Материалы по тегу: ии
|
08.06.2026 [09:41], Сергей Карасёв
Supermicro представила Arm-серверы для агентного ИИКомпания Supermicro анонсировала серверы с Arm-процессорами, оптимизированные для агентного ИИ. Устройства обеспечивают высокую энергоэффективность и масштабируемость, позволяя формировать стойки высокой плотности. Представлены модели с воздушным и жидкостным охлаждением. В частности, дебютировал сервер ARS-222H-NR типоразмера 2U, допускающий установку двух процессоров Arm AGI с 64, 128 или 136 вычислительными ядрами. Предусмотрены 24 слота для модулей DDR5-8800 суммарным объёмом до 6 Тбайт. Во фронтальной части расположены восемь отсеков для SFF-накопителей (NVMe). Есть пять слотов PCIe 6.0 x16 для карт FHHL, по одному разъёму PCIe 6.0 x8 FHHL и PCIe 6.0 x8 AIOM (OCP 3.0), а также коннектор M.2 22110/2280 для SSD с интерфейсом PCIe 4.0 x1. Применено воздушное охлаждение. Питание обеспечивают два блока мощностью 2700 Вт с сертификатом 80 Plus Titanium. Кроме того, представлен GPU-сервер ARS-522GP-NR формата 5U с поддержкой двух чипов Arm AGI. Эта машина позволяет задействовать до восьми ИИ-ускорителей двойной ширины (восемь слотов PCIe 5.0 x16). Конфигурация включает 24 разъёма для модулей DDR5-8800 (до 6 Тбайт), четыре слота PCIe 5.0 x16 FHHL, по одному слоту PCIe 6.0 x16 FHFL и PCIe 5.0 x8 AIOM (OCP 3.0). Доступны восемь фронтальных отсеков для SFF-накопителей (NVMe) и коннектор M.2 22110/2280 (PCIe 4.0 x1). Задействованы шесть блоков питания мощностью 2700 Вт с сертификатом 80 Plus Titanium и воздушное охлаждение. 
Источник изображений: Supermicro В свою очередь, модель ARS-242TP-QNR-LCC стандарта 2OU использует четырёхузловую конфигурацию с прямым жидкостным охлаждением D2C (Direct to Chip). Каждый узел рассчитан на два чипа Arm AGI, 24 модуля DDR5-8800 (до 6 Тбайт) и два накопителя M.2 22110/2280 (PCIe 6.0 x4). Кроме того, имеются два слота PCIe 6.0 x16 AIOM (OCP 3.0) и два опциональных фронтальных отсека для накопителей E1.S (PCIe 5.0 x4). Питание осуществляется от централизованного шинопровода.  Наконец, анонсирован сервер ARS-212HE-FNR формата 2U с поддержкой одного процессора Arm AGI (до 136 ядер) и 12 модулей DDR5-8800 (до 3 Тбайт). Возможны различные варианты исполнения подсистемы хранения данных, включая четыре или шесть фронтальных отсеков E1.S и шесть тыльных посадочных мест SFF. Стандартная конфигурация предлагает три слота PCIe 6.0 x16 FHFL, по одному слоту PCIe 6.0 x8 FHFL и PCIe 6.0 x16 AIOM (OCP 3.0). Реализован один слот M.2 22110/2280 (PCIe 4.0 x1). Применено воздушное охлаждение. Мощность двух установленных блоков питания с сертификатом 80 Plus Titanium достигает 3200 Вт. У всех новинок диапазон рабочих температур простирается от +10 до +35 °C.  Помимо Arm-серверов, компания Supermicro представила 12 новых систем серии X14 на аппаратной платформе Intel Xeon 6+ Clearwater Forest, включая модели ультравысокой плотности. Устройства входят в различные семейства — Hyper, SuperBlade, FlexTwin и GrandTwin. В зависимости от варианта используется форм-фактор 1U, 2U или 6U; доступны версии с воздушным и жидкостным охлаждением.
08.06.2026 [09:00], Владимир Мироненко
FirstVDS запустил vGPU-серверы на базе NVIDIA L40S и сравнил их с физическими GPU в реальных тестахПровайдер FirstVDS запустил тарифы с виртуальными GPU (vGPU) на базе NVIDIA L40S. Теперь в линейке два варианта: можно арендовать физическую видеокарту целиком (доступно с ноября 2025 года) или получить гарантированную долю виртуальной видеокарты. Компания также сравнила обе технологии в тестах и опубликовала результаты: скорость инференса LLM, генерацию видео и потребление видеопамяти. Доступны четыре тарифа vGPU — от 4 до 16 Гбайт видеопамяти. Технология vGPU делит физическую видеокарту на несколько профилей с фиксированной долей ресурсов. Серверы работают на виртуализации KVM с процессорами AMD EPYC. Стоимость — от 299 рублей в сутки. Для сравнения: тарифы с физическим GPU (Passthrough) стартуют от 1150 руб./сутки. В них доступны RTX 4090 и 5090, L4 и L40S — вся видеокарта полностью закрепляется за одной виртуальной машиной. За последние полгода спрос на GPU-серверы вырос кратно — в первую очередь из-за задач, связанных с LLM, генерацией изображений и видео. Но не каждому проекту нужна 100 % мощность физической карты. Разработчики, Data Science-команды и небольшие студии часто ищут более доступный вход с предсказуемой долей ресурсов. vGPU как раз закрывает этот запрос. Никита Попов, директор по продукту FirstVDS: «В ноябре мы закрыли потребность в сырой мощности, запустив GPU Passthrough. Но рынку нужен не только потолок производительности, но и адекватная юнит-экономика. vGPU закрывает именно этот сегмент — снижает порог входа до 300 руб. в сутки. Мы прогнали бенчмарки. Сравнивать виртуалку с выделенной картой в лоб бессмысленно — физика берет свое, чудес не бывает. Наша цель была другой: четко очертить границы применимости. Показать механику, при которой vGPU вытягивает нагрузку, и где проходит черта, за которой пора брать полноценное железо». Что показало тестированиеКомпания протестировала две конфигурации: GPU Passthrough (L40S, 48 Гбайт, 16 ядер CPU) и vGPU 16 Гбайт (8 ядер CPU). В сценариях использовались инференс LLM через llama.cpp (модели Qwen 2.5 и 3.6) и генерация видео через ComfyUI с шаблоном Wan2.2 TI2V 5B Hybrid. Результаты в целом предсказуемы: физическая карта ожидаемо обгоняет виртуальные GPU по производительности. Но обнаружилось два важных нюанса. Во-первых, при тестировании моделей среднего размера (qwen2.5-14b в двух вариантах квантизации — q3_k_m и q4_0) на vGPU-16 и Passthrough оказалось, что при полной загрузке модели в видеопамять скорость генерации токенов практически не отличается. Разница возникает только в смешанном режиме CPU+GPU (до 30–40 слоёв), где vGPU-16 сдерживает вдвое меньшее количество ядер процессора. 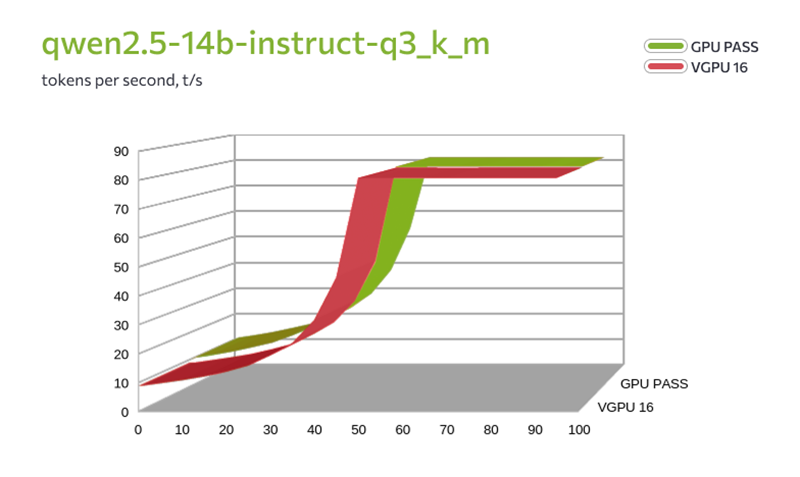
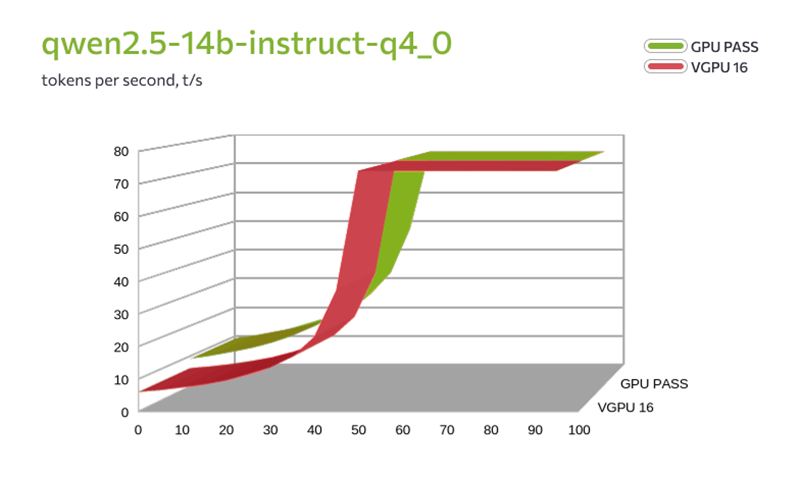
Сравнение скорости генерации токенов (qwen2.5-14b) в зависимости от количества слоёв, загруженных в GPU. Passthrough vs vGPU 16 Гбайт Во-вторых, более крупные модели (Qwen3.6-35B) в vGPU-16 полностью не загружаются — памяти не хватает, они работают только в смешанном режиме CPU+GPU со снижением скорости. Генерация видео (ComfyUI) на vGPU-16 тоже работает, но с оговорками: пришлось отключать часть функций и добавлять swap — иначе приложение аварийно завершалось. Время генерации на vGPU-16 ожидаемо выше, чем на Passthrough (для 5-секундного ролика — 293 с против 144). Таким образом, несмотря на общее преимущество физической карты, виртуальный GPU способен решать определённые задачи — например, инференс средних языковых моделей при полной загрузке в видеопамять. Это делает vGPU осмысленным выбором, когда важнее доступная цена. Для более тяжёлых сценариев (крупные модели, комфортная генерация видео без доработок) производительности vGPU может не хватить. Подробные результаты тестирования — в отдельной статье. О компанииFirstVDS — российский провайдер виртуальных серверов. В портфеле — готовые и гибкие конфигурации VPS/VDS: от высокопроизводительных CPU-серверов (линейка «CPU.Турбо 2.0» до 5,7 ГГц) до GPU-решений (Passthrough и vGPU). Также доступны S3-хранилище, домены, SSL и техподдержка 24/7. Дата-центры в Москве, Нидерландах и Казахстане. Более 20 лет на рынке.
07.06.2026 [10:31], Руслан Авдеев
МИФИ и «Росатом» разработают малые ядерные реакторы для дата-центровВ России ведутся разработки сверхмалых ядерных реакторов для ЦОД. В проекте участвуют Национальный исследовательский ядерный университет МИФИ, «Росатом» и консорциум «Большой МИФИ», сообщают «Ведомости». По словам президента «Большого МИФИ» Валерия Романюка, существует подпрограмма создания сверхмалых реакторов для ЦОД. Речь идёт об объектах мощностью от 5 до 50 МВт. Отмечается, что нагрузка на оборудование ЦОД растёт во всём мире, в связи с чем создаётся новое специализированное подразделение. Оно займётся оптимизацией работы ЦОД с применением систем искусственного интеллекта и развитием сетевой инфраструктуры. Консорциум «Большой МИФИ» объединяет как сам «ядерный университет», так и крупные компании, желающие принять участие в работах над ядерными, квантовыми и IT-проектами. В последние дни стало известно и о других проектах, связанных с индустрией ЦОД. Так, видеохостинг Rutube, входящий в «Газпром-медиа», должен обзавестись собственным ЦОД — строительство начнётся уже в конце 2026 года в Ленинградской области. ВТБ рассчитывает выделить средства на строительство неподалёку от Донецка дата-центра на 500 стоек. Его ввод в эксплуатацию запланирован на 2030 год, а эксплуатировать объект будет телеком-компания «АйСи Групп». 
Источник изображения: Hal Gatewood/unsplash.com Появились новые данные и о возможном международном сотрудничестве. Так, на фоне энергодефицита в России белорусские мощности готовы обеспечить электроэнергией российские дата-центры. Не исключался даже перенос на территорию Беларуси целых кластеров ЦОД. В конце 2025 года ВТБ прогнозировал, что к 2030 году энергопотребление дата-центров в России вырастет вдвое.
07.06.2026 [10:09], Владимир Мироненко
15 тыс. ампер на стойку: Molex представила шину питания с многоканальным жидкостным охлаждением для ИИ ЦОДКомпания Molex представила шину питания с многоканальным жидкостным охлаждением, предназначенную для использования в ИИ ЦОД. Как сообщает компания, предложенная технология объединяет распределение электроэнергии и жидкостное охлаждение в единый инфраструктурный компонент, предназначенный для поддержки ИИ-систем следующего поколения. Molex отметила, что с ростом интенсивности ИИ-нагрузок требования к мощности стоек приближаются к порогу в 1 МВт, в связи с чем традиционная инфраструктура с воздушным охлаждением достигла физического предела. Компания попыталась решить эту проблему, распространив жидкостное охлаждение на уровень распределения питания, обеспечив поддержку силы тока до 15 тыс. А и планируя в будущем достичь 25 тыс. А. Вместо одного канала, используемого в традиционной конструкции с жидкостным охлаждением, Molex предложила архитектуру с семью отдельными каналами СЖО. Многоканальная структура призвана уменьшить количество зон перегрева, а также обеспечить более равномерное и эффективное отведение тепла и более стабильную работу электрооборудования при высоких токах. 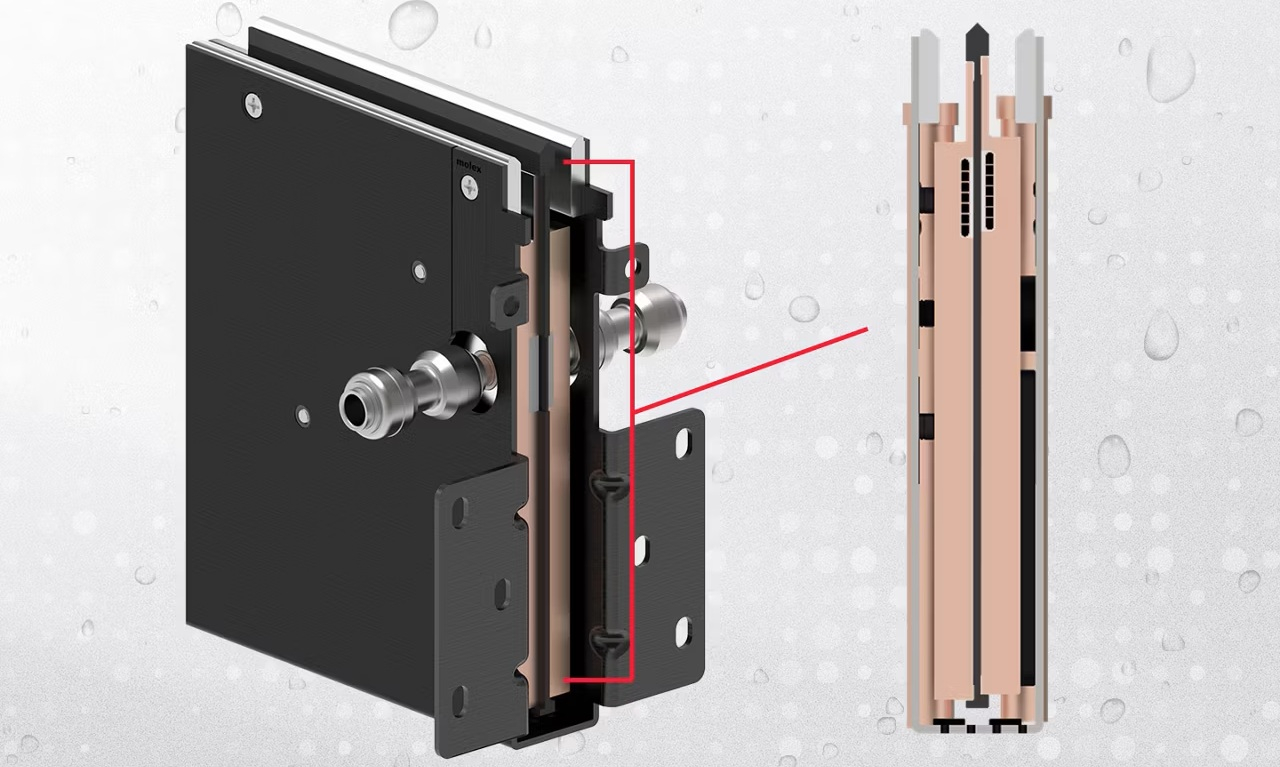
Источник изображений: Molex По данным моделирования Molex, эффективность охлаждения повышается до 20 % по сравнению с одноканальной конструкцией. При этом растёт показатель тепловой эффективности — до 15 °C T-Rise при токе 15 тыс. А. Возможность максимизировать отведение тепла при тех же габаритах позволяет архитекторам ЦОД масштабировать мощность без ущерба для ценного пространства в стойке, отметила компания. Шины могут быть сконфигурированы по длине, глубине, а также по положению входного и выходного отверстий для жидкости. Эта гибкость в сочетании со стандартным интерфейсом plug-and-play обеспечивает плавный переход к жидкостному охлаждению без необходимости перепроектирования инфраструктуры стойки. 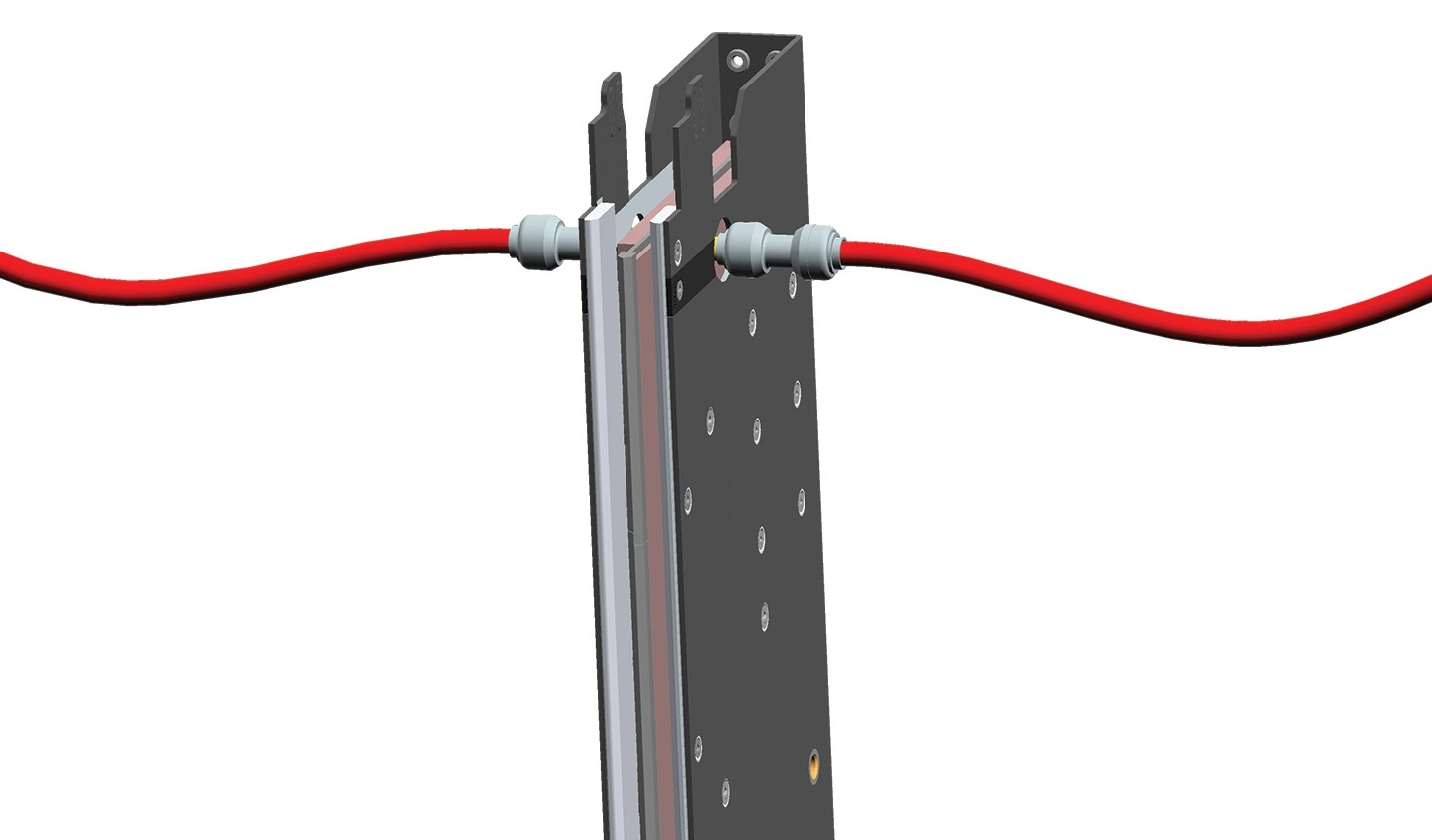 Благодаря совместимости габаритов с механическими стандартами ORV3 и HPR упрощается интеграция в стоечные архитектуры, которые уже разрабатываются с учётом всё более высоких токовых нагрузок и более высокой тепловой плотности. Совместимость с диэлектрическими и недиэлектрическими жидкостями гарантирует беспрепятственную интеграцию технологии в различные существующие контуры охлаждения объектов. Развёртывание ИИ-инфраструктуры изменило роль оборудования распределения питания. Ускорители и высокоскоростная память повышают плотность размещения оборудования в стойках, в то время как прямое охлаждение чипов уже вошло в состав основных высокопроизводительных систем. Проводники, разъёмы и шины, передающие питание по стойке, теперь подвергаются тому же тепловому и механическому воздействию, что и вычислительный слой, который они питают, отметил ресурс IN Electronics.  Распределение более высокого напряжения предлагает один из способов снижения нагрузки на медь и ограничения потерь при преобразовании. Работа Infineon с экосистемой стоек NVIDIA на 800 В DC показывает, как архитектуры на уровне стойки отходят от постепенных изменений в системе питания в сторону более масштабной электрической модернизации. Разработка Molex решает ту же проблему масштаба стойки со стороны проводников и охлаждения. Жидкостно-охлаждаемые шины питания не устранят необходимость в эффективных преобразовательных каскадах или надёжной защите, но они решают проблему обеспечения температурного режима для стоек с высокими токами. По мере повышения силы тока, силовая магистраль становится одновременно и электрическим каналом, и тепловой структурой, а её конструкция все больше влияет на плотность размещения оборудования в стойках, надёжность, удобство обслуживания и циклы модернизации.
06.06.2026 [21:50], Владимир Мироненко
Google будет выплачивать SpaceX ежемесячно $920 млн за аренду чипов NVIDIAGoogle заключила сделку с SpaceX по поводу аренды вычислительных мощностей ЦОД xAI, в рамках которой будет ежемесячно выплачивать $920 млн в период с октября 2026 года по июнь 2029 года, сообщил ресурс The Wall Street Journal. Согласно заявлению, поданному SpaceX в Комиссию по ценным бумагам и биржам США (SEC), её контрактом с Google предусмотрен доступ к 110 тыс. ускорителей NVIDIA и другим компонентам. Стоимость услуги — примерно $11 млрд в год до июня 2029 года. Если SpaceX не предоставит к 30 сентября 2026 года зарезервированные мощности, Google может расторгнуть договор после месячного льготного периода или принять предложение о любом доступном оборудовании по пропорционально сниженной цене. Также любая из сторон может расторгнуть соглашение, начиная со следующего года, уведомив об этом за 90 дней. «Это краткосрочное, своевременное соглашение, призванное обеспечить нам промежуточные мощности для удовлетворения растущего спроса клиентов на нашу агентскую платформу Gemini Enterprise, который оказался даже выше, чем мы ожидали», — заявил представитель Google Cloud. Google была одним из первых инвесторов SpaceX. Исполнительный директор Google Дональд Харрисон (Donald Harrison) входит в совет директоров SpaceX. Эксперты отмечают довольно высокую стоимость аренды и даже подозревают Google в том, что сделка призвана увеличить стоимость акций во время IPO SpaceX, поскольку Google принадлежит довольно значительная доля в SpaceX. 
Источник изображения: xAI Ранее компании обсуждали возможность сотрудничества по размещению ЦОД в космосе, пишет The Wall Street Journal. Google планирует запустить собственные орбитальные ЦОД к 2027 году в рамках проекта Project Suncatcher. Для создания этих спутников компания сотрудничает с Planet Labs. Как отметил ресурс TNW, сделка примечательна тем, что у Google есть собственные, двольно значительные вычислительные мощности. По некоторым оценкам, она является крупнейшим в мире владельцем вычислительных мощностей для ИИ, во многом благодаря своим ИИ-ускорителям TPU. Компания направит более $180 млрд на капитальные затраты в этом году и ожидает, что эта цифра «значительно увеличится» в 2027 году. Alphabet на этой неделе объявила о продаже акций на $85 млрд для финансирования этих расходов. Сделка с Alphabet по структуре похожа на соглашение, объявленное SpaceX и Anthropic в конце мая. Им предусмотрена выплата Anthropic $1,25 млрд в месяц до 2029 года за вычислительные мощности в ЦОД Colossus и Colossus II в Мемфисе (Memphis), причём точно так же предусмотрено досрочное расторжение договора. Сначала Anthropic объявила о планах арендовать 220 тыс. чипов NVIDIA у SpaceX, а затем расширила сделку до 325 тыс. чипов NVIDIA (по данным CNBC).
05.06.2026 [15:58], Сергей Карасёв
Phison представила SSD-контроллер с поддержкой PCIe 6.0Компания Phison продемонстрировала SSD-контроллер следующего поколения PS5303-X3-66. Изделие предназначено для построения высокопроизводительных накопителей корпоративного класса с интерфейсом PCIe 6.0 х4. Контроллер соответствует спецификациям NVMe 2.3 и OCP v2.6. Говорится о поддержке средств безопасности TCG Opal 2.3, DOE, IDE, Caliptra и CNSA 2.0. Решение теоретически позволяет создавать SSD вместимостью до 2 Пбайт. 
Источник изображений: Phison Чип PS5303-X3-66 обеспечивает производительность до 28 000 Мбайт/с в режимах последовательного чтения и записи. Величина IOPS (операций ввода/вывода в секунду) при произвольных чтении и записи достигает 6,8 млн. Энергетическая эффективность находится на уровне 4000 Мбайт/с/Вт. По всем этим показателям новый контроллер в два раза превосходит решения предыдущего поколения с поддержкой PCIe 5.0.  Кроме того, Phison показала новые накопители на основе PS5303-X3-66 — устройства Pascari. Они будут предлагаться в различных вариантах исполнения, включая E3.S и E1.S. В конструкцию этих SSD входят модули DRAM-памяти производства SK Hynix (Hynix H25T3TG88G). В дополнение к новому контроллеру Phison готовит другие решения с поддержкой PCIe 6.0, включая ретаймеры и редрайверы.  Кроме того, компания разработала собственный нейропроцессор (AI NPU) с кодовым именем Topaz, который содержит четыре специализированных ядра. Заявленная ИИ-производительность достигает 40 TOPS. Реализована поддержка памяти LPDDR5/5X-8533. При изготовлении применяется 6-нм технология TSMC. Восемь таких NPU положены в основу карты расширения с интерфейсом PCIe 6.0 x4, которая обеспечивает суммарное быстродействие на уровне 320 TOPS.
05.06.2026 [15:40], Руслан Авдеев
Правительство США планирует выделить $700 млн на поддержку угольной энергетики для ИИ-инфраструктурыАмериканское правительство намерено выделить до $700 млн на поддержку угольных электростанций и импорта электроэнергии. Это необходимо для того, чтобы удовлетворить растущий спрос на электричество, в первую очередь со стороны ИИ ЦОД, сообщает Datacenter Dynamics. Поддержка, как ожидается, будет осуществляться в рамках «Закона об оборонном производстве» (Defense Production Act) времён Холодной войны, который даёт исполнительной власти полномочия поддерживать частную промышленность, жизненно важную для безопасности Соединённых Штатов. В июле 2025 года администрация президента США Дональда Трампа (Donald Trump) объявила ЦОД объектами критически важной для национальной безопасности инфраструктуры. Трамп издал указ, призванный упростить получение разрешений на строительство ЦОД. Для удовлетворения растущего спроса на электричество власти активно поддержали угольную энергетику, хотя её доля в энергопотреблении страны уже достигла исторически низкого уровня — упала до 15 % от общего объёма производства электроэнергии. По имеющимся данным, из $700 млн более 50 % направят на модернизацию 13 угольных электростанций, ещё $185 млн — на софинансирование частных корпоративных проектов угольной генерации на Аляске, в Мэриленде и Западной Вирджинии, а $75 млн потратят на поддержку предложенного экспортного терминала West Gateway в Северной Калифорнии. 
Источник изображения: Tim van der Kuip/unsplash.com За последний год в США объявили о ряде мер поддержки угольного сектора. Ранее Трамп подписал указы, призванные «оживить» угольную отрасль, чтобы она помогла удовлетворить растущий спрос ИИ ЦОД на электричество. В числе прочего было принято решение отказаться от федеральных нормативов, ограничивающих добычу угля, а также поощрять использование угля для удовлетворения спроса на энергию в США и его экспорт. Кроме того, было объявлено о борьбе с «дискриминацией» добычи угля и генерации энергии на угольных электростанциях. Позже представитель Министерства энергетики США (DoE) объявил, что администрация Трампа рассчитывает на то, что вывод угольных электростанций из эксплуатации в стране будет отложен, чтобы удовлетворить спрос со стороны ИИ ЦОД. В октябре сообщалось, что американские ЦОД активно переходят на электричество с угольных объектов. По имеющимся данным, Министерство энергетики уже использовало делегированные чрезвычайные полномочия для продления срока службы угольных электростанций. В августе 2025 года компанию Consumers Energy и оператора энергосистемы Среднего Запада MISO (Midcontinent Independent System Operator) два раза обязали поддержать продолжение работы угольной электростанции J.H. Campbell в Мичигане, ссылаясь на закон, принятый почти столетие назад. В октябре Министерство энергетики выделило $625 млн на поддержку модернизации и повторного ввода в эксплуатацию угольных электростанций. Возрождение угольной энергетики, вероятно, приведёт к значительному увеличению выбросов, поскольку именно электростанции на таком топливе считаются самыми «грязными». Так, по сравнению с генерирующими мощностями, работающими на природном газе, при использовании угля выделяется вдвое больше CO2, а для выработки аналогичного количества энергии требуется значительно больше топлива.
05.06.2026 [01:27], Владимир Мироненко
Сбербанк представил универсальный оптический вычислитель для ИИ-задачСбербанк представил универсальный оптический вычислитель, созданный для реальных задач ИИ. В его основе лежит фотонная интегральная схема, разработанная специалистами компании, пишет ТАСС. По словам компании, данная разработка является первой в России и одной из первых в мире. Как сообщили в «Сбере», в задачах ИИ устройства фотоники обеспечивают принципиально новый уровень скорости и энергоэффективности. «Уже первый прототип способен выполнять более 1 млрд операций матричного умножения в секунду, и мы видим путь к увеличению частоты оптических операций до 10 ГГц и более. Само умножение в оптике происходит за доли наносекунды; при этом энергопотребление оптического ядра более чем на 30 % ниже электронных аналогов», — отметили в компании. 
Источник изображения: Paul Hanaoka/unsplash.com Также сообщается, что чип выполняет самую энергозатратную часть вычислений в ИИ — умножение матриц, на которое приходится основная нагрузка при обучении и работе LLM. В компании отметили, что переход на фотонику — один из реальных способов справиться с ростом энергопотребления ЦОД и выстроить более эффективную и масштабируемую вычислительную инфраструктуру. К тому же для страны преимущество использования оптических чипов заключается в том, что их производство локализуется проще, чем электронных.
04.06.2026 [15:31], Руслан Авдеев
«Яндекс» применит концепцию кампусов ЦОД и жидкостное охлаждение для быстрого развёртывания ИИ-мощностейКоллектив Yandex Infrastructure объявил о пересмотре подхода к строительству ЦОД и охлаждению оборудования. Предполагается, что строительство кампусов из нескольких ЦОД рядом друг с другом и использование систем жидкостного охлаждения (СЖО) помогут ускорить развёртывание ИИ-сервисов компании. Концепция кампусов не нова и активно применяется в России и за рубежом. Считается, что строительство нескольких ЦОД в одном месте, использующих общую внешнюю инфраструктуру, даст возможность более эффективно использовать имеющиеся ресурсы, сократить расходы и поднять мощность в три раза — до 180 МВт (в сравнении с немногим более 60 МВт сегодня). По данным «Яндекса», это рекордный для России уровень, позволяющий обеспечить пользователям гибко масштабировать сервисы под собственные задачи с гарантированной надёжностью. 
«Яндекс» Параллельно компания внедряет в своих ЦОД системы жидкостного охлаждения. Для этого специально разработаны дополнительные стойки-сайдкары с жидкостно-воздушными радиаторами. Такое оборудование позволяет использовать СЖО в ЦОД с воздушным охлаждением (фрикулингом) без необходимости масштабной и сложной реконструкции дата-центров. Комбинация технологий позволяет эффективно управлять температурой оборудования и даёт возможность быстрее адаптировать инфраструктуру к росту нагрузок, связанных с задачами самого «Яндекса» и его внешних партнёров. Статистика IDC за 2024 год показывала, что уже на то время 22 % дата-центров применяли СЖО. По мере роста вычислительных нагрузок на фоне широкого внедрения ИИ, внедрение таких систем становится крайне желательным для более эффективного отвода тепла и снижения энергопотребления. 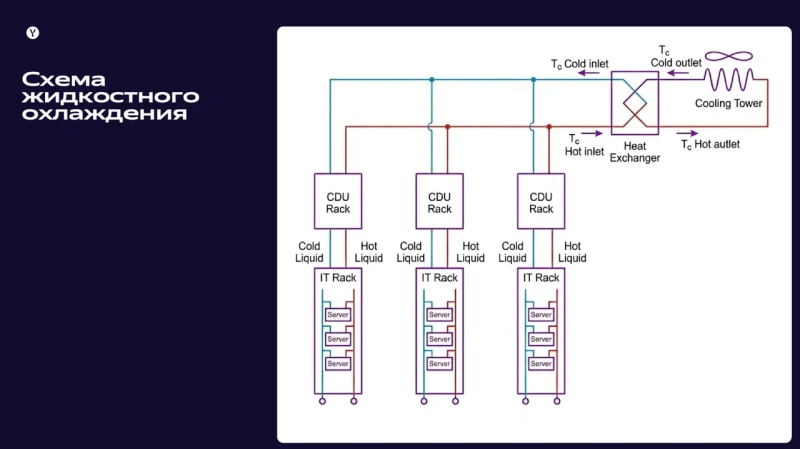
Источник изображения: «Яндекс» По данным «Яндекса», использование фрикулинга и отказ от доохлаждения обеспечивает показатель PUE на уровне 1,1 — один из лучших для ЦОД в мире. Внедрение СЖО позволит ещё больше снизить затраты энергии и укрепить экологическую безопасность дата-центров. Команда готовит внутреннюю инфраструктуру «Яндекса», необходимую для всех сервисов компании: дата-центры, сеть, распределённые хранилища данных огромного объёма, а также платформы для разработки и внедрения и инфраструктуру для машинного обучения.
04.06.2026 [14:22], Руслан Авдеев
Iren построит в Австралии кампус ИИ ЦОД мощностью 800 МВтАмериканская неооблачная компания Iren объявила подписала соглашение, предусматривающее подключение к электросети в Банди (Bundey, шт. Южная Австралия) в 2028 году дата-центра мощностью 800 МВт, сообщает Datacenter Dynamics. Это первый проект Iren в Австралии. По словам компании, Южная Австралия имеет необходимые ресурсы для ИИ-инфраструктуры — избыток «чистой» энергии, возможность подключения к сетям связи для обслуживания Азиатско-Тихоокеанского региона, а также лояльность местных властей, понимающих перспективы открывающихся перед штатом возможностей. Кампус в местности Банди поможет обеспечить запросы на ИИ-вычисления со стороны региональных и зарубежных клиентов. Растущие потребности в ИИ имеются и в самой Южной Австралии. Ранее в этом году Iren заявила, что возможности для ведения бизнеса в Австралии столь же значительны, как и в любом другом направлении из портфолио компании. По данным Iren, кампус расположится в 125 км от Аделаиды. 
Источник изображения: Liam Pozz/unsplash.com По словам властей штата, инвестиции Iren позволят создать сотни рабочих мест в строительстве, обеспечить занятость квалифицированных кадров на постоянной основе и усилят позиции Южной Австралии в качестве технологического и инновационного хаба в Азиатско-Тихоокеанском регионе. У компании имеются действующие и строящиеся площадки ЦОД в Техасе, Оклахоме и Британской Колумбии в Канаде. По данным компании, совокупная мощность её проектов достигла 5 ГВт. В распоряжении Iren — более 23 тыс. ИИ-ускорителей Ранее известная как Iris Energy, компания постепенно переориентируется с криптомайнинга на облачные ИИ-вычисления. Хотя майнинг биткоинов пока продолжается, соответствующие операции постепенно сворачиваются, а финансовые потоки перенаправляются на развитие ИИ-бизнеса. Недавно она приобрела испанского оператора ЦОД Nostrum, обеспечив себе выход в Европу. Это обеспечивает компании порядка 490 МВт подключённых к сети мощностей в Испании. Ключевым клиентом Iren является Microsoft, а NVIDIA намерена инвестировать в её неооблачный бизнес до $2,1 млрд для внедрения до 5 ГВт мощностей. Также в июне Iren получила крупную кредитную линию на $3,65 млрд с инвестиционным кредитным рейтингом для покупки ИИ-ускорителей с целью поддержки облачного ИИ-контракта с Microsoft. Инвестиционный рейтинг обычно означает, что бизнес может получить средства на более выгодных по сравнению с обычными участниками рынка условиях. |
|

