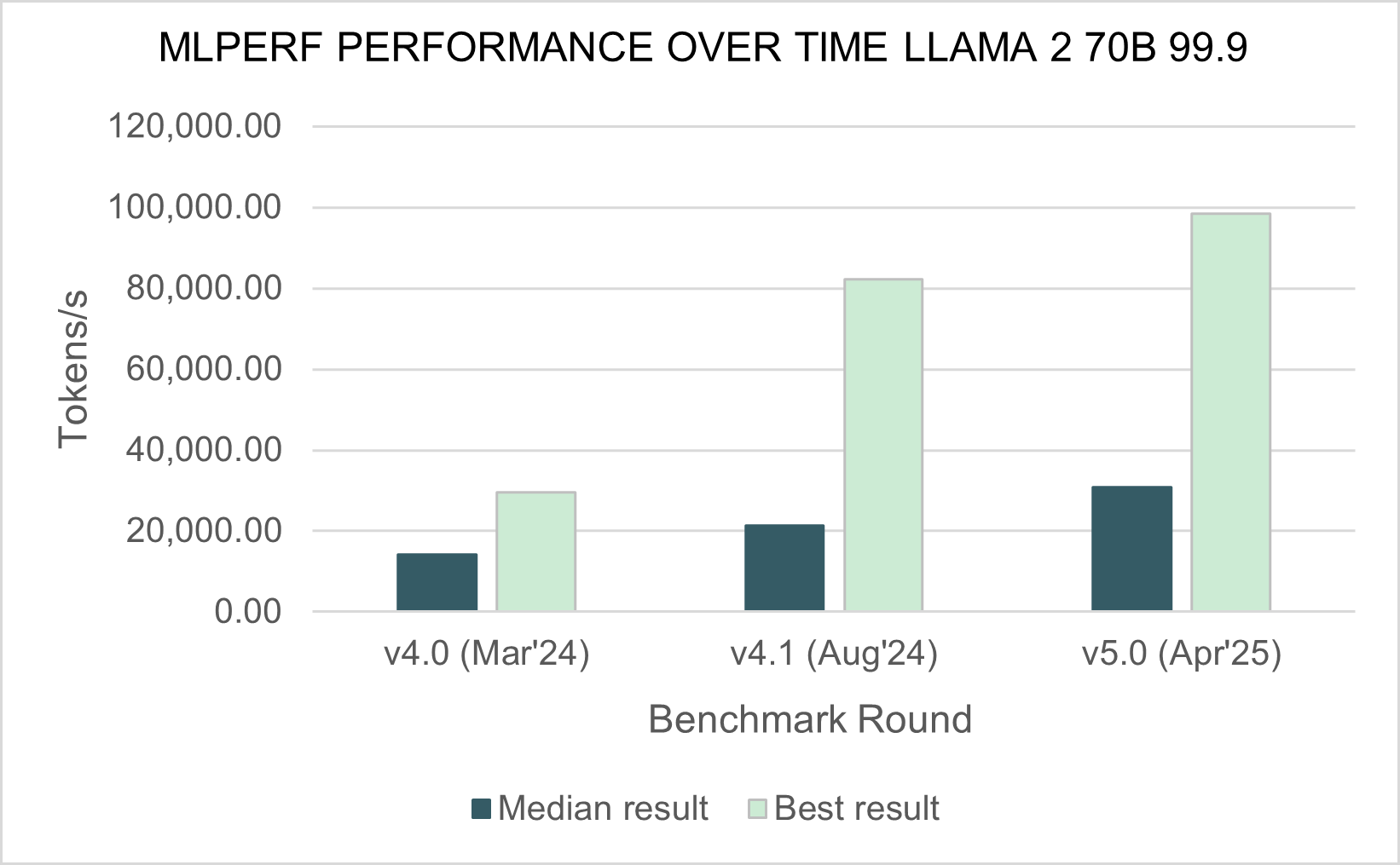
Консорциум MLCommons опубликовал результаты тестирования различных аппаратных решений в бенчмарке MLPerf Inference 5.0, о чём сообщил ресурс IEEE Spectrum. Он отметил, что ускорители NVIDIA с архитектурой Blackwell превзошли все остальные чипы, но последняя версия ускорителей Instinct от AMD — Instinct MI325X — оказалась на уровне конкурирующего решения NVIDIA H200. Сопоставимые результаты были получены в основном в тестах одной из маломасштабных больших языковых моделей (LLM) — Llama2 70B. Чтобы лучше отражать особенности развития ИИ, консорциум добавил три новых теста MLPerf — всего доступно 11 бенчмарков.
Добавлены два теста для LLM. Популярная и относительно компактная Llama2 70B уже является устоявшимся эталоном MLPerf, но консорциум решил включить тест, имитирующий скорость реагирования, ожидаемую пользователями от чат-ботов. Поэтому был добавлен новый эталон Llama2-70B Interactive, который ужесточает требования к оборудованию: системы должны выдавать не менее 25 токенов в секунду при задержке на ответ не более 450 мс.
С учётом роста популярности «агентного ИИ» в MLPerf решили добавить тестирование LLM с характеристиками, необходимыми для таких задач. В итоге была выбрана Llama3.1 405B. Эта модель имеет широкое контекстное окно — 128 тыс. токенов, что в 30 раз больше, чем у Llama2 70B. Третий новый бенчмарк — RGAT — представляет собой графовую сеть. Он классифицирует информацию в сети. Например, набор данных для тестирования RGAT состоит из научных статей, связанных между собой авторами, учреждениями и областями исследований, что составляет 2 Тбайт данных. RGAT должен классифицировать статьи по почти 3000 темам.
Источник изображения: IEEE Spectrum
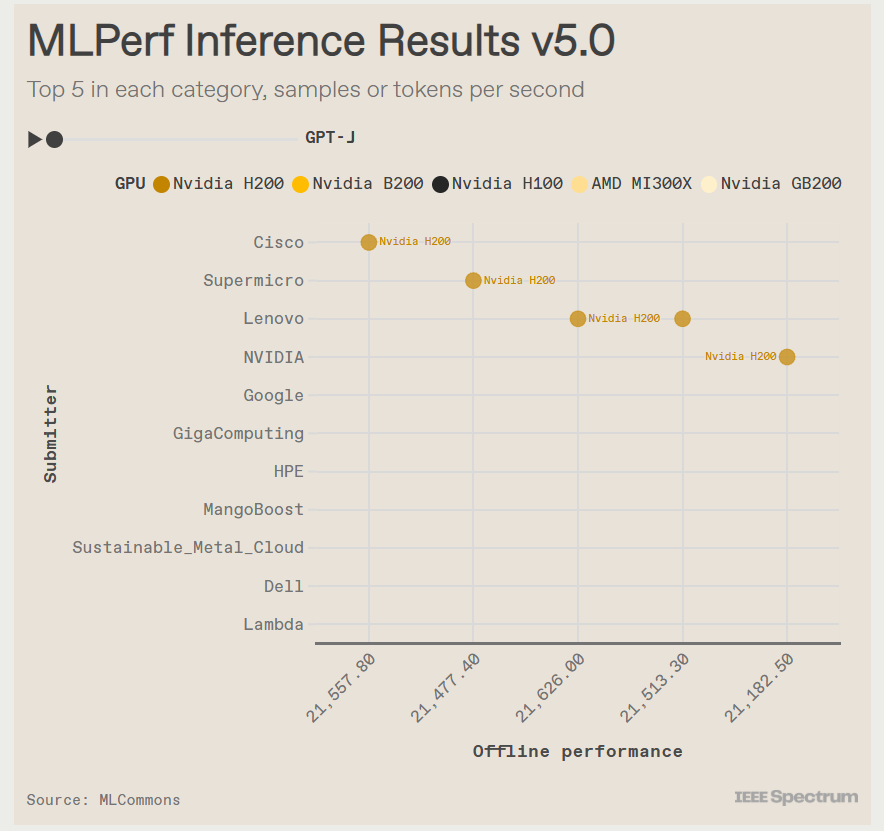
В этом раунде тестов поступили заявки от NVIDIA и 15 компаний-партнёров, включая Dell, Google и Supermicro. Оба ускорителя NVIDIA с архитектурой Hopper первого и второго поколения — H100 и H200 — показали хорошие результаты. «Мы смогли добавить ещё 60 % производительности за последний год, — у Hopper, которая была запущена в производство в 2022 году, сообщил Дэйв Сальватор (Dave Salvator), один из директоров NVIDIA. — У неё всё ещё есть некоторый запас производительности». Лидером же оказался B200 с архитектурой Blackwell. B200 содержит на 36 % больше памяти HBM, чем у H200, но, что ещё важнее, он может выполнять ключевые математические операции, используя FP4 вместо FP8 у Hopper.
В тесте Llama3.1 405B система от Supermicro с восемью B200 выдала почти в четыре раза больше токенов в секунду, чем система с восемью H200 от Cisco. И та же система Supermicro была в три раза быстрее самого быстрого сервера на H200 в интерактивной версии Llama2 70B.
NVIDIA использовала суперчип GB200 — сочетание ускорителей Blackwell и процессоров Grace — чтобы продемонстрировать эффективность интерконнекта NVLink, который позволяет работать множеству узлов как один ускоритель. В непроверенном результате, которым компания поделилась с журналистами, стойка GB200 NVL72 выдавала 869 200 токенов в секунду в Llama2 70B. Самая быстрая система текущего раунда MLPerf Inference — сервер NVIDIA B200 — показала 98 443 токена в секунду.
Ускоритель Instinct MI325X позиционируется AMD как конкурент H200. Он имеет ту же архитектуру, что и предшественник MI300, но оснащён увеличенным объёмом памяти HBM с более высокой пропускной способностью — 256 Гбайт и 6 Тбайт/с (рост на 33 % и 13 % соответственно). AMD оптимизировала ПО, что позволило увеличить скорость инференса DeepSeek-R1 в 8 раз. В тесте Llama2 70B компьютеры с восемью MI325X отставали от аналогичных систем на базе H200 всего на 3–7 %. В задачах генерации изображений система MI325X показала отличия в пределах 10 % от системы на H200. Также сообщается, что партнёр AMD, компания Mangoboost, продемонстрировала почти четырёхкратное увеличение производительности в тесте Llama2 70B, запустив вычисления на четырёх узлах.
Источник изображения: ML Commons
Intel традиционно использует в тестах только процессорные системы, чтобы показать, что для некоторых рабочих нагрузок GPU не требуются. В этот раз были представлены первые данные по чипам Intel Xeon 6900P и 6700P (Granite Rapids), выпускаемым по техпроцессу Intel 3. Компьютер с двумя Xeon 6 показал результат в 40 285 семплов в секунду в тесте распознавания изображений, что составляет около одной трети производительности системы Cisco с двумя NVIDIA H100. По сравнению с результатами Xeon 5 в октябре 2024 года новый процессор демонстрирует прирост в 80 % в данном тесте и ещё большее ускорение в задачах обнаружения объектов и медицинской визуализации. С 2021 года, когда Intel начала представлять результаты Xeon, её процессоры достигли 11-кратного прироста производительности в тесте ResNet. Intel отказалась от участия в категории ускорителей: её конкурент для H100 — Gaudi 3 — не появился ни в текущих результатах MLPerf, ни в версии 4.1, выпущенной в октябре 2024 года.
Чип Google TPU v6e также продемонстрировал свои возможности, хотя результаты были ограничены задачей генерации изображений. При 5,48 запроса в секунду система с четырьмя TPU показала прирост в 2,5 раза по сравнению с аналогичным компьютером, использующим TPU v5e, в результатах за октябрь 2024 года. Тем не менее 5,48 запроса в секунду — это примерно те же показатели, что и у аналогичного по размеру компьютера Lenovo с NVIDIA H100.
Источник:

