Материалы по тегу: ии
|
04.06.2026 [14:22], Руслан Авдеев
Iren построит в Австралии кампус ИИ ЦОД мощностью 800 МВтАмериканская неооблачная компания Iren объявила подписала соглашение, предусматривающее подключение к электросети в Банди (Bundey, шт. Южная Австралия) в 2028 году дата-центра мощностью 800 МВт, сообщает Datacenter Dynamics. Это первый проект Iren в Австралии. По словам компании, Южная Австралия имеет необходимые ресурсы для ИИ-инфраструктуры — избыток «чистой» энергии, возможность подключения к сетям связи для обслуживания Азиатско-Тихоокеанского региона, а также лояльность местных властей, понимающих перспективы открывающихся перед штатом возможностей. Кампус в местности Банди поможет обеспечить запросы на ИИ-вычисления со стороны региональных и зарубежных клиентов. Растущие потребности в ИИ имеются и в самой Южной Австралии. Ранее в этом году Iren заявила, что возможности для ведения бизнеса в Австралии столь же значительны, как и в любом другом направлении из портфолио компании. По данным Iren, кампус расположится в 125 км от Аделаиды. 
Источник изображения: Liam Pozz/unsplash.com По словам властей штата, инвестиции Iren позволят создать сотни рабочих мест в строительстве, обеспечить занятость квалифицированных кадров на постоянной основе и усилят позиции Южной Австралии в качестве технологического и инновационного хаба в Азиатско-Тихоокеанском регионе. У компании имеются действующие и строящиеся площадки ЦОД в Техасе, Оклахоме и Британской Колумбии в Канаде. По данным компании, совокупная мощность её проектов достигла 5 ГВт. В распоряжении Iren — более 23 тыс. ИИ-ускорителей Ранее известная как Iris Energy, компания постепенно переориентируется с криптомайнинга на облачные ИИ-вычисления. Хотя майнинг биткоинов пока продолжается, соответствующие операции постепенно сворачиваются, а финансовые потоки перенаправляются на развитие ИИ-бизнеса. Недавно она приобрела испанского оператора ЦОД Nostrum, обеспечив себе выход в Европу. Это обеспечивает компании порядка 490 МВт подключённых к сети мощностей в Испании. Ключевым клиентом Iren является Microsoft, а NVIDIA намерена инвестировать в её неооблачный бизнес до $2,1 млрд для внедрения до 5 ГВт мощностей. Также в июне Iren получила крупную кредитную линию на $3,65 млрд с инвестиционным кредитным рейтингом для покупки ИИ-ускорителей с целью поддержки облачного ИИ-контракта с Microsoft. Инвестиционный рейтинг обычно означает, что бизнес может получить средства на более выгодных по сравнению с обычными участниками рынка условиях.
04.06.2026 [14:17], Руслан Авдеев
BYOC: Google ставит на виртуальные электростанции Voltus для обеспечения роста ЦОДGoogle совместно с крупным оператором виртуальных электростанций — американской энергетической компанией Voltus подписали «первое крупномасштабное соглашение» по модели «Принеси мощность с собой» (Bring Your Own Capacity, BYOC). Это новый подход к обеспечению электричеством развивающихся дата-центров, сообщает Datacenter Knowledge. В рамках соглашения сроком на три года Voltus обеспечит клиенту до 100 МВт мощностей за счёт объединения ресурсов аккумуляторных систем, умных термостатов и прочих распределённых энергетических ресурсов (DER) в регионе, подконтрольном крупнейшему оператору энергосистем США PJM Interconnection. Ранее компании уже договорились о внедрении системы Tapestry для интеллектуального управления энергосетью. Конечно, даже единственный кампус гиперскейлер-уровня может потреблять до нескольких сотен мегаватт, но в данном случае примечателен сам механизм закупки — именно мощности, а не электроэнергии. Речь идёт о первом коммерческом внедрении модели BYOC, продвигаемой Voltus с 2025 года для того, чтобы операторы ЦОД могли решить свои растущие проблемы с присоединением к электросетям. BYOC позволяет не строить новые генерирующие мощности, а использовать потенциал уже имеющихся аккумуляторных энергохранилищ, а также других источников энергии, подключённых к энергосетям. 
Источник изображения: Mina Rad/unsplash.com Спрос на электричество со стороны ИИ ЦОД резко вырос, а вот на строительство новых электростанций, линий электропередачи и модернизацию инфраструктуры требуются годы на согласования и реализацию. Тем временем имеющиеся распределённые ресурсы позволяют пользоваться энергией эффективнее, утверждает Voltus. Voltus предоставляет готовый сертифицированный «пакет» мощности для крупных покупателей. Для Google соглашение станет альтернативой традиционной модели закупки электричества у энергокомпаний. В основном гиперскейлеры предпочитают заключать соглашения о покупке энергии (PPA), строить собственные источники энергии при ЦОД и напрямую инвестировать в генерирующие объекты. Вместо этого новое соглашение ориентировано на мощность — этот «продукт» призван обеспечить доступность ресурсов в периоды пиковых нагрузок на энергосистему. Деньги Google поступят многочисленным «провайдерам» распределённых энергоактивов, а Voltus будет управлять этим пакетом и выплачивать компенсацию за использование ресурсов его участникам. В Google сделку рассматривают как часть стратегии по диверсификации инструментов для развития инфраструктуры. Компания пока не привязывает соглашение к конкретному кампусу или проекту, но утверждает, что оно призвано усилить сети, обслуживающие её ЦОД, и упростить ввод новых объектов в эксплуатацию. Google стала первым гиперскейлером, приступившим к испытаниям закупки распределённых мощностей в дополнение к PPA, собственной генерации и другим источникам энергии для ЦОД. Эксперты уже сравнили схему с той ролью, которую сыграли техногиганты при масштабировании закупок возобновляемой энергии десять лет назад. По их словам, Google обеспечивает долгосрочный спрос на мощности, что позволяет увереннее финансировать активы вроде аккумуляторных энергохранилищ (BESS), подобно тому, как десятилетие назад компания стала одним из пионеров «виртуальных» закупок электроэнергии у ветряных и солнечных электростанций. 
Источник изображения: Arno Senoner/unsplash.com Цены на мощность значительно выросли на фоне ожиданий роста нагрузки на электросети и опасений, что ресурсов не хватит. Как и другие активы под управлением PJM, распределённые источники должны гарантировать заявленную мощность; предусмотрены стимулы за выполнение обязательств и штрафы за их нарушение. Не менее важным, чем «размер» виртуальной электростанции, может оказаться её состав. Эксперты утверждают, что модель способны поддержать аккумуляторные хранилища и распределённые источники экологически чистой энергии. Дополнительно в США имеются резервные генераторы общей мощностью 37 ГВт, способные участвовать в подобных программах. Правда, некоторые специалисты считают, что генераторы негативно повлияют на качество воздуха, а противодействие жителей будет весьма серьёзным. Также имеет значение, кто в конечном счёте будет платить за присоединение небольших источников энергии и модернизацию сети для поддержки распределённых энергетических ресурсов — Google или все потребители электроэнергии. Эксперты полагают, что регуляторы должны различать операторов ЦОД, помогающих энергосистеме дополнительными ресурсами, и тех, кто только требует подключения. Гиперскейлер, финансирующий и предоставляющий для сетей сертифицированные мощности, является скорее активом системы, чем дополнительной нагрузкой на неё. Предполагается, что энергокомпании и регуляторы должны учитывать такой вклад, а не относиться к активным участникам энергетического обмена как к тем, кто просто запрашивает «подключение на 500 МВт». Ещё в январе сообщалось, что США переживают крупнейший за четверть века период роста энергопотребления, обусловленный развитием ЦОД. Новая администрация США отдаёт приоритет газовой и угольной генерации перед возобновляемой энергетикой, обосновывая это необходимостью удовлетворить стремительно растущий спрос на ИИ. Теоретически возможности интеграции аккумуляторов ЦОД в энергосети обсуждается давно.
04.06.2026 [12:56], Владимир Мироненко
Акции HPE взлетели более чем на 25 % после отчёта об ажиотажном спросе на серверы и сетиАкции HPE выросли в цене более чем на 25 % после публикации финансовых результатов за II квартал 2026 финансового года, закончившийся 30 апреля 2026 года, поскольку благодаря росту продаж ИИ-серверов компания превысила ожидания Уолл-стрит по прибыли и выручке, сообщил ресурс SiliconANGLE. Скорректированная прибыль HPE на разводнённую акцию (Non-GAAP) составила 79¢, значительно превысив консенсус-прогноз аналитиков в 53¢ на акцию. Выручка за этот период составила $10,68 млрд, что на 40 % больше год к году и значительно превышает прогноз аналитиков в $9,79 млрд. Этот квартал стал самым успешным по показателю прибыли на акцию с февраля 2018 года. Чистая прибыль (GAAP) компании составила $595 млн или $0,44 на разводнённую акцию, тогда как год назад у неё были убытки в размере $1,079 млрд или $0,82 на разводнённую акцию. 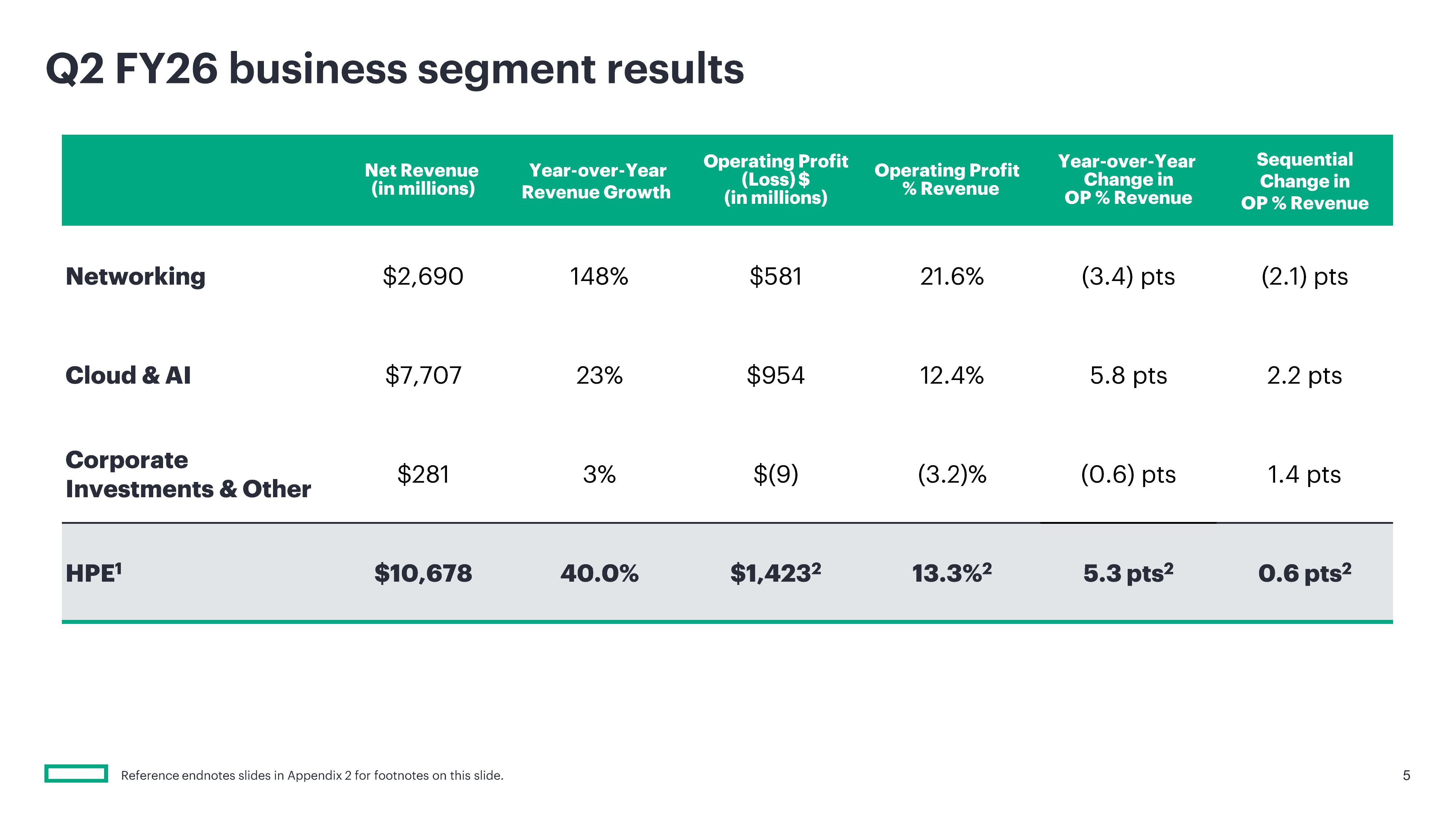
Источник изображений: HPE Главной причиной успешности квартала стал ИИ. Выручка сегмента HPE «Облачные технологии и ИИ» составила $7,7 млрд, что на 22,9 % больше год к году и выше прогноза аналитиков в размере $6,87 млрд. При этом выручка от продажи серверов составила $5,45 млрд (рост год к году на 32,7 %), превысив прогнозируемые аналитиками $4,66 млрд. Более того, несмотря на то что рентабельность продаж ИИ-серверов, как известно, невелика, HPE удалось выйти на чистую прибыль, тогда как годом ранее у неё были убытки. Антонио Нери (Antonio Neri), президент и генеральный директор HPE назвал рост выручки этого сегмента «исключительным» и заявил аналитикам на телефонной конференции, что агентный ИИ стал «ключевым фактором ускорения спроса», пишет CNBC. Нери заявил, что объёмы заказов на традиционные серверы выросли на трёхзначное число процентов по сравнению с прошлым годом, достигнув самой большой величины в истории компании. Он пояснил, что у клиентов в отраслях, ориентированных на безопасность, значительно выросла потребность в локальных серверах и ИИ-инфраструктуре, в отличие от облачных ИИ-ресурсов. Это вполне устраивает HPE, поскольку она в первую очередь ориентируется на предприятия и государственные учреждения, а не на гиперскейлеров, которые предпочитают закупать небрендированные серверы и оборудование оптом. 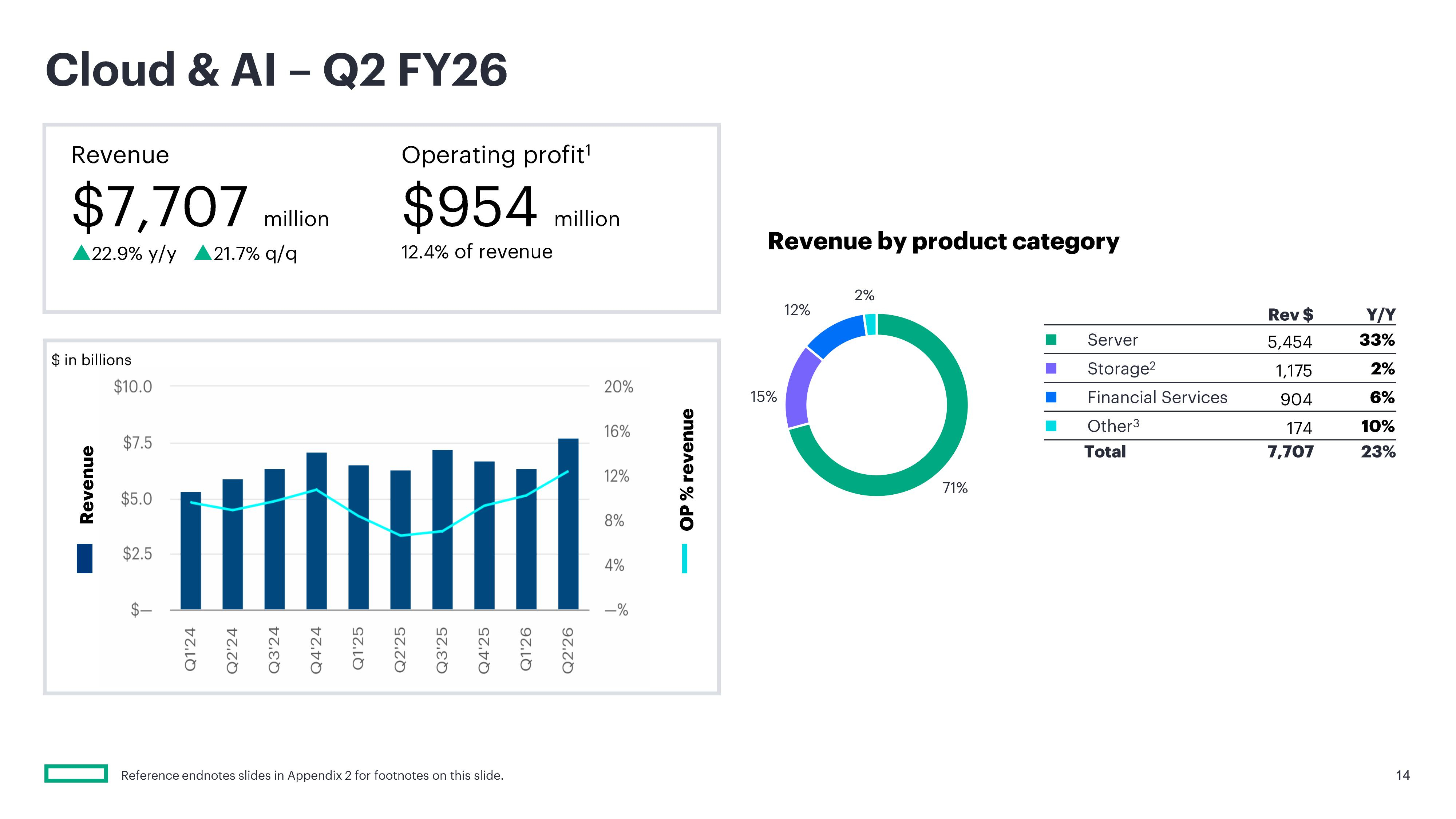 Аналитик Патрик Мурхед (Patrick Moorhead) из Moor Insights & Strategy заявил, что HPE сосредоточена на более высокодоходных возможностях, которые предоставляют эти клиенты, в отличие от своего главного конкурента Dell, который нацелен на неооблака, такие как CoreWeave. «Её рост обусловлен повышением прибыльности ИИ и тем фактом, что она достигает своих целей на полтора года раньше», — сказал он. Как отметило агентство Reuters, успешный квартал позволил компании приблизиться к достижению долгосрочных финансовых целей на два года раньше запланированного срока. Финансовый директор Мари Майерс (Marie Myers) также подчеркнула резкий рост числа клиентов, запрашивающих серверные мощности для ИИ-приложений, отметив, что эти рабочие нагрузки предъявляют гораздо более высокие вычислительные требования к инфраструктуре, чем традиционные задачи. 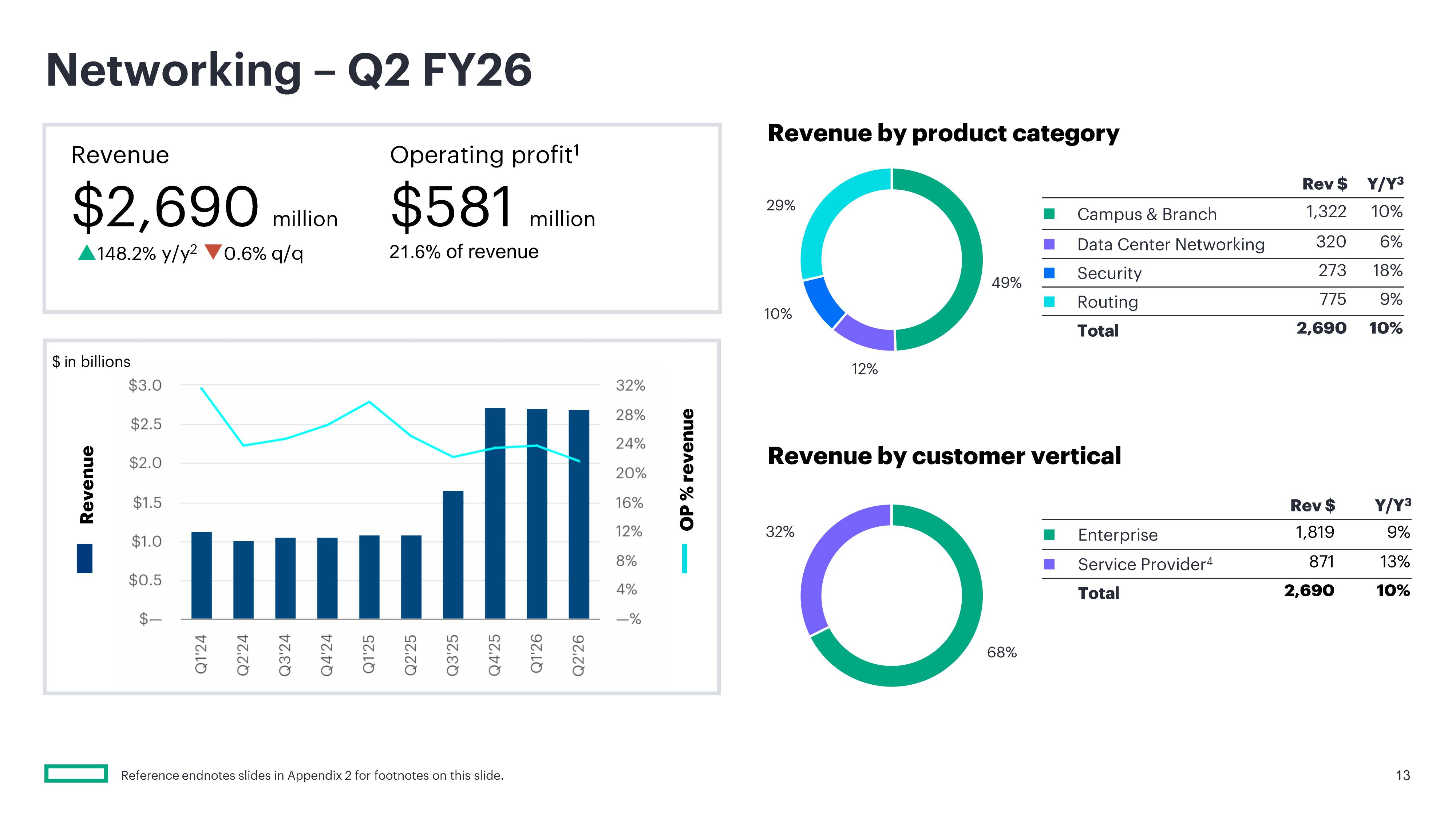 Выручка сегмента «Сетевое оборудование», который включает бизнес Juniper Networks, составила $2,7 млрд, что на 148,2 % больше, чем за аналогичный период прошлого года. В том числе выручка от кампусных и филиальных сетей (Campus & Branch) выросла на 50,2 % до $1,3 млрд. Продажи сетевого оборудования для ЦОД принесли $320 млн (рост на 288,3 %), продукты безопасности — $273 млн выручки, что на 151,2 % больше год к году, а направление маршрутизации — $775 млн по сравнению с $1 млн годом ранее. Продажи СХД выросли на 2,4 % до $1,2 млрд, выручка от финансовых услуг выросла на 5,6 % до $0,9 млрд. Выручка от корпоративных инвестиций и прочих услуг выросла на 3,3 % до $281 млн. 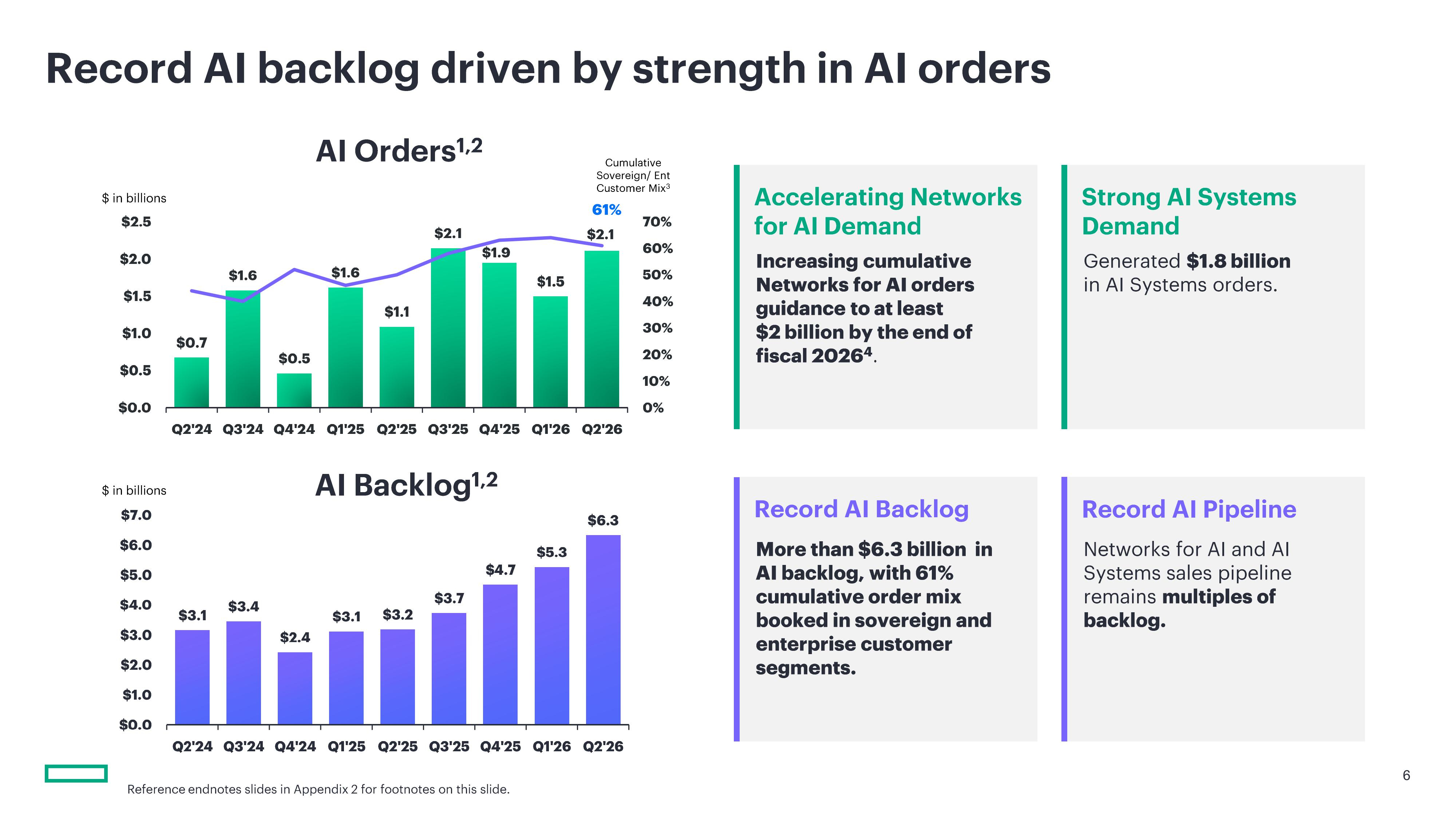 На III финансовый квартал HPE прогнозирует выручку в размере от $11,5 до $12,1 млрд и скорректированную прибыль на акцию в размере от $0,88 до $0,93. Аналитики Уолл-стрит прогнозируют прибыль всего в $0,66 на акцию при выручке в $10,9 млрд. Компания также повысила свой прогноз роста выручки на 2026 финансовый год до 29–33 %, в том числе в сегменте сетевого оборудования до 72–75 %. По скорректированной прибыли на акцию прогноз на год увеличен на $1 до диапазона от $3,35 до $3,45, по сравнению с предыдущей оценкой в $2,30–$2,50 на акцию. В то же время аналитики Уолл-стрит ожидают прибыль за весь финансовый год всего в $2,43 на акцию.
04.06.2026 [12:44], Руслан Авдеев
AirTrunk инвестирует $21 млрд в строительство в Индии 3-ГВт ЦОДАвстралийская AirTrunk объявила о намерении инвестировать $21,05 млрд в новый ЦОД в индийском штате Махараштра, расположенном в центральной части страны. Дата-центр разместят в бизнес-парке Raigad Penn Growth Centre рядом с Мумбаи (Mumbai), а мощность объекта должна составить 3 ГВт, сообщает Reuters. Поддерживаемая американским инвестиционным гигантом Blackstone, компания AirTrunk управляет дата-центрами в Азии, в том числе в Гонконге, Японии, Малайзии и Сингапуре. Индия в последнее время переживает настоящий инвестиционный бум — только в этом году компании из США намерены вложить в страну более $630 млрд. Основными драйверами роста инвестиций стали налоговые льготы для размещения дата-центров гиперскейлеров и других технологических компаний на территории страны. Финансовые вложения в ИИ ЦОД наращивают и крупнейшие индийские конгломераты: Reliance и Adani в феврале обязались вложить $110 млрд и $100 млрд соответственно. Растущий фокус на цифровой инфраструктуре критически важен для поддержки роста экономики Индии. 
Источник изображения: Tojo Basu/unsplash.com Гигантские проекты ЦОД для Индии — не редкость. Например, в декабре 2025 года сообщалось, что Microsoft инвестирует в Индию $17,5 млрд для масштабирования ИИ-инфраструктуры. В феврале 2026 года OpenAI и Tata договорились о строительстве 1 ГВт ИИ ЦОД в Индии, а в конце апреля появилась новость, что Reliance потратит $17 млрд на крупнейший в Индии кластер ЦОД мощностью 1,5 ГВт.
03.06.2026 [15:14], Руслан Авдеев
ЦОД проекта Microsoft Fairwater заработал в Висконсине, и он уже готов принять NVIDIA Vera RubinКомпания Microsoft запустила новую ИИ-фабрику проекта Fairwater в Висконсине. Ввод в эксплуатацию состоялся раньше запланированного срока, на объекте заработали сотни тысяч ИИ-систем NVIDIA Grace Blackwell, в частности NVIDIA GB200. Объект подключён к аналогичной ИИ-фабрике в Джорджии. В результате сформирована масштабируемая распределённая вычислительная система для самых требовательных передовых ИИ-моделей. Благодаря совместной работе над системами электроснабжения, охлаждения и сетевой инфраструктурой NVIDIA Spectrum-X Ethernet, а также новому сетевому протоколу Multipath Reliable Connection (MRC) с распределением пакетов данных по множественным маршрутам, архитектура Fairwater позволяет оптимизировать «экономику токенов» — стоимость обработки и генерации данных искусственным интеллектом. Дополнительно Microsoft завершила проверку платформы NVIDIA Vera Rubin. Облачный гигант подтвердил готовность платформы к развёртыванию в дата-центрах Microsoft Azure. NVIDIA Vera Rubin может использоваться наряду с системами Blackwell без необходимости модернизации инфраструктуры. Она обеспечивает производительность при инференсе до 10 раз выше на каждый затраченный мегаватт потребляемой мощности по сравнению с платформой-предшественницей. Интегрированная технология NVIDIA Confidential Computing защищает модели и данные в процессе работы ИИ-агентов. 
Источник изображения: NVIDIA Платформа NVIDIA Dynamo представляет собой программное решение для высокопроизводительного инференса, ускоряющее запуск и эксплуатацию ИИ-моделей. Кроме того, она ускоряет запуск моделей в среде AKS (Azure Kubernetes Service). Технология NVIDIA Grove отвечает за распределённую оркестрацию инференса в инфраструктуре Kubernetes. Речь идёт о запуске новой ИИ-фабрики Fairwater в США. Не так давно в эксплуатацию ввели объект в Атланте, хотя строительство в Висконсине началось довольно давно. В конце апреля глава Microsoft Сатья Наделла (Satya Nadella) заявил, что кампус строится ударными темпами и будет введён в эксплуатацию раньше намеченного срока.
03.06.2026 [15:09], Руслан Авдеев
Ayar Labs присоединилась к экосистеме NVIDIA NVLink Fusion с собственной CPO-технологиейAyar Labs присоединилась к экосистеме NVIDIA NVLink Fusion. Технология Co-Packaged Optics (CPO), предлагаемая компанией, позиционируется как решение для подключения будущих стоечных ИИ-систем на основе масштабируемой гетерогенной вычислительной архитектуры NVIDIA, сообщает Converge! Digest. Новый шаг объединяет технологию оптических интерконнектов Ayar Labs с оптическими и SerDes-технологиями NVIDIA. Это позволит крупным компаниям и разработчикам ИИ-систем интегрировать оптические соединения в ИИ-инфраструктуру на базе NVLink Fusion. ИИ-кластерам нового поколения необходимо обеспечить эффективную передачу огромных объёмов информации по мере увеличения гетерогенности систем и количества используемых ускорителей. Обычные интерконнекты практически достигли предела в контексте плотности пропускной способности, дальности действия, задержек и энергопотребления. Ayar Labs пытается преодолеть эти ограничения, интегрируя оптические модули с вычислительными. Это позволит нарастить как пропускную способность, так и дальность действия, одновременно снизив потребление электроэнергии. 
Источник изображения: Ayar Labs В рамках партнёрства с NVIDIA компания Ayar Labs намерена сотрудничать с клиентами и партнёрами по экосистеме, чтобы поддержать развёртывание своих CPO-решений в архитектурах на основе NVLink Fusion. Такая платформа позволяет интегрировать специализированные процессоры и ИИ-ускорители в стоечные системы NVIDIA, сохраняя совместимость с более широкой экосистемой NVLink. Благодаря оптической связи архитекторы систем получат ещё один вариант для проектирования крупных ИИ-фабрик. Объявление последовало за раундом финансирования серии E, в котором Ayar Labs, с 2015 года занимающаяся оптическими IO-технологиями для ИИ и HPC, привлекла $500 млн. В раунде приняла участие и компания NVIDIA. По словам Converge!, речь идёт о новой вехе для рынка CPO-технологий, поскольку этот шаг Ayar Labs приближает массовое внедрение таких решений в ИИ-инфраструктуру. Технология CPO годами рассматривалась как преемник подключаемых оптических модулей с высоким энергопотреблением и медных интерконнектов, и именно сегодня кластеры ИИ-ускорителей достигли такой производительности, что CPO становится всё более привлекательным вариантом для ИИ-систем. Решение NVIDIA включить Ayar Labs в экосистему NVLink Fusion свидетельствует о признании в отрасли ИИ того факта, что будущие системы могут потребовать использования оптики не только между стойками, но и внутри них. NVIDIA NVLink Fusion позволяет создавать кастомные ИИ-платформы со сторонними чипами и другими компонентами. Ранее NVIDIA заключила соглашения в отношении NVLink с Arm, AWS, Fujitsu, Intel, Marvell, MediaTek и SiFive.
03.06.2026 [13:49], Владимир Мироненко
Новые Arm-инстансы Azure Cobalt 200 оптимизированы для ИИ-агентов и в полтора раза быстрее ВМ Azure Cobalt 100Microsoft объявила о доступности предварительной версии Arm-инстансов Azure Cobalt 200, разработанных с нуля для масштабируемых, облачно-ориентированных и основанных на Linux ИИ-нагрузок с использованием агентов и обеспечивающих до 50 % более высокую производительность по сравнению с Cobalt 100. Компания сообщила, Cobalt 200 объединил её новейшие разработки — от «кремния» до серверов и сервисов — в области безопасности, сетей, хранения данных и разгрузки, что позволяет превосходить традиционные вычислительные решения на базе Arm. Совместная оптимизация аппаратного и программного обеспечения позволяет расширять возможности масштабирования, повышать безопасность и снижать затраты при использовании ИИ-инференса, конвейеров передачи данных, а также веб-сервисов и API, обеспечивающих работу современных сервисов. Microsoft отметила, что агенты отличаются от традиционных рабочих нагрузок тем, что они рассуждают, принимают последовательные решения и непрерывно работают в больших масштабах, что требует принципиально иного профиля вычислений. Cobalt 200 создан именно для этой среды и обеспечивает 50-% прирост производительности для таких нагрузок, делая агентов более быстрыми, функциональными и экономически эффективными в масштабах предприятия. 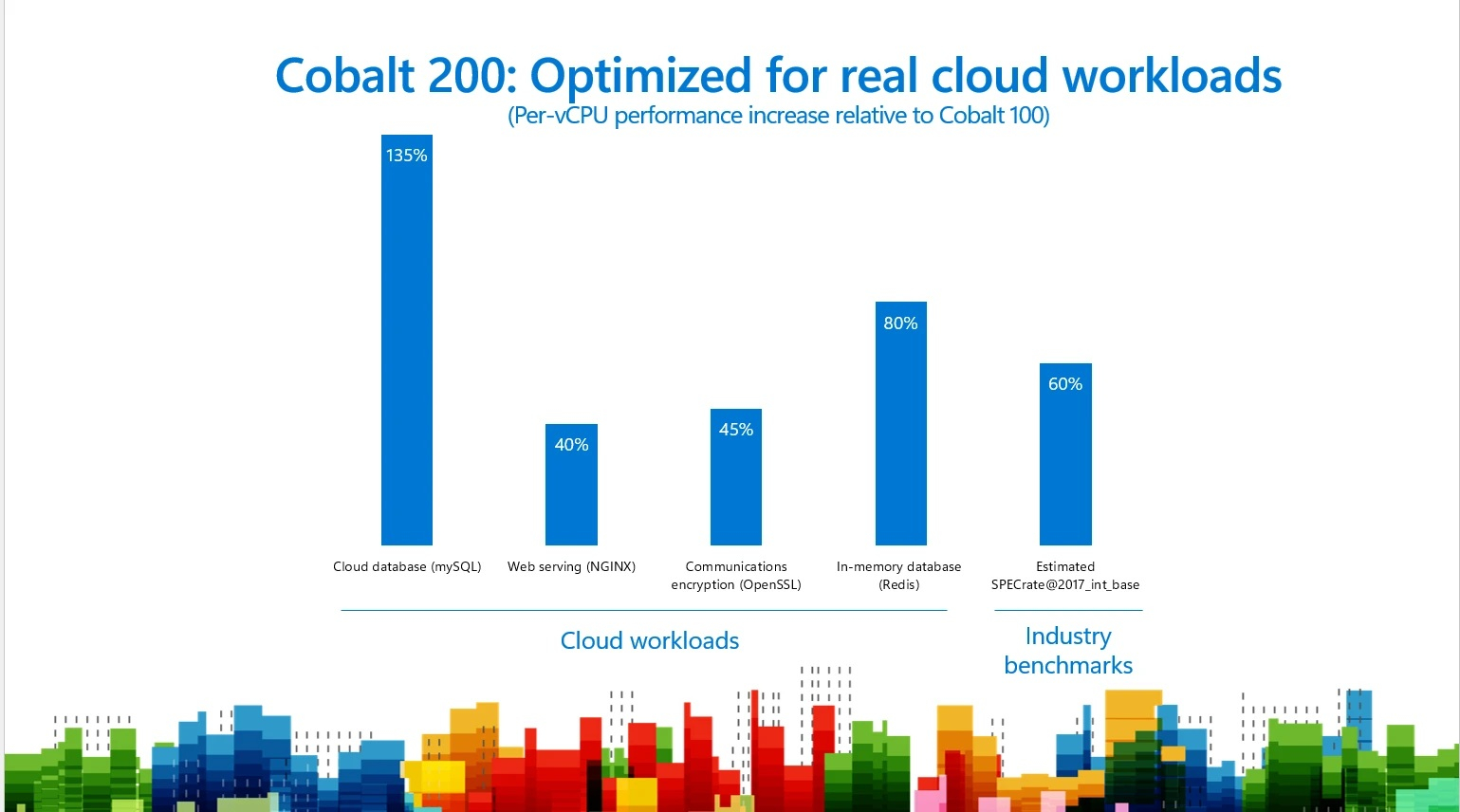
Источник изображений: Microsoft Его предшественник, Cobalt 100, доступен в 32 регионах ЦОД Azure по всему миру. Такие компании, как Databricks и Snowflake, используют Cobalt 100 для оптимизации своей облачной инфраструктуры, а такие клиенты, как Amadeus, OneTrust, Siemens, Sprinklr и Temenos, добились значительного повышения производительности и эффективности, сообщила Microsoft. На собственных облачных сервисах компании ВМ Azure Cobalt 100 обеспечивают повышение производительности до 45 % при использовании на 35 % меньшего количества вычислительных ядер по сравнению с предыдущей вычислительной платформой. Microsoft Defender for Endpoint (MDE) продемонстрировал повышение производительности на 40 % в своём инструменте управления данными. Ключевые преимущества инстансов Cobalt 200:
Компания отметила, что Cobalt 200 обеспечивает производительность на ядро и масштабируемость, необходимые для современных нагрузок агентного ИИ. Каждое ядро Cobalt 200 представляет собой полноценное физическое ядро, дополненное ёмким L2-кешем и повышенной пропускной способностью памяти на ядро. Эти конструктивные особенности обеспечивают более высокую изоляцию и стабильную производительность под нагрузкой, что позволяет агентным рабочим нагрузкам размещать больше песочниц агентов в одной виртуальной машине, одновременно удовлетворяя требованиям к задержке и пропускной способности.
Инстансы Cobalt 200 обеспечивают значительное улучшение по сравнению с Cobalt 100 в наиболее важных для продуктовой среды рабочих нагрузках, в том числе рост производительности до 135 % для облачных баз данных, до 40 % — для веб-серверов, до 45 % — для задач шифрования связи и до 80 % — для нагрузок кеширования. Инстансы Cobalt 200 полностью совместимы с инстансами Cobalt 100, что делает миграцию бесшовной. Основные платформы и языки программирования для разработчиков, включая C++, .NET, Java, Python и Rust, уже предлагают версии, разработанные специально для Arm. В числе собственных сервисов Microsoft, использующих ВМ Cobalt 200 — Dataverse и базы данных Azure. Напомним, что ранее Google объявила, что портировала около 30 тыс. внутренних нагрузок на Arm-архитектуру с использованием собственных Arm-чипов Axion и планирует перенести ещё порядка 70 тыс. В свою очередь, Oracle ещё несколько лет назад завершила миграцию всех своих облачных сервисов на Arm, как и AWS, также получившая заказы на поставку Graviton от Snowflake, Anthropic и Meta✴. Microsoft отметила, что запуск инстансов Cobalt 200 позволил ей расширить портфель Arm-инстансов для поддержки более широкого набора рабочих нагрузок. Если на базе Cobalt 100 предлагаются семейства ВМ общего назначения (Dp, Dpl) и оптимизированные по памяти (Ep), то Cobalt 200 позволил добавить ещё два семейства инстансов: Mpsv4 с увеличенным объёмом памяти и Lpsv5 с плотным локальным хранилищем. Новинки уже доступны в формате предварительных версий. Инстансы будут доступны в следующих регионах: West US3, East US2, Central US, Sweden Central, East US, West US2, Spain Central и Indonesia Central. Об их доступности в других регионах будет объявлено позже.
03.06.2026 [11:10], Руслан Авдеев
Мичиганский Stargate: Oracle и OpenAI начали строительство гигаваттного кампуса ЦОД The BarnВ городе Салин (Saline), штат Мичиган, начато строительство кампуса ЦОД Oracle/OpenAI в рамках проекта Stargate. На днях Related Digital, Blackstone, Oracle, OpenAI, Walbridge и представители местных властей провели церемонию начала работ на объекте The Barn, сообщает Datacenter Dynamics. Проект получил одобрение в октябре 2025 года. Площадка должна обеспечить пользователям 1 ГВт мощности ЦОД и обойдётся примерно в $10 млрд. Строительство всех зданий кампуса стартовало уже довольно давно. По имеющимся данным, первое из трёх зданий общей площадью около 51 100 м2 почти завершено. Фактически, по словам главы OpenAI Сэма Альтмана (Sam Altman), работы начались ещё в конце марта 2026 года, когда на территории были установлены стальные балки. Related Digital присмотрела участок и занималась проектом ещё с августа 2025 года. У OpenAI и Oracle уже есть действующий кампус Stargate в Абилине (Abilene, штат Техас). В марте партнёры объявили, что больше не намерены масштабировать ЦОД на этой площадке. Хотя над кампусом The Barn работают уже довольно давно, реализация проекта застопорилась из-за нехватки финансирования. В апреле удалось привлечь $14 млрд. Из них ценные бумаги на сумму $10 млрд для финансирования проекта приобрела Pimco, а оставшуюся часть обеспечили другие инвесторы. Blackstone выделила ещё $2 млрд. 
Источник изображения: Troy Mortier/unsplash.com Утверждается, что The Barn привлечёт в штат десятки миллиардов долларов инвестиций и позволит создать тысячи рабочих мест не только в строительстве, но и в сфере IT. Власти штата обещают, что любая действующая на его территории компания будет выполнять обязательства по созданию хорошо оплачиваемых вакансий, обеспечивать жителям экономию энергии и просто будет «хорошим соседом», заботящемся о воздухе, земле и воде. Участники проекта должны будут выделить $10 млн на строительство спортивно-развлекательного центра в Салине, ещё $14 млн направят на поддержку пожарных служб и сохранение сельхозугодий, не считая непосредственного создания рабочих мест для членов профсоюза. Это первый проект OpenAI, реализация которого осуществляется в рамках меморандума о взаимопонимании с североамериканским профсоюзом NABTU при содействии компании Walbridge. Последняя строит объекты в Мичигане уже более полувека и тоже участвует в проекте. В начале 2026 года в рамках инициативы Stargate Community компания OpenAI пообещала выделять в регионах присутствия дополнительные средства на то, чтобы её деятельность не повлияла на цены на электроэнергию для обычных потребителей. Например, планировалось строительство генерирующих мощностей для кампусов Stargate, выделение средств на создание новых энергетических объектов для штатов и др.
03.06.2026 [10:59], Сергей Карасёв
Dell представила серверы PowerEdge на базе NVIDIA Vera для агентного ИИКомпания Dell Technologies сообщила об обновлении семейства решений AI Factory with NVIDIA, ориентированных на внедрение ИИ. Дебютировали серверы PowerEdge R9822 и PowerEdge M9822 на аппаратной платформе NVIDIA Vera, предназначенные в том числе для развёртывания ИИ-агентов. Процессоры Vera содержат 88 ядер Olympus (176 потоков инструкций), совместимых с набором инструкций Arm v9.2. Возможно использование до 1,5 Тбайт LPDDR5X с пропускной способностью до 1,2 Тбайт/с. Сервер PowerEdge R9822 выполнен в форм-факторе 3U и оснащён воздушным охлаждением. Система подходит для различных сценариев использования — от агентных приложений и аналитики данных до задач общего назначения, обрабатываемых посредством CPU. Машина может интегрироваться в инфраструктуры существующих дата-центров. В свою очередь, модель PowerEdge M9822 наделена системой прямого жидкостного охлаждения. Этот сервер обеспечивает высокую плотность мощности в средах, оптимизированных для ИИ-агентов и НРС. 
Источник изображения: Dell Прочие характеристики новинок пока не раскрываются. Но отмечается, что платформа Dell AI Factory with NVIDIA поддерживает такие сетевые технологии, как Spectrum-X Ethernet и Quantum-X800 InfiniBand. Могут использоваться программные решения NVIDIA AI Enterprise, мультимодальные языковые модели NVIDIA Nemotron, среда OpenShell и пр. В продажу по всему миру серверы PowerEdge R9822 и PowerEdge M9822 поступят в сентябре текущего года. Нужно отметить, что решения на платформе NVIDIA Vera готовят и другие ведущие поставщики серверного оборудования. В частности, такие системы недавно анонсировала компания HPE.
03.06.2026 [09:00], Сергей Карасёв
Гибкие сетевые настройки и информационная безопасность: обновление Basis SDNКомпания «Базис», лидер российского рынка ПО управления динамической инфраструктурой, представила версию 1.2 продукта Basis SDN, первого самостоятельного российского решения для организации программно-определяемых сетей (SDN). Акцент в новом релизе сделан на информационной безопасности: обновлена логика работы правил обработки трафика, реализовано детальное журналирование на уровне бэкенда, улучшена интеграция со сторонним ПО, работающим с политиками и событиями безопасности. Basis SDN переводит управление сетевой инфраструктурой организации (сегментация, маршрутизация, коммутация и т.д.) с уровня «железа» на программный уровень, упрощая реализацию сложных сценариев работы сети. Новые инструменты для гибкой настройки сетевой инфраструктурыВ релизе Basis SDN 1.2 добавлены шаблоны наиболее популярных сервисов, включая NTP, IMAP, RDP и др., с предустановленными протоколами и портами назначения для быстрой настройки типовых правил безопасности без ручного указания параметров. Их можно объединять в группы с сервисами, созданными пользователем самостоятельно, что в результате заметно упрощает для ИБ-специалистов заказчика создание и изменение этих правил. 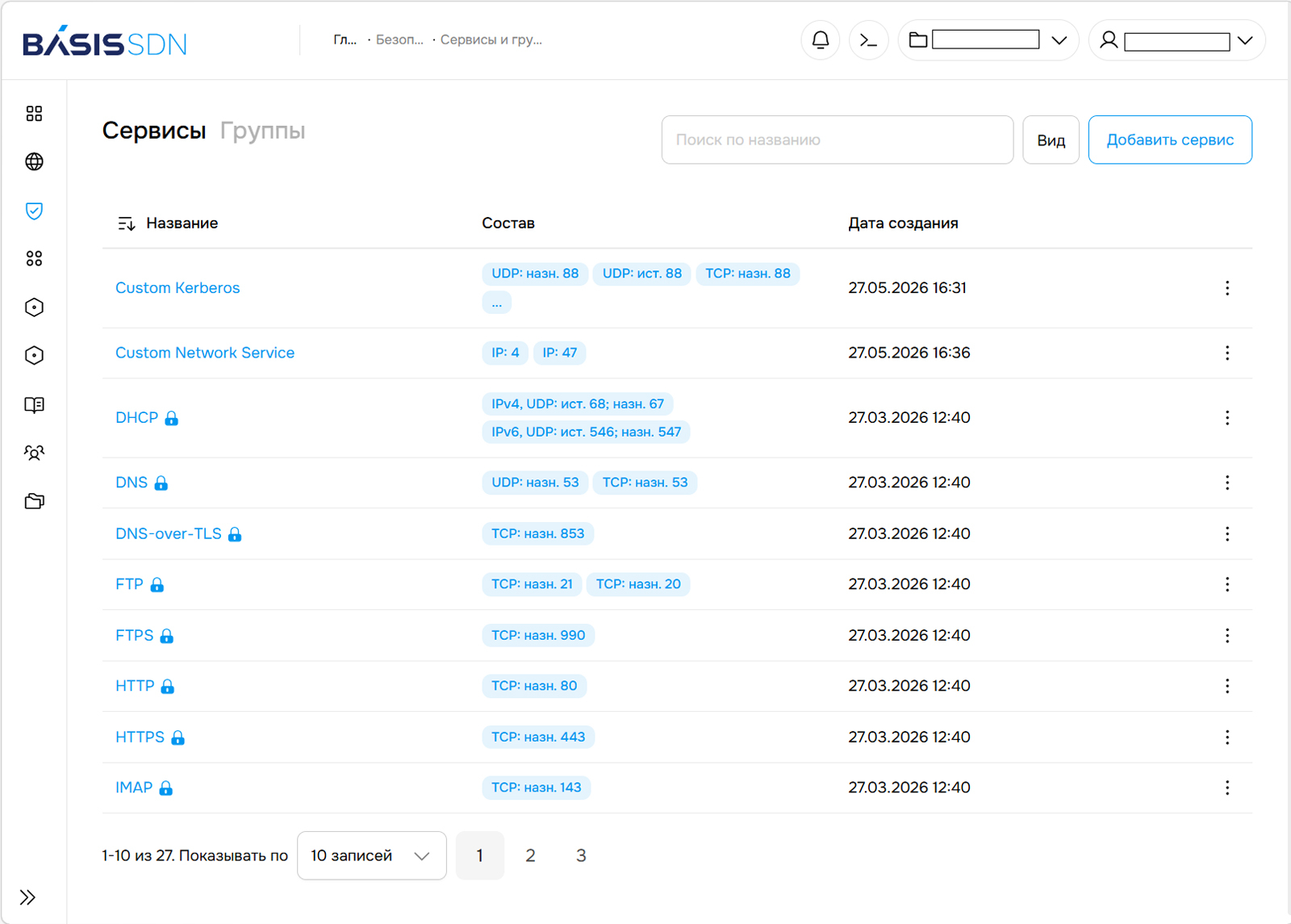
Предустановленные и пользовательские сервисы (Источник изображений: «Базис») Также в Basis SDN реализована возможность создавать сервисы не только на транспортном, но и на сетевом уровне, т. е. можно добавлять IP-протоколы в создаваемый сервис по числовому идентификатору (например, 4 — IP-in-IP, 47 — GRE, 50 — ESPP и др.). Это даёт дополнительную гибкость сетевой инфраструктуре заказчиков, поскольку они могут использовать внутри собственной сети различные специфические протоколы для решения конкретных задач, например, GRE позволяет создать виртуальный туннель для изолированной передачи IPv6-трафика внутри IPv4-сети. В релизе 1.2 появились группы безопасности — универсальные объекты, в которые можно добавлять порты, сети, адреса IPv4 и IPv6, MAC-адреса и другие компоненты инфраструктуры. Администратор Basis SDN может самостоятельно создать такой объект и затем оперировать им, например, при настройке политик безопасности. 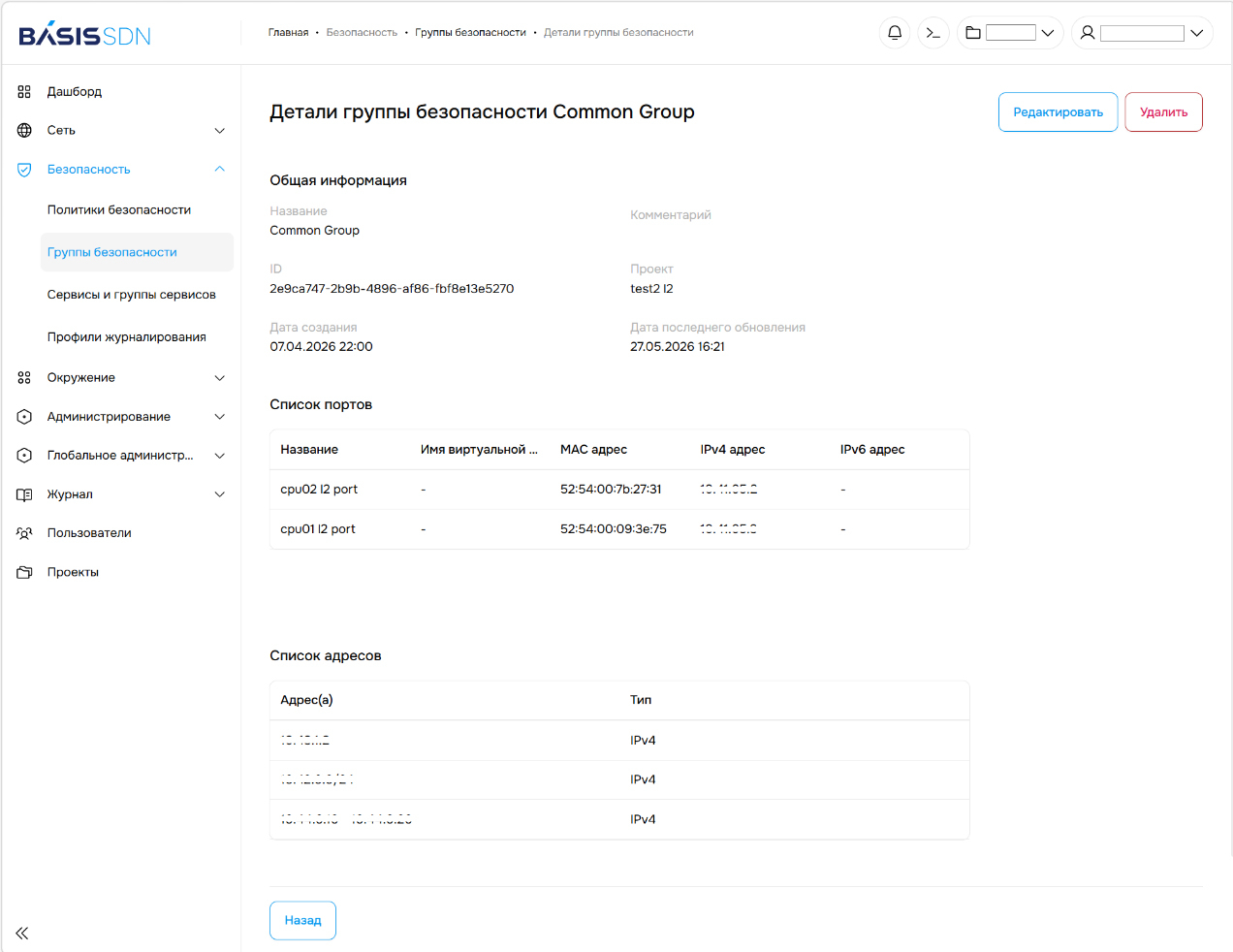
Группы безопасности Basis SDN Улучшенное журналирование событий для контроля за происходящим в сети организацииЗаписи в журнале правил безопасности обновлённого Basis SDN содержат более подробную информацию о событии: какое правило сработало, время срабатывания, тип трафика, протокол, адрес и порт источника, адрес и порт назначения, данные транспортного уровня и т. д. Эта информация упрощает для ИБ-специалистов выявление и анализ аномалий внутри сети организации. 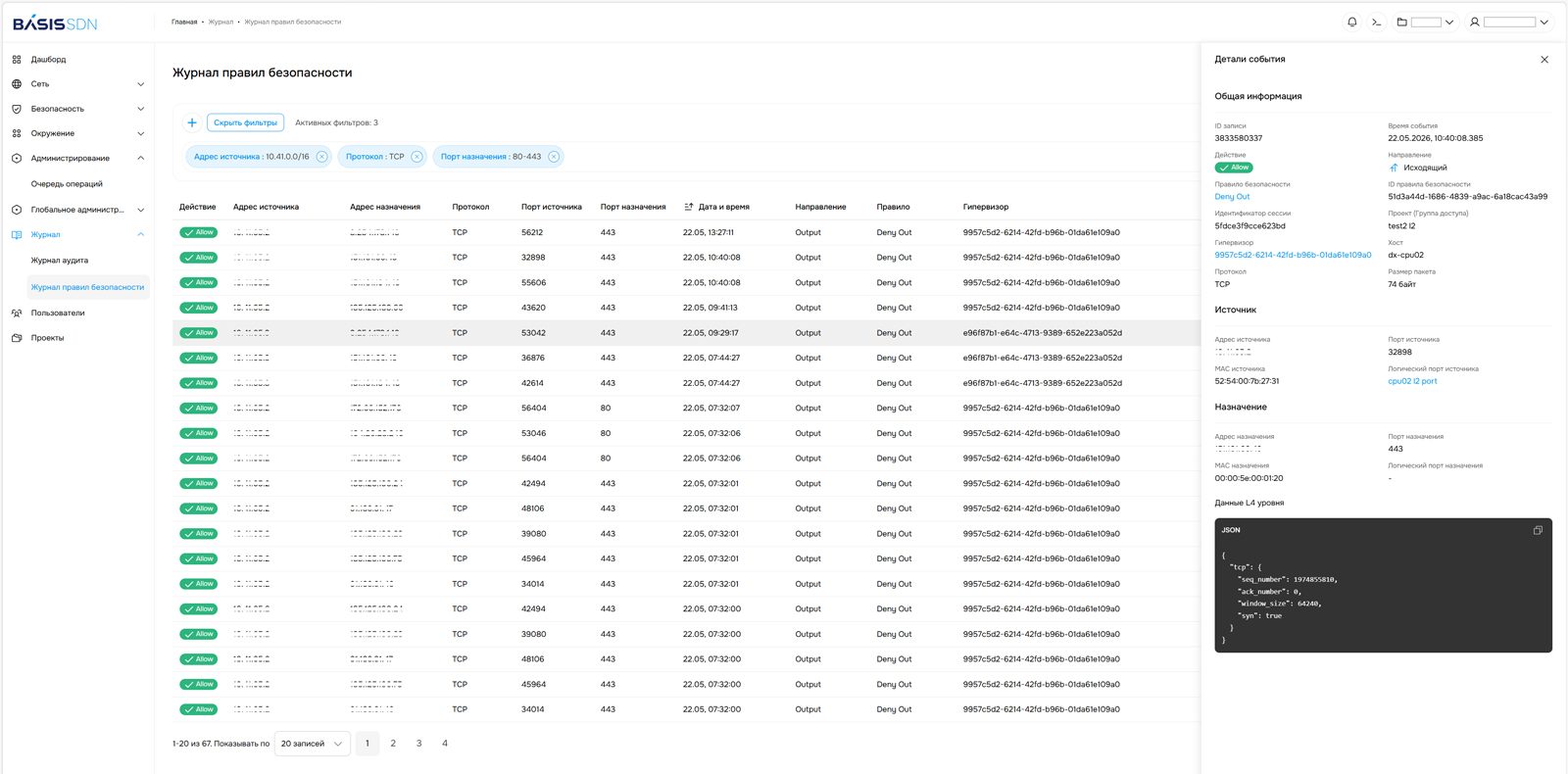
Запись в журнале правил безопасности Необходимую специалистам гибкость журналирования трафика в Basis SDN обеспечивает наличие профилей. В профиле журналирования можно управлять интенсивностью логирования трафика для новых и уже установленных сессий, а также задавать направление логирования: только входящий трафик, только исходящий, двунаправленный. Профили применяются к правилам безопасности и трафику «на лету», без перезапуска. Фильтрация записей в журнале правил безопасности Basis SDN реализована через специальный API. Такой подход позволяет специалистам искать нужные данные в журнале по их значениям, в том числе искать внутри диапазона портов, по маскам подсетей и т. д. Такой поиск намного более эффективен по сравнению с текстовым, поскольку, например, если правило действует для диапазона портов с 22 по 80, его можно найти по любому порту внутри этого диапазона, а не только по граничным значениям «22» или «80» как в текстовой форме записи. Аналогичный подход реализован для самих правил безопасности, что даёт возможность быстро находить необходимые правила и обеспечивает качественную интеграцию со сторонними решениями, работающими с сетевыми политиками безопасности (NSPM). 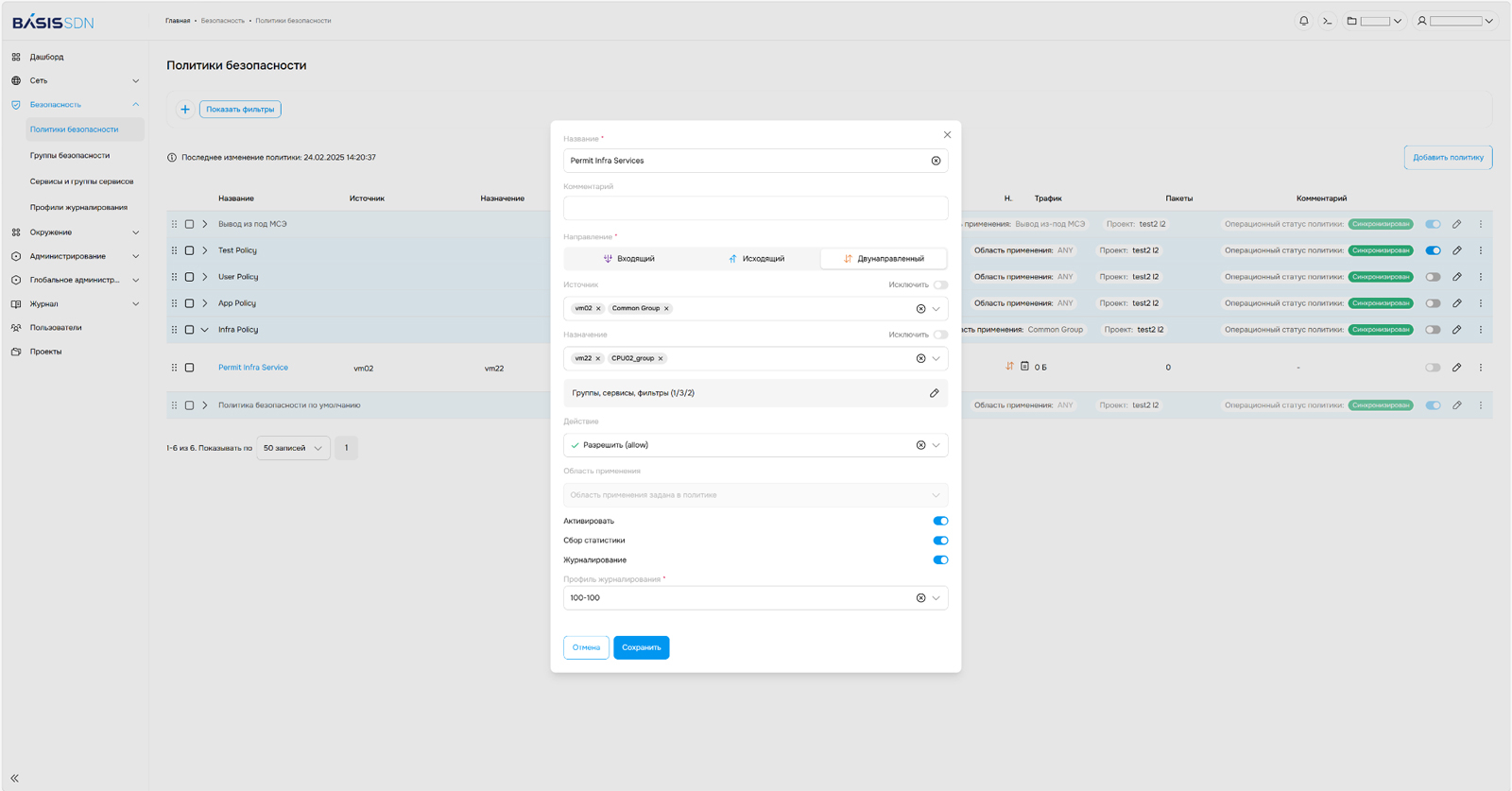
Политики и правила безопасности Для эффективного взаимодействия Basis SDN с современными решениями класса SIEM была реализована отправка событий правил безопасности на внешние серверы в формате RAW и CEF. Поддержка формата CEF избавляет ИБ-специалистов от необходимости самостоятельно размечать события, что значительно облегчает обработку данных. При необходимости специалисты заказчика могут дополнительно настроить фильтрацию передаваемых из Basis SDN данных по уровню критичности сработавшего правила. Соответствующие настройки есть как для журнала правил безопасности, так и для журнала аудита. 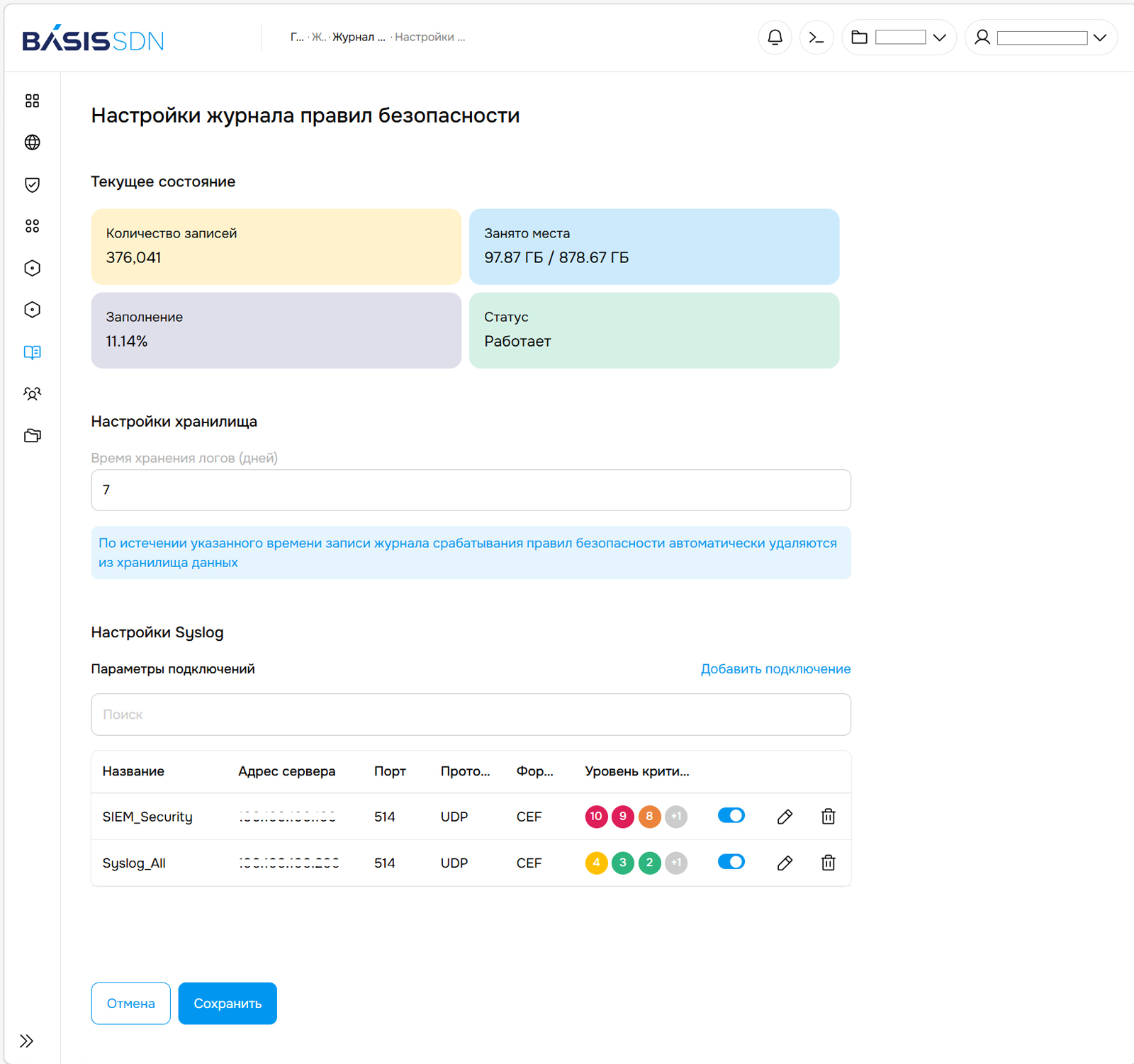
Настройки журнала правил безопасности «За год, прошедший с момента презентации Basis SDN, мы расширили функциональность решения до уровня мировых аналогов и сделали работу с ним более простой и удобной. В новом релизе мы не просто добавили ряд инструментов, а обновили логику работы Basis SDN: реализовали двунаправленные правила, создали несколько областей их применения и упорядочили наследование между этими областями. Получившаяся архитектура Basis SDN не уступает мировым аналогам и качественно опережает решения, построенные на открытом ПО», — отметил Дмитрий Сорокин, технический директор компании «Базис». |
|

