Материалы по тегу: ии
|
02.06.2026 [17:57], Владимир Мироненко
Intel с партнёрами разработает эталонный дизайн ИИ-стоек с чипами Xeon для ODM- и OEM-производителей
clearwater forest
foxconn
granite rapids
hardware
intel
nvidia
odm
oem
sambanova systems
xeon
ии
инференс
стойка
Intel совместно с SambaNova и Foxconn объявила о намерении создать референс-дизайн стоечной ИИ-инфраструктуры на базе процессоров Intel Xeon для ЦОД, гиперскейлеров и центров интеллектуального управления. Как сообщает The Register, подход основан на ранее разработанной Intel совместно с SambaNova концепции дезагрегированного ИИ. Архитектура распределяет ресурсоёмкие операции предварительного заполнения между ускорителями NVIDIA, используя чипы SambaNova для ресурсоёмких операций декодирования, что позволяет увеличить выход токенов для каждого пользователя в 2–3 раза. Генеральный директор Intel Лип-Бу Тан (Lip-Bu Tan) представил два примера таких проектов. Один предназначен для агентных нагрузок, чувствительных к задержкам, а другой — для обеспечения максимальной плотности вычислений. Обе конфигурации поддерживают до 128 процессоров Intel: либо 128-ядерных Granite Rapids-AP, либо 288-ядерных Clearwater Forest, что в сумме составляет от 16 384 P-ядер до 36 864 E-ядер, а также до 384 Тбайт DDR5 при энергопотреблении 100 кВт. Тан сообщил, что системы на основе этого референс-дизайна будут широко доступны у ODM- и OEM-партнёров компании. В рамках сотрудничества Foxconn предоставит возможности системной интеграции для новой стоечной ИИ-инфраструктуры. Компания также планирует выпускать вариант стоечной инфраструктуры с высокой плотностью процессоров для рабочих нагрузок, не требующих дополнительного ускорения, включая оптимизированные по стоимости задачи инференса, обработку данных и гибридный ИИ. Intel объявила, что облачный провайдер Vector Core Compute, созданный Vista Equity Partners и Cambium Capital, станет одним из первых, кто развернёт эту платформу, а Together.AI — её первым коммерческим клиентом. 
Источник изображения: Intel Также на выставке Computex 2026 компании Intel, SambaNova, Vista Equity Partners и Cambium Capital представили первую реальную демонстрацию дезагрегированной системы инференса, использующей процессоры Intel Xeon 6 для оркестрации, блоки RDU SambaNova SN40 для декодирования и NVIDIA Blackwell для предварительного заполнения, работающую в ЦОД Vector Core Compute в Лос-Анджелесе. Напомним, что ранее NVIDIA объявила о запуске аналогичной стоечной платформы, включающей 256 88-ядерных процессоров Vera, ускорители Rubin и LPU Groq 3. Arm также работает над парой референс-дизайнов стоечных систем для агентных рабочих нагрузок на основе своих новых процессоров Arm AGI: 36-кВт системой с воздушным охлаждением и 8160 ядрами, а также 200-кВт системой с жидкостным охлаждением и 45 696 ядрами.
02.06.2026 [14:22], Руслан Авдеев
Bull и Foxconn объединили усилия, чтобы нарастить производственные мощности ЕС в сфере ИИ-инфраструктурыЕвропейская Bull совместно с тайваньской Hon Hai Technology Group (Foxconn) объявили о стратегическом сотрудничестве, направленном на масштабирование производства облачной и ИИ-инфраструктуры. Масштабировать производство планируется как для Европы, так и для мирового рынка. Вкладом Bull станут лидерские компетенции в проектировании, внедрении и выводе на рынок ИИ-систем, а Foxconn обеспечит производственные мощности и цепочки поставок мирового масштаба. Это позволит выпускать решения в сфере ИИ-инфраструктуры, в том числе вычислительные системы и связанные с ними комплектующие. Производство будет осуществляться на заводе Bull в Анже (Angers, Франция) и заводах Foxconn в Пардубице (Pardubice, Чехия). Такой подход позволит удовлетворять растущие потребности Европы в сфере ИИ-фабрик, а также потребности «неооблачных» провайдеров в региональных производственных мощностях. При этом компании рассчитывают сохранить конкурентоспособность по соотношению стоимости, качества и сроков вывода продукции на рынок. Партнёрство сосредоточится на обеспечении своими решениями европейских ИИ-фабрик и ИИ-инфраструктуры, что соответствует европейскому видению суверенного регионального ИИ. Новая инициатива призвана стать ключевым фактором развития европейской суверенной ИИ-экосистемы благодаря размещению ключевых производственных мощностей во Франции. Для этого первоначальные инвестиции в стране превысят €120 млн. 
Источник изображения: Gabrielle Henderson/unsplash.com Тем временем отраслевые прогнозы свидетельствуют, что Европа всё ещё зависит от внешних рынков ключевых компонентов и технологий для ИИ, поэтому остаётся уязвимой в случае сбоев поставок, что ограничивает её промышленную автономию. По данным ING, сегодня на Европу приходится порядка 8 % мировых мощностей по выпуску полупроводников. Более того, по данным McKinsey, в ряде ключевых сегментов ИИ-инфраструктуры, включая облачные и передовые вычислительные платформы, доля Европы и вовсе составляет лишь 5 %. Первоначально Bull и Foxconn сосредоточатся на подготовке производства и промышленном развитии ИИ-систем, предназначенных для ресурсоёмких задач, таких как обучение ИИ и инференс. Системы будут использовать передовые ускорители, а также высокопроизводительную память, системы хранения данных, масштабируемые интерконнекты и другие компоненты. Автономные решения и варианты для стоек будут удовлетворять потребности самых разных пользователей, включая ИИ-фабрики, неооблачных провайдеров, исследовательские институты и другие организации в пределах европейских границ. Производство и начальное тестирование будут проводиться на фабриках Foxconn в Чехии, а финальная сборка, интеграция и проверка на системном уровне — на заводе Bull во Франции. В январе сообщалось, что Atos перезапускает бренд Bull, после чего его выкупило французское государство. Компания разрабатывает, внедряет и обслуживает оборудование и ПО, в том числе суперкомпьютеры. Bull позиционируется, как единственный европейский игрок, способный разрабатывать, выпускать и внедрять решения такого класса.
02.06.2026 [12:00], Сергей Карасёв
«Базис» реализовал нативную интеграцию с печатными устройствами «Катюша»Компания «Базис», лидер российского рынка ПО управления динамической ИТ-инфраструктурой, добавила в свою флагманскую платформу виртуализации рабочих мест Basis Workplace нативную интеграцию с многофункциональными устройствами (МФУ) российского производителя печатной техники «Катюша». Реализация проекта проходила в инфраструктуре банка ВТБ, который перевёл на решения «Базиса» более 60 тысяч сотрудников. В сотрудничестве с производителем печатного оборудования было реализовано техническое решение, обеспечивающее совместимость между протоколом TWAIN, используемым устройствами по умолчанию, и протоколом WIA 2, применяемым в виртуализированной инфраструктуре для взаимодействия через программные интерфейсы. Это позволило обеспечить трансляцию вызовов между протоколами и интеграцию сканирующих функций МФУ в контур виртуальных рабочих мест. Итоговое тестирование подтвердило корректную работу сканеров МФУ «Катюша» в Basis Workplace и их полную совместимость с виртуализированной инфраструктурой. 
Источник изображения: «Катюша» «Одним из ключевых преимуществ российских вендоров является работа в тесной связке с заказчиками и оперативная адаптация продуктов под их прикладные требования. Нативная интеграция нашей VDI-платформы с устройствами "Катюша" в инфраструктуре ВТБ является примером такого практического взаимодействия, когда запрос заказчика трансформируется в рабочий и тиражируемый результат. Подчеркну, что после реализации такую связку продуктов можно без опасений рекомендовать другим заказчикам, как уже проверенную», — прокомментировал Дмитрий Сорокин, технический директор «Базиса». «Для нас сотрудничество с "Базисом" – это не разовая интеграция, а системная работа. Когда два российских производителя — платформы виртуализации и печатной техники — эффективно взаимодействуют в работе с протоколами, выигрывает прежде всего заказчик. Он получает готовую, проверенную связку, где не надо ничего "допиливать" своими силами. Банк ВТБ уже оценил это на практике. Уверены, что наш опыт будет востребован и другими компаниями, которые строят собственные VDI-инфраструктуры на российском стеке», — отметил генеральный директор компании «Катюша» Максим Виноградов. «Для нас как для заказчика важно, чтобы сотрудники банка работали с удобным и надёжным инструментом, не уступающим иностранным аналогам. Проведённое тестирование подтвердило нативное взаимодействие МФУ "Катюша" с Basis Workplace, в том числе корректную работу функций сканирования в инфраструктуре виртуальных рабочих мест. Данная связка продуктов российских вендоров может успешно применяться в масштабной корпоративной инфраструктуре», — прокомментировал заместитель руководителя департамента развития инфраструктуры, вице-президент ВТБ Николай Шуткин.
02.06.2026 [11:12], Сергей Карасёв
HPE представила сервер ProLiant Compute DL394 Gen12 на платформе NVIDIA VeraКомпания HPE анонсировала сервер ProLiant Compute DL394 Gen12 для ресурсоёмких нагрузок в области ИИ и обработки данных. Система выполнена на аппаратной платформе NVIDIA Vera. Изделия Vera насчитывают 88 ядер Olympus, совместимых с набором инструкций Arm v9.2. Возможна одновременная обработка до 176 потоков инструкций. Поддерживается до 1,5 Тбайт LPDDR5X с пропускной способностью до 1,2 Тбайт/с. Характеристики ProLiant Compute DL394 Gen12 пока полностью не раскрываются. Известно, что новинка выполнена в форм-факторе 2U. HPE отмечает, что изделия Vera благодаря монолитной конструкции позволяют решить проблему неоднородного доступа к памяти, которая может наблюдаться при использовании традиционных чиплетных архитектур с большим количеством ядер. Эта особенность приводит к переменным задержкам и непредсказуемой производительности. В случае Vera каждому вычислительному ядру предоставляется полоса пропускания до 14 Гбайт/с, что даёт возможность обрабатывать данные на стабильно высокой скорости. 
Источник изображения: HPE В сервере реализованы средства управления HPE Integrated Lights-Out (HPE iLO 7). Говорится о защите от будущих кибератак, основанных на квантовых вычислениях, в соответствии с требованиями Национального института стандартов и технологий США (NIST). Средства HPE Compute Ops Management (COM) обеспечивают унифицированное управление серверной инфраструктурой из единой консоли. ProLiant Compute DL394 Gen12 может применяться для агентного ИИ, обработки больших объёмов транзакций и других задач. В продажу сервер поступит осенью текущего года.
02.06.2026 [10:04], Руслан Авдеев
NVIDIA усилила DPU BlueField-4 мониторингом работы ИИ-агентов в реальном времениNVIDIA Vera BlueField-4 STX (BF-4 STX) обеспечит ИИ-системам защиту ИИ-агентов, контекстной памяти и доступа к файлам непосредственно на аппаратном уровне, сообщает Blocks & Files. DPU поддерживает программную платформу DOCA (Data Center Infrastructure-on-a-Chip Architecture), обеспечивающую доступ по принципу Zero Trust, а также ведёт мониторинг и контроль деятельности ИИ-агентов для предотвращения утечки данных, несанкционированного доступа и других угроз. Решение разработано в рамках создания платформы NVIDIA Vera Rubin. Решение использует три интегрированные библиотеки безопасности и микросервисы DOCA, работающие в процессоре и памяти DPU. В частности, речь идёт о микросервисе DOCA Vault, благодаря которому доступ к нужным файлам с необходимыми правами получают только авторизованные ИИ-нагрузки. DOCA Argus обеспечивает прозрачность действий ИИ-агентов и рабочих нагрузок, а DOCA Flow помогает изолировать сетевой трафик и защитить конфиденциальные данные в экосистемах с многочисленными арендаторами ресурсов. 
Источник изображения: NVIDIA Благодаря BF-4 STX серверы и СХД могут анализировать и контролировать взаимодействие ИИ-агентов, данных и контекстной памяти в потоке данных. По информации NVIDIA, обнаружение угроз происходит до 1000 раз быстрее, чем в существующих средах без агентного мониторинга, а контроль работы осуществляется на скоростях до 800 Гбит/с. Свои решения в сфере безопасности интегрируют с Vera BlueField-4 STX компании Akamai, Armis, Check Point, Cisco, CrowdStrike, EQTY, F5, Fortinet, Palo Alto Networks, TrendAI, Xage Security и Zscaler. Платформы на базе STX предлагают провайдеры систем хранения данных: Cloudian, DDN, Dell, Everpure, Hitachi Vantara, HPE, IBM, MinIO, NetApp, Nutanix, VAST Data и WEKA. Системы на базе STX уже разрабатывают Asus, Foxconn, Gigabyte Technology, Supermicro, Wistron и Wiwynn. Заказчикам помогают внедрять соответствующие решения интеграторы Accenture, Deloitte и World Wide Technology.
02.06.2026 [01:04], Владимир Мироненко
ИИ-ускоритель Intel Crescent Island получит до 480 Гбайт LPDDR5XIntel сообщила новые подробности о своём будущем ИИ-ускорителе для ЦОД с кодовым именем Crescent Island, который был анонсирован в прошлом году. Новый GPU основан на архитектуре Xe3P, представляющей усовершенствованную версию Xe3, которая используется в процессорах Core Ultra 300 семейства Panther Lake. Ожидается, что Xe3P также будет использоваться в GPU Intel серии Arc-C для клиентских устройств. Компания отметила, что чип разработан специально для рабочих нагрузок агентного ИИ. В то время как традиционные ИИ-ускорители от NVIDIA и AMD полагаются на дорогую память HBM, в новом чипе Intel используется LPDDR5X, и он предназначен для работы в серверах с воздушным охлаждением, а не с жидкостным. Crescent Island будет поддерживать до 480 Гбайт памяти LPDDR5X, хотя базовая эталонная конфигурация рассчитана на 160 Гбайт. Intel заявила, что Crescent Island оптимизирован по производительности на Вт — до TDP 350 Вт в версии с воздушным охлаждением и интерфейсом PCIe. 
Источник изображений: Intel Сообщается, что GPU будет поддерживать широкий спектр форматов данных от FP4 до FP64, а также полностью открытый программный стек oneAPI, что идеально подходит для поставщиков услуг «токены как услуга» и сценариев использования для инференса. Концептуально новинка напоминает Rubin CPX, от которого NVIDIA отказалась.  Intel уже оценивает свой открытый унифицированный программный стек для гетерогенных систем ИИ с помощью существующей линейки Arc Pro B-серии, поэтому будущие версии чипов получат доступ к этим оптимизациям на ранних этапах. Intel планирует начать тестирование GPU Crescent Island для клиентов во II половине 2026 года с общей доступностью в 2027 году.
01.06.2026 [16:41], Руслан Авдеев
SoftBank намерена вложить €75 млрд в 5 ГВт ИИ ЦОД и совместное производство с Schneider Electric во ФранцииЯпонская SoftBank Group обнародовала планы строительства и эксплуатации во Франции ИИ ЦОД совокупной мощностью 5 ГВт. Это одна из крупнейших из объявленных инвестиций в европейскую ИИ-инфраструктуру на сегодня. Проект предполагает инвестиции в объёме €75 млрд ($81 млрд), сообщает Converge Digest. На первом этапе планируется потратить €45 млрд ($48,6 млрд) на постройку в О-де-Франс (Hauts-de-France) 3,1 ГВт мощностей ЦОД. Новый проект подчёркивает стремление Франции стать стратегически важным европейским хабом в сфере ИИ, цифровой инфраструктуры и промышленного производства. Первоначально будут развёрнуты площадки в Дюнкерке (Dunkirk, район Лун-Плаж), Боскеле (Bosquel) и Бушене (Bouchain). Полное завершение проекта запланировано на 2031 год. По данным SoftBank, проект должен будет способствовать локализации цепочек поставок для ИИ ЦОД в Европе, а то же время ускорятся циклы развёртывания ИИ-объектов следующего поколения. По словам SoftBank, инфраструктура будет соответствовать потребностям ИИ-разработчиков, облачных гиперскейлеров, исследовательских институтов, организаций государственного сектора — всем кому необходимы масштабные вычисления. В рамках проекта будут использоваться преимущества Франции — доступ к низкоуглеродному электричеству АЭС, землям промышленного назначения, а также близость к ключевым европейским экономическим маршрутам, связывающим Париж, Брюссель, Амстердам, Лондон и Франкфурт. 
Источник изображения: Pascal Bernardon/unsplash.com В основе стратегии SoftBank лежит промышленное взаимодействие со Schneider Electric для создания крупного производственного кластера в порту Дюнкерка. Там разместится предприятие SoftBank для выпуска готовых модулей для ЦОД, а Schneider Electric займётся интеграцией сборных силовых модулей для ИИ-инфраструктуры. Отдельно SoftBank совместно с французской Sesterce, специализирующейся на ИИ-инфраструктуре, подтвердили планы создания кампуса ИИ ЦОД мощностью 1 ГВт в Боскеле в рамках «расширенного проекта» на 5 ГВт. Для Европы проект может стать очередным шагом по обеспечению цифрового суверенитета, причём Франция нередко позиционирует себя как оптимальное место для строительства ИИ-инфраструктуры благодаря наличию развитой атомной энергетики, зон промышленной реконструкции и поддержке стратегически важных вычислительных мощностей со стороны государства. Благодаря взаимодействию со Schneider Electric, SoftBank расширяет инвестиции за пределы вычислительных мощностей, включаясь и в физическую цепочку поставок, лежащую в основе ИИ-инфраструктуры. Пока неизвестно, хватит ли у SoftBank средств на вложение €75 млрд в Европе наряду с гигантскими инвестициями в США, в т.ч. в OpenAI. Эксперты полагают, что собственных средств у компании недостаточно. Её чистая прибыль значительно выросла в последние годы, но сама компания обычно располагает всего около $30 млрд ликвидных денежных средств. Почти наверняка её придётся создать новый фонд для их сбора или привлекать заёмные деньги и партнёров. Впрочем, компания и не думает останавливаться в своей экспансии на рынке ИИ. На днях сообщалось о вероятном выходе дочерней структуры — SB Energy на IPO в США, а сама SoftBank готовит японское GPU-облако AI Data Center GPU Cloud. Кроме того, недавно сообщалось, что в США при участии SoftBank намерены построить 10-ГВт кампус ЦОД.
01.06.2026 [16:04], Руслан Авдеев
США принимают меры, чтобы заблокировать поставки ИИ-чипов NVIDIA китайским компаниямМинистерство торговли США в воскресенье приняло меры, чтобы закрыть потенциальную лазейку, потенциально позволяющую экспортировать компаниям передовые чипы NVIDIA подразделениям китайских техногигантов, находящимся за пределами КНР, сообщает Reuters. Предполагается, что лучшие американские чипы поступали филиалам китайских компаний, расположенным в странах вроде Малайзии, Индонезии и даже Японии. Новое руководство опубликовали на сайте Министерства торговли, после того как, по данным источников, в Вашингтоне появился документ, посвящённый данной лазейке. В документе, пока не имеющем авторства, сообщается, что «шлюзы незаметно открылись». Другими словами, постепенно снизилась эффективность ограничений. Пока нет данных, как много чипов экспортировали в год, когда, как пишет Reuters, «администрация Трампа оставила дверь открытой» Один из осведомлённых отраслевых источников сообщил, что речь идёт о сотнях тысяч ускорителей. В руководстве Бюро промышленности и безопасности (BIS) сообщило, что обеспечит обязательное лицензирование для структур со штаб-квартирами в Китае, даже если их подразделения расположены за его пределами. Фактически, как сообщает бюро, руководство разъясняет требования к лицензированию, действующие с 2023 года. Представитель NVIDIA заявил, что новое руководство ничего не изменит для компании, добавив, что не может поставлять чипы, поскольку Министерство торговли недвусмысленно установило в своём документе лицензионные ограничения для компании. 
Источник изображения: Nick Fewings/unspalsh.com Фактически Министерство торговли само создало лазейку, когда объявило в мае 2025 года, что не будет соблюдать правило AI Diffusion Rule, принятое в последние дни прошлой администрации США — оно фактически делило мир на страны, которым можно продавать ИИ-ускорители без ограничений и те, которым можно, но с оговорками или вовсе нельзя. По словам экспертов, оставленная лазейка позволяла зарубежным подразделениям китайских компаний покупать чипы NVIDIA Blackwell безо всяких лицензий. В результате китайские компании покупают эти чипы и, похоже, в больших масштабах. Эксперты уверены, что новое руководство закроет лазейку, но останется другая. В частности, к TSMC и другим контрактным производителям отсутствуют требования проверять, что заказываемые у них передовые ИИ-чипы не предназначены для подставных структур, работающих на китайских покупателей. Сообщается, что в новом руководстве этот недочёт по-прежнему не устранен. Кроме того, если чипы уже установлены, новый документ не требует от операторов ЦОД прекратить использование таких чипов или остановить обслуживание передового оборудования вроде серверов. Ранее сообщалось, что Китай довольно активно прибегает к контрабанде ИИ-ускорителей, а также пользуется услугами компаний за рубежом, чтобы обойти американские санкции. Кроме того, страна наращивает производство собственных ускорителей и достигла соглашения с США о поставках относительно устаревших NVIDIA H200.
01.06.2026 [12:35], Сергей Карасёв
Двухтонный ИИ: Dell начала поставки первых стоек NVIDIA Vera Rubin NVL72Компания Dell Technologies поставила свою первую стойку NVIDIA Vera Rubin NVL72. Получателем системы стала компания CoreWeave — неоооблачный провайдер, который активно расширяет инфраструктуру для ресурсоёмких нагрузок ИИ. 
Источник изображений: Dell Стойка содержит 72 ускорителя Rubin и 36 процессоров Vera на архитектуре Arm. Суммарный объём памяти HBM4 составляет 20,7 Тбайт, системной памяти LPDDR5X — 54 Тбайт. Реализовано жидкостное охлаждение горячей водой (+45 °C). Сама стойка в собранном виде весит около 1,8 т и потребляет до 230 кВт. Заявленная ИИ-производительность достигает 3,6 Эфлопс в режиме NVFP4 при инференсе, что примерно в пять раз превышает показатель Blackwell. На задачах обучения быстродействие NVFP4 составляет 2,5 Эфлопс.  Отмечается, что Dell успешно провела все необходимые диагностические тесты Vera Rubin NVL72, по результатам которых система готова к дальнейшему развёртыванию на площадке заказчика. CoreWeave намерена использовать новый кластер для расширения своей инфраструктуры НРС. Масштабный вывод платформы на рынок намечен на II половину текущего года.  Между тем сама NVIDIA объявила о начале массового производства решений поколения Vera Rubin. В числе партнёров, объявивших о поддержке этих систем, названы Dell Technologies, HPE, Lenovo и Supermicro, а также AIC, Aivres, ASRock Rack, ASUS, Cloudian, Compal, DDN, Everpure, Foxconn, GIGABYTE, Hitachi Vantara, Hyve Solutions, IBM, Inventec, MinIO, MiTAC Computing, MSI, NetApp, Nutanix, Pegatron, Quanta Cloud Technology (QCT), VAST Data, WEKA, Wistron и Wiwynn. Вместе с тем CoreWeave, а также Lambda и Oracle Cloud Infrastructure одними из первых начнут развёртывание стоек Vera Rubin в своих ИИ-инфраструктурах.
01.06.2026 [12:20], Сергей Карасёв
Hyperion Research: объём мирового рынка НРС в 2025 году превысил $70 млрд, но темп роста замедлилсяПо оценкам компании Hyperion Research, глобальные расходы в области ИИ и НРС в 2025 году превысили $70 млрд, что примерно на $10 млрд больше по сравнению с предыдущим годом. Однако темпы роста замедлились до 16,9 % против 23,5 % в 2024-м, когда этот показатель оказался самым высоким за последние три десятилетия. Аналитики учитывают затраты на серверы, хранилища данных, программное обеспечение, услуги и облачные ресурсы, связанные с ИИ и НРС. В частности, в 2025 году на локальные серверы были потрачены $29,4 млрд, что на 16,7 % больше, чем годом ранее, когда продажи такого оборудования оценивались в $25,2 млрд при росте 23,4 % в годовом исчислении. В сегменте HPC-решений для локального развёртывания на долю HPE пришлось около 22,1 % продаж — $6,5 млрд против $7,2 млрд в 2024 году. У Dell отгрузки в денежном выражении за год поднялись с $3,9 млрд до $5,3 млрд, в результате чего доля составила 18,2 %. Lenovo и Inspur получили $1,8 млрд и $1,2 млрд соответственно. Далее в рейтинге ведущих игроков указанного сегмента находятся Sugon, Penguin, Atos, IBM, Fujitsu и NEC. 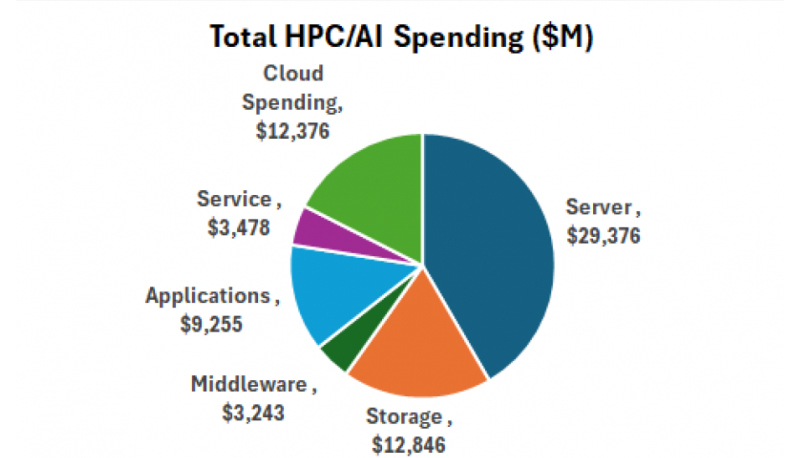
Источник изображения: Hyperion Research Системы хранения данных в 2025 году принесли поставщикам около $12,8 млрд — плюс 27,5 % по отношению к предыдущему году. Расходы в облачном сегменте оцениваются в $12,4 млрд, что на 29,7 % больше, чем в 2024-м. Приложения обеспечили $9,3 млрд, связующее ПО — $3,2 млрд, услуги — $3,5 млрд. Отмечается, что в 2021 году во всём мире были отгружены примерно 2,2 млн НРС-узлов. В 2024-м и 2025 годах показатель снизился до 500 тыс. узлов. При этом выручка в пересчёте на один узел резко возросла: в среднем с $10 тыс. до более чем $50 тыс. По прогнозам, общие затраты на локальные серверы составят около $32 млрд в 2026 году и достигнут примерно $54 млрд к 2030-му. |
|

