %). Также укрепляются позиции Топ-5 компаний на рынке ИТ-услуг. Если в 2022 году в среднем их доля составляла 44 %, то в 2025 году она увеличилась до 51 %, а в 2026 году — до 53 %. Лидирует по олигополизации рынок колокации, где в 2026 году доля Топ-5 компаний составит 89 % (в 2022 году — 84 %). За ним следует рынок ИИ-сервисов — 71 % (53 %), далее — консалтинг — 64 % (51 %), заказная разработка ПО — 47 % (28 %), аутсорсинг — 43 % (38 %), системная интеграция — 35 % (31 %), услуги ИБ — 24 % (27 %).
21.04.2026 [22:14], Руслан Авдеев
Fermi 2.0: из проекта мега-ЦОД им. Трампа ушёл не только гендир, но и главбухМногочисленные проблемы Fermi America, занимающейся эпохальным проектом мега-ЦОД им. Дональда Трампа (The President Donald J. Trump Advanced Energy and Intelligence Campus), сообщает The Register. В последние дни компания, отвечающая за строительство 17-ГВт кампуса Project Matador (HyperGrid) площадью 2,9 тыс. га в Западном Техасе, пережила серию потрясений. Сооснователь компании Тоби Нойгебауэр (Toby Neugebauer) отказался от поста генерального директора, следом подал в отставку и финансовый директор Майлз Эверсон (Miles Everson). Впрочем, оба остались членами совета директоров. Fermi не так давно столкнулась с проблемами при закупках энергетического оборудования, а также с поиском якорного арендатора мощностей своего будущего кампуса. Ранее сообщалось, что некий арендатор найден в ноябре 2025 года, но позже он отказался от сделки. Неофициально глава Fermi говорил об AWS, но фактически ни одна из сторон не признала факт переговоров. Среди других потенциальных клиентов также называлась Palantir. В результате инвесторы подали к компании коллективный иск. По данным экспертов Stifel, в минувшие выходные компания провела конференцию с целью успокоить инвесторов. По словам компании, в уходе Нойгебауэра есть и положительные стороны. Беспокойство, вызванное соответствующей новостью, понятно, но в смене CEO нет ничего экстраординарного. Кроме того, после объявления об уходе в пятницу отмечена активизация переговоров с клиентами — высока вероятность того, что проблема была именно в самом Нойгебауэре, поэтому в дальнейшем переговоры, вероятно, упростятся. 
Источник изображения: Fermi America Нойгебауэр уже столкнулся с многочисленными судебными исками, в одном из которых его обвиняют в мошенничестве. Сам бизнесмен тоже подал в суд на некоторых бывших инвесторов, в том числе известных политиков и бизнесменов, связанных PayPal, Palantir и Founders Fund. Более того, Нойгебауэ недавно вступил в перепалку с министром торговли США Говардом Лютником (Howard Lutnick), который, по его мнению, частично блокирует реализацию Project Matador. Так или иначе в понедельник были анонсированы изменения, получившие название Fermi 2.0. Ведущий независимый член совета директоров Fermi Мариус Хаас (Marius Haas) назначен председателем совета. Ранее он занимал руководящие должности в Compaq, HPE, KKR и Dell. Он же будет курировать поиск нового генерального директора. В качестве временной меры сформирован т.н. «Офис генерального директора» (Office of the CEO) — структура с двойным руководством, которую будут возглавлять недавно назначенный сопрезидент и бывший операционный директор Хакобо Ортис Бланес (Jacobo Ortiz Blanes), а также бывший советник совета директоров Анна Бофа (Anna Bofa), имеющая опыт работы в Google, Dropbox, Pinterest и Meta✴. Параллельно ведутся переговоры с кандидатом на должность временного финансового директора. Также компания прибегла к услугам кадрового агентства Heidrick & Struggles. Кроме того, появятся два новых места в совете директоров. Дополнительно компания формирует новую штаб-квартиру в Далласе (Техас) и обустраивает офис в Амарилло (Техас) — в непосредственной близости от места реализации Project Matador. В понедельник акции Fermi закрылись с падением на 15 %, их цена оказалась на 80 % ниже максимума октября 2025 года, когда они стоили $29,08.
21.04.2026 [21:56], Андрей Крупин
«Турбо облако» представило платформу для быстрого запуска ИИ-моделей с поминутной тарификацией и автоматическим масштабированиемОблачный провайдер «Турбо облако» (входит в коммерческий IT-кластер «Ростелекома»), запустил Inference Platform — платформу для развёртывания и эксплуатации моделей искусственного интеллекта, в основу которой положены ускорители NVIDIA H200 SXM с интерконнектом InfiniBand. Inference Platform поддерживает различные типы ИИ-моделей, включая open source-решения. Пользователи могут загружать собственные модели или использовать контейнерные образы, разворачивая их в облачной среде без дополнительных инфраструктурных настроек. Сервис обеспечивает автоматическое масштабирование ресурсов (автоскейлинг) в зависимости от нагрузки. Такой подход позволяет оптимизировать использование GPU и снизить затраты при нерегулярной нагрузке, говорит компания. Платформа поддерживает распределённый инференс, позволяя запускать модели объёмом до 1 тплн параметров с размещением на нескольких вычислительных узлах. Также доступно гибкое использование GPU-ресурсов, включая их дробление под задачи меньшего объёма. Дополнительным преимуществом является поминутная тарификация ресурсов, гарантирующая более точный контроль расходов по сравнению с почасовой оплатой. 
Источник изображения: Omar Lopez-Rincon / unsplash.com В настоящее время новый продукт доступен для тестирования: компании могут оценить его возможности на собственных моделях.
21.04.2026 [20:48], Владимир Мироненко
В ВТБ призвали к партнёрству с Китаем для развития суверенного ИИРазвивать суверенные технологий ИИ в России, включая использование больших языковых моделей (LLM) и вычислительных мощностей, необходимо в партнёрстве с дружественными странами, прежде всего, с Китаем, заявил заместитель руководителя технологического блока ВТБ. Он подчеркнул, что при этом важно учитывать необходимость защиты данных россиян, которые используются при обучении ИИ. Топ-менеджер отметил, что открытые LLM, разработанные китайскими компаниями, работают «чуть лучше», чем российские модели, но их использование несёт определенные риски для технологического суверенитета, так как они созданы за пределами России. Использование российских моделей, в частности, от «Яндекса» и Сбера, снимает часть этих рисков. Вместе с тем топ-менеджер ВТБ считает, необходимо использовать лучшие технологии, чтобы не оказаться в числе отстающих: «Для того, чтобы наши модели были не хуже, мы стараемся обучать их на обезличенных данных. И считаем, что партнёрство с Китаем — это правильный возможный вариант, они действительно сейчас по многим направлениям лидируют». Это также относится к развитию суперкомпьютеров, необходимых для ИИ: «Если взять вычислительные мощности, которые есть за рубежом и которые есть у нас, понятно, что те суперкомпьютеры, которые сейчас работают, в первую очередь в США, многократно превышают те мощности, которые есть в России. И это тоже проблема». 
Источник изображения: Hanson Lu/unsplash.com Он добавил, что в рамках кооперации уже запущены большие совместные лаборатории с китайскими коллегами. Также начинают осуществлять сборку серверов в России с китайскими GPU: «Это — будущее, так как без кооперации не обойтись. Мы большая и сильная страна, но есть другие большие и сильные страны, вместе с которыми мы достигнем больших результатов». Также было отмечено, что применение ИИ-технологий в финансовом секторе усложняется в связи с необходимостью выполнения требований по соблюдению банковской тайны и защите персональных данных. Поэтому, для того чтобы использовать самые эффективные и популярные большие языковые модели, но при этом не допустить утечку данных, в ВТБ используют их on-premise, ограничивая их применение защищённым банковским контуром. «На сегодняшний день к такому режиму работы готовы наши российские большие языковые модели, в том числе YandexGPT и GigaChat», — сообщил топ-менеджер. |
|

