Материалы по тегу: nextsilicon
|
26.06.2026 [12:23], Владимир Мироненко
Cornelis и NextSilicon создадут эталонные архитектуры для ИИ и HPCCornelis и NextSilicon объявили о сотрудничестве с целью разработки эталонных архитектур для ИИ и HPC. В рамках проекта компании приступили к оценке возможности использования 400G-интерконнекта Cornelis CN5000 в паре с вычислительной платформой NextSilicon Maverick-2. На первом этапе проверяется совместная работа интерконнекта и вычислительных ресурсов в различных конфигурациях, причём партнёры начали с проверенных комбинаций. Компании планируют расширить тестирование на интерконнект CN6000 со скоростью 800 Гбит/с, запуск которого запланирован на II половину 2026 года. Обе компании нацелены на решение проблемы в своей сфере. Стандартный Ethernet не рассчитан на обработку небольших, чувствительных к задержке сообщений, которые генерируются в больших масштабах при выполнении задач ИИ-инференса и симуляции HPC. Возникает перегрузка, и дорогостоящие вычислительные ресурсы простаивают в ожидании данных. CN5000 разработан для устранения этого простоя. 
Источник изображений: Cornelis Networks Вычислительные ресурсы простаивают при обработке нерегулярных, зависящих от данных рабочих нагрузок, которые доминируют в ИИ и HPC. Израильская компания NextSilicon построила ускоритель Maverick-2 на основе своей интеллектуальной вычислительной архитектуры (ICA) — программно-определяемой архитектуры с управлением потоками данных (dataflow), в которой вычисления запускаются не последовательными инструкциями, а по факту поступления данных. Платформа переконфигурируется для каждой рабочей нагрузки во время выполнения без изменения существующего кода. Сочетание подходов Cornelis и NextSilicon позволяет решить обе проблемы, обеспечивая передачу данных и поддерживая постоянную работу вычислительных ресурсов. Совместные эталонные архитектуры предоставят OEM-партнерам план создания систем, которые они смогут построить и вывести на рынок.  «Операторы постоянно говорят нам, что их самые дорогие системы простаивают, ожидая подключения к сети, — говорит Лиза Спелман (Lisa Spelman), генеральный директор Cornelis. — Мы создали CN5000, чтобы положить конец этому ожиданию. NextSilicon бросает вызов аналогичной проблеме в вычислительной сфере, поэтому это сотрудничество является естественным шагом. Вместе мы можем показать партнерам и клиентам, что дают бесперебойная сеть и вычислительная архитектура, ориентированная на рабочие нагрузки, в рамках единого решения». Наряду с HPC, сотрудничество также будет направлено на переход в ИИ-инференсе к моделям смешанных экспертов (MoE) и агентному ИИ. Инференс в продуктовых средах для этих рабочих нагрузок больше не выполняется как одна модель на одном ускорителе. Он разделяется на этапы, и данные перемещаются между этапами по сети. Дезагрегированный инференс делает сетевую инфраструктуру частью вычислительного пути. Он применим для сети, которая обрабатывает небольшие, импульсные, чувствительные к задержкам сообщения без перегрузки, и вычислительных ресурсов, которые адаптируются к каждому этапу конвейера.
16.06.2026 [09:46], Сергей Карасёв
NextSilicon готовит 128-ядерные серверные RISC-V-процессоры для ИИ и НРСКомпания NextSilicon сообщила о том, что её вычислительные ядра Arbel с архитектурой RISC-V лягут в основу процессоров корпоративного класса, ориентированных на задачи ИИ и НРС. Организовать серийное производство таких изделий планируется в I квартале 2028 года. NextSilicon проектировала Arbel с чистого листа, а первоначальной целью было создание хост-процессора для ИИ-ускорителей Maverick-3. Конструкция Arbel предусматривает наличие массивного конвейера инструкций шириной 10 команд и буфера переупорядочивания на 480 записей. Возможно выполнение 16 скалярных инструкций за цикл. Задействованы четыре интегрированных 128-бит векторных блока для обеспечения высокой производительности при параллельной обработке данных, включая нагрузки, связанные с ИИ-инференсом. 
Источник изображения: NextSilicon Сообщается, что создаваемые процессоры будут доступны в модификациях с 64 и 128 ядрами Arbel. Тактовая частота заявлена на отметке 3,4 ГГц. Тестовые изделия Arbel предполагали применение 5-нм технологии TSMC. Серийные решения будут изготавливаться по более совершенной методике для удовлетворения растущих требований к энергоэффективности и повышению плотности размещения компонентов в дата-центрах. Упомянут алгоритм прогнозирования ветвлений TAG. Говорится о полноценной поддержке профиля RVA23, который стандартизирует ISA. В RVA23 предусмотрены такие функции, как векторные операции, инструкции с плавающей запятой и атомарные инструкции, а также поддержка гипервизоров. Заявлена совместимость со стандартными дистрибутивами Linux. Ожидается, что рынок чипов с архитектурой RISC-V для дата-центров и НРС-платформ будет демонстрировать среднегодовой темп роста на уровне 33,1 % в период с 2025 по 2034 год. В результате его объём превысит $200 млрд.
19.05.2026 [12:49], Руслан Авдеев
AMD и NVIDIA свернули не туда: следующий крупный американский суперкомпьютер может получить HPC-чипы NextSiliconБольшая часть самых мощнейших суперкомпьютеров мира в рейтинге TOP500 полагаются на ускорители на основе GPU, однако Национальные лаборатории США начали искать новые архитектуры чипов, обеспечивающие высокую производительность в FP64-расчётах, востребованных для симуляций Министерства энергетики США (DoE). Последнее занимается не только вопросами энергетиками, но и управляет одними из мощнейших суперкомпьютеров мира, в т.ч. для моделирования физики ядерного оружия, виртуальных экспериментов, касающихся биологического оружия, а также решения задач обеспечения общественного здоровья и безопасности, сообщает The Register. С запуска суперкомпьютера Titan в 2012 году всё больше систем стали использовать ускорители NVIDIA, а впоследствии и чипы AMD. Однако новый суперкомпьютер Spectra Сандийских национальных лабораторий (SNL), созданный Penguin Solutions и NextSilicon, использует другие решения. В сравнении с экзафлопсными системами уровня Frontier или El Capitan он занимает относительно мало места и состоит всего из 64 узлов. Spectra используют в качестве тестовой площадки для чипов Maverick-2, успешно прошедших все приёмочные испытания. Это открывает возможность их использования в боле крупных системах. 
Источник изображения: SNL Maverick-2 используют перенастраиваемую потоковую (dataflow) архитектуру. Фактически внутри чипа находится сеть связанных вычислительных блоков, работающих не по жёстко заданной схеме, а как узлы графа. В ходе выполнения задачи каждый блок можно настроить под отдельную задачу — сложение, умножение и т.п., благодаря чему происходит адаптация под разные типы вычислений с более эффективной обработкой потоков данных. Главная особенность — возможность одновременных вычислений и передачи данных. В NextSilicon утверждают, что это значительно повышает производительность и энергоэффективность в реальных задачах. Groq, Cerebras и SambaNova и ранее предлагали чипы на «потоковых» архитектурах, но все они были ориентированы на обучение и инференс ИИ, тогда как NextSilicon ориентируется именно на HPC. Подобные архитектуры очень сложны для программирования, поэтому разработчики обычно предлагают готовые сервисы, а не просто продают серверы на их основе. NextSilicon пытается решить подобную проблему, предложив собственный компилятор, позволяющий использовать имеющиеся программы на C, Python, Fortran и CUDA без серьёзной доработки. В Сандийских лабораториях уже проверили технологию на важных HPC-нагрузках, включая HPCG, LAMMPS и Sparta, подтвердив пригодность системы для научных вычислений. 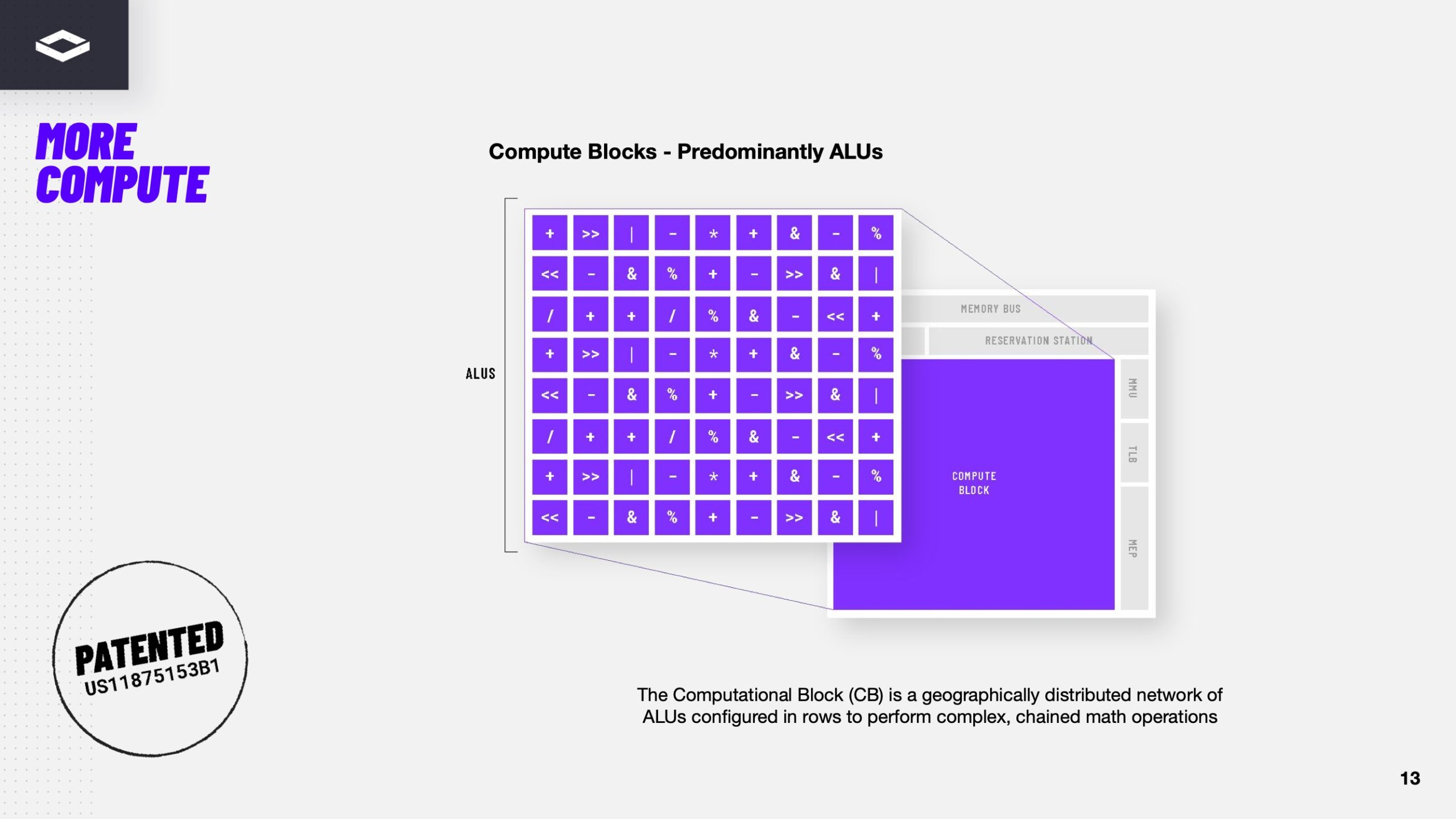
Источник изображения: NextSilicon Ставка разработчика на HPC контрастирует с вектором развития ИИ-ускорителей NVIDIA. В Rubin компания делает ставку на ИИ-вычисления, снижая «чистую» производительность FP64, полагаясь на эмуляцию посредством схемы Озаки. Если в некоторых HPC-задачах это работает, то в других эффективность подобных обходных решений весьма низкая. AMD помимо ориентированных на ИИ Instinct MI455X готовит и MI430X, где сохранены аппаратные HPC-блоки. Именно на подобные нагрузки ориентируется NextSilicon со своими наработками. Полных системных бенчмарков Maverick-2 и суперкомпьютера пока нет, но компания утверждает, что один такой ускоритель способен обеспечить порядка 600 Гфлопс в тесте HPCG (FP64). По данным стартапа, это сопоставимо по производительности с ведущими GPU, причём энергопотребление у новинки вдвое ниже. Для США главной проблемой может оказаться давление акционеров компаний, поставляющих чипы. Если ИИ сделал NVIDIA финансовым и технологическим гигантом, то рынок решений для HPC остаётся важным, но всё ещё нишевым направлением. Хотя стартапам вроде NextSilicon ещё предстоит доказать право своих продуктов на место под солнцем, Китай уже давно продемонстрировал, что GPU вовсе не обязательны для успешной конкуренции с лучшими суперкомпьютерами Запада. OceanLight и Tianhe-3 полагаются на кастомные процессоры и ускорители на базе DSP вроде Matrix 2000. Последние, по слухам, были созданы в ответ на запрет поставок Intel Xeon Phi в КНР. Также недавно появились данные о новом Arm-суперкомпьютере LineShine.
09.12.2025 [13:05], Сергей Карасёв
Сандийские национальные лаборатории запустили суперкомпьютер Spectra с ускорителями NextSilicon Maverick-2Сандийские национальные лаборатории (SNL) Министерства энергетики США (DOE) объявили о создании суперкомпьютера Spectra с нестандартной архитектурой. В его основу положены изделия Maverick-2 — интеллектуальные вычислительные ускорители (Intelligent Compute Accelerator, ICA), разработанные компанией NextSilicon. Система Spectra спроектирована по программе Vanguard, цель которой заключается в исследовании потенциала передовых компьютерных архитектур применительно к проектам в сфере национальной безопасности. Первой платформой Vanguard стал комплекс Astra, запущенный в 2018 году: на момент анонса это был самый быстрый в мире суперкомпьютер на базе Arm-чипов. Среди других примечательных машин SNL можно отметить Kingfisher на ИИ-чипах Cerebras WSE-3, а также две нейроморфные системы: на базе SpiNNaker2 и на базе Loihi II (Hala Point). 
Источник изображения: SNL Spectra объединяет 64 вычислительных узла, каждый из которых оснащён двумя двухкристальными ОАМ-модулями Maverick-2: эти изделия содержат 64 управляющих ядра RISC-V, 192 Гбайт памяти HBM3E и два интерфейса 100GbE. В общей сложности задействованы 128 экземпляров Maverick-2. Особенностью ускорителей является возможность динамической реконфигурации оборудования на основе данных, получаемых непосредственно во время выполнения задачи. Такой подход позволяет устранять узкие места, присущие традиционным CPU и GPU. Подробнее об архитектуре Maverick-2 можно узнать в нашем материале. За монтаж суперкомпьютера Spectra отвечала компания Penguin Solutions. Она разработала специализированный сервер, поддерживающий до четырёх ОАМ-модулей Maverick-2, хотя в текущей конфигурации используются два. Применены передовая СЖО с отрицательным давлением Chilldyne и платформа Penguin Tundra, что обеспечивает оптимизацию управления температурой и распределения питания, а также возможности масштабирования.
12.11.2025 [09:28], Владимир Мироненко
Переконфигурируемый ускоритель NextSilicon Maverick-2 с dataflow-архитектурой меняет подход к вычислениямВ конце октября стартап NextSilicon объявил о выходе Maverick-2 — интеллектуального ускорителя вычислений (Intelligent Compute Accelerator, ICA), анонсированного в прошлом году. Чип уже используется в Сандийских национальных лабораториях (SNL) Министерства энергетики США (DOE) в составе суперкомпьютера Vanguard-II, а также рядом клиентов. Как утверждает глава NextSilicon Элад Раз (Elad Raz), компании в сфере научных вычислений и HPC сталкиваются с проблемой ограниченных возможностей CPU и GPU, из-за чего приходится идти на компромиссы, но архитектура Maverick решает эту проблему. По словам NextSilicon, нынешние массовые CPU «скованы» архитектурой фон Неймана 80-летней давности, в которой значительная часть отведена вспомогательной логике, включая предсказание ветвлений, внеочередное исполнение и т.д., а не собственно исполнительным устройствам. В свою очередь, GPU обеспечивают более высокую параллельную производительность, но для эффективного использования ускорителей требуются специализированные среды разработки (CUDA), управление сложными иерархиями памяти, когерентностью кешей и т.п. А ASIC, созданные для конкретных ИИ-задач, обеспечивают высокую производительность и эффективность, но их разработка требует больших затрат. 
Источник изображения: NextSilicon NextSilicon предлагает заменить эти решения чипом с управлением потоками данных (dataflow), который можно перенастраивать во время выполнения задач для устранения узких мест кода, и у которого нет ограничений, присущих CPU и GPU. «В ресурсоёмких приложениях большую часть времени выполняется лишь небольшая часть кода, — рассказал Раз. — Мы разработали интеллектуальный программный алгоритм, который непрерывно отслеживает работу приложения. Он точно определяет, какой путь кода выполняется чаще всего, и перенастраивает чип для ускорения именно этих путей. И всё это мы делаем во время исполнения кода и за наносекунды». FPGA тоже можно перепрограммировать, но для этого нужен цикл перезагрузки. 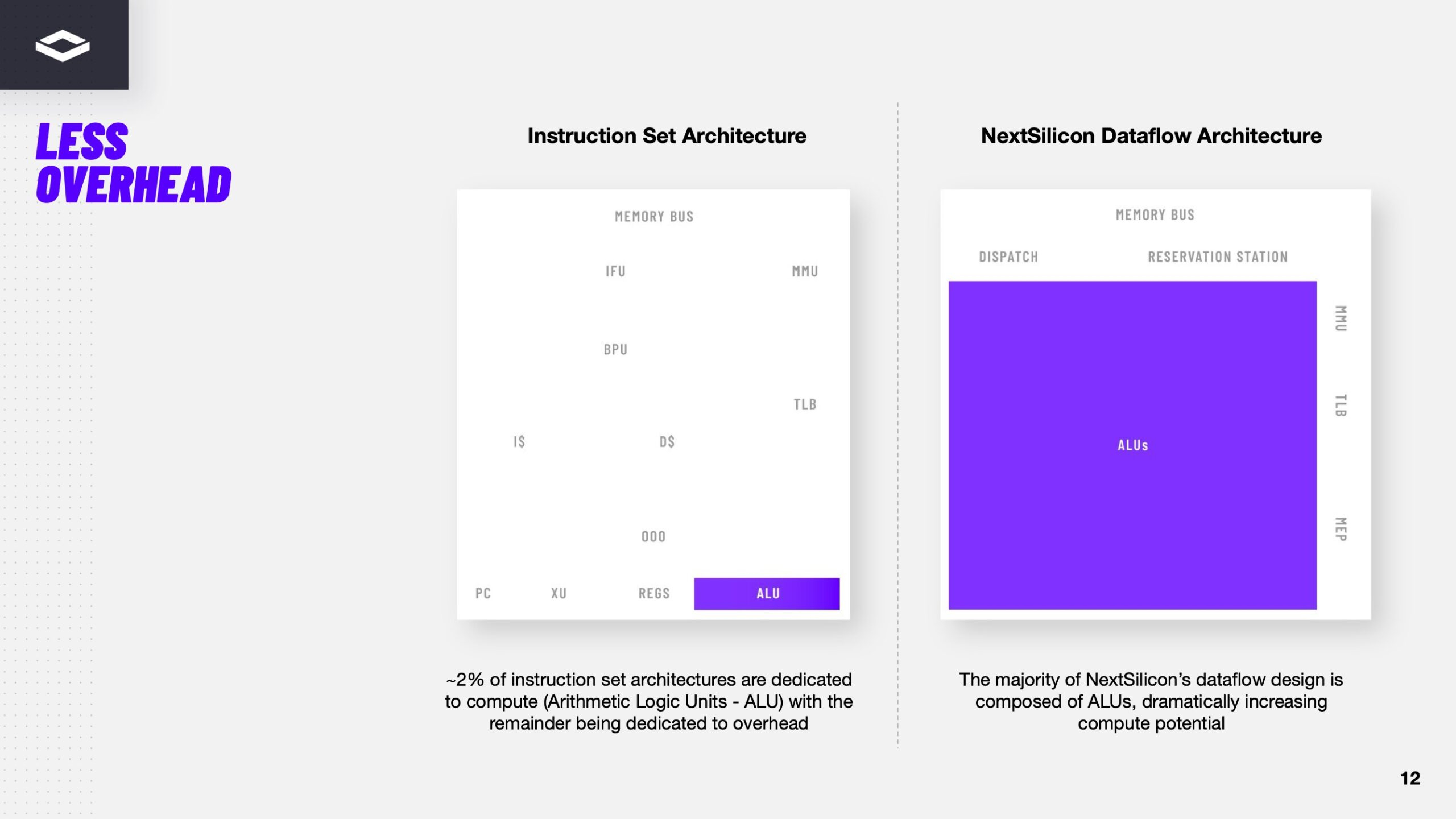
Источник изображений здесь и далее: ServeTheHome/NextSilicon Аппаратная часть Maverick представляет собой реконфигурируемую структуру ALU, которой отведена большая часть «кремния». которую можно быстро перенастраивать во время выполнения кода. Это означает больше вычислений за такт (и на Ватт), при условии, что данные находятся в нужном месте в нужное время. Алгоритм анализирует код на наличие узких мест и соответствующим образом настраивает чип во время выполнения программы. Программно-определяемая архитектура управления потоками данных позволяет достичь производительности и эффективности, близких к ASIC, не привязываясь к конкретному приложению и сохраняя гибкость алгоритмов, утверждает NextSilicon. 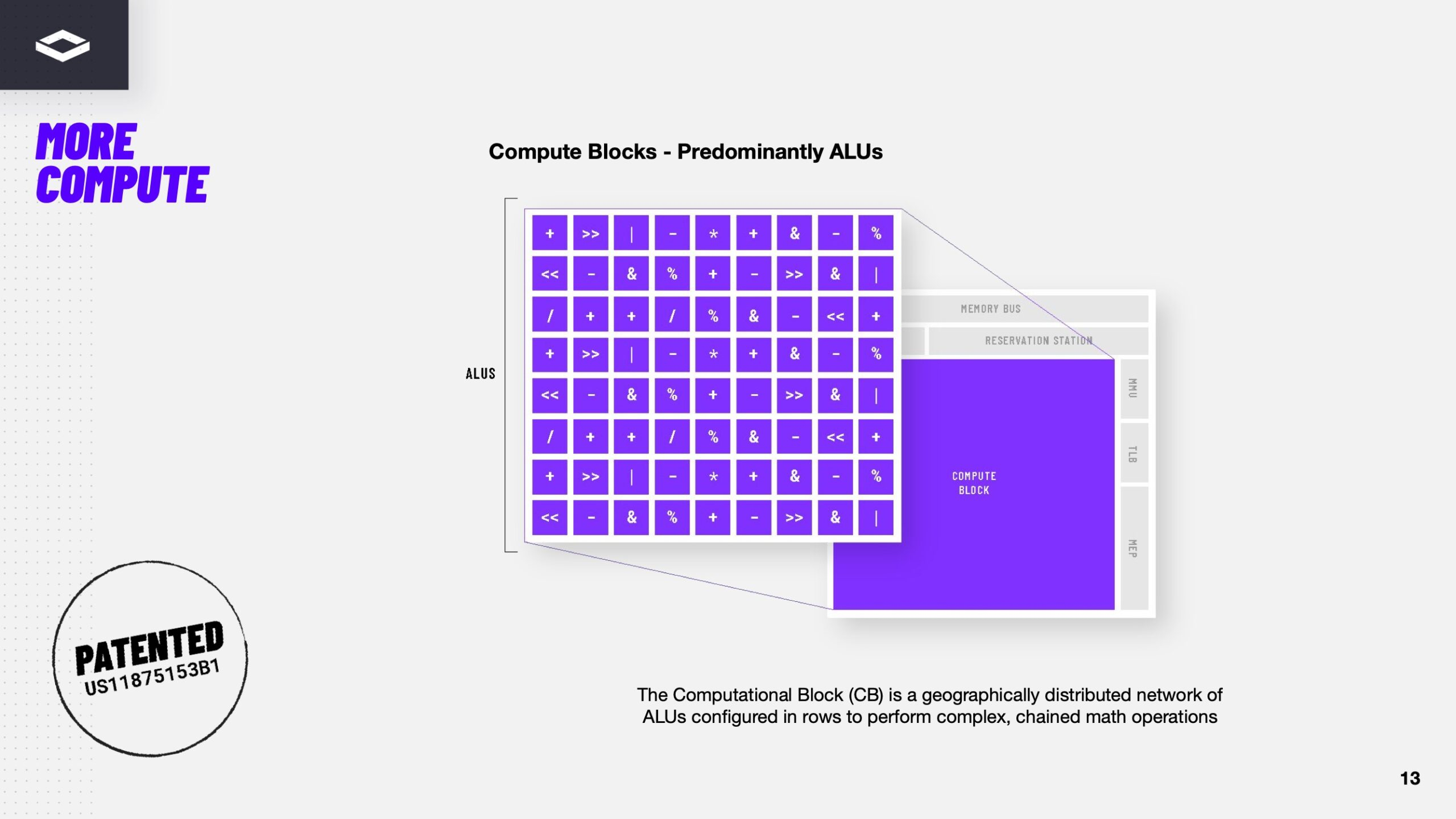 В архитектуре NextSilicon вычислительные блоки (CB) подключены к шине памяти для получения данных, которые временно хранятся в станции резервирования (RS). Диспетчер определяет время запуска вычислительного блока. (RS и диспетчер аналогичны регистрам в процессоре.) Точки входа в память (MEP-блоки) обрабатывают операции доступа к памяти, генерируя запросы к шине, а по завершении направляют ответ в RS. MMU и TLB-кеш занимаются трансляцией адресов (при необходимости). Всё остальное пространство CB занято ALU, который в первом приближении и можно считать «инструкциями». Компания не уточняет, сколько именно CB содержится в чипе, но на фото кристалла их 224. 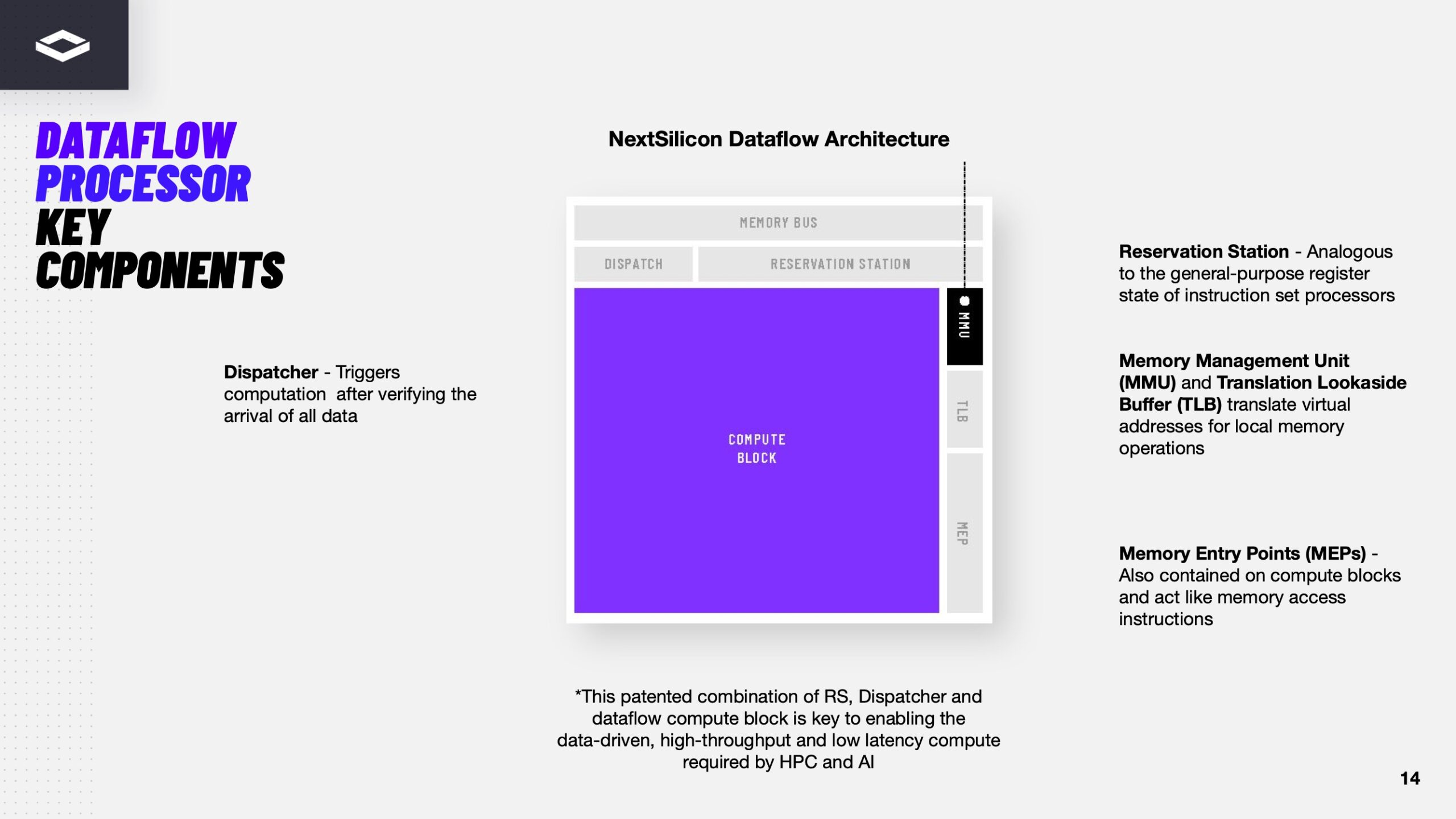 Из ALU компилятор NextSilicon формирует т.н. Mill-ядра (Mill Core) в рамках CB, фактически представляющие собой граф связанных между собой операций, которые и выполняются ALU — появление данных на входе ALU срабатывает как триггер, ALU отрабатывает свою единственную назначенную операцию и передаёт результат следующему ALU, тот следующему и т.д. до конца графа. Особенностью чипа является способность в ходе исполнения по необходимости автоматически реплицировать и оптимально размещать Mill-ядра внутри одного CB, и между несколькими CB. Пришло больше данных, которые можно параллельно обработать — будет больше Mill-ядер. Но касается это только наиболее «горячих» участков. 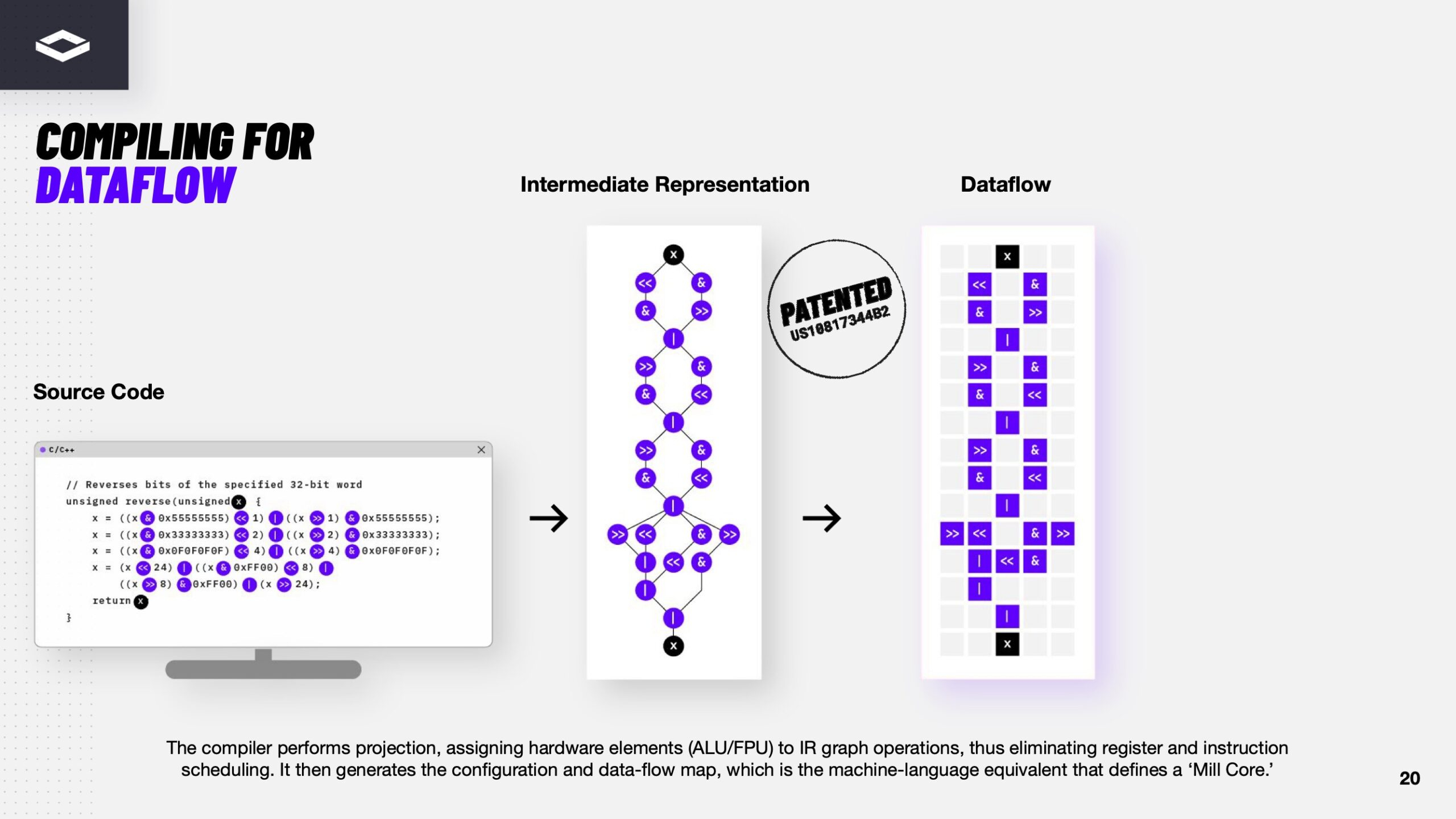 Илан Таяри (Ilan Tayari), соучредитель и вице-президент по архитектуре NextSilicon, назвал критически важным, что платформа может запускать любой код «из коробки», будь то код, написанный для CPU и GPU или ИИ-моделей. Будь то C++, Fortran, Python, CUDA, ROCm, OneAPI или даже ИИ-фреймворки, компилятор NextSilicon разделяет код на части, преобразуя их в промежуточное представление для реконфигурируемого оборудования. «Это не ограничивается тем, что существует сегодня, — сказал Таяри. — Для исследователей в сфере ИИ этот метод открывает новые захватывающие возможности. Вы получаете ускорение независимо от того, что использует ваша модель… экзотические функции активации, комплексные числа или новые математические операции: всё ускоряется сразу из коробки». 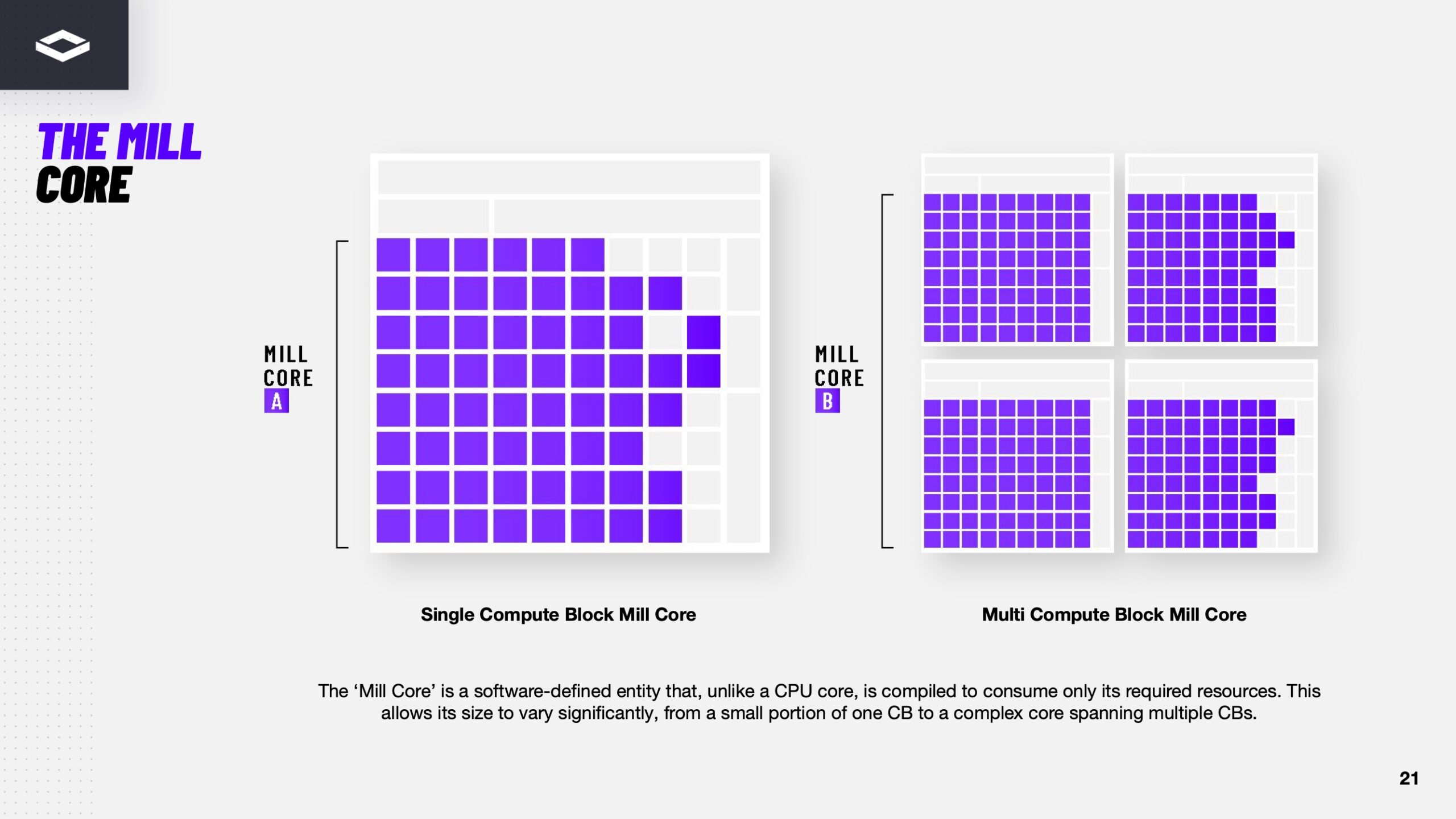 Во время выполнения приложения оперативная телеметрия на чипе непрерывно оптимизирует его. Например, в случае частого взаимодействия вычислительных подблоков граф перестраивается, чтобы приблизить их друг к другу или, например, переключиться с векторной на матричную обработку. При наличии узкого места они дублируются для обеспечения параллелизма. Это происходит автоматически, без вмешательства разработчика, в отличие, например, от VLIW-подхода. 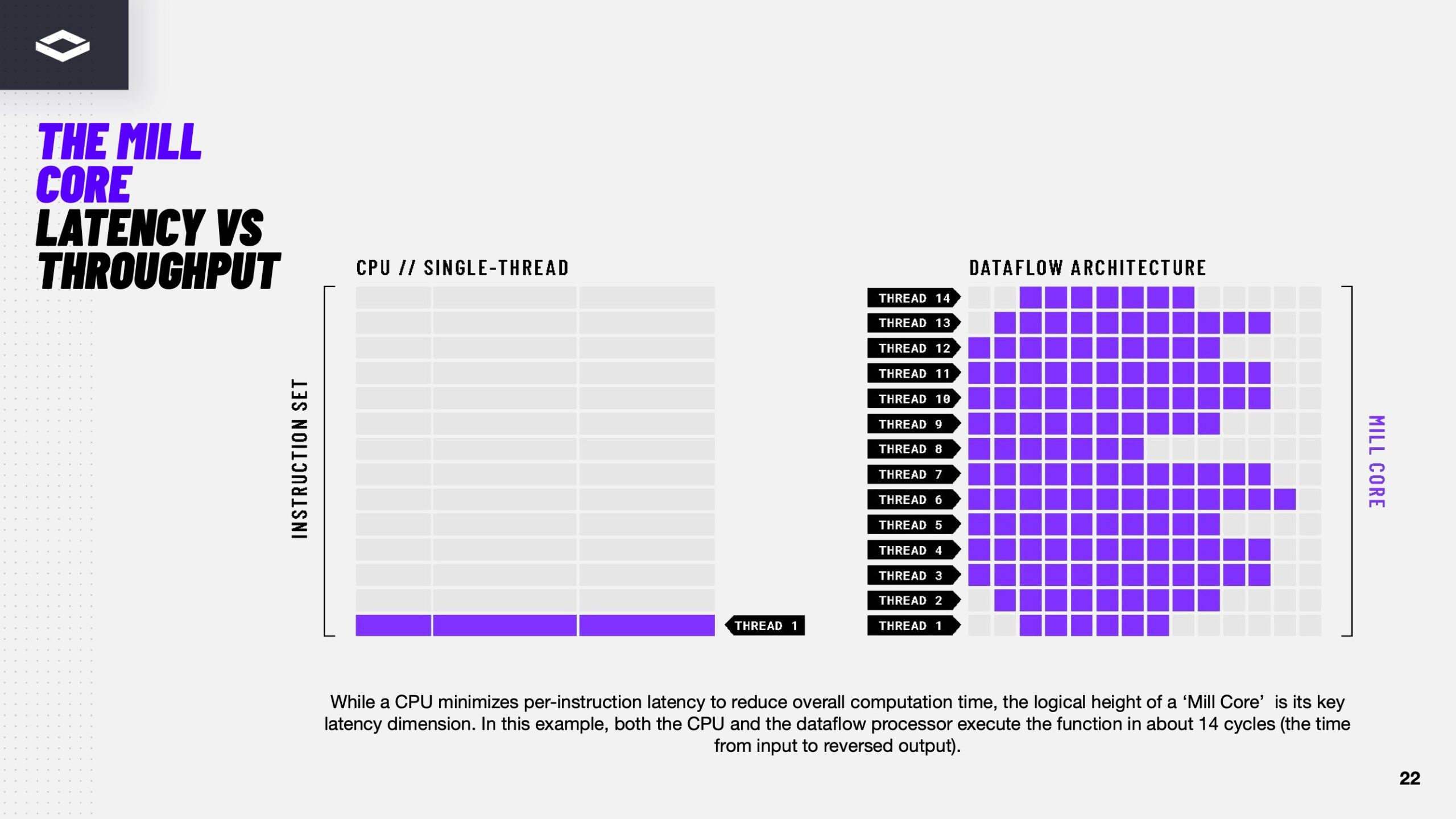 Maverick-2 выпускается по 5-нм техпроцессу TSMC в однокристальной и двухкристальной конфигурациях, работающих на частоте 1,5 ГГц. Однокристальная модель с энергопотреблением 400 Вт разработана для карт PCIe 5.0 x16, а двухкристальная модель с энергопотреблением 750 Вт — для OAM-модулей. Однокристальный вариант с воздушным охлаждением включает 32 управляющих ядра RISC-V, 96 Гбайт HBM3E, кеш 128 Мбайт и один порт 100GbE. Двухкристальный вариант OAM с жидкостным охлаждением содержит 64 управляющих ядра RISC-V, 192 Гбайт HBM3E, кеш 256 Мбайт и два интерфейса 100GbE. 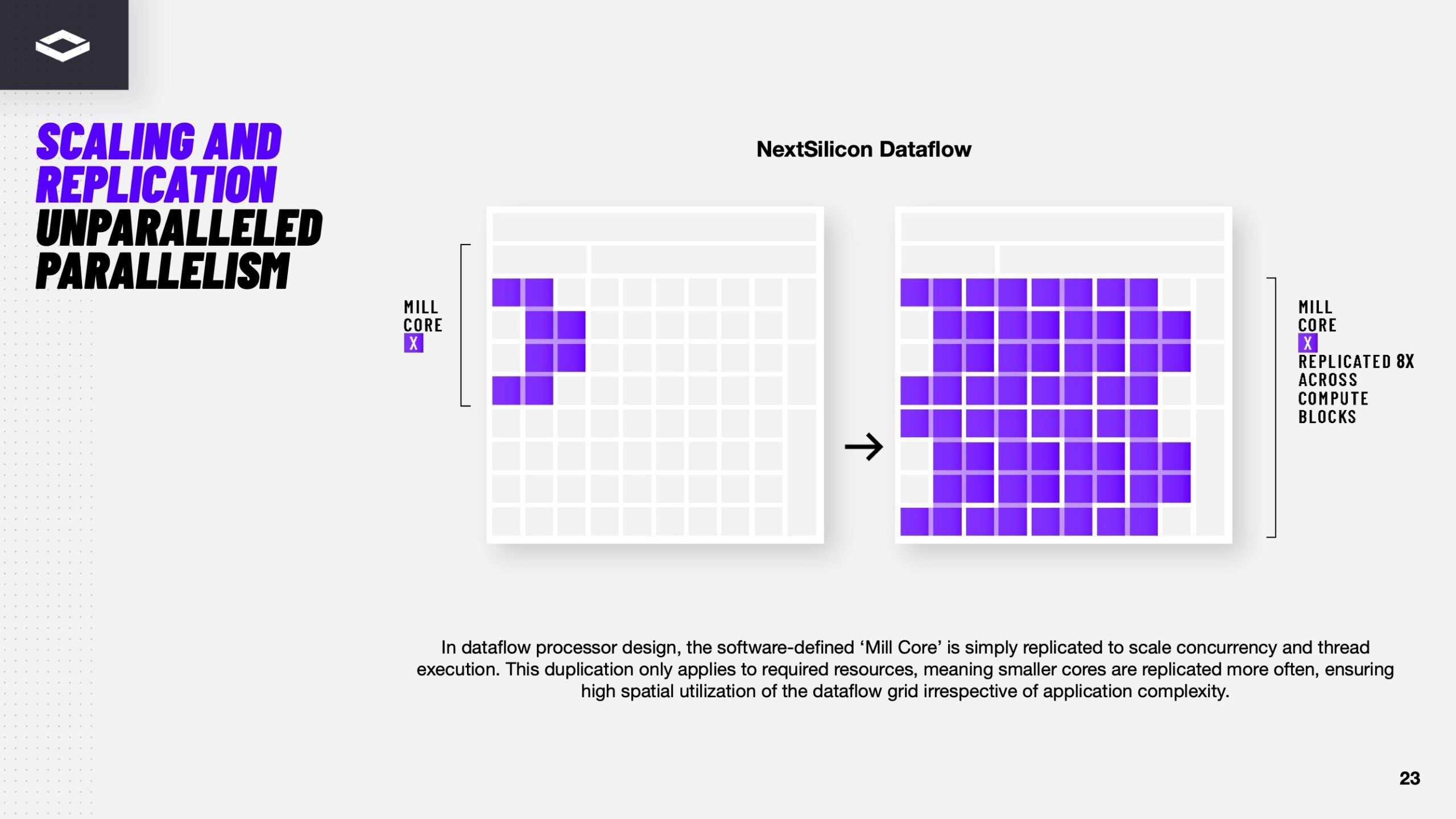 Следует отметить, что указаны максимальные значения TDP, и, как пишет ServeTheHome, ожидается, что при многих рабочих нагрузках они будут ниже. NextSilicon заявляет о возможности достижения 600 Гфлопс при потреблении 750 Вт (примерно вдвое меньше, чем у конкурентов) в бенчмарке HPCG, что составляет 4,8 Тфлопс при потреблении 6 кВт для UBB. Компания протестировала как однокристальную, так и двухкристальную версии Maverick2. В тесте STREAM пропускная способность чипа составила 5,2 Тбайт/с, в бенчмарке GUPS чип достиг 32,6 GUPS при потреблении 460 Вт, что в 22 раза быстрее, чем у CPU, и почти в шесть раз быстрее, чем у GPU для таких приложений как СУБД, агентное принятие ИИ-решений в режиме реального времени и ИИ-инференс на основе разрозненных данных. 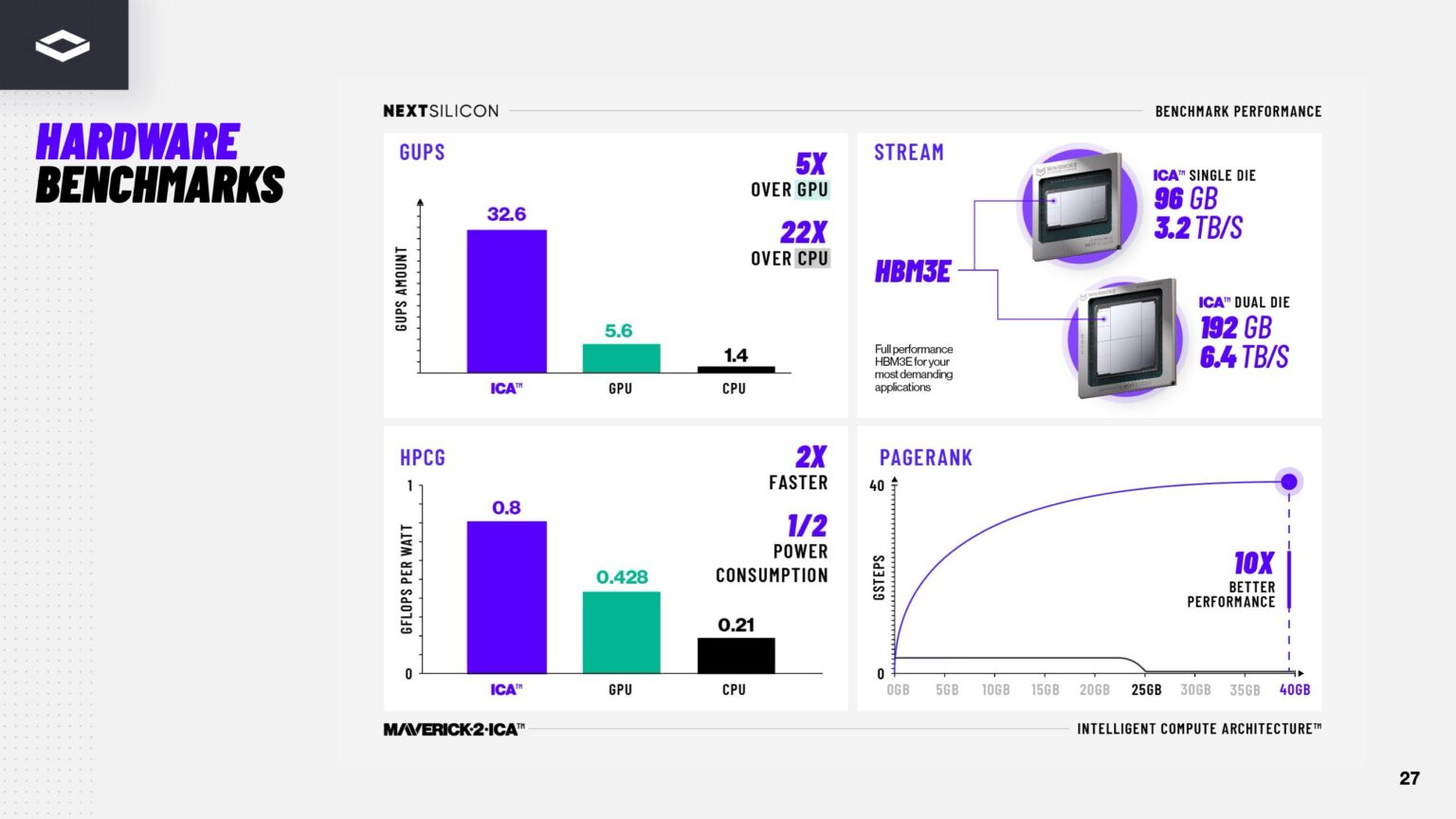 В тесте Google PageRank (PR) чип показал результат 40 Гигастраниц/с, что в 10 раз выше, чем у ведущих GPU, при вдвое меньшем энергопотреблении. Компания отметила, что при больших размерах графов (более 25 Гбайт) ведущие GPU не смогли полностью пройти тест, в то время как Maverick-2 справился с ними без труда, продемонстрировав критическую потребность в адаптивных архитектурах, способных справиться со сложными рабочими нагрузками, лежащими в основе современных ИИ-систем, социальной аналитики и сетевого интеллекта.  «[Эти результаты были] достигнуты с использованием существующего, немодифицированного кода приложения», — подчеркнул Эяль Нагар (Eyal Nagar), соучредитель и вице-президент по исследованиям и разработкам NextSilicon. «Нашим конкурентам требуются специализированные команды для модификации кода, BIOS, прошивок, ОС и параметров, чтобы достичь заявленных бенчмарков. NextSilicon обеспечивает превосходные результаты, используя уже готовое ПО», — добавил он.  NextSilicon также представила тестовый кристалл для процессора корпоративного уровня на базе ядер RISC-V, который компания планирует использовать в качестве хост-процессора в ускорителе следующего поколения Maverick-3. Процессор Arbel, разработанный с нуля, с шириной конвейера в 10 команд представляет собой эволюцию более компактных ядер RISC-V на базе Maverick-2, обрабатывающих последовательный код. По словам компании, ядра имеют производительность ядер на уровне AMD Zen 5 или Intel Lion Cove. 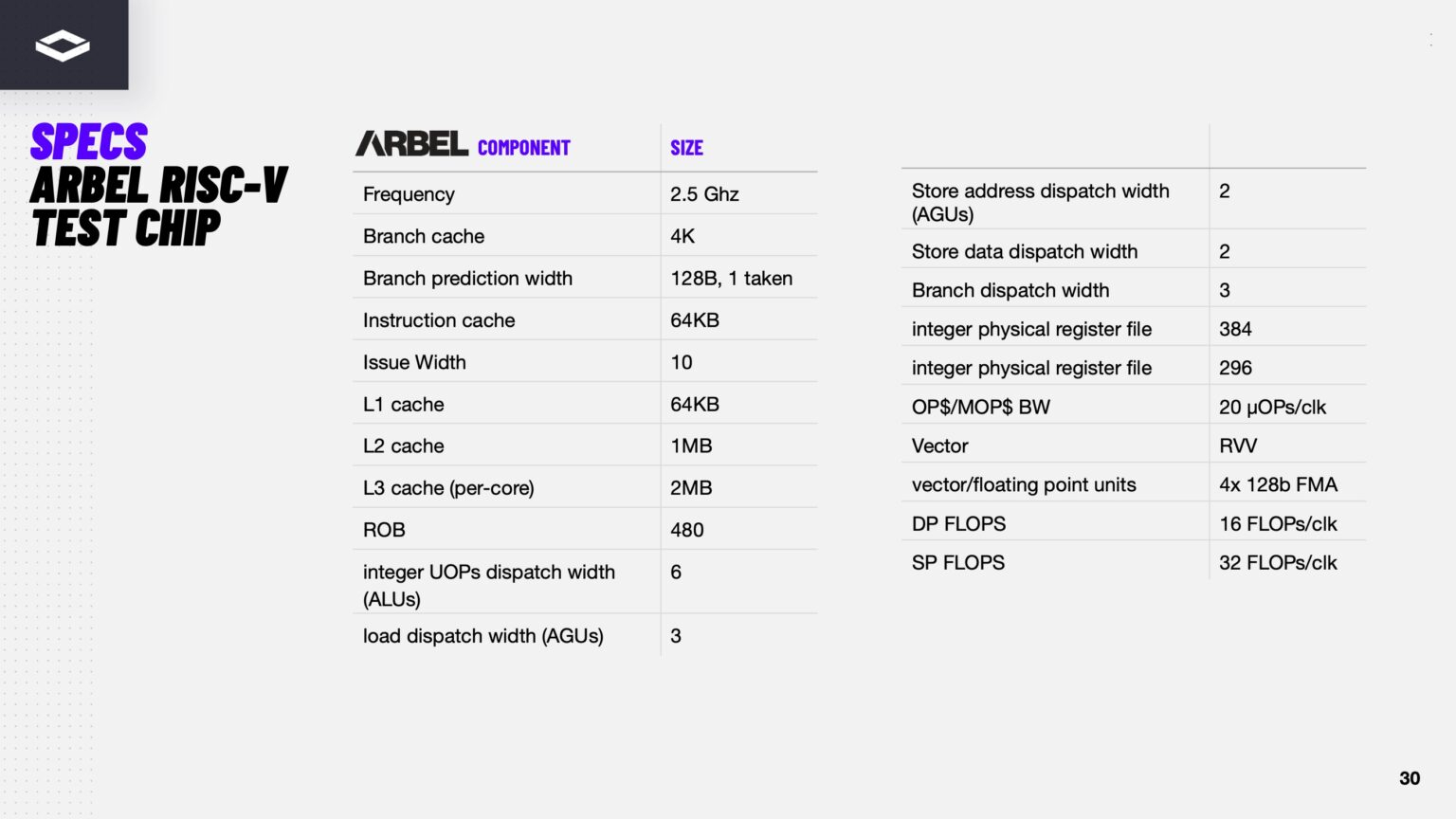 NextSilicon сообщила, что Arbel обеспечивает прорывную производительность благодаря четырём ключевым архитектурным инновациям:
«Это настоящий кремний, созданный по 5-нм техпроцессу TSMC — наша собственная запатентованная интеллектуальная собственность, а не лицензированная или заимствованная. Создан инженерами NextSilicon для воплощения видения будущего NextSilicon», — заявил Элад Раз. 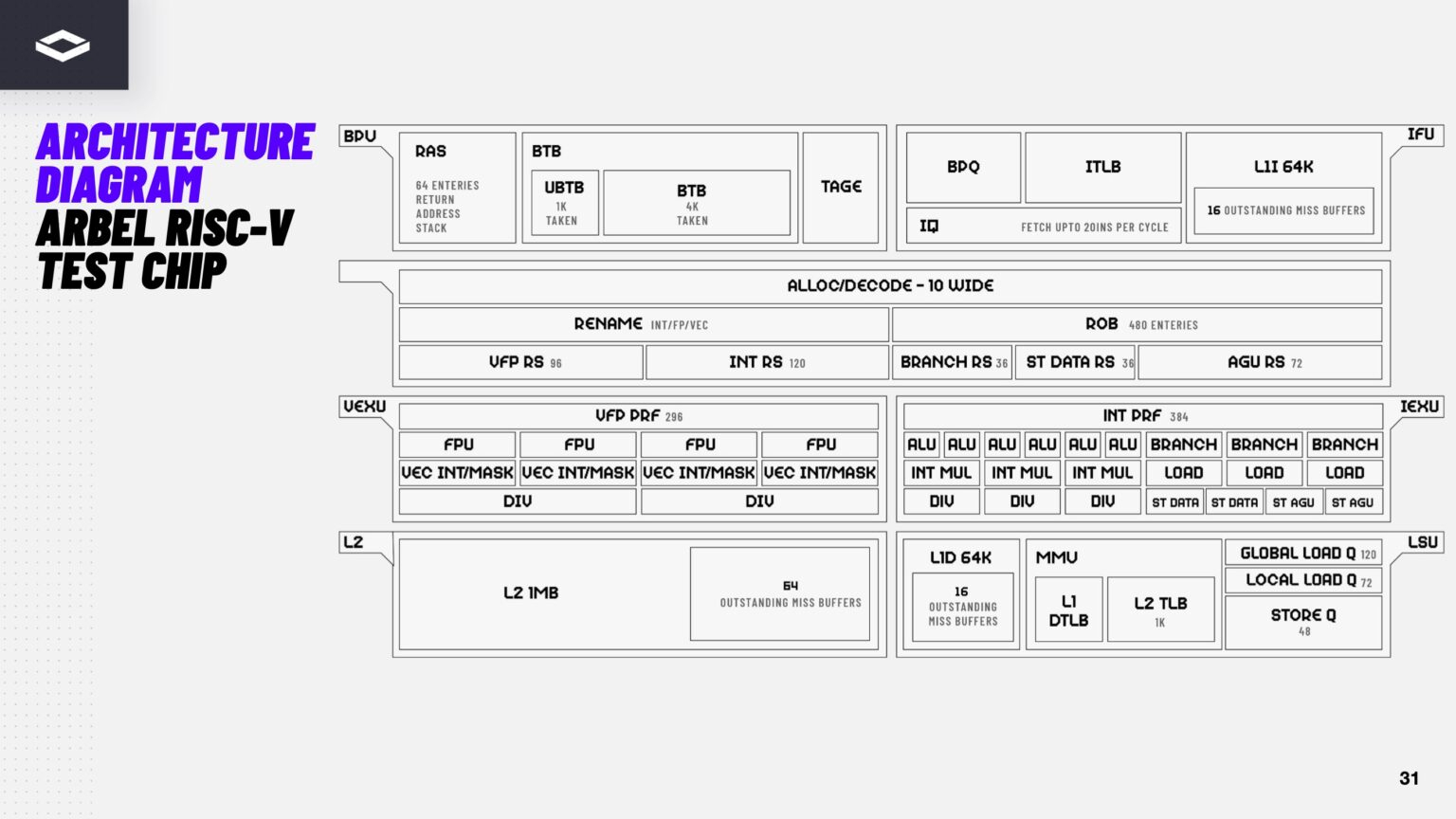 По данным компании, флагманский ускоритель Maverick2, помимо SNL, уже используется «десятками» заказчиков. Его массовые поставки начнутся в начале 2026 года, чтобы обеспечить значительный портфель заказов. NextSilicon сотрудничает с различными организациями, от Министерства энергетики США до ведущих научно-исследовательских институтов, а также коммерческих клиентов в сфере финансовых услуг, энергетики, производства и биологических наук. Программы раннего внедрения для новых клиентов уже доступны через партнёров Penguin Solutions и Dell Technologies. Ускоритель следующего поколения NextSilicon Maverick3 будет поддерживать вычисления с пониженной точностью для ИИ-задач и, как ожидается, появится в продаже в 2027 году, пишет EE Times.
04.11.2024 [17:05], Сергей Карасёв
NextSilicon представила самооптимизирующиеся ускорители вычислений Maverick-2Компания NextSilicon сообщила о разработке устройств Maverick-2 — так называемых интеллектуальных вычислительных ускорителей (Intelligent Compute Accelerator, ICA). Изделия, как утверждается, обеспечивают высокую производительность и эффективность при решении задач HPC и ИИ, а также при обслуживании векторных баз данных. NextSilicon разрабатывает новую вычислительную платформу для ресурсоёмких приложений. Применяются специальные программные алгоритмы для динамической реконфигурации оборудования на основе данных, получаемых непосредственно во время выполнения задачи. Это позволяет оптимизировать производительность и энергопотребление. 
Источник изображений: NextSilicon Maverick-2 ICA, по словам компании, представляет собой программно-определяемый аппаратный ускоритель. По заявлениям NextSilicon, изделие в плане производительности на один ватт затрачиваемой энергии более чем в четыре раза превосходит традиционные GPU, а в сравнении с топовыми CPU и вовсе достигается 20-кратное превосходство. При этом говорится об уменьшении эксплуатационных расходов более чем в два раза.  «Телеметрические данные, собранные во время работы приложения, используются интеллектуальными алгоритмами NextSilicon для непрерывной самооптимизации в реальном времени. Результатом являются эффективность и производительность в задачах HPC при сокращении потребления энергии на 50–80 % по сравнению с традиционными GPU», — заявляет компания. Решения Maverick-2 доступны в виде однокристальной карты расширения PCIe 5.0 x16 и двухкристального OAM-модуля. В первом случае объём памяти HBM3e составляет 96 Гбайт, энергопотребление — 300 Вт. У второго изделия эти показатели равны 192 Гбайт и 600 Вт. Тактовая частота в обоих вариантах — 1,5 ГГц. При производстве применяется 5-нм технология TSMC. Говорится о совместимости с популярными языками программирования и фреймворками, такими как C/C++, Fortran, OpenMP и Kokkos. Это позволяет многим приложениям работать без изменений, упрощая портирование и устраняя необходимость в проприетарном программном стеке. |
|

