Материалы по тегу: ии
|
03.08.2026 [13:03], Руслан Авдеев
DeepSeek построит собственный гигаваттный ИИ ЦОД во Внутренней МонголииКитайская DeepSeek, стоящая за разработкой передовых ИИ-моделей, способных конкурировать с западными «флагманами», намерена построить большой дата-центр во Внутренней Монголии (Китай). Компания рассчитывает на создание кампуса ИИ ЦОД мощностью 1 ГВт в городском округе Уланчаб (Ulanqab), сообщает Bloomberg. По данным источников, локация расположена в 350 км к северо-востоку от Пекина. DeepSeek рассчитывает построить собственный объект, одновременно арендуя дополнительные мощности у других компаний. По некоторым данным, что в Уланчабе планируют реализовать проекты более дюжины компаний. DeepSeek намерена ввести в эксплуатацию хотя бы часть мощностей нового кампуса к концу следующего года или в начале 2028-го. Пока неизвестно, на какие ускорителях будет работать оборудование. Наиболее распространёнными в индустрии являются чипы NVIDIA, но в Китае безусловным «чемпионом» в этой сфере называется Huawei. Кроме того, ранее ходили слухи, что DeepSeek работает над собственными ускорителями, но в данном случае речь идёт скорее о чипах для обучения, а не инференса. Хотя лидерами в сфере ИИ считаются западные компании вроде OpenAI и Anthropic, тратящие десятки миллиардов долларов на вычислительные мощности, китайские конкуренты с DeepSeek в том числе стараются нагнать их. 1-ГВт кампус ЦОД будет значительно крупнее любого современного китайского проекта, хотя он и будет отставать от 3–5-ГВт инициатив американских компаний. Китайская Z.AI (ранее Zhipu) также работает над 1-ГВт объектом, оснащать который рассчитывают только ускорителями китайского производства. 
Источник изображения: Charles MingZ/unsplash.com Со среднегодовыми температурами около +5 °C, Уланчаб якобы обеспечивает благоприятную для ЦОД прохладу, помогающую снизить энергопотребление объекта за счёт экономии на охлаждении оборудования, благодаря чему локация может быть привлекательная для китайских IT-гигантов вроде China Mobile, пишет Bloomberg. DeepSeek — один из ключевых игроков в китайской стратегии, нацеленной на конкуренцию на мировом рынке ИИ. Ранее в прошлом году компания потрясла технологическую индустрию, представив ИИ-модель с передовыми характеристиками, созданную с помощью относительно небольших вычислительных ресурсов в сравнении с другими передовыми моделями. DeepSeek также — один из лидеров в предложении недорогих, open source сервисов и продуктов, угрожающих бизнес-планам американских компаний вроде OpenAI и Anthropic. Китайские ИИ-сервисы нередко обходятся пользователям в десять и более раз дешевле, чем американские альтернативы. В июле к гонке присоединилась китайская Moonshot, дебютировавшая с моделью Kimi K3, тоже способной тягаться с западными флагманскими моделями в бенчмарках. Китайские достижения вызывают у западного бизнеса опасения, что ключевой геополитический соперник США ускоренными темпами устраняет разрыв в сфере критически важных технологий. Помимо DeepSeek, Moonshot и Z.AI, существует множество агрессивных игроков, включая Alibaba Group Holding и MiniMax Group. DeepSeek начала готовиться к IPO и может подать соответствующую заявку ещё до конца 2026 года. Новости появились после того, как она привлекла рекордные $7 млрд в ходе последнего раунда финансирования, капитализация составила около $50 млрд. В администрации президента США считают, что она сумела обойти американские экспортные ограничения, использовав ускорители NVIDIA Blackwell в ЦОД во Внутренней Монголии, которые фактически не продаются в Китай официально. Тем временем OpenAI и Anthropic обвиняют китайского конкурента в «дистилляции» — использовании их моделей для обучения собственной с аналогичными возможностями. Проект DeepSeek во Внутренней Монголии может быть знаком того, что китайские компании наращивают финансовую поддержку строительства ИИ-инфраструктуры — в этой сфере исторически лидировали бизнесы из Кремниевой долины благодаря доступ к американским рынкам капитала. По оценкам главы NVIDIA Дженсена Хуанга (Jensen Huang), создание 1-ГВт ЦОД, оснащённого самыми передовыми ускорителями, потребует около $50 млрд инвестиций. Стоимость разных ЦОД может сильно отличаться в зависимости от разных факторов, с учётом локации и чипов, которые те используют. При этом ИИ ЦОД в Китае обычно обходятся значительно дешевле, чем в США. Автономный район Внутренняя Монголия — одна из перспективных китайских провинций, отмеченных в программе Eastern Data, Western Compute. Последний предполагает размещение больших вычислительных мощностей на относительно малоосвоенном западе КНР. Впрочем, программа не вполне оправдала себя — дата-центры простаивают, а для продажи их мощностей приходится прикладывать усилия.
03.08.2026 [09:48], Владимир Мироненко
Рынок облачных услуг во II квартале показал самый высокий темп роста за восемь летСогласно данным Synergy Research Group, затраты на облачные инфраструктурные услуги во II квартале 2026 года выросли год к году более чем на $43 млрд, достигнув $143 млрд. В предыдущем квартале объём глобального рынка облачных инфраструктур, темпы роста которого в годовом исчислении увеличиваются 11-й квартал подряд, составил $128,6 млрд — за всё это время рынок увеличился вдвое. Рост во II квартале достиг 43 %, что является самым высоким показателем за последние восемь лет. И основным драйвером этого ускоренного роста рынка стал генеративный ИИ. Среди ведущих провайдеров облачных услуг по-прежнему лидирует Amazon. За ней следуют Microsoft и Google, которые продолжают демонстрировать значительно более высокие темпы роста. Доля глобального рынка этих компаний во II квартале составила 28 %, 20 % и 15 % соответственно. Во втором эшелоне провайдеров облачных услуг самые высокие темпы роста были у CoreWeave, OpenAI, Oracle, Crusoe, Nebius, Anthropic и Nscale. 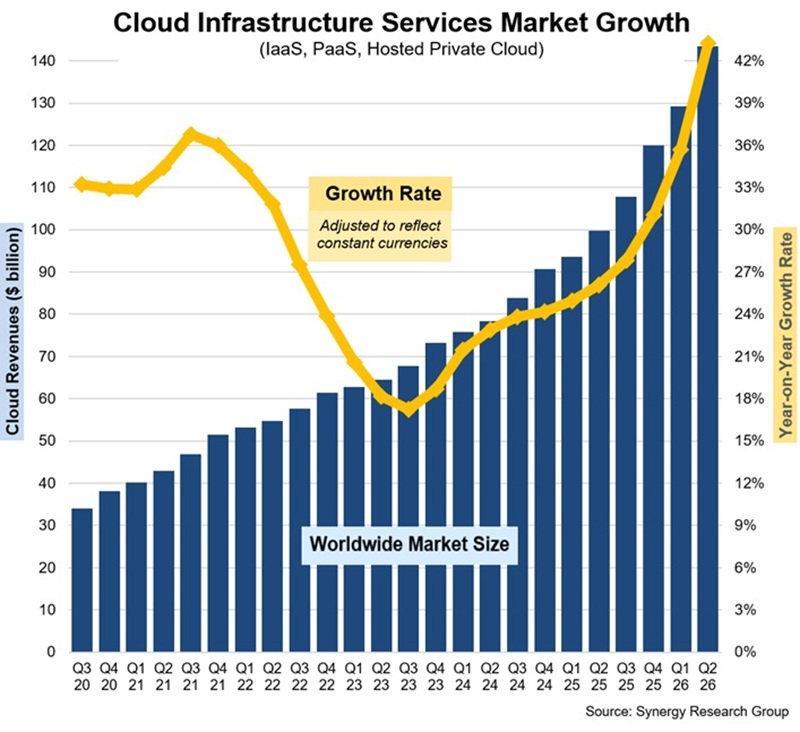
Источник изображения: Synergy Research Group Девять неооблаков вошли в число 40 крупнейших поставщиков облачных услуг исходя из доходов. Как сообщил Джон Динсдейл (John Dinsdale), главный аналитик Synergy Research Group, ИИ-технологии подстегнули облачный рынок и сейчас обеспечивают беспрецедентный рост. Основная часть рынка облачных инфраструктурных услуг приходится на публичные IaaS и PaaS, объёмы которых увеличились на 47 %. В сегменте публичных облаков на долю трёх лидеров приходится 67 % рынка. За последние два квартала доля США на мировом рынке увеличилась, что отражает масштабное развитие инфраструктуры в США как гипескейлерами, так и неооблаками. Впрочем, облачный рынок продолжает расти во всех регионах мира. Наиболее высокий рост показали Индия, Индонезия, Ирландия, Таиланд и Малайзия, темпы роста которых значительно превышают среднемировые. С большим отрывом лидируют США, которые намного превосходят по масштабам весь Азиатско-Тихоокеанский регион. Рынок США вырос на 49 % за минувший квартал, что значительно превышает среднемировой показатель. В Европе по-прежнему лидируют Великобритания и Германия, хотя наиболее высокий рост отмечен у Ирландии, Норвегии, Дании и Финляндии.
03.08.2026 [09:36], Руслан Авдеев
SpaceX/xAI построит четвёртый ЦОД в Мемфисе и избавится от «нелегальных» газовых турбин, заменив их на точно такие жеИлон Маск (Elon Musk) подтвердил строительство SpaceX/xAI (SpaceXAI) четвёртого ЦОД в Мемфисе (Теннесси). Попутно компания согласилась убрать 69 временных газовых турбин, питающих ЦОД в этом районе, сообщает Datacenter Dynamics. Не так давно экоактивисты подали против компании иск, заявив, что турбины установлены без правильно оформленных разрешений и их использование противоречит природоохранному закону Clean Air Act. Подконтрольная Маску xAI начала строить дата-центры в районе Мемфиса и Саутхейвена (Southaven) на границе штатов Теннеси и Миссури в 2024 году для размещения суперкомпьютеров Colossus. Компания в кратчайшие сроки возвела два дата-центра, а затем взялась за третий. В марте сообщалось, что SpaceXAI подала заявку на строительство ещё одного, четырёхэтажного здания площадью 28 985 м2 стоимостью $659 млн. Кроме того, компания намерена построить ещё один ИИ ЦОД в Техасе. Маск ответил на пост пользователя социальной сети X, опубликовавшего фото новой стройки на территории кампуса ЦОД xAI. По словам бизнесмена, на фото справа находится MINIHARD, который получит 220 тыс. NVIDIA GB300 с 800G-адаптерами, как и MACROHARDRR, но в улучшенной, более плотной конфигурации. Оба названия являются шуточной отсылкой к Microsoft. 
Источник изображения: S.E. Robinson, Jr./x.com Пока нет данных, хватит ли компании электроэнергии для дополнительных 220 тыс. ИИ-ускорителей GB300, на обслуживание которых, вероятно, потребуется 400 МВт. Компания заявляет, что в ЦОД близ Мемфиса она располагает 1 ГВт вычислительных мощностей, но сделанные в январе спутниковые снимки показали, что установленное охладительное оборудование рассчитано лишь на 350 МВт. В проспекте, выпущенном SpaceX перед IPO, заявлялось, что следующая фаза развития кампуса предусматривает внедрение ещё 220 тыс. ИИ-ускорителей и более 400 МВт вычислительной мощности. Размещение в районе Мемфиса дата-центров уже вызвало недовольство местных жителей и экоактивистов, в первую очередь из-за использования газовых турбин для обеспечения дата-центров энергией. Хотя именно это позволило компании быстро ввести в строй ЦОД, активисты жалуются, что из-за них ухудшилось качество воздуха в беднейших районах. Теперь заявляется, что компания уберёт со своей площадки 69 временных мобильных турбин в течение следующего года, как раз перед установкой постоянной электростанции мощностью 1,2 ГВт, разрешение на которую получено в марте. Временные турбины начнут убирать уже в августе, хотя для местных жителей мало что изменится — «постоянная электростанция» также будет состоять из 41 газовой турбины. В заявлении SpaceX сообщалось, что компания «выпустила согласованное распоряжение» с Департаментом качества окружающей среды Миссисипи, устанавливающее фиксированный график демонтажа 69 турбин. Также подчёркивается, что организована перенастройка электрооборудования для снижения уровня шума от объекта и минимизации воздействия на местных жителей. Примечательно, что буквально на днях сообщалось, что фактически xAI продолжает наращивать свою полузаконную газовую электростанцию для Colossus.
02.08.2026 [14:46], Сергей Карасёв
Supermicro представила серверные стойки со статической нагрузкой до 2500 кгSupermicro расширила ассортимент серверных стоек, анонсировав десять моделей для систем высокой плотности, ориентированных на ресурсоёмкие задачи ИИ и другие критические нагрузки. Дебютировали решения на базе стандартов OCP ORv3 и NVIDIA MGX, а также традиционные 19″ варианты. Новинки входят в продуктовое семейство Supermicro Data Center Building Block Solutions (DCBBS). Стойки могут поставляться в предварительно сконфигурированном виде, что упрощает и ускоряет развёртывание: заказчикам и интеграторам не нужно монтировать на объекте вычислительные узлы, сетевые компоненты, а также элементы подсистем питания и охлаждения. Все анонсированные устройства рассчитаны на статическую нагрузку до 2500 кг. Это позволяет размещать мощные ИИ-серверы с ускорителями на базе GPU, высокопроизводительное силовое оборудование и пр. Изделия проходят испытания на вибро- и сейсмическую устойчивость. Говорится о гибких возможностях в плане применения жидкостного охлаждения: стойки совместимы с блоками распределения охлаждающей жидкости (CDU) различных типов, теплообменниками на задней двери (RDHx) и пр. Силовые и сетевые кабели полностью изолированы. 
Источник изображения: Supermicro В число новинок входят стойки для платформ NVIDIA VR200/GB300 MGX в форматах 48U и 52U с вариантами ширины 600 и 750 мм. Кроме того, выпущены решения 44OU и 48OU стандарта ORv3 (типоразмера 21″). В традиционном 19″ исполнении доступны варианты 48U и 52U. Компания Supermicro отмечает, что её производственных возможностей достаточно для выпуска примерно 3 тыс. таких стоек в месяц. Из них около 2 тыс. могут комплектоваться СЖО.
01.08.2026 [15:39], Сергей Карасёв
10 DWPD для ИИ: ScaleFlux представила SSD-платформу для инференсаКомпания ScaleFlux анонсировала специализированную программно-аппаратную платформу на основе SSD для ресурсоёмких нагрузок ИИ-инференса. Предложенное решение может применяться в рамках архитектуры NVIDIA CMX — системы хранения данных, предназначенной для ускорения работы с контекстом в ИИ-инфраструктурах. Платформа ScaleFlux рассчитана на задачи с интенсивным использованием KV-кеша. Отмечается, что KV-блоки часто перезаписываются, хранятся разное время и могут асинхронно аннулироваться. Поэтому при инференсе, когда активно используется KV-кеш, создаётся повышенная нагрузка на SSD, что приводит к быстрому износу чипов флеш-памяти и к тому, что операторы дата-центров и гиперскейлеры вынуждены тратить огромные средства на закупку дополнительных накопителей и замену выходящих из строя устройств. 
Источник изображения: ScaleFlux Новая технология ScaleFlux призвана решить проблему. Платформа базируется на трёх ключевых принципах: анализ реального поведения рабочей нагрузки, разделение блоков KV-кеша с разными жизненными циклами и поддержание интенсивных рабочих нагрузок записи без чрезмерного увеличения ёмкости SSD или расходов на их замену. Основным элементом системы ScaleFlux является функция Flexible Data Placement (FDP): она позволяет группировать данные по их жизненному циклу (например, по сессии, вероятности повторного использования) и размещать их в отдельных физических областях накопителя. Это минимизирует внутреннее перемещение данных, а следовательно, снижает износ флеш-памяти. Платформа поддерживает более 200 потоков FDP-записи на один накопитель, обеспечивая гибкое разделение данных по типам нагрузок. Ещё одной составляющей решения ScaleFlux является телеметрия Context-Insight: она фиксирует ключевые метрики работы накопителя — задержки, глубину очереди, распределение размеров запросов, возраст данных, интервалы между записью и первым чтением, интенсивность повторного использования и пр. Для первоначального анализа рабочей нагрузки инструмент Context-Insight может использоваться в режиме «только SSD» — без внесения изменений в вышестоящие программные слои. При более глубокой интеграции система сопоставляет телеметрию SSD с метаданными приложения, включая идентификаторы сеансов и рабочих процессов, принадлежность KV-блоков, состояние жизненного цикла и т.д. Это позволяет операторам соотносить задержку и ресурс накопителей с конкретными классами рабочих нагрузок. В предварительных тестах применение платформы ScaleFlux с поддержкой FDP позволило сократить коэффициент усиления записи (Write Amplification) более чем в два раза по сравнению с традиционными хранилищами. С аппаратной точки зрения применяемые в составе системы ScaleFlux накопители рассчитаны на 7–10 и более полных перезаписей в сутки (DWPD) на протяжении пяти лет для нагрузок с использованием KV-кеша.
01.08.2026 [13:33], Владимир Мироненко
Amazon повысит капзатраты в связи с ростом цен на память и высоким спросом на ИИ-сервисыAmazon опубликовала финансовые результаты за II квартал 2026 года, продемонстрировав заметное увеличение прибыли и выручки, чему способствовал стремительный рост облачного бизнеса, укрепивший уверенность инвесторов в масштабных инвестициях компании в ИИ, пишет Reuters. Издание отметило, что основным фактором этого роста стал спрос на ИИ, что заставило компанию снова повысить прогноз капитальных затрат. Акции Amazon выросли почти на 14 %. «Рынок больше не сомневается в реальности спроса на ИИ. Новая разделительная линия — это вопрос о том, приводят ли беспрецедентные расходы к видимому, краткосрочному росту выручки и маржи», — сказал Билл Бирмингем (Bill Birmingham), управляющий директор REX Financial. 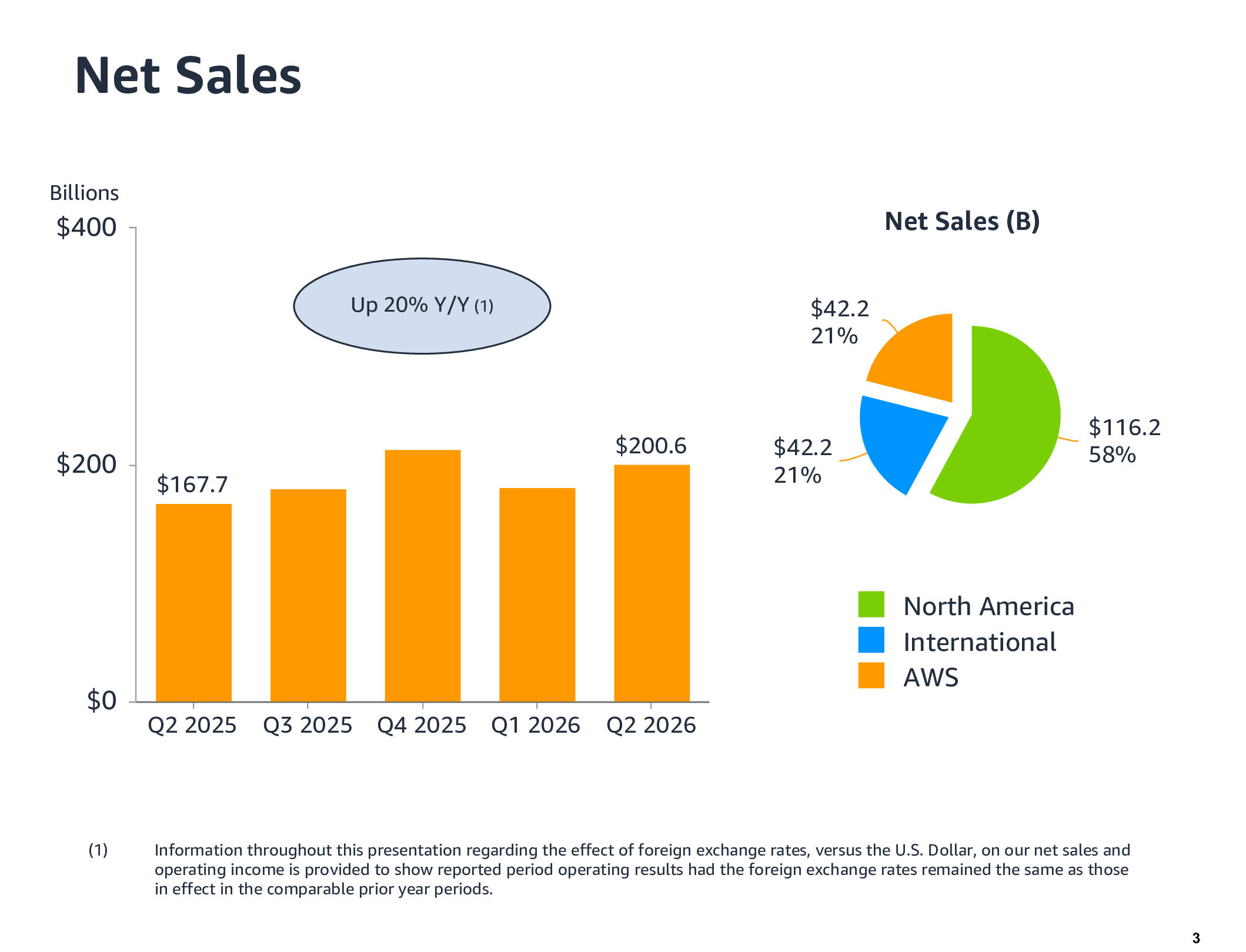
Источник изображений: Amazon Выручка Amazon за II квартал, завершившийся 30 июня, впервые превысила отметку в $200 млрд, составив $200,61 млрд, что больше год к году на 20 % и выше консенсус-прогноза аналитиков, опрошенных LSEG, в размере $196,47 млрд (по данным CNBC). Скорректированная прибыль (non-GAAP) на разводнённую акцию составила $1,97 против $1,82 по прогнозу. Чистая прибыль (GAAP) выросла до $62,6 млрд или $5,75 на разводнённую акцию, по сравнению с $18,2 млрд или $1,68 на разводнённую акцию годом раннее. Рост прибыли в основном связан с увеличением внереализационного дохода на $53 млрд, полученного от нереализованной прибыли от доли в ИИ-компании Anthropic PBC. Продажи AWS выросли на 36,7 % в годовом исчислении до $42,2 млрд, превысив прогноз аналитиков, опрошенных StreetAccount, в размере $40,54 млрд. «Это самый быстрый рост за 18 кварталов — а наши подразделения, занимающиеся ИИ и чипами, превысили темпы продаж более чем в $25 млрд каждое», — сказал Энди Джасси (Andy Jassy), президент и генеральный директор Amazon. «Конечно, именно ИИ способствует этому росту, с годовым объёмом инвестиций в ИИ более $25 млрд и ещё $25 млрд в платформу Trainium. Теперь всё внимание будет приковано к тому, сможет ли AWS стабилизировать темпы роста на уровне выше 30 %, а может быть, даже выйти на 40 %», — отметил аналитик Хольгер Мюллер (Holger Mueller) из Constellation Research. 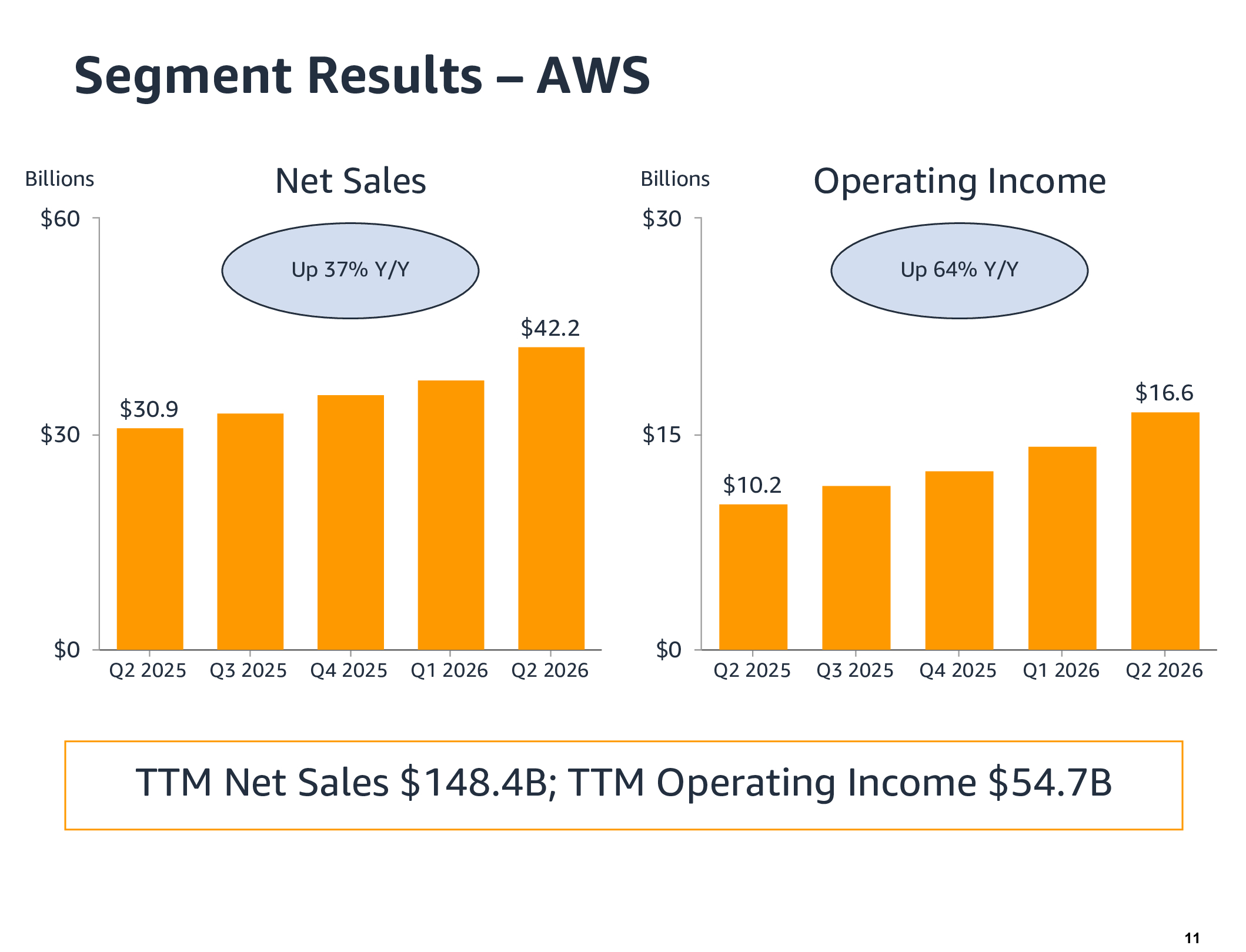 Amazon сообщила, что ожидает ещё больших расходов на ИИ. Джасси объявил об увеличении прогноза капитальных затрат на 2026 год до $220 млрд с предыдущего в размере $200 млрд. Он пояснил это ростом цен на память, добавив, что значительные инвестиции Amazon вряд ли скоро прекратятся. «Но даже при таких масштабах нам всё равно не хватит мощностей, чтобы удовлетворить весь спрос в 2026 году, и я считаю, что эта тенденция сохранится и в 2027 году, — сказал Джасси. — Фактически, спрос, который мы уже наблюдаем на 2028 год, сейчас поразителен». Джасси подчеркнул, что продолжающиеся инвестиции необходимы для того, чтобы компания могла удовлетворить растущий спрос на свои облачные сервисы. Он отметил, что на конец квартала у AWS накопился портфель невыполненных заказов на сумму $496 млрд — на $132 млрд больше, чем в предыдущем квартале. Что касается текущего квартала, Amazon прогнозирует выручку в диапазоне от $197 до $202 млрд, что ниже прогноза аналитиков, опрошенных LSEG, в $204,1 млрд. Компания объяснила снижение выручки решением перенести распродажу Prime Day в этом году на июнь, вместо обычного июльского периода.
31.07.2026 [19:05], Владимир Мироненко
Microsoft за год запустила 88 дата-центров и снижать инвестици в инфраструктуру не намеренаНа этой неделе акции Microsoft выросли на 15,5 %, увеличив её рыночную капитализацию на рекордные $450 млрд за один день, сообщил ресурс finance.yahoo.com. Это превзошло увеличение на $440 млрд рыночной стоимости у NVIDIA 9 апреля 2025 года после объявления президентом США 90-дневной паузы на введение пошлин, и стало самым большим за всю историю, согласно Bloomberg. Акции подскочили после объявления Microsoft о росте выручки на 18 % до $90,01 млрд в IV квартале 2026 финансового года, закончившемся 30 июня 2026 года, благодаря продолжающемуся расширению своего облачного бизнеса и бизнеса в области ИИ. Выручка Azure выросла за квартал на 43 %, что является самым большим ростом с начала 2022 года и генеральный директор Сатья Наделла (Satya Nadella) заявил, что доход подразделения впервые превысил $100 млрд за год. Microsoft также сообщила, что её планы по капитальным затратам на 2026 год остаются неизменными, что было позитивно встречено инвесторами. 
Источник изображений: Microsoft Выручка компания за IV финансовый квартал превысила консенсус-прогноз аналитиков, опрошенных LSEG, в размере $87,62 млрд. Скорректированная прибыль (non-GAAP) на разводнённую акцию составила $4,74 против прогноза в $4,24. Чистая прибыль (GAAP) составила $35,77 млрд или $4,81 на разводнённую акцию, что выше по сравнению с $27,23 млрд, или $3,65 на акцию годом ранее (+31 %). Microsoft сообщила о прибыли в размере $3,2 млрд от инвестиций в ИИ-компанию Anthropic и более низких, чем ожидалось, затратах, связанных с её первой в истории программой добровольного выхода на пенсию. Между тем, её игровой бизнес Xbox получил списание активов. В течение квартала оценка Anthropic выросла с $350 до $900 млрд, отметил SiliconANGLE. Выручка от облачных сервисов Microsoft (Microsoft Cloud) составила $59,3 млрд, увеличившись на 27 %, а оставшаяся часть обязательств по исполнению контрактов выросла год к году на 84 % до $678 млрд или на 8 % по сравнению с предыдущим кварталом. Последовательный рост был обусловлен обязательствами клиентов, не являющихся разработчиками ИИ-моделей, заявила Microsoft. Сегмент интеллектуальных облачных решений (Intelligent Cloud), включающий Azure, показал выручку в размере $39,31 млрд, что на 31,6 % больше, чем годом ранее, и превышает консенсус-прогноз аналитиков StreetAccount в размере $38,16 млрд.  Рост выручки облака Azure и других облачных сервисов на 43 % превысил целевой показатель аналитиков, опрошенных StreetAccount и CNBC, в размере 40,0 и 40,2 % соответственно. Финансовый директор Эми Худ (Amy Hood) прогнозирует рост Azure на 45 % в I финансовом квартале, что выше консенсус-прогноза StreetAccount в 41,4%. Выручка в сегменте «Производительность и бизнес-процессы» (Microsoft Productivity and Business Processes) выросла на 14 % до $37,85 млрд, что выше консенсус-прогноза аналитиков в $37,19 млрд. Доход от облачного сервиса Microsoft 365 увеличился на 24 %, от LinkedIn — на 12 %, от Dynamics 365 — на 12 %. В сегменте More Personal Computing выручка составила $12,85 млрд, снизившись на 4 %, но превысив прогноз аналитиков в размере $12,17 млрд. Microsoft также продолжала активно инвестировать в инфраструктуру ИИ. Компания потратила $41 млрд на капитальные затраты и аренду в течение квартала, что на 69 % больше, чем годом ранее, а за 2026 финансовый год они достигли почти $116 млрд, в основном для поддержки расширения ЦОД для обучения и инференса ИИ. Доходы от основных средств и оборудования выросли до $313,1 с $205,0 млрд годом ранее, что отражает один из крупнейших в отрасли проектов по развитию инфраструктуры. Всего компания за год развернула 88 дата-центров по всему миру, только в последнем квартале был запущен 31 ЦОД общей ёмкостью 1 ГВт. За 2025 календарный год компания получила 2 ГВт новых мощностей.  Эми Худ подтвердила планы капитальных затрат на 2026 календарный год. Она также сказала, что компания планирует увеличить срок полезной эксплуатации своих новых офисных зданий и ЦОД с 15 до 25 лет. По её словам, компания планирует в будущем перевести большую часть своих договоров аренды с финансовой аренды на операционную, что, как ожидается приведёт к капитальным затратам и счетам за финансовую аренду примерно на $175 млрд. По итогам 2026 финансового года Microsoft получила выручку $331,8 млрд (рост — 18 %). Чистая прибыль (GAAP) составила $133,7 млрд (рост — 31 %), разводнённая прибыль на акцию — $17,95. Microsoft ожидает в I квартале 2027 финансового года выручку в пределах от $89,85 до $90,95 млрд, что в среднем составляет рост на 16 %. Аналитики, опрошенные LSEG, прогнозируют выручку в $89,66 млрд. Что касается 2027 финансового года, то Худ ожидает дальнейшего роста капитальных затрат, указывая на «сигналы спроса по всему нашему портфелю».
31.07.2026 [17:58], Руслан Авдеев
EuroHPC запускает тендер на строительство до семи ИИ-гигафабрик в ЕвросоюзеEuroHPC JU объявила о начале приёма заявок на участие в тендере для строительства и эксплуатации ИИ-гигафабрик (AI Gigafactories/AIGF), сообщает HPC Wire. Гигафабрики вместе с «обычными» ИИ-фабриками обеспечат доступность ИИ-сервисов и мощностей для государственных структур и частных пользователей из государств, участвующих в проекте. Новое поколение ИИ-инфраструктуры позволит существенно расширить вычислительные возможности в регионе, обеспечив ему технологическую независимость. Расположенные в странах ЕС гигафабрики объединят огромные вычислительные мощности и необходимое программное обеспечение, облачные технологии, высокоскоростные каналы связи и энергоэффективные ЦОД. Заявку могут подать консорциумы или специальные проектные компании (Special Purpose Vehicles, SPV), объединяющие коммерческие и государственные структуры, инвесторов и прочих партнёров. Создавать гигафабрики можно как в одном месте в стране из числа участниц инициативы, так и в нескольких локациях, в т.ч. в нескольких странах ЕС с использованием распределённых вычислений. 
Источник изображения: EuroHPC JU Приём заявок закончится 12 ноября 2026 года, после этого их ожидает конкурсный отбор. Утверждается, что стратегия закупок продумана таким образом, что будут поддерживаться как начальные проекты строительства AIGF, так и их расширение. Якорным заказчиком и источником финансирования выступит Евросоюз и отдельные страны-участницы, что поможет привлечь инвестиции более €20 млрд. Ожидается, что после того, как выбор будет сделан в начале 2027 года, гигафабрики должны быть построены и введены в эксплуатацию в течение 18 мес. Успешные проекты будут по-разному финансироваться ЕС и участвующими странами, в зависимости от масштаба инициатив и спектра суверенных сервисов. Часть финансирования будет выделена в рамках текущего Многолетнего финансового плана ЕС (MFF), а основная масса средств поступит в рамках следующего Многолетнего финансового плана (2028–2035 гг.). Гигафабрики по задумке ЕС представляют собой полноценную экосистему для ИИ-вычислений, включающую оптимизированные для ИИ-задач суперкомпьютеры с современными ЦОД, системы хранения данных огромной ёмкости, а также сверхскоростные сети связи с безопасным доступом и специализированными службами поддержки. Первые ИИ-гигафабрики были анонсированы в 2024 году в Финляндии, Германии, Греции, Италии, Люксембурге, Испании и Швеции. В июне 2026 года EuroHPC JU было объявлено о запуске системы EuroHPC Federation Platform (EFP), призванной упростить доступ к суперкомпьютерам Европы. Платформа выступает в качестве единой точки доступа к вычислительным ресурсам.
31.07.2026 [17:25], Руслан Авдеев
Nebius отчиталась об усилиях в области экологии и устойчивого развитияКомпания Nebius опубликовала доклад 2025 Sustainability Report, рассказав о природоохранных, операционных и кадровых инициативах её облачной ИИ-платформы, сообщает Converge! Digest. Особое внимание уделили повышению энергоэффективности дата-центров, технологиям жидкостного охлаждения, утилизации тепла, использованию энергии из возобновляемых источников и обеспечению надёжности инфраструктуры. Главная тема отчёта — вопросы экоэффективности инфраструктуры. Nebius утверждает, что средний показатель PUE в портфолио ЦОД компании составляет 1,25. Для сравнения, в индустрии в целом он держится на уровне 1,54. При этом серверная архитектура компании обеспечивает приблизительно на 20 % больше ИИ-вычислений на ватт в сравнении с предыдущими вариантами. Предполагается, что это позволило сэкономить в 2025 году приблизительно 102 ГВт∙ч электричества. В дата-центре в Финляндии показатель эффективности водопользования WUE составил 0,018 л/кВт∙ч, намного меньше, чем в среднем по отрасли. Отмечено, что СЖО замкнутого цикла минимизирует использование пресной воды, в то же время поддерживая ИИ-вычисления высокой плотности. В отчёте подчёркивается, что компания ориентируется на более масштабные инициативы в сфере устойчивого развития, чем просто проекты, связанные с экоэффективностью дата-центров. Так, Nebius за отчётный период захватила и передала в муниципальные сети централизованного теплоснабжения 19,5 ГВт∙ч «мусорного» тепла ЦОД, а будущие кампусы проектируются с расчётом отдачи до 250 ГВт∙ч каждый год. 
Источник изображения: Nebius По данным компании, среднее время бесперебойной работы её систем (MTBF) составляет 56,6 часов, тогда как в отрасли этот показатель держится приблизительно на 9,8 часа. При этом компания располагает сертификатами уровня защиты данных ISO 27001, ISO 27701 и SOC 2 Type II. А благодаря т.н. Nebius Academy компания расширяет образование в сфере ИИ-технологий, а также поддерживает ИИ-стартапы облачными кредитами и сотрудничает с академическими структурами в рамках программ исследования ИИ. Nebius фактически вступила в «клуб» операторов ИИ-инфраструктуры, публикующих точные метрики устойчивого развития по мере масштабирования ИИ-проектов. Основное внимание всё ещё уделяется производительности ускорителей и сетевым технологиям, но отчёт в очередной раз подчёркивает важность рационального энергоснабжения, использования жидкостного охлаждения, интеграции в систему источников возобновляемой энергии и др. По мнению Converge!, доклад свидетельствует о том, что ИИ-провайдеры всё чаще рассматривают экоустойчивость как инженерную задачу, а не просто формальную бумажную работу. Экологические показатели прямо влияют на экономику эксплуатации масштабных ИИ-кластеров. Поскольку гиперскейлеры и облачные провайдеры стали конкурентами в борьбе за доступную электроэнергию и мощности ЦОД, наличие эффективного охлаждения и рациональное использование энергии сами по себе стали важными конкурентными преимуществами, не менее важными, чем наличие самих ИИ-ускорителей. Тем временем в середине июля сообщалось, что xAI продолжает наращивать газовые генерирующие мощности для кампуса Colossus, с точки зрения закона находящиеся в «серой» зоне, а Meta✴ покинула климатическую инициативу RE100, в которой участвовала десять лет — оставить её пришлось из-за неизбежного роста закупок энергии, вырабатываемой за счёт природного газа.
31.07.2026 [16:44], Руслан Авдеев
Crusoe и Aalo развернут первую ИИ-фабрику с питанием от SMRКомпании Crusoe Energy и Aalo Atomics объявили о партнёрстве, в рамках которого планируется создать первую ИИ-фабрику с питанием от атомных реакторов. Модульная ИИ-инфраструктура будет комбинироваться с малыми модульными реакторами (SMR) для демонстрации возможностей поддержки АЭС крупномасштабных ИИ-вычислений, сообщает Converge Digest. Первый пилотный проект предполагается запустить в 2027 году на территории Национальной лаборатории Айдахо (Idaho National Laboratory, INL). Там реактор Aalo будет снабжать энергией модульный ЦОД Crusoe Spark, в котором разместятся мощности облака Crusoe Cloud. Партнёры намерены расширить взаимодействие и к концу 2029 года организовать коммерческое использование реакторов Aalo дата-центрами Crusoe. Согласно договору Aalo намерена интегрировать свои модульные мини-АЭС Aalo Pods на основе реакторов с 50-МВт электрической мощности с будущими ЦОД Crusoe. Недавно Aalo удалось добиться в своём реакторе самоподдерживающейся цепной реакции в рамках пилотной программы Министерства энергетики (DoE). Aalo уже начала строить второй реактор в дополнение к расположенному на территории INR объекту Aalo-X. Он будет генерировать электричество, поставляя энергию расположенному там же модульному ЦОД Crusoe Spark. Новое партнёрство — очередное свидетельство потребности ЦОД в надёжных бесперебойных источниках энергии, способных поддержать быстрое масштабирование ИИ-инфраструктуры. 
Источник изображения: Aalo Atomics Crusoe позиционирует себя как вертикально интегрированного провайдера ИИ-инфраструктуры, участвующего в энергетических проектах, занимающегося строительством ИИ ЦОД и обеспечением облачных сервисов. Aalo получит благодаря взаимодействию возможность опробовать предварительный коммерческий сценарий своих малых модульных реакторов, специально предназначенных для ИИ ЦОД. Основанная в 2023 году в Техасе компания уже привлекла $136 млн от инвесторов, включая Valor Equity Partners, NRG Energy, Hitachi Ventures и Tishman Speyer. Взаимодействие Crusoe и Aalo — часть более широкого тренда. Технологические компании, включая Microsoft, Amazon, Google и Oracle уже анонсировали связанные с атомной энергетикой инициативы или инвестиции для поддержки расширения парка ЦОД в дальнейшем. Тем временем разработчики реакторов вроде Oklo, Kairos Power, TerraPower и X-energy продолжают продвигать создание коммерческих решений. В отличие от многих подобных проектов, партнёры намерены продемонстрировать на базе INL реальное применение модульного ядерного реактора с настоящим ЦОД и ИИ-нагрузками до того, как перейти к созданию коммерческих ИИ-кампусов. |
|

