Материалы по тегу: инференс
|
09.04.2026 [14:00], Владимир Мироненко
SambaNova и Intel готовят гетерогенное решение для агентного ИИ — конкурента продуктам NVIDIASambaNova в рамках следующего этапа сотрудничества с Intel анонсировала гетерогенное аппаратное решение, которое объединяет GPU, процессоры Intel Xeon 6 и RDU SambaNova для инференса для «самых требовательных» приложений агентного ИИ. Новинка вместе с полным ИИ-стеком станет доступна во II половине 2026 года. Компании также планируют развернуть облачную ИИ-платформу. В данном решении GPU отвечают за высокопараллельную фазу предварительного заполнения, эффективно преобразуя длинные запросы в KV-кеши, а RDU SambaNova обеспечивают высокопроизводительное декодирование с низкой задержкой. Xeon функционируют как хост-процессор для управления системой, координации задач агентного ИИ, распределения рабочей нагрузки, обработку API и т.д. Xeon также отвечает за компиляцию и запуск кода, он же проверяет результаты. 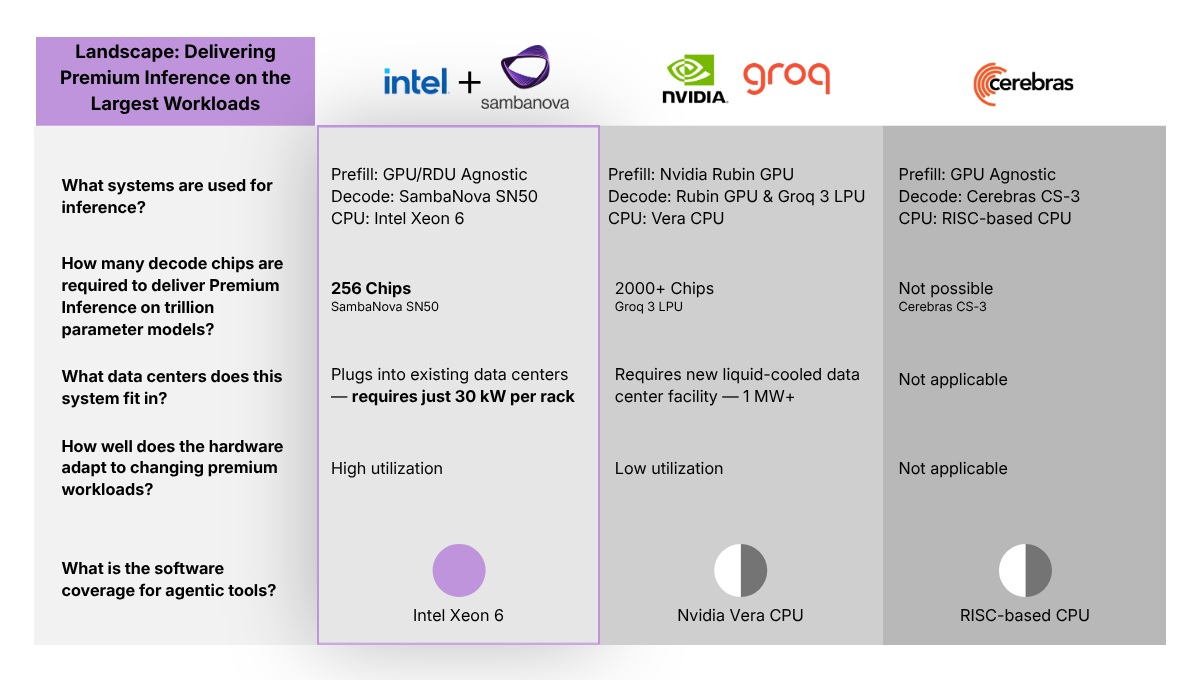
Источник изображений: Sambanova По результатам измерений SambaNova, Xeon 6 обеспечивает более чем на 50 % более быстрое время компиляции LLVM по сравнению с серверными процессорами на базе Arm и до 70 % более высокую производительность векторных баз данных по сравнению с доступными решениями на базе x86. Это ускоряет создание агентов, позволяя разработчикам быстрее переходить от идеи к реализации, говорят компании.  Как отметил ресурс Data Center Dynamics, это объявление было сделано спустя месяц после того, как SambaNova представила чип SN50 для рабочих нагрузок агентного ИИ, который, по утверждению компании, в пять раз быстрее конкурентов и втрое выгоднее с точки зрения TCO. Тогда же SambaNova также объявила о «многолетнем стратегическом сотрудничестве» с Intel для предоставления «высокопроизводительных и экономически эффективных решений для ИИ-инференса для компаний, занимающихся разработкой ИИ, поставщиков моделей, предприятий и государственных организаций по всему миру». Ранее Intel анонсировала похожую гибридную систему на базе собственных ускорителей Habana Gaudi3 и NVIDIA B200. Такого же подхода с распределением этапов инференса по разным чипам придерживается и NVIDIA в кластерах Vera Rubin, дополненных LPU Groq (вместо Rubin CPX). Основное различие между подходом Intel с SambaNova и подходом NVIDIA в том, что первый ориентируется на «более безопасный» вариант, поскольку не требует сложной базовой инфраструктуры для дезагрегированного инференса. Для заказчиков, ищущих более модульное решение стоечного масштаба, ориентированное на разделение «предварительное заполнение + декодирование», вариант Intel + SambaNova может быть более привлекательным.
06.04.2026 [01:27], Владимир Мироненко
Разработчик ИИ-чипов Hailo хочет побыстрее выйти на биржу, чтобы поправить пошатнувшееся финансовое положениеИзраильский стартап Hailo планирует в ближайшее время выйти на биржу путём SPAC-слияния, сообщил ресурс CTech со ссылкой на документы, поданные инвестором Hailo, компанией Delek Automotive. С помощью размещения акций стартап намерен укрепить финансовое положение в условиях «острой необходимости в ликвидности». В январе Hailo уволил почти 10 % своих сотрудников из-за проблем с финансами. Сделка пройдёт при значительно более низкой оценке Hailo, чем в предыдущих раундах финансирования, из-за чего Delek Automotive зафиксировала убыток в размере приблизительно ₪242 млн (около $77 млн) от своих инвестиций в 2025 году. В январе 2026 года Delek Automotive предоставила Hailo кредит в размере $9 млн под 1,5 % в месяц. Процентная ставка может вырасти до 3 %, если в течение года Hailo не проведёт операции, обеспечивающие ликвидность. Оставшиеся на балансе Delek Automotive инвестиции Hailo теперь составляют примерно ₪170 млн ($55 млн) на конец 2025 года, по сравнению с примерно ₪412 млн годом ранее. По данным Delek Automotive, рыночная стоимость Hailo теперь составляет менее $500 млн, что гораздо ниже $1,2 млрд в 2024 году. Эта новая оценка основана на предложениях, полученных от нескольких SPAC-компаний, и дополнительно снижена примерно на 26 % с учётом периода, необходимого для завершения слияния. 
Источник изображения: Hailo Компания Hailo, основанная в 2017 году Орром Даноном (Orr Danon), Ави Баумом (Avi Baum) и группой бывших сотрудников Unit 81, разрабатывает специализированные ИИ-ускорители для периферии. В 2021 году компания стала «единорогом» после привлечения $136 млн при оценке примерно в $1 млрд. В апреле 2024 года она завершила дополнительный раунд финансирования серии C на сумму $120 млн при оценке $1,2 млрд. Раунд совпал с выходом ускорителя Hailo-10 для приложений генеративного ИИ. Чипы Hailo используются в камерах, промышленных роботах и широком спектре других устройств. Благодаря использованию dataflow-архитектуры ускорители компании обеспечивают более высокую скорость инференса по сравнению с изделиями конкурентов. Компания поставляет чипы с набором программных инструментов, созданных для упрощения разработки проектов клиентов в области ИИ. Предлагается среда HailoRT, позволяющая объединить до 16 чипов Hailo в кластер. Кроме того, Hailo предлагает набор предварительно обученных ИИ-моделей, оптимизированных для работы на её чипах.
03.04.2026 [09:52], Сергей Карасёв
d-Matrix приобрела разработки GigaIO в области дата-центров, включая НРС-платформу SuperNODEСтартап d-Matrix, занимающийся разработкой ИИ-ускорителей и других специализированных изделий для НРС-систем, объявил о заключении соглашения по приобретению у компании GigaIO активов и разработок, связанных с дата-центрами. Стоимость сделки не раскрывается. В ассортименте d-Matrix присутствуют ускорители Corsair, базирующиеся на технологии вычислений в памяти DIMC (digital in-memory computing), а также IO-карты JetStream, предназначенные для распределения нагрузок ИИ-инференса между серверами в дата-центре. Кроме того, стартап создал стоечную систему SquadRack для пакетного инференса со сверхнизкой задержкой. В свою очередь, GigaIO предлагает так называемый суперкомпьютер в стойке SuperNODE для рабочих нагрузок генеративного ИИ и приложений НРС. Компания разработала архитектуру FabreX на базе PCI Express, которая позволяет объединять различные компоненты, включая GPU, FPGA и пулы памяти. Ещё одним продуктом GigaIO является «суперкомпьютер в чемодане» Gryf, который, как утверждается, обеспечивает ИИ-производительность класса ЦОД на периферии. 
Источник изображения: GigaIO d-Matrix и GigaIO начали сотрудничество весной 2025 года. Тогда стороны объединили усилия для создания «самого масштабируемого в мире» решения для инференса. Речь идёт об интеграции ИИ-ускорителей Corsair в состав платформы SuperNODE. В рамках нового соглашения d-Matrix приобрела у GigaIO основные технологии для дата-центров, включая SuperNODE и архитектуру FabreX. По условиям сделки, в d-Matrix перейдут ведущие специалисты GigaIO по разработке стоечных систем: предполагается, что это позволит ускорить развёртывание комплексных решений для высокопроизводительного инференса в ЦОД. Вместе с тем GigaIO сосредоточится на внедрении вычислительных мощностей уровня ЦОД непосредственно на периферии. В частности, планируется дальнейшее развитие концепции Gryf. По заявления GigaIO, рынок периферийных вычислений обладает огромным потенциалом. Благодаря решениям на основе Gryf клиенты смогут обрабатывать критически важные данные ближе к их источнику без проблем с задержками. При этом монтировать Gryf можно практически в любой локации.
27.03.2026 [10:03], Руслан Авдеев
ЦЕРН: для самых больших открытий на БАК нужны самые маленькие ИИ-модели, которые «зашиты» прямо в чипыИИ-инфраструктура Большого адронного коллайдера (БАК) имеет мало общего с классическим решениями на основе TPU или GPU. Вместо этого ЦЕРН (CERN) буквально «выжигает» кастомные ИИ-модели в «кремнии» для фильтрации огромных массивов данных практически в реальном времени, сообщает The Register. Ежегодно коллайдер «генерирует» 40 тыс. Эбайт «сырых» данных от сенсоров — приблизительно четверть объёма всего интернета. Такую информацию CERN хранить не может, поэтому приходится выбирать в режиме реального времени то, что представляет какую-либо ценность. Речь идёт о потоке данных до сотен терабайт в секунду. Алгоритмы для их обработки должны быть чрезвычайно быстрыми. Именно поэтому их приходится буквально «выжигать» непосредственно в чипах. В 27-км кольце БАК субатомные частицы сталкиваются на скоростях, близких к скорости света. По кольцу постоянно перемещаются около 2,8 тыс. пучков протонов с 25-с интервалами. Хотя учёные «помогают» частицам, столкновения случаются сравнительно редко — из миллиардов протонов в каждой сессии сталкиваются лишь порядка 60 пар. При столкновении образуются новые частицы, улавливаемые детекторами CERN. 
Источник изображения: Brandon Style/unsplash.com Каждое столкновение пары частиц генерирует несколько мегабайт данных. В секунду происходит около миллиарда столкновений, что приблизительно даёт около 1 Пбайт информации. Естественно, собирать и хранить такие объёмы «сырой» информации технически невозможно, поэтому CERN создал гигантскую вычислительную систему для разделения данных на «интересные» и «неинтересные» ещё на уровне детекторов. 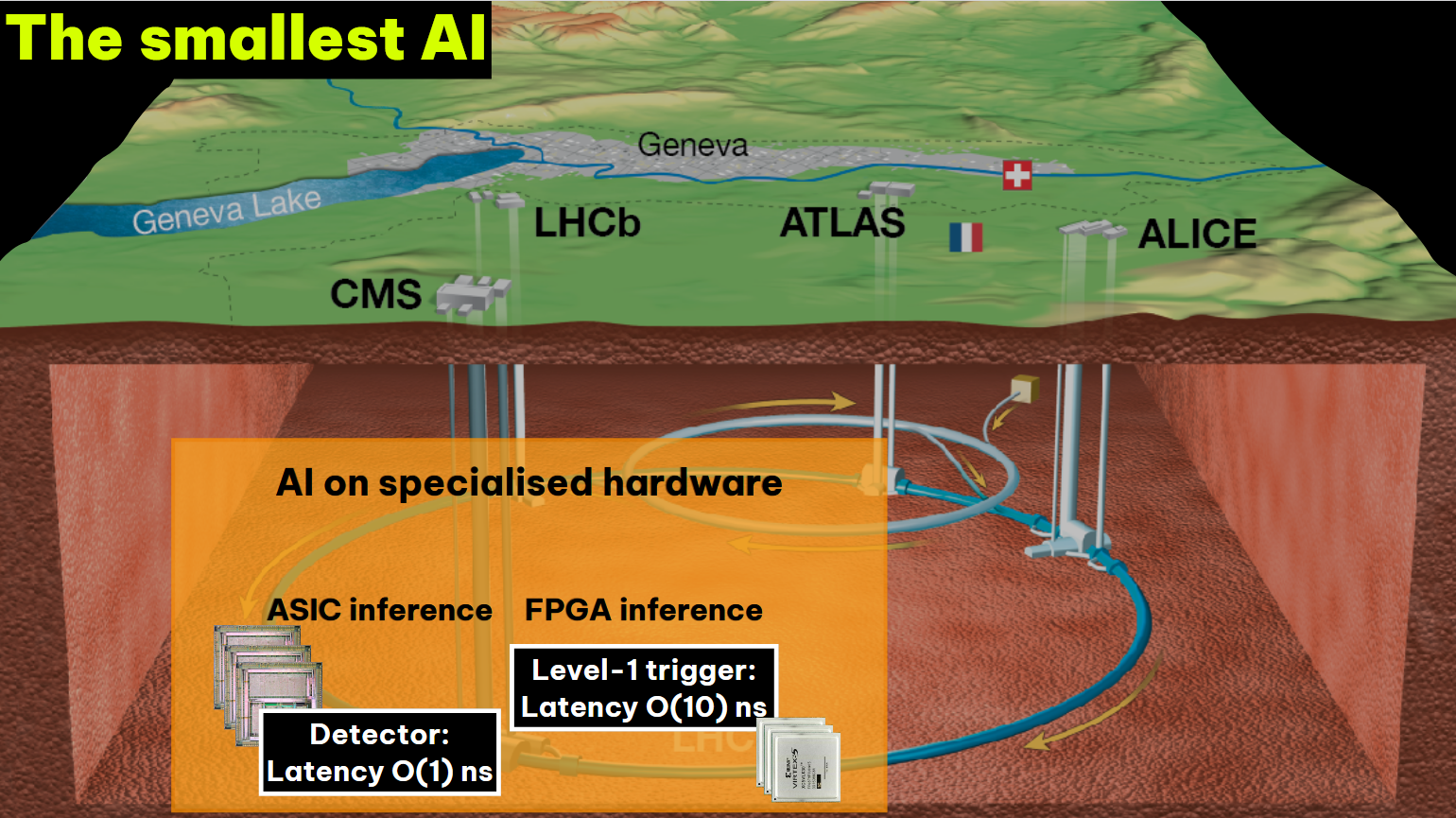
Источник изображения: Thea Klaeboe Aarrestad (ETH Zürich) Детекторы используют ASIC для буферизации данных за не более чем 4 мкс — они либо сохраняются, либо исчезают навсегда. Решение принимает фильтр Level One Trigger на базе порядка 1 тыс. FPGA, получающих данные по оптической линии на скорости около 10 Тбайт/с. Решения принимаются на лету силами самих чипов по мере поступления данных — даже самая быстрая внешняя память не справится с таким потоком информации. Специальный алгоритм AXOL1TL принимает решение не более чем за 50 нс. Фактически сохраняется лишь около 0,02 % информации о столкновениях, или приблизительно 110 тыс. событий в секунду. Отобранные сведения отправляются на поверхность, но даже после первичной фильтрации речь идёт о передаче терабайт данных ежесекундно. 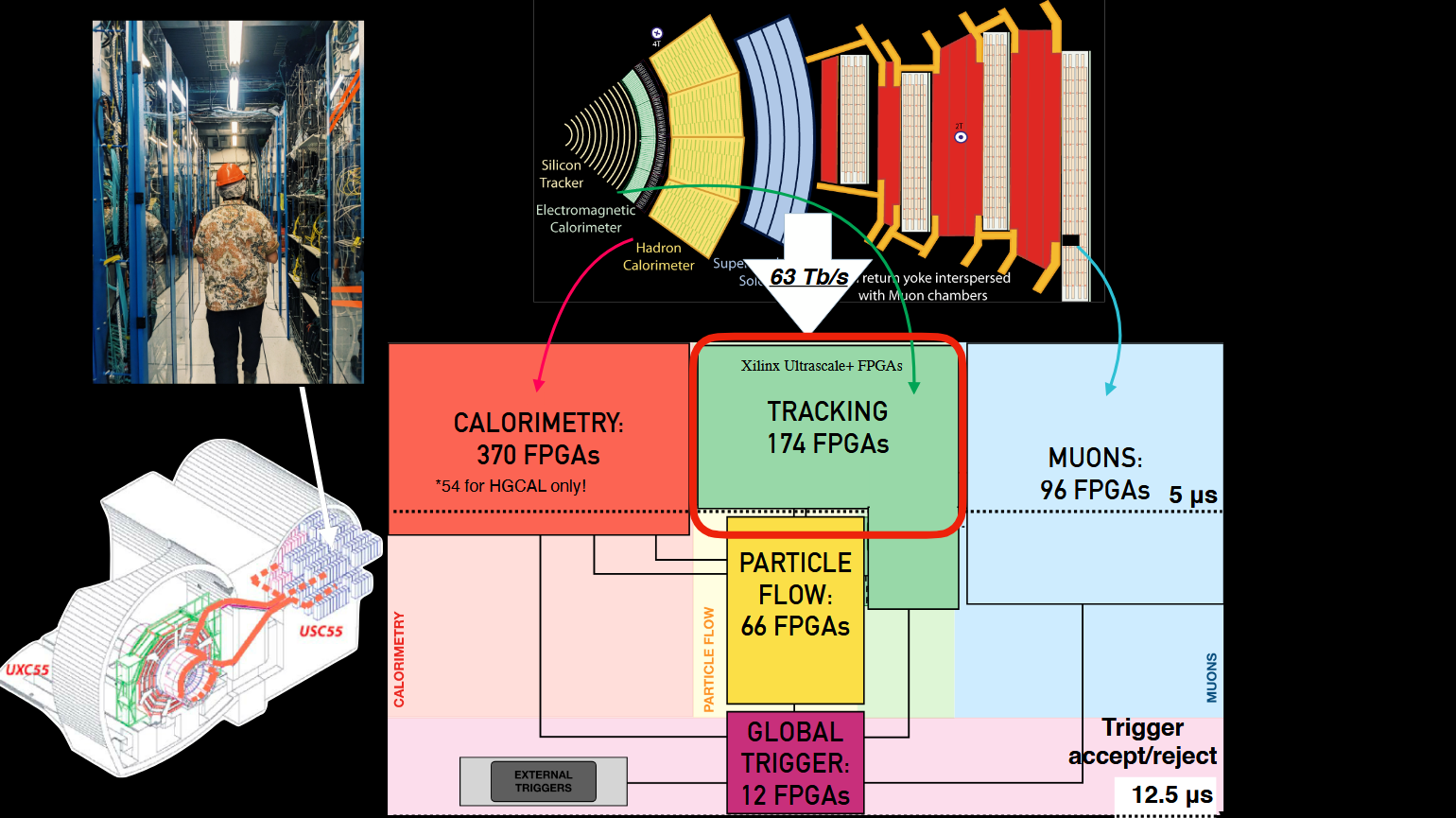
Источник изображения: Thea Klaeboe Aarrestad (ETH Zürich) На поверхности второй фильтр — High Level Trigger — оставляет для изучения уже около 1 тыс. событий в секунду. Система оснащена 25,6 тыс. CPU и 400 GPU, которые реконструируют столкновения и отбирают наиболее интересные для анализа результатов. На выходе получается около 1 Пбайт/день новых данных, которые распределяются между 170 научными центрами в 42 странах, где их могут анализировать учёные со всего света. Совокупная вычислительная мощность всех участников проекта составляет около 1,4 млн ядер. CERN стремится измерить параметры столкновений с точностью 99,999 % — это «золотой стандарт», необходимый для заявлений о научных открытиях. 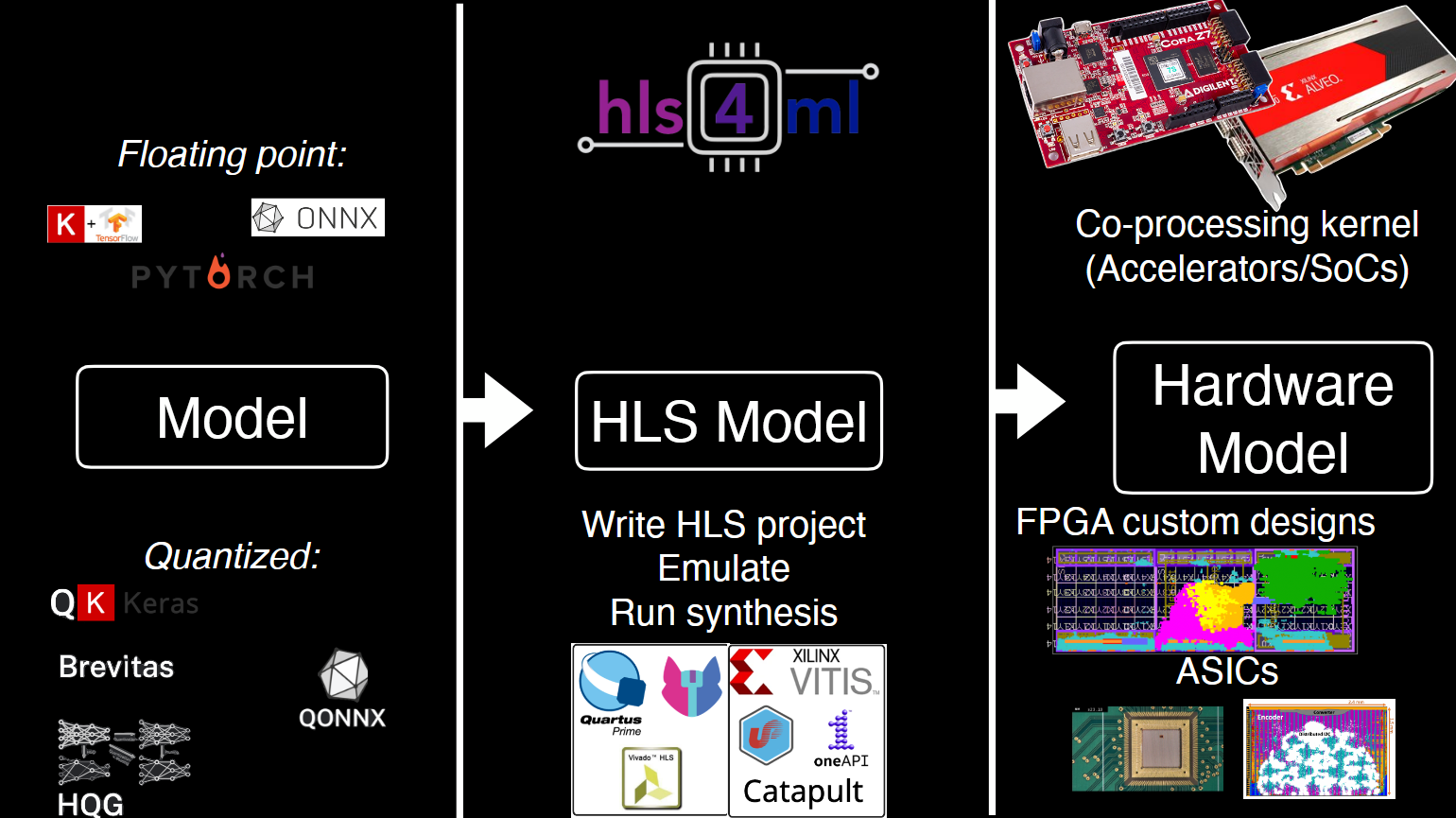
Источник изображения: Thea Klaeboe Aarrestad (ETH Zürich) Обычный ИИ-инструментарий плохо подходит для детекторов, поэтому инженерам CERN пришлось разработать собственный стек. ИИ-модели для БАК специально уменьшены, модернизированы, параллелизованы и «вымуштрованы» для выявления только действительно существенных данных. В случае с БАК они не менее производительны, но значительно «дешевле» традиционных ML-моделей. Для переноса моделей в аппаратную среду используется компилятор HLS4ML, конвертирующий модель в код C++, который можно запускать на ИИ-ускорителях, SoC, кастомных FPGA и даже «выжигать» в ASIC. При этом значительная часть ресурсов чипа отведена не под сам алгоритм, а под таблицы с предварительно рассчитанными результатами для типовых входящих значений, чтобы ещё быстрее фильтровать информацию. 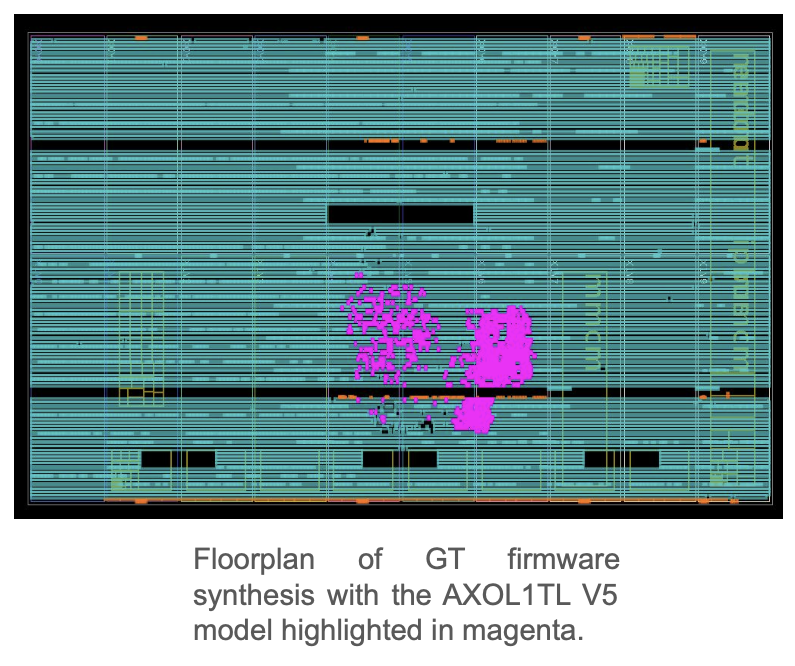
Источник изображения: CERN В конце года БАК закроют, а новый, более мощный коллайдер High Luminosity LHC должен заработать в 2031 году. Он получит более сильные магниты для фокусировки пучков частиц, сами пучки удвоятся в размерах, коллайдер будет генерировать в 10 раз больше данных, а объём информации от каждого события увеличится с 2 до 8 Мбайт. CERN уже накопил 1 Эбайт от БАК, но это лишь десятая часть от того, что предстоит хранить и обрабатывать в последующие 10 лет. И пока передовые ИИ-лаборатории создают LLM всё большего объёма, CERN движется в противоположном направлении, всеми силами упрощая и ускоряя выявление необычных событий с помощью искусственного интеллекта.
26.03.2026 [14:25], Руслан Авдеев
Gartner: к 2030 году себестоимость инференса снизится на 90 %, но качественный ИИ дешевле не станетСогласно прогнозу Gartner, к 2030 году инференс LLM с триллионом параметров будет обходиться провайдерам ИИ-сервисов более чем на 90 % дешевле в сравнении с 2025 годом. При этом речь не идёт о получении всеобщего доступа к передовым вычислениям. В Gartner для исследования каждый токен «оценили» в 3,5 байта или приблизительно четыре символа английского текста. Эксперты предполагают, что снижение затрат будет обусловлено сочетанием повышенной эффективности ИИ-чипов и сопутствующей инфраструктуры, инновациями в разработке самих моделей, повышением эффективности использования чипов, расширением использования специализированных инференс-ускорителей, а также распространением периферийных вычислений для определённых сценариев. В результате, по прогнозам Gartner, к 2030 году LLM станут в 100 раз более экономически эффективными в сравнении с первыми моделями аналогичного масштаба, представленными в 2022 году. Согласно выкладкам Gartner, эксплуатировать модели с помощью передовых ИИ-чипов будет предсказуемо значительно дешевле, чем с использованием более старого или смешанного оборудования на основе более доступных полупроводников с учётом меньшей вычислительной мощности. Про это, в частности, регулярно говорит NVIDIA. 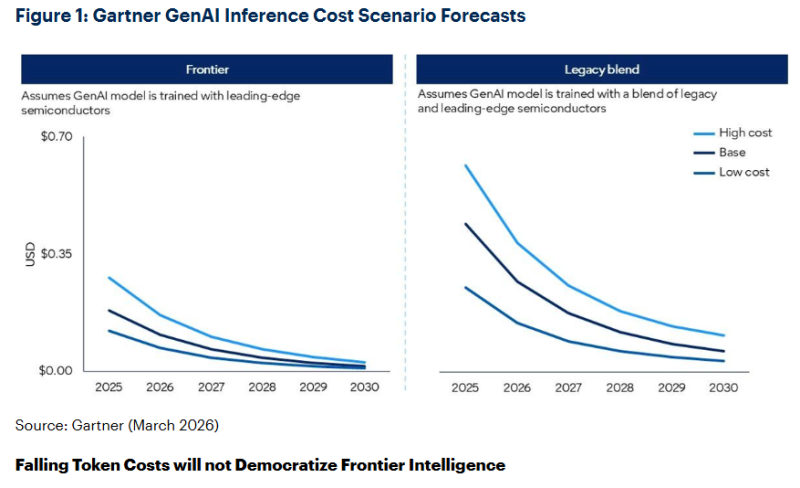
Источник изображения: Gartner Впрочем, снижение стоимости токенов вовсе не означает, что передовые технологии станут более доступными для всех. Во-первых, снижение себестоимости для ИИ-провайдеров не будет означать соизмеримого падения цен для корпоративных клиентов. Кроме того, передовым ИИ-технологиям нужно будет значительно больше токенов, чем сегодня. Так, ИИ-агенты требуют на задачу в 5–30 раз больше токенов, чем обычный чат-бот, и способны выполнять значительно больше задач, чем обычный человек, использующий ИИ. Хотя возможности ИИ расширятся, это будет сопровождаться «непропорционально большим» ростом спроса на токены. Их потребление растёт быстрее, чем снижается стоимость, поэтому ожидается увеличение затрат на инференс. Подчёркивается, что речь не идёт о демократизации передовых вычислений. Стоимость «стандартного» ИИ действительно продолжит падать, но ресурсы, необходимые для сложных ИИ-проектов, по-прежнему будут в дефиците. Руководителям ИИ-проектов, пока маскирующим недостатки их архитектур дешевеющими токенами, придётся столкнуться с трудностями при масштабировании вычислений, связанных с ИИ-агентами. По прогнозам Gartner, наиболее востребованными станут платформы, позволяющие координировать рабочие нагрузки, распределяемые в рамках целого портфеля моделей. Так, рутинные задачи необходимо поручать небольшим, специализированным ИИ-моделям, лучше подходящим при меньших затратах для специальных рабочих процессов в сравнении с универсальными решениями. А дорогостоящие ресурсы передовых моделей необходимо выделять со строгими ограничениями, резервируя их только для сложного, но высокомаржинального инференса.
24.03.2026 [23:10], Владимир Мироненко
Alibaba представила самый производительный в мире процессор на базе RISC-V — XuanTie C950Alibaba представила серверный процессор XuanTie C950 с частотой 3,2 ГГц, созданный на основе открытой архитектуры RISC-V и изготовленный по 5-нм техпроцессу, сообщил ресурс SCMP. Как заявила компания, процессор оптимизирован для облачных вычислений и ИИ-нагрузок, и сможет обрабатывать многоэтапные задачи, выполняемые ИИ-агентами. По словам компании, это «самый высокопроизводительный процессор с архитектурой RISC-V в мире». Мэн Цзяньи (Meng Jianyi), главный научный сотрудник DAMO Academy, исследовательского подразделения Alibaba, заявил, что производительность C950 более чем в три раза больше, чем у C920 прошлого поколения. «Открытая природа RISC-V позволяет разработчикам микросхем настраивать наборы инструкций и ускорять выполнение конкретных задач ИИ без или с низкими лицензионными сборами. Это особенно важно для разработки ИИ-агентов», — приводит Reuters сообщение компании. 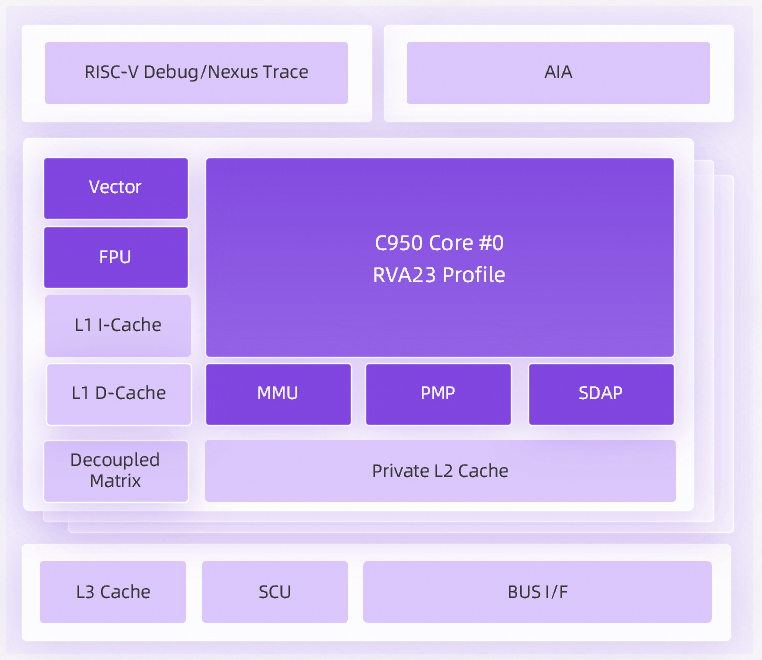
Источник изображения: Alibaba Подразделение DAMO Academy, разработавшее дизайн чипа, сообщило, что XuanTie «могут быть настроены под конкретные шаблоны инференса, помогая клиентам адаптировать чипы под свои нужды». Alibaba добавила, что по сравнению с некоторыми массовыми продуктами её процессор обеспечивает более чем 30 % «улучшение производительности благодаря гибкости в настройке для конкретных сценариев использования». На разработку C950 потребовалось два года, и это первый чип в линейке XuanTie, разработанный с нуля с учётом выполнения инференса LLM как базовой рабочей нагрузки. Предыдущий серверный чип, C930, был представен в феврале 2025 года, его поставки стартовали спустя месяц. Его предшественник, C920, поставляется с 2024 года. XuanTie C950 — это 64-бит процессор с декодером шириной 8 инструкций и 16-стадийным конвейером, предсказателем ветвлений TAGE и настраиваемым механизмом предвыборки, соответствующий профилю RVA23 и дополненный некоторыми другими инструкциями. Заявленная производительность в SPECint2006 составляет 22/ГГц. Чип включает 256-бит векторные регистры и поддержку FP16/BF16/FP32/FP64/INT8/INT16/INT32/INT64. Типовой объём кеша инструкций составляет 64 Кбайт с опциональной проверкой чётности, кеша данных — тоже 64 Кбайт, ECC опционально. L2-кеш собственный у каждого ядра — типовой объём составляет 1 Мбайт, ECC опционально. Типовой кластер состоит из 8 ядер. Для внутренней связи используется шина CHI.E/CHI.F, для внешней — AMBA ACE4.0/AXI4.0. 
Источник изображения: Alibaba Благодаря совместной оптимизации программного и аппаратного обеспечения, C950 обеспечивает высокую производительность в облачных вычислениях, включая запуск MySQL, Redis, Nginx и OpenSSL, инференс больших языковых моделей, включая Qwen и DeepSeek, а также при использовании вместе с разработанными компанией интегрированными ИИ-движками — Alibaba Vector Acceleration Engine и Matrix Acceleration Engine. Оба движка разработаны совместно с CPU-ядрами, а не «прилеплены» к ним. C950 — первый процессор RISC-V, который изначально поддерживает инференс LLM с миллиардом параметров на аппаратном уровне, утверждает компания. Расширения набора инструкций и аппаратные блоки разработаны для выполнения основных операций таких моделей, как Qwen3 и DeepSeek V3, без накладных расходов. C950 является флагманом портфолио чипов Alibaba.
24.03.2026 [16:58], Владимир Мироненко
CIX анонсировала Arm-процессоры ClawCore, «заточенные» под OpenClawКитайская компания CIX Technology (Cixin Technology) провела презентацию семейства процессоров ClawCore с архитектурой Armv9.2, специально разработанного для использования ИИ-агента OpenClaw, пишет CNX Software. Семейство на данный момент включает три модели: ClawCore-P, ClawCore-A и ClawCore-E. ClawCore-P — 12-ядерный процессор с тактовой частотой до 3,2 ГГц с GPU Immortalis-G720, обладающий ИИ-производительностью 45 TOPS и поддерживающий до 64 Гбайт LPDDR5. Сообщается, что характеристики ClawCore-P похожи на спецификации анонсированного ранее 6-нм процессора CIX P1 (CD8180) с 12 ядрами с архитектурой CIX P1, включая восемь производительных и четыре энергоэффективных ядра, частота которых немного меньше — до 2,8 ГГц, тоже оснащённого Immortalis-G720. ClawCore-P предназначен для сценариев с высокой степенью параллелизма и большой производительностью. Его поставки должны начаться до конца этого месяца. В июне 2026 года ожидается выпуск процессора ClawCore-A с восемью ядрами с частотой 3,0 ГГц, ИИ-производительностью 80 TOPS (расширяемой до 200 TOPS с помощью карты PCIe AI от Huomo Intelligent Technology) и поддержкой до 64 Гбайт LPDDR5. Он разработан для круглосуточной работы, поддерживает ECC, аппаратную безопасность (шифрование/управление ключами) и позволяет снизить стоимость токенов до 50 % за счёт локального инференса. На практике 80–90 % запросов будет выполняться на устройстве благодаря этой гибридной локально-онлайн реализации — крупные модели можно будет использовать через сервис Alibaba Cloud, партнёра проекта. 
Источник изображения: CNX Software Выход ещё одного процессора — ClawCore-E, который предназначен для использования в периферийных устройствах и устройствах IoT, ожидается к декабрю 2026 года. Сообщается, что это «сверхэкономичный» вариант чипа, с ядрами с архитектурой Armv9.2 и NPU с поддержкой голосового управления. Глава CIX Technology заявил, что серия ClawCore охватывает различные сценарии разработки и применения ИИ, включая периферийный ИИ, высокопроизводительный ИИ и многое другое, что позволит удовлетворить потребности отраслевых партнёров в интеллектуальных продуктах для всех сценариев, от AI BOX, AI NAS и AI Mini PC до периферийных ИИ-серверов и встроенного/промышленного ИИ-оборудования: «Чтобы решить различные проблемы, возникающие в разработке ИИ-приложений, мы создали серию CIX ClawCore. Её цель — помочь разработчикам отойти от традиционной фрагментированной модели разработки и сформировать агентно-ориентированный подход к переосмыслению разработки и внедрения ИИ». Компания CIX также планирует создать полноценную экосистему вокруг OpenClaw. Она намерена предложить готовые Linux-образы и обеспечить программную поддержку с пятью ключевыми предложениями:
Процессоры будут ориентированы на платформу Arm SystemReady и поддерживать операционные системы Windows, Android, Ubuntu, Tongxin/UnionTech и Kylin.
22.03.2026 [13:10], Сергей Карасёв
Почти втрое быстрее NVIDIA H20: Huawei представила ИИ-ускоритель Atlas 350 для инференсаКомпания Huawei Technologies, по сообщению газеты South China Morning Post (SCMP), представила ускоритель Atlas 350, предназначенный для ИИ-инференса. Утверждается, что в таких задачах новинка обеспечивает прирост производительности до 2,8 раза по сравнению с NVIDIA H20. Известно, что решение Atlas 350 выполнено на чипе Ascend 950PR. Заявленная ИИ-производительность в формате FP4 достигает 1,56 Пфлопс. Показатели быстродействия в других режимах пока не раскрываются, но ранее говорилось об 1 Пфлопс в FP8. Как отмечается, Huawei использует собственную память HBM. Её объём в зависимости от конфигурации ускорителя составляет до 128 Гбайт, пропускная способность — 1,6 Тбайт/с. Прочие технические характеристики не приводятся. Ускоритель Atlas 350 оптимизирован для предварительного заполнения (Prefill) в ходе инференса — это наиболее ресурсоёмкая фаза работы больших языковых моделей (LLM) в рамках процесса генерации контента: на данном этапе производится обработка входного запроса пользователя. Скорость выполнения предварительного заполнения напрямую влияет на показатель TTFT (Time To First Token), то есть, на время, прошедшее с момента ввода запроса до начала ответа. Таким образом, решение Atlas 350 подходит для ИИ-приложений реального времени и агентных систем. 
Источник изображения: Huawei Huawei также заявила о планах масштабного обновления своих СХД, включая решения OceanStor Dorado и Pacific 9926 класса All-Flash. Кроме того, компания готовит платформу FusionCube A1000, которая поможет малым и средним предприятиям быстро разворачивать ИИ-системы. «Если первая половина эпохи ИИ была сосредоточена на вычислительной мощности, то вторая половина будет определяться данными. В 2026 году Huawei продолжит модернизацию своих СХД и будет активно участвовать в крупных национальных проектах по формированию соответствующей инфраструктуры», — говорит Юань Юань (Yuan Yuan), президент подразделения по хранению данных Huawei.
21.03.2026 [12:53], Сергей Карасёв
11 Тбайт памяти для ИИ: Penguin Solutions представила кеширующий сервер MemoryAI KV на основе CXL-модулейКомпания Penguin Solutions анонсировала систему MemoryAI KV Cache Server призванную решить проблему «стены памяти» в современных инфраструктурах, ориентированных на ресурсоёмкие задачи ИИ-инференса. Устройство предоставляет до 11 Тбайт CXL-памяти, что позволяет максимально эффективно использовать доступные вычислительные мощности. Сервер (модель Altus XE4318GT-KVC) выполнен в форм-факторе 4U. Он несёт на борту два процессора AMD EPYC 9005 Turin в исполнении Socket SP5 (LGA 6096) с показателем TDP до 500 Вт. В оснащение входят контроллер ASpeed AST2600 и сетевой адаптер Intel I350-AM2. Реализованы два коннектора для SSD формата M.2 2280/22110 с интерфейсом PCIe 3.0, восемь слотов для карт PCIe 5.0 x16 FHFL и два слота для карт PCIe 5.0 x16 LP, два сетевых порта 400GbE (RJ45), два порта USB 3.0 (5 Гбит/с), а также аналоговый интерфейс D-Sub. Устройство поддерживает до 3 Тбайт памяти DDR5-6400. Кроме того, установлены восемь карт CXL, каждая из которых содержит 1 Тбайт памяти. Благодаря этому расширяются возможности применяемых в инфраструктуре ИИ-ускорителей с ограниченным объёмом HBM. Говорится о совместимости с программной средой NVIDIA Dynamo, предназначенной в том числе для ускорения инференса. В целом, как отмечает Penguin Solutions, новый сервер позволяет компаниям максимально эффективно использовать GPU-ускорители благодаря добавлению больших пулов памяти. 
Источник изображения: Penguin Solutions Устройство оборудовано четырьмя блоками питания мощностью 3000 Вт с сертификатом 80 Plus Titanium. Диапазон рабочих температур — от +10 до +35 °C. Заявлена совместимость с Red Hat Enterprise Linux (RHEL) и Rocky Linux. На систему предоставляется трёхлетняя гарантия.
20.03.2026 [11:35], Сергей Карасёв
NVIDIA представила архитектуру хранения данных BlueField-4 STX для ИИ-системКомпания NVIDIA анонсировала модульную эталонную архитектуру BlueField-4 STX, которая поможет предприятиям, облачным провайдерам и операторам дата-центров в создании высокопроизводительных платформ хранения данных, оптимизированных для задач ИИ. Отмечается, что в традиционных ЦОД применяются хранилища общего назначения, обладающие большой вместимостью. Однако они зачастую не способны обеспечивать скорость отклика, необходимую для работы ИИ-агентов: таким системам требуются доступ к информации в реальном времени и контекстная память. Архитектура STX призвана устранить существующие узкие места. Технологической основой STX является DPU NVIDIA BlueField-4, который объединяет Arm-процессор NVIDIA Grace/Vera, 128 Гбайт LPDDR5, 512 Гбайт SSD, сетевой адаптер NVIDIA ConnectX-9 SuperNic (1,6 Тбит/с) и коммутатор PCIe 6.0 с 48 линиями. Используются микросервисы NVIDIA DOCA и программное обеспечение NVIDIA AI Enterprise. Утверждается, что архитектура STX обеспечивает в четыре раза более высокую энергоэффективность по сравнению с традиционными архитектурами хранения, построенными на основе CPU. В целом, как отмечается, STX предоставляет основу для создания универсального механизма обработки данных, ускоряющего полный жизненный цикл ИИ — от обучения и аналитики до инференса на базе агентов. 
Источник изображения: NVIDIA Первой реализацией STX в масштабе стойки является новая платформа хранения NVIDIA CMX с контекстной памятью, которая расширяет память GPU. О поддержке NVIDIA STX сообщили такие компании, как Cloudian, DDN, Dell Technologies, Everpure, Hitachi Vantara, HPE, IBM, MinIO, NetApp, Nutanix, VAST Data и WEKA. Производством систем на базе STX займутся AIC, Supermicro и Quanta Cloud Technology (QCT). Внедрить платформу в числе прочих намерены CoreWeave, Crusoe, IREN, Lambda, Mistral AI, Nebius, OCI и Vultr. Решения на базе STX станут доступны во II половине текущего года. |
|

