Материалы по тегу: инференс
|
03.05.2026 [12:26], Руслан Авдеев
Nebius купила стартап Eigen AI, повышающий производительность ИИ-моделейНеооблачная компания Nebius Group NV объявила о приобретении стартапа Eigen AI. Разработки последнего повышают эффективность использования ИИ-ускорителей благодаря оптимизации ПО. Покупатель готов потратить приблизительно $643 млн, сообщает Bloomberg: $98 млн наличными средствами и 3,8 млн акций Nebius. Оценка акций основана на их 30-дневной средневзвешенной цене. Соучредителями калифорнийской Eigen, насчитывающей 20 сотрудников, являются выпускники известной ИИ-лаборатории Массачусетского технологического института (MIT). Стартап специализируется на оптимизации открытых ИИ-моделей, предлагаемых OpenAI, Alibaba, Meta✴ и NVIDIA. Технология позволяет максимизировать количество токенов, генерируемых каждым из ускорителей NVIDIA. Это, как утверждает Nebius, позволяет предоставлять более качественные и недорогие услуги. Отделившаяся от российской Yandex компания Nebius относится к группе «неооблачных» бизнесов, обеспечивающих аренду ИИ-мощностей гигантам вроде Microsoft. В ноябре 2025 года Nebius представила продукт Token Factory для инференса, позволяющий конкурировать с ИИ-стартапами и облачными гиперскейлерами. 
Источник изображения: Amina Atar/unsplash.com В условиях, когда мощности ЦОД в дефиците, Nebius резервирует часть собственных мощностей для нужд Token Factory, не передавая их клиентам в рамках долгосрочных контрактов. Это позволяет оптимизировать цены и расширить спектр предоставляемых компанией услуг. Цель Nebius — стать одним из ключевых игроков рынка инференса в следующие 18 мес. В Nebius сравнили получение максимального количества токенов с олимпийским видом спорта, а участников команды Eigen — с олимпийскими бегунами. Речь идёт уже о второй покупке Nebius за последние три месяца. В феврале компания заключила сделку по покупке Tavily и рассматривает и другие приобретения, хотя конкретные «кандидаты» пока не называются. В целом речь идёт о покупке компаний с командами и/или возможностями, ускоряющими реализацию анонсированной стратегии, либо добавляющих продукты и функции, доступные непосредственно клиентам. Компания подчёркивает, что не намерена выступать простым провайдером инфраструктуры, в то время как кто-то «сверху» будет работать с реальными клиентами.
02.05.2026 [23:32], Владимир Мироненко
Qualcomm готовится поставлять чипы гиперскейлеру — инвесторы довольны, поскольку на мобильном направлении не всё гладкоАкции Qualcomm выросли более чем на 15 % после сообщения компании о превышении прогнозов Уолл-стрит по прибыли и выручке во II квартале 2026 финансового года, а также заявления президента и гендиректора Кристиано Амона (Cristiano Amon) о планах начать поставки чипов для ЦОД «крупному гиперскейлеру» в течение календарного года, пишет SiliconANGLE. Выручка Qualcomm во II квартале 2026 финансового года, закончившемся 29 марта, составила $10,6 млрд, что на 3 % меньше, чем годом ранее, но чуть выше прогноза Уолл-стрит в размере $10,58 млрд. Компания сообщила о скорректированной прибыли на акцию в размере $2,65, что ниже показателя в $2,85 за тот же квартал прошлого года, но выше прогноза аналитиков в $2,55 на акцию. В полупроводниковом секторе (QCT) выручка увеличилась год к году на 4 % до $9,08 млрд. При этом выручка в автомобильном сегменте выросла на 38 % до $1,33 млрд, в сегменте IoT — на 9 % до $1,73 млрд, а в сегменте мобильных устройств упала на 13 % до $6,02 млрд. Выручка от лицензий (QTL) за квартал составила $1,38 млрд, что на 5 % больше, чем годом ранее. 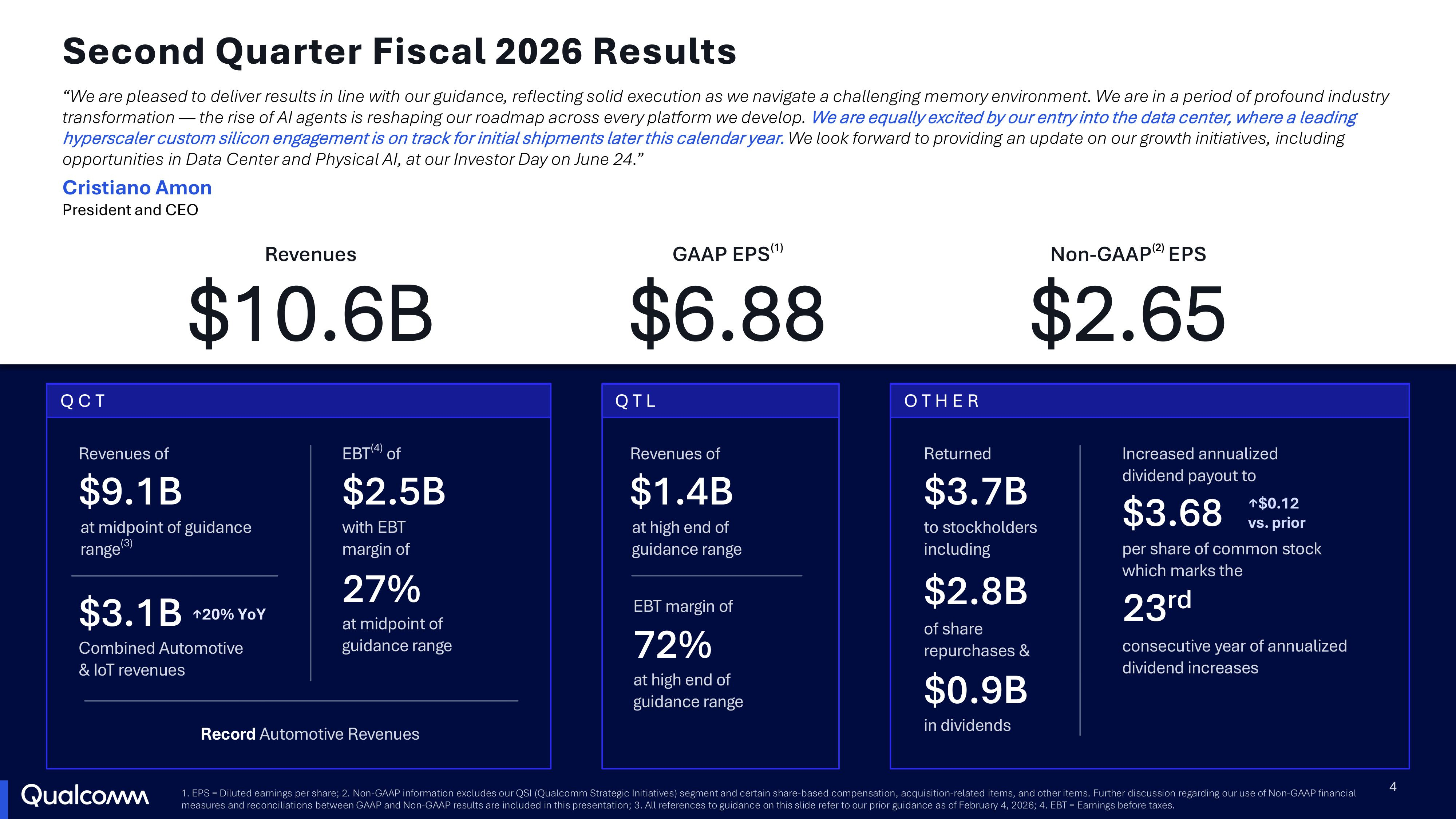
Источник изображений: Qualcomm В III финансовом квартале Qualcomm прогнозирует скорректированную прибыль на акцию в размере от $2,10 до $2,30 при прогнозе Уолл-стрит $2,43. Прогноз по выручке тоже значительно ниже консенсус-прогноза аналитиков, опрошенных LSEG (по данным Reuters) — от $9,2 до $10 млрд при прогнозе в $10,27 млрд. Свой осторожный прогноз Qualcomm объяснила ограничениями поставок памяти и связанным с этим ценовым давлением на ряд производителей мобильных устройств. Компания добавила, что выручка от продаж мобильных телефонов китайским клиентам должна достичь минимума в III квартале и вернуться к последовательному росту в следующем квартале. Qualcomm ушла с рынка продуктов для ЦОД в 2018 году, чтобы сосредоточиться на своих разработках в области смартфонов, но в августе 2025 года сообщила, что находится на «ранних этапах» возвращения на рынок и ведёт переговоры с несколькими потенциальными клиентами. Гендиректор тогда также подтвердил, что компания ведёт «продвинутые переговоры с ведущим гиперскейлером». До этого, в мае 2025 года компания подписала меморандум о взаимопонимании с Humain и объявила о работе над серверным процессором, который будет поддерживать NVIDIA NVLink.  Фактически после поглощения Nuvia компания не стала выходить на рынок ЦОД. А после долгих судебных разбирательств с Arm в связи с этой сделкой последняя фактически стала конкурентом Qualcomm и другим своим клиентам, взявшись за создание серверных CPU. С ИИ-ускорителями у компании всё тоже сложилось не очень удачно. Первое поколение широкого распространения не получило, но компания пообещала исправиться. При этом на рынке кастомных чипов для гиперскейлеров уже давно работают Broadcom и Marvell, у которых к тому же сильные компетенции в области сетевой инфраструктуры. Как пишет The Register, Кристиано Амон заявил, что компания планирует начать поставки чипов для ЦОД «ведущему гиперскейлеру» «в декабрьском квартале» и ожидает сотрудничество на несколько поколений чипов. По его словам, Qualcomm уже работает над процессором для ЦОД и высокопроизводительными ИИ-ускорителями для инференса, а также получила возможность создавать кастомные ASIC благодаря приобретению Alphawave в прошлом году за $2,4 млрд. «Мы работаем над специализированными ASIC, чего мы и хотели добиться, когда приобрели AlphaWave, — сказал Амон, — и теперь у нас есть много интеллектуальной собственности, позволяющей нам это сделать. Мы работаем над всеми тремя категориями чипов».  Амон рассказал, что Qualcomm также создала так называемый «выделенный процессор для агентских вычислений в ЦОД». По его словам, ИИ начинался с GPU для обучения, затем потребовалось специализированное оборудование для инференса, но сейчас рынок вступает в новую фазу, в которой важно «создать спрос на токены» для работы агентного ИИ. «Я думаю, что когда речь заходит об агентах, CPU становится очень важным», — сказал он, поэтому, по его словам, Qualcomm разработала именно такой чип. Кристиано Амон также прогнозирует появление «агентных смартфонов». Он привёл в качестве примера телефон ZTE, который включает в себя персонального помощника Doubao, разработанного ByteDance, и Xiaomi miclaw — ИИ-ассистента, интегрированного с ядром ОС, который анализирует запрос пользователя и определяет, какие приложения и функции смартфона нужно задействовать для его выполнения. Не исключено, что OpenAI может стать следующим крупным клиентом Qualcomm в сфере смартфонов, если генеральный директор Сэм Альтман (Sam Altman) реализует план выпустить устройство с ИИ в течение двух лет.
30.04.2026 [15:18], Владимир Мироненко
Lumai анонсировала «оптические» ИИ-серверы Iris с фотонными ускорителями инференсаБританский ИИ-стартап Lumai анонсировал семейство серверов для инференса Lumai Iris с использованием оптических вычислений, предназначенное для исполнения в реальном времени больших языковых моделей (LLM) с миллиардами параметров. Семейство Lumai Iris включает серверы Nova, Aura и Tetra. Lumai Iris Nova уже доступен для оценки гиперскейлерами, неооблачными платформами, предприятиями и исследовательскими институтами. Lumai заявил, что использование Lumai Iris позволяет ускорить выполнение задач инференса, используя свет вместо кремниевой обработки. Оптическая вычислительная система Lumai обеспечивает более быстрый инференс, более высокую эффективность выполнения и до 90 % меньшее энергопотребление по сравнению с традиционными архитектурами, при этом являясь более экологичными по сравнению с традиционными системами на базе GPU. Впрочем, технические детали оптических ИИ-ускорителей пока не раскрыты. 
Источник изображений: Lumai Компания отметила, что спрос на вычисления для ИИ смещается от обучения моделей к крупномасштабному инференсу, когда модели используются в реальных приложениях. По мере роста объёмов вычислительных задач ЦОД сталкиваются с жёсткими ограничениями по энергопотреблению и масштабируемости, с которыми традиционные кремниевые архитектуры с трудом справляются. Компания заявила, что семейство Iris призвано решить проблемы с энергопотреблением и стоимостью ИИ-инфраструктуры за счёт повышения производительности на киловатт. Традиционные кремниевые архитектуры сталкиваются с фундаментальными физическими ограничениями в масштабируемости, энергопотреблении и тепловой эффективности. Каждое новое поколение кремниевых чипов предлагает небольшие улучшения, но при этом требует значительно больше энергии и средств для масштабирования. «По мере перехода отрасли в эру инференса мы одновременно пересекаем порог посткремниевой эры, — сказал Сяньсинь Го (Xianxin Guo), генеральный директор и соучредитель Lumai. — Переходя от электронно-фотонной вычислительной парадигмы к фотонной, Lumai может обеспечить увеличение производительности на порядок при значительной экономии энергии».  Lumai отметила, что оптические вычисления позволяют значительно повысить эффективность выполнения обработки ИИ-нагрузок. Технология оптических вычислений Lumai, разработанная на основе исследований в Оксфордском университете, использует свет в трёхмерном среде, тогда как обычные чипы «живут» в 2D. Благодаря использованию массового пространственного параллелизма, миллионы операций выполняются одновременно, обеспечивая низкую стоимость и высокую пропускную способность токенов при выполнении ресурсоёмких вычислительных задач. Технология Lumai также показала свою эффективность на этапе предварительного заполнения дезагрегированных архитектур инференса, обрабатывая токены с максимальной эффективностью и масштабированием. Iris Nova выполняет инференс в реальном времени моделей Llama 8B и 70B с помощью гибридного процессора. Его гибридная архитектура сочетает цифровую обработку для управления системой и ПО с оптическим тензорным движком для основных математических операций. Такой подход обеспечивает бесшовную интеграцию серверов в ЦОД.
29.04.2026 [01:23], Владимир Мироненко
Tenstorrent представила ИИ-серверы Galaxy Blackhole для быстрой генерации токенов и без дезагрегацииTenstorrent представила вычислительную систему Galaxy Blackhole на базе ускорителей Blackhole с архитектурой RISC-V, которая позиционируется как системная ИИ-платформа, способная конкурировать с другими решениями за счёт стабильной производительности инференса, высокоскоростного доступа к памяти и масштабируемой сети — трёх факторов, которые всё чаще определяют эффективность развёртывания ИИ в реальных условиях, пишет Forbes. 6U-сервер Tensorrent Galaxy Blackhole с воздушным охлаждением основан на 32 ИИ-ускорителях Blackhole суммарной производительностью 23 Пфлопс в режиме FP8. Система включает 6,2 Гбайт SRAM (суммарно 2,9 Пбайт/с) и 1 Тбайт GDDR6 (суммарно 16 Тбайт/с). Высокоскоростную связь между узлами при горизонтальном масштабировании обеспечивают 800GbE-порты — до 56 портов на систему с общей пропускной способностью 11,2 Тбайт/с (в дуплексе). Стоимость системы Tensorrent Galaxy Blackhole составляет $110 тыс. Восьмичиповые системы NVIDIA DGX будут производительнее, но и обойдутся в три-пять раз дороже, сообщил The Register. Базовый суперкластер Galaxy Supercluster стоимостью в $440 тыс. включает четыре системы Blackhole. При этом архитектура Tenstorrent поддерживает масштабирование до 32 узлов с 1024 ускорителями. Mesh-сеть Tenstorrent не ограничивается одним узлом. Подобно кластерам TPU от Google или Trainium2 от Amazon, её можно расширить для поддержки более крупных моделей, более высокой пропускной способности или большей интерактивности, добавив больше узлов и отрегулировав параллелизм тензоров и конвейеров. 
Источник изображений: Tenstorrent Как сообщает Tenstorrent, для DeepSeek V3 её четырёхузловые суперкластеры Blackhole Galaxy Supercluster могут обрабатывать запрос на 100 тыс. токенов — эквивалент 166 страниц текста — менее чем за четыре секунды. Tenstorrent заявила, что кластеры Galaxy Blackhole могут генерировать видео быстрее, чем в реальном времени, а также очень быстро генерировать токены LLM. Демонстрационные версии систем Tenstorrent настроены на обычный режим с генерацией текста с удобочитаемой скоростью, и режим Blitz, обеспечивающий максимально быструю обработку данных, подходящую для таких приложений, как генерация кода и агентный ИИ. В режиме Blitz MoE-модель DeepSeek-671B обеспечивает «до 350 т/с на пользователя со временем получения первого токена менее 4 с», сообщила компания. Ресурс EE Times протестировал этот режим за несколько дней до официального запуска, получив 255 т/с на пользователя для коротких запросов в стиле чат-бота. Этот режим поддерживает пакетную обработку от 8 до 64 и длину контекста до 128 тыс токенов. Он работает на 16 серверах Galaxy (512 чипов) с использованием конвейерного параллелизма на этапе декодирования.  Компания отметила, что её системы не нуждаются в дезагрегации. «Мы можем выполнять и [предварительное заполнение, и декодирование] на одном узле, — сообщил генеральный директор Tenstorrent Джим Келлер (Jim Keller) изданию EE Times. — Мы создаём большой кластер, на котором можно запускать предварительное заполнение и декодирование LLM, генерацию видео, агентный ИИ… мы не специализируемся на чём-то одном. У нас много чипов, большой объём SRAM, но все чипы имеют DRAM, и все они тесно связаны между собой, поэтому наша платформа гораздо более универсальна».
23.04.2026 [01:20], Владимир Мироненко
Для обучения и инференса — Google анонсировала ИИ-ускорители TPU 8t и TPU 8iGoogle представила два TPU восьмого поколения: TPU 8t (Sunfish) для обучения ИИ и TPU 8i (Zebrafish) для ИИ-инференса. Компания и раньше экспериментировала с различными вариантами TPU, в частности, со своими чипами пятого поколения V5p и V5e, но последние поколения, такие как Trillium и Ironwood, в основном следовали единому подходу. По словам Амина Вахдата (Amin Vahdat), старшего вице-президента и главного технолога Google по ИИ и инфраструктуре, TPU 8t и TPU 8i — результат десятилетней разработки (первые TPU были анонсированы в мае 2016 г.), специально созданные для обеспечения работы суперкомпьютеров следующего поколения с высокой эффективностью и масштабируемостью. Вахдат описывает TPU 8t как «мощную платформу для обучения», созданную для «сокращения цикла разработки моделей с месяцев до недель». Она предлагает в 2,8 раза лучшее соотношение цены и производительности, чем предыдущее поколение. 
Источник изображений: Google В TPU 8t используются векторные, матричные и SparseCore-ядра, дополненные 128 Мбайт SRAM и 216 Гбайт HBM3e (6,5 Тбайт/с). FP4-производительность составляет до 12,6 Пфлопс (также поддерживаются BF16/FP8/INT8). Для вертикального масштабирования используется межчиповый интерконнект (ICI) со скоростью 19,2 Тбит/с (в каждую сторону), для горизонтального — 400 Гбит/с. Кластер с TPU 8t может масштабироваться до 9,6 тыс. чипов, предлагая 2 Пбайт памяти HBM, 121 Эфлопс и вдвое большую межчиповую пропускную способность по сравнению с Ironwood, позволяя самым сложным моделям использовать единый, огромный пул памяти. 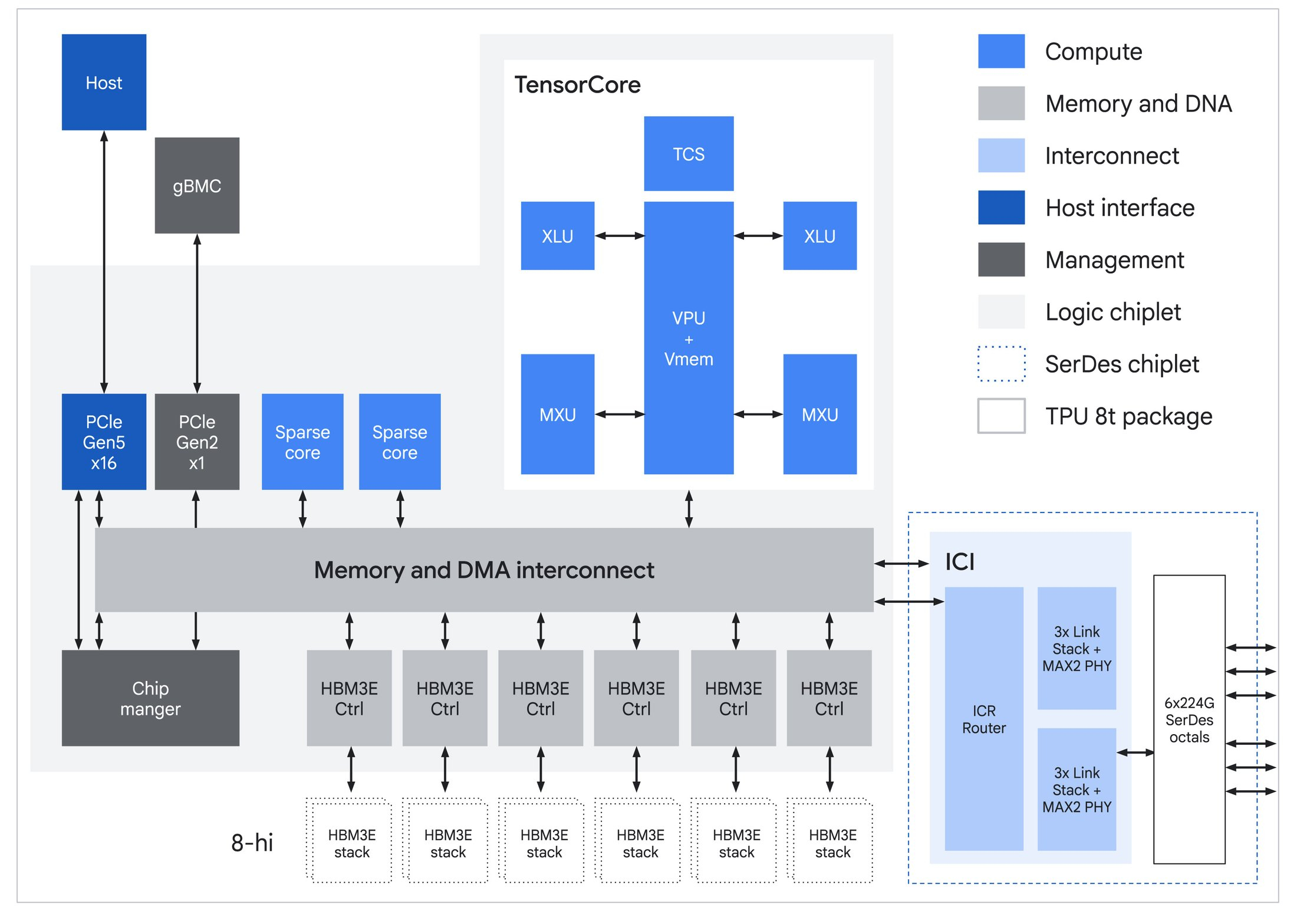 8t-кластеры объдиняет сеть Virgo Network, которая использует плоскую двухуровневую неблокирующую топологию, обеспечивает четырёхкратное увеличение пропускной способности в ЦОД и построена на коммутаторах с высокой степенью защиты, что сокращает количество сетевых уровней. В рамках одного ЦОД Virgo Network позволяет объединить до 134 тыс. чипов, что даёт до 47 Пбит/с неблокирующих соединений и более 1,6 Ифлопс с почти линейным масштабированием. А в рамках нескольких ЦОД в единый кластер можно объединить более 1 млн TPU. 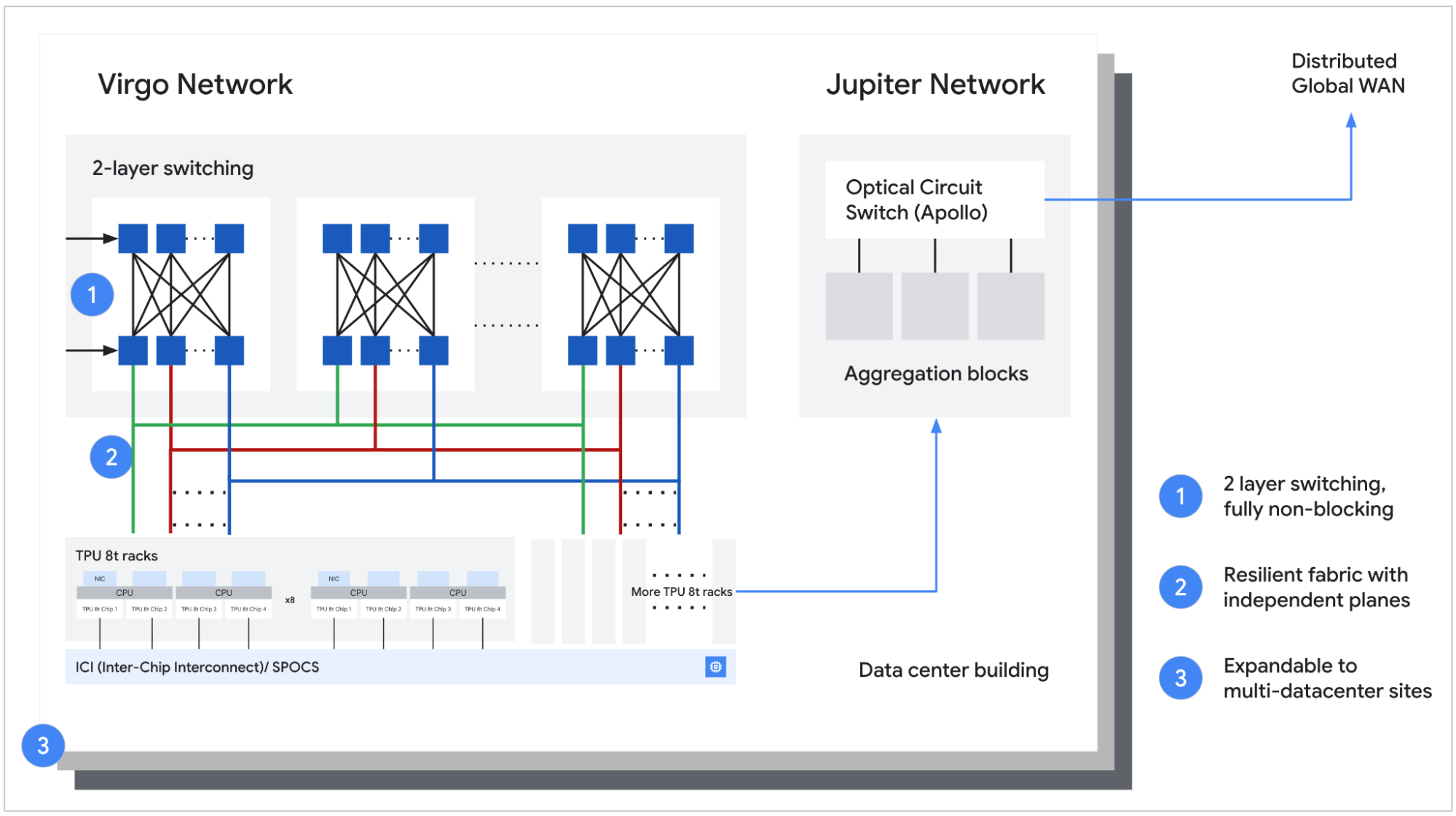 В TPU 8t используются технологии TPUDirect RDMA и TPUDirect Storage. TPU Direct RDMA обеспечивает прямую передачу данных между HBM и NIC, минуя CPU и DRAM хоста, а TPUDirect Storage напрямую связывает память TPU и СХД, таким как 10T Lustre, которая обеспечивает до 10 Тбайт/с, что даёт на порядок более быстрый доступ к хранилищу в сравнении с Ironwood и позволяет доставлять петабайты данных к ускорителям. 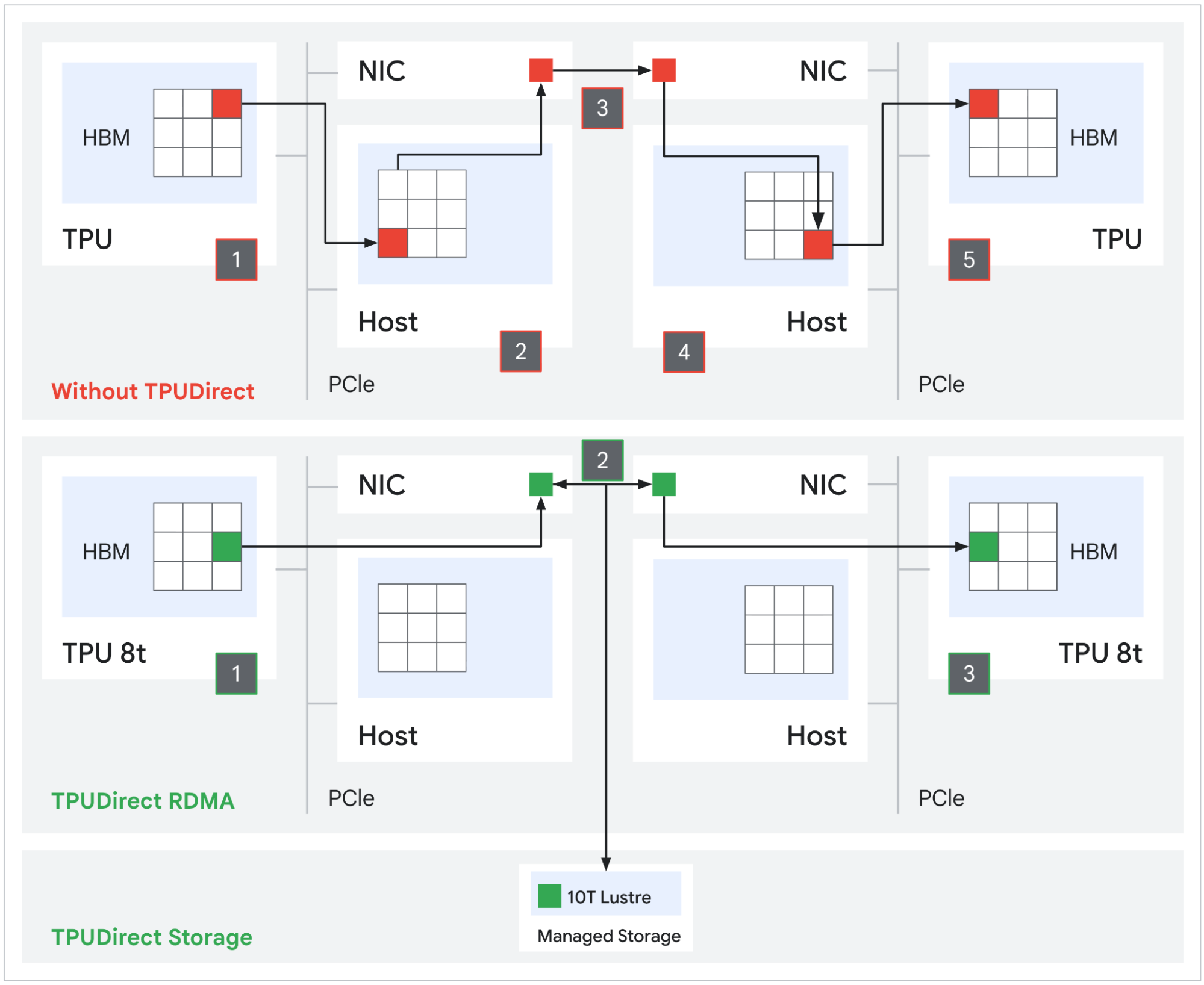 Кроме того, TPU 8t получили расширенные возможности RAS. К ним относятся телеметрия в реальном времени для десятков тысяч чипов, автоматическое обнаружение неисправных каналов ICI и перенаправление трафика без прерывания задания, а также оптическая коммутация каналов (OCS), которая перенастраивает оборудование в случае сбоев без участия человека. Всё это позволяет довести уровень утилизации чипа до 97 %.  В свою очередь, TPU 8i создан для обработки «сложной, совместной, итеративной работы множества специализированных агентов», которые появляются с развитием агентного ИИ. TPU 8i использует 288 Гбайт памяти HBM (8,6 Тбайт/с) в паре с 384 Мбайт SRAM — втрое больше, чем в предыдущем поколении. По словам Google, такой объём SRAM помогает TPU 8i удерживать большую часть KV-кеша на кристалле, что значительно сокращает время простоя ядер во время декодирования длинных контекстов. Компания отказалась от SparseCores в пользу нового встроенного механизма ускорения коллективных операций (CAE), снижая задержки на уровне кристалла и разгружая коллективные коммуникации, которые в противном случае привели бы к простою тензорных ядер чипа, отметил The Register. 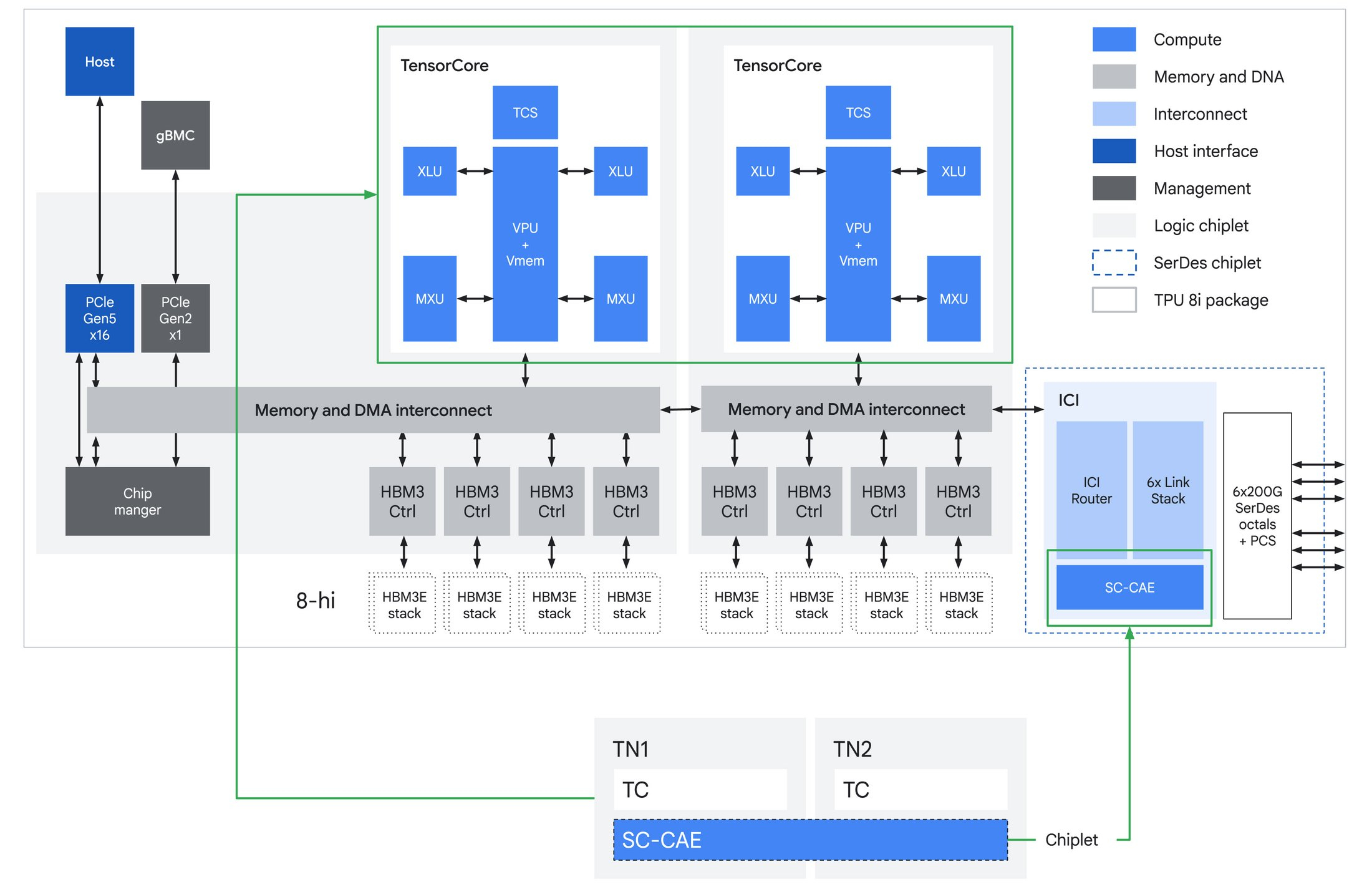 TPU 8i масштабируется до 1152 чипов в одном кластере (впрочем, в каждый момент активно не более 1024): 11,6 Эфлопс и 331,8 Тбайт HBM. ICI у 8i такой же, что у 8t, однако для объединения чипов используется топология Boardfly вместо 3D-тора, поскольку для MoE-инференса важно меньшее количество сетевых переходов между чипами. Эти инновации обеспечивают на 80 % лучшую производительность на доллар по сравнению с предыдущим поколением, позволяя предприятиям обслуживать почти вдвое больше клиентов при тех же затратах, сообщила компания. 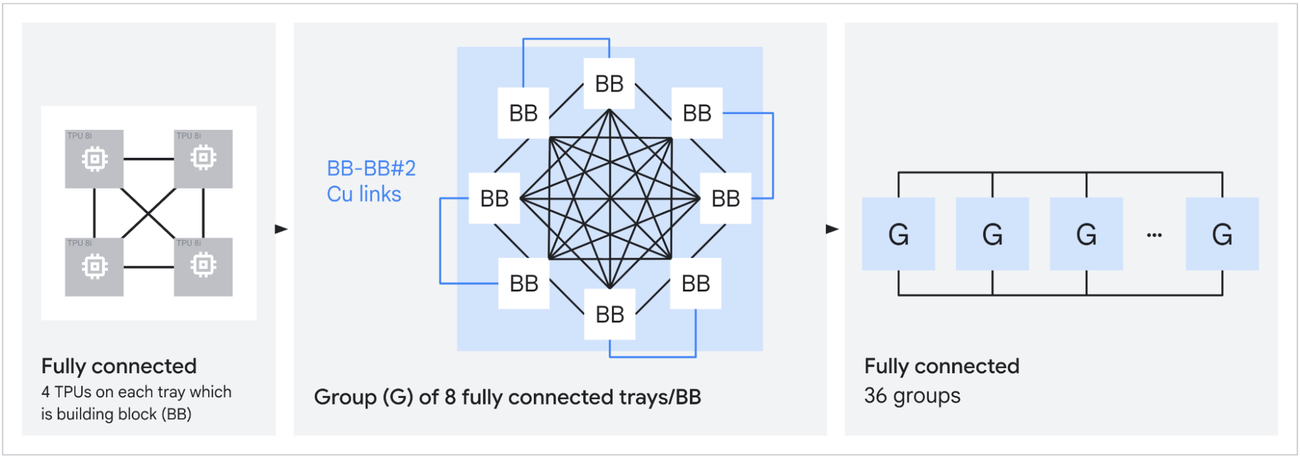 Как TPU 8t, так и 8i работают на базе собственного Arm-процессора Axion и поддерживают СЖО. Компания также заявила, что оптимизировала эффективность всей системы для обеспечения интегрированного управления питанием, которое может регулировать потребление энергии в зависимости от спроса в реальном времени, что приводит к повышению производительности на ватт до двух раз по сравнению с Ironwood. 
Фото: Sundar Pichai TPU 8 станут общедоступными на Google Cloud Platform позже в этом году в виде отдельных инстансов или как часть полнофункциональной платформы AI Hypercomputer, которая объединяет все сетевые ресурсы, хранилище, вычислительные мощности и ПО, необходимые для развёртывания или обучения LLM в масштабе. Также ожидается, что вскоре Google представит TPU v8e (Humufish). 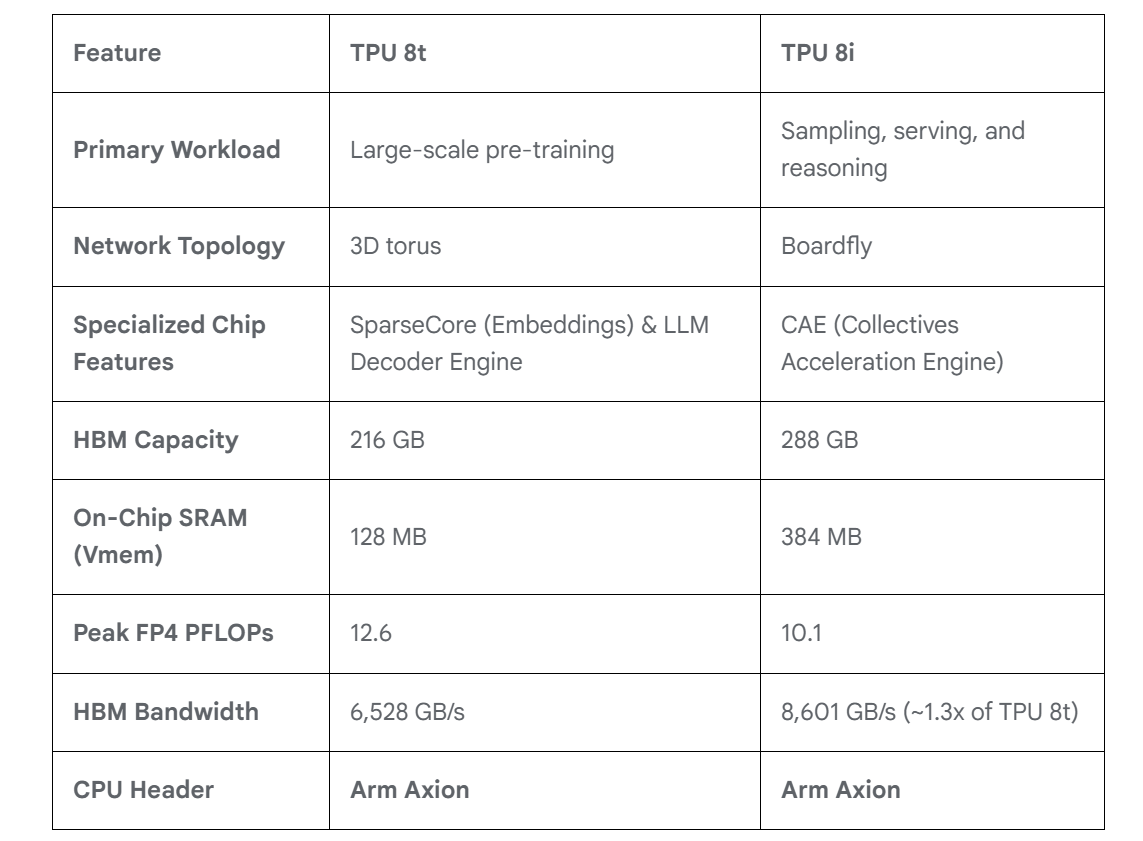
21.04.2026 [21:56], Андрей Крупин
«Турбо облако» представило платформу для быстрого запуска ИИ-моделей с поминутной тарификацией и автоматическим масштабированиемОблачный провайдер «Турбо облако» (входит в коммерческий IT-кластер «Ростелекома»), запустил Inference Platform — платформу для развёртывания и эксплуатации моделей искусственного интеллекта, в основу которой положены ускорители NVIDIA H200 SXM с интерконнектом InfiniBand. Inference Platform поддерживает различные типы ИИ-моделей, включая open source-решения. Пользователи могут загружать собственные модели или использовать контейнерные образы, разворачивая их в облачной среде без дополнительных инфраструктурных настроек. Сервис обеспечивает автоматическое масштабирование ресурсов (автоскейлинг) в зависимости от нагрузки. Такой подход позволяет оптимизировать использование GPU и снизить затраты при нерегулярной нагрузке, говорит компания. Платформа поддерживает распределённый инференс, позволяя запускать модели объёмом до 1 тплн параметров с размещением на нескольких вычислительных узлах. Также доступно гибкое использование GPU-ресурсов, включая их дробление под задачи меньшего объёма. Дополнительным преимуществом является поминутная тарификация ресурсов, гарантирующая более точный контроль расходов по сравнению с почасовой оплатой. 
Источник изображения: Omar Lopez-Rincon / unsplash.com В настоящее время новый продукт доступен для тестирования: компании могут оценить его возможности на собственных моделях.
19.04.2026 [21:20], Владимир Мироненко
Google договаривается с Marvell о разработке двух кастомных чипов для ИИ-инференсаКомпания Google (Alphabet) ведёт переговоры с Marvell Technology о совместной разработке двух кастомных чипов, предназначенных для более эффективного ИИ-инференса, сообщил ресурс The Information со ссылкой на информированные источники. Как отметил The Information, эти переговоры свидетельствуют о стремлении Google, исторически зависящей от Broadcom в отношении базовой инфраструктуры TPU, к диверсификации поставщиков. Этот потенциальный альянс в области разработки чипов является прямым ответом на меняющуюся экономику ИИ, когда огромные вычислительные затраты на обучение масштабных моделей быстро уступают место постоянным ежедневным расходам на инференс. Один из чипов относится к подсистеме памяти TPU, второй — собственно TPU следующего поколения, созданный специально для запуска ИИ-моделей. Эти чипы предназначены для совместной работы, при этом каждый из них выполняет свою часть задачи. Как подчёркивается в публикации, «текущие обсуждения направлены на разработку полупроводников исключительно для нужд Google». 
Источник изображения: Marvell Technology Помимо технической оптимизации ИИ-инференса, привлечение Marvell — это классическая тактика диверсификации поставщиков, пишет Startup Fortune. Broadcom долгое время занимала исключительно доминирующее положение на рынке заказных чипов, тесно сотрудничая с Google в разработке TPU. Но сильная зависимость от одного партнёра по проектированию неизбежно создаёт ценовые разногласия и узкие места. Добавление ещё одного партнёра даёт Google более сильные рычаги влияния во время переговоров по контрактам, а также защищает её ЦОД от геополитических и логистических сбоев. Следует отметить, что авторитет Marvell заметно вырос за последнее время. Компания недавно заключила многомиллиардное партнёрство с NVIDIA, ориентированное на оптические сети и кастомные чипы. Её акции выросли более чем на 50 % с начала года, в основном благодаря доверию инвесторов к её опыту в области инфраструктуры данных и проектирования заказных чипов. Вместе с тем Broadcom остается ключевым партнёром в реализации планов Google. В этом месяце компании подписали соглашение о продолжении работы над новыми чипами до 2031 года, сообщается в документе, направленном Broadcom регулятору. Если переговоры пройдут успешно, Marvell укрепит свой статус ведущей альтернативы Broadcom в сегменте разработки кастомных ИИ-микросхем. Также следует ждать, что капитальные затраты гиперскейлеров будут всё больше смещаться в сторону оптимизации инференса, а не просто увеличения вычислительной мощности. Аналитики отрасли в настоящее время прогнозируют, что поставки серверных ASIC для ИИ-вычислений утроятся к 2027 году, и эта тенденция почти полностью обусловлена потребностями в развёртывании больших языковых моделей.
17.04.2026 [22:53], Владимир Мироненко
ИИ-стартап Cerebras поставит OpenAI ускорители ещё на $20 млрдКомпания OpenAI заключила соглашение с ИИ-стартапом Cerebras, согласно которому она выплатит более $20 млрд в течение следующих трёх лет за поставку ИИ-ускорителей, сообщило издание The Information. В рамках сделки OpenAI получит варранты на миноритарную долю в Cerebras, при этом её доля может увеличиться по мере роста расходов, утверждают источники The Information. По их данным, OpenAI также согласилась предоставить Cerebras около $1 млрд для финансирования развёртывания ЦОД на базе её ИИ-ускорителей. До этого, в январе Cerebras договорилась с OpenAI о поставке в течение трёх лет своих ускорителей общей мощностью 750 МВт. Стоимость этой сделки оценивается в $10 млрд. Новое соглашение подчеркивает растущий интерес отрасли к вычислительным мощностям для инференса, отметило агентство Reuters. По его данным, Cerebras может раскрыть некоторые подробности своего соглашения с OpenAI, когда предоставит регулятору документы для проведения первичного публичного размещения (IPO). 
Источник изображения: Cerebras Исходя из общей суммы контрактов The Information допускает, что OpenAI может получить варранты, представляющие до 10 % доли в Cerebras. Сотрудничество с OpenAI является ключевым элементом в планах Cerebras по выходу на биржу, планирующего провести листинг во II квартале этого года. Cerebras, чья рыночная стоимость, по последним оценкам, составляет $23,1 млрд, планирует привлечь $3 млрд в ходе первичного публичного размещения акций в следующем месяце при оценке примерно в $35 млрд, сообщил The Information. Выход на биржу неоднократно откладывался. Сначала компанию подозревали в опосредованных связях с Китаем и зависимости от ближневосточных нефтедолларов, а потом компания дважды получила крупные инвестиции и нарастила капитализацию. Сделки с AWS и OpenAI укрепили её позиции и успокоили инвесторов. В пятницу Cerebras объявила о подаче заявки на первичное публичное размещение акций (IPO) в США. Компания планирует разместить свои акции на Nasdaq под тикером CBRS. Ведущими андеррайтерами размещения являются Morgan Stanley, Citigroup, Barclays и UBS. Ранее на этой неделе Morgan Stanley открыл Cerebras возобновляемую кредитную линию с доступом до $250 млн, с возможностью увеличения лимита до $850 млн после IPO, сообщил CNBC. Согласно документам, поданным в пятницу, среди инвесторов Cerebras — Alpha Wave, Benchmark, Eclipse, Fidelity и Foundation Capital. На сайте Cerebras также указан генеральный директор OpenAI Сэм Альтман (Sam Altman) в качестве инвестора. Cerebras указала в заявке, что не владеет ЦОД, которые использует для предоставления облачных услуг, но может построить собственные в будущем. В документе также сообщается, что чистая прибыль Cerebras за 2025 год составила $87,9 млн при выручке в $510 млн (рост год к году на 76 %). Компания получила прибыль в размере $1,38 на акцию, по сравнению с убытком в $9,90 на акцию годом ранее. По состоянию на 31 декабря 2025 года у Cerebras оставалось $24,6 млрд невыполненных обязательств, и ожидается, что 15 % этой суммы будет учтено в 2026 и 2027 годах.
14.04.2026 [23:00], Владимир Мироненко
Sophia Space обкатает софт на ИИ-спутниках Kepler перед запуском собственных космических ЦОДКанадская компания Kepler Communications, развернувшая в январе вычислительный комплекс из около 40 модулей NVIDIA Jetson Orin для периферийных систем на борту 10 действующих спутников, связанных между собой лазерными каналами связи, объявила о новом партнёре — Sophia Space. Сообщается, что этот стартап будет тестировать ПО для своего уникального орбитального компьютера с помощью спутниковой группировки Kepler. Kepler не планирует заниматься космическими ЦОД, но готова предлагать инфраструктуру для космических приложений, сообщила генеральный директор Мина Митри (Mina Mitry) изданию TechCrunch. По её словам, компания хочет стать промежуточным звеном, предоставляющим сетевые сервисы для других спутников в космосе, а также для летательных аппаратов, в том числе беспилотных, в воздушном пространстве Земли. В свою очередь, Sophia разрабатывает модульные космические компьютеры TILE Edge с пассивным охлаждением, которые позволят решить одну из ключевых проблем крупных ЦОД на орбите: предотвращение перегрева мощных процессоров без необходимости создания и запуска тяжёлых и дорогостоящих систем активного охлаждения. В рамках партнёрства Sophia развернёт свою собственную ОС на спутниках Kepler, объединив шесть GPU на двух космических аппаратах. Проверка работоспособности ПО на орбите станет ключевым этапом снижения рисков для Sophia перед первым запланированным запуском спутника в конце 2027 года. 
Источник изображения: Kepler Communications Для Kepler, уже имеющей 18 клиентов, это партнёрство станет дополнительным доказательством полезности её сети. В настоящее время она передаёт и обрабатывает данные, загружаемые с Земли или собираемые размещённым на собственных космических аппаратах оборудованием. Но по мере развития сектора компания рассчитывает начать подключение спутников других компаний для предоставления сетевых и вычислительных услуг. Именно в обработке данных там, где их собирают, для более быстрого реагирования, в частности, в военной области, орбитальные ЦОД докажут свою ценность. Эта концепция отличает Sophia и Kepler от таких аэрокосмических компаний, как SpaceX и Blue Origin, или стартапов, таких как Starcloud и Aetherflux, которые привлекают значительный капитал для создания крупномасштабных орбитальных ЦОД с «земными» чипами. «Поскольку мы считаем, что это скорее инференс, чем обучение, нам нужно больше распределённых GPU, — сказала Митри в интервью TechCrunch. — Если чип потребляет киловатты энергии, но работает только 10 % всего времени, то это не продуктивно. В нашем случае наши GPU используются без простоев». Глава Sophia Роб ДеМилло (Rob DeMillo) отметил, что с учётом того, что некоторые регионы в США уже ограничивают строительство ЦОД, развёртывание их на орбите становится всё более привлекательной альтернативой.
10.04.2026 [23:09], Владимир Мироненко
Intel поставит Google несколько поколений Xeon и IPUIntel и Google объявили об углублении многолетнего партнёрства в области инфраструктуры ИИ и облачных вычислений, охватывающего как развёртывание процессоров, так и совместную разработку специализированных чипов инфраструктуры (IPU). За два дня до этого компания стала партнёром по производству микрочипов для мегапроекта Tesla Terafab. В итоге акции Intel за неделю выросли на треть. Intel и Google отметили, что по мере ускорения внедрения ИИ-инфраструктура становится всё более сложной и гетерогенной, что приводит к увеличению зависимости от CPU для оркестрации, обработки данных и повышения производительности на системном уровне. В рамках сотрудничества с Intel компания Google планирует использовать несколько поколений процессоров Intel Xeon для улучшения производительности, энергоэффективности и TCO в своих инстансах. Intel уже делает кастомные Xeon для AWS. Стороны подчеркнули, что одних только ускорителей недостаточно для удовлетворения потребностей современной ИИ-инфраструктуры. «ИИ меняет подход к построению и масштабированию инфраструктуры. Масштабирование ИИ требует большего, чем просто ускорители — оно требует сбалансированных систем. CPU и IPU играют центральную роль в обеспечении производительности, эффективности и гибкости, необходимых для современных рабочих нагрузок ИИ», — сообщил генеральный директор Intel Лип-Бу Тан (Lip-Bu Tan). Как отметил ресурс The Next Web, Intel потратила последние два года на переориентацию с рынка универсальных вычислений, где она когда-то доминировала, на процессоры и специализированные инфраструктурные чипы, которые играют структурную роль в развёртывании ИИ и которые постоянно недооценивали в рамках концепций, ориентированных на GPU. Одновременно компания развивает бизнес по производству кастомных чипов для ИИ-рынка. 
Источник изображения: Intel Амин Вахдат (Amin Vahdat), старший вице-президент и главный технолог Google по инфраструктуре ИИ отметил: «Процессоры и инфраструктурное ускорение остаются краеугольным камнем систем ИИ — от организации обучения до инференса и развёртывания. Intel является надёжным партнёром уже почти два десятилетия, и её план развития Xeon даёт нам уверенность в том, что мы сможем и дальше удовлетворять растущие требования к производительности и эффективности наших рабочих нагрузок». Что важно, партнёрство охватывает несколько поколений Intel Xeon, а не текущий цикл обновления оборудования Google. Партнёрство также включает расширенную совместную разработку IPU (DPU) — специализированных программируемых ускорителей на базе ASIC, предназначенных для разгрузки сетевых функций, функций хранения, функций безопасности и т.п., которые на масштабах гиперскейлера позволяют существенно сэкономить и упростить управление инфраструктурой. Ранее компании совместно разработали свой первый IPU Mount Evans. Момент для анонса партнёрства выбран подходящий. Рабочие нагрузки ИИ смещаются от обучения на ускорителях, что позволить себе могут немногие, к масштабируемому инференсу, который является распределённым, чувствительным к задержкам, непрерывным и требовательным к ресурсам CPU для оркестрации, работы с данными и управления системой в целом. По-видимому, собственные процессоры Google Axion пока не слишком годятся на эту роль. Впрочем, для внешних заказчиков компания точно так же предлагает инстансы с чипами NVIDIA, хотя её собственные TPU пользуются огромным спросом. Впрочем, расширение сотрудничество можно объяснить и более прозаично — дефицит серверных процессоров на рынке усиливается, так что заранее договориться о поставках с крупным игроком, да ещё имеющим собственное производство на территории США, всегда выгодно. |
|

