Материалы по тегу: ии
|
07.07.2026 [18:05], Владимир Мироненко
«Совкомбанк»: в 2026 году капитальные затраты на новые ЦОД в России сократятся на третьСогласно исследованию аналитиков «Совкомбанка», в 2026 году капитальные затраты на новые ЦОД в России сократятся по сравнению с 2025 годом 30 %, с 738 до 515 млрд руб., пишут «Ведомости». 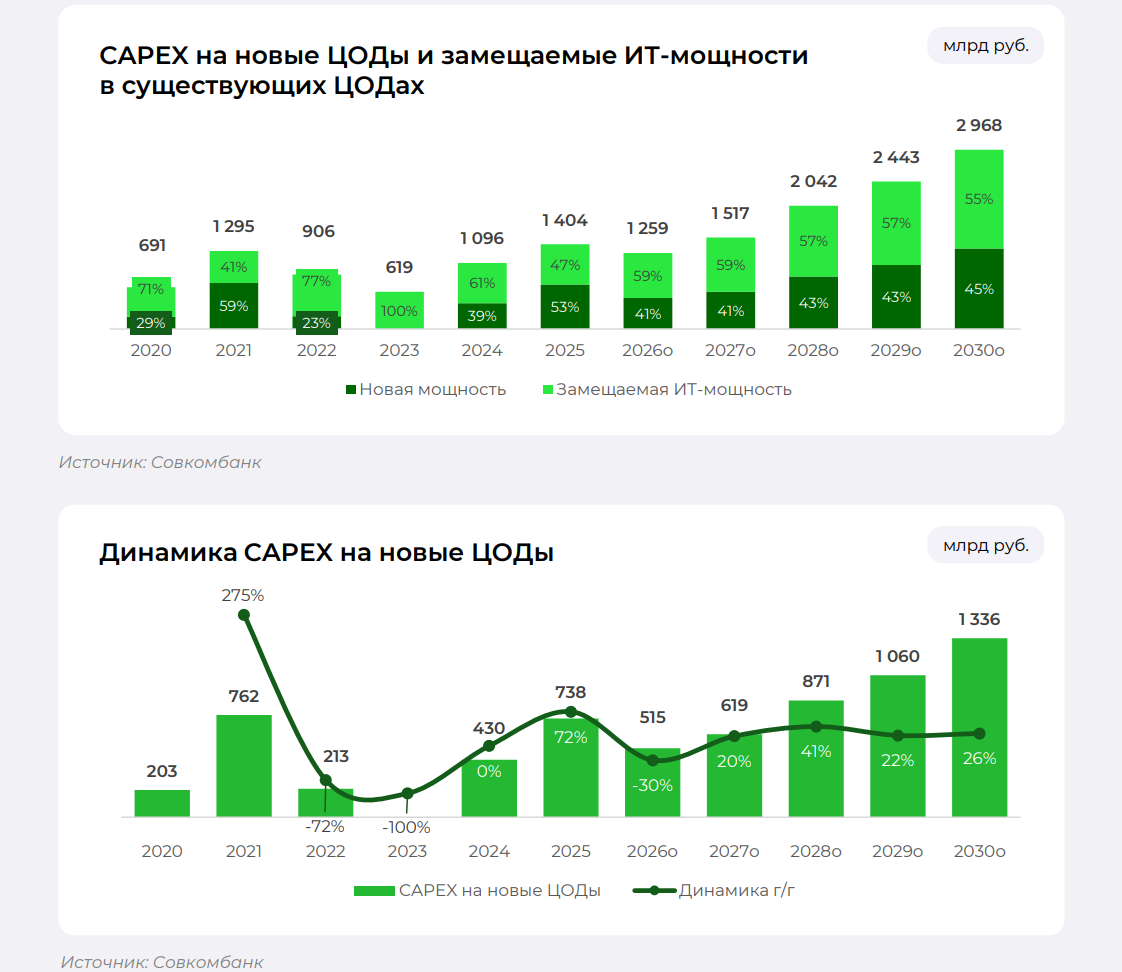
Источник изображения: «Совкомбанк» При этом совокупные капитальные затраты на ЦОД в РФ, в том числе расходы на новое строительство и замену IT-мощностей в существующих ЦОД, снизятся примерно на 10 %, с 1,404 до 1,259 трлн руб. Из них 59 % приходится на замещаемую IT-мощность, а 41 % — на новую. При этом, капзатраты на замещение IT-мощности в существующих ЦОД вырастут на 12 % до 744 млрд руб. 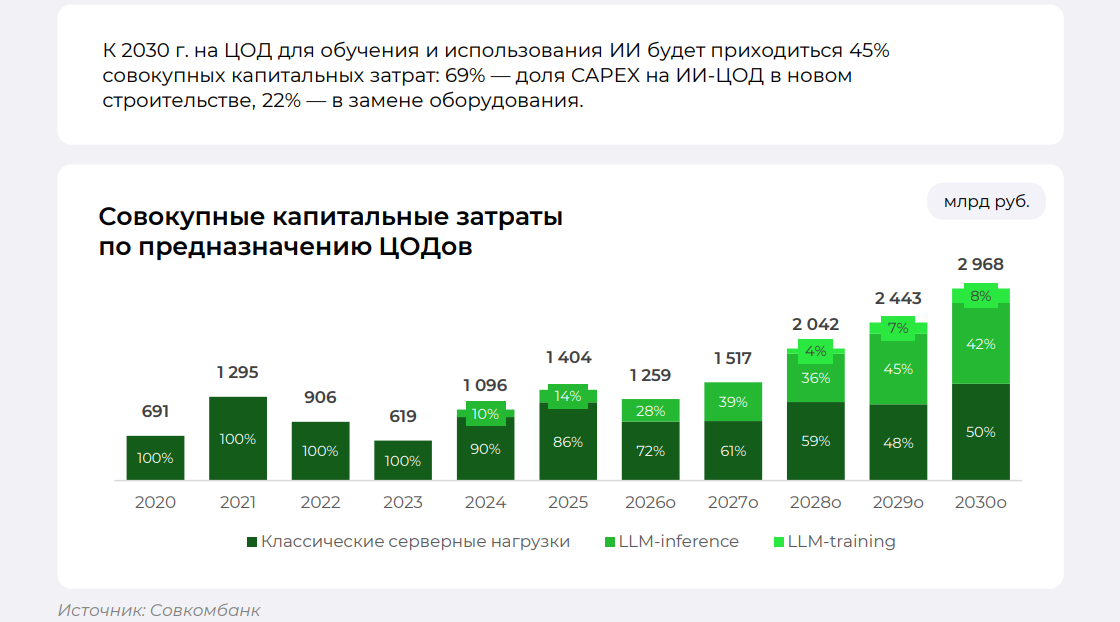
Источник изображения: «Совкомбанк» Отметив, что в 2024–2025 гг. совокупные капитальные затраты на ЦОД в РФ составили 1–1,4 трлн руб., аналитики объясняют их сокращение снижением экономической активности и стагнацией рынка, в связи с чем ввод новых объектов и замена оборудования в дата-центрах откладываются. Вместе с тем, согласно прогнозу аналитиков «Совкомбанка», в ближайшей перспективе, в период 2026–2030 гг. в РФ будет введено 988 МВт новых ЦОД, для чего потребуются инвестиции в размере 4,4 трлн руб. 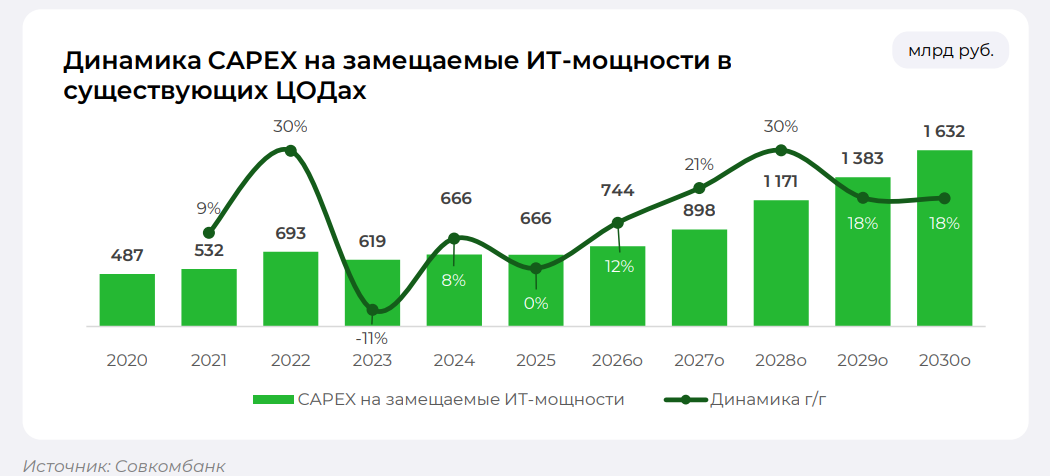
Источник изображения: «Совкомбанк» Ранее сообщалось, что из 128 объявленных в России за последние три года проектов по строительству ЦОД на сумму около 1 трлн руб. было приостановлено 38 с общим объёмом инвестиций 128,6 млрд руб. В числе причин эксперты называют высокую ставку Центробанка, недоступность энергии на ключевых рынках и рост её стоимости, долгое получение разрешений на присоединение к сети и рост спроса на высокоплотные ИИ-стойки.
07.07.2026 [16:34], Руслан Авдеев
Anthropic готова потратить миллиарды долларов на ЦОД в Австралии, но взамен требует переписать законы об интеллектуальной собственностиАмериканская Anthropic спешит как можно быстрее обеспечить себя новыми мощностями ЦОД до IPO. Компания стремится выкупить любые доступные мощности в Австралии — лишь бы те можно было ввести в эксплуатацию к середине 2027 года, поскольку она намерена сделать страну своей второй «базой» для обучения ИИ наряду с США. При этом возник вопрос использования интеллектуальной собственности, доступной на территории страны-материка, сообщает Financial Review. По данным источников, Anthropic уже в текущем месяце надеется подписать первые соглашения с австралийскими дата-центрами. Попутно она ведёт переговоры с властями, надеясь заключить специальное соглашение в сфере интеллектуальной собственности, которое позволит обучать Claude на доступных в Австралии данных. Предполагается, что в обмен на инвестиции в десятки миллиардов долларов в законодательство добавят исключение для Anthropic. Также компания рассчитывает создать фонд поддержки авторов с финансированием за счёт ежегодных платежей. Anthropic сообщила, что австралийские ЦОД нужны ей именно для обучения Claude, поскольку в США ей уже не хватает мощностей. Компания готова заключить контракты с Canberra Data Centres (CDC), AirTrunk, Iren и NextDC. Всего ей нужно около 1,4 ГВт, тогда как мощность всех австралийских ЦОД на конец 2025 года составляла около 1,5 ГВт. В случае выхода в Австралию Anthropic придётся конкурировать с Amazon и Microsoft, которые уже заключили крупные контракты и сами ищут новые ресурсы. 
Источник изображения: Sam Bhattacharyya/unsplash.com В конце марта глава Anthropic Дарио Амодеи (Dario Amodei) посетил страну, встретившись с политиками, финансистами и представителями ЦОД. Местные девелоперы уже начали переговоры с банками и инвесторами, оценивая их готовность финансировать проекты, обеспеченные контрактами с Anthropic. В первую очередь ставка делается на уже существующую инфраструктуру. В конкурсной документации Anthropic нет данных о том, будут ли ЦОД применяться для обучения и инференса одновременно, но источники сообщают именно об обучении. Пока действующее законодательство в стране не позволяет компаниям вроде Anthropic и Google обучать свои ИИ на местных данных без специального разрешения. Власти призывают техногигантов договариваться с представителями «креативного сектора» самостоятельно. Подчёркивается, что правительство неоднократно заявляло о нежелании ослаблять защиту интеллектуальной собственности в связи с развитием ИИ. Поэтому технологическую отрасль призывают искать инновационные решения с одновременным обеспечением справедливого вознаграждения авторам. 
Источник изображения: Andy Thomson/unsplash.com По словам ассоциации Data Centres Australia, ожидаемые инвестиции Anthropic в объёме $15 млрд могут оказаться под угрозой, если операторы не смогут гарантировать стабильное энергоснабжение и быстрое строительство объектов. Энергосистема Австралии включает газовые и угольные электростанции и возобновляемые источники. Операторы ЦОД вроде Firmus уже объявили о поддержке «зелёных» проектов и энергохранилищ для компенсации своего энергопотребления, но эксперты ожидают, что таких инициатив будет недостаточно для круглосуточного надёжного энергоснабжения. Anthropic уже объявила о намерении принять участие в планировании энергетической инфраструктуры страны. Новозеландская инвестиционная группа Infratil, владеющая почти половиной CDC, заявила, что стоимость последней всего за квартал выросла почти на четверть, до $18,5 млрд, из-за увеличения законтрактованных мощностей последней (включая ещё не построенные ЦОД) в Австралии и Новой Зеландии до 3,9 ГВт к 2039 году. Контракт с Anthropic был бы ей крайне выгоден. Кроме того, переманить бизнес Anthropic хотя бы частично очень хотят в Великобритании и даже в Австрии.
07.07.2026 [09:00], Владимир Мироненко
«Базис» выпустил версию платформы Basis Digital Energy 1.7«Базис» (входит в ГК РТК-ЦОД) объявил о выпуске обновления Basis Digital Energy — платформы для управления полным жизненным циклом кластеров на базе Kubernetes. В выпуске Basis Digital Energy 1.7 были добавлены такие функции, как развёртывание кластеров из пользовательских шаблонов и расширение сценариев работы с гипервизором Basis vCore, а также появилась поддержка управления хранилищем артефактов из веб-интерфейса. Решение обеспечивает пользователей инструментами для сборки, тестирования и развёртывания приложений в виде единого управляемого сервиса. В соответствии с подходом DevSecOps осуществляется контроль безопасности на всех этапах разработки и тестирования для выявления рисков на ранних этапах и снижения вероятности появления уязвимостей в готовых решениях. Появившийся в новой версии Basis Digital Energy механизм шаблонов позволяет администратору сохранять готовую конфигурацию кластера, чтобы в дальнейшем оперативно разворачивать на её основе однотипные кластеры. Это не только сокращает долю ручных операций при построении инфраструктуры, но и снижает риск ошибок при повторном развёртывании, обеспечивая более быстрый и предсказуемый результат. 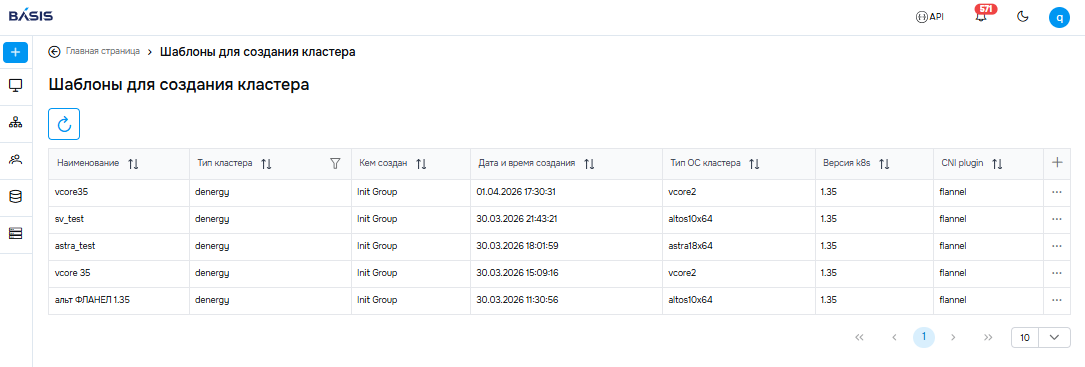
Источник изображений: «Базис» Сохранённые шаблоны для создания кластера Особое внимание в релизе уделено обеспечению комфортной работы в закрытых контурах. В веб-интерфейсе Basis Digital Energy был добавлен раздел управления системным хранилищем артефактов iStore, благодаря чему администратор платформы сможет просматривать и редактировать списки образов и helm-чартов, а также отслеживать действия пользователей через журнал операций. Хранилище iStore обеспечивает возможность работы приложений и кластеров Kubernetes без доступа в интернет, гарантируя конфиденциальность при работе в изолированных средах. Также на Basis Digital Energy с vCore, собственном гипервизоре «Базиса», входящем в единую экосистему продуктов компании, теперь можно как разворачивать саму платформу Basis Digital Energy, так и создавать управляемые кластеры. При создании кластера, а также при добавлении новых узлов и балансировщиков на физических серверах (Bare Metal) теперь можно задавать собственные имена узлов и балансировщиков нагрузки. Также с выходом Basis Digital Energy 1.7 были расширены возможности по установке приложений. Через новый пользовательский каталог теперь можно устанавливать в кластер собственные приложения из кастомных helm-чартов, помимо набора сертифицированных инструментов. Также в каталог был добавлен APISIX — API-шлюз для маршрутизации, защиты и управления трафиком в кластере Kubernetes. 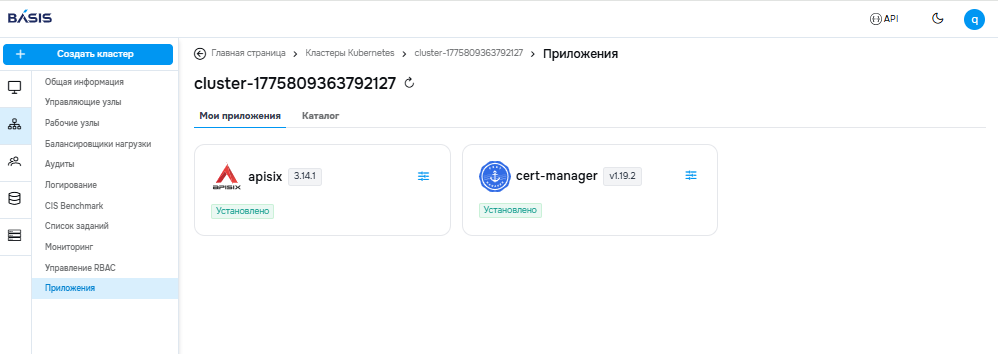
Пользовательский каталог приложений Basis Digital Energy Кроме того, в новом релизе была увеличена гибкость и эффективность платформы под нагрузкой. Администратор теперь сможет выбирать, нужно ли устанавливать сервис мониторинга кластера, при этом фоновый процесс мониторинга состояния узлов и балансировщиков был оптимизирован. В дополнение был переработан механизм аудита для снижения нагрузки на базу данных, заменив хранение записей в ней на файловое хранение. «По данным аналитиков iKS Consulting, следующие 5 лет сегмент российской контейнеризации будет расти примерно на 25 % год к году, и это одна из причин, почему мы вкладываем значительные ресурсы в развитие Basis Digital Energy. Другая, не менее важная причина — потребность заказчиков в решении для работы с контейнерами как части виртуальной инфраструктуры, включающей также серверные и VDI-решения. Именно поэтому мы развиваем наши продукты как единую экосистему», — сообщил Дмитрий Сорокин, технический директор «Базис».
06.07.2026 [18:07], Владимир Мироненко
Selectel и ИТМО создали СП для разработки платформы по созданию ИИ-агентов для бизнесаSelectel и Национальный исследовательский университет ИТМО объявили о запуске совместного предприятия с целью разработки решений в сфере ИИ, в частности — платформы для создания, внедрения и промышленной эксплуатации мультиагентных систем на базе больших языковых моделей (LLM). Новая платформа позволит быстро создавать ИИ-решения под конкретные бизнес-процессы заказчиков, подключать их к корпоративным данным и системам, измерять качество работы и безопасно их развивать по мере изменения задач бизнеса. Коммерческая модель будет учитывать фактическое потребление вычислительных ресурсов и токенов. Оплата заказчиком использования ИИ-агентов будет производиться в зависимости от объёма, сложности и места выполнения работы: на инфраструктуре Selectel, в выделенном контуре или непосредственно у заказчика. Сообщается, что в штат СП войдёт проектная группа ИТМО и опытные эксперты индустрии. ИТМО выступит ключевым центром компетенций с готовыми наработками, а Selectel обеспечит финансирование проекта на сумму более 1 млрд руб., а также предоставит необходимую IT-инфраструктуру. Ранее сообщалось, что Selectel создал новую компанию для реализации ИИ-проектов — «Эмерджентные мультиагентные системы» (ООО «ЭМС»). По словам Олега Любимова, гендиректора Selectel, объединив экспертизу Selectel в построении специализированной инфраструктуры для ИИ с профильными компетенциями команды ИТМО, и действуя при этом как самостоятельный игрок, новое предприятие будет способствовать ускорению развития прикладных решений, необходимых крупному бизнесу на фоне перехода к агентной экономике ИИ-систем. 
Источник изображения: ИТМО Любимов уточнил в интервью ресурсу Forbes, что у Selectel доля в уставном капитале СП составляет ⅔, у ИТМО — ⅓. Руководитель ИТМО Александр Бухановский рассказал Forbes, что специалисты ИТМО разработали технологию, которая автоматизирует конструирование прикладных агентов ИИ и мультиагентных систем на их основе под комплексные бизнес-задачи. «Мы реализовали ИИ, который умеет делать ИИ», — отметил он. С 2020 года Selectel инвестировал в развитие ИИ-решений более 3,5 млрд руб. В ближайшие пять лет провайдер планирует увеличить финансирование проектов в сфере ИИ, выделив на эти цели 10 млрд руб. С конца прошлого года 25 % АО «Селектел» принадлежит компании «Каталитик Пипл», созданной МКПАО «Т-Технологии» и ХК «Интеррос».
06.07.2026 [17:55], Андрей Крупин
Представлена российская платформа «Боцман AI» для запуска ИИ-моделей внутри защищённого контура компании«Группа Астра» объявила о выпуске программного комплекса «Боцман AI», предназначенного для развёртывания языковых и других моделей искусственного интеллекта внутри защищённого контура организации, без передачи данных во внешние облачные сервисы. «Боцман AI» является расширением платформы «Боцман» — отечественного решения оркестрации контейнеров на базе Kubernetes, входящего в состав Astra Dev Platform и ориентированного на компании, которые строят внутренние платформы разработки и эксплуатируют приложения в изолированных или регулируемых IT-инфраструктурах. Решение позволяет организациям разворачивать и запускать ИИ-нагрузки внутри собственного сетевого контура — с сохранением суверенитета над данными, предсказуемыми затратами и без привязки к зарубежным провайдерам. Для работы с «Боцман AI» достаточно произвести описание ИИ-модели через стандартный Kubernetes-ресурс — всё остальное система делает автоматически, говорят разработчики. Она самостоятельно подготавливает хранилище весов и запускает среду выполнения с нужным движком — будь то vLLM, Ollama, SGLang или FasterWhisper, после чего публикует модель через единый шлюз. Отдельного внимания заслуживает механизм обновлений — они происходят без образования окна недоступности, что особенно критично при работе с дорогостоящей GPU-инфраструктурой. 
Источник изображения: Numan Ali / unsplash.com Для взаимодействия с моделями в «Боцман AI» задействован OpenAI-совместимый API. Помимо базовой функциональности, платформа предлагает ряд инструментов для промышленной эксплуатации. В неё встроены автоматическое масштабирование под нагрузку, система биллинга и управление API-ключами с контролем бюджетов, что позволяет прозрачно распределять ресурсы между командами и проектами. Установка программного решения осуществляется через «Боцман Apps & Marketplace» в виде Helm-чарта.
06.07.2026 [16:50], Руслан Авдеев
Передовой ИИ ЦОД Microsoft Fairwater в Висконсине оказался не только продвинутым, но и шумнымНедавно Microsoft объявила о вводе в эксплуатацию своего самого передового дата-центра по проекту Fairwater в Маунт-Плезант (Mount Pleasant) в Висконсине, который со временем станет вдвое крупнее. Однако вскоре после запуска дата-центра группа местных жителей подала к компании коллективный иск, в котором жалуется на высокий уровень шума от нового объекта, сообщает Wisconsin Public Radio. Коллективный иск подан на днях в Окружной суд восточного округа Висконсина тремя гражданами, проживающими вблизи дата-центра. В исковом заявлении сообщается, что в процесс эксплуатации и обслуживания оборудования создаётся «чрезмерный и необоснованный» шум, который достигает собственности истцов. Тем самым причиняется ущерб их собственности с нарушением права на спокойное пользование ею. Кроме того, Microsoft обвиняется в халатности, поскольку компания, по словам истцов, не принимает достаточных мер для устранения проблемы. В иске утверждается, что ЦОД создаёт значимое шумовое загрязнение из-за работы дизельных генераторов и HVAC-систем, включая чиллеры, градирни, вентиляционные установки и др. — при этом сама Microsoft гордится системой охлаждения ЦОД, называя её одной из крупнейших в мире. В иске же подчёркивается, что шум не просто чрезмерный, но и «постоянный и повсеместный». Утверждается, что хотя некоторые процессы создают слышимый шум, значительная часть шумового загрязнения приходится на низкочастотный инфразвук. 
Источник изображения: Red Shuheart/unsplash.com Представитель Microsoft заявил, что компания стремится быть «хорошим соседом». 15 апреля компания сообщила, что жители к северу от ЦОД заметили «монотонный гудящий звук». Хотя уровень этого шума якобы соответствовал местным нормативам, Microsoft заявила, что серьёзно относится к подобным отзывам, и назвала источником шума являются охлаждающие вентиляторы. 18 июня было объявлено, что инженеры провели тесты и приняли меры по снижению уровня шума. С тех пор, как заявляют власти Маунт-Плезант, официальных жалоб больше не было. Есть и другие жалобы, в частности, на шум и пыль со строительных площадок, где возводят новые очереди проекта. Причём пыли столько, что, по словам некоторых, мыть машины нет смысла, хотя компания обещала, что подметально-уборочные машины будут работать по 10 часов в день, а на выездах со стройплощадок установят системы помывки покрышек. Речь идёт также о световом загрязнении, увеличении транспортного трафика и изменении сельского ландшафта. По словам Microsoft, строительные работы разрешены с 06:00 до 22:00, но не всех жителей это устраивает. Некоторым даже пришлось переехать из-за возникших неудобств. Microsoft подчёркивает, что продолжает работать с генеральным подрядчиком, чтобы устранять проблемы и свести к минимум влияние строек на соседние населённые пункты. При этом в новостях сообщалось, что в строительстве принимают участие почти 10 тыс. рабочих, а Microsoft и её подрядчики нанимают всё новых людей. Тем временем глава поселения Маунт-Плезант очень высоко оценил открытие дата-центра. По его словам, это историческая веха для всего округа. Стоить отметить, что чрезмерные восторги по поводу строительства ЦОД чреваты неприятностями для самих американских чиновников. Так, в апреле появилась новость, что в городке Фестус штата Миссури, после того, как городской совет без лишнего шума одобрил строительство дата-центра стоимостью $6 млрд, избиратели отстранили от должности половину его членов. А QTS и Compass были вынуждены отказаться от строительства крупного кампуса в Вирджинии, поскольку местные жители и активисты сделали работу компаний и партнёров невозможной.
06.07.2026 [14:33], Руслан Авдеев
Brookfield увеличит инвестиции в Bloom Energy до $25 млрд — для внедрения топливных ячеек в ИИ ЦОДКомпания Brookfield расширила взаимодействие с американской Bloom Energy — разработчиком и поставщиком твердооксидных топливных элементов (SOFC). Она поддержит расширение поставок соответствующих систем клиентам, занимающимся оснащением ИИ ЦОД, сообщает Datacenter Dynamics. В рамках расширенного соглашения Brookfield нарастит инвестиции в Bloom с $5 млрд, о которых договорились в октябре 2025 года, до $25 млрд. Компании подчёркивают, что новый этап сотрудничества отражает высокий спрос со стороны рынка ЦОД на топливные элементы Bloom. Расширенный инвестиционный пакет — часть специального фонда AI Infrastructure Fund компании Brookfield, основанного в ноябре 2025 года с целью инвестировать $100 млрд. Стратегия Brookfield — инвестиции в крупные ИИ-фабрики, энергетические решения, вычислительные мощности и стратегические партнёрства в сфере распоряжения капиталом. По словам Bloom Energy, на момент заключения партнёрства оговаривалось, что речь идёт о первом этапе более масштабного плана. Новые обязательства отражают новый импульс на рынке — о нём свидетельствуют недавно анонсированные крупномасштабные сделки в сфере ЦОД. Bloom — ведущий разработчик и поставщик топливных элементов для дата-центров на основе SOFC. Утверждается, что это обеспечивает более высокий КПД, чем сжигание и более низкие выбросы. 
Источник изображения: Bloom Energy Компания уже заключила ряд соглашений в сфере ЦОД. В мае она подписала контракт c Nebius на обеспечение генерирующими мощностями ЦОД в США. До этого она расширила соглашение с Oracle о поставке 2,8 ГВт мощностей, в прошлом году было подписано соглашение на 1,2 ГВт. Развёртывание оборудования уже началось и продолжится в 2027 году. Также соглашение о развёртывании систем Bloom общей мощностью более 100 МВт в 19 ЦОД заключено с Equinix, подписан договор с American Electric Power на поставку SOFC мощностью до 1 ГВт, чтобы обеспечить автономное электроснабжение ИИ ЦОД.
06.07.2026 [13:07], Сергей Карасёв
NVIDIA откладывает выпуск стоек Kyber на год и отказывается от архитектуры NVL72×2Компания NVIDIA, по информации SemiAnalysis, вынуждена пересмотреть планы по выпуску ИИ-продуктов следующего поколения. В частности, возникли сложности с проектом стоек Kyber, релиз которых откладывается примерно на год — до 2028-го. Изначально предполагалось, что NVIDIA выпустит стоечное решение Kyber NVL144/NVL72 в 2027 году. Система объединит 144 ускорителя Rubin Ultra с NVLink 7, обеспечив четырёхкратное повышение производительности по сравнению с Blackwell NVL72 (Oberon). Однако теперь стало известно, что вывод Kyber на коммерческий рынок задержится примерно на 12 мес. Связано это с трудностями при разработке центральной коммутационной платы (midplane). Выпуск NVL576 — более крупной системы, объединяющей восемь стоек посредством оптических соединений CPO, — скорее всего, также будет отложен или же решение выйдет ограниченной партией. 
Источник изображения: NVIDIA Сообщается, что NVIDIA полностью отказалась от архитектуры NVL72×2, которая рассматривалась в качестве альтернативы Kyber. В случае NVL72×2 изучалась возможность размещения двух стоек Oberon «спина к спине». Однако проект пришлось отменить из-за критики со стороны облачных провайдеров и гиперскейлеров, которые посчитали такую конструкцию неудобной и слишком дорогой в эксплуатации. Вместе с тем в GB200 NVIDIA тоже изначально отказалась от NVL36×2, но в итоге партнёры реализовали такую конфигурацию. Отменён также выпуск изделий Rubin Ultra с четырьмя вычислительными чиплетами, тогда как коммутаторы NVLink с интегрированной оптикой (СРО) станут доступны не ранее, чем состоится анонс ускорителей Feynman. На этом фоне ожидается увеличение объёмов поставок решений Oberon Rubin и Oberon Rubin Ultra. В целом, уже организовано масштабное производство изделий Rubin: предстоящей осенью NVIDIA начнёт поставлять их восьми облачным партнёрам, включая Amazon Web Services (AWS), Microsoft Azure и Google Cloud.
05.07.2026 [19:48], Сергей Карасёв
Crusoe рассчитывает привлечь $3 млрд при оценке в $30 млрдКомпания Crusoe, специализирующаяся на строительстве дата-центров для ИИ-нагрузок, по информации Bloomberg, ведёт переговоры о проведении раунда финансирования на $3 млрд. При этом оценка стартапа может достичь $30 млрд, что втрое превышает его рыночную стоимость по состоянию на 2025 год. О том, какие именно инвесторы могут предоставить средства, не сообщается. В последнем раунде финансирования Crusoe участвовали NVIDIA, Salesforce Ventures и более десятка других компаний. На сегодняшний день стартап привлёк в общей сложности $2,77 млрд. Crusoe реализует проекты ЦОД в интересах крупных технологических компаний, таких как Microsoft, Oracle и OpenAI. Компания располагает контрактами на дата-центры общей мощностью почти 5 ГВт. Недавно Crusoe заключила соглашение на поставку 1,6 ГВт вычислительных мощностей ЦОД для Meta✴. 
Источник изображения: Crusoe Crusoe занимается созданием дата-центров из предварительно изготовленных модулей, которые поставляются с серверными стойками, системами управления питанием и оборудованием для охлаждения. Компания также оказывает поддержку заказчикам при вводе объектов в эксплуатацию, включая подсоединение ЦОД к электросети. Дополнительно предоставляется платформа управления Command Center, которая выявляет сбои в работе ИИ-серверов и автоматически заменяет проблемные узлы резервными машинами. В целом, как заявляет Crusoe, её комплексный подход значительно ускоряет реализацию крупных инфраструктурных проектов в области ИИ. Компания способна создать новый дата-центр за несколько месяцев, тогда как зачастую на подобные проекты уходят годы. Crusoe также управляет собственным публичным облаком, оптимизированным для задач ИИ.
03.07.2026 [15:34], Руслан Авдеев
Meta✴ отправила в болота Луизианы 65-тонных роботов на постройку солнечной электростанции для ИИ ЦОДДесять 65-тонных роботов Built Robotics работают на строительстве комплекса Hyperion компании Meta✴. В частности, речь идёт о работах на территории солнечной электростанции в Луизиане, призванной обслуживать крупнейший ЦОД компании, сообщает eWeek. Ежедневно автономные машины забивают в грунт почти 1 тыс. свай, каждая длиной около 4,3 м и массой 91 кг. Built Robotics оснащает строительную робототехнику датчиками, камерами, GPS и специальным ПО, позволяющим машинам автономно работать в заранее заданных зонах. На объекте они выполняют более половины работ по забивке свай. В ассортименте Built Robotics есть машина RPD 35, которая отвечает за транспортировку и забивку свай, а также стабилизатор RPS 25, который позиционирует и удерживает сваи в процессе забивки. При этом не уточняется, какие именно модели применяются в Луизиане. На некоторых участках в низинах местность очень болотистая, именно туда и направили роботов, потому что «им всё равно». Built Robotics сравнивает роль человека с ролью «прораба» для роботов. Рабочие организуют работу машин, обеспечивают их топливом и материалами, а также контролируют выполнение работ. По оценкам компании, обычной строительной бригаде понадобилось бы в 3–4 раза больше работников для выполнения того же объёма работ, который выполняют 10 роботов в Луизиане. Для строительных компаний, которым не хватает людей для реализации крупных энергопроектов, это серьёзный стимул для внедрения автономной техники. 
Источник изображения: Built Robotics Кампус Hyperion — это крупнейший проект ИИ ЦОД в истории Meta✴ на сегодняшний день, он обойдётся в $50 млрд. Итоговая мощность ЦОД, как ожидается, составит 5 ГВт. Для питания дата-центров Entergy построит десять газовых электростанций общей мощностью 7,4 ГВт и индивидуальную ЛЭП за $1,2 млрд. А солнечная электростанция должна разбавить эти мощности «чистой» энергией. |
|

